Oktatóanyag: Nagyméretű adatok indexelése az Apache Sparkból a SynapseML és az Azure AI Search használatával
Ebben az Azure AI Search-oktatóanyagban megtudhatja, hogyan indexelheti és kérdezheti le a Spark-fürtből betöltött nagyméretű adatokat. Állítson be egy Jupyter-jegyzetfüzetet, amely a következő műveleteket hajtja végre:
- Különböző űrlapok (számlák) betöltése adatkeretbe egy Apache Spark-munkamenetben
- Elemezze őket a funkciók meghatározásához
- Az eredményül kapott kimenet összeállítása táblázatos adatstruktúrába
- A kimenet írása az Azure AI Searchben üzemeltetett keresési indexbe
- A létrehozott tartalom megismerése és lekérdezése
Ez az oktatóanyag függőséget igényel a SynapseML-ről, amely egy nyílt forráskód kódtár, amely támogatja a nagy adathalmazokon keresztüli, nagymértékben párhuzamos gépi tanulást. A SynapseML-ben a keresési indexelés és a gépi tanulás speciális feladatokat végző transzformátorokon keresztül érhető el. A transzformátorok számos AI-képességre koppintanak. Ebben a gyakorlatban az AzureSearchWriter API-kat használhatja elemzéshez és AI-bővítéshez.
Bár az Azure AI Search natív AI-bővítéssel rendelkezik, ez az oktatóanyag bemutatja, hogyan férhet hozzá az AI-képességekhez az Azure AI Searchen kívül. Ha a SynapseML-t használja indexelők vagy készségek helyett, nem vonatkoznak önre adatkorlátok vagy az objektumokkal kapcsolatos egyéb korlátozások.
Tipp.
A bemutató rövid videóját itt tekintheti meg https://www.youtube.com/watch?v=iXnBLwp7f88: . A videó további lépésekkel és vizualizációkkal bővül ebben az oktatóanyagban.
Előfeltételek
Szüksége van a kódtárra synapseml és több Azure-erőforrásra. Ha lehetséges, használja ugyanazt az előfizetést és régiót az Azure-erőforrásokhoz, és helyezzen el mindent egy erőforráscsoportba az egyszerű törlés érdekében. Az alábbi hivatkozások a portál telepítésére mutatnak. A mintaadatok importálása nyilvános helyről történik.
- SynapseML 1. csomag
- Azure AI Search (bármely szint) 2
- Azure AI-szolgáltatások (bármely szint) 3
- Azure Databricks (bármely szint) 4
1 Ez a hivatkozás feloldja a csomag betöltésére szolgáló oktatóanyagot.
2 Az ingyenes keresési szinttel indexelheti a mintaadatokat, de magasabb szintet is választhat, ha az adatkötetek nagyok. Számlázható szintek esetén adja meg a keresési API-kulcsot a Függőségek beállítása lépéssel tovább.
3 Ez az oktatóanyag az Azure AI Document Intelligencet és az Azure AI Translatort használja. Az alábbi utasításokban adjon meg egy többszolgáltatásos kulcsot és a régiót. Ugyanez a kulcs mindkét szolgáltatás esetében működik.
4 Ebben az oktatóanyagban az Azure Databricks biztosítja a Spark számítási platformot. A munkaterület beállításához a portál utasításait használtuk.
Feljegyzés
A fenti Azure-erőforrások mindegyike támogatja a Microsoft Identity platform biztonsági funkcióit. Az egyszerűség kedvéért ez az oktatóanyag kulcsalapú hitelesítést feltételez az egyes szolgáltatások portáloldalairól másolt végpontok és kulcsok használatával. Ha éles környezetben implementálja ezt a munkafolyamatot, vagy megosztja a megoldást másokkal, ne felejtse el lecserélni a rögzített kulcsokat integrált biztonsági vagy titkosított kulcsokkal.
1. lépés: Spark-fürt és jegyzetfüzet létrehozása
Ebben a szakaszban hozzon létre egy fürtöt, telepítse a synapseml kódtárat, és hozzon létre egy jegyzetfüzetet a kód futtatásához.
Az Azure Portalon keresse meg az Azure Databricks-munkaterületet, és válassza a Munkaterület indítása lehetőséget.
A bal oldali menüben válassza a Számítás lehetőséget.
Válassza a Számítás létrehozása lehetőséget.
Fogadja el az alapértelmezett konfigurációt. A fürt létrehozása több percet vesz igénybe.
Telepítse a
synapsemltárat a fürt létrehozása után:Válassza a Kódtárak lehetőséget a fürt lapjának tetején található lapok közül.
Válassza az Új telepítése lehetőséget.
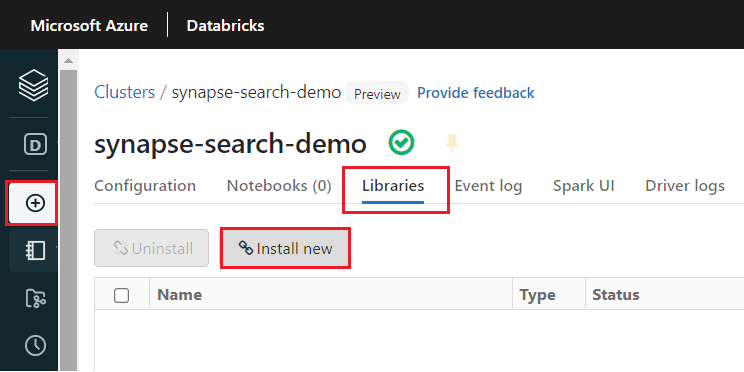
Válassza a Maven lehetőséget.
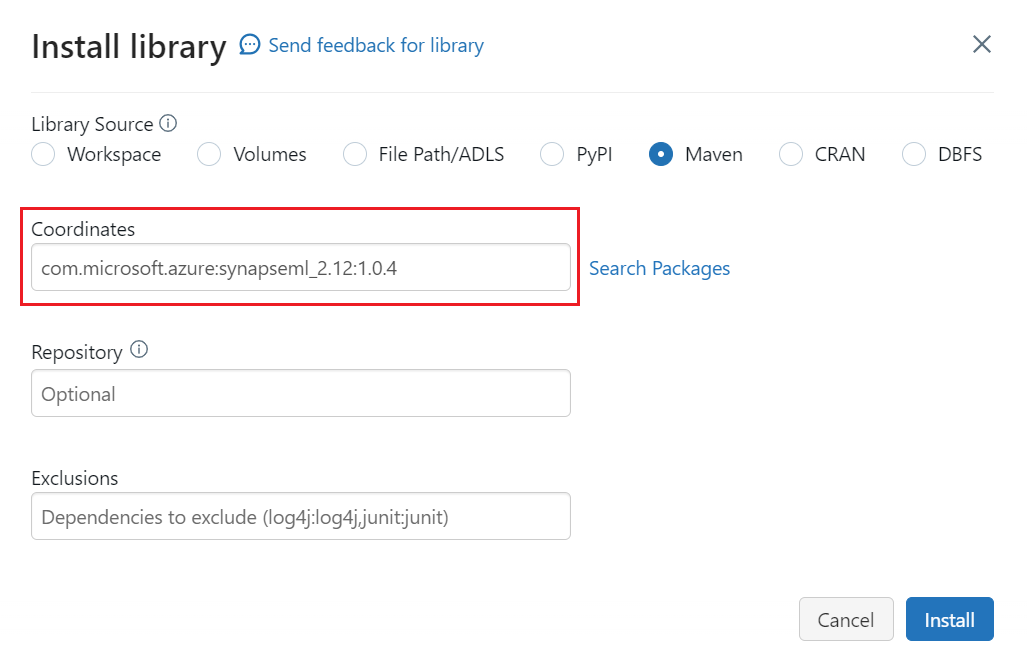
A Koordináták mezőben adja meg a
com.microsoft.azure:synapseml_2.12:1.0.4Válassza a Telepítés lehetőséget.
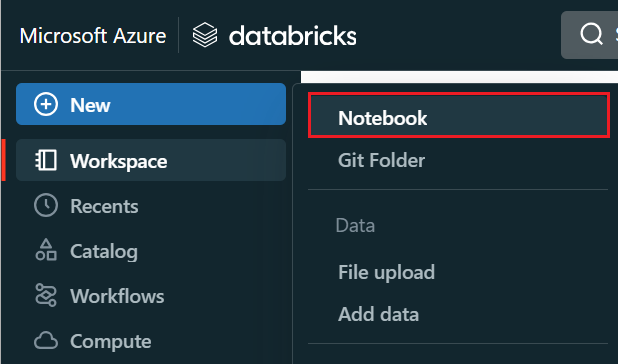
A bal oldali menüben válassza a Jegyzetfüzet létrehozása lehetőséget>.
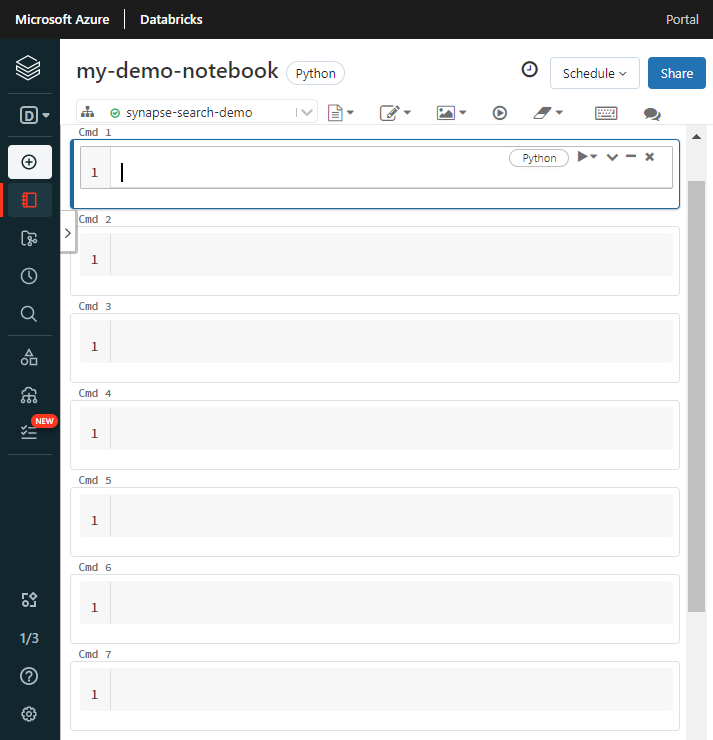
Adjon nevet a jegyzetfüzetnek, válassza ki alapértelmezett nyelvként a Pythont , és válassza ki a tárat tartalmazó fürtöt
synapseml.Hozzon létre hét egymást követő cellát. Illessze be a kódot mindegyikbe.
2. lépés: Függőségek beállítása
Illessze be a következő kódot a jegyzetfüzet első cellájába.
Cserélje le a helyőrzőket végpontokra és hozzáférési kulcsokra az egyes erőforrásokhoz. Adjon nevet egy új keresési indexnek. Nincs szükség további módosításokra, ezért futtassa a kódot, amikor készen áll.
Ez a kód több csomagot importál, és beállítja a munkafolyamatban használt Azure-erőforrásokhoz való hozzáférést.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
3. lépés: Adatok betöltése a Sparkba
Illessze be a következő kódot a második cellába. Nincs szükség módosításokra, ezért futtassa a kódot, amikor készen áll.
Ez a kód betölt néhány külső fájlt egy Azure Storage-fiókból. A fájlok különböző számlák, és egy adatkeretbe vannak beolvasva.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
4. lépés: Dokumentumintelligencia hozzáadása
Illessze be a következő kódot a harmadik cellába. Nincs szükség módosításokra, ezért futtassa a kódot, amikor készen áll.
Ez a kód betölti az AnalyzeInvoices transzformátort , és átadja a számlákat tartalmazó adatkeretre mutató hivatkozást. Meghívja az Azure AI Document Intelligence előre összeállított számlamodellét , hogy adatokat nyerjen ki a számlákból.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
A lépés kimenetének a következő képernyőképhez hasonlóan kell kinéznie. Figyelje meg, hogy az űrlapelemzés egy sűrűn strukturált oszlopba van csomagolva, amellyel nehéz dolgozni. A következő átalakítás úgy oldja meg ezt a problémát, hogy sorokat és oszlopokat elemez az oszlopban.
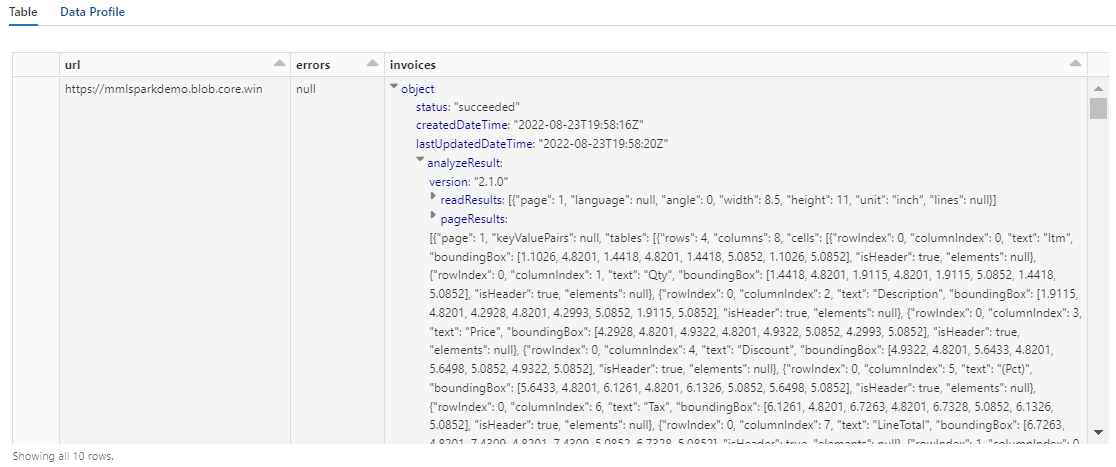
5. lépés: A dokumentumintelligencia kimenetének strukturálása
Illessze be a következő kódot a negyedik cellába, és futtassa. Nincs szükség módosításra.
Ez a kód betölti a FormOntologyLearnert, egy transzformátort, amely elemzi a Dokumentumintelligencia-transzformátorok kimenetét, és táblázatos adatstruktúrára következtet. Az AnalyzeInvoices kimenete dinamikus, és a tartalomban észlelt funkcióktól függően változik. A transzformátor emellett egyetlen oszlopba összesíti a kimenetet. Mivel a kimenet dinamikus és konszolidált, nehéz olyan alárendelt átalakításokban használni, amelyek több struktúrát igényelnek.
A FormOntologyLearner kibővíti az AnalyzeInvoices transzformátor segédprogramját, és olyan mintákat keres, amelyek táblázatos adatstruktúra létrehozásához használhatók. Ha a kimenetet több oszlopba és sorba rendezi, a tartalom más átalakítókban, például az AzureSearchWriterben is hasznosíthatóvá válik.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Figyelje meg, hogy ez az átalakítás hogyan alakítja át a beágyazott mezőket egy táblába, amely lehetővé teszi a következő két átalakítást. Ez a képernyőkép a rövidség kedvéért van levágva. Ha követi a saját jegyzetfüzetét, 19 oszlopa és 26 sora van.
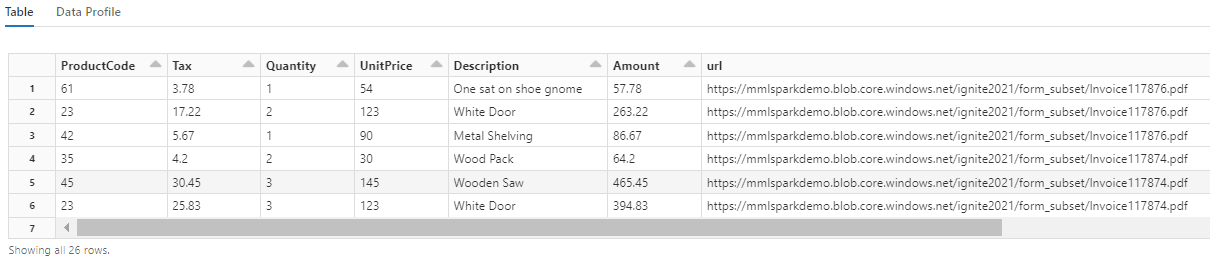
6. lépés: Fordítások hozzáadása
Illessze be az alábbi kódot az ötödik cellába. Nincs szükség módosításokra, ezért futtassa a kódot, amikor készen áll.
Ez a kód betölti a Translate szolgáltatást, amely meghívja az Azure AI Translator szolgáltatást az Azure AI-szolgáltatásokban. Az eredeti szöveg, amely angolul a "Leírás" oszlopban található, gépi fordításban különböző nyelvekre van lefordítva. Az összes kimenet a "output.translations" tömbbe van összesítve.
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Tipp.
A lefordított sztringek kereséséhez görgessen a sorok végéhez.
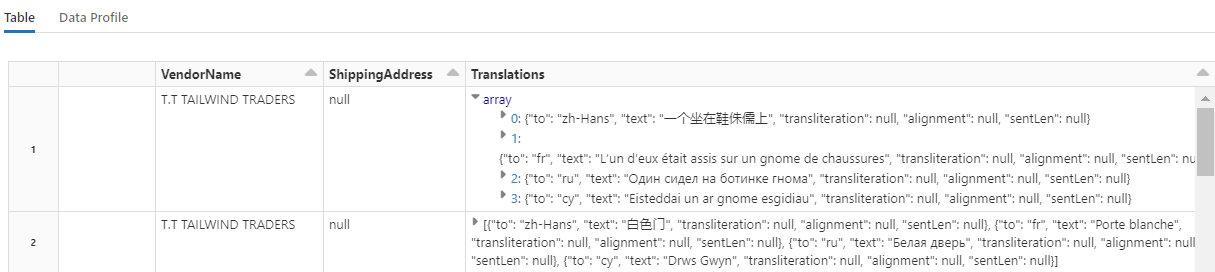
7. lépés: Keresési index hozzáadása az AzureSearchWriterrel
Illessze be a következő kódot a hatodik cellába, majd futtassa. Nincs szükség módosításra.
Ez a kód betölti az AzureSearchWritert. Táblázatos adatkészletet használ fel, és egy keresési index sémájára következtet, amely minden oszlophoz egy mezőt határoz meg. Mivel a fordítási struktúra egy tömb, az index összetett gyűjteményként van tagolt, almezőkkel az egyes nyelvi fordításokhoz. A létrehozott index rendelkezik egy dokumentumkulccsal, és az Index REST API-val létrehozott mezők alapértelmezett értékeit használja.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Az Azure Portal keresőszolgáltatás-lapjaiban megtekintheti az AzureSearchWriter által létrehozott indexdefiníciót.
Feljegyzés
Ha nem tudja használni az alapértelmezett keresési indexet, megadhat egy külső egyéni definíciót a JSON-ban, és az URI-t sztringként adja át az "indexJson" tulajdonságban. Először hozza létre az alapértelmezett indexet, hogy tudja, mely mezőket kell megadnia, majd kövesse a testreszabott tulajdonságokat, ha konkrét elemzőkre van szüksége, például.
8. lépés: Az index lekérdezése
Illessze be a következő kódot a hetedik cellába, majd futtassa. Nincs szükség módosításra, kivéve, ha módosítani szeretné a szintaxist, vagy további példákat szeretne kipróbálni a tartalom további megismeréséhez:
Nincs olyan transzformátor vagy modul, amely lekérdezéseket ad ki. Ez a cella a Search Documents REST API egyszerű hívása.
Ez a példa az "ajtó" ("search": "door") szót keresi. Az egyező dokumentumok számának "számát" is visszaadja, és csak a "Leírás" és a "Fordítások" mezők tartalmát választja ki az eredményekhez. Ha meg szeretné jeleníteni a mezők teljes listáját, távolítsa el a "select" paramétert.
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
Az alábbi képernyőképen a mintaszkript cellakimenete látható.
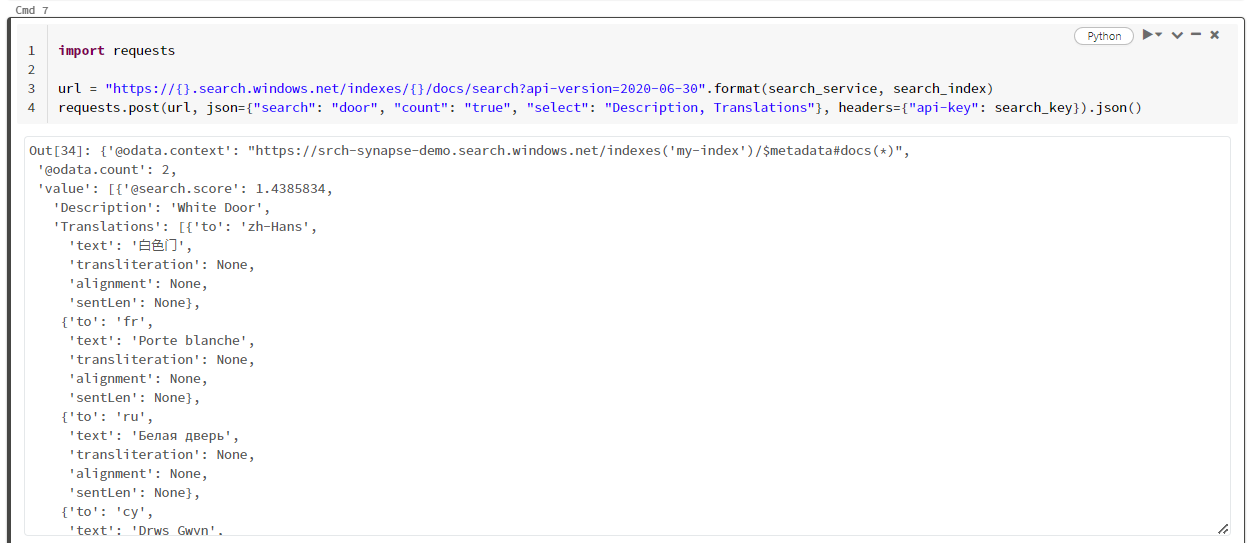
Az erőforrások eltávolítása
Ha a saját előfizetésében dolgozik, a projekt végén célszerű eltávolítania a már nem szükséges erőforrásokat. A továbbra is futó erőforrások költségekkel járhatnak. Az erőforrásokat törölheti egyesével, vagy az erőforráscsoport törlésével eltávolíthatja a benne lévő összes erőforrást is.
A portálon a bal oldali navigációs panel Minden erőforrás vagy Erőforráscsoport hivatkozásával kereshet és kezelhet erőforrásokat.
Következő lépések
Ebben az oktatóanyagban megismerkedett az AzureSearchWriter transzformátorsal a SynapseML-ben, amely új módszer a keresési indexek Azure AI Searchben való létrehozására és betöltésére. A transzformátor bemenetként strukturált JSON-t használ. A FormOntologyLearner képes biztosítani a SynapseML-ben a Dokumentumintelligencia-transzformátorok által előállított kimenethez szükséges struktúrát.
Következő lépésként tekintse át a SynapseML egyéb oktatóanyagait, amelyek átalakított tartalmakat hoznak létre, amelyeket érdemes lehet megvizsgálni az Azure AI Search használatával: