Oktatóanyag: Az első gépi tanulási modell betanítása (SDK v1, 2. rész 3)
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Ez az oktatóanyag bemutatja, hogyan taníthat be gépi tanulási modellt az Azure Machine Learningben. Ez az oktatóanyag egy kétrészes oktatóanyag-sorozat 2. része.
Az 1. rész: A sorozat "Hello world!" futtatása során megtanulta, hogyan futtathat feladatokat a felhőben egy vezérlőszkripttel.
Ebben az oktatóanyagban egy gépi tanulási modellt betanító szkript beküldésével hajtja végre a következő lépést. Ez a példa segít megérteni, hogyan könnyíti meg az Azure Machine Learning a helyi hibakeresés és a távoli futtatások konzisztens viselkedését.
Az oktatóanyag során az alábbi lépéseket fogja végrehajtani:
- Hozzon létre egy betanítási szkriptet.
- Azure Machine Learning-környezet definiálása a Conda használatával.
- Hozzon létre egy vezérlőszkriptet.
- Az Azure Machine Learning-osztályok (
Environment,Run, ).Metrics - Küldje el és futtassa a betanítási szkriptet.
- A kód kimenetének megtekintése a felhőben.
- Naplómetrikák az Azure Machine Learningbe.
- A metrikák megtekintése a felhőben.
Előfeltételek
- A sorozat 1. részének befejezése.
Betanítási szkriptek létrehozása
Először egy model.py fájlban definiálja a neurális hálózati architektúrát. Az összes betanítási kód az alkönyvtárba kerül, beleértve a src model.py.
A betanítási kód a PyTorch ebből a bevezető példából származik. Az Azure Machine Learning fogalmai minden gépi tanulási kódra vonatkoznak, nem csak a PyTorchra.
Hozzon létre egy model.py fájlt az src almappában. Másolja a kódot a fájlba:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xAz eszköztáron kattintson a Mentés gombra a fájl mentéséhez. Ha szeretné, zárja be a lapot.
Ezután adja meg a betanítási szkriptet az src almappában is. Ez a szkript PyTorch
torchvision.datasetAPI-k használatával tölti le a CIFAR10 adathalmazt, beállítja a model.py definiált hálózatot, és két korszakra tanítja be standard SGD és kereszt-entrópia veszteség használatával.Hozzon létre egy train.py szkriptet az src almappában:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Most a következő mappaszerkezettel rendelkezik:

Helyi tesztelés
Válassza a Szkript mentése és futtatása a terminálban lehetőséget a train.py szkript közvetlenül a számítási példányon való futtatásához.
A szkript befejezése után válassza a Frissítés lehetőséget a fájlmappák fölött. Megjelenik az új, get-started/data Expand this mappa nevű adatmappa a letöltött adatok megtekintéséhez.

Python-környezet létrehozása
Az Azure Machine Learning egy olyan környezet koncepcióját biztosítja, amely reprodukálható, verziószámozott Python-környezetet jelöl a kísérletek futtatásához. Könnyen létrehozhat környezeteket egy helyi Conda- vagy pipkörnyezetből.
Először hozzon létre egy fájlt a csomagfüggőségekkel.
Hozzon létre egy új fájlt a következő nevű
pytorch-env.ymlelső lépések mappában:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionAz eszköztáron kattintson a Mentés gombra a fájl mentéséhez. Ha szeretné, zárja be a lapot.
A vezérlőszkript létrehozása
A következő vezérlőszkript és a "Hello world!" beküldéséhez használt szkript közötti különbség az, hogy hozzáad néhány további sort a környezet beállításához.
Hozzon létre egy új Python-fájlt a következő nevű run-pytorch.pyelső lépések mappában:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Tipp.
Ha a számítási fürt létrehozásakor más nevet használt, ügyeljen arra, hogy a kódban compute_target='cpu-cluster' is módosítsa a nevet.
A kódmódosítások ismertetése
env = ...
A fent létrehozott függőségfájlra hivatkozik.
config.run_config.environment = env
A futtatás elküldése az Azure Machine Learningbe
Válassza a Szkript mentése és futtatása a terminálban lehetőséget a run-pytorch.py szkript futtatásához.
Megjelenik egy hivatkozás a megnyíló terminálablakban. Kattintson a hivatkozásra a feladat megtekintéséhez.
Feljegyzés
A azureml_run_type_providers betöltésekor hibajelzések jelenhetnek meg. Ezeket a figyelmeztetéseket figyelmen kívül hagyhatja. A kimenet megtekintéséhez használja a figyelmeztetések alján található hivatkozást.
A kimenet megtekintése
- A megnyíló lapon megjelenik a feladat állapota. A szkript első futtatásakor az Azure Machine Learning létrehoz egy új Docker-rendszerképet a PyTorch-környezetből. Az egész feladat végrehajtása körülbelül 10 percet vehet igénybe. Ezt a lemezképet a jövőbeli feladatokban újra felhasználjuk, hogy sokkal gyorsabban fussanak.
- A Docker buildnaplóit az Azure Machine Learning Studióban tekintheti meg. a buildnaplók megtekintéséhez:
- Válassza a Kimenetek + naplók lapot.
- Válassza ki az azureml-logs mappát.
- Válassza 20_image_build_log.txt.
- Ha a feladat állapota befejeződött, válassza a Kimenet + naplók lehetőséget.
- Válassza user_logs, majd std_log.txt a feladat kimenetének megtekintéséhez.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Ha hibaüzenet Your total snapshot size exceeds the limitjelenik meg, az adatmappa a source_directory használt értékben ScriptRunConfigtalálható.
Válassza ki a mappa végén található ... elemet, majd az Áthelyezés lehetőséget az adatok áthelyezéséhez az első lépések mappába.
Naplóbetanítási metrikák
Most, hogy már rendelkezik modellbetanítással az Azure Machine Learningben, kezdjen nyomon követni néhány teljesítménymetrikát.
Az aktuális betanítási szkript metrikákat nyomtat ki a terminálon. Az Azure Machine Learning több funkcióval rendelkező naplózási metrikákhoz biztosít mechanizmust. Néhány sornyi kód hozzáadásával vizualizálhatja a metrikákat a studióban, és összehasonlíthatja a metrikákat több feladat között.
Train.py módosítása naplózásra
Módosítsa a train.py szkriptet úgy, hogy két további kódsort is tartalmazzon:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Mentse a fájlt, majd zárja be a lapot, ha szeretné.
A további két kódsor ismertetése
A train.py a betanítási szkripten belülről érheti el a futtatási objektumot a Run.get_context() metódus használatával, és a metrikák naplózására használhatja:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Az Azure Machine Learning metrikái a következők:
- Kísérlet és futtatás szerint rendszerezve, így könnyen nyomon követheti és összehasonlíthatja a metrikákat.
- Felhasználói felülettel rendelkezik, így megjelenítheti a betanítási teljesítményt a stúdióban.
- Úgy tervezték, hogy skálázható legyen, így ezeket az előnyöket még több száz kísérlet futtatásakor is megtarthatja.
A Conda környezeti fájl frissítése
A train.py szkript most vett egy új függőséget.azureml.core Frissítés pytorch-env.yml a változásnak megfelelően:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
A futtatás elküldése előtt mentse a fájlt.
A futtatás elküldése az Azure Machine Learningbe
Jelölje ki a run-pytorch.py szkript fülét, majd válassza a Szkript mentése és futtatása a terminálban lehetőséget a run-pytorch.py szkript újrafuttatásához. Győződjön meg arról, hogy először menti a módosításokat pytorch-env.yml .
Ezúttal, amikor meglátogatja a stúdiót, lépjen a Metrikák lapra, ahol mostantól élő frissítéseket láthat a modell betanítási veszteségéről! A betanítás megkezdése 1–2 percet is igénybe vehet.

Az erőforrások eltávolítása
Ha most egy másik oktatóanyagot szeretne folytatni, vagy saját betanítási feladatokat szeretne elindítani, ugorjon a kapcsolódó erőforrásokra.
Számítási példány leállítása
Ha most nem fogja használni, állítsa le a számítási példányt:
- A stúdió bal oldalán válassza a Számítás lehetőséget.
- A felső lapokban válassza a Számítási példányok lehetőséget
- Válassza ki a számítási példányt a listában.
- A felső eszköztáron válassza a Leállítás lehetőséget.
Az összes erőforrás törlése
Fontos
A létrehozott erőforrások előfeltételként használhatók más Azure Machine Learning-oktatóanyagokhoz és útmutatókhoz.
Ha nem tervezi használni a létrehozott erőforrások egyikét sem, törölje őket, hogy ne járjon költséggel:
Az Azure Portal keresőmezőjében adja meg az erőforráscsoportokat , és válassza ki az eredmények közül.
A listából válassza ki a létrehozott erőforráscsoportot.
Az Áttekintés lapon válassza az Erőforráscsoport törlése lehetőséget.
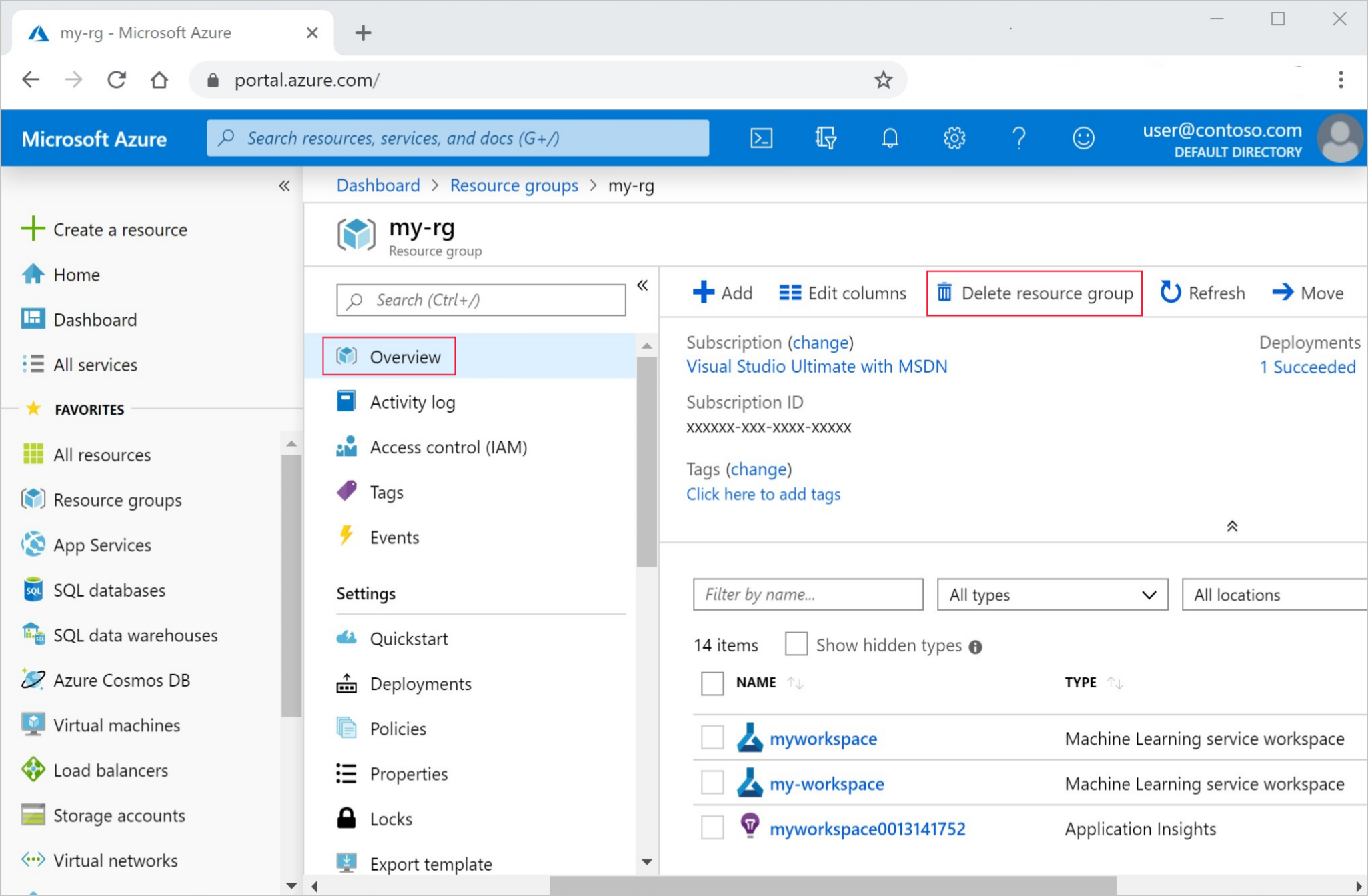
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Megtarthatja az erőforráscsoportot is, de egyetlen munkaterületet törölhet. Jelenítse meg a munkaterület tulajdonságait, és válassza a Törlés lehetőséget.
Kapcsolódó erőforrások
Ebben a munkamenetben egy alapszintű "Hello world!" szkriptről frissített egy reálisabb betanítási szkriptre, amely egy adott Python-környezetet igényelt a futtatáshoz. Látta, hogyan használhat válogatott Azure Machine Learning-környezeteket. Végül láthatta, hogyan naplózhatja a metrikákat néhány kódsorban az Azure Machine Learningbe.
Más módokon is létrehozhat Azure Machine Learning-környezeteket, például pip requirements.txt fájlból vagy meglévő helyi Conda-környezetből.