Oktatóanyag: Igény előrejelzése kód nélküli automatizált gépi tanulással az Azure Machine Learning Studióban
Megtudhatja, hogyan hozhat létre idősorozat-előrejelzési modellt anélkül, hogy egyetlen kódsort írnál az Azure Machine Learning Studióban automatizált gépi tanulással. Ez a modell előrejelzi a kerékpármegosztási szolgáltatás bérleti igényét.
Ebben az oktatóanyagban nem ír kódot, a studio felület használatával végzi el a betanítást. Megtudhatja, hogyan végezheti el a következő feladatokat:
- Adathalmaz létrehozása és betöltése.
- Automatizált gépi tanulási kísérlet konfigurálása és futtatása.
- Adja meg az előrejelzési beállításokat.
- A kísérlet eredményeinek megismerése.
- A legjobb modell üzembe helyezése.
Próbálja ki az automatizált gépi tanulást is az alábbi modelltípusokhoz:
- A besorolási modellek kód nélküli példáiért tekintse meg az oktatóanyagot: Besorolási modell létrehozása automatizált gépi tanulással az Azure Machine Learningben.
- Az objektumészlelési modell első példakódját a következő oktatóanyagban tekinti meg: Objektumészlelési modell betanítása autoML-vel és Pythonnal.
Előfeltételek
Egy Azure Machine Learning-munkaterület. Lásd: Munkaterület-erőforrások létrehozása.
A bike-no.csv adatfájl letöltése
Bejelentkezés a stúdióba
Ebben az oktatóanyagban az Azure Machine Learning Studióban futtatott automatizált gépi tanulási kísérletét hozza létre, amely egy összevont webes felület, amely gépi tanulási eszközöket tartalmaz az adatelemzési forgatókönyvek végrehajtásához az adatelemzési szakemberek számára minden készségszinten. A stúdió nem támogatott az Internet Explorer böngészőkben.
Válassza ki az előfizetést és a létrehozott munkaterületet.
Válassza az Első lépések lehetőséget.
A bal oldali panelen válassza az Automatizált gépi tanulás lehetőséget a Szerző szakaszban.
Válassza az +Új automatizált gépi tanulási feladat lehetőséget.
Adathalmaz létrehozása és betöltése
A kísérlet konfigurálása előtt töltse fel az adatfájlt a munkaterületre egy Azure Machine Learning-adatkészlet formájában. Ezzel biztosíthatja, hogy az adatok megfelelően legyenek formázva a kísérlethez.
Az Adathalmaz kiválasztása űrlapon válassza a Helyi fájlok lehetőséget a +Adathalmaz létrehozása legördülő listában.
Az Alapszintű információs űrlapon adjon nevet az adathalmaznak, és adjon meg egy opcionális leírást. Az adathalmaz típusának alapértelmezés szerint táblázatosnak kell lennie, mivel az Azure Machine Learning Studióban az automatizált gépi tanulás jelenleg csak a táblázatos adathalmazokat támogatja.
A bal alsó sarokban válassza a Tovább gombot
Az Adattár és a fájlkijelölési űrlapon válassza ki az alapértelmezett adattárat, amely automatikusan be lett állítva a munkaterület létrehozásakor, a workspaceblobstore (Azure Blob Storage) szolgáltatásban. Itt töltheti fel az adatfájlt.
Válassza a Fájlok feltöltése lehetőséget a Feltöltés legördülő listában.
Válassza ki a bike-no.csv fájlt a helyi számítógépen. Ez az előfeltételként letöltött fájl.
Válassza a Tovább lehetőséget
Amikor a feltöltés befejeződött, a Beállítások és az előnézeti űrlap előre ki lesz töltve a fájltípus alapján.
Ellenőrizze, hogy a Beállítások és az előnézet űrlap az alábbiak szerint van-e kitöltve, és válassza a Tovább gombot.
Mező Leírás Az oktatóanyag értéke Fájlformátum Meghatározza a fájlban tárolt adatok elrendezését és típusát. Tagolt Elválasztókarakter Egy vagy több karakter a különálló, független régiók közötti határ megadásához egyszerű szöveges vagy más adatfolyamokban. Vessző Kódolás Meghatározza, hogy milyen bitet használjon a sématábla az adathalmaz olvasásához. UTF-8 Oszlopfejlécek Azt jelzi, hogy az adathalmaz fejlécei (ha vannak ilyenek) hogyan lesznek kezelve. Csak az első fájl rendelkezik fejlécekkel Sorok kihagyása Azt jelzi, hogy a program hány sort hagy ki az adathalmazból, ha vannak ilyenek. Egyik sem A sémaűrlap lehetővé teszi a kísérlet adatainak további konfigurálását.
Ebben a példában hagyja figyelmen kívül az alkalmi és a regisztrált oszlopokat. Ezek az oszlopok a cnt oszlop lebontását képezik, ezért nem vesszük fel őket.
Ebben a példában is hagyja meg a Tulajdonságok és típus alapértelmezett beállításait.
Válassza a Tovább lehetőséget.
A Részletek megerősítése űrlapon ellenőrizze, hogy az adatok megegyeznek-e az Alapadatok és beállítások, valamint az előnézeti űrlapok korábban feltöltött adataival.
Válassza a Létrehozás lehetőséget az adathalmaz létrehozásának befejezéséhez.
Jelölje ki az adathalmazt, amint megjelenik a listában.
Válassza a Tovább lehetőséget.
Feladat konfigurálása
Miután betöltötte és konfigurálta az adatokat, állítsa be a távoli számítási célt, és válassza ki az előrejelezni kívánt adatok melyik oszlopát.
- Töltse ki a Feladat konfigurálása űrlapot az alábbiak szerint:
Adja meg a kísérlet nevét:
automl-bikeshareVálassza ki a cntet céloszlopként, amit előre szeretne jelezni. Ez az oszlop a kerékpármegosztások teljes bérleti díjának számát jelzi.
Számítási típusként válassza ki a számítási fürtöt .
Válassza az +Új lehetőséget a számítási cél konfigurálásához. Az automatizált gépi tanulás csak az Azure Machine Learning számítást támogatja.
Töltse ki a Virtuális gép kiválasztása űrlapot a számítás beállításához.
Mező Leírás Az oktatóanyag értéke Virtuálisgép-szint Válassza ki, hogy milyen prioritással kell rendelkeznie a kísérletnek Dedikált Virtuális gép típusa Válassza ki a virtuális gép típusát a számításhoz. CPU (központi feldolgozó egység) Virtuális gép mérete Válassza ki a virtuális gép méretét a számításhoz. Az ajánlott méretek listája az adatok és a kísérlet típusa alapján érhető el. Standard_DS12_V2 Válassza a Tovább lehetőséget a Beállítások konfigurálása űrlap kitöltéséhez.
Mező Leírás Az oktatóanyag értéke Számítási név Egyedi név, amely azonosítja a számítási környezetet. kerékpár-számítás Minimális / maximális csomópontok A profiladatok megadásához meg kell adnia egy vagy több csomópontot. Minimális csomópontok: 1
Maximális csomópontok: 6Tétlenség másodperccel a leskálázás előtt Üresjárati idő, mielőtt a fürt automatikusan leskálázható a minimális csomópontszámra. 120 (alapértelmezett) Speciális beállítások Virtuális hálózat konfigurálására és engedélyezésére szolgáló beállítások a kísérlethez. Egyik sem Válassza a Létrehozás lehetőséget a számítási cél lekéréséhez.
Ez néhány percet vesz igénybe.
A létrehozás után válassza ki az új számítási célt a legördülő listából.
Válassza a Tovább lehetőséget.
Előrejelzési beállítások kiválasztása
Végezze el az automatizált gépi tanulási kísérlet beállítását a gépi tanulási feladat típusának és konfigurációs beállításainak megadásával.
A Feladat típusa és beállításai űrlapon válassza az Idősor-előrejelzés lehetőséget gépi tanulási feladattípusként.
Válassza ki a dátumot az Idő oszlopban , és hagyja üresen az Idősor azonosítóit .
A gyakoriság az, hogy milyen gyakran gyűjti össze a korábbi adatokat. Az automatikus észlelés maradjon kijelölve.
Az előrejelzési horizont az előrejelezni kívánt jövőbe eső idő hossza. Törölje az automatikus kijelölés jelölését, és írja be a 14-et a mezőbe.
Válassza a További konfigurációs beállítások megtekintése lehetőséget, és töltse ki a mezőket az alábbiak szerint. Ezek a beállítások a betanítási feladat jobb szabályozásához és az előrejelzés beállításainak megadásához szükségesek. Ellenkező esetben az alapértelmezett értékek a kísérlet kiválasztása és az adatok alapján lesznek alkalmazva.
További beállítások Leírás Az oktatóanyag értéke Elsődleges metrika Kiértékelési mérőszám, amellyel a gépi tanulási algoritmust mérni fogja. Normalizált gyökér középértéke négyzetes hiba A legjobb modell ismertetése Automatikusan megjeleníti az automatizált gépi tanulás által létrehozott legjobb modell magyarázatát. Engedélyezés Letiltott algoritmusok A betanítási feladatból kizárni kívánt algoritmusok Szélsőséges véletlenszerű fák További előrejelzési beállítások Ezek a beállítások segítenek javítani a modell pontosságát.
Előrejelzési célelmaradások: milyen messze szeretné létrehozni a célváltozó késéseit
Célgördülő ablak: a gördülő ablak méretét határozza meg, amely felett a rendszer olyan funkciókat hoz létre, mint a maximális, a minimális és az összeg.
Előrejelzési célelmaradások: Nincs
Célgördülő ablak mérete: NincsKilépési feltétel Ha egy feltétel teljesül, a betanítási feladat leáll. Betanítási feladat ideje (óra): 3
Metrikapont küszöbértéke: NincsEgyidejűség Az iterációnként végrehajtott párhuzamos iterációk maximális száma Maximális egyidejű iterációk: 6 Válassza a Mentés lehetőséget.
Válassza a Következő lehetőséget.
Az [Opcionális] Érvényesítési és tesztelési űrlapon:
- Válassza a k-fold keresztérvényesítést érvényesítési típusként.
- Válassza az 5 lehetőséget a keresztérvényesítések számaként.
Kísérlet futtatása
A kísérlet futtatásához válassza a Befejezés lehetőséget. Megnyílik a Feladat részletei képernyő, amelynek tetején a Feladat állapota látható a feladatszám mellett. Ez az állapot a kísérlet előrehaladásával frissül. Az értesítések a stúdió jobb felső sarkában is megjelennek, hogy tájékoztassák a kísérlet állapotáról.
Fontos
Az előkészítés 10-15 percet vesz igénybe a kísérletfeladat előkészítéséhez.
A futtatás után 2-3 percet vesz igénybe az egyes iterációk.
Éles környezetben valószínűleg elsétálhat egy kicsit, mivel ez a folyamat időt vesz igénybe. Várakozás közben azt javasoljuk, hogy kezdje el felfedezni a tesztelt algoritmusokat a Modellek lapon, amint befejeződnek.
Modellek felfedezése
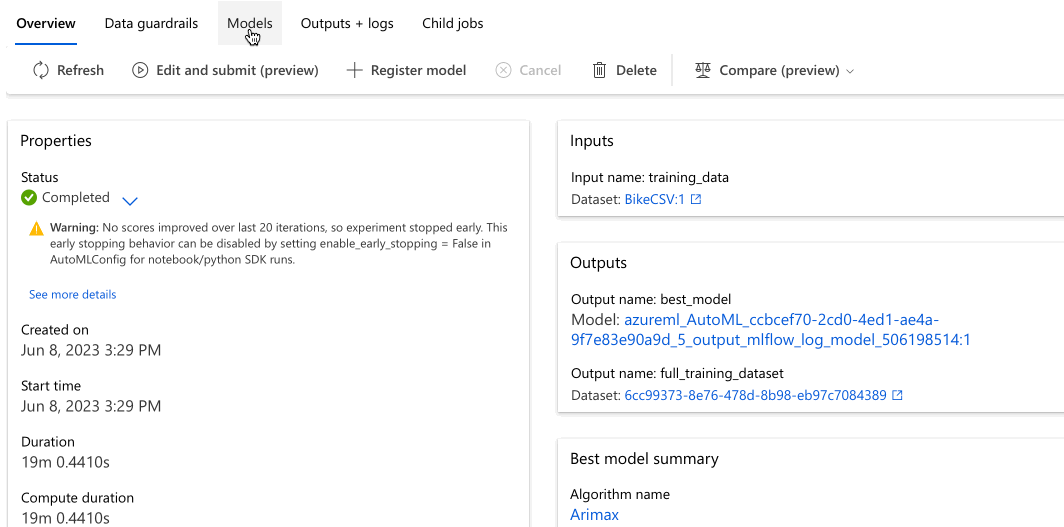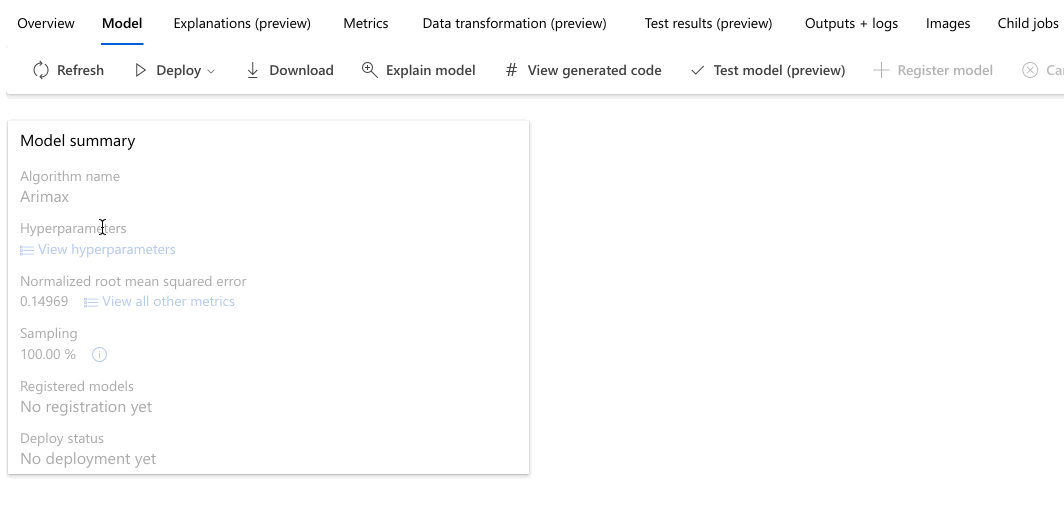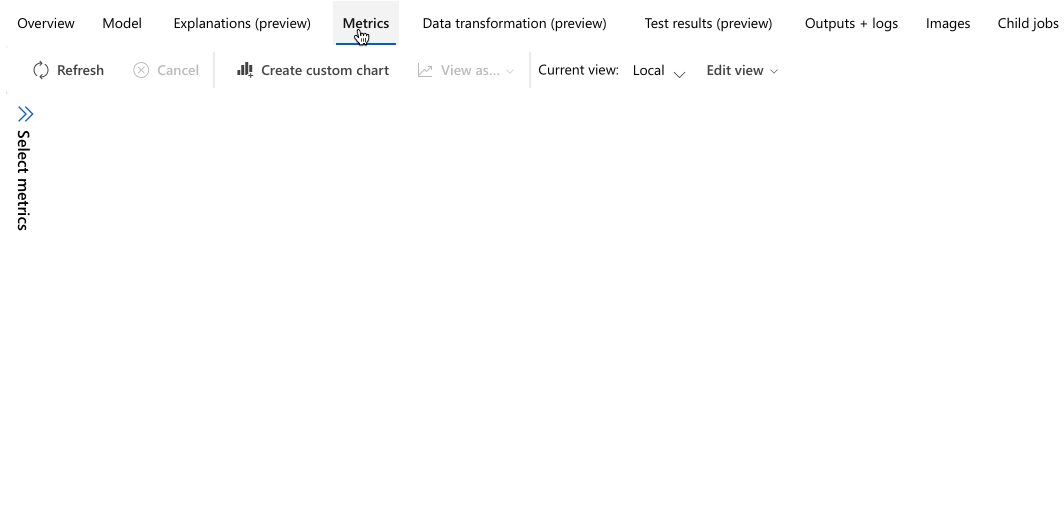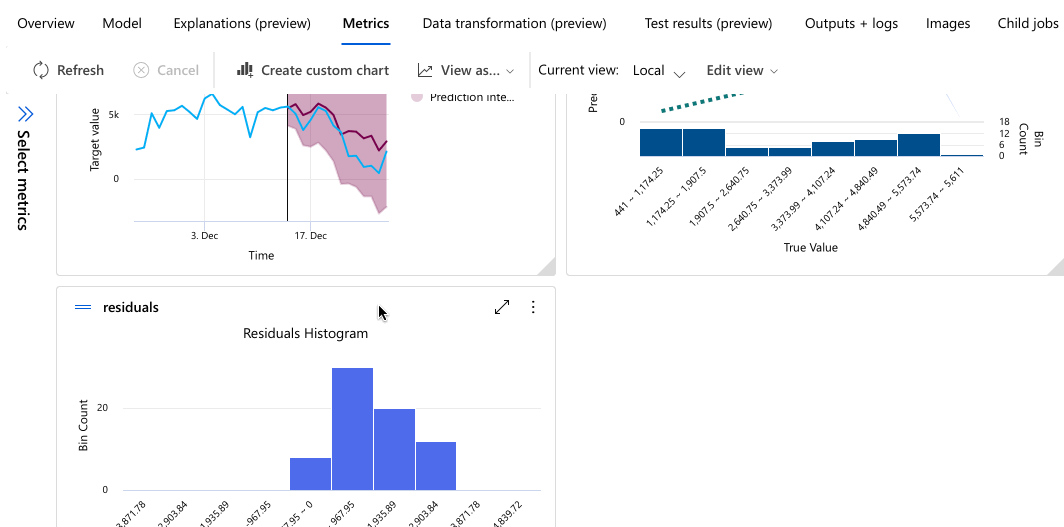
Lépjen a Modellek lapra a tesztelt algoritmusok (modellek) megtekintéséhez. A modelleket alapértelmezés szerint a metrika pontszáma rendezi a befejezésük során. Ebben az oktatóanyagban az a modell áll a lista tetején, amely a kiválasztott normalizált gyökér középértékének négyzetes átlaga alapján a legmagasabb pontszámot adja.
Amíg az összes kísérletmodell befejeződik, válassza ki a kész modell algoritmusnevét a teljesítmény részleteinek megismeréséhez.
Az alábbi példa egy modellt választ ki a feladat által létrehozott modellek listájából. Ezután az Áttekintés és a Metrikák fület választva megtekintheti a kiválasztott modell tulajdonságait, metrikáit és teljesítménydiagramjait.
A modell üzembe helyezése
Az Azure Machine Learning Studio automatizált gépi tanulásával néhány lépésben üzembe helyezheti a legjobb modellt webszolgáltatásként. Az üzembe helyezés a modell integrációja, hogy előre jelezhesse az új adatokat, és azonosíthassa a lehetséges lehetőségeket.
Ebben a kísérletben a webszolgáltatásban való üzembe helyezés azt jelenti, hogy a kerékpármegosztási vállalat iteratív és méretezhető webes megoldással rendelkezik a kerékpármegosztások bérleti szükségletének előrejelzéséhez.
A feladat befejezése után lépjen vissza a szülőfeladat lapjára a képernyő tetején található 1. feladat kiválasztásával.
A Legjobb modell összegzése szakaszban a kísérlet kontextusában a legjobb modell van kiválasztva a normalizált gyökér középértéke négyzetes hibametrika alapján.
Ezt a modellt üzembe helyezzük, de javasoljuk, hogy az üzembe helyezés körülbelül 20 percet vesz igénybe. Az üzembe helyezési folyamat több lépést is magában foglal, többek között a modell regisztrálását, az erőforrások generálását és a webszolgáltatáshoz való konfigurálását.
Válassza ki a legjobb modellt a modellspecifikus oldal megnyitásához.
Válassza a képernyő bal felső részén található Üzembe helyezés gombot.
Töltse ki a Modell üzembe helyezése panelt az alábbiak szerint:
Mező Érték Üzemelő példány neve bikeshare-deploy Üzembe helyezés leírása kerékpármegosztási igény üzembe helyezése Számítási típus Az Azure Compute Instance (ACI) kiválasztása Hitelesítés engedélyezése Letiltás. Egyéni üzembehelyezési eszközök használata Letiltás. A letiltás lehetővé teszi az alapértelmezett illesztőfájl (pontozási szkript) és a környezeti fájl automatikus generálását. Ebben a példában a Speciális menüben megadott alapértelmezett értékeket használjuk.
Válassza az Üzembe helyezés lehetőséget.
A Feladat képernyő tetején megjelenik egy zöld sikerüzenet, amely jelzi, hogy az üzembe helyezés sikeresen elindult. Az üzembe helyezés előrehaladása a Modell összegzése panelen, az Üzembe helyezés állapot alatt található.
Miután az üzembe helyezés sikeres volt, egy operatív webszolgáltatással rendelkezik, amely előrejelzéseket hoz létre.
A Következő lépésekkel többet tudhat meg az új webszolgáltatás használatáról, és tesztelheti az előrejelzéseket a Power BI beépített Azure Machine Learning-támogatásával.
Az erőforrások eltávolítása
Az üzembehelyezési fájlok nagyobbak, mint az adatok és a kísérletfájlok, ezért többe kerülnek a tárolásuk. Csak az üzembehelyezési fájlokat törölje a fiók költségeinek minimalizálása érdekében, vagy ha meg szeretné tartani a munkaterületet és a kísérletfájlokat. Ellenkező esetben törölje a teljes erőforráscsoportot, ha egyik fájlt sem szeretné használni.
Az üzembe helyezési példány törlése
Törölje csak az üzembe helyezési példányt az Azure Machine Learning Studióból, ha meg szeretné tartani az erőforráscsoportot és a munkaterületet más oktatóanyagokhoz és feltáráshoz.
Nyissa meg az Azure Machine Learning Studiót. Lépjen a munkaterületre, és az Eszközök panel bal oldalán válassza a Végpontok lehetőséget.
Jelölje ki a törölni kívánt üzembe helyezést, és válassza a Törlés lehetőséget.
Válassza a Folytatás lehetőséget.
Az erőforráscsoport törlése
Fontos
A létrehozott erőforrások előfeltételként használhatók más Azure Machine Learning-oktatóanyagokhoz és útmutatókhoz.
Ha nem tervezi használni a létrehozott erőforrások egyikét sem, törölje őket, hogy ne járjon költséggel:
Az Azure Portalon válassza az Erőforráscsoportok lehetőséget a bal szélen.
A listából válassza ki a létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
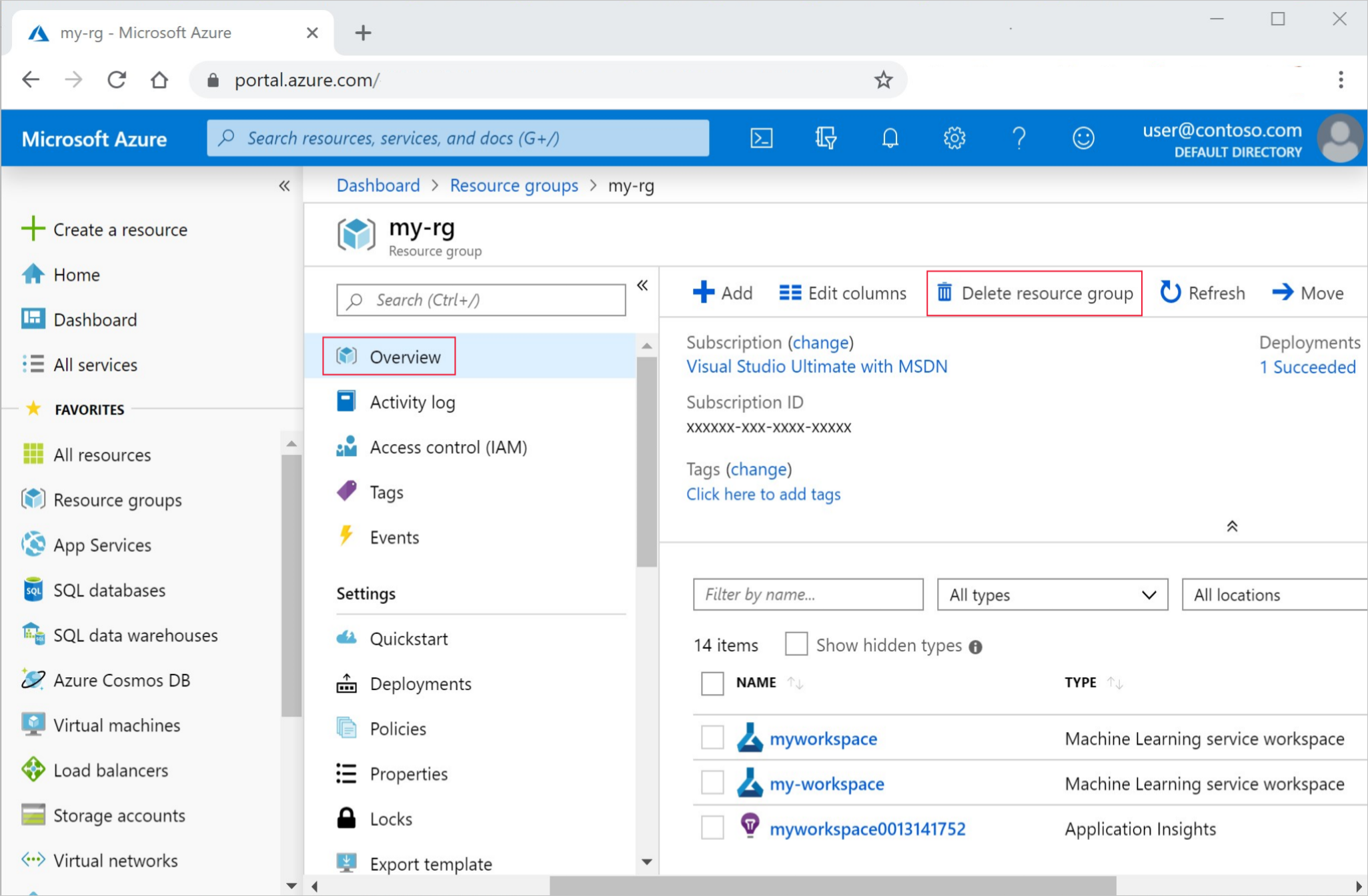
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Következő lépések
Ebben az oktatóanyagban automatizált gépi tanulást használt az Azure Machine Learning Studióban egy olyan idősorozat-előrejelzési modell létrehozásához és üzembe helyezéséhez, amely előrejelzi a kerékpármegosztások bérleti igényét.
- További információ az automatizált gépi tanulásról.
- A besorolási metrikákkal és diagramokkal kapcsolatos további információkért tekintse meg az automatizált gépi tanulási eredményekről szóló cikket.
- További információ az előrejelzéssel kapcsolatos gyakori kérdésekről.
Feljegyzés
Ez a kerékpármegosztási adatkészlet az oktatóanyaghoz módosult. Ez az adatkészlet egy Kaggle-verseny részeként lett elérhetővé téve, és eredetileg a Capital Bikeshare-on keresztül volt elérhető. Az UCI Machine Learning Database-ben is megtalálható.
Forrás: Fanaee-T, Hadi, and Gama, Joao, Event labeling combining combining ensemble detectors and background knowledge, Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg.