Feladatok és bemeneti adatok létrehozása kötegelt végpontokhoz
A kötegelt végpontok nagy mennyiségű adaton végzett hosszú kötegelt műveletek végrehajtására használhatók. Ezek az adatok különböző helyeken helyezhetők el. Egyes kötegvégpontok bemenetként konstans paramétereket is fogadhatnak. Ebben az oktatóanyagban bemutatjuk, hogyan adhatja meg ezeket a bemeneteket, valamint a különböző támogatott típusokat vagy helyeket.
Végpont meghívása előtt
Batch-végpont sikeres meghívásához és feladatok létrehozásához győződjön meg arról, hogy rendelkezik a következővel:
Rendelkezik a batch végpont üzembe helyezésének futtatásához szükséges engedélyekkel. AzureML-adattudós, közreműködői és tulajdonosi szerepkörök használhatók az üzembe helyezés futtatásához. Az egyéni szerepkör-definíciók esetében olvassa el az Engedélyezés kötegelt végpontokon a szükséges engedélyek megismeréséhez.
A végpont meghívásához érvényes Microsoft Entra ID-jogkivonattal rendelkezik, amely egy biztonsági tagot jelöl. Ez a rendszernév lehet egyszerű felhasználó vagy szolgáltatásnév. Mindenesetre a végpont meghívása után létrejön egy kötegtelepítési feladat a jogkivonathoz társított identitás alatt. Tesztelési célokra használhatja a saját hitelesítő adatait a meghíváshoz az alábbiakban leírtak szerint.
Az Azure CLI használatával interaktív vagy eszközkód-hitelesítéssel jelentkezhet be:
az loginHa többet szeretne megtudni arról, hogyan hitelesíthető több típusú hitelesítő adatokkal, olvassa el az Engedélyezés kötegelt végpontokon című cikket.
A végpontot üzembe helyező számítási fürtnek hozzáférése van a bemeneti adatok olvasásához.
Tipp.
Ha hitelesítő adatok nélküli adattárat vagy külső Azure Storage-fiókot használ adatbemenetként, győződjön meg arról, hogy számítási fürtöket konfigurál az adathozzáféréshez. A számítási fürt felügyelt identitása a tárfiók csatlakoztatásához használatos. A feladat (meghívó) identitása továbbra is a mögöttes adatok olvasására szolgál, így részletes hozzáférés-vezérlés érhető el.
Feladatok létrehozása – alapismeretek
Ha kötegelt végpontból szeretne feladatot létrehozni, meg kell hívnia. A meghívás elvégezhető az Azure CLI, az Azure Machine Tanulás Pythonhoz készült SDK vagy egy REST API-hívás használatával. Az alábbi példák a kötegelt végpontok meghívásának alapjait mutatják be, amelyek egyetlen bemeneti adatmappát kapnak feldolgozásra. Tekintse meg a különböző bemenetekkel és kimenetekkel rendelkező példák bemeneteinek és kimeneteinek megértését.
Használja a műveletet kötegelt invoke végpontok alatt:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Adott üzemelő példány meghívása
A Batch-végpontok több üzembe helyezést is üzemeltethetnek ugyanazon a végponton belül. Az alapértelmezett végpontot akkor használja a rendszer, ha a felhasználó másként nem rendelkezik. Az alábbi módon módosíthatja az üzembe helyezést:
Használja az argumentumot --deployment-name , vagy -d adja meg az üzembe helyezés nevét:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Feladattulajdonságok konfigurálása
A létrehozott feladat néhány tulajdonságát a meghívás időpontjában konfigurálhatja.
Feljegyzés
A feladattulajdonságok konfigurálása jelenleg csak a folyamatösszetevők üzembe helyezésével rendelkező kötegelt végpontokon érhető el.
Kísérlet nevének konfigurálása
Az argumentum --experiment-name használatával adja meg a kísérlet nevét:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Bemenetek és kimenetek ismertetése
A Batch-végpontok tartós API-t biztosítanak, amellyel a felhasználók kötegelt feladatokat hozhatnak létre. Ugyanezzel a felülettel adhatja meg az üzembe helyezés által várt bemeneteket és kimeneteket. Bemenetek használatával továbbíthat minden olyan információt, amelyre a végpontnak szüksége van a feladat elvégzéséhez.
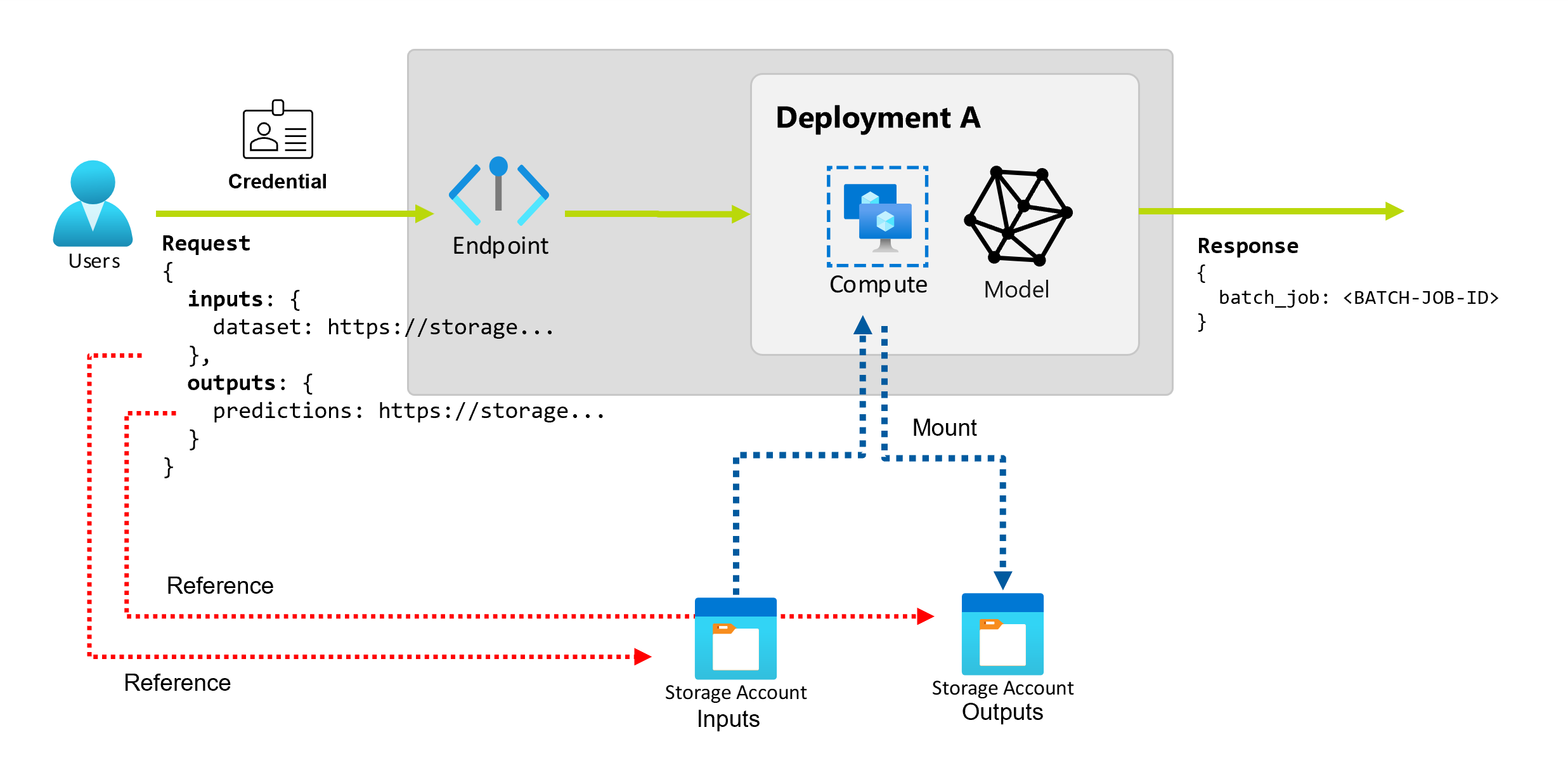
A Batch-végpontok kétféle bemenetet támogatnak:
- Adatbemenetek, amelyek egy adott tárolóhelyre vagy az Azure Machine Tanulás-objektumra mutatnak.
- Konstans bemenetek, amelyek olyan literális értékek (például számok vagy sztringek), amelyeket át szeretne adni a feladatnak.
A bemenetek és kimenetek száma és típusa a kötegelt üzembe helyezés típusától függ. A modelltelepítések mindig egy adatbevitelt igényelnek, és egy adatkimenetet hoznak létre. A literális bemenetek nem támogatottak. A folyamatösszetevők üzembe helyezései azonban általánosabb szerkezetet biztosítanak a végpontok létrehozásához, és lehetővé teszik tetszőleges számú bemenet (adat és literál) és kimenet megadását.
Az alábbi táblázat összefoglalja a kötegelt telepítések bemeneteit és kimeneteit:
| Üzemelő példány típusa | Bemenet száma | Támogatott bemenettípusok | Kimenet száma | Támogatott kimenettípusok |
|---|---|---|---|---|
| Modell üzembe helyezése | 0 | Adatbemenetek | 0 | Adatkimenetek |
| Folyamatösszetevő üzembe helyezése | [0..N] | Adatbemenetek és literális bemenetek | [0..N] | Adatkimenetek |
Tipp.
A bemenetek és kimenetek neve mindig el van nevezve. Ezek a nevek kulcsként szolgálnak az azonosításukhoz és a tényleges érték átadásához a meghívás során. A modelltelepítések esetében, mivel mindig egy bemenetre és kimenetre van szükségük, a rendszer figyelmen kívül hagyja a nevet a meghívás során. Hozzárendelheti a használati esetet legjobban leíró nevet, például a "sales_estimation" nevet.
Adatbemenetek
Az adatbemenetek olyan bemenetekre vonatkoznak, amelyek az adatok elhelyezésének helyére mutatnak. Mivel a kötegvégpontok általában nagy mennyiségű adatot használnak fel, a meghívási kérelem részeként nem adhatja át a bemeneti adatokat. Ehelyett meg kell adnia azt a helyet, ahová a kötegvégpontnak mennie kell az adatok kereséséhez. A bemeneti adatok csatlakoztatása és streamelése a célszámításon a teljesítmény javítása érdekében történik.
A Batch-végpontok a következő tárolási lehetőségekben található fájlok olvasását támogatják:
- Az Azure Machine Tanulás adategységeket, beleértve a mappát (
uri_folder) és a fájlt (uri_file). - Azure Machine Tanulás Adattárak, beleértve az Azure Blob Storage-t, az Azure Data Lake Storage Gen1-et és az Azure Data Lake Storage Gen2-t.
- Azure Storage-fiókok, beleértve az 1. generációs Azure Data Lake Storage-t, az Azure Data Lake Storage Gen2-t és az Azure Blob Storage-t.
- Helyi adatmappák/fájlok (Azure Machine Tanulás CLI vagy Azure Machine Tanulás SDK for Python). Ez a művelet azonban azt eredményezi, hogy a helyi adatok fel lesznek töltve a munkaterület alapértelmezett Azure Machine Tanulás Adattárba.
Fontos
Elavulással kapcsolatos értesítés: A típusú FileDataset (V1) adathalmazok elavultak, és a jövőben megszűnnek. A funkcióra támaszkodó meglévő kötegvégpontok továbbra is működni fognak, de a GA CLIv2 (2.4.0 és újabb) vagy a GA REST API (2022-05-01 és újabb) használatával létrehozott kötegvégpontok nem támogatják a V1-es adatkészletet.
Konstans bemenetek
A literális bemenetek olyan bemenetekre vonatkoznak, amelyek a meghíváskor megjeleníthetők és feloldhatók, például sztringek, számok és logikai értékek. Általában konstans bemenetekkel adja át a paramétereket a végpontnak egy folyamatösszetevő üzembe helyezésének részeként. A Batch-végpontok a következő literális típusokat támogatják:
stringbooleanfloatinteger
A konstans bemenetek csak a folyamatösszetevők üzemelő példányaiban támogatottak. A feladatok konstans bemenetekkel való létrehozása című cikkből megtudhatja , hogyan adhatja meg őket.
Adatkimenetek
Az adatkimenetek arra a helyre vonatkoznak, ahol egy kötegelt feladat eredményeit el kell helyezni. A kimenetek név alapján vannak azonosítva, és az Azure Machine Tanulás automatikusan egyedi elérési utat rendel az egyes elnevezett kimenetekhez. Szükség esetén azonban megadhat egy másik elérési utat is.
Fontos
A Batch-végpontok csak az Azure Blob Storage-adattárakban támogatják a kimenetek írását. Ha olyan tárfiókba kell írnia, amelyen engedélyezve vannak a hierarchikus névterek (más néven Azure Datalake Gen2 vagy ADLS Gen2), figyelje meg, hogy az ilyen tárolási szolgáltatás regisztrálható Azure Blob Storage-adattárként, mivel a szolgáltatások teljes mértékben kompatibilisek. Ily módon kimeneteket írhat kötegelt végpontokról az ADLS Gen2-be.
Feladatok létrehozása adatbemenetekkel
Az alábbi példák bemutatják, hogyan hozhat létre feladatokat, hogyan végezhet adatbevitelt adategységekből, adattárakból és Azure Storage-fiókokból.
Adategység bemeneti adatai
Az Azure Machine Tanulás adategységek (korábbi nevén adathalmazok) a feladatok bemeneteként támogatottak. Kövesse az alábbi lépéseket egy kötegelt végpontfeladat futtatásához egy regisztrált adategységben tárolt adatokkal az Azure Machine Tanulás:
Figyelmeztetés
A Table (MLTable) típusú adategységek jelenleg nem támogatottak.
Először hozza létre az adategységet. Ez az adategység egy több CSV-fájlt tartalmazó mappából áll, amelyet párhuzamosan fog feldolgozni kötegelt végpontok használatával. Ezt a lépést kihagyhatja, ha az adatok már regisztrálva van adategységként.
Adategység-definíció létrehozása a következő helyen
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/dataEzután hozza létre az adategységet:
az ml data create -f heart-dataset-unlabeled.ymlHozza létre a bemenetet vagy a kérést:
DATASET_ID=$(az ml data show -n heart-dataset-unlabeled --label latest | jq -r .id)Feljegyzés
Az adategység-azonosító a következőképpen
/subscriptions/<subscription>/resourcegroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/data/<data-asset>/versions/<version>nézne ki. A bemenet megadására is használhatóazureml:/<datasset_name>@latest.Futtassa a végpontot:
--setAz argumentum használatával adja meg a bemenetet:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDA modelltelepítést kiszolgáló végpontok esetében az
--inputargumentum használatával megadhatja az adatbevitelt, mivel a modelltelepítéshez mindig csak egy adatbevitel szükséges.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_IDAz argumentum
--setáltalában hosszú parancsokat hoz létre, ha több bemenet van megadva. Ilyen esetekben helyezze a bemeneteket egyYAMLfájlba, és adja--filemeg a végponthíváshoz szükséges bemeneteket.inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latestaz ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Adatbevitel adattárakból
Az Azure Machine-Tanulás regisztrált adattárakból származó adatokra közvetlenül hivatkozhatnak kötegelt üzembe helyezési feladatok. Ebben a példában először feltölt néhány adatot az Alapértelmezett adattárba az Azure Machine Tanulás munkaterületen, majd futtat egy kötegelt üzembe helyezést rajta. Kövesse az alábbi lépéseket egy kötegelt végpontfeladat adattárban tárolt adatokkal történő futtatásához.
Az Alapértelmezett adattár elérése az Azure Machine Tanulás-munkaterületen. Ha az adatai egy másik tárolóban találhatóak, használhatja ezt az adattárat. Nem szükséges az alapértelmezett adattárat használnia.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Feljegyzés
Az adattárak azonosítója a következőképpen
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>nézne ki.Tipp.
A munkaterület alapértelmezett blobadattárolója a workspaceblobstore. Ezt a lépést kihagyhatja, ha már ismeri a munkaterület alapértelmezett adattárának erőforrás-azonosítóját.
Néhány mintaadatot fel kell töltenie az adattárba. Ez a példa feltételezi, hogy már feltöltötte az adattárban található mintaadatokat a Blob Storage-fiók mappájában
sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/dataheart-disease-uci-unlabeled. Mielőtt továbblépne, győződjön meg arról, hogy ezt megtette.Hozza létre a bemenetet vagy a kérést:
Helyezze a fájl elérési útját a következő változóba:
DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Feljegyzés
Tekintse meg, hogyan van hozzáfűzve az elérési út
pathsaz adattár erőforrás-azonosítóhoz, és jelezheti, hogy az alábbiakban egy elérési út található.Tipp.
A bemenet megadására is használható
azureml://datastores/<data-store>/paths/<data-path>.Futtassa a végpontot:
--setAz argumentum használatával adja meg a bemenetet:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHA modelltelepítést kiszolgáló végpontok esetében az
--inputargumentum használatával megadhatja az adatbevitelt, mivel a modelltelepítéshez mindig csak egy adatbevitel szükséges.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderAz argumentum
--setáltalában hosszú parancsokat hoz létre, ha több bemenet van megadva. Ilyen esetekben helyezze a bemeneteket egyYAMLfájlba, és adja--filemeg a végponthíváshoz szükséges bemeneteket.inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlHa az adatok fájlként szolgálnak, használja
uri_fileinkább típusként.
Bemeneti adatok az Azure Storage-fiókokból
Az Azure Machine Tanulás kötegelt végpontok nyilvános és privát Azure Storage-fiókok felhőbeli helyéről is beolvashatják az adatokat. A következő lépésekkel futtathat kötegelt végpontfeladatot egy tárfiókban tárolt adatokkal:
Feljegyzés
Tekintse meg a számítási fürtök adathozzáférésre való konfigurálását ismertető szakaszt, amely további információt nyújt a tárfiókok adatainak sikeres beolvasásához szükséges további konfigurációkról.
Hozza létre a bemenetet vagy a kérést:
Futtassa a végpontot:
--setAz argumentum használatával adja meg a bemenetet:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAA modelltelepítést kiszolgáló végpontok esetében az
--inputargumentum használatával megadhatja az adatbevitelt, mivel a modelltelepítéshez mindig csak egy adatbevitel szükséges.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderAz argumentum
--setáltalában hosszú parancsokat hoz létre, ha több bemenet van megadva. Ilyen esetekben helyezze a bemeneteket egyYAMLfájlba, és adja--filemeg a végponthíváshoz szükséges bemeneteket.inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataaz ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlHa az adatok fájlként szolgálnak, használja
uri_fileinkább típusként.
Feladatok létrehozása konstans bemenetekkel
A folyamatösszetevők üzembe helyezése konstans bemeneteket vehet igénybe. Az alábbi példa bemutatja, hogyan adhat meg egy , típus típusú score_modestringbemenetet a következő appendértékkel:
Helyezze a bemeneteket egy YAML fájlba, és adja --file meg a végponthíváshoz szükséges bemeneteket.
inputs.yml
inputs:
score_mode:
type: string
default: append
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Az argumentumot --set az érték megadásához is használhatja. Azonban általában hosszú parancsokat hoz létre, ha több bemenet van megadva:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Feladatok létrehozása adatkimenetekkel
Az alábbi példa bemutatja, hogyan módosíthatja az elnevezett score kimenet helyét. A teljesség érdekében ezek a példák egy nevű bemenetet heart_datasetis konfigurálnak.
A kimenetek mentéséhez használja az Azure Machine Tanulás-munkaterület alapértelmezett adattárát. A munkaterület bármely más adattárát használhatja, feltéve, hogy az egy blobtároló-fiók.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Feljegyzés
Az adattárak azonosítója a következőképpen
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>nézne ki.Adatkimenet létrehozása:
DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"A teljesség érdekében hozzon létre egy adatbevitelt is:
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Feljegyzés
Tekintse meg, hogyan van hozzáfűzve az elérési út
pathsaz adattár erőforrás-azonosítóhoz, és jelezheti, hogy az alábbiakban egy elérési út található.Futtassa az üzembe helyezést: