Pontozási modellek üzembe helyezése kötegelt végpontokon
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
A Batch-végpontok kényelmes módot nyújtanak olyan modellek üzembe helyezésére, amelyek következtetést futtatnak nagy mennyiségű adaton. Ezek a végpontok leegyszerűsítik a modellek kötegelt pontozáshoz való üzemeltetésének folyamatát, így a fókusz nem az infrastruktúrára, hanem a gépi tanulásra koncentrál.
A modell üzembe helyezéséhez használjon kötegelt végpontokat a következő esetekben:
- Drága modelljei hosszabb időt igényelnek a következtetés futtatásához.
- Nagy mennyiségű, több fájlban elosztott adatra kell következtetnie.
- Nem rendelkezik alacsony késési követelményekkel.
- Kihasználhatja a párhuzamosítás előnyeit.
Ebben a cikkben kötegelt végpontot használ egy olyan gépi tanulási modell üzembe helyezéséhez, amely megoldja a klasszikus MNIST (Módosított Nemzeti Szabványügyi és Technológiai Intézet) számjegyfelismerési problémáját. Az üzembe helyezett modell ezután kötegelt következtetést hajt végre nagy mennyiségű adat – ebben az esetben a képfájlok – alapján. Először hozzon létre egy, a Torch használatával létrehozott modell kötegelt üzembe helyezését. Ez az üzembe helyezés lesz az alapértelmezett a végponton. Később létrehoz egy második üzembe helyezést a TensorFlow (Keras) használatával létrehozott módhoz, teszteli a második üzembe helyezést, majd beállítja a végpont alapértelmezett üzembe helyezését.
A jelen cikkben szereplő parancsok helyi futtatásához szükséges kódmintákkal és fájlokkal együtt követendő lépésekért tekintse meg a Példák adattár klónozása című szakaszt. A kódmintákat és -fájlokat az azureml-examples adattár tartalmazza.
Előfeltételek
A cikkben ismertetett lépések végrehajtása előtt győződjön meg arról, hogy rendelkezik a következő előfeltételekkel:
Azure-előfizetés. Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot. Próbálja ki az Azure Machine Learning ingyenes vagy fizetős verzióját.
Egy Azure Machine Learning-munkaterület. Ha nincs ilyenje, a Munkaterületek kezelése című cikk lépéseit követve hozzon létre egyet.
A következő feladatok elvégzéséhez győződjön meg arról, hogy rendelkezik ezekkel az engedélyekkel a munkaterületen:
Batch-végpontok és -üzemelő példányok létrehozása/kezelése: Tulajdonosi szerepkör, közreműködői szerepkör vagy egyéni szerepkör használata.
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*ARM-környezetek létrehozása a munkaterület erőforráscsoportjában: Tulajdonosi szerepkör, közreműködői szerepkör vagy egyéni szerepkör használata, amely lehetővé teszi
Microsoft.Resources/deployments/writeabban az erőforráscsoportban, ahol a munkaterület üzembe van helyezve.
Az Azure Machine Learning használatához telepítenie kell a következő szoftvert:
A KÖVETKEZŐRE VONATKOZIK:
Azure CLI ml-bővítmény v2 (aktuális)Az Azure CLI és az
mlAzure Machine Learning bővítménye.az extension add -n ml
A példák adattárának klónozása
A cikkben szereplő példa az azureml-examples adattárban található kódmintákon alapul. Ha helyileg szeretné futtatni a parancsokat a YAML és más fájlok másolása/beillesztése nélkül, először klónozza az adattárat, majd módosítsa a könyvtárakat a mappára:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
A rendszer előkészítése
Csatlakozás a munkaterülethez
Először csatlakozzon az Azure Machine Learning-munkaterülethez, ahol dolgozni fog.
Ha még nem állította be az Azure CLI alapértelmezett beállításait, mentse az alapértelmezett beállításokat. Az előfizetés, a munkaterület, az erőforráscsoport és a hely értékeinek többszöri átadásának elkerülése érdekében futtassa ezt a kódot:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Számítás létrehozása
A Batch-végpontok számítási fürtökön futnak, és támogatják az Azure Machine Learning számítási fürtöket (AmlCompute) és a Kubernetes-fürtöket. A fürtök megosztott erőforrások, ezért egy fürt egy vagy több kötegtelepítést üzemeltethet (szükség esetén más számítási feladatokkal együtt).
Hozzon létre egy számítást az batch-clusteralábbi kódban látható módon. Igény szerint módosíthatja a számítást, és hivatkozhat a számításra azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Feljegyzés
A számításért jelenleg nem számítunk fel díjat, mivel a fürt 0 csomóponton marad, amíg meg nem hívja a batch végpontot, és el nem küld egy kötegpontozási feladatot. A számítási költségekről további információt az AmlCompute költségeinek kezelése és optimalizálása című témakörben talál.
Batch-végpont létrehozása
A kötegvégpontok olyan HTTPS-végpontok, amelyeket az ügyfelek meghívhatnak egy kötegpontozási feladat aktiválásához. A kötegelt pontozási feladat egy olyan feladat, amely több bemenetet is pontszámmal rendelkezik. A kötegelt üzembe helyezés olyan számítási erőforrások készlete, amelyek a tényleges kötegpontozást (vagy kötegelt következtetést) tartalmazó modellt üzemeltetik. Egy kötegvégpont több kötegtelepítéssel is rendelkezhet. A kötegelt végpontokkal kapcsolatos további információkért lásd : Mik azok a kötegelt végpontok?.
Tipp.
Az egyik kötegelt üzembe helyezés a végpont alapértelmezett központi telepítéseként szolgál. A végpont meghívásakor az alapértelmezett üzembe helyezés elvégzi a tényleges kötegpontozást. A kötegvégpontokról és az üzemelő példányokról további információt a kötegvégpontok és a kötegelt üzembe helyezés című témakörben talál.
Nevezze el a végpontot. A végpont nevének egyedinek kell lennie egy Azure-régióban, mivel a nevet a végpont URI-ja tartalmazza. Például csak egy kötegvégpont lehet, amelyben a név
mybatchendpointszerepelwestus2.A kötegvégpont konfigurálása
A következő YAML-fájl egy kötegvégpontot határoz meg. Ezt a fájlt a parancssori felület parancsával használhatja a kötegelt végpontok létrehozásához.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningAz alábbi táblázat a végpont fő tulajdonságait ismerteti. A teljes kötegvégpont YAML-sémáját lásd : CLI (v2) batch endpoint YAML-séma.
Kulcs Leírás nameA kötegvégpont neve. Az Azure-régió szintjén egyedinek kell lennie. descriptionA kötegvégpont leírása. Ez a tulajdonság opcionális. tagsA végpontba felvenni kívánt címkék. Ez a tulajdonság opcionális. Hozza létre a végpontot:
Kötegelt üzembe helyezés létrehozása
A modelltelepítés a tényleges következtetést okozó modell üzemeltetéséhez szükséges erőforrások készlete. Batch-modell üzembe helyezéséhez a következő elemekre van szüksége:
- Regisztrált modell a munkaterületen
- A modell pontszámát hívó kód
- Környezet, amelyen telepítve vannak a modell függőségei
- Az előre létrehozott számítási és erőforrás-beállítások
Először regisztrálja az üzembe helyezendő modellt – egy fáklyamodellt a népszerű számjegyfelismerési problémához (MNIST). A Batch-környezetek csak a munkaterületen regisztrált modelleket helyezhetik üzembe. Ezt a lépést kihagyhatja, ha az üzembe helyezni kívánt modell már regisztrálva van.
Tipp.
A modellek nem a végponthoz, hanem az üzembe helyezéshez vannak társítva. Ez azt jelenti, hogy egyetlen végpont különböző modelleket (vagy modellverziókat) képes kiszolgálni ugyanabban a végpontban, feltéve, hogy a különböző modellek (vagy modellverziók) különböző üzemelő példányokban vannak üzembe helyezve.
Most itt az ideje, hogy hozzon létre egy pontozó szkriptet. A Batch-üzemelő példányokhoz pontozási szkript szükséges, amely jelzi, hogyan kell végrehajtani egy adott modellt, és hogyan kell feldolgozni a bemeneti adatokat. A Batch-végpontok támogatják a Pythonban létrehozott szkripteket. Ebben az esetben üzembe helyez egy modellt, amely beolvassa a számjegyeket képviselő képfájlokat, és a megfelelő számjegyet adja ki. A pontozási szkript a következő:
Feljegyzés
MLflow-modellek esetén az Azure Machine Learning automatikusan létrehozza a pontozási szkriptet, így önnek nem kell megadnia egyet. Ha a modell MLflow-modell, kihagyhatja ezt a lépést. További információ a kötegvégpontok MLflow-modellekkel való használatáról: MLflow-modellek használata kötegtelepítésekben.
Figyelmeztetés
Ha automatikus gépi tanulási (AutoML) modellt helyez üzembe egy batch-végpont alatt, vegye figyelembe, hogy az AutoML által biztosított pontozási szkript csak online végpontokhoz használható, és nem kötegelt végrehajtásra lett tervezve. A kötegelt üzembe helyezés pontozási szkriptjeinek létrehozásáról további információt a Kötegtelepítések pontozási szkriptjeinek létrehozása című témakörben talál.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Hozzon létre egy környezetet, ahol a kötegtelepítés futni fog. A környezetnek tartalmaznia kell a csomagokat és
azureml-dataset-runtime[fuse]a kötegvégpontok által megkövetelt csomagokatazureml-core, valamint a kód futtatásához szükséges függőségeket. Ebben az esetben a függőségek egyconda.yamlfájlban lettek rögzítve:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Fontos
A csomagok
azureml-core,azureml-dataset-runtime[fuse]amelyekre a kötegtelepítések szükségesek, és szerepelnie kell a környezeti függőségekben.Adja meg a környezetet az alábbiak szerint:
A környezetdefiníció magát az üzembehelyezési definíciót fogja tartalmazni névtelen környezetként. Az üzembe helyezés során a következő sorok láthatók:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlFigyelmeztetés
A kötegelt környezetekben a válogatott környezetek nem támogatottak. Meg kell adnia a saját környezetét. A folyamat egyszerűsítése érdekében mindig használhatja a válogatott környezet alaprendszerképét.
Üzembehelyezési definíció létrehozása
üzembe helyezési fáklya/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoAz alábbi táblázat a köteg üzembe helyezésének fő tulajdonságait ismerteti. A teljes kötegelt üzembehelyezési YAML-sémáért tekintse meg a CLI (v2) batch deployment YAML-sémáját.
Kulcs Leírás nameAz üzembe helyezés neve. endpoint_nameAz üzembe helyezés létrehozásához szükséges végpont neve. modelA kötegelt pontozáshoz használandó modell. A példa egy beágyazott modellt határoz meg a használatával path. Ez a definíció lehetővé teszi a modellfájlok automatikus feltöltését és regisztrálását automatikusan generált névvel és verzióval. További lehetőségekért tekintse meg a Modell sémát . Az éles forgatókönyvekhez ajánlott eljárásként külön kell létrehoznia a modellt, és itt kell hivatkoznia rá. Meglévő modellre való hivatkozáshoz használja a szintaxistazureml:<model-name>:<model-version>.code_configuration.codeA modell pontozásához használt összes Python-forráskódot tartalmazó helyi könyvtár. code_configuration.scoring_scriptA Python-fájl a code_configuration.codekönyvtárban. Ennek a fájlnak függvénytinit()és függvényt kell tartalmazniarun(). Használja a függvénytinit()bármilyen költséges vagy gyakori előkészítéshez (például a modell memóriába való betöltéséhez).init()a rendszer csak egyszer hívja meg a folyamatot. Az egyes bejegyzések pontozásáramini_batchhasználhatórun(mini_batch); az érték a fájl elérési útjainak listája. Arun()függvénynek pandas DataFrame-et vagy tömböt kell visszaadnia. Minden visszaadott elem a bemeneti elem egy sikeres futtatását jelzi amini_batch. A pontozási szkriptek készítésével kapcsolatos további információkért lásd : A pontozási szkript ismertetése.environmentA modell pontozásához használni kívánt környezet. A példa egy beágyazott conda_filekörnyezetet határoz meg az andimage. Aconda_filefüggőségek aimage. A környezet automatikusan regisztrálva lesz egy automatikusan létrehozott névvel és verzióval. További lehetőségekért tekintse meg a Környezeti sémát . Az éles forgatókönyvekhez ajánlott eljárásként külön kell létrehoznia a környezetet, és itt kell hivatkoznia rá. Meglévő környezetre való hivatkozáshoz használja a szintaxistazureml:<environment-name>:<environment-version>.computeA kötegelt pontozás futtatásához használni kívánt számítás. A példa az batch-clusterelején létrehozott szöveget használja, és aazureml:<compute-name>szintaxissal hivatkozik rá.resources.instance_countAz egyes kötegelt pontozási feladatokhoz használandó példányok száma. settings.max_concurrency_per_instanceA párhuzamos scoring_scriptfuttatások maximális száma példányonként.settings.mini_batch_sizeAz egy run()hívásban feldolgozható fájlokscoring_scriptszáma.settings.output_actionHogyan kell rendszerezni a kimenetet a kimeneti fájlban. append_rowaz összesrun()visszaadott kimeneti eredményt egyetlen, elnevezettoutput_file_namefájlba fogja egyesíteni.summary_onlynem egyesítheti a kimeneti eredményeket, és csak a kiszámított értéket számítja kierror_threshold.settings.output_file_nameA kötegpontozás kimeneti fájljának neve a következőhöz append_rowoutput_action: .settings.retry_settings.max_retriesSikertelen próbálkozások scoring_scriptrun()maximális száma.settings.retry_settings.timeoutEgy mini köteg pontozásának scoring_scriptrun()időtúllépése másodpercben.settings.error_thresholdA figyelmen kívül hagyandó bemeneti fájl pontozási hibáinak száma. Ha a teljes bemenet hibaszáma meghaladja ezt az értéket, a kötegpontozási feladat leáll. A példa azt -1jelzi, hogy a kötegpontozási feladat megszüntetése nélkül tetszőleges számú hiba engedélyezett.settings.logging_levelNaplók részletessége. A részletesség növelésének értékei a következők: FIGYELMEZTETÉS, INFORMÁCIÓ és HIBAKERESÉS. settings.environment_variablesA környezeti változó név-érték párjainak szótára, amelyet az egyes kötegpontozási feladatokhoz kell beállítani. Hozza létre az üzembe helyezést:
Futtassa a következő kódot egy batch-üzembe helyezés létrehozásához a batch végpont alatt, és állítsa be alapértelmezett üzembe helyezésként.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultTipp.
A
--set-defaultparaméter az újonnan létrehozott üzembe helyezést állítja be a végpont alapértelmezett üzemelő példányaként. Ezzel kényelmesen létrehozhatja a végpont új alapértelmezett üzembe helyezését, különösen az első üzembe helyezéshez. Az éles forgatókönyvek ajánlott eljárása, hogy új üzembe helyezést szeretne létrehozni anélkül, hogy alapértelmezettként állítanák be. Ellenőrizze, hogy az üzembe helyezés a várt módon működik-e, majd később frissítse az alapértelmezett üzembe helyezést. A folyamat implementálásával kapcsolatos további információkért tekintse meg az Új modell üzembe helyezése című szakaszt.Ellenőrizze a kötegvégpont és az üzembe helyezés részleteit.

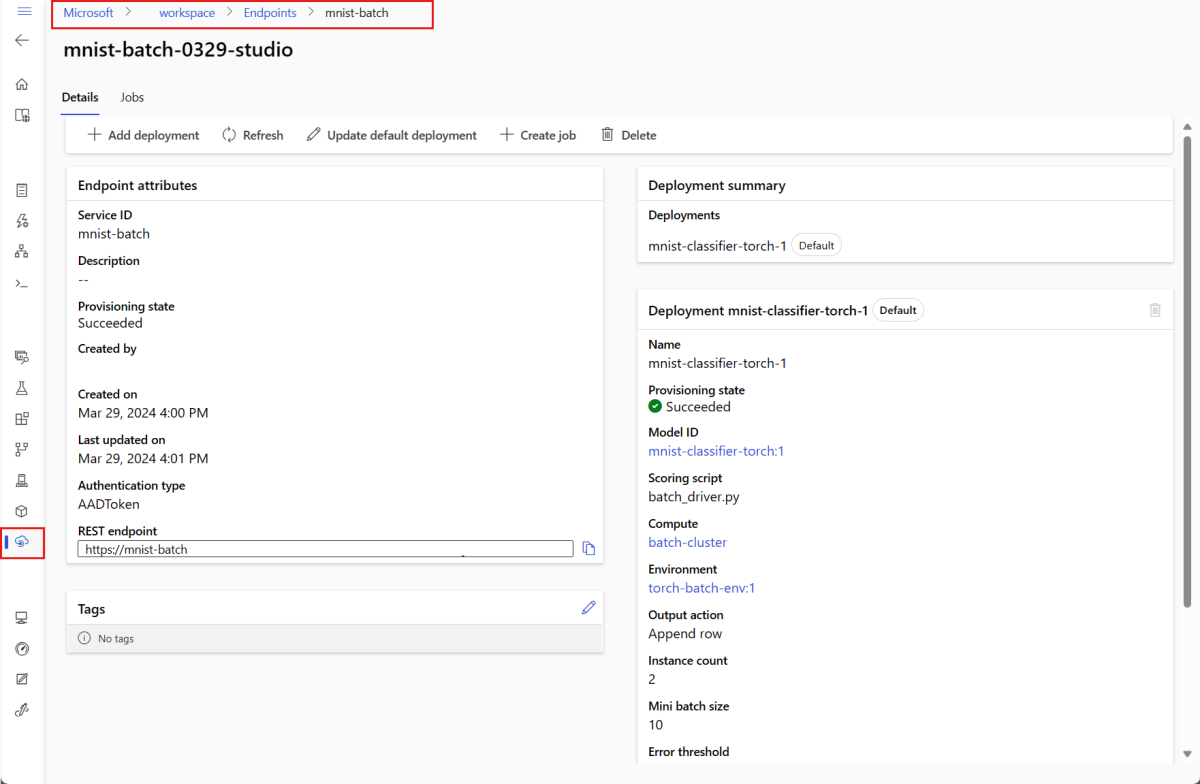
Batch-végpontok futtatása és a hozzáférési eredmények elérése
A kötegvégpont meghívása kötegpontozási feladatot indít el. A rendszer visszaadja a feladatot name a meghívási válaszból, és a kötegelt pontozási folyamat nyomon követésére használható. Amikor kötegelt végpontokon futtatja a pontozási modelleket, meg kell adnia a bemeneti adatok elérési útját, hogy a végpontok megtalálhassák a pontszámolni kívánt adatokat. Az alábbi példa bemutatja, hogyan indíthat el új feladatot az Azure Storage-fiókban tárolt MNIST-adathalmaz mintaadatain keresztül.
Kötegelt végpontot futtathat és hívhat meg az Azure CLI, az Azure Machine Learning SDK vagy a REST-végpontok használatával. További információ ezekről a lehetőségekről: Feladatok és bemeneti adatok létrehozása kötegelt végpontokhoz.
Feljegyzés
Hogyan működik a párhuzamosítás?
A batch-telepítések fájlszinten terjesztik a munkát, ami azt jelenti, hogy egy 100 fájlt tartalmazó mappa, amely 10 fájlból álló mini-kötegekkel rendelkezik, 10 köteg 10 fájlt hoz létre egyenként. Figyelje meg, hogy ez az érintett fájlok méretétől függetlenül történik. Ha a fájlok túl nagy méretűek ahhoz, hogy nagy minikötegekben dolgozzanak fel, javasoljuk, hogy vagy ossza fel a fájlokat kisebb fájlokra, hogy magasabb szintű párhuzamosságot érjen el, vagy csökkentse a fájlok számát mini-kötegenként. A kötegtelepítések jelenleg nem tudják figyelembe venni a fájl méreteloszlását.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



A Batch-végpontok támogatják a különböző helyeken található fájlok vagy mappák olvasását. A támogatott típusokról és azok megadásáról további információt a Batch-végpontok feladataiból származó adatok elérése című témakörben talál.
Kötegelt feladat végrehajtási folyamatának monitorozása
A kötegelt pontozási feladatok általában némi időt vesznek igénybe a bemenetek teljes készletének feldolgozásához.
Az alábbi kód ellenőrzi a feladat állapotát, és az Azure Machine Learning Studióra mutató hivatkozást ad ki további részletekért.
az ml job show -n $JOB_NAME --web

Kötegelt pontozási eredmények ellenőrzése
A feladatkimenetek a felhőalapú tárolóban vannak tárolva, akár a munkaterület alapértelmezett blobtárolójában, akár a megadott tárolóban. Az alapértelmezett beállítások módosításáról a kimeneti hely konfigurálása című témakörben olvashat. A következő lépések lehetővé teszik a pontozási eredmények megtekintését az Azure Storage Explorerben a feladat befejezésekor:
Futtassa az alábbi kódot a kötegelt pontozási feladat azure Machine Learning Studióban való megnyitásához. A feladatstúdió hivatkozása az értékként
interactionEndpoints.Studio.endpointmegadott válaszbaninvokeis szerepel.az ml job show -n $JOB_NAME --webA feladat gráfjában válassza ki a
batchscoringlépést.Válassza a Kimenetek + naplók lapot, majd az Adatkimenetek megjelenítése lehetőséget.
Az adatkimenetek közül válassza az ikont a Storage Explorer megnyitásához.

A Pontozási eredmények a Storage Explorerben az alábbi mintalaphoz hasonlóak:



A kimeneti hely konfigurálása
A kötegpontozási eredmények alapértelmezés szerint a munkaterület alapértelmezett blobtárolójában vannak tárolva egy feladatnév (rendszer által generált GUID) nevű mappában. A kötegvégpont meghívásakor beállíthatja, hogy hol tárolja a pontozási kimeneteket.
Az Azure Machine Learning regisztrált adattárában lévő bármely mappa konfigurálására használható output-path . A szintaxis --output-path ugyanaz, mint --input amikor egy mappát ad meg, azureml://datastores/<datastore-name>/paths/<path-on-datastore>/azaz. Új kimeneti fájlnév konfigurálására használható --set output_file_name=<your-file-name> .
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Figyelmeztetés
Egyedi kimeneti helyet kell használnia. Ha a kimeneti fájl létezik, a kötegpontozási feladat sikertelen lesz.
Fontos
A bemenetekkel ellentétben a kimenetek csak a Blob Storage-fiókokon futó Azure Machine Learning-adattárakban tárolhatók.
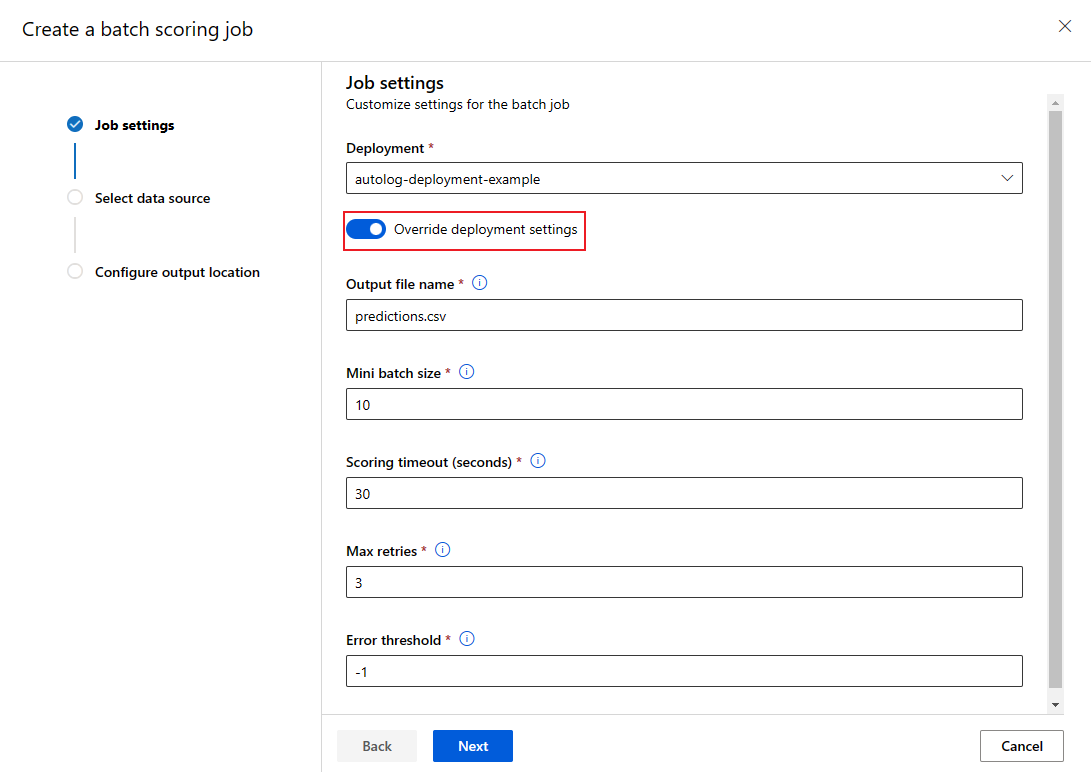
Az üzembehelyezési konfiguráció felülírása minden feladathoz
Kötegvégpont meghívásakor bizonyos beállítások felülírhatók a számítási erőforrások lehető legjobb kihasználása és a teljesítmény javítása érdekében. A következő beállítások konfigurálhatók feladatonként:
- Példányok száma: ezzel a beállítással felülírhatja a számítási fürttől kérendő példányok számát. Nagyobb mennyiségű adatbevitel esetén például érdemes lehet több példányt használni a kötegek végpontok közötti pontozásának felgyorsításához.
- Mini-köteg mérete: ezzel a beállítással felülírhatja az egyes mini kötegekbe belefoglalandó fájlok számát. A mini kötegek számát a bemeneti fájlok teljes száma és a mini köteg mérete határozza meg. A kisebb mini kötegméret további mini kötegeket hoz létre. A mini kötegek párhuzamosan futtathatók, de további ütemezési és meghívási többletterhelések is lehetnek.
- Más beállítások, például a maximális újrapróbálkozések, az időtúllépés és a hibaküszöb felülírhatók. Ezek a beállítások hatással lehetnek a kötegek végpontok közötti pontozási idejére a különböző számítási feladatok esetében.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
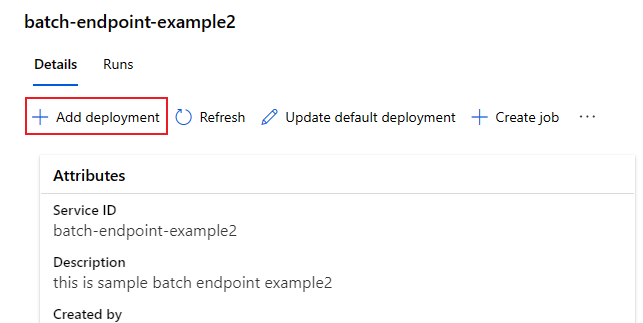
Üzembe helyezések hozzáadása végponthoz
Miután üzembe helyezéssel rendelkező kötegelt végponttal rendelkezik, tovább finomíthatja a modellt, és új üzembe helyezéseket vehet fel. A Batch-végpontok továbbra is kiszolgálják az alapértelmezett üzembe helyezést, miközben új modelleket fejleszt és helyez üzembe ugyanazon a végponton. Az üzemelő példányok nincsenek hatással egymásra.
Ebben a példában hozzáad egy második üzembe helyezést, amely egy Keras és TensorFlow használatával készült modellt használ ugyanazon MNIST-probléma megoldásához.
Második üzembe helyezés hozzáadása
Hozzon létre egy környezetet, ahol a kötegtelepítés futni fog. Vegye fel a környezetbe a kód futtatásához szükséges függőségeket. A kódtárat
azureml-coreis hozzá kell adnia, mivel a kötegtelepítések működéséhez szükség van rá. Az alábbi környezetdefiníció rendelkezik a TensorFlow-modell futtatásához szükséges kódtárakkal.A környezetdefiníció magában az üzembehelyezési definícióban névtelen környezetként szerepel.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlA használt Conda-fájl a következőképpen néz ki:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Hozzon létre egy pontozószkriptet a modellhez:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Üzembehelyezési definíció létrehozása
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvHozza létre az üzembe helyezést:
Futtassa a következő kódot egy batch-üzembe helyezés létrehozásához a batch-végpont alatt, és állítsa be alapértelmezett üzembe helyezésként.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMETipp.
Ebben
--set-defaultaz esetben a paraméter hiányzik. Az éles forgatókönyvekhez ajánlott eljárásként hozzon létre egy új üzembe helyezést anélkül, hogy alapértelmezettként lenne beállítva. Ezután ellenőrizze, és később frissítse az alapértelmezett üzembe helyezést.
Nem alapértelmezett kötegtelepítés tesztelése
Az új nem alapértelmezett üzembe helyezés teszteléséhez ismernie kell a futtatni kívánt üzembe helyezés nevét.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Az értesítés --deployment-name a végrehajtandó üzembe helyezés megadására szolgál. Ez a paraméter lehetővé teszi a invoke nem alapértelmezett üzembe helyezést a kötegvégpont alapértelmezett üzembe helyezésének frissítése nélkül.
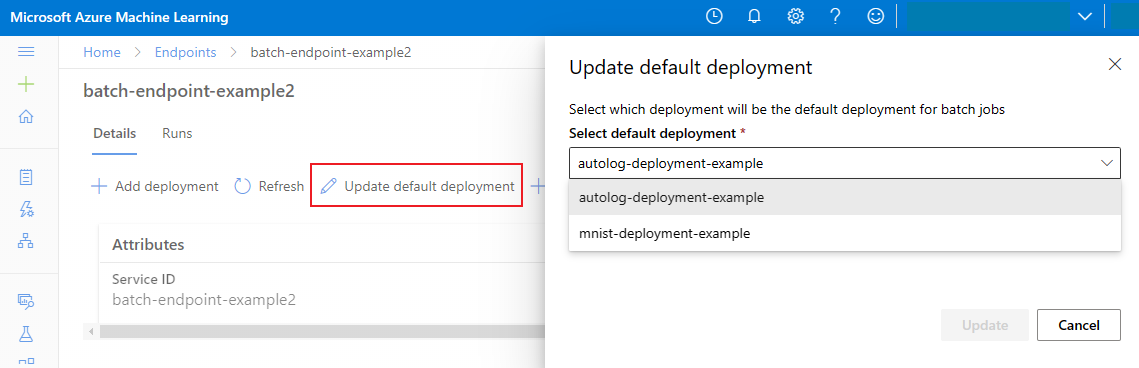
Az alapértelmezett kötegtelepítés frissítése
Bár egy adott üzembe helyezést meghívhat egy végponton belül, általában magát a végpontot kell meghívnia, és engedélyeznie kell a végpontnak, hogy eldöntse, melyik üzemelő példányt használja – az alapértelmezett üzembe helyezést. Az alapértelmezett üzembe helyezést (és következésképpen az üzembe helyezést kiszolgáló modellt) anélkül módosíthatja, hogy módosítaná a végpontot megváltó felhasználóval kötött szerződést. Az alapértelmezett üzembe helyezés frissítéséhez használja a következő kódot:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
A kötegvégpont és az üzembe helyezés törlése
Ha nem a régi kötegtelepítést használja, törölje az alábbi kód futtatásával. --yes a törlés megerősítésére szolgál.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Futtassa a következő kódot a kötegvégpont és annak összes mögöttes üzembe helyezésének törléséhez. A kötegelt pontozási feladatok nem törlődnek.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes