A Netezza-migráláson túl modern adattárház implementálása a Microsoft Azure-ban
Ez a cikk egy hétrészes sorozat hetedik része, amely útmutatást nyújt a Netezza-ból Azure Synapse Analyticsbe való migráláshoz. A cikk középpontjában a modern adattárházak implementálásának ajánlott eljárásai áll.
Az adattárház azure-ba való migrálásán túl
A meglévő adattárház Azure Synapse Analyticsbe való migrálásának egyik fő oka egy globálisan biztonságos, skálázható, alacsony költségű, natív felhőbeli, használatalapú elemzési adatbázis használata. A Azure Synapse segítségével integrálhatja a migrált adattárházat a teljes Microsoft Azure elemzési ökoszisztémával, hogy kihasználhassa más Microsoft-technológiák előnyeit, és modernizálhassa a migrált adattárházat. Ezek a technológiák a következők:
Azure Data Lake Storage költséghatékony adatbetöltéshez, előkészítéshez, tisztításhoz és átalakításhoz. Data Lake Storage felszabadíthatja a gyorsan növekvő előkészítési táblák által elfoglalt adattárház-kapacitást.
Azure Data Factory az együttműködésen alapuló informatikai és önkiszolgáló adatintegrációhoz a felhőbeli és helyszíni adatforrásokhoz és streamelési adatokhoz csatlakozó összekötőkkel.
Common Data Model a konzisztens megbízható adatok több technológia közötti megosztásához, beleértve a következőket:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- Azure IoT
- Microsoft ISV-partnerek
A Microsoft adatelemzési technológiái, beleértve a következőket:
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (Spark szolgáltatásként)
- Jupyter-notebookok
- RStudio
- ML.NET
- Az Apache Sparkhoz készült .NET lehetővé teszi, hogy az adatelemzők Azure Synapse adatokat használjanak a gépi tanulási modellek nagy léptékű betanítása céljából.
Az Azure HDInsight nagy mennyiségű adat feldolgozására és a big data-adatok Azure Synapse adatokkal való összekapcsolására egy logikai adattárház polyBase használatával történő létrehozásával.
Azure Event Hubs, az Azure Stream Analytics és az Apache Kafka segítségével integrálhatja a Azure Synapse élő streamelési adatait.
A big data növekedésének következtében a gépi tanulás iránti igény az egyénileg létrehozott, betanított gépi tanulási modellek Azure Synapse való használatát tette lehetővé. A gépi tanulási modellek lehetővé teszik az adatbázison belüli elemzések tömeges, eseményvezérelt és igény szerinti futtatását. Az adatbázison belüli elemzések több BI-eszközből és alkalmazásból származó Azure Synapse való kihasználása konzisztens előrejelzéseket és javaslatokat is biztosít.
Emellett integrálhatja a Azure Synapse az Azure-beli Microsoft partnereszközökkel, hogy lerövidítse az idő értékét.
Tekintsük át közelebbről, hogyan használhatja ki a Microsoft elemzési ökoszisztémájának technológiáit az adattárház modernizálásához, miután migrált Azure Synapse.
Adat-előkészítés és ETL-feldolgozás kiszervezése a Data Lake Storage és a Data Factory számára
A digitális átalakítás kulcsfontosságú kihívást jelentett a vállalatok számára azáltal, hogy új adatok özönét generálta a rögzítéshez és elemzéshez. Jó példa erre az online tranzakciófeldolgozási (OLTP) rendszerek mobileszközökről való szolgáltatáshoz való megnyitásával létrehozott tranzakciós adatok. Az adatok nagy része az adattárházakba kerül, és az OLTP-rendszerek jelentik a fő forrást. Mivel az ügyfelek most inkább a tranzakciós arányt vezetik, mint az alkalmazottak, az adattárház-előkészítési táblákban lévő adatok mennyisége gyorsan növekedett.
A vállalatba történő gyors adatbeáramlás és az új adatforrások, például az eszközök internetes hálózata (IoT) mellett a vállalatoknak módot kell találniuk az adatintegrációs ETL-feldolgozás vertikális felskálázására. Az egyik módszer az adatbetöltés, az adattisztítás, az átalakítás és az integráció kiszervezése egy data lake-be, és az adatok nagy léptékben történő feldolgozása az adattárház modernizálási programjának részeként.
Miután migrálta az adattárházat Azure Synapse, a Microsoft modernizálhatja az ETL-feldolgozást az adatok Data Lake Storage való betöltésével és előkészítésével. Ezután a Data Factory használatával nagy léptékben megtisztíthatja, átalakíthatja és integrálhatja az adatokat, mielőtt a PolyBase használatával párhuzamosan betöltené őket Azure Synapse.
Az ELT-stratégiák esetében fontolja meg az ELT-feldolgozás kiszervezését Data Lake Storage az adatmennyiség vagy a gyakoriság növekedésével párhuzamosan történő egyszerű skálázás érdekében.
Microsoft Azure Data Factory
Azure Data Factory egy használatalapú, hibrid adatintegrációs szolgáltatás, amely nagy mértékben skálázható ETL- és ELT-feldolgozást biztosít. A Data Factory egy webes felhasználói felületet biztosít, amellyel kód nélküli adatintegrációs folyamatokat hozhat létre. A Data Factoryvel a következőket teheti:
Kód nélküli, skálázható adatintegrációs folyamatokat hozhat létre.
Egyszerűen szerezhet be adatokat nagy léptékben.
Csak a valóban használt funkciókért kell fizetnie.
Csatlakozzon helyszíni, felhőbeli és SaaS-alapú adatforrásokhoz.
Felhőbeli és helyszíni adatok nagy léptékű betöltése, áthelyezése, tisztítása, átalakítása, integrálása és elemzése.
Zökkenőmentesen szerkesszen, monitorozza és kezelje a helyszíni és a felhőbeli adattárakra kiterjedő folyamatokat.
Használatalapú fizetéses felskálázás engedélyezése az ügyfelek növekedésével összhangban.
Ezeket a funkciókat kód írása nélkül is használhatja, vagy hozzáadhat egyéni kódot a Data Factory-folyamatokhoz. Az alábbi képernyőképen egy Példa Data Factory-folyamat látható.

Tipp
A Data Factory segítségével kód nélkül hozhat létre skálázható adatintegrációs folyamatokat.
Data Factory-folyamatfejlesztés megvalósítása számos helyről, beleértve a következőket:
Microsoft Azure Portal.
Microsoft Azure PowerShell.
Programozott módon .NET-ből és Pythonból többnyelvű SDK-val.
Azure Resource Manager(ARM)-sablonok.
REST API-k.
Tipp
A Data Factory helyszíni, felhőbeli és SaaS-adatokhoz tud csatlakozni.
Azok a fejlesztők és adattudósok, akik inkább kódot írnak, könnyedén készíthetnek Data Factory-folyamatokat Java, Python és .NET nyelven az adott programozási nyelvekhez elérhető szoftverfejlesztői készletek (SDK-k) használatával. A Data Factory-folyamatok lehetnek hibrid adatfolyamok, mivel a helyszíni adatközpontokban, a Microsoft Azure-ban, más felhőkben és SaaS-ajánlatokban lévő adatokat csatlakoztathatják, betölthetik, megtisztíthatják, átalakíthatják és elemezhetik.
Miután data factory-folyamatokat fejlesztett ki az adatok integrálásához és elemzéséhez, globálisan üzembe helyezheti ezeket a folyamatokat, és ütemezheti őket kötegelt futtatásra, igény szerint meghívhatja őket szolgáltatásként, vagy valós időben futtathatja őket eseményvezérelt alapon. A Data Factory-folyamatok egy vagy több végrehajtási motoron is futtathatók, és figyelhetik a végrehajtást a teljesítmény biztosítása és a hibák nyomon követése érdekében.
Tipp
A Azure Data Factory folyamatok szabályozzák az adatok integrálását és elemzését. A Data Factory egy nagyvállalati szintű adatintegrációs szoftver, amely informatikai szakembereknek szól, és adatszervezési képességgel rendelkezik az üzleti felhasználók számára.
Használati esetek
A Data Factory több használati esetet is támogat, például:
Felhőbeli és helyszíni adatforrásokból származó adatok előkészítése, integrálása és bővítése a migrált adattárház és adatpiacok feltöltéséhez a Microsoft Azure Synapse.
A felhőalapú és helyszíni adatforrásokból származó adatok előkészítése, integrálása és bővítése a gépi tanulási modellek fejlesztéséhez és az elemzési modellek újratanításához használható betanítási adatok előállításához.
Az adatok előkészítésének és elemzésének vezénylése prediktív és leíró elemzési folyamatok létrehozásához az adatok kötegelt feldolgozásához és elemzéséhez, például hangulatelemzéshez. Cselekedjen az elemzés eredményei alapján, vagy töltse fel az adattárházat az eredményekkel.
Adatok előkészítése, integrálása és bővítése az Azure-felhőben futó adatvezérelt üzleti alkalmazásokhoz az olyan operatív adattárakon, mint az Azure Cosmos DB.
Tipp
Betanítási adatkészletek létrehozása az adatelemzésben gépi tanulási modellek fejlesztéséhez.
Adatforrások
A Data Factory lehetővé teszi a felhőből és a helyszíni adatforrásokból származó összekötők használatát. A helyi integrációs modulként ismert ügynökszoftver biztonságosan hozzáfér a helyszíni adatforrásokhoz, és támogatja a biztonságos, skálázható adatátvitelt.
Adatok átalakítása Azure Data Factory használatával
A Data Factory-folyamaton belül bármilyen típusú adatot betölthet, megtisztíthat, átalakíthat, integrálhat és elemezhet ezekből a forrásokból. Az adatok strukturálhatók, részben strukturálhatók, például JSON vagy Avro, vagy strukturálatlanok.
Kód írása nélkül a professzionális ETL-fejlesztők a Data Factory-leképezési adatfolyamokkal szűrhetik, feloszthatják, összekapcsolhatják több típust, kereshetnek, kimutatást készíthetnek, feloldhatják, rendezhetik, egyesíthetik és összesíthetik az adatokat. Emellett a Data Factory támogatja a helyettesítő kulcsokat, a több írásfeldolgozási lehetőséget, például az insert, upsert, update, table rekreáció és táblacsokorolást, valamint számos céladattárat – más néven fogadókat – is. Az ETL-fejlesztők aggregációkat is létrehozhatnak, beleértve az idősorozat-összesítéseket is, amelyekhez ablakokat kell elhelyezni az adatoszlopokon.
Tipp
A professzionális ETL-fejlesztők a Data Factory-leképezési adatfolyamok használatával megtisztíthatják, átalakíthatják és integrálhatják az adatokat anélkül, hogy kódot kellene írniuk.
Olyan leképezési adatfolyamokat futtathat, amelyek tevékenységként alakítják át az adatokat egy Data Factory-folyamatban, és szükség esetén több leképezési adatfolyamot is felvehet egyetlen folyamatba. Ily módon a bonyolultságot úgy kezelheti, hogy a kihívást jelentő adatátalakítási és integrációs feladatokat kisebb, kombinálható leképezési adatfolyamokra bontja. Szükség esetén egyéni kódot is hozzáadhat. Ezen funkciók mellett a Data Factory leképezési adatfolyamai a következőkre is képesek:
Kifejezéseket definiálhat az adatok tisztításához és átalakításához, a számítási összesítésekhez és az adatok bővítéséhez. Ezek a kifejezések például funkciófejlesztést végezhetnek egy dátummezőn, hogy több mezőre bontva betanítási adatokat hozzanak létre a gépi tanulási modell fejlesztése során. A függvények gazdag készletéből létrehozhat kifejezéseket, amelyek közé tartoznak a matematikai, időbeli, felosztási, egyesítési, sztringösszefűzési, feltételek, mintaegyeztetés, csere és sok más függvény.
Automatikusan kezeli a sémaeltolódást, hogy az adatátalakítási folyamatok ne befolyásolhassák az adatforrások sémaváltozásait. Ez a képesség különösen fontos az IoT-adatok streamelésekor, ahol a sémamódosítások értesítés nélkül megtörténhetnek, ha az eszközök frissítve vannak, vagy ha az IoT-adatokat gyűjtő átjáróeszközök kihagyják az olvasást.
Particionálja az adatokat, hogy az átalakítások párhuzamosan, nagy léptékben fussanak.
Ellenőrizze a streamelési adatokat az átalakítandó stream metaadatainak megtekintéséhez.
Tipp
A Data Factory támogatja a sémamódosítások automatikus észlelését és kezelését a bejövő adatokban, például a streamelési adatokban.
Az alábbi képernyőképen egy Data Factory-leképezési adatfolyam látható.

Az adatmérnökök profilt készíthetnek az adatminőségről, és megtekinthetik az egyes adatátalakítások eredményeit a hibakeresési képesség fejlesztés közbeni engedélyezésével.
Tipp
A Data Factory képes az adatok particionálására is, hogy az ETL-feldolgozás nagy léptékben fusson.
Szükség esetén kibővítheti a Data Factory átalakítási és elemzési funkcióit, ha hozzáad egy társított szolgáltatást, amely tartalmazza a kódot egy folyamatba. Egy Azure Synapse Spark-készlet jegyzetfüzete például olyan Python-kódot tartalmazhat, amely betanított modellt használ a leképezési adatfolyam által integrált adatok pontozásához.
Egy Data Factory-folyamat integrált adatait és eredményeit egy vagy több adattárban, például Data Lake Storage, Azure Synapse vagy Hive-táblákban tárolhatja a HDInsightban. Más tevékenységeket is meghívhat a Data Factory elemzési folyamatai által létrehozott elemzések végrehajtásához.
Tipp
A Data Factory-folyamatok bővíthetőek, mert a Data Factory lehetővé teszi saját kód írását és futtatását egy folyamat részeként.
A Spark használata az adatintegráció skálázásához
Futásidőben a Data Factory belsőleg Azure Synapse Spark-készleteket használ, amelyek a Microsoft Spark szolgáltatásajánlatai, az adatok azure-felhőbeli tisztítására és integrálására. Nagy mennyiségű, nagy sebességű adatokat, például kattintásfolyam-adatokat nagy léptékben takaríthat meg, integrálhat és elemezhet. A Microsoft célja a Data Factory-folyamatok futtatása más Spark-disztribúciókon is. AMellett, hogy ETL-feladatokat futtat a Sparkban, a Data Factory Pig-szkripteket és Hive-lekérdezéseket is meghívhat a HDInsightban tárolt adatok eléréséhez és átalakításához.
Összekapcsolhatja az önkiszolgáló adat-előkészítést és a Data Factory ETL-feldolgozást a különböző adatfolyamok használatával
Az adatmeghatolás lehetővé teszi, hogy az üzleti felhasználók, más néven a civil adat integrátorok és adatmérnökök a platform segítségével vizuálisan felderítsék, feltárják és előkészítsék az adatokat nagy léptékben, kód írása nélkül. Ez a Data Factory-funkció könnyen használható, és hasonló a Microsoft Excel Power Query vagy a Microsoft Power BI-adatfolyamokhoz, ahol az önkiszolgáló üzleti felhasználók egy táblázatstílusú felhasználói felületet használnak, amely legördülő átalakításokkal készíti elő és integrálja az adatokat. Az alábbi képernyőképen egy példa látható, amely a Data Factory-beli adatáramlást űzi.

Az Exceltől és a Power BI-tól eltérően a Data Factory az Power Query használatával hozza létre az M-kódot, majd lefordítja azt egy nagymértékben párhuzamos, memórián belüli Spark-feladatra a felhőalapú végrehajtáshoz. Az adatfolyamok leképezésének és a Data Factoryben történő átszervezésének kombinációja lehetővé teszi a professzionális ETL-fejlesztők és üzleti felhasználók együttműködését az adatok közös üzleti célú előkészítéséhez, integrálásához és elemzéséhez. Az előző Data Factory-leképezési adatfolyam-diagram bemutatja, hogy a Data Factory és a Azure Synapse Spark-készlet jegyzetfüzetei hogyan kombinálhatók ugyanabban a Data Factory-folyamatban. A Data Factoryben az adatfolyamok leképezésének és átrendezésének kombinációja segít az informatikai és üzleti felhasználóknak, hogy tisztában legyenek azzal, hogy milyen adatfolyamokat hoztak létre, és támogatja az adatfolyamok újrafelhasználását az újra feltalálás minimalizálása, valamint a hatékonyság és a konzisztencia maximalizálása érdekében.
Tipp
A Data Factory támogatja az adatfolyamok átrendezését és az adatfolyamok leképezését, így az üzleti felhasználók és az informatikai felhasználók közös platformon integrálhatják az adatokat.
Adatok és elemzések összekapcsolása elemzési folyamatokban
Az adatok tisztítása és átalakítása mellett a Data Factory kombinálhatja az adatintegrációt és az elemzést ugyanabban a folyamatban. A Data Factory használatával adatintegrációs és elemzési folyamatokat is létrehozhat, ez utóbbi pedig az előbbi bővítménye. Egy elemzési modellt elvethet egy folyamatba, hogy létrehozhasson egy olyan elemzési folyamatot, amely tiszta, integrált adatokat hoz létre előrejelzésekhez vagy javaslatokhoz. Ezután azonnal reagálhat az előrejelzésekre vagy javaslatokra, vagy tárolhatja őket az adattárházban, hogy új megállapításokat és javaslatokat nyújtson, amelyek megtekinthetők a BI-eszközökben.
Az adatok kötegelt pontozásához létrehozhat egy olyan elemzési modellt, amelyet szolgáltatásként hív meg egy Data Factory-folyamaton belül. Az elemzési modelleket kód nélkül fejlesztheti a Azure Machine Learning stúdió vagy az Azure Machine Learning SDK-val Azure Synapse Spark-készletjegyzetfüzetek vagy RStudio használatával. Amikor sparkos gépi tanulási folyamatokat futtat Azure Synapse Spark-készlet jegyzetfüzetén, az elemzés nagy léptékben történik.
Az integrált adatokat és a Data Factory elemzési folyamat eredményeit tárolhatja egy vagy több adattárban, például Data Lake Storage, Azure Synapse vagy Hive-táblákban a HDInsightban. Más tevékenységeket is meghívhat a Data Factory elemzési folyamatai által létrehozott elemzések végrehajtásához.
Lake-adatbázis használata konzisztens megbízható adatok megosztásához
Az adatintegrálási beállítások egyik fő célja, hogy az adatokat egyszer integrálják, és mindenhol újra felhasználják, nem csak egy adattárházban. Előfordulhat például, hogy integrált adatokat szeretne használni az adatelemzésben. Az újrafelhasználás elkerüli az újbóli feltalálást, és biztosítja a konzisztens, általánosan ismert adatokat, amelyekben mindenki megbízhat.
A Common Data Model azokat az alapvető adatentititásokat ismerteti, amelyek megoszthatóak és újrafelhasználhatók a vállalaton belül. Az újrafelhasználás érdekében a Common Data Model olyan általános adatneveket és definíciókat hoz létre, amelyek a logikai adatentitásokat írják le. A gyakori adatnevek közé tartozik például az Ügyfél, a Fiók, a Termék, a Szállító, a Rendelések, a Kifizetések és a Visszaküldés. Az informatikai és üzleti szakemberek adatintegrációs szoftverekkel közös adategységeket hozhatnak létre és tárolhatnak, hogy maximalizálják az újrafelhasználásukat, és mindenhol konzisztenciát teremthessenek.
Azure Synapse iparágspecifikus adatbázissablonokat biztosít a tó adatainak szabványosításához. A lake-adatbázissablonok előre definiált üzleti területek sémáit biztosítják, így az adatok strukturált módon tölthetők be egy tóadatbázisba. A teljesítmény akkor jön létre, ha adatintegrációs szoftverrel hoz létre közös adategységeket a lake database-adatbázisokban, és így önleíró megbízható adatokat eredményez, amelyeket az alkalmazások és az elemzési rendszerek felhasználhatnak. A Data Factory használatával közös adategységeket hozhat létre Data Lake Storage.
Tipp
Data Lake Storage a Microsoft Azure Synapse, az Azure Machine Learning, a Azure Synapse Spark és a HDInsight alapját képező megosztott tároló.
A Power BI, a Spark Azure Synapse, a Azure Synapse és az Azure Machine Learning közös adategységeket használhat. Az alábbi diagram bemutatja, hogyan használható egy tóadatbázis Azure Synapse.

Tipp
Adatok integrálása a lake database logikai entitások megosztott tárolóban való létrehozásához a közös adategységek újrafelhasználásának maximalizálása érdekében.
Integráció a Microsoft adatelemzési technológiáival az Azure-ban
Az adattárház modernizálásának egy másik fő célkitűzése a versenyelőnyhöz szükséges elemzések előállítása. Elemzések készítéséhez integrálhatja a migrált adattárházat a Microsofttal és a külső adatelemzési technológiákkal az Azure-ban. Az alábbi szakaszok a Microsoft által kínált gépi tanulási és adatelemzési technológiákat ismertetik, amelyekből megtudhatja, hogyan használhatók Azure Synapse egy modern adattárház-környezetben.
Microsoft-technológiák az azure-beli adatelemzéshez
A Microsoft számos olyan technológiát kínál, amely támogatja az előzetes elemzést. Ezekkel a technológiákkal gépi tanulással prediktív elemzési modelleket hozhat létre, vagy strukturálatlan adatokat elemezhet mély tanulással. A technológiák a következők:
Azure Machine Learning Studio
Azure Machine Learning
Spark-készlet jegyzetfüzeteinek Azure Synapse
ML.NET (API, CLI vagy ML.NET Model Builder for Visual Studio)
.NET for Apache Spark
Az adatelemzők az RStudio (R) és a Jupyter Notebooks (Python) használatával fejleszthetnek elemzési modelleket, vagy olyan keretrendszereket használhatnak, mint a Keras vagy a TensorFlow.
Tipp
Gépi tanulási modellek fejlesztése kód nélküli vagy alacsony kódszámú megközelítéssel, vagy olyan programozási nyelvek használatával, mint a Python, az R és a .NET.
Azure Machine Learning Studio
Azure Machine Learning stúdió egy teljes mértékben felügyelt felhőszolgáltatás, amely lehetővé teszi a prediktív elemzések összeállítását, üzembe helyezését és megosztását egy húzással, webes felhasználói felületen. Az alábbi képernyőképen a Azure Machine Learning stúdió felhasználói felülete látható.

Azure Machine Learning
Az Azure Machine Learning egy SDK-t és szolgáltatásokat biztosít a Pythonhoz, amely támogatja az adatok gyors előkészítését, valamint a gépi tanulási modellek betanítása és üzembe helyezését. Az Azure Machine Learninget az Azure-jegyzetfüzetekben a Jupyter Notebook használatával használhatja, olyan nyílt forráskódú keretrendszerekkel, mint a PyTorch, a TensorFlow, a scikit-learn vagy a Spark MLlib – a Spark gépi tanulási könyvtára. Az Azure Machine Learning egy AutoML-képességet biztosít, amely automatikusan tesztel több algoritmust, hogy azonosítsa a legpontosabb algoritmusokat a modell fejlesztésének felgyorsítása érdekében.
Tipp
Az Azure Machine Learning SDK-t biztosít a gépi tanulási modellek fejlesztéséhez több nyílt forráskódú keretrendszer használatával.
Az Azure Machine Learning használatával olyan gépi tanulási folyamatokat is létrehozhat, amelyek a végpontok közötti munkafolyamatokat kezelik, programozott módon méretezhetők a felhőben, és modelleket helyezhetnek üzembe a felhőben és a peremhálózaton egyaránt. Az Azure Machine Learning olyan munkaterületeket tartalmaz, amelyek olyan logikai terek, amelyeket programozott módon vagy manuálisan hozhat létre a Azure Portal. Ezek a munkaterületek egy helyen tárolják a számítási célokat, kísérleteket, adattárakat, betanított gépi tanulási modelleket, Docker-rendszerképeket és üzembe helyezett szolgáltatásokat, hogy lehetővé tegyék a csapatok együttműködését. Az Azure Machine Learninget a Visual Studióban használhatja a Visual Studio for AI bővítményével.
Tipp
A kapcsolódó adattárak, kísérletek, betanított modellek, Docker-rendszerképek és üzembe helyezett szolgáltatások rendszerezése és kezelése a munkaterületeken.
Spark-készlet jegyzetfüzeteinek Azure Synapse
A Azure Synapse Spark-készlet jegyzetfüzete egy Azure-ra optimalizált Apache Spark-szolgáltatás. Azure Synapse Spark-készlet jegyzetfüzeteivel:
Az adatmérnökök skálázható adat-előkészítési feladatokat hozhatnak létre és futtathatnak a Data Factory használatával.
Az adatelemzők nagy méretekben hozhatnak létre és futtathatnak gépi tanulási modelleket olyan nyelveken írt jegyzetfüzetek használatával, mint a Scala, az R, a Python, a Java és az SQL az eredmények megjelenítéséhez.
Tipp
Azure Synapse Spark egy dinamikusan skálázható Spark szolgáltatásajánlat a Microsofttól, a Spark skálázható adat-előkészítést, modellfejlesztést és üzembe helyezett modellvégrehajtást kínál.
Az Azure Synapse Spark-készlet jegyzetfüzeteiben futó feladatok nagy léptékben lekérhetik, feldolgozhatják és elemezhetik az adatokat a Azure Blob Storage, a Data Lake Storage, a Azure Synapse, a HDInsight és a streamelési adatszolgáltatásokból, például az Apache Kafkából.
Tipp
Azure Synapse Spark számos Microsoft-elemzési ökoszisztéma-adattárban férhet hozzá az adatokhoz az Azure-ban.
Azure Synapse Spark-készlet jegyzetfüzetei támogatják az automatikus skálázást és az automatikus leállítást a teljes tulajdonosi költség (TCO) csökkentése érdekében. Az adatelemzők az MLflow nyílt forráskódú keretrendszerével kezelhetik a gépi tanulási életciklust.
ML.NET
ML.NET egy nyílt forráskódú, platformfüggetlen gépi tanulási keretrendszer Windows, Linux és macOS rendszerekhez. A Microsoft ML.NET hozott létre, hogy a .NET-fejlesztők meglévő eszközöket, például ML.NET Visual Studio Model Buildert használva egyéni gépi tanulási modelleket fejlesszenek ki, és integrálhassák őket a .NET-alkalmazásaikba.
Tipp
A Microsoft kiterjesztette gépi tanulási képességét a .NET-fejlesztőkre.
.NET for Apache Spark
Az Apache Sparkhoz készült .NET az R, a Scala, a Python és a Java mellett a .NET-re is kiterjeszti a Spark támogatását, és célja, hogy a Spark minden Spark API-ban elérhető legyen a .NET-fejlesztők számára. Bár az Apache Sparkhoz készült .NET jelenleg csak az Apache Sparkban érhető el a HDInsightban, a Microsoft elérhetővé kívánja tenni az Apache Sparkhoz készült .NET-et Azure Synapse Spark-készlet jegyzetfüzeteiben.
A Azure Synapse Analytics használata az adattárházzal
A gépi tanulási modellek és a Azure Synapse kombinálásához a következőket teheti:
A gépi tanulási modellek kötegelt vagy valós idejű streamelési adatokkal új megállapításokat hozhatnak létre, és ezeket az elemzéseket hozzáadják a Azure Synapse már ismertekhez.
A Azure Synapse adataival új prediktív modelleket fejleszthet és taníthat be máshol, például más alkalmazásokban történő üzembe helyezéshez.
Gépi tanulási modelleket helyezhet üzembe, beleértve a máshol betanított modelleket is, Azure Synapse az adattárházban lévő adatok elemzéséhez és az új üzleti érték eléréséhez.
Tipp
Gépi tanulási modellek nagy léptékű betanítása, tesztelése, kiértékelése és futtatása Azure Synapse Spark-készlet jegyzetfüzeteiben az Azure Synapse adatainak használatával.
Az adatelemzők az RStudio, a Jupyter Notebooks és Azure Synapse Spark-készlet jegyzetfüzeteit az Azure Machine Learningdel együtt használhatják olyan gépi tanulási modellek fejlesztésére, amelyek Azure Synapse Spark-készlet jegyzetfüzeteiben Azure Synapse adatokat használnak. Az adatelemzők például létrehozhatnak egy nem felügyelt modellt, amely szegmentálta az ügyfeleket különböző marketingkampányok vezetéséhez. Felügyelt gépi tanulással betaníthat egy modellt egy adott eredmény előrejelzéséhez, például előrejelezheti az ügyfél változásra való hajlandóságát, vagy javasolhatja az ügyfél számára a következő legjobb ajánlatot, hogy növelje az értékét. Az alábbi ábra bemutatja, hogyan használható Azure Synapse az Azure Machine Learninghez.
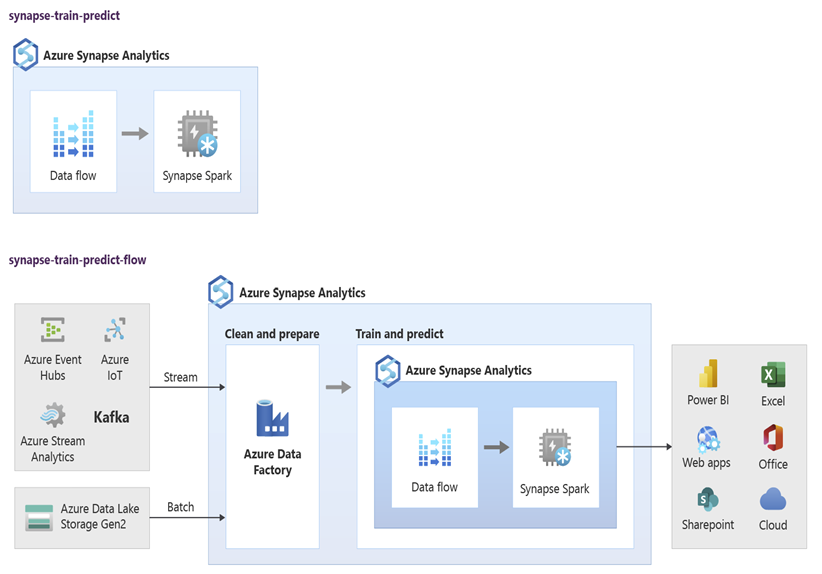
Egy másik forgatókönyvben betöltheti a közösségi hálózat adatait, vagy áttekintheti a webhely adatait a Data Lake Storage, majd előkészítheti és elemezheti az adatokat egy Azure Synapse Spark-készlet jegyzetfüzetében természetes nyelvi feldolgozással, hogy értékelje az ügyfelek véleményét a termékeiről vagy márkájáról. Ezután hozzáadhatja ezeket a pontszámokat az adattárházhoz. Ha big data-elemzést használ a negatív hangulat termékértékesítésekre gyakorolt hatásának megértéséhez, hozzáadja azt, amit már tud az adattárházban.
Tipp
Készítsen új elemzéseket az Azure-beli gépi tanulással kötegelve vagy valós időben, és adja hozzá az adattárházban megismert információkhoz.
Élő streamelési adatok integrálása a Azure Synapse Analyticsbe
A modern adattárházban lévő adatok elemzésekor képesnek kell lennie valós időben elemezni a streamelési adatokat, és összekapcsolni az adattárházban lévő előzményadatokkal. Ilyen például az IoT-adatok kombinálása termék- vagy eszközadatokkal.
Tipp
Integrálja az adattárházat az IoT-eszközökről vagy kattintásstreamekből származó streamelési adatokkal.
Miután sikeresen migrálta az adattárházat Azure Synapse, az adattárház modernizálási gyakorlatának részeként bevezetheti az élő streamelési adatintegrációt az Azure Synapse extra funkcióinak kihasználásával. Ehhez streamelési adatokat kell betöltenie az Event Hubson keresztül, más technológiákkal, például az Apache Kafkával, vagy potenciálisan a meglévő ETL-eszközével, ha támogatja a streamelési adatforrásokat. Az adatokat a Data Lake Storage tárolja. Ezután hozzon létre egy külső táblát Azure Synapse a PolyBase használatával, és mutasson a Data Lake Storage streamelt adatokra, hogy az adattárház mostantól új táblákat tartalmaz, amelyek hozzáférést biztosítanak a valós idejű streamelési adatokhoz. A külső táblát úgy kérdezheti le, mintha az adatok az adattárházban adták volna meg a standard T-SQL-t bármely olyan BI-eszközből, amely hozzáfér a Azure Synapse. A streamelési adatokat más táblákhoz is csatlakoztathatja előzményadatokkal, így olyan nézeteket hozhat létre, amelyek élő streamelési adatokat csatlakoztatnak az előzményadatokhoz, hogy megkönnyítse az üzleti felhasználók számára az adatok elérését.
Tipp
Streamelési adatok betöltése Data Lake Storage az Event Hubsból vagy az Apache Kafkából, és az adatok elérése Azure Synapse a PolyBase külső tábláinak használatával.
Az alábbi ábrán egy valós idejű adattárház Azure Synapse van integrálva a streamelési adatokkal a Data Lake Storage.

Logikai adattárház létrehozása a PolyBase használatával
A PolyBase használatával létrehozhat egy logikai adattárházat, amely leegyszerűsíti a felhasználók hozzáférését több elemzési adattárhoz. Számos vállalat alkalmazott "számítási feladatra optimalizált" elemzési adattárakat az elmúlt években az adattárházaik mellett. Az Azure elemzési platformjai a következők:
Data Lake Storage Azure Synapse Spark-készlet jegyzetfüzetével (Spark mint szolgáltatás) big data-elemzéshez.
HDInsight (Hadoop mint szolgáltatás), big data-elemzéshez is.
Gráfelemzéshez használható NoSQL Graph-adatbázisok, amelyek az Azure Cosmos DB-ben végezhetők el.
Event Hubs és Stream Analytics, a mozgásban lévő adatok valós idejű elemzéséhez.
Előfordulhat, hogy nem Microsoft-megfelelői vannak ezeknek a platformoknak, vagy egy fő adatkezelési (MDM-) rendszer, amelyhez hozzá kell férni az ügyfelek, szállítók, termékek, eszközök stb. konzisztens megbízható adataihoz.
Tipp
A PolyBase leegyszerűsíti a hozzáférést több mögöttes elemzési adattárhoz az Azure-ban az üzleti felhasználók könnyű elérése érdekében.
Ezek az elemzési platformok a vállalaton belüli és kívüli új adatforrások robbanása és az üzleti felhasználók által az új adatok rögzítésére és elemzésére vonatkozó igény miatt jelentek meg. Az új adatforrások a következők:
A gép által létrehozott adatok, például az IoT-érzékelő adatai és a kattintásstream-adatok.
Az emberi adatok, például a közösségi hálózati adatok, a webhelyadatok, az ügyfelek bejövő e-mailjei, a képek és a videók áttekintése.
Egyéb külső adatok, például a nyílt kormányzati adatok és az időjárási adatok.
Ezek az új adatok túlmutatnak a strukturált tranzakciós adatokon és a fő adatforrásokon, amelyek általában adatraktárakat táplálnak, és gyakran a következőket tartalmazzák:
- Részben strukturált adatok, például JSON, XML vagy Avro.
- Strukturálatlan adatok, például szöveg, hang, kép vagy videó, amelyek feldolgozása és elemzése összetettebb.
- Nagy mennyiségű adat, nagy sebességű adat vagy mindkettő.
Ennek eredményeképpen új, összetettebb elemzések jelentek meg, mint például a természetes nyelvi feldolgozás, a gráfelemzés, a mély tanulás, a streamelemzés vagy a nagy mennyiségű strukturált adat összetett elemzése. Az ilyen típusú elemzések általában nem fordulnak elő az adattárházban, ezért nem meglepő, hogy különböző elemzési platformok jelennek meg a különböző elemzési számítási feladatokhoz, ahogy az alábbi ábrán is látható.

Tipp
A több elemzési adattárban lévő adatok úgy néznek ki, mintha minden egy rendszerben lenne, és csatlakoztatni Azure Synapse logikai adattárház-architektúraként ismert.
Mivel ezek a platformok új megállapításokat hoznak létre, normális elvárás, hogy az új megállapításokat kombináljuk a Azure Synapse már ismertekkel, ezt teszi lehetővé a PolyBase.
A PolyBase-adatvirtualizálás Azure Synapse belüli használatával olyan logikai adattárházat valósíthat meg, amelyben a Azure Synapse adatai más Azure-beli és helyszíni elemzési adattárakban, például a HDInsightban, az Azure Cosmos DB-ben vagy a Stream Analyticsből vagy az Event Hubsból Data Lake Storage streamelt adatokhoz vannak csatlakoztatva. Ez a megközelítés csökkenti a felhasználók összetettségét, akik a Azure Synapse külső tábláihoz férnek hozzá, és nem kell tudniuk, hogy az általuk használt adatok több mögöttes elemzési rendszerben vannak tárolva. Az alábbi ábra egy összetett adattárház-struktúrát mutat be, amely viszonylag egyszerűbb, mégis hatékony felhasználói felületi módszerekkel érhető el.

A diagram bemutatja, hogyan kombinálhatók a Microsoft elemzési ökoszisztémájának más technológiái az Azure Synapse logikai adattárház-architektúra képességével. Az adatokat például betöltheti Data Lake Storage, és a Data Factory használatával fürtözheti az adatokat, hogy megbízható adattermékeket hozzon létre, amelyek a Microsoft Lake-adatbázis logikai adatentitásait képviselik. Ezek a megbízható, általánosan ismert adatok ezután felhasználhatók és újra felhasználhatók különböző elemzési környezetekben, például Azure Synapse, Azure Synapse Spark-készletjegyzetfüzetekben vagy az Azure Cosmos DB-ben. Az ezekben a környezetekben létrehozott elemzések a PolyBase által lehetővé tett logikai adattárház-adatvirtualizálási rétegen keresztül érhetők el.
Tipp
A logikai adattárház-architektúra leegyszerűsíti az üzleti felhasználók számára az adatokhoz való hozzáférést, és új értéket ad hozzá az adattárházban már ismertekhez.
Összefoglalás
Miután migrálja az adattárházat Azure Synapse, kihasználhatja a Microsoft elemzési ökoszisztémájának egyéb technológiáit. Ezzel nemcsak modernizálja az adattárházat, hanem a más Azure-beli elemzési adattárakban előállított megállapításokat integrált elemzési architektúrába helyezi.
Az ETL-feldolgozást kibővítheti bármilyen típusú adatok Data Lake Storage való betöltésére, majd a Data Factory használatával nagy léptékben előkészítheti és integrálhatja az adatokat megbízható, általánosan ismert adategységek előállításához. Ezeket az eszközöket az adattárház használhatja fel, és adatelemzők és más alkalmazások érhetik el. Valós idejű és kötegelt elemzési folyamatokat hozhat létre, és gépi tanulási modelleket hozhat létre kötegelt, valós idejű streamelési adatokon és igény szerinti szolgáltatásként.
A PolyBase használatával vagy COPY INTO az adattárházon túlra lépve leegyszerűsítheti az Azure több mögöttes elemzési platformjáról származó megállapításokhoz való hozzáférést. Ehhez hozzon létre holisztikus integrált nézeteket egy logikai adattárházban, amely támogatja a streameléshez, a big data-hez és a hagyományos adattárház-elemzésekhez való hozzáférést BI-eszközökből és alkalmazásokból.
Az adattárház Azure Synapse való migrálásával kihasználhatja az Azure-ban futó gazdag Microsoft-elemzési ökoszisztémát, hogy új értéket teremtsen a vállalatában.
Következő lépések
A dedikált SQL-készletbe való migrálásról további információt az Adattárház migrálása dedikált SQL-készletbe az Azure Synapse Analyticsben című témakörben talál.