Azure Stream Analytics-kimenet az Azure Cosmos DB-be
Az Azure Stream Analytics JSON formátumban képes adatokat kiadni az Azure Cosmos DB-be. Lehetővé teszi az adatarchiválást és az alacsony késésű lekérdezéseket a strukturálatlan JSON-adatokon. Ez a cikk a konfiguráció implementálásának ajánlott eljárásait ismerteti (Stream Analytics–Cosmos DB). Ha nem ismeri az Azure Cosmos DB-t, első lépésként tekintse meg az Azure Cosmos DB dokumentációját .
Feljegyzés
- A Stream Analytics jelenleg csak az SQL API-n keresztül támogatja az Azure Cosmos DB-hez való csatlakozást. Más Azure Cosmos DB API-k még nem támogatottak. Ha a Stream Analyticset más API-kkal létrehozott Azure Cosmos DB-fiókokra mutatja, előfordulhat, hogy az adatok nem lesznek megfelelően tárolva.
- Azt javasoljuk, hogy az Azure Cosmos DB kimenetként való használatakor állítsa a feladatát 1.2-es kompatibilitási szintre.
Az Azure Cosmos DB kimeneti célként való használatának alapjai
A Stream Analytics Azure Cosmos DB-kimenete lehetővé teszi a streamfeldolgozási eredmények JSON-kimenetként való írását az Azure Cosmos DB-tárolókba. A Stream Analytics nem hoz létre tárolókat az adatbázisban. Ehelyett előbb létre kell hoznia őket. Ezután szabályozhatja az Azure Cosmos DB-tárolók számlázási költségeit. A tárolók teljesítményét, konzisztenciáját és kapacitását közvetlenül is hangolhatja az Azure Cosmos DB API-k használatával. Az alábbi szakaszok részletesen ismertetik az Azure Cosmos DB tárolóbeállításait.
Konzisztencia, rendelkezésre állás és késés finomhangolása
Az alkalmazás követelményeinek megfelelően az Azure Cosmos DB lehetővé teszi az adatbázis és a tárolók finomhangolását, valamint a konzisztencia, a rendelkezésre állás, a késés és az átviteli sebesség közötti kompromisszumot.
Attól függően, hogy a forgatókönyv milyen szintű olvasási konzisztenciára van szüksége az olvasási és írási késéshez, választhat egy konzisztenciaszintet az adatbázisfiókban. Az átviteli sebességet a kérelemegységek (kérelemegységek) tárolón való skálázásával javíthatja. Az Azure Cosmos DB alapértelmezés szerint lehetővé teszi az egyes CRUD-műveletek szinkron indexelését a tárolóhoz. Ez a lehetőség egy másik hasznos lehetőség az írási/olvasási teljesítmény szabályozásához az Azure Cosmos DB-ben. További információkért tekintse át az adatbázis és a lekérdezés konzisztenciaszintjeinek módosítása című cikket.
Upserts a Stream Analyticsből
Az Azure Cosmos DB-vel való Stream Analytics-integráció lehetővé teszi rekordok beszúrását vagy frissítését a tárolóban egy adott dokumentumazonosító-oszlop alapján. Ezt a műveletet upsert-nek is nevezik. A Stream Analytics optimista upsert megközelítést használ. A frissítések csak akkor történnek meg, ha egy beszúrás dokumentumazonosító-ütközéssel meghiúsul.
Az 1.0-s kompatibilitási szinttel a Stream Analytics PATCH műveletként hajtja végre ezt a frissítést, így lehetővé teszi a dokumentum részleges frissítését. A Stream Analytics új tulajdonságokat ad hozzá, vagy növekményesen lecserél egy meglévő tulajdonságot. A JSON-dokumentumban a tömbtulajdonságok értékeinek módosítása azonban a teljes tömb felülírását eredményezi. Vagyis a tömb nincs egyesítve.
Az 1.2-vel az upsert viselkedése módosul a dokumentum beszúrásához vagy cseréjéhez. Ezt a viselkedést az 1.2-es kompatibilitási szintről szóló későbbi szakasz ismerteti.
Ha a bejövő JSON-dokumentum rendelkezik meglévő azonosítómezővel, a rendszer automatikusan ezt a mezőt használja az Azure Cosmos DB Dokumentumazonosító oszlopaként. Minden további írást így kezelünk, ami az alábbi helyzetek egyikéhez vezet:
- Az egyedi azonosítók beszúráshoz vezetnek.
- A duplikált azonosítók és a dokumentumazonosítók azonosítóra van állítva, és az upserthez vezetnek.
- A duplikált azonosítók és a dokumentumazonosító nem vezet hibához az első dokumentum után.
Ha menteni szeretné az összes dokumentumot, beleértve azokat is, amelyek duplikált azonosítóval rendelkeznek, nevezze át a lekérdezés azonosító mezőjét (az AS kulcsszó használatával). Hagyja, hogy az Azure Cosmos DB létrehozza az AZONOSÍTÓ mezőt, vagy cserélje le az azonosítót egy másik oszlop értékére (az AS kulcsszó vagy a Dokumentumazonosító beállítás használatával).
Adatparticionálás az Azure Cosmos DB-ben
Az Azure Cosmos DB automatikusan skálázza a partíciókat a számítási feladat alapján. Ezért azt javasoljuk, hogy korlátlan tárolókat használjon az adatok particionálásához. Amikor a Stream Analytics korlátlan tárolókba ír, annyi párhuzamos írót használ, mint az előző lekérdezési lépés vagy bemeneti particionálási séma.
Feljegyzés
Az Azure Stream Analytics csak a legfelső szintű partíciókulcsokkal rendelkező korlátlan tárolókat támogatja. Például /region támogatott. A beágyazott partíciókulcsok (például /region/name) nem támogatottak.
A partíciókulcs kiválasztásától függően a következő figyelmeztetés jelenhet meg:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
Fontos, hogy olyan partíciókulcs-tulajdonságot válasszon, amely számos különböző értékkel rendelkezik, és lehetővé teszi a számítási feladatok egyenletes elosztását ezen értékek között. A particionálás természetes összetevőjeként az azonos partíciókulcsot tartalmazó kérelmeket egyetlen partíció maximális átviteli sebessége korlátozza.
Az azonos partíciókulcs-értékhez tartozó dokumentumok tárolási mérete 20 GB-ra korlátozódik (a fizikai partícióméret korlátja 50 GB). Az ideális partíciókulcs az, amely gyakran jelenik meg szűrőként a lekérdezésekben, és elegendő számossággal rendelkezik ahhoz, hogy a megoldás méretezhető legyen.
A Stream Analytics-lekérdezésekhez használt partíciókulcsoknak és az Azure Cosmos DB-nek nem kell azonosnak lenniük. A teljes mértékben párhuzamos topológiák a Stream Analytics-lekérdezés partíciókulcsaként az Input Partition Key használatát javasolják, PartitionIdde előfordulhat, hogy nem ez a javasolt választás egy Azure Cosmos DB-tároló partíciókulcsához.
A partíciókulcs az Azure Cosmos DB tárolt eljárásaiban és eseményindítóiban lévő tranzakciók határa is. Válassza ki a partíciókulcsot, hogy a tranzakciókban együtt előforduló dokumentumok ugyanazt a partíciókulcs-értéket használhassák. A particionálás az Azure Cosmos DB-ben című cikk további részleteket tartalmaz a partíciókulcs kiválasztásáról.
Rögzített Azure Cosmos DB-tárolók esetén a Stream Analytics nem teszi lehetővé a vertikális fel- és kiskálázást, miután megteltek. Ezek felső korlátja 10 GB és 10 000 RU/s átviteli sebesség. Ha egy rögzített tárolóból korlátlan tárolóba szeretné migrálni az adatokat (például egy legalább 1000 RU/s-val és egy partíciókulcsmal rendelkezőt), használja az adatmigrálási eszközt vagy a változáscsatorna-kódtárat.
A több rögzített tárolóba való írás lehetősége elavult. Nem javasoljuk a Stream Analytics-feladat horizontális felskálázásához.
Továbbfejlesztett átviteli sebesség az 1.2-es kompatibilitási szinttel
Az 1.2-es kompatibilitási szinttel a Stream Analytics támogatja a natív integrációt az Azure Cosmos DB-be való tömeges íráshoz. Ez az integráció lehetővé teszi, hogy hatékonyan írjon az Azure Cosmos DB-be, miközben maximalizálja az átviteli sebességet és hatékonyan kezeli a szabályozási kéréseket.
A továbbfejlesztett írási mechanizmus új kompatibilitási szinten érhető el, mivel a upsert viselkedése eltér. Az 1.2 előtti szintek esetében a frissítési viselkedés a dokumentum beszúrása vagy egyesítése. Az 1.2-vel az upsert viselkedése módosul a dokumentum beszúrásához vagy cseréjéhez.
Az 1.2 előtti szintek esetében a Stream Analytics egy egyéni tárolt eljárással ömleszti a dokumentumokat partíciókulcsonként az Azure Cosmos DB-be. Itt egy köteg tranzakcióként van megírva. Még akkor is, ha egyetlen rekord átmeneti hibát (szabályozást) eredményez, a teljes köteget újra kell próbálkozni. Ez a viselkedés viszonylag lassúvá teszi a még ésszerű szabályozással rendelkező forgatókönyveket.
Az alábbi példa két azonos Stream Analytics-feladatot mutat be, amely ugyanabból az Azure Event Hubs-bemenetből olvas be. Mindkét Stream Analytics-feladat teljes mértékben particionált egy átmenő lekérdezéssel, és azonos Azure Cosmos DB-tárolókba írható. A bal oldali metrikák az 1.0 kompatibilitási szinttel konfigurált feladatból származnak. A jobb oldali metrikák 1.2-vel vannak konfigurálva. Az Azure Cosmos DB-tároló partíciókulcsa egy egyedi GUID, amely a bemeneti eseményből származik.
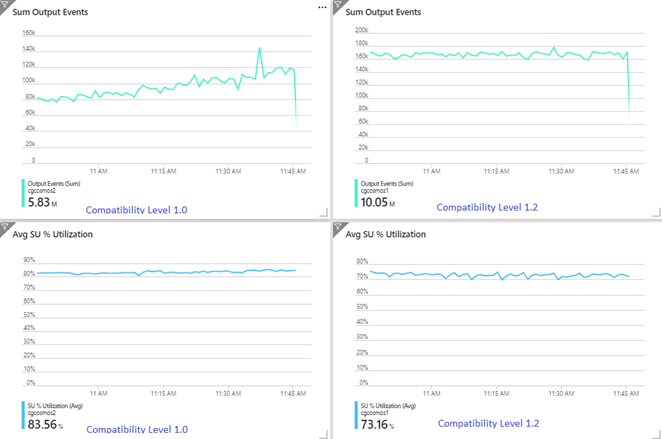
Az Event Hubs bejövő eseménysebessége kétszer magasabb, mint az Azure Cosmos DB-tárolók (20 000 kérelemegység) betöltésre van konfigurálva, ezért a szabályozás az Azure Cosmos DB-ben várható. Az 1.2-vel rendelkező feladat azonban folyamatosan magasabb átviteli sebességgel (kimeneti események percenként) és alacsonyabb átlagos SU%-os kihasználtsággal ír. A környezetben ez a különbség néhány további tényezőtől függ. Ezek a tényezők közé tartozik az eseményformátum kiválasztása, a bemeneti esemény/üzenet mérete, a partíciókulcsok és a lekérdezés.
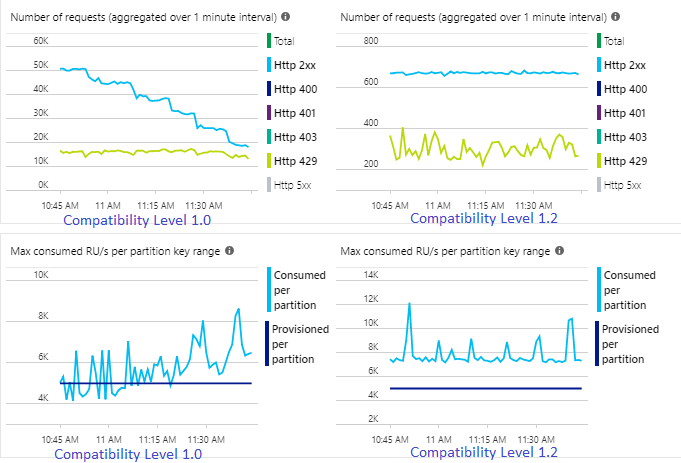
Az 1.2-vel a Stream Analytics intelligensebb az Azure Cosmos DB-ben elérhető átviteli sebesség 100%-ának felhasználásában, és kevés ismétlést biztosít a szabályozástól vagy a sebességkorlátozástól. Ez a viselkedés jobb élményt nyújt más számítási feladatok, például a tárolón egyszerre futó lekérdezések számára. Ha látni szeretné, hogy a Stream Analytics hogyan méretezhető fel fogadóként az Azure Cosmos DB-vel másodpercenként 1000-10 000 üzenethez, próbálja ki ezt az Azure-mintaprojektet.
Az Azure Cosmos DB-kimenet átviteli sebessége megegyezik az 1.0-val és az 1.1-gyel. Határozottan javasoljuk , hogy az 1.2-es kompatibilitási szintet használja a Stream Analyticsben az Azure Cosmos DB-vel.
Azure Cosmos DB-beállítások JSON-kimenethez
Ha az Azure Cosmos DB-t kimenetként használja a Stream Analyticsben, az a következő információkérést generálja.
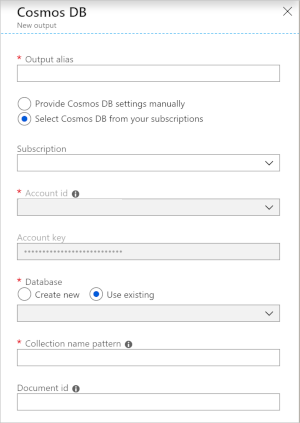
| Mező | Leírás |
|---|---|
| Kimeneti alias | Egy alias, amely erre a kimenetre hivatkozik a Stream Analytics-lekérdezésben. |
| Előfizetés | Az Azure-előfizetés. |
| Számlaazonosító | Az Azure Cosmos DB-fiók neve vagy végpont URI-ja. |
| Fiókkulcs | Az Azure Cosmos DB-fiók megosztott hozzáférési kulcsa. |
| Adatbázis | Az Azure Cosmos DB-adatbázis neve. |
| Tárolónév | A tároló neve, például MyContainer. Egy névvel ellátott MyContainer tárolónak léteznie kell. |
| Dokumentumazonosító | Opcionális. Az egyedi kulcsként használt kimeneti események oszlopneve, amelyen a beszúrási vagy frissítési műveleteknek alapulnia kell. Ha üresen hagyja, a program minden eseményt beszúr, és nincs frissítési lehetőség. |
Miután konfigurálta az Azure Cosmos DB-kimenetet, használhatja azt a lekérdezésben egy INTO utasítás céljaként. Ha így használ Azure Cosmos DB-kimenetet, a partíciókulcsot explicit módon kell beállítani.
A kimeneti rekordnak tartalmaznia kell egy kis- és nagybetűket megkülönböztető oszlopot, amelyet az Azure Cosmos DB partíciókulcsa után neveztek el. A nagyobb párhuzamosság érdekében az utasításhoz szükség lehet egy PARTÍCIÓ BY záradékra , amely ugyanazt az oszlopot használja.
Íme egy minta lekérdezés:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
Hibakezelés és újrapróbálkozások
Ha átmeneti hiba, a szolgáltatás elérhetetlensége vagy szabályozása történik, miközben a Stream Analytics eseményeket küld az Azure Cosmos DB-nek, a Stream Analytics határozatlan időre újrapróbálkozott a művelet sikeres befejezéséhez. De nem próbálja meg újrapróbálkozásokat a következő hibák esetén:
- Jogosulatlan (HTTP-hibakód: 401)
- NotFound (HTTP-hibakód: 404)
- Tiltott (HTTP-hibakód: 403)
- BadRequest (HTTP-hibakód: 400)
Gyakori problémák
A rendszer egyedi indexkorlátot ad hozzá a gyűjteményhez, és a Stream Analytics kimeneti adatai megsértik ezt a korlátozást. Győződjön meg arról, hogy a Stream Analytics kimeneti adatai nem sértik az egyedi korlátozásokat, és nem távolítják el a korlátozásokat. További információ: Egyedi kulcskorlátozások az Azure Cosmos DB-ben.
Az
PartitionKeyoszlop nem létezik.Az
Idoszlop nem létezik.