Azure Databricks ML-kísérletek nyomon követése az MLflow és az Azure Machine Learning használatával
Az MLflow egy nyílt forráskódú kódtár a gépi tanulási kísérletek életciklusának kezelésére. Az MLflow használatával integrálhatja az Azure Databrickset az Azure Machine Learning szolgáltatással, hogy a lehető legjobbat kapja mindkét terméktől.
Ebben a cikkben a következőkkel ismerkedhet meg:
- Az MLflow az Azure Databricks és az Azure Machine Learning használatához szükséges kódtárak.
- Az Azure Databricks-futtatások nyomon követése az MLflow használatával az Azure Machine Learningben.
- Modellek naplózása MLflow használatával az Azure Machine Learningben való regisztrációhoz.
- Az Azure Machine Learningben regisztrált modellek üzembe helyezése és felhasználása.
Előfeltételek
- Telepítse a
azureml-mlflowcsomagot, amely kezeli az Azure Machine Learningtel való kapcsolatot, beleértve a hitelesítést is. - Egy Azure Databricks-munkaterület és -fürt.
- Azure Machine Learning-munkaterület létrehozása.
- Megtudhatja, hogy milyen hozzáférési engedélyekre van szüksége az MLflow-műveletek munkaterületen való végrehajtásához.
Példajegyzetfüzetek
Az Azure Databricks betanítási modelljei és az Azure Machine Learningben való üzembe helyezése bemutatja, hogyan taníthat be modelleket az Azure Databricksben, és hogyan helyezheti üzembe őket az Azure Machine Learningben. Azt is tartalmazza, hogyan kezelheti azokat az eseteket, amikor a kísérleteket és modelleket az Azure Databricks MLflow-példányával is nyomon szeretné követni, és hogyan használhatja az Azure Machine Learninget az üzembe helyezéshez.
Kódtárak telepítése
Ha könyvtárakat szeretne telepíteni a fürtre, lépjen a Tárak lapra, és válassza az Új telepítése lehetőséget
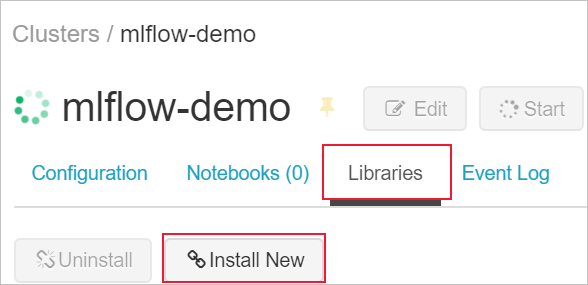
A Csomag mezőbe írja be az azureml-mlflow parancsot, majd válassza a telepítést. Ismételje meg ezt a lépést, ha további csomagokat szeretne telepíteni a fürtre a kísérlethez.
Azure Databricks-futtatások nyomon követése az MLflow használatával
Az Azure Databricks kétféleképpen konfigurálható a kísérletek MLflow használatával történő nyomon követésére:
- Nyomon követés az Azure Databricks-munkaterületen és az Azure Machine Learning-munkaterületen is (kettős nyomon követés)
- Kizárólag az Azure Machine Learning nyomon követése
Az Azure Databricks-munkaterület összekapcsolásakor alapértelmezés szerint a kettős nyomon követés lesz konfigurálva.
Kettős nyomon követés az Azure Databricksben és az Azure Machine Learningben
Az ADB-munkaterület és az Azure Machine Learning-munkaterület összekapcsolása lehetővé teszi a kísérletadatok nyomon követését az Azure Machine Learning-munkaterületen és az Azure Databricks-munkaterületen egyszerre. Ezt kettős nyomkövetésnek nevezzük.
Figyelmeztetés
Az Azure Machine Learning-munkaterületen egy privát kapcsolaton belüli kettős nyomon követés jelenleg nem támogatott. Ehelyett konfiguráljon exkluzív nyomon követést az Azure Machine Learning-munkaterülettel .
Figyelmeztetés
A 21Vianet által üzemeltetett Microsoft Azure-ban jelenleg nem támogatott kettős nyomkövetés. Ehelyett konfiguráljon exkluzív nyomon követést az Azure Machine Learning-munkaterülettel .
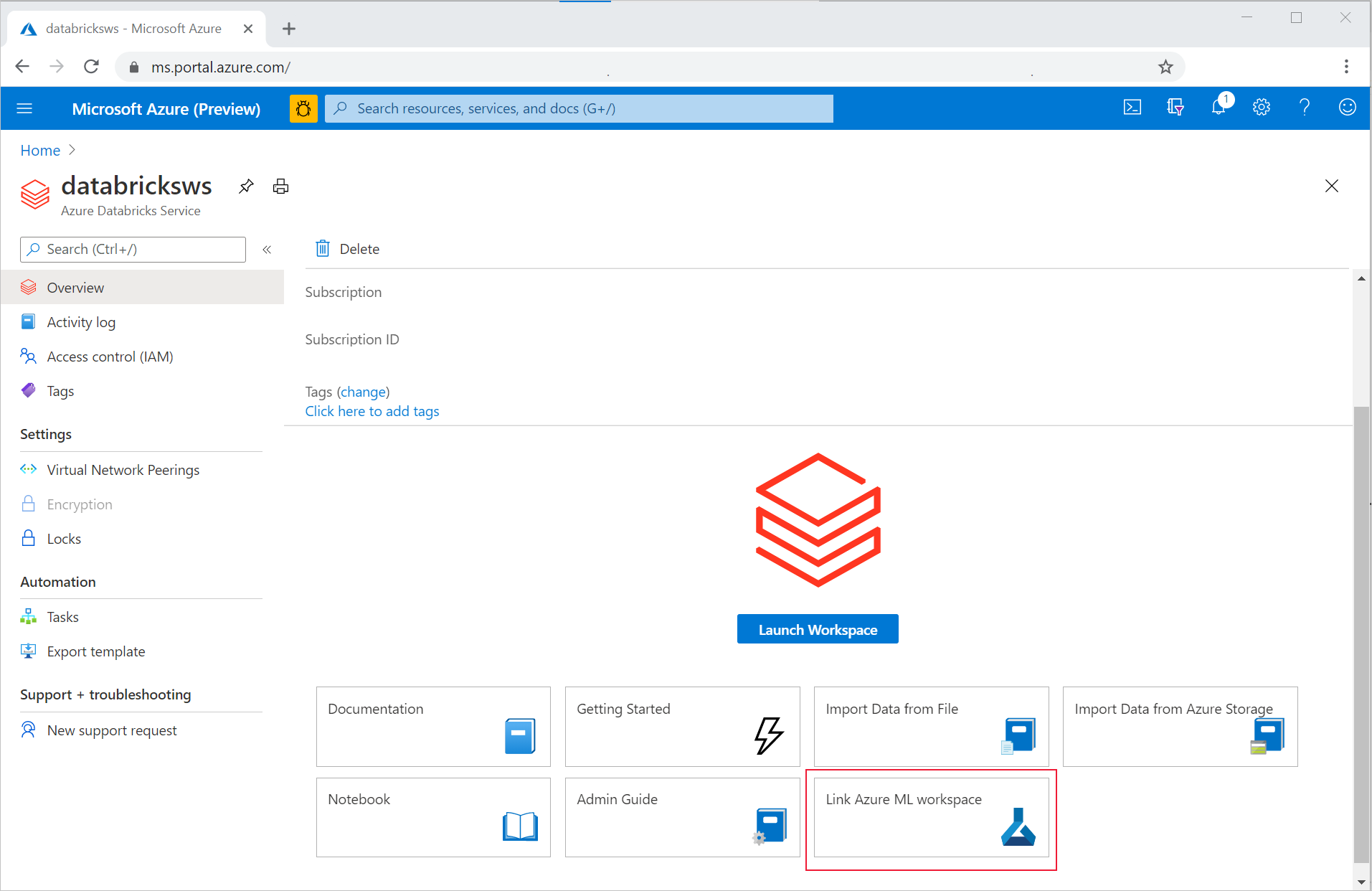
Ha az ADB-munkaterületet egy új vagy meglévő Azure Machine Learning-munkaterülethez szeretné kapcsolni,
- Jelentkezzen be az Azure portálra.
- Lépjen az ADB-munkaterület Áttekintés lapjára.
- Kattintson az Azure Machine Learning-munkaterület csatolása gombra a jobb alsó sarokban.
Miután összekapcsolta az Azure Databricks-munkaterületet az Azure Machine Learning-munkaterülettel, az MLflow Tracking automatikusan a következő helyeken lesz nyomon követve:
- A csatolt Azure Machine Learning-munkaterület.
- Az eredeti ADB-munkaterület.
Az MLflow az Azure Databricksben ugyanúgy használható, mint korábban. Az alábbi példa beállítja a kísérlet nevét, ahogy az általában az Azure Databricksben történik, és elkezd naplózást végezni néhány paraméteren:
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Feljegyzés
A nyomkövetéssel ellentétben a modellregisztrációs adatbázisok nem támogatják a modellek egyidejű regisztrálását mind az Azure Machine Learningben, mind az Azure Databricksben. Vagy az egyiket, vagy a másikat kell használni. További részletekért olvassa el a modellek regisztrálása a beállításjegyzékben az MLflow-ban című szakaszt.
Nyomon követés kizárólag az Azure Machine Learning-munkaterületen
Ha inkább központosított helyen szeretné kezelni a követett kísérleteket, beállíthatja, hogy az MLflow nyomon követése csak az Azure Machine Learning-munkaterületen legyen nyomon követve. Ennek a konfigurációnak az az előnye, hogy egyszerűbb üzembe helyezési útvonalat tesz lehetővé az Azure Machine Learning üzembe helyezési beállításaival.
Figyelmeztetés
A privát kapcsolattal kompatibilis Azure Machine Learning-munkaterülethez az Azure Databrickset a saját hálózatában (VNet-injektálás) kell üzembe helyeznie a megfelelő kapcsolat biztosításához.
Az MLflow-követési URI-t úgy kell konfigurálnia, hogy kizárólag az Azure Machine Learningre mutasson, ahogy az az alábbi példában is látható:
Nyomkövetési URI konfigurálása
Kérje le a munkaterület nyomkövetési URI-ját:
A KÖVETKEZŐRE VONATKOZIK:
 Azure CLI ml-bővítmény v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Jelentkezzen be és konfigurálja a munkaterületet:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>A nyomkövetési URI-t a következő paranccsal szerezheti
az ml workspacebe:az ml workspace show --query mlflow_tracking_uri
A nyomkövetési URI konfigurálása:
Ezután a metódus
set_tracking_uri()az MLflow-követési URI-t az adott URI-ra pontokat jelölő URI-ra mutatja.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Tipp.
Megosztott környezeteken, például Azure Databricks-fürtön, Azure Synapse Analytics-fürtön vagy hasonlókon végzett munka esetén hasznos, ha a környezeti változót
MLFLOW_TRACKING_URIa fürt szintjén úgy állítja be, hogy automatikusan konfigurálja az MLflow-követési URI-t úgy, hogy a fürtben futó összes munkamenethez az Azure Machine Learningre mutasson, nem pedig munkamenetenkénti alapon.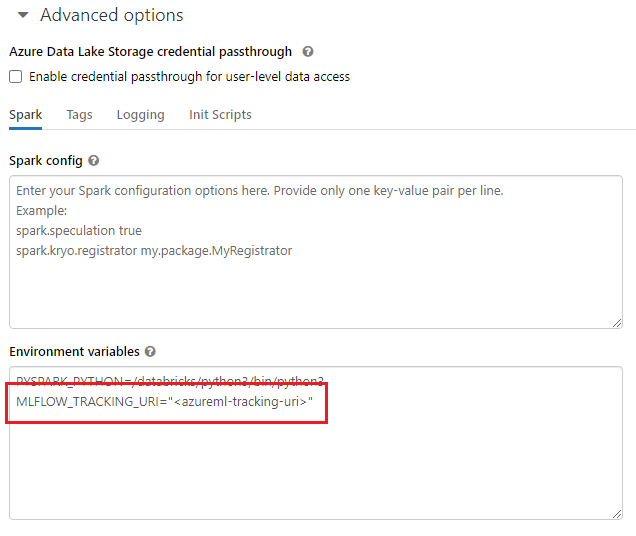
A környezeti változó konfigurálása után az ilyen fürtön futó kísérletek nyomon lesznek követve az Azure Machine Learningben.
Hitelesítés konfigurálása
A nyomkövetés konfigurálása után azt is konfigurálnia kell, hogy a hitelesítés hogyan történjen a társított munkaterületen. Alapértelmezés szerint az MLflow-hoz készült Azure Machine Learning beépülő modul interaktív hitelesítést végez az alapértelmezett böngésző megnyitásával, hogy hitelesítő adatokat kérjen. Tekintse meg az MLflow konfigurálását az Azure Machine Learninghez: A hitelesítés konfigurálása az MLflow hitelesítésének további módjaihoz az Azure Machine Learning-munkaterületeken.
Az olyan interaktív feladatok esetében, ahol egy felhasználó csatlakozik a munkamenethez, interaktív hitelesítésre támaszkodhat, ezért nincs szükség további műveletekre.
Figyelmeztetés
Az interaktív böngészőhitelesítés letiltja a kódvégrehajtást, amikor hitelesítő adatokat kér. Ez nem alkalmas hitelesítésre felügyelet nélküli környezetekben, például betanítási feladatokban. Javasoljuk, hogy más hitelesítési módot is konfiguráljon.
Azokban az esetekben, amikor felügyelet nélküli végrehajtásra van szükség, konfigurálnia kell egy szolgáltatásnevet az Azure Machine Learningtel való kommunikációhoz.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Tipp.
A megosztott környezeteken való munka során célszerű ezeket a környezeti változókat a számításnál konfigurálni. Ajánlott eljárásként titkos kulcsként kezelni őket az Azure Key Vault egy példányában, amikor csak lehetséges. Az Azure Databricksben például a fürtkonfigurációban az alábbiak szerint használhat titkos kulcsokat a környezeti változókban: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Az Azure Databricksben való műveletet egy környezeti változóban található titkos kódra hivatkozva, vagy a platform hasonló dokumentációjában találja.
A kísérlet nevei az Azure Machine Learningben
Ha az MLflow úgy van konfigurálva, hogy kizárólag az Azure Machine Learning-munkaterületen kövesse a kísérleteket, a kísérlet elnevezési konvenciójának az Azure Machine Learning által használtat kell követnie. Az Azure Databricksben a kísérletek neve annak az elérési útnak a neve, ahol a kísérlet mentésre /Users/alice@contoso.com/iris-classifierkerül. Az Azure Machine Learningben azonban közvetlenül meg kell adnia a kísérlet nevét. Az előző példához hasonlóan ugyanez a kísérlet neve is közvetlenül a következő iris-classifier :
mlflow.set_experiment(experiment_name="experiment-name")
Paraméterek, metrikák és összetevők nyomon követése
Az MLflow az Azure Databricksben ugyanúgy használható, mint korábban. További részletekért lásd: Log & view metrics and log files.
Naplózási modellek az MLflow használatával
A modell betanítása után a módszerrel naplózhatja a nyomkövetési kiszolgálóra mlflow.<model_flavor>.log_model() . <model_flavor>, a modellhez társított keretrendszerre hivatkozik. Ismerje meg, hogy milyen modellízek támogatottak. Az alábbi példában az MLLib Spark-kódtárral létrehozott modell regisztrálva van:
mlflow.spark.log_model(model, artifact_path = "model")
Érdemes megemlíteni, hogy az íz spark nem felel meg annak a ténynek, hogy egy modellt betanítunk egy Spark-fürtben, hanem a használt betanítási keretrendszer miatt (tökéletesen betaníthat egy modellt a TensorFlow és a Spark használatával, és így a használni tensorflowkívánt íz).
A modellek a nyomon követett futtatáson belül vannak naplózva. Ez azt jelenti, hogy a modellek az Azure Databricksben és az Azure Machine Learningben (alapértelmezett) vagy kizárólag az Azure Machine Learningben érhetők el, ha a nyomkövetési URI-t úgy konfigurálta, hogy rá mutasson.
Fontos
Figyelje meg, hogy itt a paraméter registered_model_name nincs megadva. Az ilyen paraméter következményeivel és a beállításjegyzék működésével kapcsolatos további részletekért olvassa el a modellek regisztrálása a beállításjegyzékben az MLflow használatával című szakaszt.
Modellek regisztrálása a beállításjegyzékben az MLflow használatával
A nyomkövetéssel ellentétben a modellregisztrációs adatbázisok nem működhetnek egyszerre az Azure Databricksben és az Azure Machine Learningben. Vagy az egyiket, vagy a másikat kell használni. Alapértelmezés szerint az Azure Databricks-munkaterületet használják a modellregisztrációs adatbázisokhoz; hacsak nem úgy döntött, hogy az MLflow Trackingt csak az Azure Machine Learning-munkaterületen követi nyomon, akkor a modellregisztrációs adatbázis az Azure Machine Learning-munkaterület.
Ezt követően, figyelembe véve az alapértelmezett konfigurációt, az alábbi sor naplózza a modellt az Azure Databricks és az Azure Machine Learning megfelelő futtatásán belül, de csak az Azure Databricksben fogja regisztrálni:
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
Ha a névvel rendelkező regisztrált modell nem létezik, a metódus regisztrál egy új modellt, létrehozza az 1. verziót, és visszaad egy ModelVersion MLflow objektumot.
Ha már létezik regisztrált modell a névvel, a metódus létrehoz egy új modellverziót, és visszaadja a verzióobjektumot.
Az Azure Machine Learning Registry használata az MLflow használatával
Ha az Azure Machine Learning Model Registryt szeretné használni az Azure Databricks helyett, javasoljuk, hogy az MLflow Trackingt csak az Azure Machine Learning-munkaterületen kövesse nyomon. Ezzel megszűnik a modellek regisztrációjának kétértelműsége, és egyszerűbbé válik az összetettség.
Ha azonban továbbra is a kettős követési képességeket szeretné használni, de modelleket szeretne regisztrálni az Azure Machine Learningben, utasíthatja az MLflow-t az Azure Machine Learning használatára a modellregisztrációs adatbázisokhoz az MLflow modellregisztrációs adatbázisának URI-jának konfigurálásával. Ez az URI pontosan ugyanazzal a formátummal és értékkel rendelkezik, mint az MLflow tracking URI.
mlflow.set_registry_uri(azureml_mlflow_uri)
Feljegyzés
A kapott érték azureml_mlflow_uri ugyanúgy lett lefokozva, mint a Set MLflow Trackingben , hogy csak az Azure Machine Learning-munkaterületen kövesse nyomon.
A forgatókönyvre vonatkozó teljes példáért tekintse meg az Azure Databricksben található betanítási modelleket , és helyezze üzembe őket az Azure Machine Learningben.
Az Azure Machine Learningben regisztrált modellek üzembe helyezése és felhasználása
Az Azure Machine Learning Service-ben MLflow használatával regisztrált modellek a következőképpen használhatók:
Azure Machine Learning-végpont (valós idejű és köteg): Ez az üzembe helyezés lehetővé teszi az Azure Machine Learning üzembe helyezési képességeit az Azure Container Instances (ACI), az Azure Kubernetes (AKS) vagy a felügyelt következtetési végpontok valós idejű és kötegelt következtetéséhez.
MLFlow-modellobjektumok vagy Pandas UDF-ek, amelyek streamelési vagy kötegelt folyamatokban használhatók az Azure Databricks-jegyzetfüzetekben.
Modellek üzembe helyezése Azure Machine Learning-végpontokon
A azureml-mlflow beépülő modul használatával üzembe helyezhet egy modellt az Azure Machine Learning-munkaterületen. Az MLflow-modellek üzembe helyezésének lapján részletes információkat talál arról, hogyan helyezhet üzembe modelleket a különböző célokra.
Fontos
A modelleket regisztrálni kell az Azure Machine Learning regisztrációs adatbázisában az üzembe helyezésükhöz. Ha a modellek az Azure Databricks MLflow-példányában vannak regisztrálva, akkor újra regisztrálnia kell őket az Azure Machine Learningben. Ebben az esetben tekintse meg az Azure Databricks betanítási modelljeit, és helyezze üzembe őket az Azure Machine Learningben
Modellek üzembe helyezése az ADB-ben kötegelt pontozáshoz UDF-ek használatával
A kötegelt pontozáshoz Azure Databricks-fürtöket választhat. A Mlflow használatával bármely modellt feloldhat a csatlakoztatott beállításjegyzékből. Általában az alábbi két módszer egyikét fogja használni:
- Ha a modellt Spark-kódtárakkal (például
MLLib) képezték be és készítették el, akkormlflow.pyfunc.spark_udfa modell betöltésére és Spark Pandas UDF-ként való használatára szolgál az új adatok pontozásához. - Ha a modell nem Spark-kódtárakkal lett betanítve vagy felépítve, használja
mlflow.pyfunc.load_modelvagymlflow.<flavor>.load_modeltöltse be a modellt a fürtillesztőbe. Figyelje meg, hogy ily módon a fürtön végbe kívánt párhuzamosításokat vagy munkaterjesztéseket Önnek kell vezénylnie. Figyelje meg azt is, hogy az MLflow nem telepíti a modell futtatásához szükséges kódtárat. Ezeket a kódtárakat a fürtben kell telepíteni a futtatás előtt.
Az alábbi példa bemutatja, hogyan tölthet be egy modellt a névvel ellátott uci-heart-classifier beállításjegyzékből, és hogyan használhatja azt Spark Pandas UDF-ként új adatok pontozásához.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Tipp.
Tekintse meg a modellek beállításjegyzékből való betöltésének további módjait a beállításjegyzékből származó modellekre való hivatkozáshoz.
Miután betöltötte a modellt, új adatokkal végezheti el a pontszámot:
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Az erőforrások eltávolítása
Ha meg szeretné tartani az Azure Databricks-munkaterületet, de már nincs szüksége az Azure Machine Learning-munkaterületre, törölheti az Azure Machine Learning-munkaterületet. Ez a művelet az Azure Databricks-munkaterület és az Azure Machine Learning-munkaterület leválasztását eredményezi.
Ha nem tervezi használni a naplózott metrikákat és összetevőket a munkaterületen, az egyesével történő törlés lehetősége jelenleg nem érhető el. Ehelyett törölje a tárfiókot és a munkaterületet tartalmazó erőforráscsoportot, így nem kell fizetnie:
Az Azure Portalon válassza az Erőforráscsoportok lehetőséget a bal szélen.
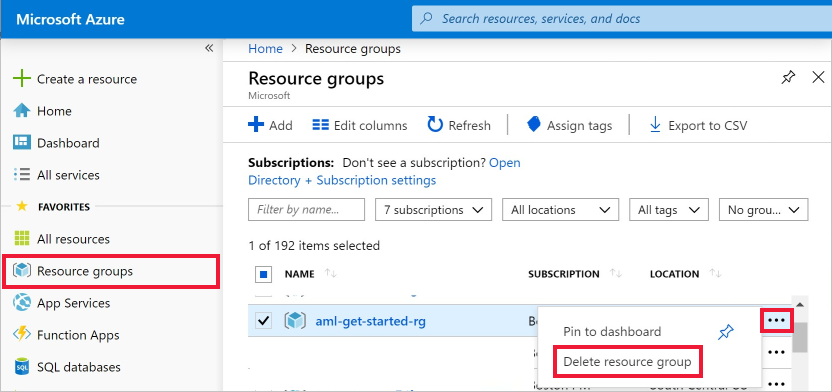
Válassza ki a listában az Ön által létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Következő lépések
- MLflow-modellek üzembe helyezése Azure-webszolgáltatásként.
- A modellek kezelése.
- Kísérletfeladatok nyomon követése az MLflow és az Azure Machine Learning használatával.
- További információ az Azure Databricksről és az MLflow-ról.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: