A Netezza-migrálások tervezése és teljesítménye
Ez a cikk egy hétrészes sorozat első része, amely útmutatást nyújt a Netezza-ból az Azure Synapse Analyticsbe való migráláshoz. A cikk középpontjában a tervezés és a teljesítmény ajánlott eljárásai kerülnek.
Áttekintés
Az IBM támogatásának megszűnése miatt a Netezza adattárházrendszerek számos meglévő felhasználója szeretné kihasználni a modern felhőkörnyezetek által nyújtott innovációkat. A szolgáltatásként nyújtott infrastruktúra (IaaS) és a szolgáltatásként nyújtott platform (PaaS) felhőkörnyezetek lehetővé teszik az infrastruktúra-karbantartáshoz és a platformfejlesztéshez hasonló feladatokat a felhőszolgáltatónak.
Tipp.
Az Azure-környezet a képességek és eszközök átfogó készletét tartalmazza, nem csupán egy adatbázist.
Bár a Netezza és az Azure Synapse Analytics egyaránt olyan SQL-adatbázis, amely nagymértékben párhuzamos feldolgozási (MPP) technikákat használ a rendkívül nagy adatmennyiségek nagy lekérdezési teljesítményének eléréséhez, a megközelítésben van néhány alapvető különbség:
Az örökölt Netezza-rendszereket gyakran telepítik a helyszínen, és saját hardvert használnak, míg az Azure Synapse felhőalapú, és Azure Storage- és számítási erőforrásokat használ.
A Netezza-konfiguráció frissítése jelentős feladat, amely extra fizikai hardvert és esetleg hosszadalmas adatbázis-újrakonfigurálást, illetve memóriaképet és újratöltést foglal magában. Mivel a tárolási és számítási erőforrások különállóak az Azure-környezetben, és rugalmas skálázási képességgel rendelkeznek, ezek az erőforrások egymástól függetlenül felfelé vagy lefelé skálázhatók.
Szükség szerint szüneteltetheti vagy átméretezheti az Azure Synapse-t az erőforrás-használat és a költségek csökkentése érdekében.
A Microsoft Azure egy globálisan elérhető, rendkívül biztonságos, skálázható felhőkörnyezet, amely magában foglalja az Azure Synapse-t, valamint a támogató eszközök és képességek ökoszisztémáját. A következő diagram az Azure Synapse ökoszisztémáját foglalja össze.
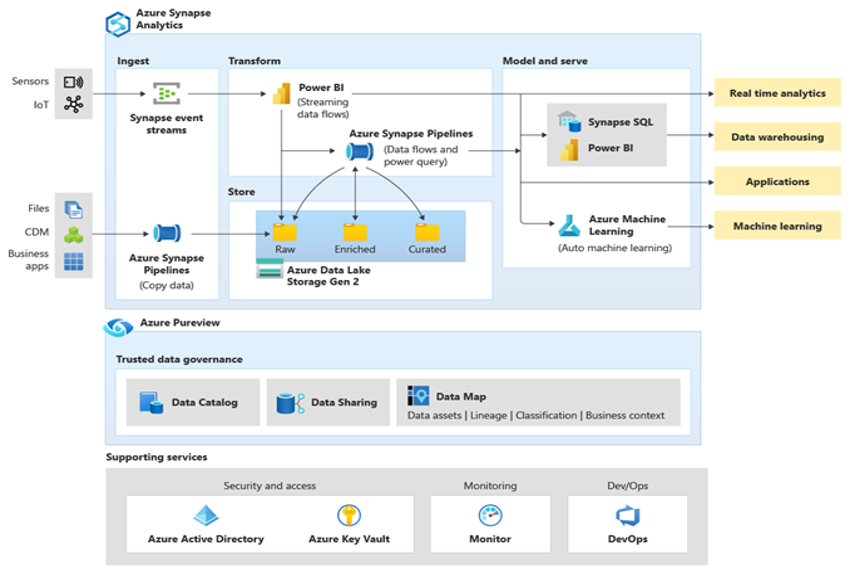
Az Azure Synapse a legkiválóbb relációs adatbázis-teljesítményt nyújt olyan technikákkal, mint az MPP és az automatizált gyorsítótárazás több szintje a gyakran használt adatokhoz. Ezeknek a technikáknak az eredményeit olyan független teljesítménymutatókban tekintheti meg, mint amilyen például a GigaOm által nemrég futtatott módszer, amely összehasonlítja az Azure Synapse-t más népszerű felhőalapú adattárház-ajánlatokkal. Az Azure Synapse-környezetbe migrált ügyfelek számos előnnyel járnak, többek között az alábbiakat:
Jobb teljesítmény és ár/teljesítmény.
Nagyobb rugalmasság és rövidebb érték.
Gyorsabb kiszolgálótelepítés és alkalmazásfejlesztés.
Rugalmas méretezhetőség – csak a tényleges használatért kell fizetnie.
Továbbfejlesztett biztonság/megfelelőség.
Csökkentett tárolási és vészhelyreállítási költségek.
Alacsonyabb általános TCO, jobb költségkontroll és egyszerűsített működési kiadások (OPEX).
Az előnyök maximalizálása érdekében migráljon új vagy meglévő adatokat és alkalmazásokat az Azure Synapse platformra. A migrálás számos szervezetben magában foglalja egy meglévő adattárház áthelyezését egy régi helyszíni platformról, például a Netezza-ból az Azure Synapse-ba. Magas szinten a migrálási folyamat az alábbi lépéseket tartalmazza:
Előkészítés 🡆
Hatókör definiálása – migrálandó.
Adatok és folyamatok leltárának összeállítása a migráláshoz.
Adatmodell-módosítások definiálása (ha van ilyen).
Forrásadat-kinyerési mechanizmus definiálása.
Azonosítsa a használni kívánt azure-beli és külső eszközöket és funkciókat.
Az új platformon korán betanítsa a személyzetet.
Az Azure-célplatform beállítása.
Migrálás 🡆
Kezdjen kicsi és egyszerű.
Ahol csak lehetséges, automatizálja.
A migrálási erőfeszítések csökkentése érdekében használja az Azure beépített eszközeit és szolgáltatásait.
Táblák és nézetek metaadatainak migrálása.
A karbantartandó előzményadatok migrálása.
Tárolt eljárások és üzleti folyamatok migrálása vagy újrabontása.
ETL/ELT növekményes terhelési folyamatok migrálása vagy újrabontása.
Migrálás után
A folyamat minden szakaszának figyelése és dokumentálása.
A megszerzett tapasztalatokkal sablont hozhat létre a jövőbeli migrálásokhoz.
Szükség esetén újra megtervezi az adatmodellt (új platformteljesítmény és méretezhetőség használatával).
Alkalmazások és lekérdezési eszközök tesztelése.
Mérje fel és optimalizálja a lekérdezési teljesítményt.
Ez a cikk általános információkat és irányelveket tartalmaz a teljesítményoptimalizáláshoz, amikor egy adattárházat egy meglévő Netezza-környezetből az Azure Synapse-ba migrál. A teljesítményoptimalizálás célja, hogy a séma migrálása után az Azure Synapse-ban ugyanazt vagy jobb adatraktár-teljesítményt érje el.
Kialakítási szempontok
Migrálás hatóköre
Amikor Netezza-környezetből való migrálásra készül, fontolja meg az alábbi migrálási lehetőségeket.
Válassza ki a kezdeti migrálás számítási feladatát
Az örökölt Netezza-környezetek általában idővel fejlődtek, hogy több területet és vegyes számítási feladatokat foglaljanak magukba. Amikor eldönti, hogy hol kezdjen egy migrálási projekttel, válasszon egy területet, ahol a következő lehetőségek közül választhat:
Az Azure Synapse-be való migrálás életképességének igazolása az új környezet előnyeinek gyors biztosításával.
Lehetővé teszi a házon belüli műszaki személyzet számára, hogy releváns tapasztalatokat szerezzen azokkal a folyamatokkal és eszközökkel kapcsolatban, amelyeket más területek migrálásakor fognak használni.
Hozzon létre egy sablont a forrás Netezza-környezetre és a már meglévő eszközökre és folyamatokra vonatkozó további migrálásokhoz.
A Netezza-ból való kezdeti migrálásra jó jelölt, környezeti támogatás az előző elemeket, és:
Online tranzakciófeldolgozási (OLTP) számítási feladat helyett BI/Analytics számítási feladatot implementál.
Van egy adatmodellje, például csillag- vagy hópehelyséma, amely minimális módosítással migrálható.
Tipp.
Hozzon létre egy leltárt az áttelepítendő objektumokról, és dokumentálja az áttelepítési folyamatot.
A kezdeti migrálás során a migrált adatok mennyiségének elég nagynak kell lennie az Azure Synapse-környezet képességeinek és előnyeinek bemutatásához, de nem túl nagy az érték gyors bemutatásához. Az 1–10 terabájtos tartományban jellemző a méret.
A kezdeti migrálási projektnél minimalizálja a kockázatot, az erőfeszítést és a migrálási időt, hogy gyorsan láthassa az Azure-felhőkörnyezet előnyeit. Az átemeléses és a fázisalapú migrálási megközelítés egyaránt csak az adatpiacokra korlátozza a kezdeti migrálás hatókörét, és nem foglalkozik az olyan szélesebb körű migrálási szempontokkal, mint az ETL-migrálás és az előzményadatok migrálása. Ezeket a szempontokat azonban a projekt későbbi szakaszaiban is kezelheti, miután a migrált adattároló réteget újra kitöltötte az adatokkal és a szükséges buildelési folyamatokkal.
A migrálás emelése és váltása a fázisos megközelítéssel szemben
A migrálásnak általában két típusa van, függetlenül a tervezett migrálás céljától és hatókörétől: az átemelés és az eltolódás a jelenlegi állapotban, és egy olyan fázisalapú megközelítés, amely magában foglalja a változásokat.
Átemelés
Az átemeléses migrálás során a meglévő adatmodellek, például a csillagséma változatlanul migrálva lesznek az új Azure Synapse-platformra. Ez a megközelítés minimalizálja a kockázatokat és a migrálási időt azáltal, hogy csökkenti az Azure-felhőkörnyezetbe való áttérés előnyeinek eléréséhez szükséges munkát. A lift és a shift migrálása jó választás az alábbi forgatókönyvekhez:
- Meglévő Netezza-környezettel rendelkezik, amely egyetlen áttelepítendő adattovábbítmánnyal rendelkezik, vagy
- Meglévő Netezza-környezete már jól megtervezett csillag- vagy hópehelysémában lévő adatokkal rendelkezik, vagy
- A modern felhőkörnyezetbe való áttérés idő- és költségterheléssel jár.
Tipp.
Az emelés és a váltás jó kiindulópont, még akkor is, ha a következő fázisok módosításokat vezetnek be az adatmodellben.
A módosításokat magában foglaló fázisos megközelítés
Ha egy régi adattárház hosszú ideig fejlődött, előfordulhat, hogy újra kell terveznie a szükséges teljesítményszintek fenntartásához. Előfordulhat, hogy újra kell terveznie, hogy támogassa az új adatokat, például az IoT-streameket. Az újratervezési folyamat részeként migráljon az Azure Synapse-be, hogy kihasználhassa a méretezhető felhőkörnyezet előnyeit. A migrálás a mögöttes adatmodell módosítását is magában foglalhatja, például az Inmon-modellről az adattárolóra való áttérést.
A Microsoft azt javasolja, hogy a meglévő adatmodellt az Azure-ba helyezhesse át, és az Azure-környezet teljesítményének és rugalmasságának használatával alkalmazza az újratervezési módosításokat. Így az Azure képességeivel anélkül hajthatja végre a módosításokat, hogy az hatással lenne a meglévő forrásrendszerre.
Metaadat-alapú migrálás implementálása az Azure Data Factory használatával
Az Azure-környezet képességeivel automatizálhatja és vezényelheti a migrálási folyamatot. Ez a megközelítés minimálisra csökkenti a meglévő Netezza-környezet teljesítménybeli találatait, amelyek esetleg már a kapacitás közelében futnak.
Az Azure Data Factory egy felhőalapú adatintegrációs szolgáltatás, amely támogatja az adatvezérelt munkafolyamatok létrehozását a felhőben, amelyek koordinálják és automatizálják az adatáthelyezést és az adatátalakítást. A Data Factory használatával olyan adatvezérelt munkafolyamatokat (folyamatokat) hozhat létre és ütemezhet, amelyek különböző adattárakból származó adatokat használnak be. A Data Factory olyan számítási szolgáltatások használatával tudja feldolgozni és átalakítani az adatokat, mint az Azure HDInsight Hadoop, a Spark, az Azure Data Lake Analytics és az Azure Machine Learning.
Amikor Data Factory-létesítményeket szeretne használni a migrálási folyamat kezeléséhez, hozzon létre olyan metaadatokat, amelyek felsorolják az összes migrálni kívánt adattáblát és azok helyét.
Tervezési különbségek a Netezza és az Azure Synapse között
Ahogy korábban említettük, a Netezza és az Azure Synapse Analytics-adatbázisok megközelítésében van néhány alapvető különbség, és ezeket a különbségeket a következő szakaszban tárgyaljuk.
Több adatbázis és egyetlen adatbázis és séma
A Netezza-környezet gyakran több különálló adatbázist tartalmaz. Lehetnek például különálló adatbázisok a következőkhöz: adatbetöltési és előkészítési táblák, alapvető raktártáblák és adatpiacok (más néven szemantikai réteg). Az ETL- vagy ELT-folyamatfolyamatok adatbázisközi illesztéseket implementálhatnak, és adatokat helyezhetnek át a különálló adatbázisok között.
Ezzel szemben az Azure Synapse-környezet egyetlen adatbázist tartalmaz, és sémákkal elválasztja a táblákat logikailag különálló csoportokra. Javasoljuk, hogy a cél Azure Synapse-adatbázisban található sémák sorozatával utánozza a Netezza-környezetből migrált különálló adatbázisokat. Ha a Netezza-környezet már használ sémákat, előfordulhat, hogy új elnevezési konvenciót kell használnia, amikor áthelyezi a meglévő Netezza-táblákat és -nézeteket az új környezetbe. Összefűzheti például a meglévő Netezza-sémát és táblaneveket az új Azure Synapse-táblanévvel, és az új környezetben sémanevek használatával megtarthatja az eredeti különálló adatbázisneveket. Ha a sémakonszolidáció elnevezése pontokkal rendelkezik, az Azure Synapse Spark problémákat tapasztalhat. Bár a logikai struktúrák fenntartásához sql-nézeteket használhat az alapul szolgáló táblákon, ennek a megközelítésnek vannak lehetséges hátrányai:
Az Azure Synapse nézetei írásvédettek, ezért az adatok frissítésének az alapul szolgáló alaptáblákon kell végbe mennie.
Előfordulhat, hogy már létezik egy vagy több nézetréteg, és egy további nézetréteg hozzáadása hatással lehet a teljesítményre és a támogatottságra, mert a beágyazott nézetek hibaelhárítása nehéz.
Tipp.
Több adatbázist egyesíthet egyetlen adatbázisba az Azure Synapse-ban, és sémanevek használatával logikailag elválaszthatja a táblákat.
Táblázatokkal kapcsolatos szempontok
Ha táblákat migrál különböző környezetek között, általában csak a nyers adatok és a fizikai migrálást leíró metaadatok. A forrásrendszer más adatbáziselemei, például az indexek általában nem lesznek migrálva, mert szükségtelenek vagy más módon implementálhatók az új környezetben.
A forráskörnyezet teljesítményoptimalizálásai( például indexek) jelzik, hogy hová adhat teljesítményoptimalizálást az új környezetben. Ha például a forrás Netezza környezetben lévő lekérdezések gyakran használnak zónatérképeket, az azt sugallja, hogy egy nem fürtözött indexet kell létrehozni az Azure Synapse-ban. Más natív teljesítményoptimalizálási technikák, például a táblareplikáció alkalmazhatóbbak lehetnek, mint a hasonló indexek egyenes létrehozása.
Tipp.
A meglévő indexek a migrált raktárban lévő indexelési jelöltekre utalnak.
Nem támogatott Netezza-adatbázisobjektum-típusok
A Netezza-specifikus funkciók gyakran lecserélhetők az Azure Synapse szolgáltatásaira. Egyes Netezza-adatbázis-objektumok azonban nem támogatottak közvetlenül az Azure Synapse-ban. A nem támogatott Netezza-adatbázis-objektumok alábbi listája azt ismerteti, hogyan érhet el egyenértékű funkciókat az Azure Synapse-ban.
Zónaleképek: a Netezza-ban a rendszer automatikusan létrehozza és karbantartja a zónaleképeket a következő oszloptípusokhoz, és a lekérdezési időben a beolvasandó adatok mennyiségének korlátozására szolgálnak:
INTEGER8 bájt vagy annál kisebb hosszúságú oszlopok.- Temporális oszlopok, például
DATE: ,TIMEésTIMESTAMP. CHARoszlopokat, ha egy materializált nézet része, és aORDER BYzáradékban szerepel.
Az NZ-eszközkészlet részét képező segédprogrammal megtudhatja, hogy mely oszlopok rendelkeznek zónaleképeztetésekkel
nz_zonemap. Az Azure Synapse nem tartalmaz zónaleképezéseket, de hasonló eredményeket érhet el más, felhasználó által definiált indextípusok és/vagy particionálás használatával.Csoportosított alaptáblák (CBT): a Netezza-ban a CBT-ket gyakran használják ténytáblákhoz, amelyek rekordmilliárdokat tartalmazhatnak. Egy ilyen hatalmas tábla vizsgálata jelentős feldolgozási időt igényel, mivel a megfelelő rekordok lekéréséhez teljes táblázatvizsgálatra lehet szükség. A korlátozó CBT-k rekordjainak rendszerezése lehetővé teszi, hogy a Netezza azonos vagy közeli mértékben csoportosítsa a rekordokat. Ez a folyamat zónatérképeket is létrehoz, amelyek javítják a teljesítményt a vizsgálandó adatok mennyiségének csökkentésével.
Az Azure Synapse-ban hasonló hatást érhet el particionálással és/vagy más indexek használatával.
Materializált nézetek: A Netezza támogatja a materializált nézeteket, és azt javasolja, hogy egy vagy több materializált nézetet használjon több oszlopot tartalmazó nagyméretű táblákhoz, ha a lekérdezésekben csak néhány oszlopot használnak rendszeresen. A rendszer automatikusan frissíti a materializált nézeteket az alaptábla adatainak frissítésekor.
Az Azure Synapse támogatja a materializált nézeteket, ugyanazokkal a funkciókkal, mint a Netezza.
Netezza adattípus-leképezés
A Legtöbb Netezza-adattípus közvetlen egyenértékű az Azure Synapse-ban. Az alábbi táblázat a Netezza-adattípusok Azure Synapse-ba való leképezésének ajánlott megközelítését mutatja be.
| Netezza adattípus | Azure Synapse-adattípus |
|---|---|
| BIGINT | BIGINT |
| BINÁRIS VÁLTOZÓ(n) | VARBINARY(n) |
| LOGIKAI | BIT |
| BYTEINT | TINYINT |
| KARAKTER VÁLTOZÓ(n) | VARCHAR(n) |
| KARAKTER(n) | CHAR(n) |
| DÁTUM | DÁTUM(dátum) |
| DECIMÁLIS(p;s) | DECIMÁLIS(p;s) |
| DUPLA PONTOSSÁG | LEBEG |
| FLOAT(n) | FLOAT(n) |
| EGÉSZ SZÁM | INT |
| INTERVALLUM | Az INTERVAL-adattípusok jelenleg nem támogatottak közvetlenül az Azure Synapse-ban, de időbeli függvények( például DATEDIFF) használatával kiszámíthatók. |
| PÉNZ | PÉNZ |
| NEMZETI KARAKTER VÁLTOZÓ(n) | NVARCHAR(n) |
| NATIONAL CHARACTER(n) | NCHAR(n) |
| NUMERIKUS(p;s) | NUMERIKUS(p;s) |
| VALÓDI | VALÓDI |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Az Azure Synapse jelenleg nem támogatja az olyan térbeli adattípusokat, mint például a ST_GEOMETRY, de az adatok VARCHAR vagy VARBINARY formátumban tárolhatók. |
| TIME | TIME |
| IDŐZÓNA | DATETIMEOFFSET |
| TIMESTAMP | DATETIME |
Tipp.
A migrálás előkészítési fázisában mérje fel a nem támogatott adattípusok számát és típusát.
A külső gyártók eszközöket és szolgáltatásokat kínálnak a migrálás automatizálásához, beleértve az adattípusok leképezését is. Ha egy harmadik féltől származó ETL-eszköz már használatban van a Netezza környezetben, az eszközzel implementálhatja a szükséges adatátalakításokat.
AZ SQL DML szintaxisbeli eltérései
Az SQL DML szintaxisbeli különbségei vannak a Netezza SQL és az Azure Synapse T-SQL között. Ezeket a különbségeket részletesen tárgyaljuk a Netezza-migrálások SQL-problémáinak minimalizálása című témakörben.
STRPOS: a Netezza-ban aSTRPOSfüggvény egy sztringen belüli részsztring pozícióját adja vissza. Az Azure Synapse egyenértékű függvénye az argumentumok fordított sorrendjével vanCHARINDEX. A Netezza példáulSELECT STRPOS('abcdef','def')...egyenértékűSELECT CHARINDEX('def','abcdef')...az Azure Synapse-val.AGE: A Netezza támogatja azAGEoperátort, hogy két időérték közötti intervallumot adjon meg, például időbélyegeket vagy dátumokat, például:SELECT AGE('23-03-1956','01-01-2019') FROM.... Az Azure Synapse-ban az intervallum lekérésére használhatóDATEDIFF, például:SELECT DATEDIFF(day, '1956-03-26','2019-01-01') FROM.... Jegyezze fel a dátumábrázolás sorrendjét.NOW(): A Netezza az Azure Synapse-ban való megjelenítésreCURRENT_TIMESTAMPhasználjaNOW().
Függvények, tárolt eljárások és sorozatok
Amikor egy adattárházat kiforrott környezetből, például a Netezza-ból migrál, valószínűleg az egyszerű tábláktól és nézetektől eltérő elemeket kell migrálnia. Ellenőrizze, hogy az Azure-környezetben lévő eszközök helyettesíthetik-e a függvények, a tárolt eljárások és a szekvenciák funkcióit, mivel általában hatékonyabb a beépített Azure-eszközök használata, mint az Azure Synapse elemeinek újrakódolása.
Az előkészítési fázis részeként hozzon létre egy leltárt az áttelepítendő objektumokról, határozzon meg egy kezelési módszert, és foglalja le a megfelelő erőforrásokat a migrálási tervben.
Az adatintegrációs partnerek olyan eszközöket és szolgáltatásokat kínálnak, amelyek automatizálják a függvények, a tárolt eljárások és a szekvenciák migrálását.
A következő szakaszok a függvények, a tárolt eljárások és a szekvenciák migrálását is ismertetik.
Functions
A legtöbb adatbázis-termékhez hasonlóan a Netezza is támogatja a rendszer- és felhasználó által definiált függvényeket az SQL-implementációban. Ha régi adatbázisplatformot migrál az Azure Synapse-ba, a gyakori rendszerfüggvények általában módosítás nélkül migrálhatók. Egyes rendszerfüggvények szintaxisa kissé eltérő lehet, de a szükséges módosítások automatizálhatók.
Netezza rendszerfüggvények vagy tetszőleges, az Azure Synapse-ban nem megfelelő felhasználó által definiált függvények esetén ezeket a függvényeket egy célkörnyezeti nyelv használatával kell újrakódolni. A Netezza felhasználó által definiált függvények nzlua vagy C++ nyelven kódoltak. Az Azure Synapse a Transact-SQL nyelvet használja a felhasználó által definiált függvények implementálásához.
Tárolt eljárások
A legtöbb modern adatbázis-termék támogatja az adatbázisokon belüli tárolási eljárásokat. A Netezza erre a célra biztosítja a Postgres PL/pgSQL-en alapuló NZPLSQL-nyelvet. A tárolt eljárások általában SQL-utasításokat és eljárási logikát is tartalmaznak, és adatokat vagy állapotot adnak vissza.
Az Azure Synapse támogatja a tárolt eljárásokat a T-SQL használatával, ezért a migrált tárolt eljárásokat ezen a nyelven kell újrakódolnia.
Sorozatok
A Netezza-ban a szekvencia egy elnevezett adatbázis-objektum, amely a következő használatával CREATE SEQUENCEjön létre: . A sorozat egyedi numerikus értékeket biztosít a NEXT VALUE FOR metóduson keresztül. A létrehozott egyedi számokat helyettesítő kulcsértékként használhatja az elsődleges kulcsokhoz.
Az Azure Synapse nem implementálCREATE SEQUENCE, de identitásoszlopokkal vagy SQL-kóddal implementálhatja a sorozat következő sorszámát generáló sorozatokat.
Metaadatok és adatok kinyerése Netezza-környezetből
Adatdefiníciós nyelv (DDL) létrehozása
Az ANSI SQL-szabvány a Data Definition Language (DDL) parancsok alapszintaxisát határozza meg. Egyes DDL-parancsok, például CREATE TABLE és CREATE VIEW– a Netezza és az Azure Synapse esetében is – gyakoriak, de implementációspecifikus funkciókkal bővültek.
A meglévő Netezza CREATE TABLE és CREATE VIEW szkriptek szerkesztéséhez egyenértékű definíciókat érhet el az Azure Synapse-ban. Ehhez előfordulhat, hogy módosított adattípusokat kell használnia, és el kell távolítania vagy módosítania a Netezza-specifikus záradékokat, példáulORGANIZE ON.
A Netezza-környezetben a rendszerkatalógus-táblák határozzák meg az aktuális táblát és a nézetdefiníciót. A felhasználó által karbantartott dokumentációtól eltérően a rendszerkatalógus adatai mindig teljesek, és szinkronban lesznek az aktuális tábladefiníciókkal. Az olyan segédprogramok használatával, mint például nz_ddl_table, hozzáférhet a rendszerkatalógus adataihoz, hogy olyan DDL-utasításokat hozzon létre CREATE TABLE , amelyek egyenértékű táblákat hoznak létre az Azure Synapse-ban.
A rendszerkatalógus adatait feldolgozó külső migrálási és ETL-eszközöket is használhat a hasonló eredmények eléréséhez.
Adatok kinyerése a Netezza-ból
Nyers táblázatadatokat a Netezza-táblákból egybesimított fájlokba, például CSV-fájlokba nyerhet ki standard Netezza-segédprogramokkal, például nzsql és nzunload használatával, vagy külső táblákon keresztül. Ezután gzip használatával tömörítheti az egysíkú tagolt fájlokat, és feltöltheti a tömörített fájlokat az Azure Blob Storage-ba az AzCopy vagy az Azure data transport tools, például az Azure Data Box használatával.
A lehető leghatékonyabban nyerje ki a táblaadatokat. Használja a külső táblák megközelítését, mert ez a leggyorsabb kinyerési módszer. Több kivonat párhuzamos végrehajtása az adatkinyerés átviteli sebességének maximalizálása érdekében. A következő SQL-utasítás külső táblakivonatot hajt végre:
CREATE EXTERNAL TABLE '/tmp/export_tab1.csv' USING (DELIM ',') AS SELECT * from <TABLENAME>;
Ha elegendő hálózati sávszélesség áll rendelkezésre, adatokat kinyerhet egy helyszíni Netezza rendszerből közvetlenül az Azure Synapse-táblákba vagy az Azure Blob Data Storage-ba. Ehhez használja a Data Factory-folyamatokat, illetve külső adatmigrálást vagy ETL-termékeket .
Tipp.
Használja a Netezza külső táblázatokat a leghatékonyabb adatkinyeréshez.
A kinyert adatfájloknak csv, optimalizált soroszlop (ORC) vagy Parquet formátumban kell tagolt szöveget tartalmazniuk.
További információ az adatok és az ETL Netezza-környezetből való migrálásáról: Adatmigrálás, ETL és terhelés a Netezza-migrálásokhoz.
Teljesítményjavaslatok Netezza-migrálásokhoz
A teljesítményoptimalizálás célja az Azure Synapse-ba való migrálás után az adattárház teljesítménye azonos vagy jobb.
Hasonlóságok a teljesítményhangolási megközelítés fogalmaiban
A Netezza-adatbázisok számos teljesítményhangolási fogalma igaz az Azure Synapse-adatbázisokra. Példa:
Az adateloszlás használatával az adatok összefűzhetők ugyanahhoz a feldolgozási csomóponthoz.
Egy adott oszlop legkisebb adattípusával tárhelyet takaríthat meg, és felgyorsíthatja a lekérdezések feldolgozását.
Győződjön meg arról, hogy az összekapcsolandó oszlopok adattípusa megegyezik az illesztések feldolgozásának optimalizálása és az adatátalakítások szükségességének csökkentése érdekében.
Annak érdekében, hogy az optimalizáló a legjobb végrehajtási tervet hozza létre, győződjön meg arról, hogy a statisztikák naprakészek.
A teljesítmény monitorozása beépített adatbázis-képességekkel az erőforrások hatékony használatának biztosítása érdekében.
Tipp.
A migrálás kezdetén rangsorolja az Azure Synapse hangolási beállításainak ismeretét.
A teljesítményhangolási megközelítés eltérései
Ez a szakasz a Netezza és az Azure Synapse közötti alacsony szintű teljesítmény-finomhangolási implementáció különbségeit emeli ki.
Adatterjesztési beállítások
A teljesítmény érdekében az Azure Synapse többcsomópontos architektúrával lett tervezve, és párhuzamos feldolgozást használ. A táblázat teljesítményének optimalizálása érdekében az Azure Synapse-ban és DISTRIBUTE ON a Netezza-ban az utasításokban CREATE TABLE DISTRIBUTION definiálhat adatterjesztési lehetőséget.
A Netezza-val ellentétben az Azure Synapse kis táblák és nagy táblák közötti helyi illesztéseket támogat kis táblareplikálással. Vegyük például egy kis dimenziótáblát és egy nagy ténytáblát egy csillagséma-modellben. Az Azure Synapse képes replikálni a kisebb dimenziótáblát az összes csomópontra, így biztosítva, hogy a nagy tábla illesztési kulcsainak értéke egy egyező, helyileg elérhető dimenziósorsal rendelkezzen. A dimenziótáblák replikációjának többletterhelése egy kis dimenziótáblánál viszonylag alacsony. A nagyméretű dimenziótáblák esetében a kivonatelosztási módszer megfelelőbb. További információ az adatterjesztési lehetőségekről: Tervezési útmutató replikált táblák használatához és útmutató elosztott táblák tervezéséhez.
Adatindexelés
Az Azure Synapse számos felhasználó által definiálható indexelési lehetőséget támogat, amelyek működése és használata a Netezza rendszer által felügyelt zónatérképeihez képest eltérő. Az Azure Synapse különböző indexelési beállításairól további információt a dedikált SQL-készlettáblák indexei című témakörben talál.
A forrás Netezza-környezetben meglévő rendszer által felügyelt zónaleképezések hasznos jelzést nyújtanak az adathasználatról és az Azure Synapse-környezetben történő indexelésre jelölt oszlopokról.
Adatparticionálás
Egy vállalati adattárházban a ténytáblák több milliárd sort tartalmazhatnak. A particionálás optimalizálja ezeknek a tábláknak a karbantartási és lekérdezési teljesítményét úgy, hogy külön részekre osztja őket a feldolgozott adatok mennyiségének csökkentése érdekében. Az Azure Synapse-ban az CREATE TABLE utasítás egy tábla particionálási specifikációját határozza meg.
Particionáláshoz táblánként csak egy mezőt használhat. Ez a mező gyakran dátummező, mert számos lekérdezést dátum vagy dátumtartomány szűr. A tábla particionálását a kezdeti betöltés után módosíthatja a CREATE TABLE AS (CTAS) utasítással, hogy újra létrehozza a táblát egy új eloszlással. Az Azure Synapse particionálásának részletes ismertetését lásd : Particionálási táblák dedikált SQL-készletben.
Adattábla statisztikái
Az ETL-/ELT-feladatokra vonatkozó statisztikai lépésekkel gondoskodnia kell arról, hogy az adattáblák statisztikái naprakészek legyenek.
PolyBase vagy COPY INTO adatbetöltéshez
A PolyBase támogatja a nagy mennyiségű adat hatékony betöltését egy adattárházba párhuzamos betöltési streamek használatával. További információ: PolyBase adatbetöltési stratégia.
A COPY INTO támogatja a nagy átviteli sebességű adatbetöltést is, és:
Adatlekérés egy mappában és almappában lévő összes fájlból.
Adatok lekérése több helyről ugyanabban a tárfiókban. Több helyet is megadhat vesszővel tagolt elérési utak használatával.
Azure Data Lake Storage (ADLS) és Azure Blob Storage.
CSV, PARQUET és ORC fájlformátumok.
Számítási feladatok kezelése
A vegyes számítási feladatok futtatása erőforrás-kihívásokat jelenthet az elfoglalt rendszereken. A sikeres számítási feladatok kezelési sémája hatékonyan kezeli az erőforrásokat, biztosítja a rendkívül hatékony erőforrás-kihasználtságot, és maximalizálja a befektetés megtérülését (ROI). A számítási feladatok besorolása, a számítási feladatok fontossága és a számítási feladatok elkülönítése nagyobb ellenőrzést biztosít a számítási feladatok rendszererőforrás-használatában.
A számítási feladatok kezelési útmutatója ismerteti a számítási feladatok elemzésének, a számítási feladatok fontosságának kezelésének és monitorozásának módszereit, valamint az erőforrásosztály számítási feladatcsoporttá alakításának lépéseit. A számítási feladat figyeléséhez használja az Azure Portalt és a T-SQL-lekérdezéseket a DMV-ken , hogy biztosítsa a megfelelő erőforrások hatékony felhasználását.
Következő lépések
A Netezza-migrálás ETL-jének és terhelésének megismeréséhez tekintse meg a következő cikket ebben a sorozatban: Adatmigrálás, ETL és betöltés a Netezza-migrálásokhoz.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: