Útmutató elosztott táblák tervezéséhez dedikált SQL-készlet használatával az Azure Synapse Analyticsben
Ez a cikk ajánlásokat tartalmaz a kivonatolt és ciklikus időszeleteléses elosztott táblák dedikált SQL-készletekben való tervezéséhez.
Ez a cikk feltételezi, hogy ismeri a dedikált SQL-készlet adatelosztási és adatáthelyezési fogalmait. További információ: Azure Synapse Analytics-architektúra.
Mi az elosztott tábla?
Az elosztott táblák egyetlen táblaként jelennek meg, de a sorok valójában 60 eloszlásban vannak tárolva. A sorok kivonatoló vagy ciklikus időszeleteléses algoritmussal vannak elosztva.
A kivonat-elosztás javítja a nagy ténytáblák lekérdezési teljesítményét, és ez a cikk középpontjában áll. A ciklikus időszeleteléses eloszlás hasznos a betöltési sebesség javításához. Ezek a tervezési lehetőségek jelentős hatással vannak a lekérdezési és betöltési teljesítmény javítására.
Egy másik táblatárolási lehetőség egy kis tábla replikálása az összes számítási csomóponton. További információ: Tervezési útmutató replikált táblákhoz. Ha gyorsan szeretne választani a három lehetőség közül, olvassa el az Elosztott táblák a táblák áttekintésében című témakört.
A táblatervezés részeként a lehető legnagyobb mértékben ismerje meg az adatokat és az adatok lekérdezésének módját. Fontolja meg például az alábbi kérdéseket:
- Mekkora az asztal?
- Milyen gyakran frissül a tábla?
- Rendelkezem tény- és dimenziótáblával egy dedikált SQL-készletben?
Elosztott kivonat
A kivonatelosztott táblák egy determinisztikus kivonatoló függvénnyel osztják el a táblázat sorait a számítási csomópontok között, hogy minden sort egy-egy eloszláshoz rendeljenek.
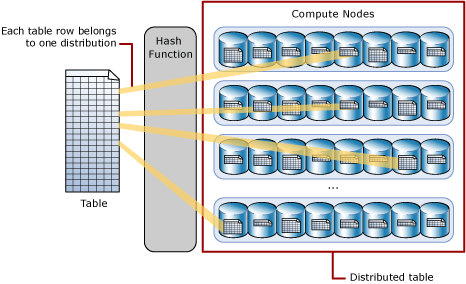
Mivel az azonos értékek mindig ugyanazt az eloszlást használják, az SQL Analytics beépített ismeretekkel rendelkezik a sorhelyekről. A dedikált SQL-készletben ez a tudás a lekérdezések során az adatáthelyezés minimalizálására szolgál, ami javítja a lekérdezések teljesítményét.
A kivonatelosztott táblák jól működnek a csillagséma nagy ténytábláihoz. Nagyon sok sort tartalmazhatnak, és továbbra is magas teljesítményt érhetnek el. Vannak olyan tervezési szempontok, amelyek segítenek az elosztott rendszer által nyújtott teljesítmény eléréséhez. Egy jó terjesztési oszlop vagy oszlop kiválasztása az egyik ilyen szempont, amelyet ebben a cikkben ismertetünk.
Érdemes lehet kivonatelosztott táblát használni, ha:
- A lemez táblamérete meghaladja a 2 GB-ot.
- A táblázat gyakori beszúrási, frissítési és törlési műveleteket tartalmaz.
Ciklikus időszeletelés elosztott
A ciklikus időszeletelésű elosztott táblák egyenletesen osztják el a táblázat sorait az összes eloszlásban. A sorok eloszlásokhoz való hozzárendelése véletlenszerű. A kivonatelosztott táblákkal ellentétben az egyenlő értékű sorok nem garantáltan ugyanahhoz az eloszláshoz lesznek hozzárendelve.
Ennek eredményeképpen a rendszernek néha meg kell hívnia egy adatáthelyezési műveletet, hogy jobban rendszerezze az adatokat, mielőtt feloldhat egy lekérdezést. Ez a további lépés lelassíthatja a lekérdezéseket. Például egy ciklikus időszeleteléses táblához való csatlakozáshoz általában újra kell átfogni a sorokat, ami teljesítménybeli találat.
Fontolja meg a táblázat ciklikus időszeleteléses eloszlásának használatát a következő forgatókönyvekben:
- Az első lépések egyszerű kiindulópontként, mivel ez az alapértelmezett
- Ha nincs kézenfekvő csatlakozási kulcs
- Ha nincs megfelelő jelölt oszlop a tábla kivonatelosztásához
- Ha a tábla nem oszt meg közös illesztőkulcsot más táblákkal
- Ha az illesztés kevésbé jelentős, mint a lekérdezés többi illesztése
- Ha a tábla átmeneti átmeneti tábla
A New York-i taxikaadatok betöltése című oktatóanyag példaként szolgál az adatok ciklikus időszeleteléses előkészítési táblába való betöltésére.
Elosztási oszlop kiválasztása
A kivonatelosztott táblák terjesztési oszlopokkal vagy oszlopkészlettel rendelkezik, amelyek a kivonatkulcsot tartalmazzák. Az alábbi kód például egy kivonatelosztott ProductKey táblát hoz létre terjesztési oszlopként.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
A kivonatok eloszlása több oszlopra is alkalmazható az alaptábla egyenletesebb eloszlása érdekében. A többoszlopos elosztással legfeljebb nyolc oszlopot választhat ki a disztribúcióhoz. Ez nemcsak az adatok időbeli eltérését csökkenti, hanem a lekérdezési teljesítményt is javítja. Például:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Feljegyzés
A többoszlopos elosztás az Azure Synapse Analyticsben az adatbázis kompatibilitási szintjének 50 ezzel a paranccsal történő módosításával engedélyezhető.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; Az adatbáziskompatibilitási szint beállításával kapcsolatos további információkért lásd : ALTER DATABASE SCOPED CONFIGURATION. A többoszlopos disztribúciókkal kapcsolatos további információkért lásd : CREATE MATERIALIZED VIEW, CREATE TABLE vagy CREATE TABLE AS SELECT.
A terjesztési oszlopokban tárolt adatok frissíthetők. A terjesztési oszlopokban lévő adatok frissítése adateloszlási műveletet eredményezhet.
A terjesztési oszlopok kiválasztása fontos tervezési döntés, mivel a kivonatoszlopokban lévő értékek határozzák meg a sorok elosztását. A legjobb választás több tényezőtől függ, és általában kompromisszumokkal jár. Miután kiválasztott egy terjesztési oszlopot vagy oszlopkészletet, nem módosíthatja azt. Ha első alkalommal nem a legjobb oszlopokat választotta ki, a CREATE TABLE AS SELECT (CTAS) használatával újra létrehozhatja a táblázatot a kívánt terjesztési kivonatkulcs használatával.
Válasszon ki egy egyenletesen elosztott adatokat tartalmazó terjesztési oszlopot
A legjobb teljesítmény érdekében az összes eloszlásnak körülbelül ugyanannyi sorból kell rendelkeznie. Ha egy vagy több disztribúciónak aránytalan számú sora van, egyes disztribúciók befejezik a párhuzamos lekérdezések egy részét mások előtt. Mivel a lekérdezés nem fejezhető be, amíg az összes disztribúció feldolgozása befejeződött, minden lekérdezés csak olyan gyors, mint a leglassabb eloszlás.
- Az adateltérés azt jelenti, hogy az adatok nem egyenletesen oszlanak el a disztribúciók között
- A feldolgozási eltérés azt jelenti, hogy egyes disztribúciók hosszabb időt vesznek igénybe, mint mások párhuzamos lekérdezések futtatásakor. Ez akkor fordulhat elő, ha az adatok eltúlzottak.
A párhuzamos feldolgozás kiegyensúlyozásához válasszon ki egy olyan terjesztési oszlopot vagy oszlopkészletet, amely:
- Számos egyedi értékkel rendelkezik. Egy vagy több terjesztési oszlop ismétlődő értékekkel rendelkezhet. Minden azonos értékű sor ugyanahhoz az eloszláshoz van rendelve. Mivel 60 eloszlás létezik, egyes disztribúciók 1 egyedi értékkel rendelkezhetnek > , míg mások nulla értékekkel végződhetnek.
- Nem rendelkezik NULL-sel, vagy csak néhány NULL-sel rendelkezik. Szélsőséges példa esetén, ha a terjesztési oszlopokban lévő összes érték NULL értékű, az összes sor ugyanahhoz az eloszláshoz lesz rendelve. Ennek eredményeképpen a lekérdezésfeldolgozás egy elosztásra van eltűrve, és nem élvezi a párhuzamos feldolgozás előnyeit.
- Nem dátumoszlop. Az ugyanarra a dátumra vonatkozó összes adat ugyanabban az eloszlásban található, vagy dátum szerint csoportosítja a rekordokat. Ha több felhasználó is ugyanahhoz a dátumhoz (például a mai dátumhoz) szűr, akkor a 60 disztribúcióból csak 1 végzi el az összes feldolgozási munkát.
Olyan terjesztési oszlop kiválasztása, amely minimalizálja az adatáthelyezést
A megfelelő lekérdezés eredményének lekéréséhez előfordulhat, hogy a lekérdezések adatokat helyeznek át az egyik számítási csomópontról a másikra. Az adatáthelyezés általában akkor fordul elő, ha a lekérdezések összekapcsolásokat és összesítéseket tartalmaznak elosztott táblákon. A dedikált SQL-készlet teljesítményének optimalizálásához az egyik legfontosabb stratégia egy olyan terjesztési oszlop vagy oszlopkészlet kiválasztása, amely segít minimalizálni az adatáthelyezést.
Az adatáthelyezés minimalizálásához válasszon ki egy olyan terjesztési oszlopot vagy oszlopkészletet, amely:
- A ,
GROUP BY,DISTINCT,OVERésHAVINGzáradékokban használatosJOIN. Ha két nagy ténytábla gyakori illesztésekkel rendelkezik, a lekérdezési teljesítmény javul, ha mindkét táblát az egyik illesztési oszlopban osztja el. Ha egy táblát nem használnak illesztésekben, érdemes lehet a táblát egy olyan oszlop- vagy oszlopkészleten terjeszteni, amely gyakran szerepel aGROUP BYzáradékban. - A záradékok
WHEREnem használják. Ha egy lekérdezés záradékaWHEREés a tábla terjesztési oszlopai ugyanazon az oszlopon találhatók, a lekérdezés nagy adateltérésbe ütközhet, ami miatt a terhelés csak kevés disztribúcióra csökken. Ez hatással van a lekérdezési teljesítményre, ideális esetben számos disztribúció osztozik a feldolgozási terhelésen. - Nem dátumoszlop.
WHEREzáradékok gyakran dátum szerint szűrnek. Ha ez történik, az összes feldolgozás csak néhány, a lekérdezési teljesítményt befolyásoló disztribúción futhat. Ideális esetben számos disztribúció osztozik a feldolgozási terhelésen.
Miután megtervezett egy kivonatelosztott táblát, a következő lépés az adatok betöltése a táblába. A betöltéssel kapcsolatos útmutatásért tekintse meg a betöltés áttekintését.
Hogyan állapíthatja meg, hogy a disztribúció jó választás-e
Miután betöltötte az adatokat egy kivonatelosztott táblába, ellenőrizze, hogy a sorok egyenletesen vannak-e elosztva a 60 eloszlás között. Az eloszlásonkénti sorok akár 10%-ig is változhatnak anélkül, hogy észrevehető hatással lenne a teljesítményre.
Fontolja meg a terjesztési oszlopok kiértékelésének alábbi módjait.
Annak megállapítása, hogy a tábla adateltérésben van-e
Az adateltérés gyors ellenőrzéséhez használja a DBCC PDW_SHOWSPACEUSED. Az alábbi SQL-kód a 60 eloszlásban tárolt táblasorok számát adja vissza. A kiegyensúlyozott teljesítmény érdekében az elosztott táblában lévő sorokat egyenletesen kell elosztani az összes eloszlásban.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Annak megállapításához, hogy mely táblák több mint 10%-os adateltérésben vannak:
- Hozza létre a Táblák áttekintési cikkben látható nézetet
dbo.vTableSizes. - Futtassa az alábbi lekérdezést:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Lekérdezéstervek ellenőrzése az adatáthelyezéshez
A jó terjesztési oszlopkészlet lehetővé teszi, hogy az illesztések és az összesítések minimális adatáthelyezéssel rendelkezzenek. Ez hatással van az illesztések írási módjára. Ha két kivonatelosztott táblán szeretne minimális adatáthelyezést elérni egy illesztéshez, az illesztési oszlopok egyikének terjesztési oszlopban vagy oszlopokban kell lennie. Ha két kivonatelosztott tábla egy azonos adattípusú terjesztési oszlophoz csatlakozik, az illesztés nem igényel adatáthelyezést. Az illesztések további oszlopokat is használhatnak adatáthelyezés nélkül.
Az adatáthelyezés elkerülése az illesztés során:
- Az illesztésben részt vevő táblákat kivonatként kell elosztani az illesztésben részt vevő oszlopok egyikén .
- Az illesztési oszlopok adattípusainak meg kell egyeznie mindkét tábla között.
- Az oszlopokat egyenlő operátorral kell összekapcsolni.
- Az illesztés típusa nem lehet
CROSS JOIN.
Annak megtekintéséhez, hogy a lekérdezések adatáthelyezést tapasztalnak-e, megtekintheti a lekérdezéstervet.
Terjesztési oszlop problémájának megoldása
Nem szükséges minden adateltérési esetet megoldani. Az adatok elosztása a megfelelő egyensúlyt kell megtalálni az adateltérés és az adatáthelyezés minimalizálása között. Az adateltérés és az adatáthelyezés minimalizálása nem mindig lehetséges. Előfordulhat, hogy a minimális adatáthelyezés előnye meghaladja az adateltérés hatását.
Annak eldöntéséhez, hogy fel kell-e oldania az adateltéréseket egy táblában, a lehető legnagyobb mértékben meg kell értenie a számítási feladat adatmennyiségeit és lekérdezéseit. A Lekérdezésfigyelési cikk lépéseivel monitorozhatja a ferdeség lekérdezési teljesítményre gyakorolt hatását. Pontosabban azt, hogy mennyi ideig tart a nagy lekérdezések végrehajtása az egyes disztribúciókon.
Mivel a meglévő táblák terjesztési oszlopai nem módosíthatók, az adateltérés feloldásának tipikus módja a tábla ismételt létrehozása különböző terjesztési oszlopokkal.
A tábla újbóli létrehozása új terjesztési oszlopkészlettel
Ez a példa a CREATE TABLE AS SELECT parancsot használja a különböző kivonatelosztó oszlopokkal rendelkező táblák újbóli létrehozásához.
Először használja CREATE TABLE AS SELECT (CTAS) az új táblát az új kulccsal. Ezután hozza létre újra a statisztikákat, és végül az átnevezéssel cserélje le a táblákat.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Kapcsolódó tartalom
Elosztott tábla létrehozásához használja az alábbi utasítások egyikét:
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: