Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure Synapse Analytics különböző elemzési motorokat kínál az adatok betöltéséhez, átalakításához, modellezéséhez, elemzéséhez és terjesztéséhez. Az Apache Spark-készlet nyílt forráskódú big data számítási képességeket biztosít. Miután létrehozott egy Apache Spark-készletet a Synapse-munkaterületen, az adatok betölthetők, modellezhetők, feldolgozhatók és terjeszthetők a gyorsabb elemzés érdekében.
Ebben a rövid útmutatóban megtudhatja, hogyan hozhat létre Apache Spark-készletet egy Synapse-munkaterületen az Azure Portal használatával.
Fontos
A Spark-példányok számlázása percenként történik, függetlenül attól, hogy használja-e őket vagy sem. Feltétlenül állítsa le a Spark-példányt, miután befejezte a használatát, vagy állítson be egy rövid időkorlátot. További információkért lásd a cikk Az erőforrások eltávolítása című szakaszát.
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot.
Előfeltételek
- Szüksége lesz Azure-előfizetésre. Szükség esetén hozzon létre egy ingyenes Azure-fiókot
- A Synapse-munkaterületet fogja használni.
Bejelentkezés az Azure Portalra
Jelentkezzen be az Azure portálra
Ugrás a Synapse-munkaterületre
Lépjen arra a Synapse-munkaterületre, ahol az Apache Spark-készlet létrejön, ha beírja a szolgáltatás nevét (vagy közvetlenül az erőforrás nevét) a keresősávba.
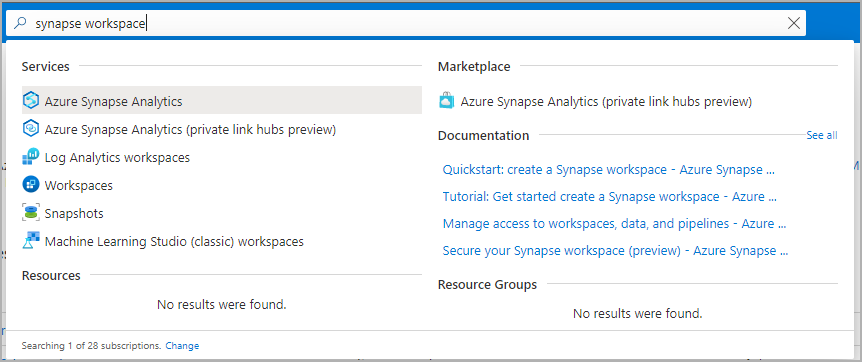
A munkaterületek listájából írja be a megnyitni kívánt munkaterület nevét (vagy a név egy részét). Ebben a példában egy contosoanalytics nevű munkaterületet használunk.
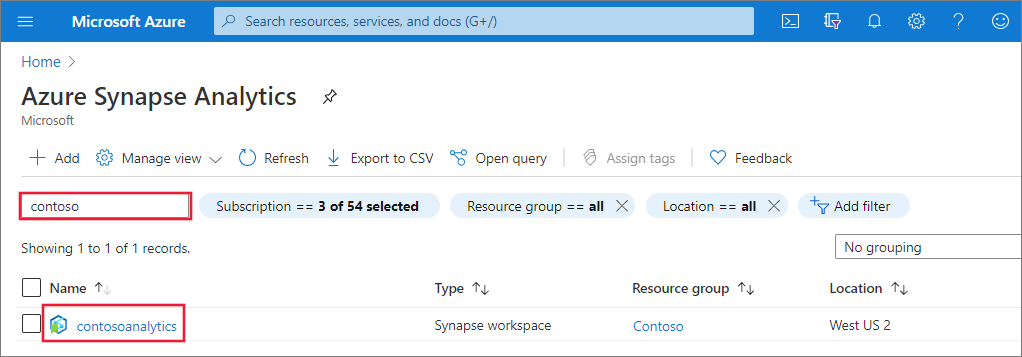


Új Apache Spark-készlet létrehozása
A Synapse-munkaterületen, ahol létre szeretné hozni az Apache Spark-készletet, válassza az Új Apache Spark-készletet.

Adja meg a következő adatokat az Alapismeretek lapon:
Beállítás Ajánlott érték Leírás Apache Spark-készlet neve Érvényes készletnév, például contososparkEz az Apache Spark-készlet neve. Csomópont mérete Kicsi (4 vCPU / 32 GB) Állítsa be ezt a legkisebb méretre a gyorsindítás költségeinek lecsökkentése érdekében. Automatikus méretezés Fogyatékos Ehhez a gyors útmutatóhoz nincs szükség automatikus skálázásra Csomópontok száma 5 A költségek csökkentése érdekében használjon kisebb méretet ennél a gyorsútmutatónál. 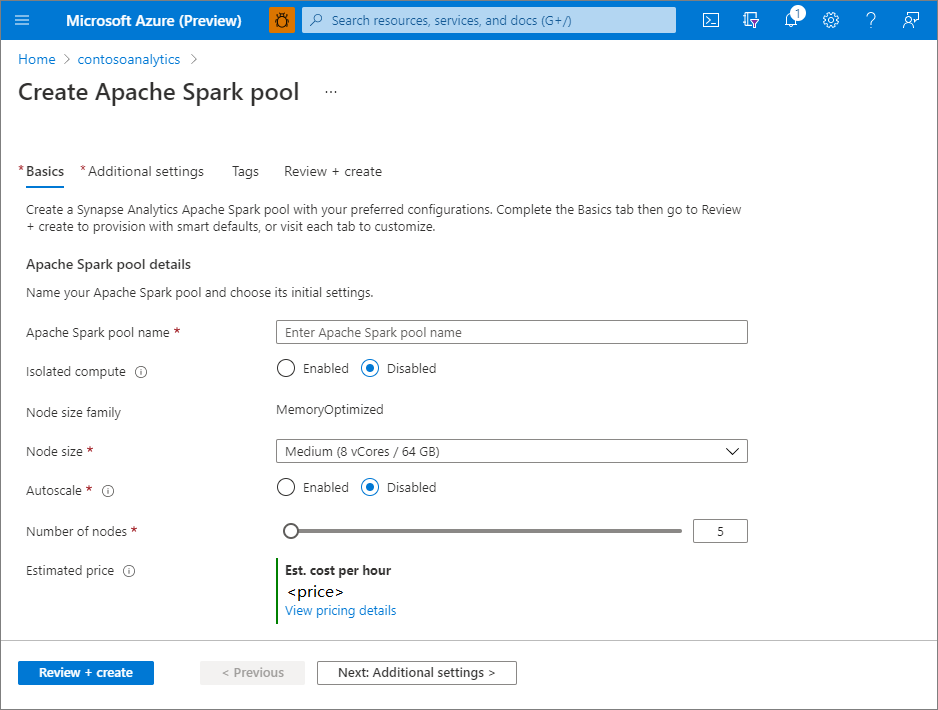
Fontos
Az Apache Spark-készletek által használható nevekre meghatározott korlátozások vonatkoznak. A neveknek csak betűket vagy számokat kell tartalmazniuk, 15 vagy annál kevesebb karakternek kell lenniük, betűvel kell kezdődniük, nem tartalmazhatnak fenntartott szavakat, és egyedinek kell lenniük a munkaterületen.
Válassza a Tovább elemet: további beállítások, és tekintse át az alapértelmezett beállításokat. Ne módosítsa az alapértelmezett beállításokat.

Válassza a Tovább: címkék lehetőséget. Fontolja meg az Azure-címkék használatát. A "Tulajdonos" vagy a "CreatedBy" címke például azonosítja, hogy ki hozta létre az erőforrást, és a "Környezet" címkével azonosíthatja, hogy ez az erőforrás éles környezetben, fejlesztésben stb. található-e. További információ: Az Azure-erőforrások elnevezési és címkézési stratégiájának fejlesztése.
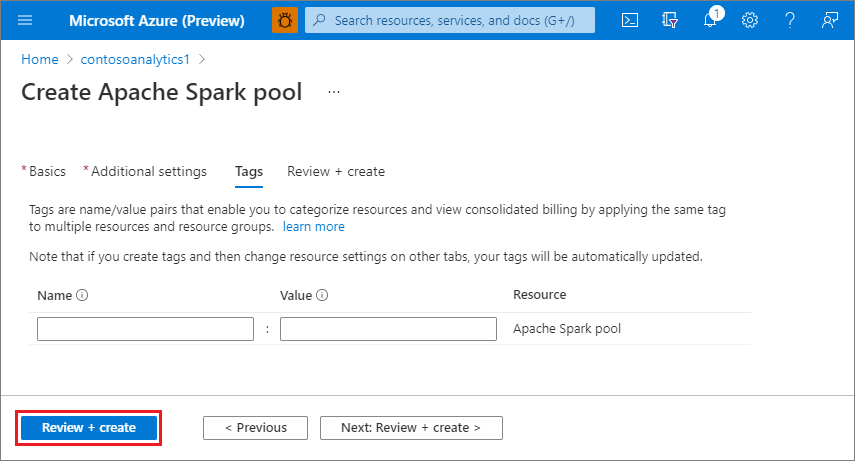
Válassza az Áttekintés + létrehozás lehetőséget.
Győződjön meg arról, hogy a korábban megadott adatok helyesen jelennek meg, majd válassza a Létrehozás lehetőséget.
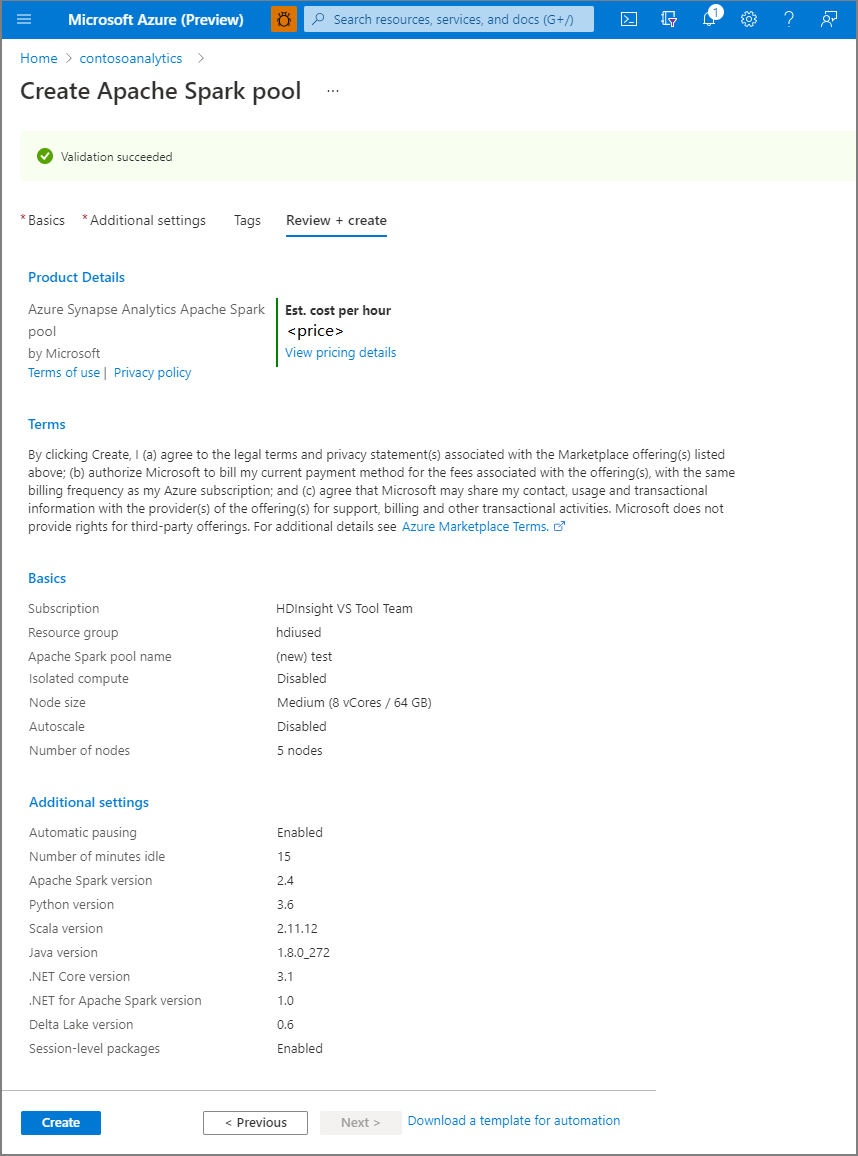
Ekkor elindul az erőforrás-kiépítési folyamat, amely azt jelzi, hogy a folyamat befejeződött.
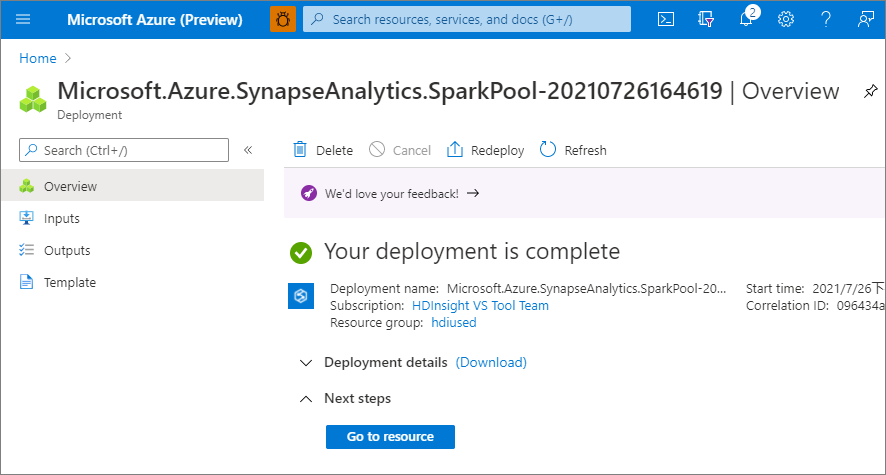
A kiépítés befejezése után a munkaterületre való visszalépéskor megjelenik egy új bejegyzés az újonnan létrehozott Apache Spark-készlethez.

Jelenleg nincsenek futó erőforrások, nincsenek díjak a Sparkért, metaadatokat hozott létre a létrehozni kívánt Spark-példányokról.







Erőforrások tisztítása
Az alábbi lépések törlik az Apache Spark-készletet a munkaterületről.
Figyelmeztetés
Az Apache Spark-készlet törlése eltávolítja az elemzési motort a munkaterületről. A továbbiakban nem lehet csatlakozni a készlethez, és az Apache Spark-készletet használó összes lekérdezés, folyamat és jegyzetfüzet nem fog működni.
Ha törölni szeretné az Apache Spark-készletet, hajtsa végre a következő lépéseket:
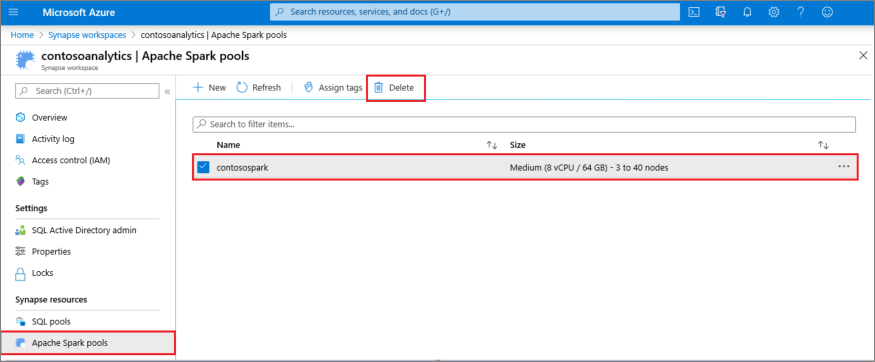
- Lépjen a munkaterületen található Apache Spark készletek paneljához.
- Válassza ki a törölni kívánt Apache Spark-készletet (ebben az esetben a contososparkot).
- Válassza a Törlés lehetőséget.
- Erősítse meg a törlést, és válassza a Törlés gombot.
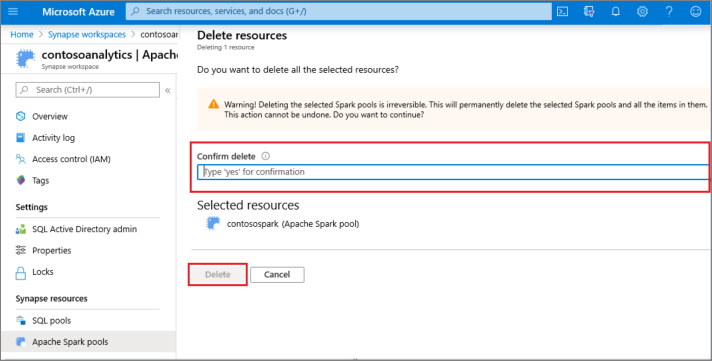
- Ha a folyamat sikeresen befejeződött, az Apache Spark-készlet már nem fog szerepelni a munkaterület erőforrásai között.
