Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben a rövid útmutatóban megtudhatja, hogyan hozhat létre kiszolgáló nélküli Apache Spark-készletet az Azure Synapse-ban webes eszközökkel. Ezután megtanulhat csatlakozni az Apache Spark-készlethez, és Spark SQL-lekérdezéseket futtathat fájlokon és táblákon. Az Apache Spark gyors adatelemzést és klaszterezést biztosít memóriabeli feldolgozás által. További információ az Azure Synapse Sparkról : Áttekintés: Apache Spark az Azure Synapse-on.
Fontos
A Spark-példányok számlázása percenként történik, függetlenül attól, hogy használja-e őket vagy sem. Feltétlenül állítsa le a Spark-példányt, miután befejezte a használatát, vagy állítson be egy rövid időkorlátot. További információkért lásd a cikk Az erőforrások eltávolítása című szakaszát.
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot.
Előfeltételek
- Szüksége lesz Azure-előfizetésre. Szükség esetén hozzon létre egy ingyenes Azure-fiókot
- Synapse Analytics-munkaterület
- Kiszolgáló nélküli Apache Spark-készlet
Bejelentkezés az Azure Portalra
Jelentkezzen be a Azure portalra.
Ha nem rendelkezik Azure-előfizetéssel, hozzon létre egy ingyenes Azure-fiókot mielőtt elkezdi.
Jegyzetfüzet létrehozása
A jegyzetfüzetek olyan interaktív környezetek, amelyek különböző programozási nyelveket támogatnak. A jegyzetfüzet lehetővé teszi az adatokkal való interakciót, a kód markdownnal, szöveggel való kombinálását és egyszerű vizualizációk végrehajtását.
A használni kívánt Azure Synapse-munkaterület Azure Portal nézetében válassza a Synapse Studio indítása lehetőséget.
A Synapse Studio elindítása után válassza a Fejlesztés lehetőséget. Ezután válassza a "+" ikont egy új erőforrás hozzáadásához.
Innen válassza a Jegyzetfüzet lehetőséget. A rendszer létrehoz egy új jegyzetfüzetet, és automatikusan létrehozott névvel nyitja meg.

A Tulajdonságok ablakban adja meg a jegyzetfüzet nevét.
Az eszköztáron kattintson a Közzététel gombra.
Ha a munkaterületen csak egy Apache Spark-készlet található, akkor alapértelmezés szerint ki van választva. A legördülő menüben válassza ki a megfelelő Apache Spark-készletet, ha nincs kiválasztva.
Kattintson a Kód hozzáadása elemre. Az alapértelmezett nyelv az
Pyspark. A Pyspark és a Spark SQL kombinációját fogja használni, így az alapértelmezett választás rendben van. További támogatott nyelvek a Scala és a .NET a Sparkhoz.Ezután létrehoz egy egyszerű Spark DataFrame-objektumot a manipulálásához. Ebben az esetben kódból hozod létre. Három sor és három oszlop van:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Most futtassa a cellát az alábbi módszerek egyikével:
Nyomja le a SHIFT+ENTER billentyűkombinációt.
Válassza a cella bal oldalán található kék lejátszás ikont.
Kattintson az eszköztáron lévő Összes futtatása gombra.
Ha az Apache Spark-készletpéldány még nem fut, az automatikusan elindul. Az Apache Spark-készlet példányának aktuális állapota a futó cella alatt, valamint az állapotpanelen, a jegyzetfüzet alján is látható. A medence méretétől függően az indítás 2-5 percet vesz igénybe. A kód futtatása után a cella alatti információk megjelenítik, hogy mennyi ideig tartott a futtatás és a végrehajtás. A kimeneti cellában megjelenik a kimenet.
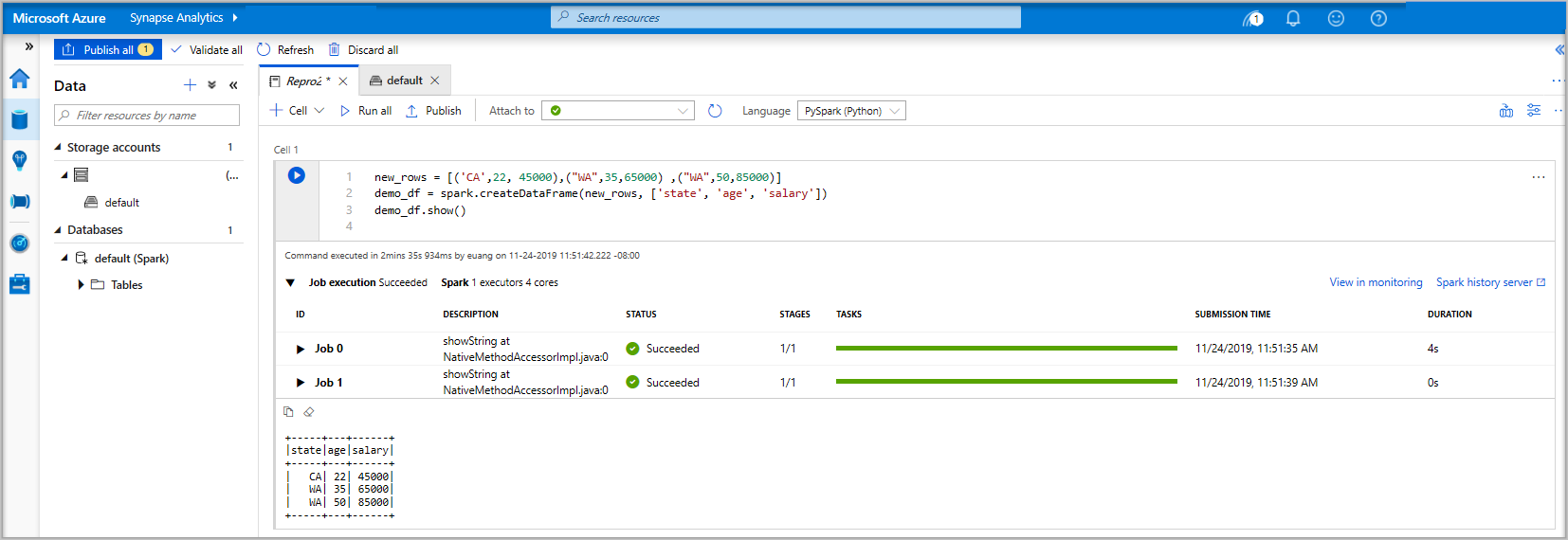
Az adatok most már léteznek egy DataFrame-ben, ahonnan sokféleképpen használhatja az adatokat. A gyorsbevezető további szakaszában különböző formátumokban lesz szüksége rá.
Írja be az alábbi kódot egy másik cellába, és futtassa. Ez létrehoz egy Spark-táblát, egy CSV-t és egy Parquet-fájlt az adatok másolataival:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Ha a Storage Explorert használja, láthatja a fent használt fájlok írásának két különböző módját. Ha nincs megadva fájlrendszer, akkor a rendszer az alapértelmezettet használja, ebben az esetben
default>user>trusted-service-user>demo_df. Az adatok a megadott fájlrendszer helyére kerülnek.Figyelje meg, hogy mind a "csv" és a "parquet" formátumban, mind az írási műveletek során létrejön egy könyvtár sok particionált fájllal.


Spark SQL-utasítások futtatása
A strukturált lekérdezési nyelv (SQL) a leggyakrabban használt és egyúttal legszélesebb körben alkalmazott nyelv az adatok lekérdezésére és definiálására. A Spark SQL az Apache Spark bővítményeként működik a strukturált adatok ismerős SQL-szintaxissal való feldolgozásához.
Illessze be a következő kódot egy üres cellába, majd futtassa a kódot. A parancs felsorolja a készlet tábláinak listáját.
%%sql SHOW TABLESHa jegyzetfüzetet használ az Azure Synapse Apache Spark-készlettel, egy előre beállított beállítást
sqlContextkap, amellyel lekérdezéseket futtathat a Spark SQL használatával.%%sqlutasítja a jegyzetfüzetet, hogy használja az előre beállítottsqlContexta lekérdezés futtatásához. A lekérdezés lekéri az első 10 sort egy olyan rendszertáblából, amely alapértelmezés szerint az összes Azure Synapse Apache Spark-készletet tartalmazza.Futtasson egy másik lekérdezést a
demo_dfadatainak megtekintéséhez.%%sql SELECT * FROM demo_dfA kód két kimeneti cellát hoz létre, az egyik az adatokat tartalmazza, a másik pedig a feladatnézetet jeleníti meg.
Alapértelmezés szerint az eredménynézet egy rácsot jelenít meg. A rács alatt azonban van egy nézetváltó, amely lehetővé teszi, hogy a nézet váltson a rács- és a gráfnézetek között.

A Nézetváltóban válassza a Diagram lehetőséget.
Válassza a Nézet beállításai ikont a jobb szélen.
A Diagram típusa mezőben válassza a "sávdiagram" lehetőséget.
Az X tengely oszlopmezőjében válassza az "állapot" lehetőséget.
Az Y tengely oszlopmezőjében válassza a "fizetés" lehetőséget.
Az Összesítés mezőben válassza az "AVG" lehetőséget.
Válassza az Alkalmazás lehetőséget.

Lehetőség van ugyanazt az SQL futtatási élményt megszerezni, anélkül, hogy nyelvet kellene váltani. Ezt úgy teheti meg, hogy lecseréli a fenti SQL-cellát erre a PySpark-cellára, a kimeneti felület ugyanaz, mert a megjelenítési parancsot használja:
display(spark.sql('SELECT * FROM demo_df'))A korábban végrehajtott cellák mindegyikének lehetősége volt az Előzmények kiszolgálóra és a Figyelésre lépni. A hivatkozásokra kattintva a felhasználói élmény különböző részeire léphet.
Megjegyzés
Az Apache Spark néhány hivatalos dokumentációja a Spark-konzol használatára támaszkodik, amely nem érhető el a Synapse Sparkban. Használja inkább a jegyzetfüzetet vagy az IntelliJ-szolgáltatásokat .
Erőforrások tisztítása
Az Azure Synapse menti az adatokat az Azure Data Lake Storage-ban. Biztonságosan hagyhatja, hogy egy Spark-példány leálljon, ha nincs használatban. A kiszolgáló nélküli Apache Spark-készletért díjat számítunk fel, amíg az fut, még akkor is, ha nincs használatban.
Mivel az úszómedence díjai sokszor magasabbak, mint a tárolási díjak, ezért gazdasági szempontból érdemes a Spark-példányokat leállítani, ha nincsenek használatban.
A Spark-példány leállítása érdekében zárja be a csatlakoztatott munkameneteket (jegyzetfüzeteket). A készlet leáll az Apache Spark-készletben megadott tétlenségi idő elérésekor. A befejezési munkamenetet a jegyzetfüzet alján található állapotsorból is kiválaszthatja.
Következő lépések
Ebben a rövid útmutatóban megtanulta, hogyan hozhat létre kiszolgáló nélküli Apache Spark-készletet, és hogyan futtathat egy alapszintű Spark SQL-lekérdezést.