Stream Analytics-streamegységek megismerése és módosítása
A streamelési egység és a streamelési csomópont ismertetése
A streamelési egységek (SU-k) a Stream Analytics-feladatok végrehajtásához lefoglalt számítási erőforrásokat jelölik. Minél magasabb az SU-k száma, annál több processzor- és memória-erőforrás van lefoglalva a feladathoz. Ez a kapacitás lehetővé teszi, hogy a lekérdezési logikára összpontosítson, és absztrakciókat végez a Stream Analytics-feladat időben történő futtatásához szükséges hardver kezeléséhez.
Az Azure Stream Analytics két streamegység-struktúrát támogat: su V1 (elavult) és SU V2 (ajánlott).
Az SU V1 modell az ASA eredeti ajánlata, amelyben minden 6 termékváltozat egyetlen streamelési csomópontnak felel meg egy feladathoz. A feladatok 1 és 3 termékváltozattal is futtathatók, és ezek tört streamelési csomópontokkal felelnek meg. A skálázás a 6 SU-feladaton túl 6 lépésben történik, 12,18-ra, 24-re és annál többre úgy, hogy több streamelési csomópontot ad hozzá, amelyek elosztott számítási erőforrásokat biztosítanak.
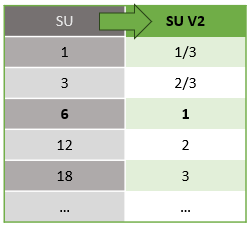
Az SU V2 modell (ajánlott) egy egyszerűsített struktúra, amely kedvező díjszabást biztosít ugyanahhoz a számítási erőforráshoz. Az SU V2 modellben az 1 SU V2 egy streamelési csomópontnak felel meg a feladathoz. A 2 SU V2-nek 2, 3–3 stb. felel meg. Az 1/3 és a 2/3 SU V2-vel rendelkező feladatok egy streamelési csomóponttal, de a számítási erőforrások töredékével is elérhetők. Az 1/3 és 2/3 SU V2 feladatok költséghatékony megoldást nyújtanak a kisebb léptékű számítási feladatokhoz.
A V1 és V2 streamelési egységek mögöttes számítási teljesítménye a következő:
Az SU díjszabásával kapcsolatos információkért látogasson el az Azure Stream Analytics díjszabási oldalára.
A streamelési egységek konverzióinak és alkalmazásuknak ismertetése
A streamelési egységek automatikusan átalakíthatók REST API-rétegből felhasználói felületre (Azure Portal és Visual Studio Code). Ezt az átalakítást a Tevékenységnaplóban is láthatja, ahol az SU-értékek másként jelennek meg, mint a felhasználói felületen. Ennek az az oka, hogy a REST API-mezők egész számokra korlátozódnak, és az ASA-feladatok támogatják a tört csomópontokat (1/3 és 2/3 streamegység). Az ASA felhasználói felülete 1/3, 2/3, 1, 2, 3, ... stb., míg a háttérrendszer (tevékenységnaplók, REST API-réteg) ugyanazokat az értékeket jeleníti meg 10-zel megszorozva, mint 3, 7, 10, 20, 30.
| Standard | Standard V2 (felhasználói felület) | Standard V2 (háttérrendszer, például naplók, Rest API stb.) |
|---|---|---|
| 0 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 0 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Ez lehetővé teszi számunkra, hogy ugyanazt a részletességet közvetítsünk, és kiküszöböljük a tizedesvesszőt a V2 termékváltozatok API-rétegében. Ez az átalakítás automatikus, és nincs hatással a feladat teljesítményére.
A használat és a memória kihasználtságának ismertetése
A kis késésű streamfeldolgozás érdekében az Azure Stream Analytics-feladatok minden feldolgozást a memóriában hajtanak végre. Ha elfogy a memória, a streamelési feladat meghiúsul. Emiatt egy éles feladat esetében fontos figyelni egy streamelési feladat erőforrás-használatát, és gondoskodni arról, hogy elegendő erőforrás legyen lefoglalva a feladatok 24/7-ben való futtatásához.
Az SU %kihasználtsági metrika, amely 0% és 100% között mozog, a számítási feladat memóriahasználatát ismerteti. A minimális erőforrásigényű streamelési feladatok esetében ez a metrika általában 10% és 20% között van. Ha az SU%-os kihasználtság magas (80% fölötti), vagy ha a bemeneti események háttérbe szorulnak (még alacsony SU%-os kihasználtság mellett is, mivel nem jeleníti meg a processzorhasználatot), a számítási feladat valószínűleg több számítási erőforrást igényel, ami megköveteli a streamelési egységek számának növelését. A legjobb, ha az SU-metrikát 80% alatt tartja, hogy figyelembe vegye az alkalmi kiugró értékeket. A megnövekedett számítási feladatokra való reagáláshoz és a streamelési egységek számának növeléséhez érdemes lehet 80%-os riasztást beállítani az SU-kihasználtság metrikájára. Emellett a vízjel késleltetése és a háttérbeli eseménymetrikák használatával is megállapíthatja, hogy van-e hatása.
Stream Analytics-streamegységek (SU-k) konfigurálása
Jelentkezzen be az Azure portálra.
Az erőforrások listájában keresse meg a skálázni kívánt Stream Analytics-feladatot, majd nyissa meg.
A feladatlap Konfigurálás fejléce alatt válassza a Méretezés lehetőséget. Feladat létrehozásakor a termékváltozatok alapértelmezett száma 1.
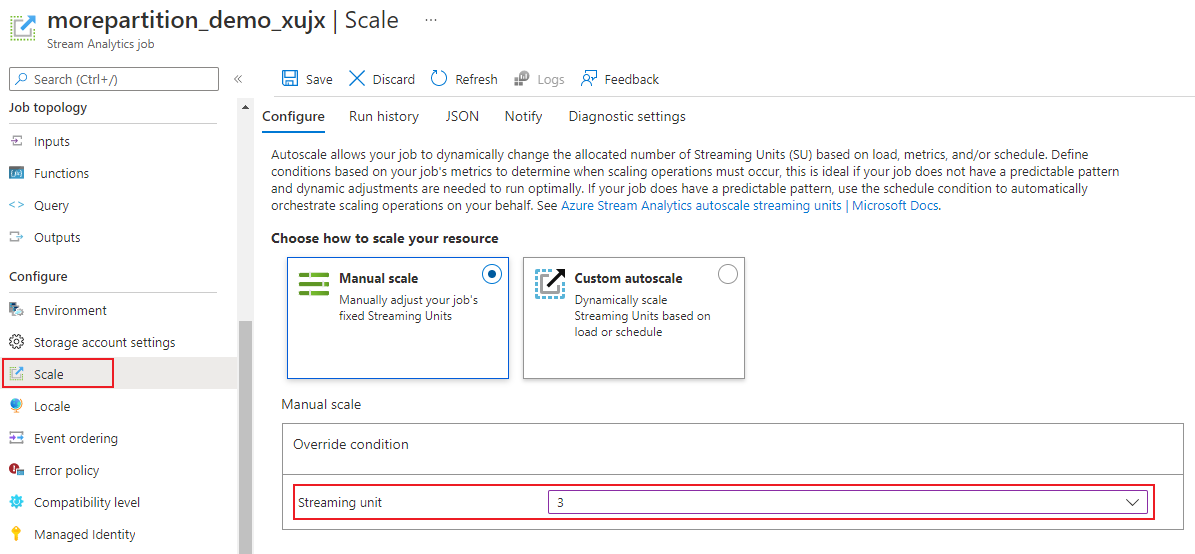
A feladat termékváltozatainak beállításához válassza a legördülő listában az SU lehetőséget. Figyelje meg, hogy egy adott SU-tartományra korlátozódik.
Futás közben módosíthatja a feladathoz rendelt termékváltozatok számát. Előfordulhat, hogy a feladat futtatásakor a feladat nem particionált kimenetet használ, vagy többlépéses lekérdezéssel rendelkezik, amely különböző PARTÍCIÓ SZERINTI értékekkel rendelkezik.
Feladat teljesítményének figyelése
Az Azure Portal használatával nyomon követheti a feladatok teljesítményével kapcsolatos metrikákat. A metrikák definíciójának megismeréséhez tekintse meg az Azure Stream Analytics feladatmetrikáit. A metrikák portálon történő monitorozásáról további információt a Stream Analytics-feladat monitorozása az Azure Portalon című témakörben talál.
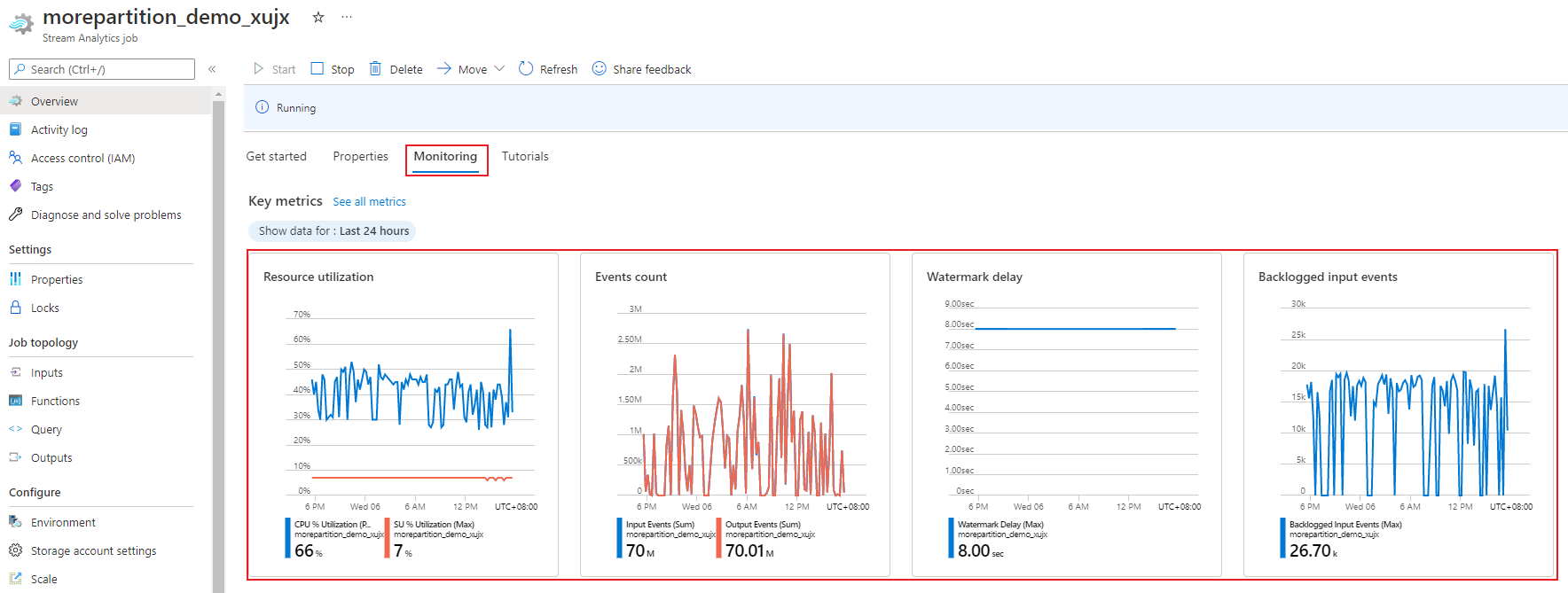
Számítsa ki a számítási feladat várható átviteli sebességét. Ha az átviteli sebesség a vártnál kisebb, hangolja a bemeneti partíciót, hangolja a lekérdezést, és adja hozzá a termékváltozatokat a feladathoz.
Hány SU-ra van szükség egy feladathoz?
Az adott feladathoz szükséges termékváltozatok számának kiválasztása a bemenetek partíciókonfigurációjától és a feladatban definiált lekérdezéstől függ. A Méretezés lapon beállíthatja a megfelelő számú termékváltozatot. Ajánlott a szükségesnél több termékváltozatot lefoglalni. A Stream Analytics feldolgozási motorja a késésre és az átviteli sebességre optimalizál a további memória kiosztásának költségén.
Általában az ajánlott eljárás az 1 SU V2-vel kezdeni az olyan lekérdezések esetében, amelyek nem használják a PARTITION BY-t. Ezután egy próba- és hibametódussal állapítsa meg az édes helyet, amelyben módosítja a termékváltozatok számát a reprezentatív mennyiségű adat átadása után, és vizsgálja meg az SU%kihasználtsági metrikát. A Stream Analytics-feladatok által használható streamelési egységek maximális száma a feladathoz definiált lekérdezés lépéseinek számától és az egyes lépések partícióinak számától függ. A korlátokról itt tudhat meg többet.
A megfelelő számú termékváltozat kiválasztásáról további információt az alábbi oldalon talál: Azure Stream Analytics-feladatok méretezése az átviteli sebesség növeléséhez.
Feljegyzés
Az adott feladathoz szükséges termékváltozatok száma a bemenetek partíciókonfigurációjától és a feladathoz definiált lekérdezéstől függ. Egy feladathoz legfeljebb a kvótát választhatja ki a termékváltozatokban. Az Azure Stream Analytics-előfizetés kvótájára vonatkozó információkért tekintse meg a Stream Analytics korlátait. Ha a kvótán túl szeretné növelni előfizetései termékváltozatait, lépjen kapcsolatba Microsoft ügyfélszolgálata. A feladatonkénti termékváltozatok érvényes értékei: 1/3, 2/3, 1, 2, 3 stb.
A streamelési egységek százalékos kihasználtságát növelő tényezők
A temporális (időorientált) lekérdezési elemek a Stream Analytics által biztosított állapotalapú operátorok alapvető készletei. A Stream Analytics belsőleg kezeli a műveletek állapotát a felhasználó nevében, a memóriahasználat kezelésével, a rugalmasság ellenőrzésével és az állapot helyreállításával a szolgáltatásfrissítések során. Annak ellenére, hogy a Stream Analytics teljes mértékben kezeli az állapotokat, számos ajánlott eljárásra vonatkozó javaslatot érdemes megfontolnia a felhasználóknak.
Vegye figyelembe, hogy az összetett lekérdezési logikával rendelkező feladatok magas SU%-os kihasználtsággal rendelkezhetnek akkor is, ha nem fogad folyamatosan bemeneti eseményeket. Ez a bemeneti és kimeneti események hirtelen megugrása után fordulhat elő. Ha a lekérdezés összetett, előfordulhat, hogy a feladat továbbra is fenntartja az állapotot a memóriában.
Az SU%-kihasználtság rövid időre hirtelen 0-ra csökkenhet, mielőtt visszatér a várt szintre. Ez átmeneti hibák vagy rendszer által kezdeményezett frissítések miatt történik. Ha a lekérdezés nem teljes mértékben párhuzamos, előfordulhat, hogy egy feladat streamelési egységeinek számának növelése nem csökkenti az SU%-os kihasználtságot.
A kihasználtság egy adott időszakban történő összehasonlítása során használjon eseménysebesség-metrikákat. Az InputEvents és a OutputEvents metrikák azt mutatják, hogy hány eseményt olvastak és dolgoztak fel. Vannak olyan metrikák, amelyek a hibaesemények számát is jelzik, például a deszerializálási hibákat. Amikor az események száma az időegységenként növekszik, az SU%a legtöbb esetben nő.
Állapotalapú lekérdezési logika időbeli elemekben
Az Azure Stream Analytics-feladat egyik egyedi képessége az állapotalapú feldolgozás, például az ablakos aggregátumok, az időbeli illesztések és az időbeli elemzési függvények végrehajtása. Ezek az operátorok megőrzik az állapotinformációkat. A lekérdezési elemek maximális ablakmérete hét nap.
A temporális ablak koncepciója több Stream Analytics-lekérdezési elemben is megjelenik:
Ablakos aggregátumok: csoportosítási szempont a csúszás, a felhúzás és a tolóablakok alapján
Időbeli illesztések: JOIN with DATEDIFF függvény
Időbeli elemzési függvények: ISFIRST, LAST és LAG limit duration
Az alábbi tényezők befolyásolják a Stream Analytics-feladatok által használt memóriát (a streamelési egységek metrikáinak egy részét):
Ablakos összesítések
Az ablakos összesítéshez felhasznált memória (állapotméret) nem mindig arányos közvetlenül az ablak méretével. Ehelyett a felhasznált memória arányos az adatok számosságával vagy az egyes időablakokban lévő csoportok számával.
A következő lekérdezésben például a lekérdezés számosságához társított clusterid szám.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Az előző lekérdezés magas számossága által okozott problémák megoldásához eseményeket küldhet az Event Hubsnak particionált clusteridmódon, és horizontálisan felskálázhatja a lekérdezést, lehetővé téve, hogy a rendszer külön dolgozza fel az egyes bemeneti partíciókat a PARTITION BY használatával, ahogyan az alábbi példában látható:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
A lekérdezés particionálása után több csomóponton is el van osztva. Ennek eredményeképpen az egyes csomópontokba érkező értékek száma clusterid csökken, ezáltal a csoport számossága operátoronként csökken.
Az Event Hubs-partíciókat a csoportosítási kulccsal kell particionelni, hogy ne legyen szükség csökkentési lépésre. További információkért tekintse meg az Event Hubs áttekintését.
Időbeli illesztések
Az időbeli illesztések felhasznált memóriája (állapotmérete) arányos az illesztés ideiglenes váltószobájában lévő események számával, ami az eseménybemenet sebessége és a váltószoba méretének szorzata. Más szóval az illesztések által felhasznált memória arányos a DateDiff időtartományával és az átlagos eseménysebesség szorzatával.
Az illesztés nem egyező eseményeinek száma befolyásolja a lekérdezés memóriakihasználtságát. A következő lekérdezés a kattintásokat generáló oldalmegjelenéseket keresi:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
Ebben a példában előfordulhat, hogy sok hirdetés jelenik meg, és kevesen kattintanak rá, és az összes eseményt az időablakban kell tartani. A felhasznált memória arányos az ablak méretével és az események gyakoriságával.
Ennek megoldásához küldjön eseményeket az Event Hubsnak az illesztőkulcsok (ebben az esetben az azonosító) által particionált eseményközpontba, és skálázza fel a lekérdezést úgy, hogy lehetővé teszi a rendszer számára az egyes bemeneti partíciók külön-külön történő feldolgozását a PARTITION BY használatával az alábbi módon:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
A lekérdezés particionálása után több csomóponton is el van osztva. Ennek eredményeképpen az egyes csomópontokba érkező események száma csökken, ezáltal csökkentve az illesztésablakban tárolt állapot méretét.
Időbeli elemzési függvények
A temporális elemzési függvények által felhasznált memória (állapotméret) arányos az eseménysebesség és az időtartam szorzatával. Az elemzési függvények által felhasznált memória nem arányos az ablak méretével, hanem a partíciók száma minden egyes időablakban.
A szervizelés hasonló az időbeli illesztéshez. A lekérdezést a PARTITION BY használatával skálázhatja fel.
Rendelésen kívüli puffer
A felhasználó konfigurálhatja a rendelésen kívüli puffer méretét az Eseményrendezés konfigurációs panelen. A puffer a bemenetek az ablak időtartamára való tárolására és átrendezésére szolgál. A puffer mérete arányos az eseménybemeneti sebesség és a rendelésen kívüli ablak méretének szorzatával. Az alapértelmezett ablakméret 0.
A rendelésen kívüli puffer túlcsordulásának elhárításához horizontálisan felskálázza a lekérdezést a PARTITION BY használatával. A lekérdezés particionálása után több csomóponton is el van osztva. Ennek eredményeképpen az egyes csomópontokba érkező események száma csökken, ezáltal csökken az egyes átrendező pufferekben lévő események száma.
Bemeneti partíciók száma
A feladatbemenet minden bemeneti partíciója rendelkezik pufferrel. Minél nagyobb a bemeneti partíciók száma, annál több erőforrást használ fel a feladat. Az Azure Stream Analytics minden egyes streamegységhez körülbelül 7 MB/s bemenetet képes feldolgozni. Ezért optimalizálhatja a Stream Analytics streamelési egységeinek számát és az eseményközpont partícióinak számát.
Általában egy 1/3-as streamelési egységgel konfigurált feladat elegendő két partícióval rendelkező eseményközponthoz (ami az eseményközpont minimális értéke). Ha az eseményközpont több partícióval rendelkezik, a Stream Analytics-feladat több erőforrást használ fel, de nem feltétlenül használja az Event Hubs által biztosított többletteljesítményt.
Az 1 V2-alapú streamelési egységgel rendelkező feladatokhoz 4 vagy 8 partícióra lehet szükség az eseményközpontból. Kerülje azonban a túl sok szükségtelen partíciót, mivel ez túlzott erőforrás-használatot okoz. Például egy 16 partícióval rendelkező vagy annál nagyobb eseményközpont egy Stream Analytics-feladatban, amelynek 1 streamegysége van.
Referenciaadatok
Az ASA-ban lévő referenciaadatok a gyors keresés érdekében betöltődnek a memóriába. Az aktuális implementációval minden referenciaadattal rendelkező illesztési művelet megőrzi a referenciaadatok másolatát a memóriában, még akkor is, ha ugyanazokat a referenciaadatokat többször is összekapcsolja. A PARTITION BY-val rendelkező lekérdezések esetében minden partíció rendelkezik a referenciaadatok egy-egy példányával, így a partíciók teljesen leválasztva vannak. A multiplikátor effektussal a memóriahasználat gyorsan magas lehet, ha több partícióval többször csatlakozik referenciaadatokhoz.
UDF-függvények használata
UDF-függvény hozzáadásakor az Azure Stream Analytics betölti a JavaScript-futtatókörnyezetet a memóriába. Ez hatással lesz az SU%.
Következő lépések
- Párhuzamos lekérdezések létrehozása az Azure Stream Analyticsben
- Az Azure Stream Analytics-feladatok skálázása az átviteli sebesség növelése érdekében
- Azure Stream Analytics-feladatmetrikák
- Az Azure Stream Analytics feladatmetrikáinak dimenziói
- Stream Analytics-feladat monitorozása az Azure Portallal
- Stream Analytics-feladatok teljesítményének elemzése metrikák dimenzióival
- A streamelési egységek ismertetése és módosítása