Vektoros lekérdezés létrehozása az Azure AI Searchben
Az Azure AI Searchben, ha vektorindexe van, ez a cikk a következő lépéseket ismerteti:
Ez a cikk REST-et használ az ábrához. Más nyelvű kódmintákért tekintse meg az azure-search-vector-samples GitHub-adattárat a vektoros lekérdezéseket tartalmazó végpontok közötti megoldásokhoz.
Akkor is használhatja a Search Explorert az Azure Portalon, ha konfigurál egy vektorizálót, amely beágyazásokká alakítja a sztringeket.
Előfeltételek
Azure AI Search, bármely régióban és bármilyen szinten.
Vektorindex az Azure AI Searchben. Ellenőrizze, hogy van-e
vectorSearchszakasz az indexben a vektorindex megerősítéséhez.A Visual Studio Code rest-ügyféllel és mintaadatokkal, ha ezeket a példákat önállóan szeretné futtatni. A REST-ügyfél használatának megkezdéséhez tekintse meg a következő rövid útmutatót: Azure AI Search a REST használatával.
Lekérdezési sztring bemenetének konvertálása vektorsá
Vektormező lekérdezéséhez magának a lekérdezésnek vektornak kell lennie.
A felhasználó szöveges lekérdezési sztringjének vektoros ábrázolássá alakításának egyik módszere egy beágyazási kódtár vagy API meghívása az alkalmazáskódban. Ajánlott eljárásként mindig ugyanazokat a beágyazási modelleket használja, amelyeket beágyazások létrehozásához használ a forrásdokumentumokban. Kódmintákat talál, amelyek bemutatják , hogyan hozhat létre beágyazásokat az azure-search-vector-samples adattárban.
A második módszer az integrált vektorizáció használata, amely jelenleg nyilvános előzetes verzióban érhető el, hogy az Azure AI Search kezelje a lekérdezésvektorizációs bemeneteket és kimeneteket.
Íme egy REST API-példa egy Azure OpenAI-beágyazási modell üzembe helyezéséhez küldött lekérdezési sztringre:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
A várt válasz 202 lesz az üzembe helyezett modell sikeres hívásához.
A válasz törzsében a "beágyazás" mező a "bemenet" lekérdezési sztring vektoros ábrázolása. Tesztelési célokra a "beágyazás" tömb értékét egy lekérdezési kérelemben a "vectorQueries.vector" fájlba másolná a következő szakaszokban látható szintaxis használatával.
A POST-hívás tényleges válasza az üzembe helyezett modellre 1536 beágyazást tartalmaz, amelyeket itt vágunk le, hogy csak az első néhány vektor legyen olvasható.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
Ebben a megközelítésben az alkalmazáskód felelős a modellhez való csatlakozásért, a beágyazások generálásáért és a válasz kezeléséhez.
Vektoros lekérdezési kérelem
Ez a szakasz a vektoros lekérdezések alapstruktúráját mutatja be. Vektoros lekérdezések létrehozásához használhatja az Azure Portalt, a REST API-kat vagy az Azure SDK-kat. Ha 2023-07-01-preview-ról migrál, akkor kompatibilitástörő változások következnek be. További részletekért lásd : Frissítés a legújabb REST API-ra .
A 2023-11-01 a Search POST stabil REST API-verziója. Ez a verzió a következőket támogatja:
vectorQueriesa vektorkeresés felépítése.kindbeállítássalvectormegadhatja, hogy a lekérdezés vektortömb.vectora lekérdezés (szöveg vagy kép vektoros ábrázolása).exhaustive(nem kötelező) teljes KNN-t hív meg lekérdezéskor, még akkor is, ha a mező indexelve van a HNSW-hez.
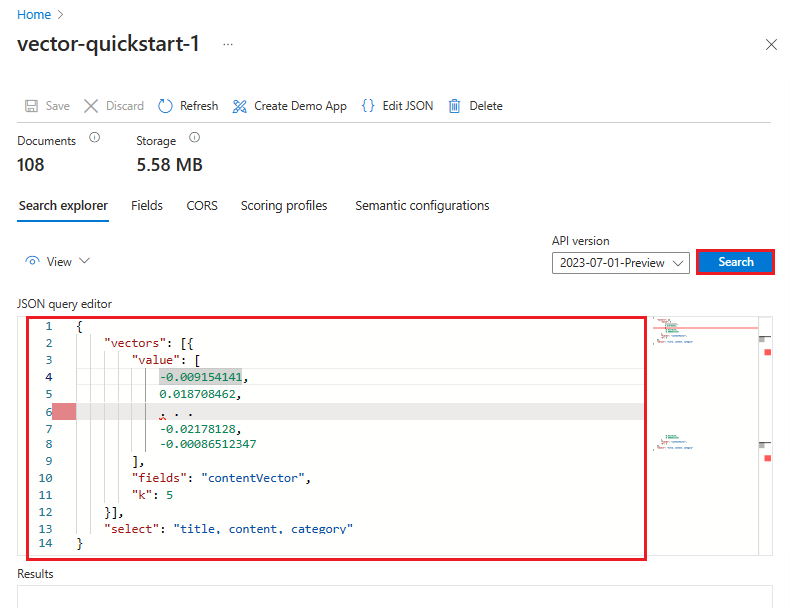
A következő példában a vektor ennek a sztringnek a megjelenítése: "amit az Azure-szolgáltatások támogatnak a teljes szöveges keresésben". A lekérdezés a contentVector mezőt célozza meg. A lekérdezés eredményeket ad k vissza. A tényleges vektor 1536 beágyazással rendelkezik, ezért ebben a példában az olvashatóság érdekében vágja le.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"k": 5
}
]
}
Vektoros lekérdezési válasz
Az Azure AI Searchben a lekérdezési válaszok alapértelmezés szerint az összes retrievable mezőből állnak. Gyakori azonban, hogy a keresési eredményeket a mezők egy részhalmazára retrievable korlátozza, ha egy select utasításban listázzuk őket.
A vektoros lekérdezésekben gondosan gondolja át, hogy a válaszban vektormezőkre van-e szükség. A vektormezők nem olvashatók az emberek számára, ezért ha választ küld egy weblapra, akkor az eredményre jellemző nem adatmegjelenítő mezőket kell választania. Ha például a lekérdezés a következőre contentVectorfut, akkor vissza is térhet content .
Ha vektormezőket szeretne az eredményben, íme egy példa a válaszstruktúrára. contentVector a beágyazások sztringtömbje, amelyet itt vágunk le a rövidítéshez. A keresési pontszám relevanciát jelez. A környezet más nem adatvetítő mezőket is tartalmaz.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Főbb pontok:
kmeghatározza, hogy hány legközelebbi szomszéd eredményt ad vissza, ebben az esetben három. A vektoros lekérdezések mindig eredményeket adnak visszak, feltéve, hogy legalábbkdokumentumok léteznek, még akkor is, ha vannak rossz hasonlóságú dokumentumok, mivel az algoritmus megkeresika lekérdezésvektor legközelebbi szomszédjait.Ezt
@search.scorea vektorkeresési algoritmus határozza meg.A keresési eredmények mezői vagy az összes
retrievablemező, vagy egyselectzáradék mezői. A vektoros lekérdezés végrehajtása során az egyezés csak vektoradatokon történik. A válaszok azonban az index bármelyretrievablemezőjét tartalmazhatják. Mivel a vektormezők eredményének dekódolására nincs lehetőség, a nem adatfeltáró szövegmezők felvétele hasznos lehet az emberi olvasható értékekhez.
Vektoros lekérdezés szűrővel
A lekérdezési kérelem tartalmazhat vektoros lekérdezést és szűrőkifejezést. A szűrők nem meg nem felelő mezőkre filterable vonatkoznak, sztringmezőkre vagy numerikusakra, és hasznosak a keresési dokumentumok szűrési feltételek alapján történő belefoglalásához vagy kizárásához. Bár egy vektormező önmagában nem szűrhető, a szűrők ugyanazon index más mezőire is alkalmazhatók.
A szűrőket kizárási feltételként alkalmazhatja a lekérdezés végrehajtása előtt vagy a lekérdezés végrehajtása után a keresési eredmények szűréséhez. Az egyes üzemmódok és a várt teljesítmény indexméreten alapuló összehasonlításához tekintse meg a Szűrők vektoros lekérdezésekben című témakört.
Tipp.
Ha nem rendelkezik szöveges vagy numerikus értékeket tartalmazó forrásmezőkkel, ellenőrizze, hogy vannak-e olyan dokumentum metaadatai, mint például a LastModified vagy a CreatedBy tulajdonságok, amelyek hasznosak lehetnek egy metaadat-szűrőben.
A 2023-11-01 az API stabil verziója. A következőt teszi:
vectorFilterModeelőszűrő (alapértelmezett) vagy postfilter szűrési mód esetén.filteradja meg a feltételeket.
A következő példában a vektor ennek a lekérdezési sztringnek a reprezentációja: "amit az Azure-szolgáltatások támogatnak a teljes szöveges keresésben". A lekérdezés a contentVector mezőt célozza meg. A tényleges vektor 1536 beágyazással rendelkezik, ezért ebben a példában az olvashatóság érdekében vágja le.
A szűrőfeltételeket a program egy szűrhető szövegmezőre alkalmazza (category ebben a példában), mielőtt a keresőmotor végrehajtja a vektoros lekérdezést.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"filter": "category eq 'Databases'",
"vectorFilterMode": "preFilter",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"k": 5
}
]
}
Több vektormező
A "vectorQueries.fields" tulajdonságot több vektormezőre is beállíthatja. A vektoros lekérdezés a listában megadott fields összes vektormezőn fut. Több vektormező lekérdezésekor győződjön meg arról, hogy mindegyik ugyanabból a beágyazási modellből tartalmaz beágyazást, és hogy a lekérdezés is ugyanabból a beágyazási modellből jön létre.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Több vektoros lekérdezés
A több lekérdezéses vektoros keresés több lekérdezést küld a keresési index több vektormezőjében. Erre a lekérdezési kérelemre gyakori példa, ha olyan modelleket használ, mint például a CLIP egy többmodális vektoros kereséshez, ahol ugyanaz a modell képes vektorizálni a kép- és szövegtartalmat.
Az alábbi lekérdezési példa a hasonlóságot keresi mind a kettőben myImageVectormyTextVector, mind pedig a két különböző lekérdezésbe ágyazott, párhuzamosan futtatott lekérdezési beágyazást. Ez a lekérdezés olyan eredményt hoz létre, amelyet a Kölcsönös rangsor fúzió (RRF) használatával pontozott.
vectorQueriesvektoros lekérdezések tömbje.vectorA keresési index képvektorait és szövegvektorait tartalmazza. Minden példány külön lekérdezés.fieldsmegadja, hogy melyik vektormezőt célozza meg.kaz eredményekbe belefoglalandó legközelebbi szomszéd egyezések száma.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
A keresési eredmények szöveg és képek kombinációját is tartalmazhatják, feltéve, hogy a keresési index tartalmaz egy mezőt a képfájlhoz (a keresési index nem tárolja a képeket).
Lekérdezés integrált vektorizálással (előzetes verzió)
Ez a szakasz egy vektoros lekérdezést jelenít meg, amely meghívja az új integrált vektorizációs előnézeti funkciót, amely egy szöveges lekérdezést vektorsá alakít át. Használja a 2023-10-01-Preview REST API-t és az újabb előzetes REST API-kat vagy egy frissített béta Azure SDK-csomagot.
Az előfeltétel egy olyan keresési index, amely konfigurálva van egy vektormezőhöz, és hozzá van rendelve egy vektormezőhöz . A vektorizáló kapcsolati adatokat biztosít a lekérdezési időpontban használt beágyazási modellhez. Ellenőrizze a vektorizálók specifikációjának indexdefinícióját.
A lekérdezések vektorok helyett szöveges sztringeket biztosítanak:
kindbeállításnak a következőre kell állítania:text.textszöveges sztringgel kell rendelkeznie. Át lesz adva a vektormezőhöz rendelt vektorizálónak.fieldsa keresendő vektormező.
Íme egy egyszerű példa a lekérdezési időpontban vektorizált lekérdezésre. A szöveges sztring vektorizált, majd a descriptionVector mező lekérdezésére szolgál.
POST https://{{search-service}}.search.windows.net/indexes/{{index}}/docs/search?api-version=2024-05-01-preview
{
"select": "title, genre, description",
"vectorQueries": [
{
"kind": "text",
"text": "mystery novel set in London",
"fields": "descriptionVector",
"k": 5
}
]
}
Íme egy hibrid lekérdezés , amely a szöveges lekérdezések integrált vektorizálását használja. Ez a lekérdezés több lekérdezésvektormezőt, több nem megadó mezőt, szűrőt és szemantikai rangsorolást tartalmaz. A különbségek kind a vektoros lekérdezés és a text sztring helyett a vector.
Ebben a példában a keresőmotor három vektorizációs hívást indít a hozzá rendelt vektorizálókhoz descriptionVectorsynopsisVectorés authorBioVector az indexhez. Az eredményként kapott vektorok a dokumentumok saját mezőikre való lekérésére szolgálnak. A keresőmotor egy kulcsszókeresést is végrehajt a search lekérdezésen, "mystery novel set in London".
POST https://{{search-service}}.search.windows.net/indexes/{{index}}/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: {{admin-api-key}}
{
"search":"mystery novel set in London",
"searchFields":"description, synopsis",
"semanticConfiguration":"my-semantic-config",
"queryType":"semantic",
"select": "title, author, synopsis",
"filter": "genre eq 'mystery'",
"vectorFilterMode": "postFilter",
"vectorQueries": [
{
"kind": "text",
"text": "mystery novel set in London",
"fields": "descriptionVector, synopsisVector",
"k": 5
},
{
"kind": "text"
"text": "living english author",
"fields": "authorBioVector",
"k": 5
}
]
}
Mind a négy lekérdezés pontszáma összeolvad az RRF rangsorolásával. A másodlagos szemantikai rangsorolást a rendszer meghívja az egyesített keresési eredményeken keresztül, de az searchFields egyetlen olyan találatok kiemelése, amelyek a leginkább szemantikailag igazodnak a találatokhoz "search":"mystery novel set in London".
Feljegyzés
A vektorosítókat az indexelés és a lekérdezés során használják. Ha nincs szüksége adatrészletezésre és vektorizálásra az indexben, kihagyhatja az olyan lépéseket, mint az indexelő, a képességkészlet és az adatforrás létrehozása. Ebben a forgatókönyvben a vektorizálót csak lekérdezési időpontban használja a szöveges sztring beágyazássá alakításához.
A rangsorolt eredmények száma vektoros lekérdezési válaszban
A vektoros lekérdezés megadja a k paramétert, amely meghatározza, hogy hány találatot ad vissza az eredmény. A keresőmotor mindig a találatok k számát adja vissza. Ha k nagyobb, mint az indexben lévő dokumentumok száma, akkor a dokumentumok száma határozza meg a visszaadható dokumentumok felső korlátját.
Ha ismeri a teljes szöveges keresést, akkor nulla eredményt vár, ha az index nem tartalmaz kifejezést vagy kifejezést. A vektoros keresésben azonban a keresési művelet a legközelebbi szomszédokat azonosítja, és mindig eredményeket ad vissza k , még akkor is, ha a legközelebbi szomszédok nem hasonlóak. Így előfordulhat, hogy nem etikátlan vagy nem témakörön kívüli lekérdezések eredményei jelennek meg, különösen akkor, ha nem használ utasításokat a határok megadásához. A kevésbé releváns eredmények rosszabb hasonlósági pontszámmal rendelkeznek, de még mindig ezek a "legközelebbi" vektorok, ha nincs közelebb semmi. Így a nem értelmezhető eredményekkel rendelkező válaszok továbbra is eredményeket adhatnak vissza k , de az egyes eredmények hasonlósági pontszáma alacsony lenne.
A teljes szöveges keresést tartalmazó hibrid megközelítés enyhítheti ezt a problémát. Egy másik kockázatcsökkentés a keresési pontszám minimális küszöbértékének beállítása, de csak akkor, ha a lekérdezés egy tiszta egyvektoros lekérdezés. A hibrid lekérdezések nem kedveznek a minimális küszöbértékeknek, mert az RRF-tartományok sokkal kisebbek és változékonyak.
Az eredményszámot befolyásoló lekérdezési paraméterek a következők:
"k": ncsak vektoros lekérdezések eredményei"top": nkeresési paramétert tartalmazó hibrid lekérdezések eredményei
A "k" és a "top" is választható. Meghatározatlan, a válaszban szereplő eredmények alapértelmezett száma 50. A "top" és a "skip" beállítással több találatot is megadhat, vagy módosíthatja az alapértelmezett értéket .
Vektoros lekérdezésekben használt rangsorolási algoritmusok
Az eredmények rangsorolása az alábbiak szerint történik:
- Hasonlóság metrika
- Reciprok Rank Fusion (RRF), ha több keresési találat van.
Hasonlóság metrika
A csak vektoros lekérdezés indexszakaszában vectorSearch megadott hasonlósági metrika. Az érvényes értékek a következők cosine: , euclideanés dotProduct.
Az Azure OpenAI-beágyazási modellek koszinuszos hasonlóságot használnak, ezért ha Azure OpenAI-beágyazási modelleket használ, cosine az ajánlott metrika. Egyéb támogatott rangsorolási metrikák a következők: euclidean és dotProduct.
Az RRF használata
Több halmaz akkor jön létre, ha a lekérdezés több vektormezőt céloz meg, több vektoros lekérdezést futtat párhuzamosan, vagy ha a lekérdezés vektoros és teljes szöveges keresés hibridje, szemantikai rangsorolással vagy anélkül.
A lekérdezés végrehajtása során a vektoros lekérdezések csak egy belső vektorindexet célozhatnak meg. Így több vektormező és több vektoros lekérdezés esetén a keresőmotor több lekérdezést hoz létre, amelyek az egyes mezők megfelelő vektorindexeit célják. A kimenet az egyes lekérdezések rangsorolt eredményeinek halmaza, amelyek az RRF használatával vannak egyesítve. További információ: Relevanciapontozás a Kölcsönös rangsor fúzió (RRF) használatával.
Küszöbértékek beállítása az alacsony pontszámú eredmények kizárásához (előzetes verzió)
Mivel a legközelebbi szomszédkeresés mindig a kért k szomszédokat adja vissza, több alacsony pontszámú találat is lekérhető a k keresési eredmények számkövetelményének teljesítése során.
A 2024-05-01-es verziójú REST API-k használatával mostantól hozzáadhat egy threshold lekérdezési paramétert, amely kizárja az alacsony pontszámú keresési eredményeket egy minimális pontszám alapján. A szűrés a különböző visszahívási csoportok eredményeinek összeolvadása előtt történik.
Ebben a példában a 0,8 alatti pontszámot tartalmazó összes találat ki lesz zárva a vektorkeresési eredményekből, még akkor is, ha a találatok száma az alá kcsökken.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-Preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall hibrid kereséshez (előzetes verzió)
A vektoros lekérdezéseket gyakran használják olyan hibrid szerkezetekben, amelyek nem aktormezőket tartalmaznak. Ha azt tapasztalja, hogy a BM25-rangsorolt eredmények egy hibrid lekérdezési eredményben felül vagy alul vannak jelölve, beállíthatja maxTextRecallSize , hogy növelje vagy csökkentse a hibrid rangsoroláshoz megadott BM25-rangsorolt eredményeket.
Ezt a tulajdonságot csak a "search" és a "vectorQueries" összetevőket tartalmazó hibrid kérelmekben állíthatja be.
További információ: Set maxTextRecallSize – Create a hybrid query.
Vektorok súlyozása (előzetes verzió)
Adjon hozzá egy lekérdezési paramétert weight a keresési műveletekben szereplő vektoros lekérdezések relatív súlyának megadásához. Ez az érték két vagy több vektoros lekérdezés által ugyanabban a kérelemben vagy egy hibrid lekérdezés vektorrészéből előállított több rangsorlista eredményeinek kombinálásakor használatos.
Az alapértelmezett érték 1,0, az értéknek nullánál nagyobb pozitív számnak kell lennie.
Az egyes dokumentumok kölcsönös rangsorolvasási pontszámainak kiszámításakor súlyozást használunk. A számítás az érték szorzója a weight dokumentum rangpontszámával szemben a megfelelő eredményhalmazon belül.
Az alábbi példa egy hibrid lekérdezés két vektoros lekérdezési sztringgel és egy szöveges sztringgel. A vektoros lekérdezésekhez súlyok vannak rendelve. Az első lekérdezés a súly 0,5 vagy fele, ami csökkenti annak fontosságát a kérelemben. A második vektoros lekérdezés kétszer olyan fontos.
A szöveges lekérdezések nem rendelkeznek súlyparaméterekkel, de a maxTextRecallSize beállításával növelheti vagy csökkentheti azok fontosságát.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-Preview
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
Következő lépések
Következő lépésként tekintse át a vektoros lekérdezési kód példáit Pythonban, C# vagy JavaScriptben.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: