1. oktatóanyag: Szolgáltatáskészlet fejlesztése és regisztrálása kezelt funkciótár
Ez az oktatóanyag-sorozat bemutatja, hogyan integrálhatók zökkenőmentesen a funkciók a gépi tanulási életciklus minden fázisában: prototípus-tervezés, betanítás és üzembe helyezés.
Az Azure Machine Learning kezelt funkciótár segítségével felderítheti, létrehozhatja és üzembe helyezheti a funkciókat. A gépi tanulás életciklusa egy prototípuskészítési fázist tartalmaz, ahol különböző funkciókkal kísérletezhet. Ez egy üzemeltetési fázist is magában foglal, amelyben a modellek üzembe helyezése és a következtetési lépések a funkcióadatok kereséséhez szükségesek. A funkciók a gépi tanulási életciklus kötőszöveteként szolgálnak. A kezelt funkciótár alapfogalmaival kapcsolatos további információkért tekintse meg a Mi az kezelt funkciótár? című témakört, és ismerje meg kezelt funkciótár erőforrások legfelső szintű entitásainak ismertetését.
Ez az oktatóanyag bemutatja, hogyan hozhat létre szolgáltatáskészlet-specifikációt egyéni átalakításokkal. Ezt a funkciókészletet használja a betanítási adatok létrehozásához, a materializálás engedélyezéséhez és a visszatöltés végrehajtásához. A materializálás kiszámítja egy funkcióablak funkcióértékeit, majd ezeket az értékeket egy materializálási tárolóban tárolja. Ezután minden funkció-lekérdezés használhatja ezeket az értékeket a materializálási tárolóból.
Materializálás nélkül a funkciókészlet-lekérdezés menet közben alkalmazza az átalakításokat a forrásra, hogy kiszámítsa a szolgáltatásokat, mielőtt visszaadja az értékeket. Ez a folyamat jól működik a prototípus-készítéshez. Éles környezetben végzett betanítási és következtetési műveletek esetén azonban azt javasoljuk, hogy a nagyobb megbízhatóság és rendelkezésre állás érdekében a funkciók megvalósuljon.
Ez az oktatóanyag az kezelt funkciótár oktatóanyag-sorozat első része. Itt megtudhatja, hogyan:
- Hozzon létre egy új, minimális funkciótár-erőforrást.
- Szolgáltatáskészlet fejlesztése és helyi tesztelése funkcióátalakítási képességgel.
- Szolgáltatástár-entitás regisztrálása a funkciótárolóban.
- Regisztrálja a szolgáltatástárban kifejlesztett szolgáltatáskészletet.
- Hozzon létre egy minta betanítási DataFrame-et a létrehozott funkciók használatával.
- Engedélyezze az offline materializálást a szolgáltatáskészleteken, és töltse ki a funkcióadatokat.
Ez az oktatóanyag-sorozat két számmal rendelkezik:
- A csak SDK-s pálya csak Python SDK-kat használ. Válassza ezt a pályát tiszta, Python-alapú fejlesztéshez és üzembe helyezéshez.
- Az SDK és a CLI-nyomkövetés a Python SDK-t használja a szolgáltatáskészletek fejlesztéséhez és teszteléséhez, és a PARANCSSOR-t használja CRUD-műveletekhez (létrehozás, olvasás, frissítés és törlés). Ez a pálya a folyamatos integráció és a folyamatos teljesítés (CI/CD) vagy a GitOps-forgatókönyvekben hasznos, ahol a CLI/YAML van előnyben.
Előfeltételek
Mielőtt folytatná ezt az oktatóanyagot, ügyeljen az alábbi előfeltételekre:
Egy Azure Machine Learning-munkaterület. A munkaterület létrehozásával kapcsolatos további információkért tekintse meg a munkaterület erőforrásainak létrehozását ismertető rövid útmutatót.
A felhasználói fiókban szüksége van a tulajdonosi szerepkörre ahhoz az erőforráscsoporthoz, amelyben a szolgáltatástároló létrejön.
Ha az oktatóanyaghoz új erőforráscsoportot használ, az erőforráscsoport törlésével egyszerűen törölheti az összes erőforrást.
A jegyzetfüzet-környezet előkészítése
Ez az oktatóanyag egy Azure Machine Learning Spark-jegyzetfüzetet használ a fejlesztéshez.
Az Azure Machine Learning Studio környezetében válassza a Jegyzetfüzetek lehetőséget a bal oldali panelen, majd válassza a Minták lapot.
Keresse meg a featurestore_sample könyvtárat (válassza a Samples>SDK v2>sdk>Python>featurestore_sample), majd válassza a Klónozás lehetőséget.

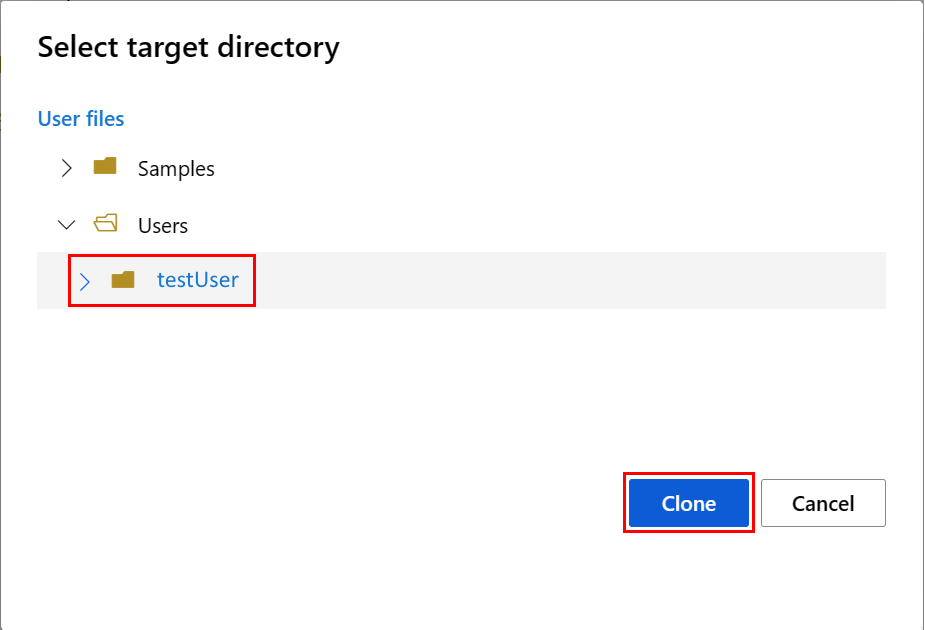
Megnyílik a Célkönyvtár kiválasztása panel. Válassza ki a Felhasználók könyvtárat, majd válassza ki a felhasználónevet, majd végül válassza a Klónozás lehetőséget.
A jegyzetfüzet-környezet konfigurálásához fel kell töltenie a conda.yml fájlt:
- Válassza a Jegyzetfüzetek lehetőséget a bal oldali panelen, majd válassza a Fájlok lapot.
- Keresse meg az env könyvtárat (válassza a Felhasználók>your_user_name featurestore_sample>>projekt>env) lehetőséget, majd válassza ki a conda.yml fájlt.
- Válassza a Letöltés lehetőséget.
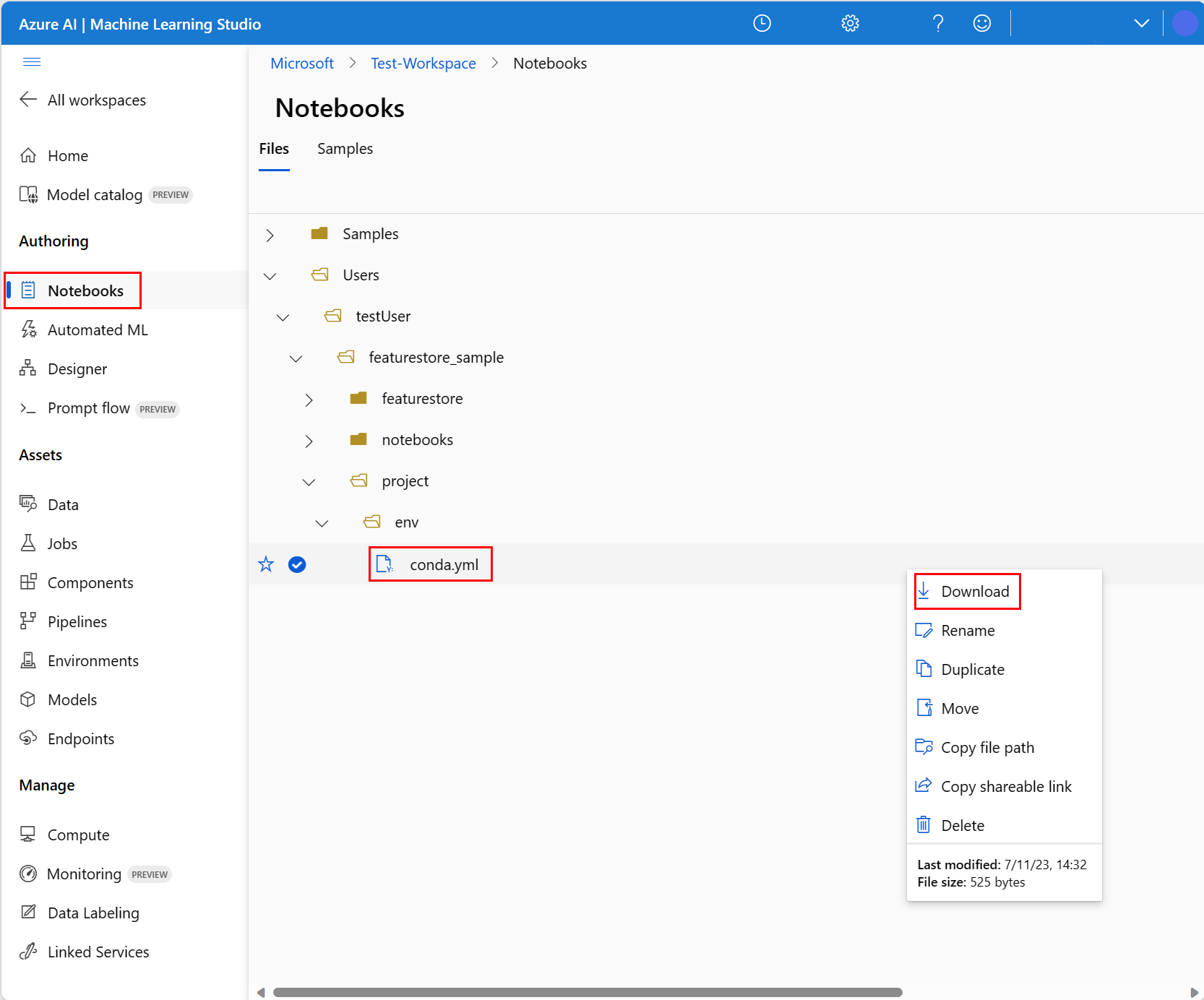
- Válassza a Kiszolgáló nélküli Spark Compute lehetőséget a felső navigációs Compute legördülő listában. Ez a művelet egy-két percet is igénybe vehet. Várjon, amíg a felső állapotsoron megjelenik a Konfigurálás munkamenet.
- Válassza a Munkamenet konfigurálása lehetőséget a felső állapotsoron.
- Válassza ki a Python-csomagokat.
- Válassza a Conda-fájlok feltöltése lehetőséget.
- Válassza ki a
conda.ymlhelyi eszközön letöltött fájlt. - (Nem kötelező) Növelje a munkamenet időtúllépését (percek alatt üresjárati időt) a kiszolgáló nélküli Spark-fürt indítási idejének csökkentése érdekében.
Az Azure Machine Learning-környezetben nyissa meg a jegyzetfüzetet, majd válassza a Munkamenet konfigurálása lehetőséget.
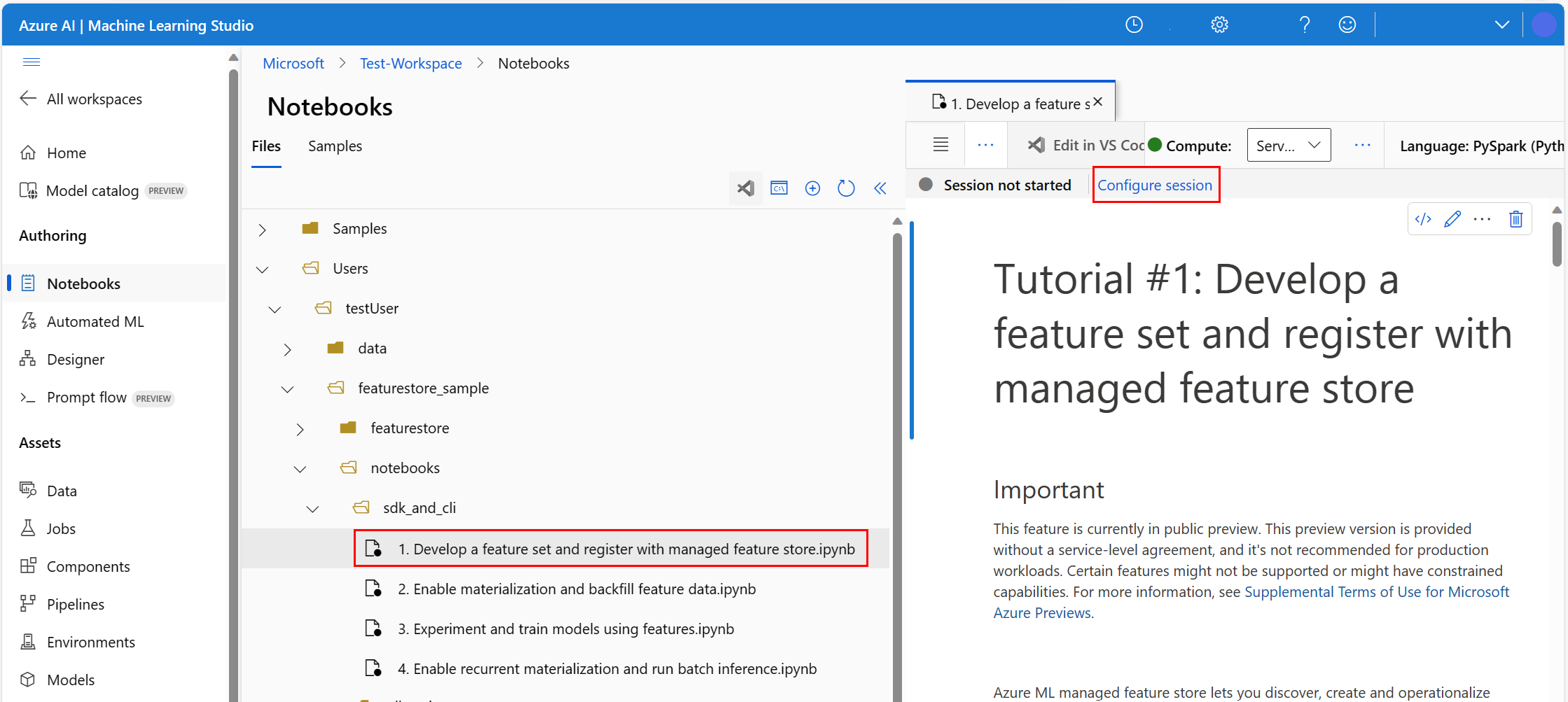
A Munkamenet konfigurálása panelen válassza ki a Python-csomagokat.
Töltse fel a Conda-fájlt:
- A Python-csomagok lapon válassza a Conda-fájl feltöltése lehetőséget.
- Keresse meg a Conda-fájlt üzemeltető könyvtárat.
- Válassza a conda.yml, majd a Megnyitás lehetőséget.
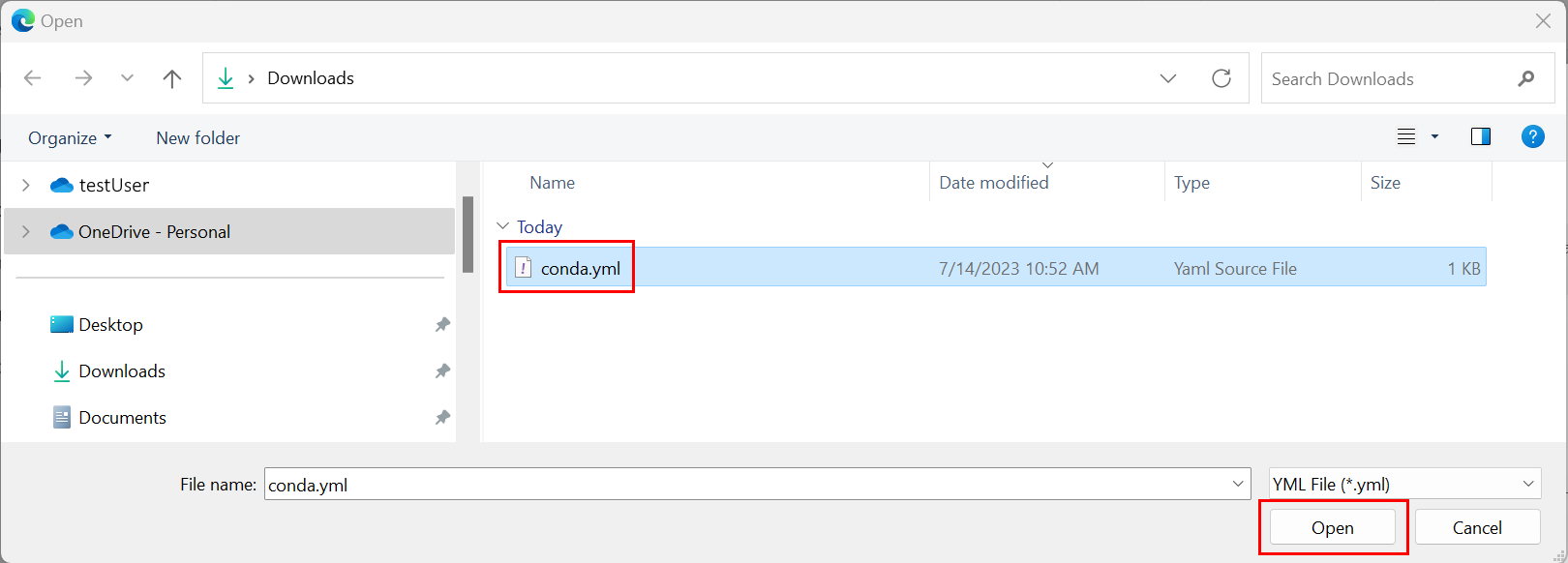
Válassza az Alkalmazás lehetőséget.







A Spark-munkamenet indítása
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")A minták gyökérkönyvtárának beállítása
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")A parancssori felület beállítása
Nem alkalmazható.
Feljegyzés
Egy szolgáltatástár használatával újra felhasználhatja a különböző projektek funkcióit. Egy projekt-munkaterületet (egy Azure Machine Learning-munkaterületet) használ a következtetési modellek betanításához, kihasználva a funkciótárolók funkcióit. Számos projekt-munkaterület megoszthatja és újra felhasználhatja ugyanazt a funkciótárolót.
Ez az oktatóanyag két SDK-t használ:
A CRUD SDK szolgáltatástárolója
Ugyanazt
MLClienta (csomagnevetazure-ai-ml) SDK-t használja, amelyet az Azure Machine Learning-munkaterületen használ. A szolgáltatástár munkaterület-típusként van implementálva. Ennek eredményeképpen ez az SDK a CRUD-műveletekhez használható funkciótárolókhoz, funkciókészletekhez és funkciótár-entitásokhoz.Szolgáltatástár alapszintű SDK
Ez az SDK (
azureml-featurestore) funkciókészletek fejlesztésére és felhasználására szolgál. Az oktatóanyag későbbi lépései az alábbi műveleteket ismertetik:- Szolgáltatáskészlet-specifikáció fejlesztése.
- Funkcióadatok lekérése.
- Listázhat vagy lekérhet egy regisztrált funkciókészletet.
- Szolgáltatáslekérési specifikációk létrehozása és feloldása.
- Betanítási és következtetési adatok létrehozása időponthoz kötött illesztések használatával.
Ez az oktatóanyag nem igényli az SDK-k explicit telepítését, mivel a korábbi conda.yml utasítások ezt a lépést ismertetik.
Minimális funkciótároló létrehozása
Adja meg a szolgáltatástár paramétereit, beleértve a nevet, a helyet és az egyéb értékeket.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Hozza létre a szolgáltatástárolót.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Inicializáljon egy szolgáltatástároló alapvető SDK-ügyfelet az Azure Machine Learninghez.
Az oktatóanyag korábbi részében leírtak szerint a funkciótároló alapvető SDK-ügyfelet a funkciók fejlesztésére és felhasználására használják.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Adja meg az "Azure Machine Learning adattudós" szerepkört a szolgáltatástárban a felhasználói identitásnak. Szerezze be a Microsoft Entra objektumazonosító értékét az Azure Portalról a felhasználói objektumazonosító megkeresése című szakaszban leírtak szerint.
Rendelje hozzá az AzureML adattudós szerepkört a felhasználói identitáshoz, hogy erőforrásokat hozhasson létre a szolgáltatástár-munkaterületen. Az engedélyek propagálásához szükség lehet egy kis időre.
A hozzáférés-vezérléssel kapcsolatos további információkért látogasson el a hozzáférés-vezérlés kezelése kezelt funkciótár erőforráshoz.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Szolgáltatáskészlet prototípusa és fejlesztése
Az alábbi lépésekben létrehoz egy olyan funkciókészletet, amelynek neve transactions összesítőablak-alapú funkciókkal rendelkezik:
Ismerkedjen meg a
transactionsforrásadatokkal.Ez a jegyzetfüzet nyilvánosan elérhető blobtárolóban tárolt mintaadatokat használ. Csak illesztőprogramon keresztül olvasható be a
wasbsSparkba. Amikor saját forrásadatokkal hoz létre szolgáltatáskészleteket, egy Azure Data Lake Storage Gen2-fiókban tárolja őket, és használjon egy illesztőprogramotabfssaz adatútvonalon.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueA funkciókészlet helyi fejlesztése.
A szolgáltatáskészlet-specifikációk a helyileg fejleszthető és tesztelhető funkciókészletek önálló definíciói. Itt hozza létre ezeket a gördülőablak-összesítő funkciókat:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
Tekintse át a funkcióátalakítási kódfájlt: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Figyelje meg a funkciókhoz definiált gördülő összesítést. Ez egy Spark-transzformátor.
Ha többet szeretne megtudni a funkciókészletről és az átalakításokról, látogasson el a What is kezelt funkciótár? erőforrásra.
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Exportálás funkciókészlet-specifikációként.
Ha regisztrálni szeretné a funkciókészlet specifikációját a szolgáltatástárolóban, ezt a specifikációt egy adott formátumban kell mentenie.
Tekintse át a létrehozott
transactionsfunkciókészlet specifikációját. Nyissa meg ezt a fájlt a fájlfáról a featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml specifikáció megtekintéséhez.A specifikáció a következő elemeket tartalmazza:
source: Egy tárolási erőforrásra mutató hivatkozás. Ebben az esetben ez egy blobtároló-erőforrás parquet-fájlja.features: A funkciók és adattípusaik listája. Ha átalakítási kódot ad meg, a kódnak olyan DataFrame-et kell visszaadnia, amely megfelel a funkcióknak és az adattípusoknak.index_columns: A funkciókészlet értékeinek eléréséhez szükséges illesztőkulcsok.
A specifikációval kapcsolatos további információkért látogasson el az Kezelt funkciótár és a CLI (v2) szolgáltatáskészlet YAML-sémaerőforrásainak megértéséhez.
A funkciókészlet specifikációjának megőrzése egy másik előnyt is kínál: a funkciókészlet specifikációja támogatja a forráskövetést.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
Szolgáltatástár-entitás regisztrálása
Ajánlott eljárásként az entitások segítenek kikényszeríteni ugyanazon illesztéskulcs-definíció használatát az azonos logikai entitásokat használó funkciókészletekben. Az entitások közé tartoznak például a fiókok és az ügyfelek. Az entitások általában egyszer jönnek létre, majd újra felhasználhatók a funkciókészletek között. További információért látogasson el az kezelt funkciótár legfelső szintű entitásainak megértéséhez.
Inicializálja a szolgáltatástároló CRUD-ügyfelet.
Az oktatóanyag
MLClientkorábbi részében leírtak szerint funkciótároló-objektumot hozhat létre, olvashat, frissíthet és törölhet. Az itt látható jegyzetfüzetkódcella-minta egy korábbi lépésben létrehozott szolgáltatástárolóra keres. Itt nem használhatja újra ugyanaztml_clientaz értéket, amelyet az oktatóanyag korábbi részében használt, mivel ez az érték az erőforráscsoport szintjén van hatókörben. A funkciótárolók létrehozásának előfeltétele a megfelelő hatókörkezelés.Ebben a kódmintában az ügyfél hatóköre a szolgáltatástár szintjén van.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )Regisztrálja az entitást
accounta funkciótárolóban.Hozzon létre egy entitást
account, amely rendelkezik az illesztőkulcsaccountIDtípusávalstring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
A tranzakciós funkciókészlet regisztrálása a funkciótárolóban
Ezzel a kóddal regisztrálhat egy funkciókészlet-objektumot a funkciótárolóban. Ezután újra felhasználhatja az objektumot, és egyszerűen megoszthatja azt. A szolgáltatáskészlet-objektumok regisztrálása felügyelt képességeket kínál, beleértve a verziószámozást és a materializálást. Az oktatóanyag-sorozat későbbi lépései a felügyelt képességekre vonatkoznak.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())A funkciótár felhasználói felületének megismerése
A funkciótárolók létrehozása és frissítései csak az SDK-val és a parancssori felülettel történhetnek. A felhasználói felületen kereshet vagy tallózhat a funkciótárban:
- Nyissa meg az Azure Machine Learning globális kezdőlapját.
- Válassza ki a funkciótárolókat a bal oldali panelen.
- Az akadálymentes funkciók listájában válassza ki az oktatóanyag korábbi részében létrehozott szolgáltatástárat.
A Storage Blob-adatolvasó szerepkör hozzáférésének biztosítása a felhasználói fiókhoz az offline áruházban
A Storage Blob Data Reader szerepkört hozzá kell rendelni a felhasználói fiókjához az offline áruházban. Ez biztosítja, hogy a felhasználói fiók beolvassa a materializált funkciók adatait az offline materializálási tárolóból.
Szerezze be a Microsoft Entra objektumazonosító értékét az Azure Portalról a felhasználói objektumazonosító megkeresése című szakaszban leírtak szerint.
Az offline materializációs tárolóval kapcsolatos információk a Funkciótár felhasználói felületén található Funkciótár áttekintési oldaláról szerezhető be. A tárfiók előfizetés-azonosítójának, a tárfiók erőforráscsoport-nevének és a tárfiók nevének értékeit az Offline materializálási tár kártyán találja.
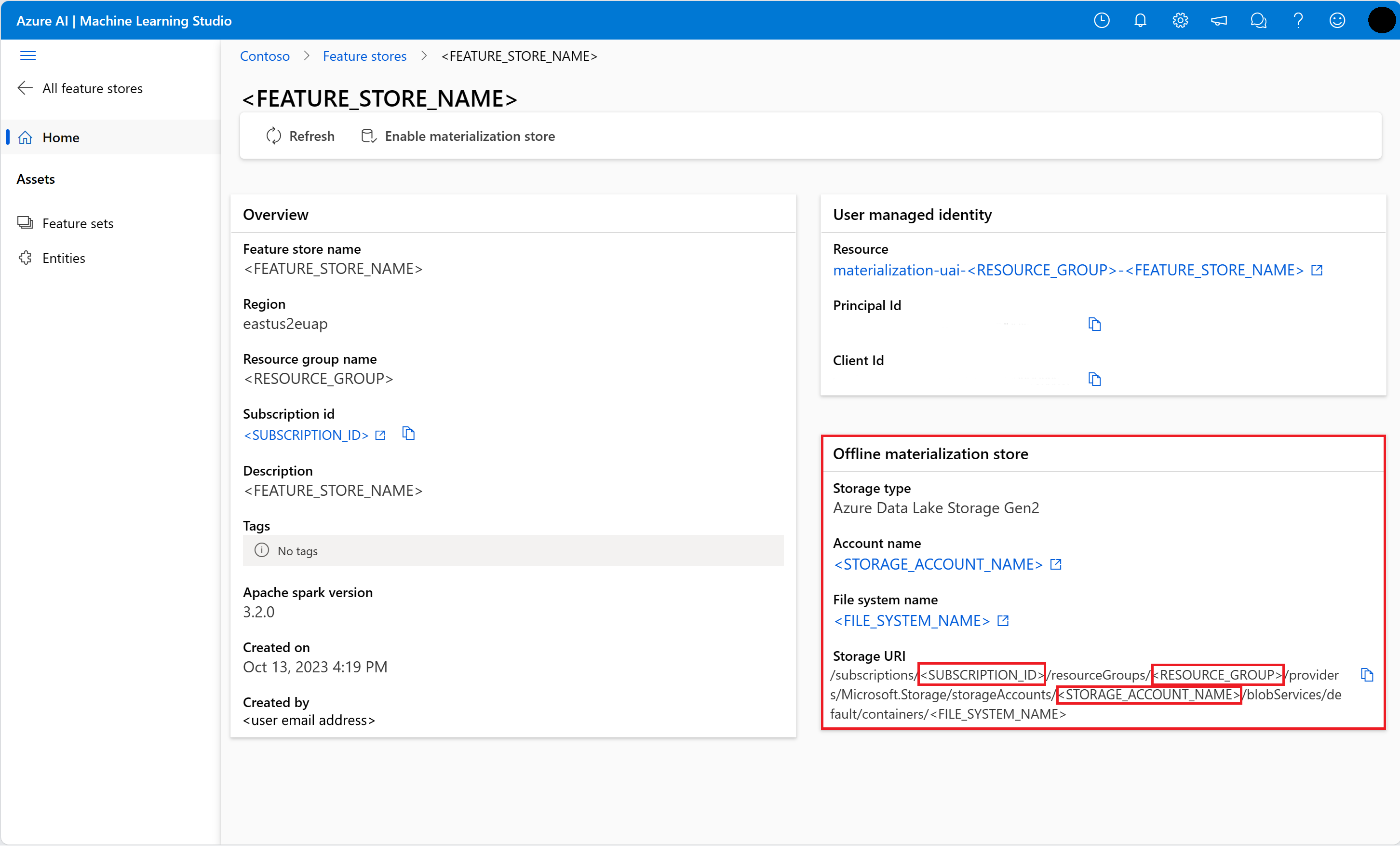
A hozzáférés-vezérléssel kapcsolatos további információkért látogasson el a hozzáférés-vezérlés kezelése kezelt funkciótár erőforráshoz.
Hajtsa végre ezt a kódcellát a szerepkör-hozzárendeléshez. Az engedélyek propagálásához szükség lehet egy kis időre.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Betanítási dataFrame létrehozása a regisztrált funkciókészlettel
Megfigyelési adatok betöltése.
A megfigyelési adatok általában a betanításhoz és a következtetéshez használt alapvető adatokat foglalják magukban. Ezek az adatok a funkcióadatokkal összekapcsolva hozzák létre a teljes betanítási adaterőforrást.
A megfigyelési adatok az esemény során rögzített adatok. Itt alapvető tranzakciós adatokkal rendelkezik, beleértve a tranzakcióazonosítót, a fiókazonosítót és a tranzakció összegének értékeit. Mivel betanításra használja, hozzáfűzött célváltozóval (is_fraud) is rendelkezik.
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueSzerezze be a regisztrált szolgáltatáskészletet, és sorolja fel annak funkcióit.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Válassza ki azokat a funkciókat, amelyek a betanítási adatok részévé válnak. Ezután a funkciótároló SDK-val hozza létre magát a betanítási adatokat.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueAz időponthoz kötött illesztés hozzáfűzi a funkciókat a betanítási adatokhoz.
Kapcsolat nélküli materializálás engedélyezése a transactions funkciókészleten
Miután engedélyezte a funkciókészletek materializálását, elvégezheti a visszatöltést. Ismétlődő materializálási feladatokat is ütemezhet. További információkért látogasson el a sorozat erőforrásának harmadik oktatóanyagára.
Spark.sql.shuffle.partitions beállítása a yaml-fájlban a funkcióadatok méretének megfelelően
A Spark-konfiguráció spark.sql.shuffle.partitions opcionális paraméter, amely befolyásolhatja a szolgáltatáskészlet offline tárolóba való létrehozásakor (naponta) létrehozott parquet-fájlok számát. Ennek a paraméternek az alapértelmezett értéke 200. Ajánlott eljárásként kerülje a sok kis parquet-fájl létrehozását. Ha az offline funkció lekérése lassúvá válik a funkciókészlet materializálása után, lépjen az offline áruház megfelelő mappájába, és ellenőrizze, hogy a probléma túl sok kis parquetfájlt tartalmaz-e (naponta), és ennek megfelelően állítsa be ennek a paraméternek az értékét.
Feljegyzés
A jegyzetfüzetben használt mintaadatok kicsik. Ezért ez a paraméter a featureset_asset_offline_enabled.yaml fájlban 1 értékre van állítva.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())A szolgáltatáskészlet-objektumot YAML-erőforrásként is mentheti.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)A funkciókészlet adatainak visszatöltése transactions
A korábban ismertetett módon a materializálás kiszámítja egy funkcióablak funkcióértékeit, és ezeket a kiszámított értékeket egy materializálási tárolóban tárolja. A funkciók materializálása növeli a számított értékek megbízhatóságát és rendelkezésre állását. Az összes funkció-lekérdezés most már a materializálási tároló értékeit használja. Ez a lépés egyszeri feltöltést hajt végre egy 18 hónapos funkcióablakban.
Feljegyzés
Előfordulhat, hogy meg kell határoznia egy háttérbetöltési adatablak értékét. Az ablaknak meg kell egyeznie a betanítási adatok ablakával. Ha például 18 hónapnyi adatot szeretne használni a betanításhoz, 18 hónapig le kell kérnie a funkciókat. Ez azt jelenti, hogy egy 18 hónapos időszakra vissza kell töltenie.
Ez a kódcella a definiált funkcióablak aktuális állapotának nincs vagy hiányos állapotával materializálja az adatokat.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Tipp.
- Az
timestamposzlopnak a formátumot kell követnieyyyy-MM-ddTHH:mm:ss.fffZ. - A
feature_window_start_timerészletesség másodpercrefeature_window_end_timekorlátozódik. Az objektumbandatetimemegadott minden ezredmásodperc figyelmen kívül lesz hagyva. - A materializálási feladat csak akkor lesz elküldve, ha a funkcióablak adatai megegyeznek a
data_statusbackfill feladat elküldésekor megadott adatokkal.
Mintaadatok nyomtatása a funkciókészletből. A kimeneti adatok azt mutatják, hogy az adatokat a materializálási tárolóból kérték le. A get_offline_features() metódus lekérte a betanítási és következtetési adatokat. Alapértelmezés szerint a materializálási tárolót is használja.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Az offline funkciók materializálásának további megismerése
A Materialization-feladatok felhasználói felületén megismerheti egy funkciókészlet funkció materializálási állapotát.
Nyissa meg az Azure Machine Learning globális kezdőlapját.
Válassza ki a funkciótárolókat a bal oldali panelen.
Az akadálymentes szolgáltatástárolók listájában válassza ki azt a funkciótárolót, amelyhez a visszatöltést végezte.
Válassza a Materialization jobs (Anyagosítási feladatok ) lapot.
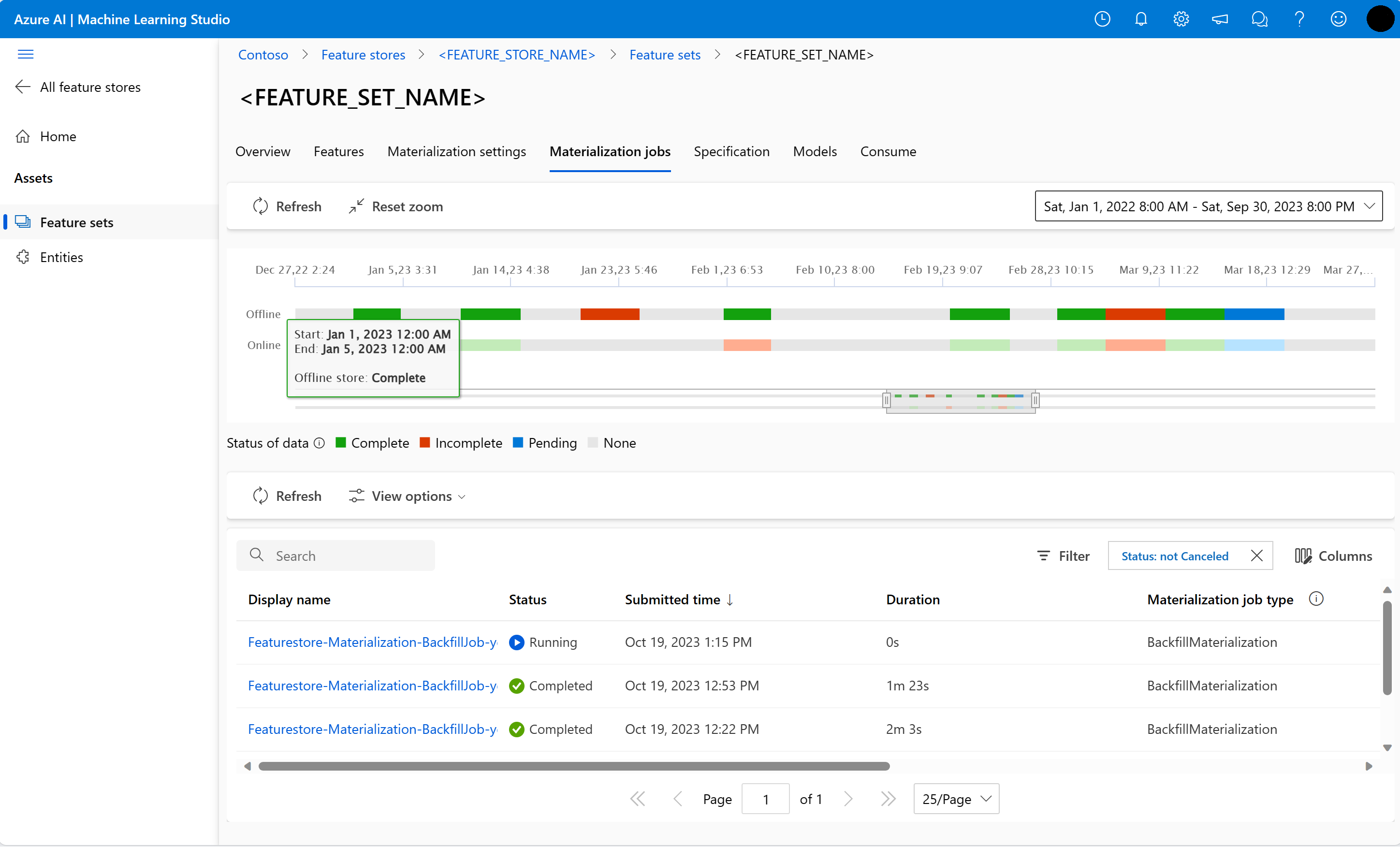

Az adat materializálási állapota lehet
- Kész (zöld)
- Hiányos (piros)
- Függőben (kék)
- Nincs (szürke)
Az adatintervallumok az adatok egybefüggő részét jelölik ugyanazzal az adatmegvalósítási állapottal. A korábbi pillanatképnek például 16 adatintervalluma van az offline materializálási tárolóban.
Az adatok legfeljebb 2000 adatintervallumot tartalmazhatnak. Ha az adatok több mint 2000 adatintervallumot tartalmaznak, hozzon létre egy új funkciókészlet-verziót.
Egyetlen háttérbetöltési feladatban több adatállapot (például
["None", "Incomplete"]) listáját is megadhatja.A visszatöltés során a rendszer minden olyan adatintervallumhoz új materializálási feladatot küld, amely a megadott funkcióablakba esik.
Ha egy materializálási feladat függőben van, vagy a feladat olyan adatintervallumban fut, amely még nem lett kitöltve, a rendszer nem küld el új feladatot az adott adatintervallumhoz.
Újrapróbálkozott egy sikertelen materializálási feladat.
Feljegyzés
Sikertelen materializálási feladat feladatazonosítójának lekérése:
- Lépjen a Materialization-feladatok felhasználói felületére a funkciókészlethez.
- Válassza ki egy adott feladat megjelenítendő nevét sikertelen állapottal.
- Keresse meg a feladatazonosítót a Feladat áttekintése lapon található Név tulajdonság alatt. A következővel
Featurestore-Materialization-kezdődik: .
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Offline materialization store frissítése
- Ha egy offline materializációs tárolót frissíteni kell a szolgáltatástár szintjén, akkor a funkciótároló összes funkciókészletének le kell tiltania az offline materializációt.
- Ha az offline materializálás le van tiltva egy szolgáltatáskészleten, az offline materializálási tárolóban már materializált adatok materializálási állapota alaphelyzetbe áll. Az alaphelyzetbe állítás olyan adatokat jelenít meg, amelyek már használhatatlanná váltak. Az offline materializálás engedélyezése után újra el kell küldenie a materializálási feladatokat.
Ez az oktatóanyag a betanítási adatokat a funkciótároló funkcióival, az engedélyezett materializálással az offline funkciótárolóba építette, és egy visszatöltést hajtott végre. Ezután modellbetanítást fog futtatni ezekkel a funkciókkal.
A fölöslegessé vált elemek eltávolítása
A sorozat ötödik oktatóanyaga az erőforrások törlését ismerteti.
Következő lépések
- Tekintse meg a következő oktatóanyagot a sorozatban: Modellek kísérletezése és betanítása funkciók használatával.
- További információ a funkciótár fogalmairól és az kezelt funkciótár legfelső szintű entitásairól.
- Ismerje meg a kezelt funkciótár identitás- és hozzáférés-vezérlését.
- Tekintse meg a kezelt funkciótár hibaelhárítási útmutatójában.
- Tekintse meg a YAML-referenciát.