Azure Synapse Analytics ML-kísérletek nyomon követése az MLflow és az Azure Machine Learning használatával
Ebből a cikkből megtudhatja, hogyan engedélyezheti az MLflow számára az Azure Machine Learninghez való csatlakozást egy Azure Synapse Analytics-munkaterületen végzett munka során. Ezt a konfigurációt követési, modellfelügyeleti és modelltelepítési célokra használhatja.
Az MLflow egy nyílt forráskódú kódtár a gépi tanulási kísérletek életciklusának kezelésére. Az MLFlow Tracking az MLflow egyik összetevője, amely naplózza és nyomon követi a betanítási futtatási metrikákat és a modellösszetevőket. További információ az MLflow-ról.
Ha MLflow-projekttel rendelkezik az Azure Machine Learningtel való betanítása érdekében, tekintse meg az ML-modellek betanítása MLflow-projektek és az Azure Machine Learning (előzetes verzió) című témakört.
Előfeltételek
Kódtárak telepítése
Kódtárak telepítése dedikált fürtre az Azure Synapse Analyticsben:
Hozzon létre egy
requirements.txtfájlt a kísérletekhez szükséges csomagokkal, de győződjön meg arról, hogy a következő csomagokat is tartalmazza:requirements.txt
mlflow azureml-mlflow azure-ai-mlLépjen az Azure Analytics-munkaterület portálra.
Lépjen a Kezelés lapra, és válassza az Apache Spark-készletek lehetőséget.
Kattintson a fürt neve melletti három pontra, és válassza a Csomagok lehetőséget.
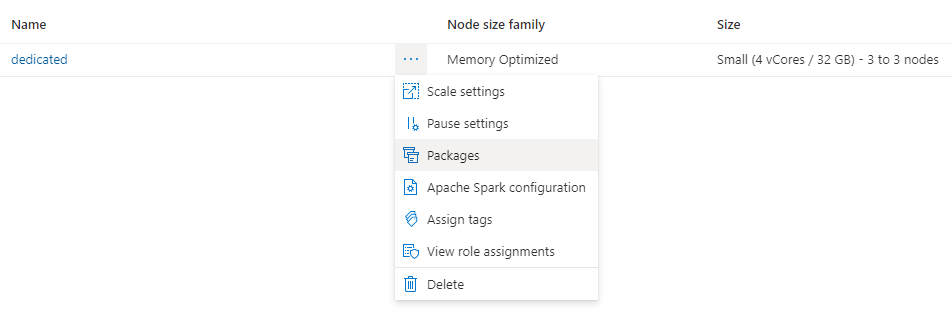
A Követelmények fájlok szakaszban kattintson a Feltöltés gombra.
Töltse fel a
requirements.txtfájlt.Várja meg, amíg a fürt újraindul.
Kísérletek nyomon követése az MLflow használatával
Az Azure Synapse Analytics konfigurálható kísérletek nyomon követésére az MLflow használatával az Azure Machine Learning-munkaterületen. Az Azure Machine Learning egy központosított adattárat biztosít a kísérletek, modellek és üzemelő példányok teljes életciklusának kezeléséhez. Emellett azzal az előnnyel is rendelkezik, hogy egyszerűbb üzembe helyezést tesz lehetővé az Azure Machine Learning üzembe helyezési beállításaival.
Jegyzetfüzetek konfigurálása az Azure Machine Learninghez csatlakoztatott MLflow használatára
Ha az Azure Machine Learninget szeretné központi adattárként használni kísérletekhez, használhatja az MLflow-t. Minden jegyzetfüzeten, amelyen dolgozik, konfigurálnia kell a nyomkövetési URI-t, hogy a használni kívánt munkaterületre mutasson. Az alábbi példa bemutatja, hogyan végezhető el:
Nyomkövetési URI konfigurálása
Kérje le a munkaterület nyomkövetési URI-ját:
A KÖVETKEZŐRE VONATKOZIK:
 Azure CLI ml-bővítmény v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Jelentkezzen be és konfigurálja a munkaterületet:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>A nyomkövetési URI-t a következő paranccsal szerezheti
az ml workspacebe:az ml workspace show --query mlflow_tracking_uri
A nyomkövetési URI konfigurálása:
Ezután a metódus
set_tracking_uri()az MLflow-követési URI-t az adott URI-ra pontokat jelölő URI-ra mutatja.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Tipp.
Megosztott környezeteken, például Azure Databricks-fürtön, Azure Synapse Analytics-fürtön vagy hasonlókon végzett munka esetén hasznos, ha a környezeti változót
MLFLOW_TRACKING_URIa fürt szintjén úgy állítja be, hogy automatikusan konfigurálja az MLflow-követési URI-t úgy, hogy a fürtben futó összes munkamenethez az Azure Machine Learningre mutasson, nem pedig munkamenetenkénti alapon.
Hitelesítés konfigurálása
A nyomkövetés konfigurálása után azt is konfigurálnia kell, hogy a hitelesítés hogyan történjen a társított munkaterületen. Alapértelmezés szerint az MLflow-hoz készült Azure Machine Learning beépülő modul interaktív hitelesítést végez az alapértelmezett böngésző megnyitásával, hogy hitelesítő adatokat kérjen. Tekintse meg az MLflow konfigurálását az Azure Machine Learninghez: A hitelesítés konfigurálása az MLflow hitelesítésének további módjaihoz az Azure Machine Learning-munkaterületeken.
Az olyan interaktív feladatok esetében, ahol egy felhasználó csatlakozik a munkamenethez, interaktív hitelesítésre támaszkodhat, ezért nincs szükség további műveletekre.
Figyelmeztetés
Az interaktív böngészőhitelesítés letiltja a kód végrehajtását, amikor hitelesítő adatokat kér. Ez a megközelítés nem alkalmas felügyelet nélküli környezetekben, például betanítási feladatokban való hitelesítésre. Javasoljuk, hogy konfiguráljon egy másik hitelesítési módot.
Azokban a forgatókönyvekben, ahol felügyelet nélküli végrehajtásra van szükség, konfigurálnia kell egy szolgáltatásnevet az Azure Machine Learningtel való kommunikációhoz.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Tipp.
Megosztott környezetek használatakor javasoljuk, hogy ezeket a környezeti változókat a számításnál konfigurálja. Ajánlott eljárásként titkos kulcsként kezelheti őket az Azure Key Vault egy példányában.
Az Azure Databricksben például a fürtkonfigurációban az alábbiak szerint használhat titkos kulcsokat a környezeti változókban: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. A megközelítés Azure Databricksben való implementálásával kapcsolatos további információkért lásd : Titkos kód egy környezeti változóban , vagy tekintse meg a platform dokumentációját.
A kísérlet nevei az Azure Machine Learningben
Az Azure Machine Learning alapértelmezés szerint egy úgynevezett alapértelmezett kísérletben Defaultfut. Általában érdemes beállítani azt a kísérletet, amelyen dolgozni fog. A kísérlet nevének beállításához használja az alábbi szintaxist:
mlflow.set_experiment(experiment_name="experiment-name")
Paraméterek, metrikák és összetevők nyomon követése
Az MLflow az Azure Synapse Analyticsben ugyanúgy használható, mint korábban. További részletekért lásd: Log & view metrics and log files.
Modellek regisztrálása a beállításjegyzékben az MLflow használatával
A modellek regisztrálhatók az Azure Machine Learning-munkaterületen, amely egy központosított adattárat kínál az életciklusuk kezeléséhez. Az alábbi példa naplózza a Spark MLLib-vel betanított modellt, és regisztrálja azt a beállításjegyzékben is.
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
Ha a névvel rendelkező regisztrált modell nem létezik, a metódus regisztrál egy új modellt, létrehozza az 1. verziót, és visszaad egy ModelVersion MLflow objektumot.
Ha már létezik regisztrált modell a névvel, a metódus létrehoz egy új modellverziót, és visszaadja a verzióobjektumot.
Az Azure Machine Learningben regisztrált modellek az MLflow használatával kezelhetők. További részletekért tekintse meg az Azure Machine Learning modellregisztrációs adatbázisainak kezelését az MLflow használatával.
Az Azure Machine Learningben regisztrált modellek üzembe helyezése és felhasználása
Az Azure Machine Learning Service-ben MLflow használatával regisztrált modellek a következőképpen használhatók:
Azure Machine Learning-végpont (valós idejű és köteg): Ez az üzembe helyezés lehetővé teszi az Azure Machine Learning üzembe helyezési képességeit az Azure Container Instances (ACI), az Azure Kubernetes (AKS) vagy a felügyelt végpontok valós idejű és kötegelt következtetéséhez.
MLFlow-modellobjektumok vagy Pandas UDF-ek, amelyek streamelési vagy kötegelt folyamatokban használhatók az Azure Synapse Analytics-jegyzetfüzetekben.
Modellek üzembe helyezése Azure Machine Learning-végpontokon
A azureml-mlflow beépülő modul használatával üzembe helyezhet egy modellt az Azure Machine Learning-munkaterületen. Az MLflow-modellek üzembe helyezésének lapján részletes információkat talál arról, hogyan helyezhet üzembe modelleket a különböző célokra.
Fontos
A modelleket regisztrálni kell az Azure Machine Learning regisztrációs adatbázisában az üzembe helyezésükhöz. A nem regisztrált modellek üzembe helyezése nem támogatott az Azure Machine Learningben.
Modellek üzembe helyezése kötegelt pontozáshoz UDF-ek használatával
A kötegelt pontozáshoz Azure Synapse Analytics-fürtöket választhat. A rendszer betölti az MLFlow-modellt, és Spark Pandas UDF-ként használja az új adatok pontozásához.
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Az erőforrások eltávolítása
Ha meg szeretné tartani az Azure Synapse Analytics-munkaterületet, de már nincs szüksége az Azure Machine Learning-munkaterületre, törölheti az Azure Machine Learning-munkaterületet. Ha nem tervezi használni a naplózott metrikákat és összetevőket a munkaterületen, az egyesével történő törlés lehetősége jelenleg nem érhető el. Ehelyett törölje a tárfiókot és a munkaterületet tartalmazó erőforráscsoportot, így nem kell fizetnie:
Az Azure Portalon válassza az Erőforráscsoportok lehetőséget a bal szélen.
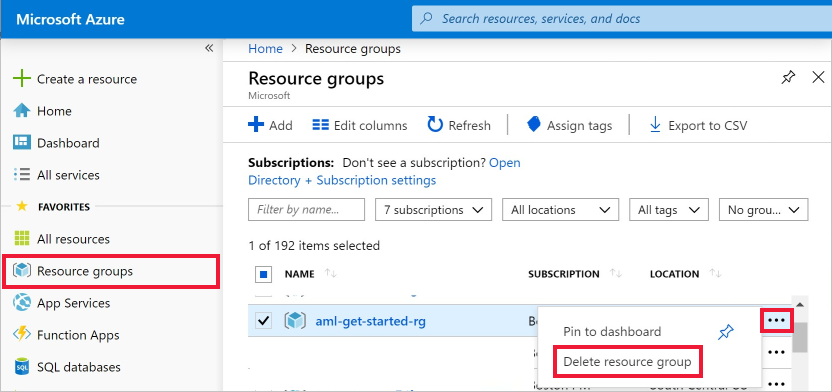
Válassza ki a listában az Ön által létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.