Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure Table Storage egy olyan szolgáltatás, amely strukturált NoSQL-adatokat tárol a felhőben. Séma nélküli tárolót biztosít, ahol minden entitás egy kulccsal érhető el, és attribútumok készletét tartalmazza. Egyetlen tábla különböző tulajdonságokkal rendelkező entitásokat tartalmazhat, a tulajdonságok pedig különböző adattípusokból állhatnak.
Az Azure használatakor a megbízhatóság közös felelősség. A Microsoft számos lehetőséget kínál a rugalmasság és a helyreállítás támogatására. Ön a felelős azért, hogy megértse, hogyan működnek ezek a képességek az összes használt szolgáltatáson belül, és válassza ki azokat a képességeket, amelyekre szüksége van az üzleti célok és az üzemidő céljainak eléréséhez.
Ez a cikk azt ismerteti, hogyan teheti rugalmassá a Table Storage-t számos lehetséges kimaradás és probléma esetén, beleértve az átmeneti hibákat, a rendelkezésre állási zónák kimaradásait és a régiókimaradásokat. Azt is ismerteti, hogyan használható biztonsági másolatok más típusú problémákból való helyreállításra, és kiemeli a Table Storage szolgáltatásszint-szerződéssel (SLA) kapcsolatos legfontosabb információkat.
Megjegyzés:
A Table Storage az Azure Storage platform része. A Table Storage egyes funkciói számos Azure Storage-szolgáltatásban gyakoriak. Ebben a cikkben az Azure Storage vagy a Storage használatával hivatkozunk ezekre a gyakori képességekre.
A termelési üzembe helyezési javaslatok a megbízhatóság érdekében
Éles környezetek esetén hajtsa végre a következő műveleteket:
Engedélyezze a zónaredundáns tárolást (ZRS) a Table Storage-erőforrásokat tartalmazó tárfiókokhoz. A ZRS magasabb rendelkezésre állást biztosít az adatok szinkron replikálásával az elsődleges régió több rendelkezésre állási zónájában. Ez a replikáció védelmet nyújt a rendelkezésre állási zónák hibáival szemben.
Ha rugalmasságra van szüksége a régiókimaradásokkal szemben, és a tárfiók elsődleges régiója párosítva van, fontolja meg a georedundáns tárolás (GRS) engedélyezését az adatok aszinkron replikálásához a párosított régióba. A támogatott régiókban georedundáns tárolással (GZRS) kombinálhatja a georedundáns és a zónaredundáns tárolást.
Nagy léptékű éles számítási feladatokhoz, vagy ha magas rugalmassági követelményekkel rendelkezik, fontolja meg az Azure Cosmos DB for Table használatát. Az Azure Cosmos DB for Table kompatibilis a Table Storage-hoz írt alkalmazásokkal. Nagy léptékben támogatja az alacsony késésű olvasási és írási műveleteket, és rugalmas konzisztenciamodellekkel erős globális eloszlást biztosít több régió között. Emellett beépített biztonsági mentést és egyéb képességeket is biztosít, amelyek javítják az alkalmazás rugalmasságát és teljesítményét.
A megbízhatósági architektúra áttekintése
A Table Storage elosztott NoSQL-adatbázisként működik az Azure Storage platforminfrastruktúrájában. A szolgáltatás a táblaadatok több példányán keresztül biztosítja a redundanciát, és az adott redundanciamodell a tárfiók konfigurációjától függ.
A helyileg redundáns tárolás (LRS) a tárfiókokban lévő adatokat egy vagy több, a választott elsődleges régióban található Azure rendelkezésre állási zónába replikálja. Bár nincs lehetőség az előnyben részesített rendelkezésre állási zóna kiválasztására, az Azure áthelyezheti vagy kibővítheti az LRS-fiókokat a zónák között a terheléselosztás javítása érdekében. Nincs garancia arra, hogy az adatok el lesznek osztva a zónák között. A rendelkezésre állási zónákkal kapcsolatos további információkért lásd: Mik azok a rendelkezésre állási zónák?.

A zónaredundáns tárolás (ZRS), a georedundáns tárolás (GRS) és a georedundáns tárolás (GZRS) további védelmet nyújt. Ez a cikk részletesen ismerteti ezeket a beállításokat.
Rugalmasság átmeneti hibákhoz
Az átmeneti hibák rövid, időszakos meghibásodások a komponensekben. Gyakran előfordulnak elosztott környezetben, például a felhőben, és ezek a műveletek szokásos részei. Az átmeneti hibák rövid idő elteltével kijavítják magukat. Fontos, hogy az alkalmazások kezelni tudják az átmeneti hibákat, általában az érintett kérések újrapróbálásával.
Minden felhőalapú alkalmazásnak követnie kell az Azure átmeneti hibakezelési útmutatóját, amikor a felhőben üzemeltetett API-kkal, adatbázisokkal és egyéb összetevőkkel kommunikálnak. További információ: Átmeneti hibák kezelésére vonatkozó javaslatok.
A Table Storage-ügyfélkódtárak és az SDK-k beépített újrapróbálkozási szabályzatokat tartalmaznak, amelyek automatikusan kezelik a gyakori átmeneti hibákat, például a hálózati időtúllépéseket, az ideiglenes szolgáltatás elérhetetlenségét (HTTP 503), a szabályozási válaszokat (HTTP 429) és a partíciókiszolgáló túlterhelési feltételeit. Amikor az alkalmazás ezeket az átmeneti feltételeket tapasztalja, az ügyfélkódtárak automatikusan újrapróbálkoznak az exponenciális háttérstratégiák használatával.
Ha a Table Storage használatakor hatékonyan szeretné kezelni az átmeneti hibákat, hajtsa végre a következő műveleteket:
Konfiguráljon megfelelő időtúllépéseket a Table Storage-ügyfélben a válaszkészség és az ideiglenes lassulások rugalmasságának egyensúlya érdekében. Az Azure Storage-ügyfélkönyvtárak alapértelmezett időtúllépési beállításai általában a legtöbb forgatókönyvhöz alkalmasak.
Exponenciális visszalépés implementálása az újrapróbálkozási szabályzatokhoz, különösen akkor, ha az alkalmazás HTTP 503-kiszolgáló foglalt vagy HTTP 500-művelet időtúllépési hibákba ütközik. A Table Storage szabályozhatja az egyes partíciók gyakori elérésűvé válását vagy a tárfiókok korlátainak megközelítését.
Partícióérzékeny újrapróbálkozásos logika tervezése nagy léptékű alkalmazásokban. A partícióérzékeny újrapróbálkozási logika egy fejlettebb megközelítés, amely figyelembe veszi a Table Storage particionált architektúráját, és több partíció között osztja el a műveleteket, hogy csökkentse az egyes partíciókiszolgálók szabályozásának valószínűségét.
A Table Storage architektúrájáról és a rugalmas és nagy léptékű alkalmazások tervezéséről további információt a Table Storage teljesítmény- és méretezhetőségi ellenőrzőlistájában talál.
Rugalmasság a rendelkezésre állási zóna hibáival szemben
A rendelkezésre állási zónák fizikailag különálló adatközpont-csoportok egy Azure-régión belül. Ha egy zóna meghibásodik, a szolgáltatások a fennmaradó zónák egyikére is át tudnak adni feladatokat.
A Table Storage zónaredundáns, amikor ZRS-konfigurációval telepíti. A helyileg redundáns tárolástól (LRS) eltérően a ZRS garantálja, hogy az Azure szinkron módon replikálja a táblaadatokat több rendelkezésre állási zónában. Ez a konfiguráció biztosítja, hogy a táblák akkor is elérhetők maradjanak, ha egy teljes rendelkezésre állási zóna elérhetetlenné válik. Minden írási műveletet több zónában kell nyugtázni, mielőtt a szolgáltatás befejezi az írást, ami erős konzisztenciagaranciát biztosít.
A zónaredundancia engedélyezve van a tárfiók szintjén, és az adott fiókon belüli összes Table Storage-erőforrásra vonatkozik. Mivel a beállítás a teljes tárfiókra vonatkozik, nem konfigurálhat különálló entitásokat a különböző redundanciaszintekhez. Ha egy rendelkezésre állási zóna üzemkimaradást tapasztal, az Azure Storage automatikusan átirányítja a kéréseket kifogástalan állapotú zónákba anélkül, hogy önnek vagy az alkalmazásának beavatkozására lenne szükség.

Requirements
- Régiótámogatás: Zónaredundáns Azure Storage-fiókokat bármely olyan régióban üzembe helyezhet, amely támogatja a rendelkezésre állási zónákat.
- Tárfióktípusok: A ZRS table storage-hoz való engedélyezéséhez standard általános célú v2-tárfiókot kell használnia. A prémium szintű tárfiókok nem támogatják a Table Storage-t.
Költség
A zónaredundáns tárolás (ZRS) engedélyezésekor a többletreplikációs és tárolási többletterhelés miatt a helyileg redundáns tárolástól (LRS) eltérő díjat kell fizetnie.
Részletes díjszabási információkért lásd a Table Storage díjszabását.
A rendelkezésre állási zóna támogatásának konfigurálása
Zónaredundáns tárfiók és tábla létrehozása:
Tárfiók létrehozása. A ZRS, a GZRS vagy az olvasási hozzáférésű georedundáns tárolás (RA-GZRS) lehetőséget válassza redundanciabeállításként.
Replikáció típusának módosítása. A meglévő tárfiók zónaredundáns tárolásra (ZRS) való módosításáról, valamint a konfigurációs beállításokról és követelményekről a tárfiók replikálásának módosítása című témakörben olvashat.
Zónaredundancia letiltása. A ZRS-fiókok konvertálása nem zónakonfigurációra, például helyileg redundáns tárolásra (LRS) ugyanazzal a redundanciakonfiguráció-módosítási folyamattal.
Viselkedés, ha minden zóna kifogástalan
Ez a szakasz azt ismerteti, hogy mire számíthat, ha egy Table Storage-fiók zónaredundanciára van konfigurálva, és az összes rendelkezésre állási zóna működőképes.
Forgalomirányítás zónák között: A zónaredundáns tárolással (ZRS) rendelkező Azure Storage automatikusan osztja el a kéréseket több rendelkezésre állási zónában lévő tárolófürtök között. A forgalomelosztás transzparens az alkalmazások számára, és nem igényel ügyféloldali konfigurációt.
Adatreplikálás zónák között: A ZRS-be írt összes írási művelet szinkron módon replikálódik a régió összes rendelkezésre állási zónája között. Az adatok feltöltése vagy módosításakor a művelet nem tekinthető befejezettnek, amíg az adatok sikeresen nem replikálódnak az összes rendelkezésre állási zónában. Ez a szinkron replikáció erős konzisztenciát és nulla adatvesztést biztosít a zónahibák során.
Viselkedés zónahiba esetén
Amikor egy rendelkezésre állási zóna elérhetetlenné válik, a Table Storage automatikusan kezeli a feladatátvételi folyamatot az alábbi viselkedésekkel válaszolva:
- Észlelés és válasz: A Microsoft automatikusan észleli a zónahibákat, és helyreállítási folyamatokat kezdeményez. A zónaredundáns tárfiókokhoz (ZRS) nincs szükség ügyfélműveletre. Ha egy zóna elérhetetlenné válik, az Azure olyan hálózati frissítéseket hajt végre, mint a tartománynévrendszer (DNS) újrapontozása.
- Értesítés: A Microsoft nem értesíti automatikusan, ha egy zóna le van omlva. Az Azure Resource Health használatával azonban figyelheti az egyes erőforrások állapotát, és beállíthat Resource Health-riasztásokat a problémákról való értesítéshez. Az Azure Service Health használatával is megismerheti a szolgáltatás általános állapotát, beleértve a zónahibákat is, és beállíthat Service Health-riasztásokat a problémákról való értesítéshez.
Aktív kérések: Előfordulhat, hogy a repülés közbeni kérések a helyreállítási folyamat során elvesznek, és újra meg kell próbálkozni. Az alkalmazásoknak újrapróbálkozásos logikát kell implementálniuk az átmeneti megszakítások kezeléséhez.
Várható adatvesztés: A zónahibák során nem történik adatvesztés, mert az adatok szinkron módon replikálódnak több zónára az írási műveletek befejezése előtt.
Várható állásidő: Az automatikus helyreállítás során a forgalom kifogástalan állapotú zónákba való átirányítása során általában néhány másodpercnyi állásidő fordulhat elő. A ZRS-alkalmazások tervezésekor kövesse az átmeneti hibakezelés gyakorlatát, beleértve az újrapróbálkozási szabályzatok exponenciális visszalépéssel történő implementálását is.
- Forgalom átirányítása: Ha egy zóna elérhetetlenné válik, az Azure olyan hálózati frissítéseket hajt végre, mint a tartománynévrendszer (DNS) újrapontozása, hogy a kérések a fennmaradó kifogástalan rendelkezésre állási zónákba legyenek irányítva. A szolgáltatás teljes funkcionalitást biztosít az kifogástalan állapotú zónák használatával, és nem igényel ügyfélintervenciót.
Zóna helyreállítása
A sikertelen rendelkezésre állási zóna helyreállításakor az Azure Storage automatikusan visszaállítja a normál műveleteket az összes rendelkezésre állási zónában. A szolgáltatás automatikusan biztosítja az adatok konzisztenciáját a kimaradás időszakában végrehajtott műveletek szinkronizálásával.
Zónahibák tesztelése
Zónaredundáns tárolás (ZRS) használatakor az Azure Storage automatikusan kezeli a replikációt, a forgalomirányítást és a zónaleállítási válaszokat. Mivel ez a szolgáltatás teljes mértékben felügyelt, nem kell kezdeményeznie vagy ellenőriznie a rendelkezésre állási zónák meghibásodási folyamatait.
Rugalmasság régiószintű hibákhoz
Az Azure Storage, többek között az Azure Blob Storage, az Azure Files, az Azure Table Storage és az Azure Queue Storage, számos georedundanciát és feladatátvételi képességet biztosít a különböző követelményeknek megfelelően.
Fontos
A georedundáns tárolás (GRS) csak az Azure párosított régióiban működik. Ha a tárfiók régiója nincs párosítva, fontolja meg az egyéni többrégiós megoldások használatát a rugalmasság érdekében.
Georedundáns tárolás párosított régiókhoz
Az Azure Storage több típusú GRS-t biztosít párosított régiókban. Bármelyik típusú GRS-t is használja, a másodlagos régióban lévő adatok mindig helyileg redundáns tárolással (LRS) replikálódnak. Ez a megközelítés védelmet nyújt a másodlagos régión belüli hardverhibák ellen.
A GRS támogatást nyújt az Azure párosított régióba történő tervezett és nem tervezett feladatátvételekhez, ha az elsődleges régióban kimaradás történik. A GRS aszinkron módon replikálja az adatokat az elsődleges régióból a párosított régióba.
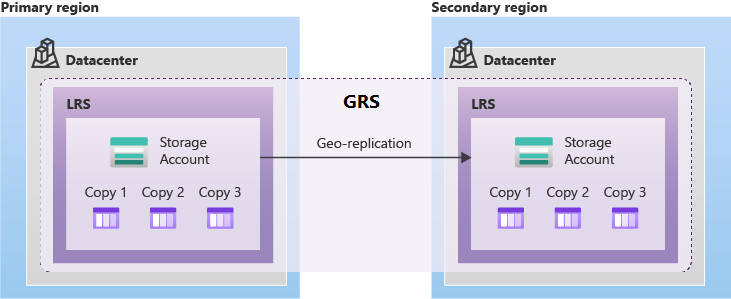
A geozónaredundáns tárolás (GZRS) több rendelkezésre állási zónában replikálja az adatokat az elsődleges régióban és a párosított régióban.
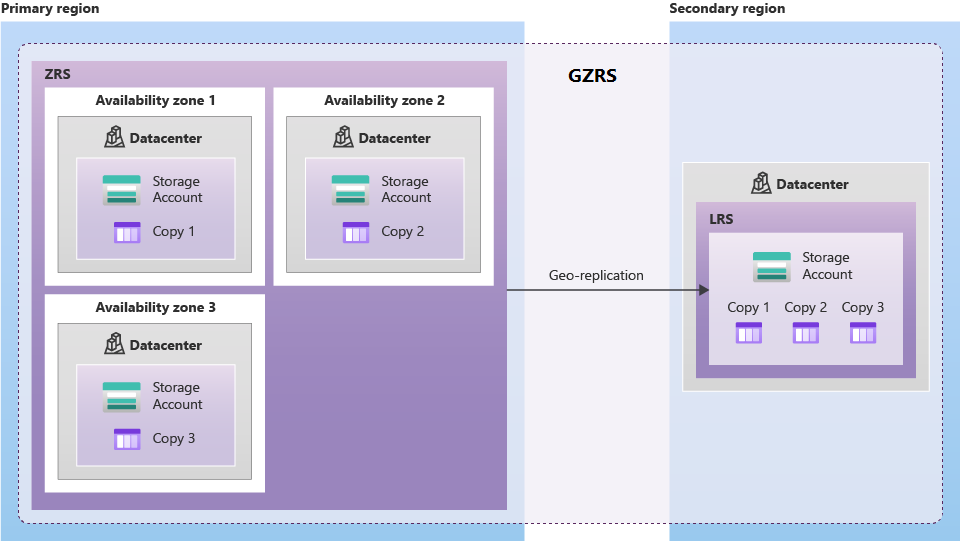


- Az olvasási hozzáférésű georedundáns tárolás (RA-GRS) és az olvasási hozzáférésű geo-zónaredundáns tárolás (RA-GZRS) kibővíti a georedundáns tárolást (GRS) és a georedundáns tárolást (GZRS), a másodlagos végponthoz való olvasási hozzáférés további előnye mellett. Ezek a lehetőségek ideálisak a magas rendelkezésre állású, üzletileg kritikus fontosságú alkalmazásokhoz tervezett alkalmazásokhoz. Abban a valószínűtlen esetben, ha az elsődleges végpont leállást tapasztal, a másodlagos régióhoz való olvasási hozzáférésre konfigurált alkalmazások továbbra is működhetnek.
Átállás típusai
Az Azure Storage három feladatátvételi típust támogat különböző helyzetekben.
Ügyfél által felügyelt nem tervezett feladatátvétel: Ha régiószintű tárolási hiba történik az elsődleges régióban, ön kezdeményezi a helyreállítást.
Ügyfél által felügyelt tervezett feladatátvétel: Ön a felelős a helyreállítás elindításáért, ha a megoldás egy másik része meghibásodik az elsődleges régióban, és a teljes megoldást át kell állítania egy másodlagos régióra. Tervezett feladatátvételt akkor használjon, ha a tárolás továbbra is működőképes marad az elsődleges régióban, de a teljes megoldást egy másodlagos régióra kell átvennie, például a megfelelőségi és naplózási követelmények biztosítására tervezett vészhelyreállítási gyakorlatokhoz.
Microsoft által felügyelt feladatátvétel: Kivételes körülmények között a Microsoft feladatátvételt kezdeményezhet az adott régióban található összes georedundáns tárfiók (GRS) esetében. A Microsoft által felügyelt feladatátvétel azonban végső megoldás, és várhatóan csak hosszabb üzemkimaradás után lesz végrehajtva. Nem szabad a Microsoft által felügyelt feladatátvételre támaszkodnia.
A GRS-fiókok ezen feladatátvételi típusok bármelyikét használhatják. Nem kell előre konfigurálnia egy tárfiókot a feladatátvételi típusok előzetes használatához.
Requirements
Régiótámogatás: Az Azure Storage georedundáns konfigurációi az Azure párosított régióit használják a másodlagos régiók replikáláshoz. A másodlagos régió automatikusan az elsődleges régió kiválasztása alapján lesz meghatározva, és nem szabható testre. Az Azure párosított régióinak teljes listáját az Azure-régiók listájában találja.
Ha a tárfiók régiója nincs párosítva, fontolja meg az egyéni többrégiós megoldások használatát a rugalmasság érdekében.
- Tárfióktípusok: A georedundáns tárolás (GRS) és az ügyfél által kezdeményezett feladatátvétel és feladat-visszavétel minden olyan Azure-párosított régióban elérhető, amely támogatja az általános célú v2 Azure Storage-fiókokat.
Megfontolások
A többrégiós Table Storage megvalósításakor vegye figyelembe a következő fontos tényezőket:
Aszinkron replikáció késése: A másodlagos régióba történő adatreplikálás aszinkron, ami azt jelenti, hogy az adatok elsődleges régióba történő írása és a másodlagos régióban való elérhetővé válása között eltérés van. Ez az késés potenciális adatvesztést okozhat, ha az elsődleges régió hibája a legutóbbi adatok replikálása előtt következik be. Az adatvesztést a helyreállítási pont célkitűzése (RPO) méri. A replikáció késése várhatóan kevesebb, mint 15 perc, de ez az idő becslés, és nem garantált.
A Last Sync Time tulajdonságban ellenőrizheti, hogy mennyi adat veszhet el, ha a tárfiók nem tervezett feladatátvételt futtat.
Másodlagos régióhoz való hozzáférés: A georedundáns tárolás (GRS) és a geozónára redundáns tárolás (GZRS) konfigurációk esetén a másodlagos régió nem érhető el olvasásra, amíg feladatátvétel nem történik.
Az olvasási hozzáférésű georedundáns tárolás (RA-GRS) és az olvasási hozzáférésű geo-zónaredundáns tárolás (RA-GZRS) konfigurációi olvasási hozzáférést biztosítanak a másodlagos régióhoz a normál műveletek során, de az aszinkron replikáció késése miatt kissé elavult adatokat adhatnak vissza.
- Funkciókorlátozások: Egyes Azure Storage-funkciók nem támogatottak, vagy korlátozottak a georedundáns tárolás (GRS) vagy az ügyfél által felügyelt feladatátvétel használatakor. A georedundancia megvalósítása előtt tekintse át a funkciók kompatibilitását .
Költség
A többrégiós Azure Storage-fiókkonfigurációk további költségekkel járnak a régiók közötti replikációhoz és a másodlagos régióban történő tároláshoz. Az Azure-régiók közötti adatátvitelt a standard régiók közötti sávszélesség alapján számítjuk fel.
Részletes díjszabási információkért lásd a Table Storage díjszabását.
Többrégiós támogatás konfigurálása
- Hozzon létre egy új georedundáns tárfiókot (GRS). GRS-fiók létrehozásához tekintse meg a Tárfiók létrehozása című témakört , és válassza a GRS, az olvasási hozzáférésű georedundáns tárolás (RA-GRS), a geo-zónaredundáns tárolás (GZRS) vagy az olvasási hozzáférésű geo-zónaredundáns tárolás (RA-GZRS) lehetőséget a fiók létrehozása során.
Georedundancia engedélyezése meglévő tárfiókon. Ha egy meglévő tárfiókot georedundáns tárolóvá (GRS) szeretne konvertálni, olvassa el a tárfiók replikálás módjának módosítása című témakört.
Figyelmeztetés
Miután a fiók georedundanciára van konfigurálva, jelentős ideig tarthat, amíg az új elsődleges régióban lévő meglévő adatok teljes mértékben át lesznek másolva az új másodlagos régióba.
A jelentős adatvesztés elkerülése érdekében ellenőrizze a Legutóbbi szinkronizálási idő tulajdonság értékét, mielőtt nem tervezett feladatátvételt kezdeményez. A lehetséges adatvesztés kiértékeléséhez hasonlítsa össze az utolsó szinkronizálási időt az adatok új elsődleges régióba való írásának utolsó időpontjával.
Georedundancia letiltása. A GRS-fiókokat konvertálja vissza egyrégiós konfigurációkká, például helyileg redundáns tárolásra (LRS) vagy zónaredundáns tárolásra (ZRS) ugyanazzal a redundanciakonfiguráció-módosítási folyamattal.
Viselkedés, ha minden régió kifogástalan
Ez a szakasz azt ismerteti, hogy mire számíthat, ha egy tárfiók georedundanciára van konfigurálva, és minden régió működőképes.
Forgalomirányítás régiók között: Az Azure Storage aktív-passzív megközelítést használ, ahol minden írási művelet és a legtöbb olvasási művelet az elsődleges régióba lesz irányítva.
Az olvasási hozzáférésű georedundáns tárolás (RA-GRS) és az olvasási hozzáférésű geo-zónaredundáns tárolás (RA-GZRS) konfigurációi esetében az alkalmazások opcionálisan olvashatnak a másodlagos régióból a másodlagos végpont eléréséhez. Ez a megközelítés explicit alkalmazáskonfigurációt igényel, és nem automatikus. Emellett az aszinkron replikáció késése miatt a másodlagos régió adatai kissé elavultak lehetnek.
Régiók közötti adatreplikálás: Az írási műveletek először az elsődleges régióhoz lesznek lekötve a következő konfigurált redundanciatípusok használatával:
- Helyileg redundáns tárolás (LRS) georedundáns tároláshoz (GRS) és RA-GRS
- Zónaredundáns tárolás (ZRS) georedundáns tároláshoz (GZRS) és RA-GZRS
Az elsődleges régió sikeres befejezése után az adatok aszinkron módon replikálódnak arra a másodlagos régióra, ahol az LRS használatával vannak tárolva.
A régiók közötti replikáció aszinkron jellege azt jelenti, hogy az adatok elsődleges régióba való írása és a másodlagos régióban való rendelkezésre állása között általában késés áll fenn. A replikációs időt az Utolsó szinkronizálási idő tulajdonság használatával figyelheti.
Viselkedés régióhiba esetén
Ez a szakasz azt ismerteti, hogy mire számíthat, ha egy tárfiók georedundanciára van konfigurálva, és kimaradás történik az elsődleges régióban.
Ügyfél által felügyelt feladatátvétel (nem tervezett): Nem tervezett feladatátvételt használjon, ha az elsődleges régióban nem érhető el a tároló.
Észlelés és válasz: Abban a valószínűtlen esetben, ha a tárfiók nem érhető el az elsődleges régióban, érdemes lehet kezdeményezni egy ügyfél által felügyelt, nem tervezett feladatátvételt. A döntés meghozatalához vegye figyelembe a következő tényezőket:
Azt jelzi, hogy az Azure Resource Health problémákat mutat-e az elsődleges régió tárfiókjához való hozzáféréssel kapcsolatban
Azt jelzi, hogy a Microsoft javasolja-e a feladatátvételt egy másik régióba
Figyelmeztetés
A nem tervezett feladatátvétel adatvesztést okozhat. Mielőtt elindít egy ügyfél által felügyelt feladatátvételt, döntse el, hogy a szolgáltatás visszaállítása indokolja-e az adatvesztés kockázatát.
Értesítés: A Microsoft nem értesíti automatikusan, ha egy régió leáll. Azonban:
Az Azure Resource Health használatával figyelheti az egyes erőforrások állapotát, és beállíthat Resource Health-riasztásokat a problémákról való értesítéshez.
Az Azure Service Health használatával megismerheti a szolgáltatás általános állapotát, beleértve a régióhibákat is, és beállíthat Service Health-riasztásokat a problémákról való értesítéshez.
Aktív kérések: A feladatátvételi folyamat során mind az elsődleges, mind a másodlagos tárfiók végpontja ideiglenesen elérhetetlenné válik mind az olvasás, mind az írás esetében. Előfordulhat, hogy az aktív kérések elvethetők, és az ügyfélalkalmazásoknak újra kell próbálkoznia a feladatátvétel befejezése után.
Várható adatvesztés: Az adatvesztés gyakori a nem tervezett feladatátvétel során az aszinkron replikáció késése miatt, ami azt jelenti, hogy a legutóbbi írások nem replikálhatók. A Legutóbbi szinkronizálási idő tulajdonságban ellenőrizheti, hogy mennyi adat veszhet el egy nem tervezett feladatátvétel során. A várt adatvesztést gyakran helyreállítási pont célkitűzésnek (RPO) is nevezik. Az RPO általában kisebb, mint 15 perc, de ezt az időt nem garantálják.
Várható állásidő: A várható állásidőt gyakran helyreállítási időkorlátnak (RTO) is nevezik. Az ügyfél által felügyelt feladatátvétel általában 60 percen belül befejeződik a fiók méretétől és összetettségétől függően.
Forgalom átirányítása: A feladatátvétel befejeződése után az Azure automatikusan frissíti a tárfiók végpontjait, hogy az alkalmazásokat ne kelljen újrakonfigurálni. Ha az alkalmazás gyorsítótárazza a tartománynévrendszer (DNS) bejegyzéseit, szükség lehet a gyorsítótár törlésére annak biztosítása érdekében, hogy az alkalmazás forgalmat küldjön az új elsődleges régióba.
Feladatátvétel utáni konfiguráció: A nem tervezett feladatátvétel befejezése után a célrégióban lévő tárfiók a helyileg redundáns tárolási (LRS) szintet használja. Ha újra georeplikálásra van szüksége, újra engedélyeznie kell a georedundáns tárolást (GRS), és meg kell várnia, amíg az adatok replikálódnak az új másodlagos régióba.
További információ az ügyfél által felügyelt feladatátvétel kezdeményezéséről: Hogyan működik az ügyfél által felügyelt (nem tervezett) feladatátvétel , és hogyan kezdeményezhet tárfiók feladatátvételt.
Ügyfél által felügyelt feladatátvétel (tervezett): Tervezett feladatátvételt akkor használjon, ha a tárolás továbbra is működőképes marad az elsődleges régióban, de más okból át kell adnia a teljes megoldást egy másodlagos régióba. Előfordulhat például, hogy egy másik Azure-szolgáltatás problémát tapasztal, és át kell váltania egy másodlagos régió használatára a teljes megoldáshoz. Vagy használhatja a tervezett feladatátvételt katasztrófa utáni helyreállítási (DR) próbafuttatás elvégzésére megfelelőségi és auditálási célokra.
Észlelés és válasz: Ön a felelős az automatikus átállásról való döntésért. Ezt a döntést általában akkor hozod meg, ha régiók közötti feladatátvételre van szükség, annak ellenére, hogy a tárfiók kifogástalan állapotú. Előfordulhat például, hogy feladatátvételt indít el, ha egy másik alkalmazásösszetevő jelentős leállását nem tudja helyreállítani az elsődleges régióban.
Értesítés: A Microsoft nem értesíti automatikusan, ha egy régió leáll. Azonban:
Az Azure Resource Health használatával figyelheti az egyes erőforrások állapotát, és beállíthat Resource Health-riasztásokat a problémákról való értesítéshez.
Az Azure Service Health használatával megismerheti a szolgáltatás általános állapotát, beleértve a régióhibákat is, és beállíthat Service Health-riasztásokat a problémákról való értesítéshez.
Aktív kérések: A feladatátvételi folyamat során mind az elsődleges, mind a másodlagos tárfiók végpontja ideiglenesen elérhetetlenné válik mind az olvasás, mind az írás esetében. Előfordulhat, hogy az aktív kérések elvethetők, és az ügyfélalkalmazásoknak újra kell próbálkoznia a feladatátvétel befejezése után.
Várható adatvesztés: Nem várható adatvesztés, mert a feladatátvételi folyamat csak az összes adat szinkronizálása után fejeződik be, ami nulla RPO-t eredményez.
Várható állásidő: A feladatátvétel általában 60 percen belül fejeződik be, ami azt jelenti, hogy a várt RTO 60 perc, a fiók méretétől és összetettségétől függően. A feladatátvételi folyamat során mind az elsődleges, mind a másodlagos tárfiók végpontja ideiglenesen elérhetetlenné válik mind az olvasás, mind az írás esetében.
Forgalom átirányítása: A feladatátvétel befejeződése után az Azure automatikusan frissíti a tárfiók végpontjait, hogy az alkalmazásokat ne kelljen újrakonfigurálni. Ha az alkalmazás gyorsítótárazza a DNS-bejegyzéseket, szükség lehet a gyorsítótár törlésére annak biztosítása érdekében, hogy az alkalmazás forgalmat küldjön az új elsődleges régióba.
Feladatátvétel utáni konfiguráció: A tervezett feladatátvétel befejezése után a célrégióban lévő tárfiók továbbra is georeplikált lesz, és a GRS-szinten marad.
Az ügyfél által felügyelt feladatátvétel elindításáról további információt az ügyfél által felügyelt (tervezett) feladatátvétel működése és a tárfiók feladatátvételének kezdeményezése című témakörben talál.
Microsoft által felügyelt feladatátvétel: Olyan súlyos katasztrófa esetén, amikor a Microsoft megállapítja, hogy az elsődleges régió véglegesen helyreállíthatatlan, automatikus feladatátvételt kezdeményezhet a másodlagos régióba. A Microsoft kezeli a teljes folyamatot, és nincs szükség ügyfélműveletre. A feladatátvétel előtt eltelt idő a katasztrófa súlyosságától és a helyzet értékeléséhez szükséges időtől függ.
Értesítés: A Microsoft nem értesíti automatikusan, ha egy régió leáll. Azonban:
Az Azure Resource Health használatával figyelheti az egyes erőforrások állapotát, és beállíthat Resource Health-riasztásokat a problémákról való értesítéshez.
Az Azure Service Health használatával megismerheti a szolgáltatás általános állapotát, beleértve a régióhibákat is, és beállíthat Service Health-riasztásokat a problémákról való értesítéshez.
Fontos
Használja az ügyfél által felügyelt feladatátvételi lehetőségeket a DR-csomagok fejlesztéséhez, teszteléséhez és implementálásához. Ne támaszkodhat a Microsoft által felügyelt feladatátvételre, amely csak szélsőséges körülmények között használható. A Microsoft által felügyelt feladatátvételt valószínűleg egy teljes régióban kezdeményezik. Nem kezdeményezhető egyéni tárfiókok, előfizetések vagy ügyfelek számára. Az átváltás különböző időpontokban történhet a különböző Azure-szolgáltatások esetében. Javasoljuk, hogy az ügyfél által felügyelt feladatátvételt használja.
Régió helyreállítása
A feladat-visszavételi folyamat jelentősen eltér a Microsoft által felügyelt és az ügyfél által felügyelt feladatátvételi forgatókönyvek között.
Ügyfél által felügyelt feladatátvétel (nem tervezett): A nem tervezett feladatátvétel után a tárfiók helyileg redundáns tárolással (LRS) van konfigurálva. A feladat-visszavételhez újra létre kell hoznia a georedundáns tárolási (GRS) kapcsolatot, és várnia kell az adatok replikálására.
Ügyfél által felügyelt feladatátvétel (tervezett): A tervezett feladatátvétel után a tárfiók georeplikált marad. Kezdeményezhet egy másik, ügyfél által felügyelt feladatátvételt az eredeti elsődleges régióba való visszavételhez. Ugyanezek a feladatátvételi szempontok érvényesek.
Microsoft által felügyelt feladatátvétel: Ha a Microsoft feladatátvételt kezdeményez, valószínű, hogy jelentős katasztrófa történt az elsődleges régióban, és előfordulhat, hogy az elsődleges régió nem lesz helyreállítható. Az ütemtervek vagy helyreállítási tervek a regionális katasztrófa- és helyreállítási erőfeszítések mértékétől függenek. Kísérje figyelemmel az Azure Service Health-kommunikációt a részletekért.
Régióhibák tesztelése
A vészhelyreállítási eljárások teszteléséhez regionális hibákat szimulálhat.
Tervezett feladatátvételi tesztelés: A georedundáns tárolási (GRS-) fiókok esetében a karbantartási időszakokban tervezett feladatátvételi műveleteket hajthat végre a teljes feladatátvételi és feladat-visszavételi folyamat teszteléséhez. A tervezett feladatátvétel nem igényel adatvesztést, de a feladatátvétel és a feladat-visszavétel során is leáll.
Másodlagos végpont tesztelése: Az olvasási hozzáférésű georedundáns tárolás (RA-GRS) és az olvasási hozzáférésű geo-zónaredundáns tárolás (RA-GZRS) konfigurációihoz rendszeresen tesztelje az olvasási műveleteket a másodlagos végponton, hogy az alkalmazás sikeresen be tudja olvasni az adatokat a másodlagos régióból.
Egyéni többrégiós megoldások a rugalmasság érdekében
Előfordulhat, hogy az Azure Storage régióközi feladatátvételi képességei a következő okok miatt nem megfelelőek:
A tárfiók egy nem párosított régióban található.
Az üzleti üzemidejű célok nem teljesülnek a beépített feladatátvételi lehetőségek által biztosított helyreállítási idő vagy adatvesztés miatt.
Olyan régióba kell átváltania, amely nem képezi párját az elsődleges régiónak.
Aktív/aktív konfigurációra van szükség a régiók között.
Ez a szakasz magas szintű áttekintést nyújt néhány megfontolandó megközelítésről. Az Azure Storage többrégiós üzembehelyezési topológiáinak átfogó áttekintése nem tartozik a cikk hatókörébe.
Megjegyzés:
A Table Storage használatára készült alkalmazások esetében fontolja meg az Azure Cosmos DB for Table használatát. Az Azure Cosmos DB for Table támogatja a fejlett többrégiós követelményeket, beleértve a nem támogatott régiók támogatását is. A Table Storage-hoz készült alkalmazásokkal való kompatibilitásra is tervezték.
Az Azure Storage több régióban is üzembe helyezhető, ha minden régióban külön tárfiókokat használ. Ez a megközelítés rugalmasságot biztosít a régiók kiválasztásában, a nem használt régiók használatát, valamint részletesebb vezérlést biztosít a replikáció időzítése és az adatok konzisztenciája felett. Ha több tárfiókot implementál régiók között, régiók közötti adatreplikálást kell konfigurálnia, terheléselosztási és feladatátvételi szabályzatokat kell implementálnia, valamint biztosítania kell az adatok régiók közötti konzisztenciáját.
A Table Storage esetében a többfiókos megközelítés megköveteli az adateloszlás kezelését, a táblák régiók közötti szinkronizálásának kezelését, beleértve az ütközések feloldását és az egyéni feladatátvételi logika implementálását.
Biztonsági mentés és visszaállítás
A Table Storage nem nyújt hagyományos biztonsági mentési képességeket, például az időponthoz kötött visszaállítást (PITR). A táblaadatokhoz azonban egyéni biztonsági mentési stratégiákat is implementálhat.
Ha beépített biztonsági mentési képességekre van szüksége, fontolja meg az Azure Cosmos DB for Tablere való áttérést, amely támogatja mind az időszakos, mind a folyamatos biztonsági mentéseket. További információ: Online biztonsági mentés és igény szerinti adat-visszaállítás az Azure Cosmos DB-ben.
Olyan forgatókönyvek esetén, amelyek adatmentést igényelnek a Table Storage-ból, vegye figyelembe az alábbi módszereket:
Exportálás az Azure Data Factory használatával. A Table Storage Azure Data Factory-összekötőjével exportálhatja az entitásokat egy másik helyre. Például biztonsági másolatot készíthet minden entitásról egy Azure Blob Storage-ban tárolt JSON-fájlra.
Alkalmazásszintű biztonsági mentés végrehajtása. Egyéni biztonsági mentési logikát valósíthat meg az alkalmazásokon belül a kritikus táblaentitások exportálásához más tárolási szolgáltatásokba, például az Azure SQL Database-be vagy az Azure Cosmos DB-be a robusztusabb biztonsági mentési és visszaállítási képességek érdekében.
A Table Storage biztonsági mentési stratégiáinak tervezésekor vegye figyelembe az adatok particionált jellegét, és győződjön meg arról, hogy a biztonsági mentési folyamatok több partíció párhuzamos feldolgozásával hatékonyan kezelhetik a nagy táblákat.
A legtöbb megoldás esetében nem szabad kizárólag biztonsági másolatokra támaszkodnia. Ehelyett használja az útmutatóban ismertetett egyéb képességeket a rugalmassági követelmények támogatására. A biztonsági másolatok azonban védelmet nyújtanak bizonyos kockázatok ellen, amelyeket más megközelítések nem. További információ: Mi a redundancia, a replikáció és a biztonsági mentés?
Szolgáltatásiszint-szerződés
Az Azure Storage szolgáltatásszintű szerződése (SLA) leírja a szolgáltatás várható rendelkezésre állását és azokat a feltételeket, amelyeket teljesíteni kell a rendelkezésre állási elvárás eléréséhez. A rendelkezésre állási SLA, amelyre jogosult, a tárolási szinttől és a használt replikációs típustól függ. További információ: SLA-k online szolgáltatásokhoz.
Kapcsolódó tartalom
- Mi az a Table Storage?
- Méretezhető és performanszos táblák tervezése
- Redundancia az Azure Storage szolgáltatásban
- Az Azure Storage vészhelyreállításának tervezése és feladatátvétele
- A Table Storage teljesítmény- és méretezhetőségi ellenőrzőlistája
- Azure-megbízhatóság
- Javaslatok átmeneti hibák kezelésére