Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik: Dedikált Azure Synapse Analytics SQL-készletek
Amikor a felhasználók dedikált SQL-készletben kérdeznek le egy oszlopcentrikus táblát, az optimalizáló ellenőrzi az egyes szegmensekben tárolt minimális és maximális értékeket. A lekérdezési predikátum határain kívül eső szegmensek nem olvashatók lemezről memóriába. A lekérdezések gyorsabban befejeződhetnek, ha az olvasandó szegmensek száma és teljes mérete kicsi.
Note
Ez a cikk a dedikált Azure Synapse Analytics SQL-készletekre vonatkozik. Az SQL Server és más SQL-platformok rendezett oszlopcentrikus indexeivel kapcsolatos információkért lásd : Teljesítmény finomhangolás rendezett fürtözött oszlopcentrikus indexekkel.
Rendezett és nem rendezett klaszterezett oszlop adattárolós index
Alapértelmezés szerint minden indexbeállítás nélkül létrehozott tábla esetében egy belső összetevő (indexszerkesztő) létrehoz egy nem rendezett fürtözött oszlopcentrikus indexet (CCI). Az egyes oszlopokban lévő adatok külön CCI sorcsoport-szegmensbe lesznek tömörítve. Az egyes szegmensek értéktartományában vannak metaadatok, így a lekérdezési predikátum határain kívül eső szegmensek nem lesznek beolvasva a lemezről a lekérdezés végrehajtása során. A CCI a legmagasabb szintű adattömörítést biztosítja, és csökkenti az olvasáshoz szükséges szegmensek méretét, hogy a lekérdezések gyorsabban fussanak. Mivel azonban az indexszerkesztő nem rendezi az adatokat, mielőtt szegmensekbe tömörítené őket, egymást átfedő értéktartományokkal rendelkező szegmensek fordulhatnak elő, így a lekérdezések több szegmenst olvasnak be a lemezről, és tovább tart a befejezésük.
A rendezett fürtözött oszlopcentrikus indexek hatékony szegmens elhagyást tesznek lehetővé, ami sokkal gyorsabbá teszi a teljesítményt azáltal, hogy nagy mennyiségű, a lekérdezési feltételnek nem megfelelő rendezett adatot kihagy. Rendezett CCI létrehozásakor a dedikált SQL-készletmotor rendezi a memóriában lévő meglévő adatokat a rendelési kulcs(ok) alapján, mielőtt az indexszerkesztő indexszegmensekbe tömörítené őket. A rendezett adatok esetén a szegmensek átfedése csökken, így a lekérdezések hatékonyabb szegmenseliszorítást és ezáltal gyorsabb teljesítményt eredményeznek, mivel a lemezről beolvasandó szegmensek száma kisebb. Ha az összes adat egyszerre rendezhető a memóriában, akkor elkerülhető a szegmensek átfedése. Az adattárházakban lévő nagy táblák miatt ez a forgatókönyv nem gyakran fordul elő.
Egy oszlop szegmenstartományainak ellenőrzéséhez futtassa a következő parancsot a tábla nevével és az oszlop nevével:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Note
Egy rendezett CCI-táblában az azonos DML- vagy adatbetöltési műveletekből származó új adatok az adott kötegen belül vannak rendezve, a tábla összes adata között nincs globális rendezés. A felhasználók újraépíthetik a rendezett CCI-t a tábla összes adatának rendezéséhez. A dedikált SQL-készletben az oszlopbeli index újjáépítése offline művelet. Particionált táblák esetén az ÚJRAÉPÍTÉS egyszerre egy partícióval történik. Az újraépített partícióban lévő adatok "offline" állapotban vannak, és nem érhetők el, amíg az ÚJRAÉPÍTÉS befejeződik az adott partícióhoz.
Lekérdezési teljesítmény
A lekérdezések teljesítménye egy rendezett CCI-ből a lekérdezési mintáktól, az adatok méretétől, az adatok rendezettségétől, a szegmensek fizikai szerkezetétől, valamint a lekérdezés végrehajtásához választott DWU-tól és erőforrásosztálytól függ. A megrendelt CCI-tábla tervezésekor a felhasználóknak érdemes áttekinteniük ezeket a tényezőket, mielőtt kiválasztanák a rendezési oszlopokat.
Az összes ilyen mintát tartalmazó lekérdezések általában gyorsabban futnak a rendezett CCI-vel.
- A lekérdezések egyenlőségi, egyenlőtlenségi vagy tartománybeli predikátumokkal rendelkeznek.
- A predikátumoszlopok és a rendezett CCI-oszlopok megegyeznek.
Ebben a példában a T1 tábla egy fürtözött oszloptár indexet tartalmaz, amely Col_C, Col_B és Col_A sorrendjében van rendezve.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Az 1. és a 2. lekérdezés teljesítménye jobban hasznosíthatja a rendezett CCI-t, mint a többi lekérdezést, mivel ezek az összes rendezett CCI-oszlopra hivatkoznak.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Adatbetöltési teljesítmény
A rendezett CCI-táblákba való adatbetöltés teljesítménye hasonló egy particionált táblához. Az adatok rendezett CCI-táblába való betöltése hosszabb időt vehet igénybe, mint a nem rendezett CCI-táblák az adatrendező művelet miatt, de a lekérdezések később gyorsabban futhatnak a rendezett CCI-vel.
Íme egy példa az adatok különböző sémákkal rendelkező táblákba való betöltésének teljesítmény-összehasonlítására.
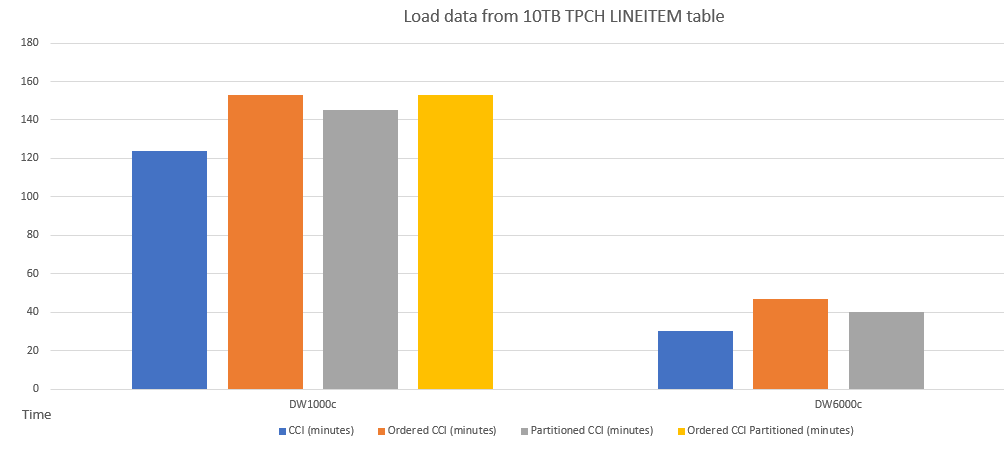
Íme egy példa a lekérdezési teljesítmény összehasonlítására a CCI és a rendezett CCI között.
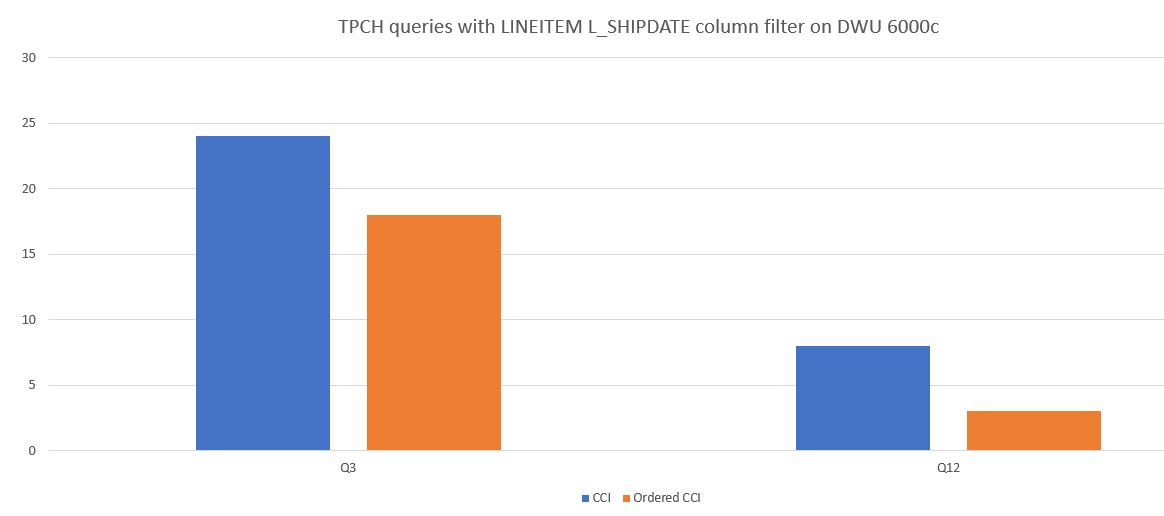
Szegmens átfedésének csökkentése
Az átfedésben lévő szegmensek száma a rendezendő adatok méretétől, a rendelkezésre álló memóriától és a párhuzamosság maximális fokától (MAXDOP) függ a rendezett CCI-létrehozás során. A következő stratégiák csökkentik a szegmensek átfedését a rendezett CCI létrehozásakor.
Az erőforrásosztály magasabb DWU-n való használatával
xlargerctöbb memóriát biztosít az adatrendezéshez, mielőtt az indexszerkesztő szegmensekbe tömörítené az adatokat. Az indexszegmensben az adatok fizikai helye nem módosítható. Nincs adatrendezés egy szegmensen belül vagy szegmensek között.Rendezett CCI létrehozása a .
OPTION (MAXDOP = 1)A rendezett CCI-létrehozáshoz használt szálak mindegyike az adatok egy részhalmazán működik, és helyileg rendezi őket. Nincs globális rendezés különböző szálak szerint rendezett adatok között. A párhuzamos szálak használata csökkentheti a rendezett CCI-k létrehozásának idejét, de több egymást átfedő szegmenst eredményez, mint egyetlen szál használata. Egyetlen szálas művelettel a legmagasabb tömörítési minőséget biztosítja. Például:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Note
Az Azure Synapse Analytics dedikált SQL-készleteiben jelenleg a MAXDOP beállítás csak a parancs használatával CREATE TABLE AS SELECT létrehozott rendezett CCI-táblákban támogatott. Rendezett CCI létrehozása CREATE INDEX vagy CREATE TABLE parancsokkal nem támogatja a MAXDOP beállítást. Ez a korlátozás nem vonatkozik az SQL Server 2022-es és újabb verzióira, ahol a MAXDOP paramétert megadhatja a CREATE INDEX vagy CREATE TABLE parancsokkal.
- Mielőtt betöltené őket a táblákba, rendezze előre az adatokat a rendezési kulcs(ok) alapján.
Íme egy példa egy rendezett CCI-táblaeloszlásra, amelynek nulla szegmense átfedésben van a fenti javaslatok alapján. A rendezett CCI-tábla egy DWU1000c adatbázisban jön létre a CTAS használatával egy 20 GB-os halomtáblából, MAXDOP 1 és xlargerc alkalmazásával. A CCI egy BIGINT oszlopra van rendezve, ismétlődő értékek nélkül.
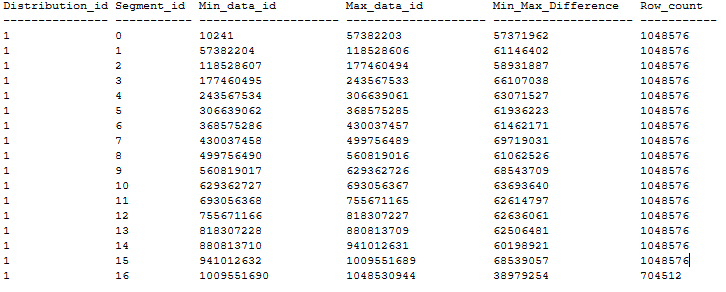
Rendezett CCI létrehozása nagy táblákon
A rendezett CCI létrehozása offline művelet. Partíciók nélküli táblák esetén az adatok csak a megrendelt CCI létrehozási folyamat befejezéséig lesznek elérhetők a felhasználók számára. Particionált táblák esetén, mivel a motor partíciónként hozza létre a megrendelt CCI-partíciót, a felhasználók továbbra is hozzáférhetnek az adatokhoz olyan partíciókban, ahol a rendezett CCI-létrehozás nem folyamatban van. Ezzel a beállítással minimalizálhatja az állásidőt a nagy táblákon történő rendelés szerinti CCI létrehozása során.
- Hozzon létre partíciókat a célként megadott nagy táblán (más néven
Table_A). - Hozzon létre egy üres rendezett CCI-táblát (más néven
Table_B) ugyanazzal a táblával és partíciós sémával, mint aTable_A. - Váltson át egy partícióról
Table_Aa másikraTable_B. - Futtassa a
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>a hozzárendelt partíció újraépítéséhez a következő helyen:Table_B. - Ismételje meg a 3. és a 4. lépést az egyes partíciók esetében a következőben
Table_A: . - Miután az összes partíció át lett váltva
Table_A-rólTable_B-re, és újjá lett építve, távolítsa elTable_A, majd nevezze átTable_B-atTable_A-re.
Tip
A dedikált, rendezett CCI-vel rendelkező SQL-készlettáblák esetében az ALTER INDEX REBUILD a következővel tempdbrendezi újra az adatokat: . Monitorozd tempdb az újraépítési műveletek során. Ha több tempdb helyre van szüksége, skálázza fel a tárhelykészletet. Az index újraépítésének befejezése után vertikálisan lefelé skálázható.
A rendezett CCI-vel rendelkező dedikált SQL-készlettáblák esetében az ALTER INDEX REORGANIZE nem rendezi újra az adatokat. Az adatok újrarendezéséhez használja az ALTER INDEX REBUILD parancsot.
A CCI rendezett karbantartásával kapcsolatos további információkért lásd a fürtözött oszlopcentrikus indexek optimalizálását ismertető témakört.
Funkcióbeli különbségek az SQL Server 2022 képességeiben
Az SQL Server 2022 (16.x) bevezette a rendezett fürtözött oszloptárolási indexeket, hasonlóan az Azure Synapse dedikált SQL-készletek szolgáltatásához.
- Jelenleg csak az SQL Server 2022 (16.x) és újabb verziók támogatják a fürtözött oszlopcentrikus bővített szegmenskiküszöbölési képességeket a karakterlánc-, bináris- és guid adattípusokhoz, valamint a datetimeoffset adattípust a kettőnél nagyobb nagyságrendhez. Korábban ez a szegmenskivezetés numerikus, dátum- és időadattípusokra, valamint a datetimeoffset adattípusra vonatkozik, amelynek mérete kisebb vagy egyenlő kettőnél.
- Jelenleg csak az SQL Server 2022 (16.x) és újabb verziók támogatják a fürtözött oszlopcentrikus sorcsoport eltávolítását például az előtagok
LIKEcolumn LIKE 'string%'esetében. A szegmensek eltávolítását nem támogatja a LIKE előtag nélküli használata, példáulcolumn LIKE '%string'.
További információkért tekintse meg a Columnstore Indexek újdonságai című témakört.
Examples
A. Rendezett oszlopok és sorrend szerinti ellenőrzés:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Az oszlopok sorszámának módosításához, oszlopok hozzáadásához vagy eltávolításához a sorrendi listáról, illetve a CCI-ről rendezett CCI-re való váltáshoz:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Következő lépések
- További fejlesztési tippekért tekintse meg a fejlesztés áttekintését.
- Oszlopalapú indexek: Áttekintés
- Az oszlopcentrikus indexek újdonságai
- oszlopalapú indexek – Tervezési útmutató
- Oszlopcentrikus indexek – Lekérdezési teljesítmény