Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben a rövid útmutatóban az Azure Synapse Analytics használatával fog létrehozni egy folyamatot, amely egy Azure Data Lake Storage Gen2 -forrásból (ADLS Gen2) származó adatokat alakít át egy ADLS Gen2-fogadóvá leképezési adatfolyam használatával. A rövid útmutatóban szereplő konfigurációs minta kibontható az adatok leképezési adatfolyam használatával történő átalakításakor
Ebben a rövid útmutatóban a következő lépéseket kell elvégeznie:
- Hozzon létre egy folyamatot egy Adatfolyam tevékenységgel az Azure Synapse Analyticsben.
- Leképezési adatfolyam létrehozása négy átalakítással.
- A folyamat próbafuttatása
- Adatfolyam tevékenység figyelése
Előfeltételek
Azure-előfizetés: Ha nem rendelkezik Azure-előfizetéssel, a kezdés előtt hozzon létre egy ingyenes Azure-fiókot .
Azure Synapse-munkaterület: Synapse-munkaterület létrehozása az Azure Portal használatával a következő rövid útmutató utasításai szerint: Synapse-munkaterület létrehozása.
Azure Storage-fiók: Az ADLS-tárolót használja forrás- és fogadóadattárként. Ha még nem rendelkezik tárfiókkal, tekintse meg az Azure Storage-fiók létrehozásának lépéseit ismertető cikket.
Az oktatóanyagban átalakítandó fájl MoviesDB.csv, amely itt található. Ha le szeretné kérni a fájlt a GitHubról, másolja a tartalmat egy tetszőleges szövegszerkesztőbe, és mentse helyileg .csv fájlként. Ha fel szeretné tölteni a fájlt a tárfiókba, olvassa el a Blobok feltöltése az Azure Portallal című témakört. A példák egy "sample-data" nevű tárolóra fognak hivatkozni.
Ugrás a Synapse Studióra
Az Azure Synapse-munkaterület létrehozása után kétféleképpen nyithatja meg a Synapse Studiót:
- Nyissa meg a Synapse-munkaterületet az Azure Portalon. Válassza a Megnyitás a Synapse Studio-kártyán az Első lépések csoportban.
- Nyissa meg az Azure Synapse Analyticset , és jelentkezzen be a munkaterületre.
Ebben a rövid útmutatóban az "adftest2020" nevű munkaterületet használjuk példaként. Automatikusan a Synapse Studio kezdőlapjára navigál.
Folyamat létrehozása Adatfolyam tevékenységgel
A folyamatok a tevékenységek egy csoportjának végrehajtásához szükséges logikai folyamatot tartalmazzák. Ebben a szakaszban egy Adatfolyam tevékenységet tartalmazó folyamatot fog létrehozni.
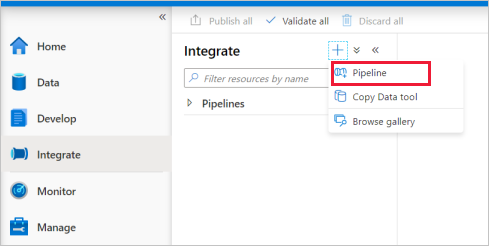
Lépjen az Integrálás lapra. Válassza a folyamatfejléc melletti plusz ikont, és válassza a Folyamat lehetőséget.
A folyamat Tulajdonságok beállításai lapján adja meg a TransformMovies for Name kifejezést.
A Tevékenységek panel Áthelyezés és átalakítás területén húzza az adatfolyamot a folyamatvászonra.
Az Adatfolyam hozzáadása lap előugró ablakában válassza az Új adatfolyam létrehozása –>Adatfolyam lehetőséget. Kattintson az OK gombra, amikor végzett.

Nevezze el az adatfolyamot a TransformMovies névvel a Tulajdonságok lapon.
Átalakítási logika létrehozása az adatfolyam-vásznon
A Adatfolyam létrehozása után a rendszer automatikusan elküldi az adatfolyam-vászonra. Ebben a lépésben létrehoz egy adatfolyamot, amely az ADLS-tárolóban lévő MoviesDB.csv veszi át, és összesíti a 1910 és 2000 közötti átlagos besorolást. Ezután visszaírja ezt a fájlt az ADLS-tárolóba.
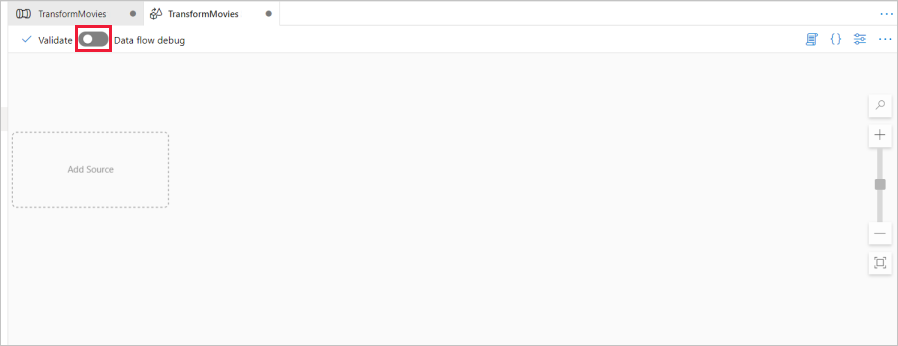
Az adatfolyam-vászon fölött húzza be az adatfolyam hibakeresési csúszkát. A hibakeresési mód lehetővé teszi az átalakítási logika interaktív tesztelését egy élő Spark-fürtön. Adatfolyam fürtök bemelegedése 5-7 percet vesz igénybe, és a felhasználóknak ajánlott először bekapcsolniuk a hibakeresést, ha Adatfolyam fejlesztést terveznek. További információ: Hibakeresési mód.
Az adatfolyam-vásznon adjon hozzá egy forrást a Forrás hozzáadása mezőre kattintva.
Nevezze el a forrás MoviesDB-t. Új forrásadatkészlet létrehozásához válassza az Új lehetőséget.
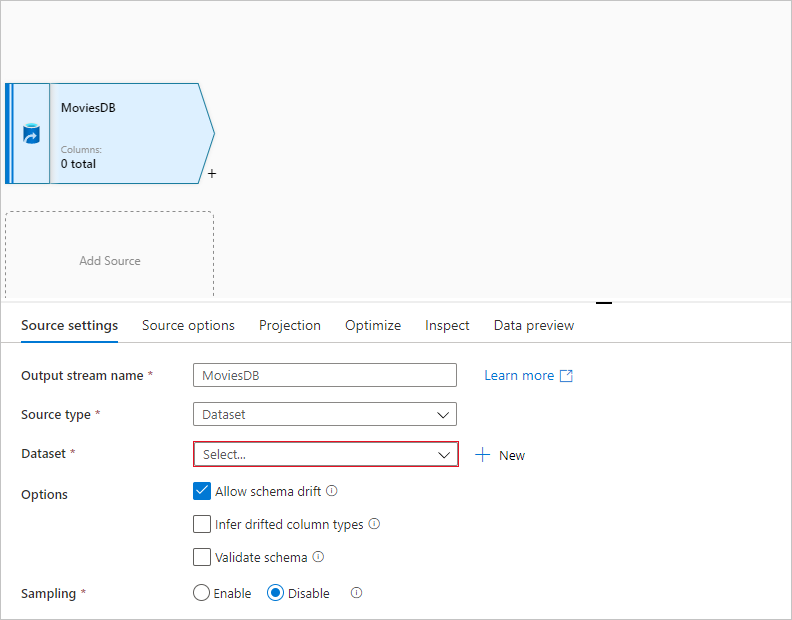
Válassza az Azure Data Lake Storage Gen2 lehetőséget. Válassza a Folytatás lehetőséget.

Válassza a DelimitedText lehetőséget. Válassza a Folytatás lehetőséget.
Nevezze el az adathalmazt a MoviesDB-nek. A társított szolgáltatás legördülő listájában válassza az Új lehetőséget.
A társított szolgáltatás létrehozási képernyőjén adja meg az ADLS Gen2 társított ADLSGen2 szolgáltatást, és adja meg a hitelesítési módszert. Ezután adja meg a kapcsolat hitelesítő adatait. Ebben a rövid útmutatóban az Account billentyűt használjuk a tárfiókhoz való csatlakozáshoz. A Kapcsolat tesztelése lehetőséget választva ellenőrizheti, hogy a hitelesítő adatok helyesen lettek-e beállítva. Miután végzett, válassza a Létrehozás lehetőséget.
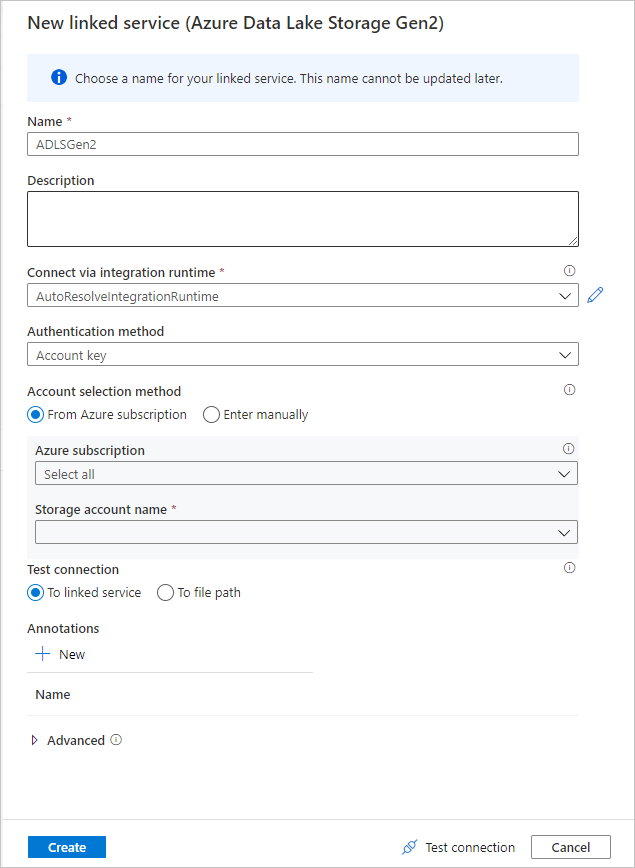
Miután visszatért az adathalmaz létrehozási képernyőjére, a Fájl elérési útja mező alatt adja meg a fájl helyét. Ebben a rövid útmutatóban a "MoviesDB.csv" fájl a "sample-data" tárolóban található. Mivel a fájl fejlécekkel rendelkezik, ellenőrizze az Első sort fejlécként. Válassza a Kapcsolat/tár lehetőséget a fejlécséma közvetlen importálásához a tárban lévő fájlból. Kattintson az OK gombra, amikor végzett.
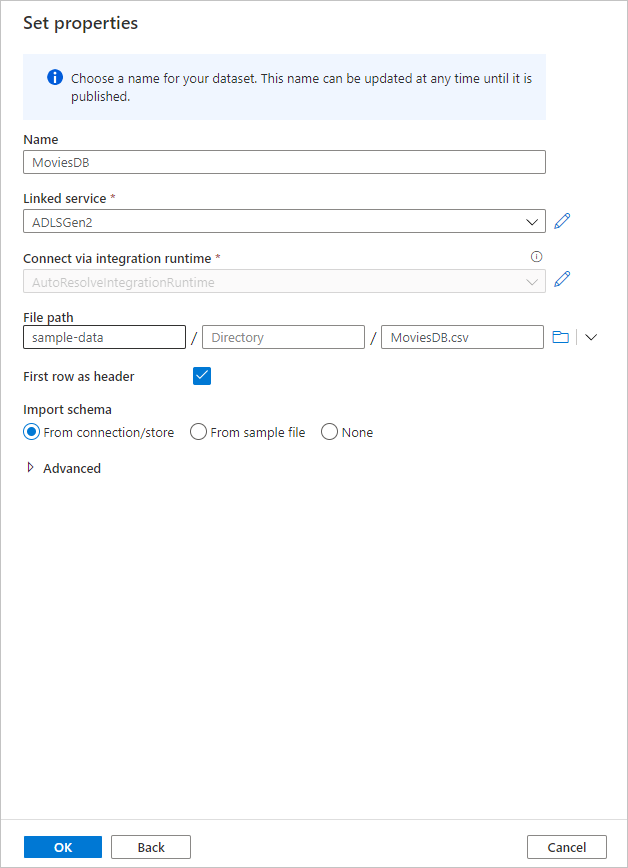
Ha a hibakeresési fürt elindult, lépjen a forrásátalakítás Adatelőnézet lapjára, és válassza a Frissítés lehetőséget az adatok pillanatképének lekéréséhez. Az adatelőnézet használatával ellenőrizheti, hogy az átalakítás megfelelően van-e konfigurálva.
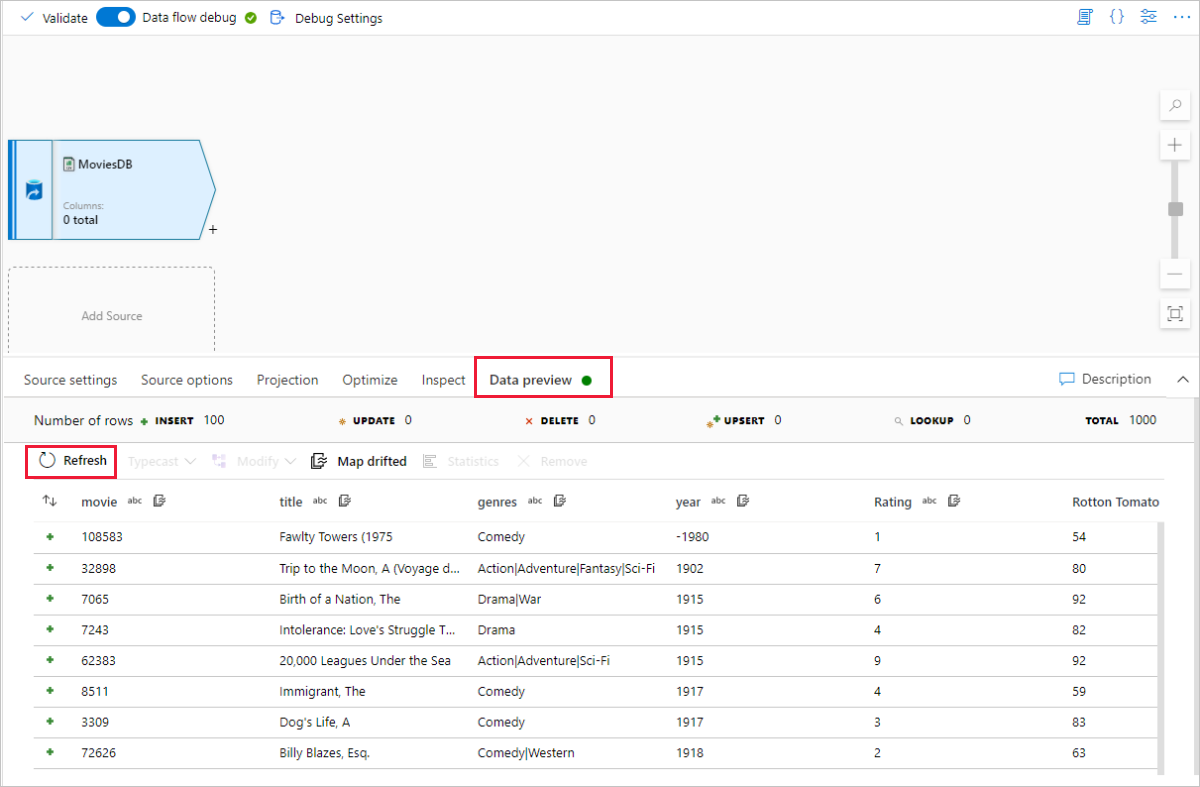
Az adatfolyam-vásznon a forráscsomópont mellett válassza a plusz ikont egy új átalakítás hozzáadásához. Az első hozzáadott átalakítás egy szűrő.
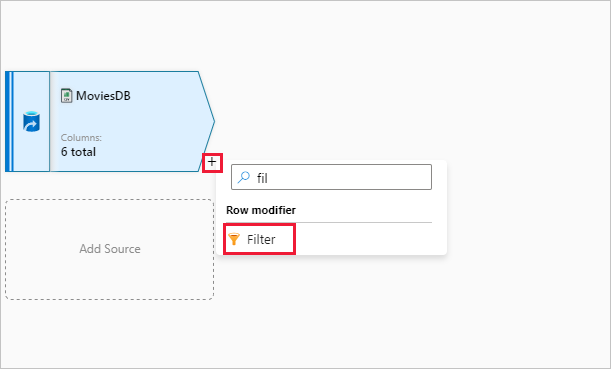
Nevezze el a szűrőátalakítás Szűrőévek nevet. A kifejezésszerkesztő megnyitásához válassza a Szűrő bekapcsolva gomb melletti kifejezésmezőt. Itt adhatja meg a szűrési feltételt.
Az adatfolyam-kifejezésszerkesztővel interaktívan hozhat létre különböző átalakításokban használható kifejezéseket. A kifejezések tartalmazhatnak beépített függvényeket, a bemeneti sémából származó oszlopokat és felhasználó által definiált paramétereket. A kifejezések készítéséről további információt Adatfolyam kifejezésszerkesztőben talál.
Ebben a rövid útmutatóban az 1910 és 2000 között megjelent műfaji vígjátékok filmjeit szeretné szűrni. Mivel az év jelenleg sztring, a függvény használatával egész számmá kell alakítania
toInteger(). Az 1910-es és a 200-es literális évértékekkel való összehasonlításhoz használja a nagyobb vagy egyenlő (>=) és (<=) operátorokat. Egyesítve ezeket a kifejezéseket a&&(és) operátorral. A kifejezés a következőképpen jelenik meg:toInteger(year) >= 1910 && toInteger(year) <= 2000Ha meg szeretné találni, hogy mely filmek vígjátékok, a függvény segítségével megtalálhatja a
rlike()"Comedy" mintát az oszlop műfajaiban. Egyesíteni kell arlikekifejezést az év összehasonlításával a következőhöz:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')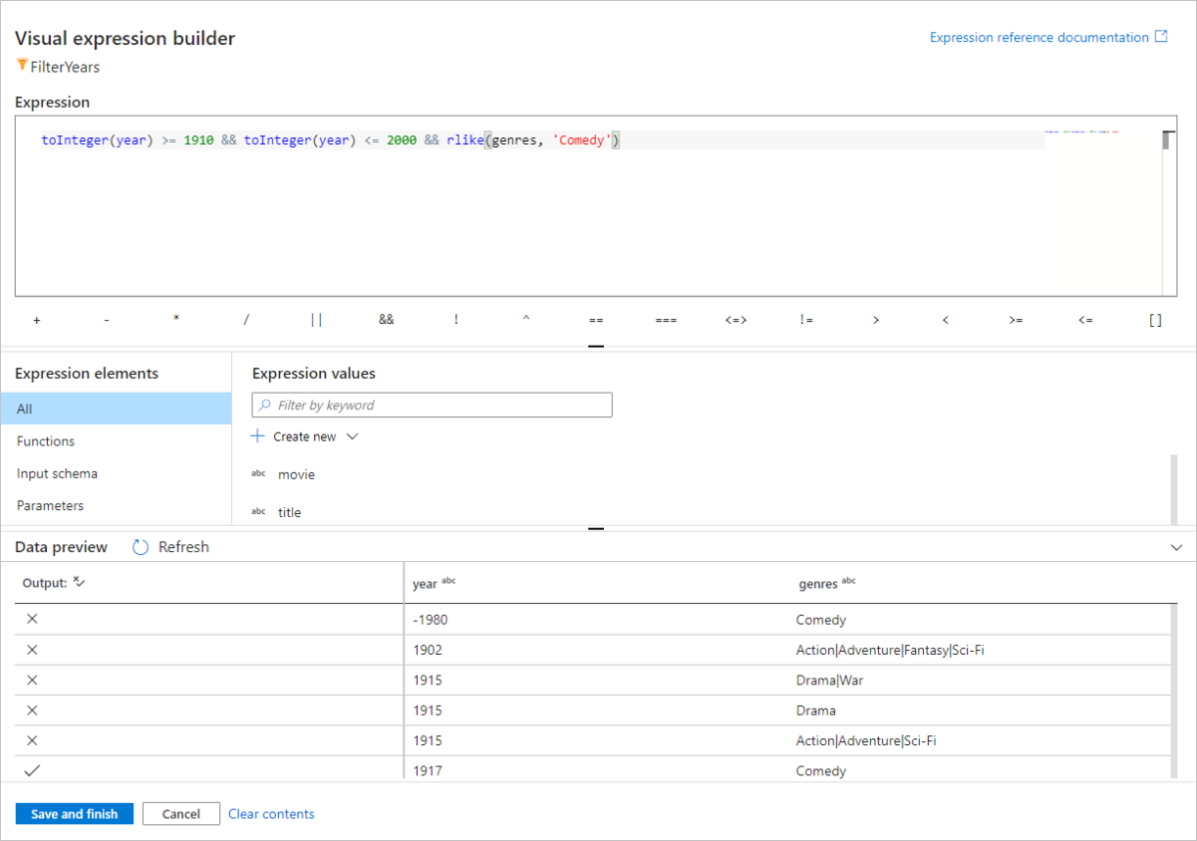
Ha aktív hibakeresési fürtje van, a Frissítés gombra kattintva ellenőrizheti a logikát a használt bemenetekhez képest a kifejezéskimenet megtekintéséhez. Több helyes válasz is van arra, hogyan valósíthatja meg ezt a logikát az adatfolyam-kifejezés nyelvével.
Ha végzett a kifejezéssel, válassza a Mentés és befejezés lehetőséget.
Adatelőnézet beolvasásával ellenőrizze, hogy a szűrő megfelelően működik-e.
A következő átalakítási művelet a Sémamódosító alatt lévő Összesítés átalakítás.
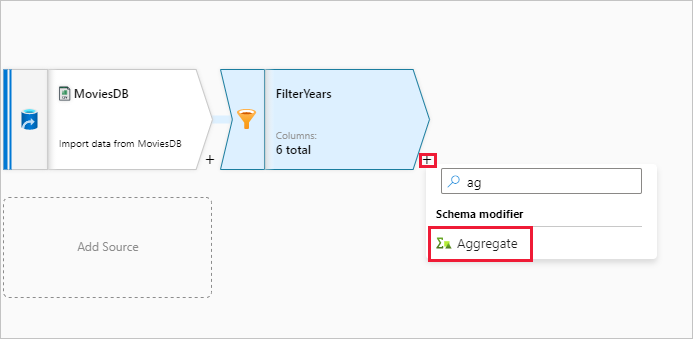
Nevezze el összesített átalakítását AggregateComedyRatings néven. A Csoportosítás lapon válassza ki az évet a legördülő listából, és csoportosítsa az összesítéseket a film kiadásának évéhez.
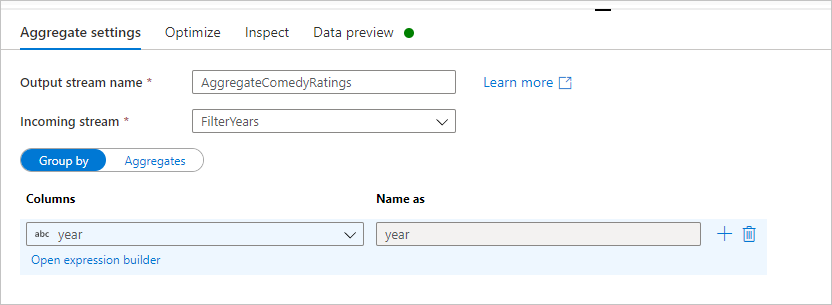
Lépjen az Összesítések lapra. A bal oldali szövegmezőben nevezze el az AverageComedyRating összesítő oszlopot. A megfelelő kifejezésmezőt választva adja meg az összesítő kifejezést a kifejezésszerkesztőn keresztül.
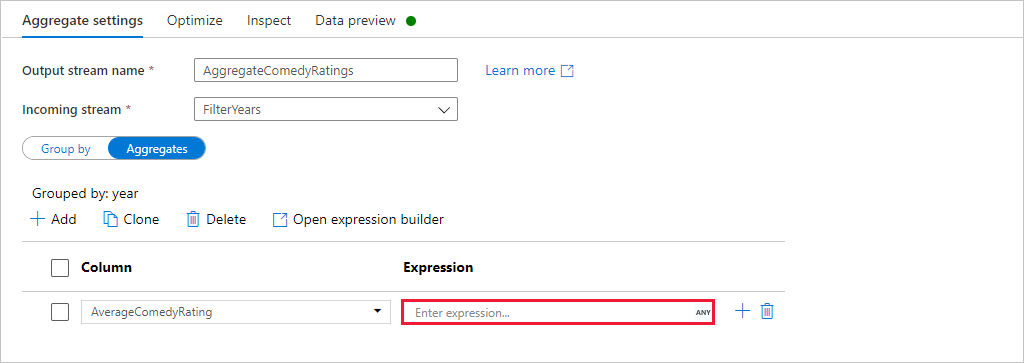
Az oszlopminősítés átlagának lekéréséhez használja az összesítő függvényt
avg(). Mivel a Rating egy sztring, ésavg()numerikus bemenetet vesz fel, az értéket számmá kell konvertálnunk atoInteger()függvényen keresztül. Ez a kifejezés a következőképpen néz ki:avg(toInteger(Rating))Ha elkészült, válassza a Mentés és befejezés lehetőséget.
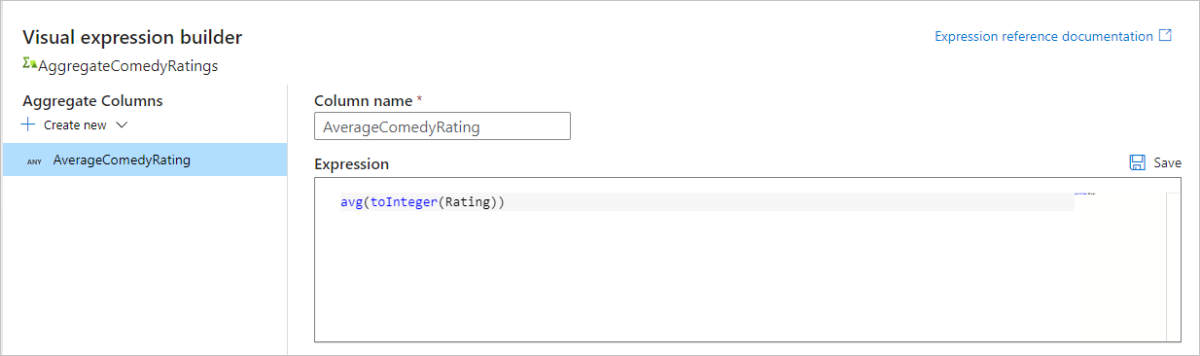
Az átalakítási kimenet megtekintéséhez lépjen az Adatelőnézet lapra. Figyelje meg, hogy csak két oszlop van, év és AverageComedyRating.
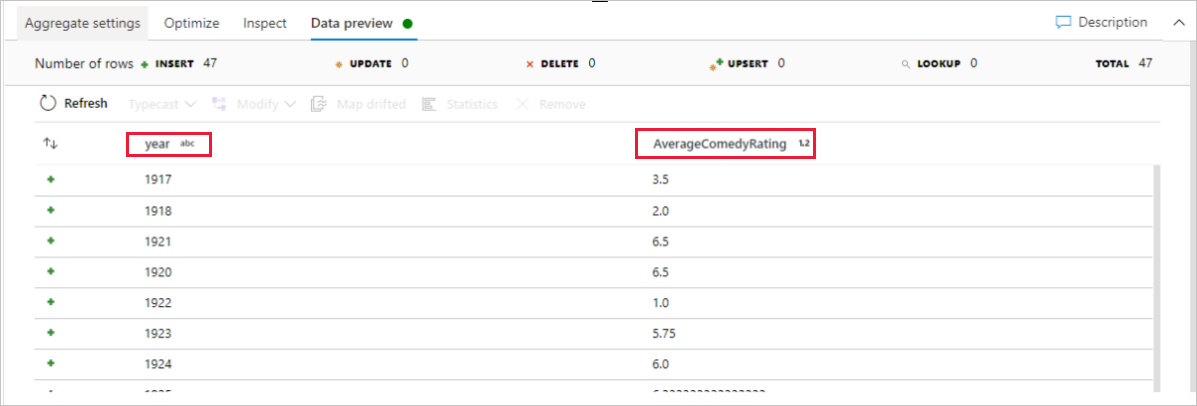
A következő lépésben egy Fogadó átalakítást szeretne hozzáadni a Cél területen.
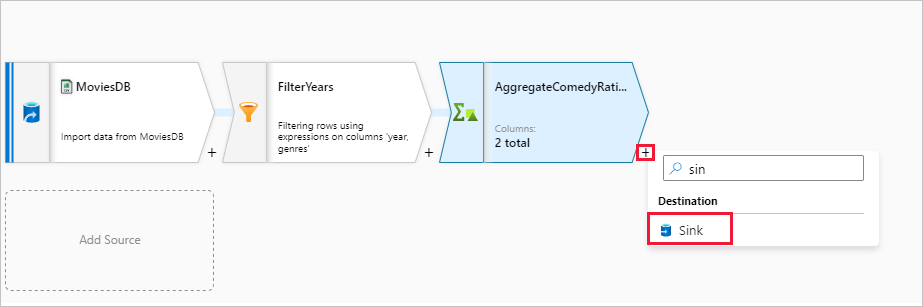
Nevezze el a fogadó fogadóját. Válassza az Új lehetőséget a fogadóadatkészlet létrehozásához.
Válassza az Azure Data Lake Storage Gen2 lehetőséget. Válassza a Folytatás lehetőséget.
Válassza a DelimitedText lehetőséget. Válassza a Folytatás lehetőséget.
Nevezze el a Fogadó adatkészletet a MoviesSink névvel. Csatolt szolgáltatás esetén válassza ki a 7. lépésben létrehozott ADLS Gen2 társított szolgáltatást. Adjon meg egy kimeneti mappát az adatok írásához. Ebben a rövid útmutatóban a "sample-data" tároló "output" mappájába írunk. A mappának nem kell előzetesen léteznie, és dinamikusan létrehozható. Állítsa be az első sort fejlécként igazként, és válassza a Nincs az importálási sémához lehetőséget. Kattintson az OK gombra, amikor végzett.
Most befejezte az adatfolyam összeállítását. Készen áll a folyamat futtatására.
A Adatfolyam futtatása és figyelése
A közzététel előtt hibakeresést végezhet egy folyamaton. Ebben a lépésben elindítja az adatfolyam-folyamat hibakeresési futását. Bár az adatelőnézet nem ír adatokat, a hibakeresési futtatás adatokat ír a fogadó célhelyére.
Lépjen a folyamatvászonra. Hibakeresési futtatás indításához válassza a Hibakeresés lehetőséget.
A Adatfolyam tevékenységek folyamatbeli hibakeresése az aktív hibakeresési fürtöt használja, de az inicializálás legalább egy percet vesz igénybe. Az előrehaladást a Kimenet lapon követheti nyomon. Miután a futtatás sikeres volt, válassza a szemüveg ikont a monitorozási panel megnyitásához.

A monitorozási panelen láthatja az egyes átalakítási lépések során eltelt sorok és idő számát.
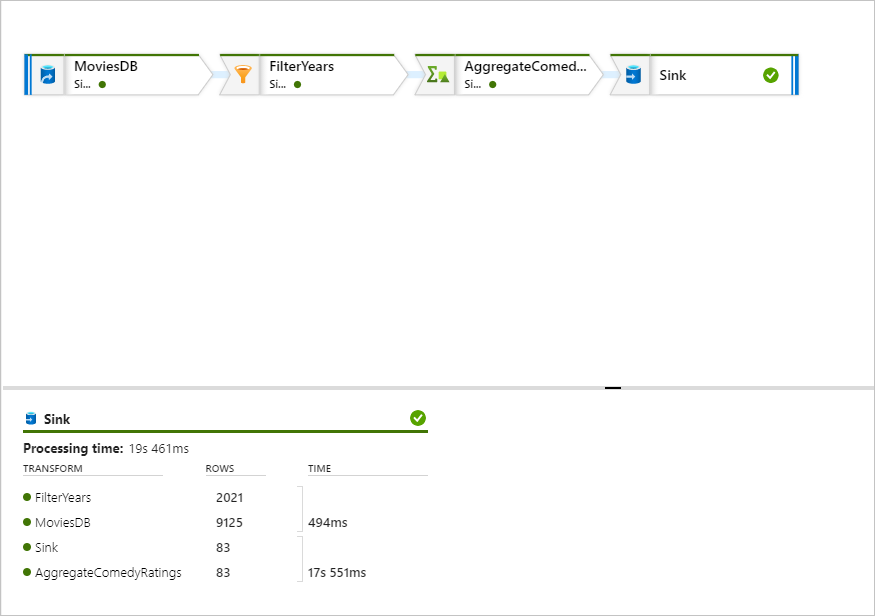
Az átalakítás kiválasztásával részletes információkat kaphat az oszlopokról és az adatok particionálásáról.
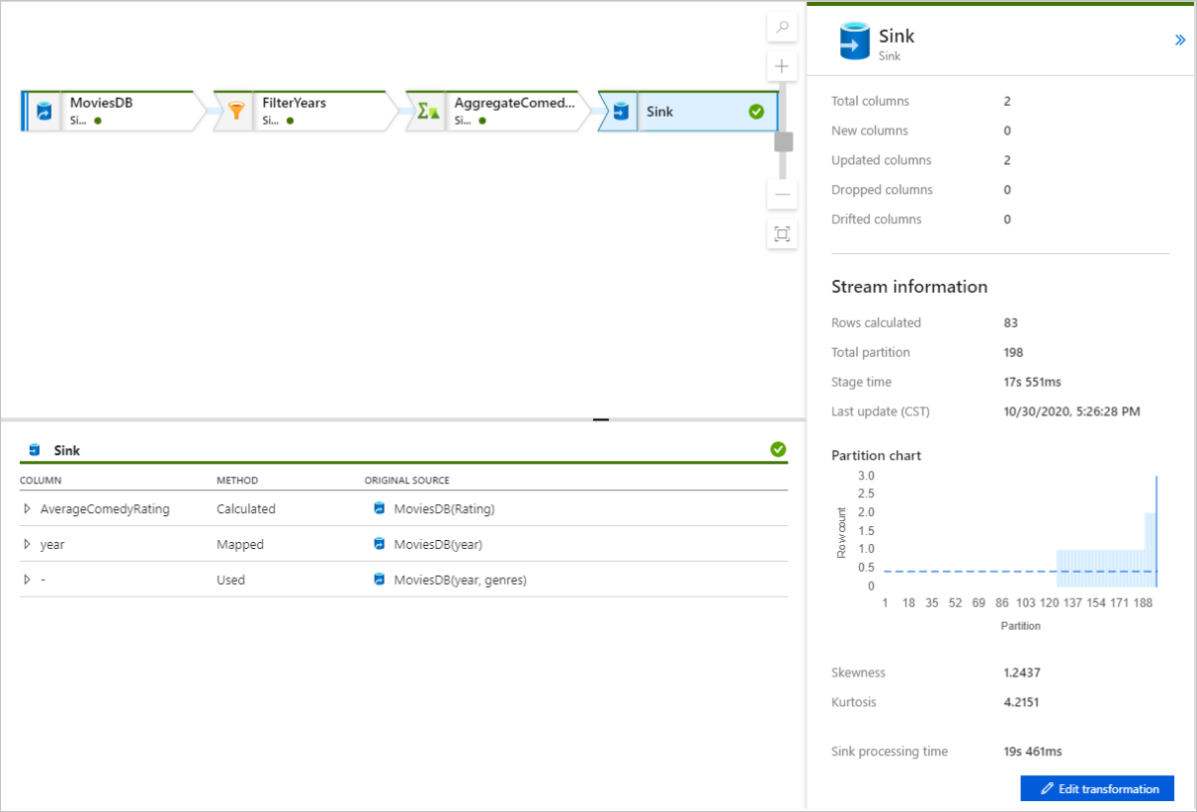
Ha helyesen követte ezt a rövid útmutatót, 83 sort és 2 oszlopot kellett volna írnia a fogadó mappájába. Az adatokat a blobtároló ellenőrzésével ellenőrizheti.
Következő lépések
Az Azure Synapse Analytics támogatásáról a következő cikkekben olvashat: