Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A keresési megoldásokban az összetett mintákkal vagy speciális karakterekkel rendelkező sztringek használata nehézkes lehet, mert az alapértelmezett elemző eltávolítja vagy félreértelmezi a minta értelmes részeit. Ez rossz keresési élményt eredményez, ahol a felhasználók nem találják meg a várt információkat. A telefonszámok egy klasszikus példa sztringekre, amelyeket nehéz elemezni. Különböző formátumúak, és speciális karaktereket tartalmaznak, amelyeket az alapértelmezett elemző figyelmen kívül hagy.
A telefonszámokkal kapcsolatos oktatóanyag bemutatja, hogyan oldhatja meg a mintás adatproblémát egy egyéni elemző használatával. Ez a megközelítés ugyanúgy használható, mint a telefonszámok esetében, vagy az azonos jellemzőkkel rendelkező mezőkhöz (speciális karakterekkel mintázva), például URL-címekhez, e-mailekhez, irányítószámokhoz és dátumokhoz.
Ebben az oktatóanyagban egy REST-ügyfelet és az Azure AI Search REST API-kat használ a következőkre:
- A probléma ismertetése
- Kezdeti egyéni elemző fejlesztése telefonszámok kezeléséhez
- Az egyéni elemző tesztelése
- Iteráció az egyéni elemzők tervezésénél az eredmények további javítása érdekében
Előfeltételek
Egy Azure-fiók, aktív előfizetéssel. Fiók létrehozása ingyenes.
Azure AI Search. Hozzon létre egy szolgáltatást , vagy keressen egy meglévő szolgáltatást az aktuális előfizetésében. Ebben az oktatóanyagban ingyenes szolgáltatást használhat.
Visual Studio Code REST-ügyféllel.
Fájlok letöltése
Az oktatóanyag forráskódja az Azure-Samples/azure-search-rest-samples GitHub-adattár custom-analyzer.rest fájljában található.
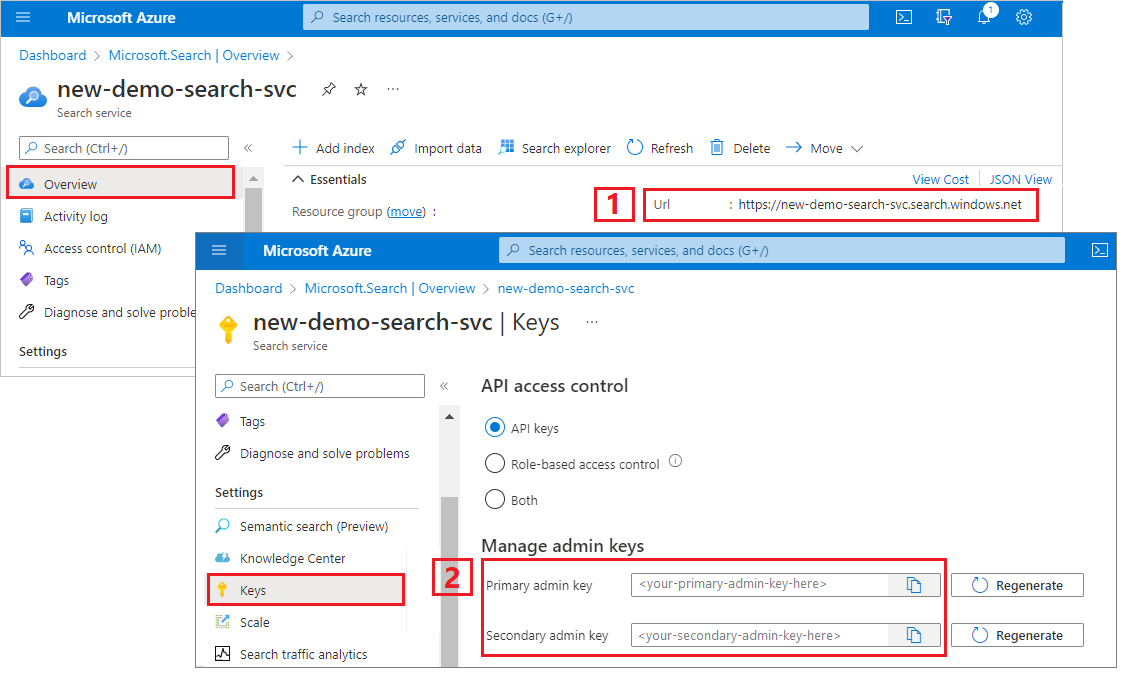
Rendszergazdai kulcs és URL-cím másolása
Az oktatóanyagBAN szereplő REST-hívásokhoz keresési szolgáltatásvégpontra és rendszergazdai API-kulcsra van szükség. Ezeket az értékeket az Azure Portalon szerezheti be.
Jelentkezzen be az Azure Portalra, nyissa meg az Áttekintés lapot, és másolja ki az URL-címet. A végpontok például a következőképpen nézhetnek ki:
https://mydemo.search.windows.net.A Beállítások> területen másolja ki a rendszergazdai kulcsot. A rendszergazdai kulcsok objektumok hozzáadására, módosítására és törlésére szolgálnak. Két felcserélhető rendszergazdai kulcs van. Másolja valamelyiket.
Az érvényes API-kulcs kérésenként megbízhatóságot hoz létre a kérést küldő alkalmazás és az azt kezelő keresési szolgáltatás között.
Kezdeti index létrehozása
Nyisson meg egy új szövegfájlt a Visual Studio Code-ban.
Állítsa be a változókat a keresési végpontra és az előző szakaszban gyűjtött API-kulcsra.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HEREMentse a fájlt fájlkiterjesztéssel
.rest.Illessze be a következő példát egy kis, két mezőből álló
phone-numbers-indexindex létrehozásához:idésphone_number. Még nem definiált elemzőt, ezért astandard.lucenerendszer alapértelmezés szerint az elemzőt használja.### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Válassza a Kérés elküldése elemet. Válasznak kell lennie
HTTP/1.1 201 Created, és a válasz törzsének tartalmaznia kell az indexséma JSON-ábrázolását.Adatok betöltése az indexbe különböző telefonszámformátumokat tartalmazó dokumentumok használatával. Ezek a tesztadatok.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Próbálja ki a felhasználó által beírthoz hasonló lekérdezéseket. Előfordulhat például, hogy a felhasználó tetszőleges számú formátumban keres
(425) 555-0100, és továbbra is az eredmények visszaadását várja. Kezdje a kereséssel(425) 555-0100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}A lekérdezés négyből három várt eredményt ad vissza, de két váratlan eredményt is ad vissza.
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Próbálkozzon újra formázás nélkül:
4255550100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Ez a lekérdezés még rosszabbul teljesít, mivel a négy helyes egyezés közül csak egyet ad vissza.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Ha zavarónak találja ezeket az eredményeket, nem egyedül van. A következő szakasz ismerteti, hogy miért kapja meg ezeket az eredményeket.
Az elemzők működésének áttekintése
A keresési eredmények megértéséhez meg kell értenie, hogy az elemző mit csinál. Innen tesztelheti az alapértelmezett elemzőt az Analyze API-val, amely az igényeinek jobban megfelelő elemző megtervezésének alapja.
Az elemző a lekérdezési sztringek és indexelt dokumentumok szövegének feldolgozásáért felelős teljes szöveges keresőmotor összetevője. A különböző elemzők a forgatókönyvtől függően különböző módon módosítják a szöveget. Ebben a forgatókönyvben egy telefonszámokra szabott elemzőt kell létrehoznunk.
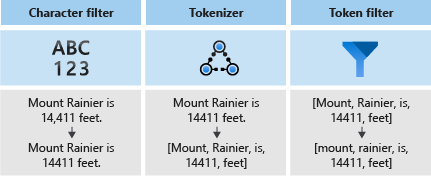
Az elemzők három összetevőből állnak:
- Karakterszűrők , amelyek eltávolítják vagy lecserélik az egyes karaktereket a bemeneti szövegből.
- Tokenizer, amely a bemeneti szöveget kivonatokra bontja, amelyek kulcsként szolgálnak a keresési indexben.
- Jogkivonatszűrők , amelyek a tokenizer által előállított jogkivonatokat módosítják.
Az alábbi ábra bemutatja, hogyan működik együtt ez a három összetevő egy mondat tokenizálásához.
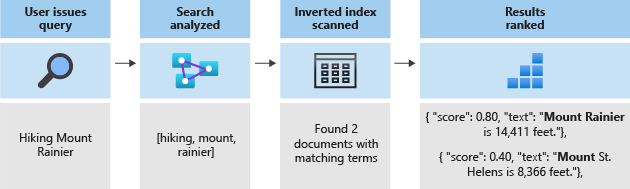
Ezek a jogkivonatok ezután egy fordított indexben vannak tárolva, amely lehetővé teszi a gyors, teljes szöveges keresést. Az invertált indexek lehetővé teszik a teljes szöveges keresést úgy, hogy a lexikális elemzés során kinyert összes egyedi kifejezést leképezik azokat a dokumentumokat, amelyekben előfordulnak. Az alábbi ábrán egy példa látható:

Az összes keresés az invertált indexben tárolt kifejezések kereséséhez szükséges. Amikor egy felhasználó lekérdezést ad ki:
- A rendszer elemzi a lekérdezést, és elemzi a lekérdezési kifejezéseket.
- Az invertált index egyező kifejezéseket tartalmazó dokumentumokat keres.
- A pontozó algoritmus rangsorolja a lekért dokumentumokat.
Ha a lekérdezési kifejezések nem felelnek meg a fordított indexben szereplő feltételeknek, a függvény nem ad vissza eredményeket. A lekérdezések működésével kapcsolatos további információkért tekintse meg a teljes szöveges keresést az Azure AI Searchben.
Feljegyzés
A részleges kifejezéses lekérdezések fontos kivételt jelentenek ebben a szabályban. A hagyományos kifejezéses lekérdezésekkel ellentétben ezek a lekérdezések (előtagos lekérdezés, helyettesítő lekérdezés és regex lekérdezés) megkerülik a lexikális elemzési folyamatot. A részleges kifejezések csak kisbetűsek az indexben szereplő feltételekkel való egyeztetés előtt. Ha egy elemző nincs konfigurálva az ilyen típusú lekérdezések támogatására, gyakran váratlan eredményeket kap, mert az indexben nem léteznek egyező kifejezések.
Elemzők tesztelése az Analyze API használatával
Az Azure AI Search egy Analyze API-t biztosít, amely lehetővé teszi az elemzők tesztelését, hogy megértse, hogyan dolgozzák fel a szöveget.
Hívja meg az Analyze API-t a következő kéréssel:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
Az API a szövegből kinyert tokeneket adja vissza az Ön által megadott elemző használatával. A standard Lucene-elemző három különálló tokenként osztja fel a telefonszámot.
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Ezzel szemben az írásjelek nélkül formázott telefonszámot 4255550100 egyetlen tokenbe rendezi.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Válasz:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Ne feledje, hogy a lekérdezési kifejezések és az indexelt dokumentumok elemzése is folyamatban van. Visszatérve az előző lépés keresési eredményeire, láthatja, hogy miért jelennek meg ezek a találatok.
Az első lekérdezésnél visszakapott telefonszámok váratlanok, mert egy elemük, 555, megegyezik a keresett kifejezések egyikével. A második lekérdezésben csak az egy számot adja vissza a rendszer, mert ez az egyetlen rekord, amelynek jogkivonata megegyezik 4255550100.
Egyéni elemző létrehozása
Most, hogy megismerte a látott eredményeket, hozzon létre egy egyéni elemzőt a tokenizációs logika továbbfejlesztéséhez.
A cél az, hogy intuitív keresést biztosítson a telefonszámok között, függetlenül attól, hogy milyen formátumban van a lekérdezés vagy az indexelt sztring. Az eredmény eléréséhez adjon meg egy karakterszűrőt, egy jogkivonat-szűrőt és egy jogkivonatszűrőt.
Karakterszűrők
A karakterszűrők feldolgozzák a szöveget, mielőtt betáplálják a tokenizerbe. A karakterszűrők gyakran használják a HTML-elemek szűrését és a speciális karakterek cseréjét.
Telefonszámok esetén el szeretné távolítani a szóközöket és a speciális karaktereket, mert nem minden telefonszámformátum tartalmazza ugyanazokat a speciális karaktereket és szóközöket.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
A szűrő eltávolítja és szóközöket -()+. távolít el a bemenetből.
| Bevitel | Kimenet |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizáló
A tokenizerek egységekre bontják a szöveget, és eltávolítanak néhány karaktert, például az írásjeleket. A tokenizálás célja sok esetben az, hogy egy mondatot külön szavakra bontsunk.
Ebben a forgatókönyvben használjon egy kulcsszó-tokenizálót, keyword_v2, hogy a telefonszámot egyetlen kifejezésként rögzítse. Nem ez az egyetlen módja a probléma megoldásának, ahogy az Alternatív megközelítések szakaszban is ismertetjük .
A kulcsszó tokenizálók mindig ugyanazt a szöveget adják vissza, egy kifejezésként.
| Bevitel | Kimenet |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Elemszűrők
A token szűrők módosítják vagy kiszűrik a tokenizáló által létrehozott tokeneket. A token szűrők egyik gyakori használata, hogy az összes karaktert kisbetűsre alakítják egy kisbetűs token szűrő segítségével. Egy másik gyakori felhasználási terület a stopwords kiszűrése, például the: , andvagy is.
Bár ehhez a forgatókönyvhöz nem kell egyik szűrőt sem használnia, használjon nGram-jogkivonat-szűrőt a telefonszámok részleges keresésének engedélyezéséhez.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
A nGram_v2 token szűrő a tokeneket egy adott méretű n-grammokra osztja fel a minGram és maxGram paraméterek alapján.
A telefonelemzőhöz a minGram értéke 3-re van beállítva, mert ez a legrövidebb részszöveg, amelyet a felhasználók várhatóan keresnek.
maxGram úgy van beállítva 20 , hogy az összes telefonszám, még a mellékekkel is, egyetlen n-grammba illeszkedjen.
Az n-gramm szerencsétlen mellékhatása, hogy néhány hamis pozitív eredményt adnak vissza. Ezt egy későbbi lépésben kijavíthatja, ha létrehoz egy külön elemzőt olyan keresésekhez, amelyek nem tartalmazzák az n-gram jogkivonat szűrőt.
| Bevitel | Kimenet |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Elemző
A karakterszűrők, a tokenizáló és a token szűrők alkalmazásával készen áll az elemző definiálására.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
Az Analyze API-ból az alábbi bemenetek alapján az egyéni elemző kimenetei a következők:
| Bevitel | Kimenet |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
A kimeneti oszlopban lévő összes token megtalálható az indexben. Ha a lekérdezés tartalmazza a kifejezéseket, a rendszer visszaadja a telefonszámot.
Építsd újra az új elemzővel
Törölje az aktuális indexet.
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2024-07-01 HTTP/1.1 api-key: {{apiKey}}Hozza létre újra az indexet az új elemzővel. Ez az indexséma hozzáad egy egyéni elemződefiníciót és egy egyéni elemző-hozzárendelést a telefonszám mezőhöz.
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Az egyéni elemző tesztelése
Az index ismételt létrehozása után tesztelje az elemzőt a következő kéréssel:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Mostanra meg kell jelennie a telefonszámból eredő tokenek gyűjteményének.
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Az egyéni elemző módosítása a hamis pozitív értékek kezeléséhez
Miután az egyéni elemzővel minta lekérdezéseket végzett az indexen, látnia kell, hogy a visszahívás javult, és a rendszer visszaadja az összes egyező telefonszámot. Az n-gram token szűrő azonban téves pozitív találatokat is visszaad. Ez az n-gram token szűrő gyakori mellékhatása.
A hamis pozitív értékek elkerülése érdekében hozzon létre egy külön elemzőt a lekérdezéshez. Ez az elemző megegyezik az előzőével, azzal a kivételel, hogy kihagyja a custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
Az indexdefinícióban adjon meg egy indexAnalyzer és egy searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Ezzel a módosítással minden beállítás be van állítva. A következő lépések az alábbiak:
Törölje az indexet.
Hozza létre újra az indexet, miután hozzáadta az új egyéni elemzőt (
phone_analyzer-search), és hozzárendelte az elemzőt aphone-numbermező tulajdonságáhozsearchAnalyzer.Töltse be újra az adatokat.
A lekérdezések újratesztelése annak ellenőrzéséhez, hogy a keresés a várt módon működik-e. Ha a mintafájlt használja, ez a lépés létrehozza a harmadik indexet
phone-number-index-3.
Alternatív megközelítések
Az előző szakaszban ismertetett elemző úgy lett kialakítva, hogy maximalizálja a keresési rugalmasságot. Ennek azonban az az ára, hogy sok, esetleg nem lényeges kifejezést tárol az indexben.
Az alábbi példa egy olyan alternatív elemzőt mutat be, amely hatékonyabb a tokenizálásban, de hátrányai vannak.
A bemenet 14255550100 figyelembe véve az elemző nem tudja logikailag feldarabolni a telefonszámot. Például nem tudja elkülöníteni az országkódot a 1körzetszámtól. 425 Ez az eltérés azt eredményezi, hogy a rendszer nem adja vissza a telefonszámot, ha egy felhasználó nem tartalmaz országkódot a keresésben.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
Az alábbi példában a telefonszám olyan darabokra van felosztva, amelyeket általában egy felhasználó keres.
| Bevitel | Kimenet |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
A követelményektől függően ez a probléma hatékonyabb megközelítése lehet.
Főbb tanulságok
Ez az oktatóanyag bemutatta az egyéni elemzők létrehozásának és tesztelésének folyamatát. Létrehozott egy indexet, indexelt adatokat, majd lekérdezte az indexet, hogy lássa, milyen keresési eredmények lettek visszaadva. Innen az Analyze API használatával látta a lexikális elemzési folyamatot működés közben.
Bár az ebben az oktatóanyagban definiált elemző egyszerű megoldást kínál a telefonszámok keresésére, ugyanez a folyamat használható egyéni elemző létrehozására minden olyan forgatókönyvhöz, amely hasonló jellemzőkkel rendelkezik.
Az erőforrások takarítása
Ha a saját előfizetésében dolgozik, érdemes eltávolítania azokat az erőforrásokat, amelyekre a projekt végén már nincs szüksége. A továbbra is futó erőforrások költségekkel járhatnak. Az erőforrásokat törölheti egyesével, vagy az erőforráscsoport törlésével eltávolíthatja a benne lévő összes erőforrást is.
Az erőforrásokat az Azure Portalon, a bal oldali navigációs panel Minden erőforrás vagy erőforráscsoport hivatkozásával keresheti meg és kezelheti.
Következő lépések
Most, hogy már tudja, hogyan hozhat létre egyéni elemzőt, tekintse meg az összes különböző szűrőt, tokenizert és elemzőt, amelyek a gazdag keresési élmény létrehozásához érhetők el: