Oktatóanyag: Apache Spark-alkalmazás létrehozása az IntelliJ-vel Synapse-munkaterület használatával
Ez az oktatóanyag bemutatja, hogyan használhatja az Azure Toolkit for IntelliJ beépülő modult a Scalában írt Apache Spark-alkalmazások fejlesztéséhez, majd közvetlenül az IntelliJ integrált fejlesztői környezetből (IDE) egy kiszolgáló nélküli Apache Spark-készletbe való beküldéséhez. A beépülő modult többféleképpen is használhatja:
- Scala Spark-alkalmazás fejlesztése és elküldése Spark-készleten.
- A Spark-készletek erőforrásainak elérése.
- Scala Spark-alkalmazás helyi fejlesztése és futtatása.
Ebben az oktatóanyagban az alábbiakkal fog megismerkedni:
- Az Azure Toolkit for IntelliJ beépülő modul használata
- Apache Spark-alkalmazások fejlesztése
- Alkalmazás küldése Spark-készletekbe
Előfeltételek
Azure toolkit plugin 3.27.0-2019.2 – Telepítés az IntelliJ beépülő modul adattárából
Scala Beépülő modul – Telepítés az IntelliJ beépülő modul adattárából.
A következő előfeltételek csak Windows-felhasználók számára szükségesek:
Ha windowsos számítógépen futtatja a helyi Spark Scala alkalmazást, kivételt kaphat a SPARK-2356-ban leírtak szerint. A kivétel azért fordul elő, mert a WinUtils.exe hiányzik a Windowsból. A hiba megoldásához töltse le a végrehajtható WinUtilst egy olyan helyre, mint a C:\WinUtils\bin. Ezután adja hozzá a környezeti változót HADOOP_HOME, és állítsa a változó értékét a C:\WinUtils értékre.
Spark Scala-alkalmazás létrehozása Spark-készlethez
Indítsa el az IntelliJ IDEA-t, és válassza az Új projekt létrehozása lehetőséget az Új projekt ablak megnyitásához.
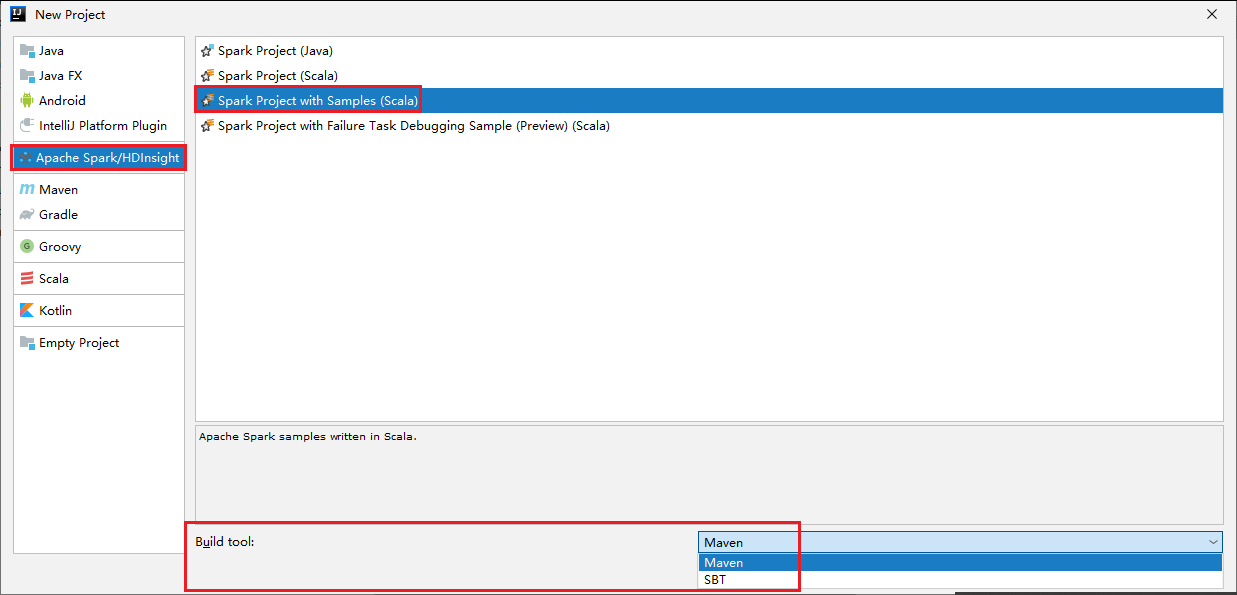
Válassza az Apache Spark/HDInsight lehetőséget a bal oldali panelen.
Válassza a Spark Project with Samples (Scala) lehetőséget a főablakból.
A Build eszköz legördülő listájában válasszon az alábbi típusok közül:
- A Maven a Scala projektlétrehozási varázslójának támogatása.
- SBT a függőségek kezeléséhez és a Scala-projekt létrehozásához.
Válassza a Következő lehetőséget.
Az Új projekt ablakban adja meg a következő információkat:
Property Leírás Projekt neve Adjon meg egy nevet. Ebben az oktatóanyagban a következőt használjuk: myApp.Projekt helye Adja meg a kívánt helyet a projekt mentéséhez. Project SDK Lehet, hogy az IDEA első használatakor üres. Válassza az Új lehetőséget... és lépjen a JDK-ra. Spark-verzió A létrehozási varázsló integrálja a Spark SDK és a Scala SDK megfelelő verzióját. Itt kiválaszthatja a szükséges Spark-verziót. 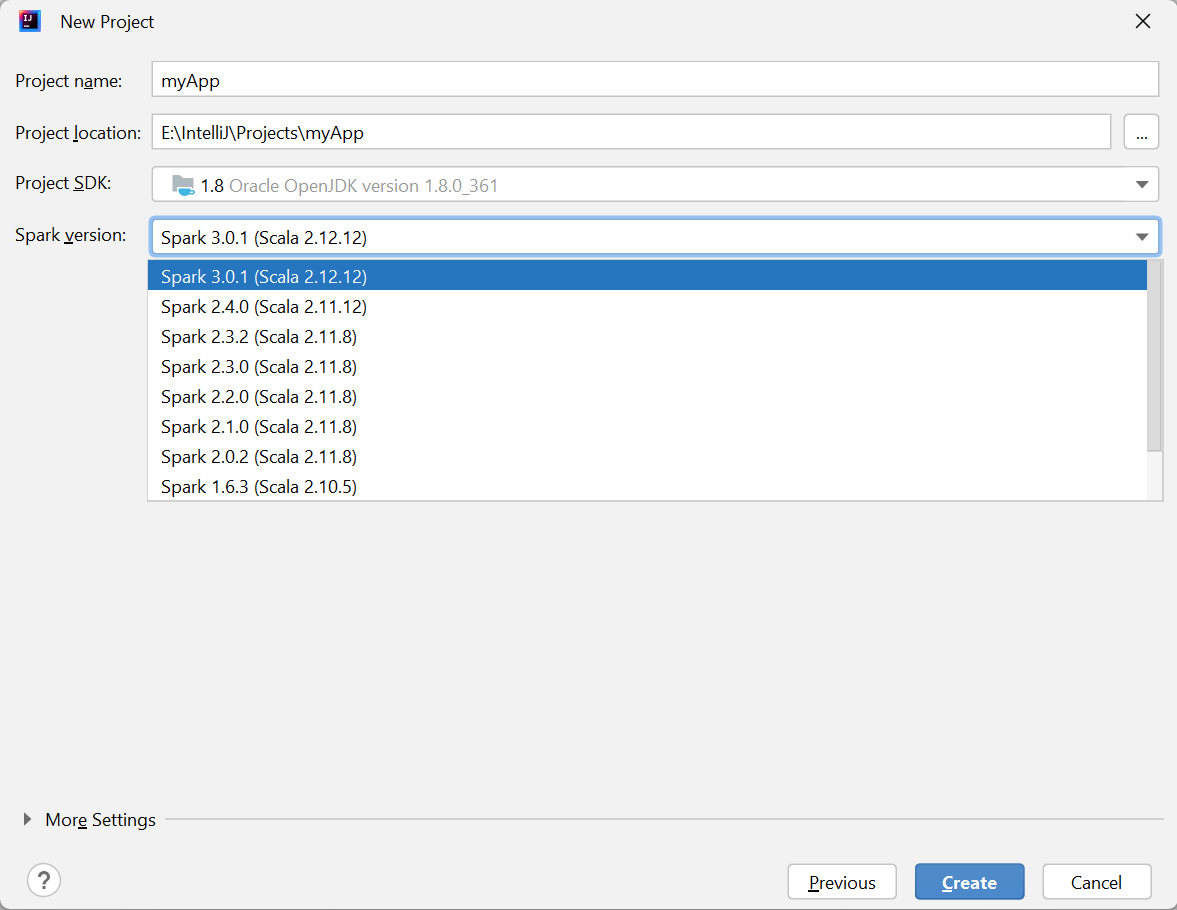
Válassza a Befejezés lehetőséget. A projekt elérhetővé válása eltarthat néhány percig.
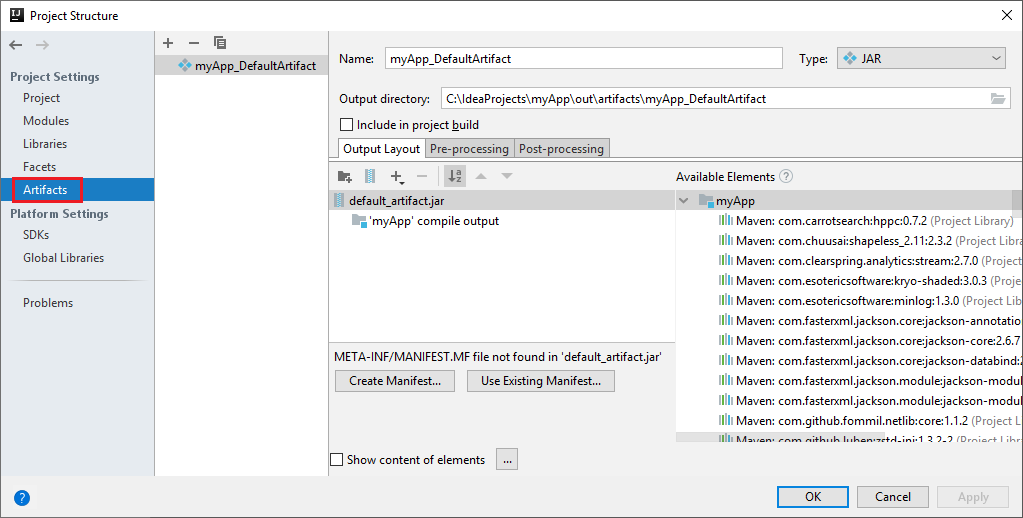
A Spark-projekt automatikusan létrehoz egy összetevőt. Az összetevő megtekintéséhez végezze el a következő műveleteket:
a. A menüsávon navigáljon a Fájlprojekt>struktúrája... elemre.
b. A Projektstruktúra ablakban válassza az Összetevők lehetőséget.
c. Válassza a Mégse elemet az összetevő megtekintése után.
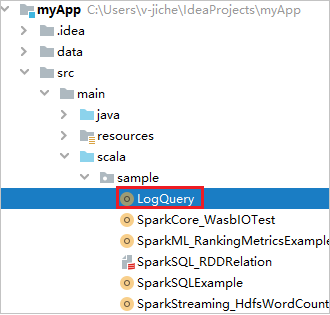
Keresse meg a LogQueryt a myApp>src>fő>Scala-minta>>LogQueryből. Ez az oktatóanyag a LogQueryt használja a futtatáshoz.
Csatlakozás a Spark-készletekhez
Jelentkezzen be az Azure-előfizetésbe a Spark-készletekhez való csatlakozáshoz.
Jelentkezzen be az Azure-előfizetésébe
A menüsávon navigáljon a Windows>Azure Explorer Nézet>eszközre.
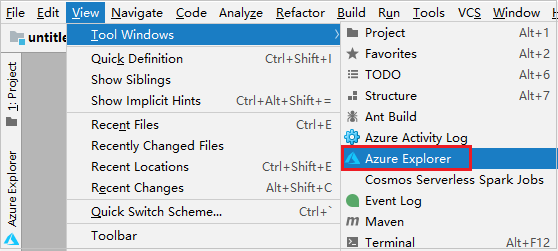
Az Azure Explorerben kattintson a jobb gombbal az Azure-csomópontra , majd válassza a Bejelentkezés lehetőséget.
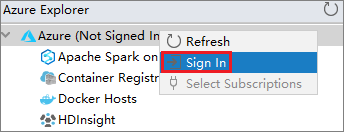
Az Azure Bejelentkezési párbeszédpanelen válassza az Eszközbejelentkeztetés, majd a Bejelentkezés lehetőséget.
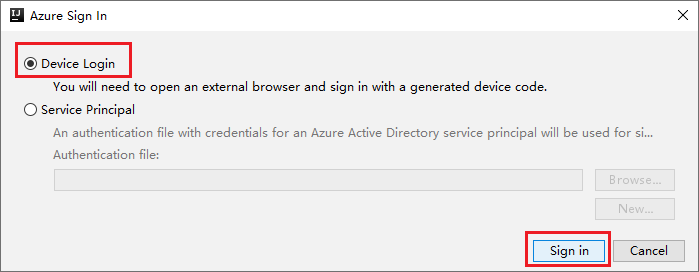
Az Azure Device Login párbeszédpanelen válassza a Másolás> Megnyitás lehetőséget.
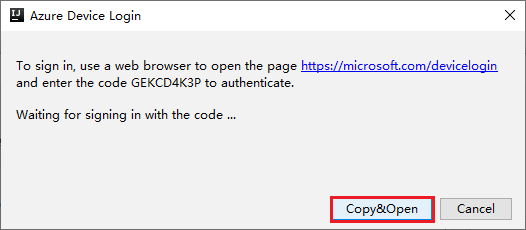
A böngészőfelületen illessze be a kódot, majd válassza a Tovább gombot.
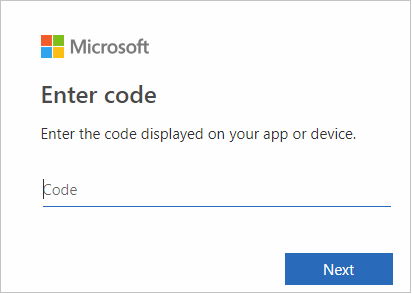
Adja meg azure-beli hitelesítő adatait, majd zárja be a böngészőt.
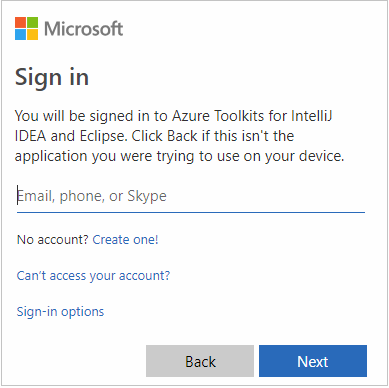
Miután bejelentkezett, az Előfizetések kiválasztása párbeszédpanel felsorolja a hitelesítő adatokhoz társított Összes Azure-előfizetést. Válassza ki az előfizetést, majd válassza a Kiválasztás lehetőséget.
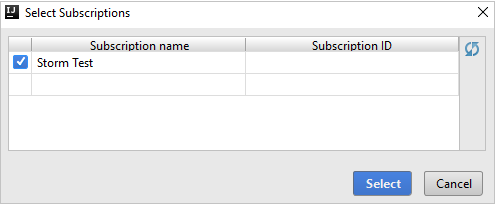
Az Azure Explorerben bontsa ki az Apache Sparkot a Synapse-on az előfizetéseiben lévő munkaterületek megtekintéséhez.
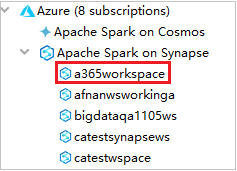
A Spark-készletek megtekintéséhez tovább bővítheti a munkaterületet.
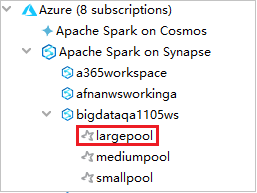
Spark Scala-alkalmazás távoli futtatása Spark-készleten
Scala-alkalmazás létrehozása után távolról futtathatja.
Nyissa meg a Futtatás/hibakeresés konfigurációk ablakot az ikon kiválasztásával.
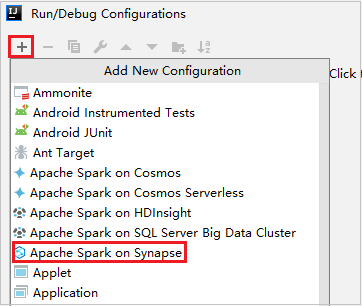
A Konfigurációk futtatása/hibakeresése párbeszédpanelen válassza az +Apache Sparkot a Synapse-on.
A Futtatási/hibakeresési konfigurációk ablakban adja meg a következő értékeket, majd kattintson az OK gombra:
Tulajdonság Érték Spark-készletek Válassza ki azokat a Spark-készleteket, amelyeken futtatni szeretné az alkalmazást. Elküldendő összetevő kiválasztása Hagyja meg az alapértelmezett beállítást. Főosztály neve Az alapértelmezett érték a kijelölt fájl főosztálya. Az osztályt a három pont (...) kiválasztásával és egy másik osztály kiválasztásával módosíthatja. Feladatkonfigurációk Módosíthatja az alapértelmezett kulcsot és értékeket. További információ: Apache Livy REST API. Parancssori argumentumok Szükség esetén a főosztályhoz szóközzel elválasztott argumentumokat is megadhat. Hivatkozott jarok és hivatkozott fájlok Ha vannak ilyenek, megadhatja a hivatkozott Jars és fájlok elérési útját. Az Azure-beli virtuális fájlrendszerben is tallózhat a fájlok között, amely jelenleg csak az ADLS Gen2-fürtöt támogatja. További információ: Apache Spark-konfiguráció és erőforrások feltöltése a fürtbe. Feladatfeltöltési tárterület Bontsa ki a további lehetőségek megjelenítéséhez. Tárhelytípusa Válassza az Azure Blob használata a feltöltéshez vagy a fürt alapértelmezett tárfiókjának használata a legördülő listából való feltöltéshez . Tárfiók Adja meg a tárfiókot. Tárkulcs Adja meg a tárkulcsot. Tároló tárolója A tárfiók és a tárkulcs megadása után válassza ki a tárolót a legördülő listából. 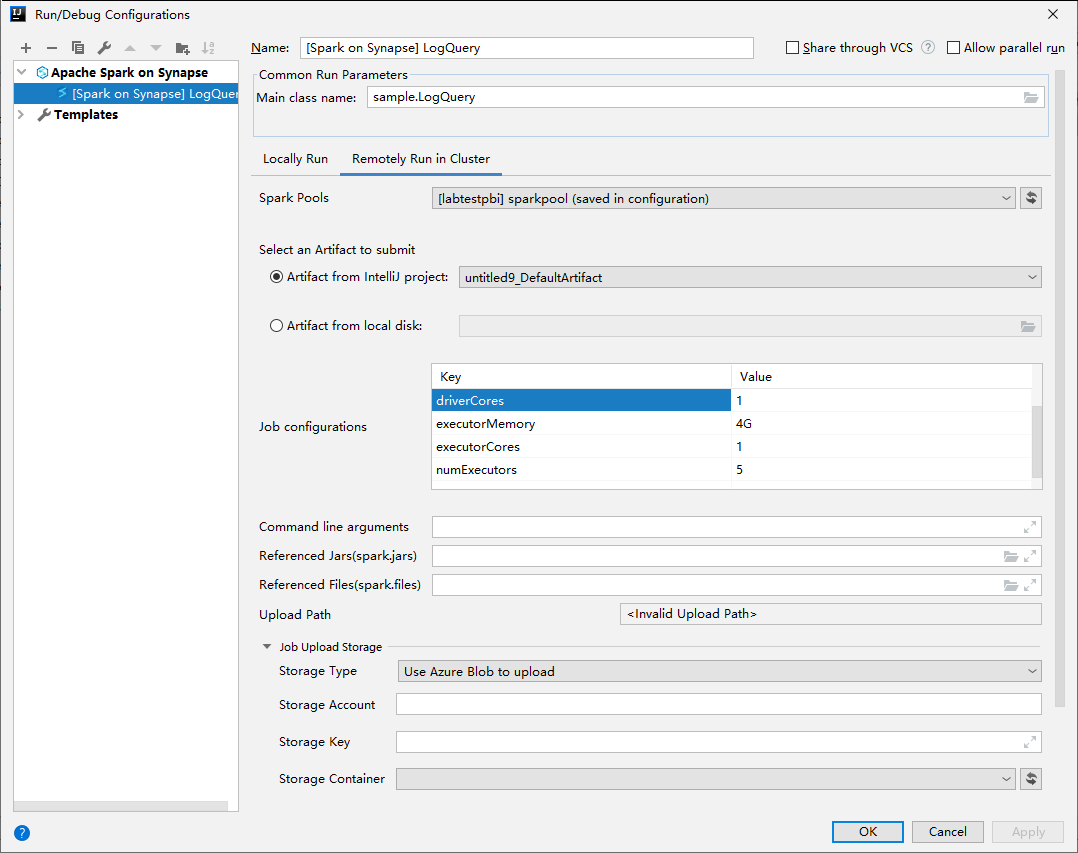
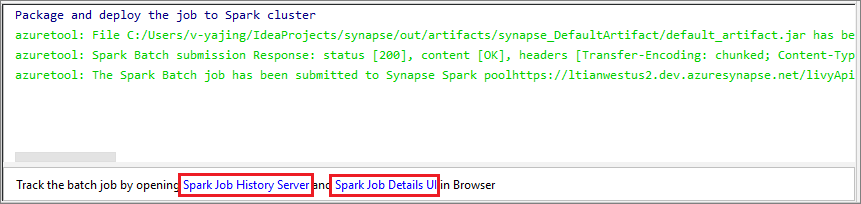
Válassza a SparkJobRun ikont a projekt kijelölt Spark-készletbe való elküldéséhez. A Fürt távoli Spark-feladata lap alján a feladat végrehajtásának előrehaladása látható. Az alkalmazást a piros gombra kattintva állíthatja le.

Apache Spark-alkalmazások helyi futtatása/hibakeresése
Az alábbi utasításokat követve beállíthatja a helyi futtatási és helyi hibakeresést az Apache Spark-feladathoz.
1. forgatókönyv: Helyi futtatás futtatása
Nyissa meg a Futtatás/hibakeresés konfigurációk párbeszédpanelt, és válassza a pluszjelet (+). Ezután válassza az Apache Spark on Synapse lehetőséget. Adja meg a menteni kívánt név, főosztálynév adatait.
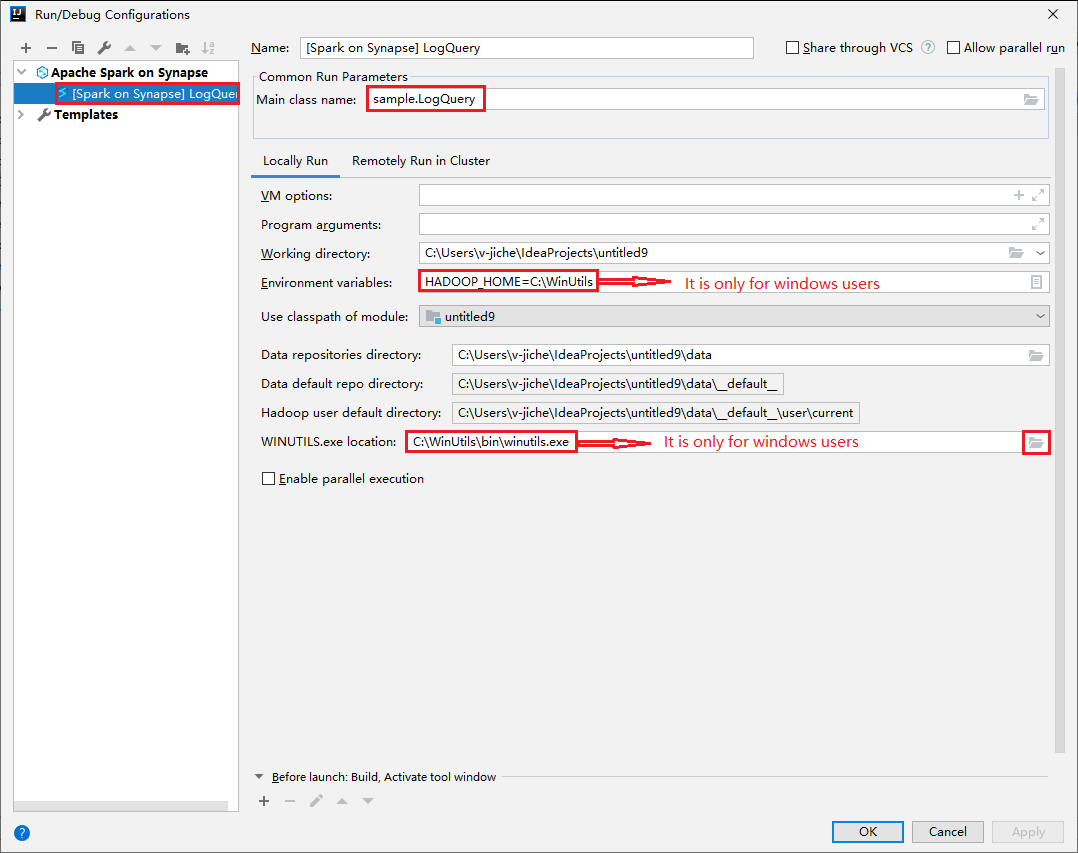
- A környezeti változók és a WinUtils.exe hely csak windowsos felhasználók számára érhetők el.
- Környezeti változók: A rendszer környezeti változója automatikusan észlelhető, ha korábban beállította, és nem kell manuálisan hozzáadnia.
- WinUtils.exe hely: A WinUtils helyét a jobb oldali mappaikon kiválasztásával adhatja meg.
Ezután válassza a helyi lejátszás gombot.

Ha a helyi futtatás befejeződött, ha a szkript kimenetet tartalmaz, ellenőrizheti a kimeneti fájlt az alapértelmezett adatokból>.
2. forgatókönyv: Helyi hibakeresés
Nyissa meg a LogQuery-szkriptet , és állítson be töréspontokat.
A helyi hibakereséshez válassza a Helyi hibakeresés ikont.

Synapse-munkaterület elérése és kezelése
Az Azure Explorerben különböző műveleteket hajthat végre az Azure Toolkit for IntelliJ-ben. A menüsávon navigáljon a Windows>Azure Explorer Nézet>eszközre.
A munkaterület elindítása
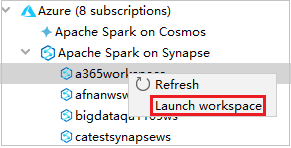
Az Azure Explorerben lépjen az Apache Sparkra a Synapse-en, majd bontsa ki.
Kattintson a jobb gombbal egy munkaterületre, majd válassza a Munkaterület indítása lehetőséget, és megnyílik a webhely.
Spark-konzol
Futtathatja a Spark helyi konzolját (Scala), vagy futtathatja a Spark Livy interaktív munkamenet-konzolt (Scala).
Spark helyi konzol (Scala)
Győződjön meg arról, hogy teljesítette a WINUTILS.EXE előfeltételét.
A menüsávon navigáljon a Konfigurációk szerkesztése parancsra...>
A Futtatási/hibakeresési konfigurációk ablakban, a bal oldali panelen keresse meg az Apache Sparkot a Synapse>[Spark on Synapse] myApp webhelyen.
A főablakban válassza a Helyi futtatás lapot.
Adja meg a következő értékeket, majd kattintson az OK gombra:
Tulajdonság Érték Környezeti változók Győződjön meg arról, hogy a HADOOP_HOME értéke helyes. WINUTILS.exe hely Győződjön meg arról, hogy az elérési út helyes. 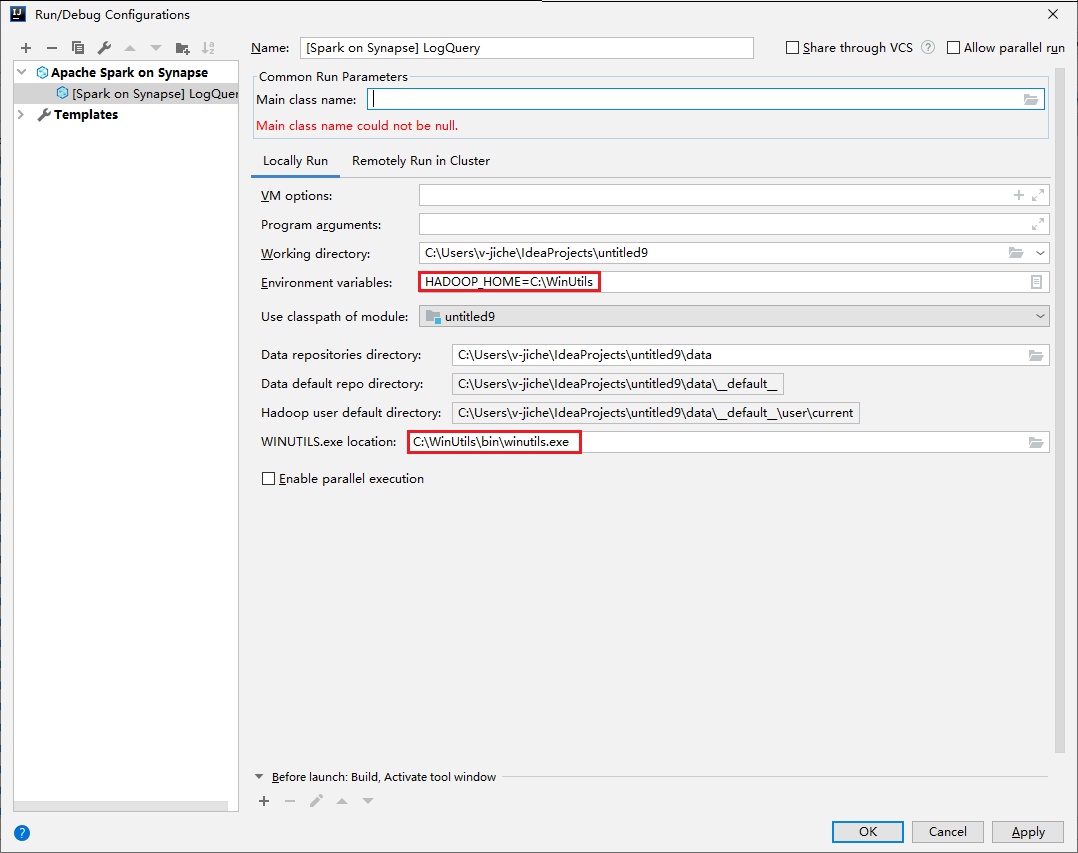
A Projectben keresse meg a myApp>src>fő>scala>myAppját.
A menüsávon keresse meg a Spark-konzolt futtató Spark-konzolt>>(Scala).
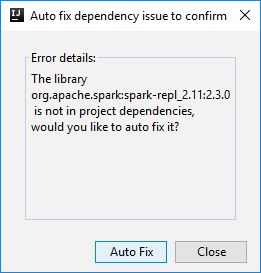
Ezután két párbeszédpanel jelenhet meg, hogy megkérdezze, szeretné-e automatikusan kijavítani a függőségeket. Ha igen, válassza az Automatikus javítás lehetőséget.
A konzolnak az alábbi képhez hasonlóan kell kinéznie. Írja be a konzolablak típusát
sc.appName, majd nyomja le a ctrl+Enter billentyűkombinációt. Az eredmény megjelenik. A helyi konzolt a piros gombra kattintva állíthatja le.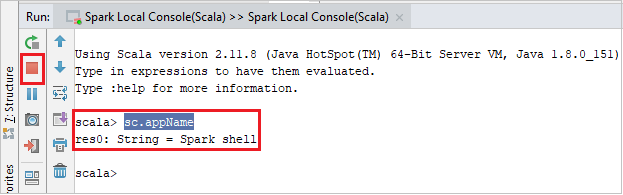
Spark Livy interaktív munkamenet-konzol (Scala)
Csak az IntelliJ 2018.2 és 2018.3 rendszeren támogatott.
A menüsávon navigáljon a Konfigurációk szerkesztése parancsra...>
A Futtatási/hibakeresési konfigurációk ablakban, a bal oldali panelen keresse meg az Apache Sparkot a synapse[Spark on synapse>] myApp webhelyen.
A főablakban válassza a Távoli futtatás a Fürt lapon lehetőséget.
Adja meg a következő értékeket, majd kattintson az OK gombra:
Tulajdonság Érték Főosztály neve Válassza ki a főosztály nevét. Spark-készletek Válassza ki azokat a Spark-készleteket, amelyeken futtatni szeretné az alkalmazást. 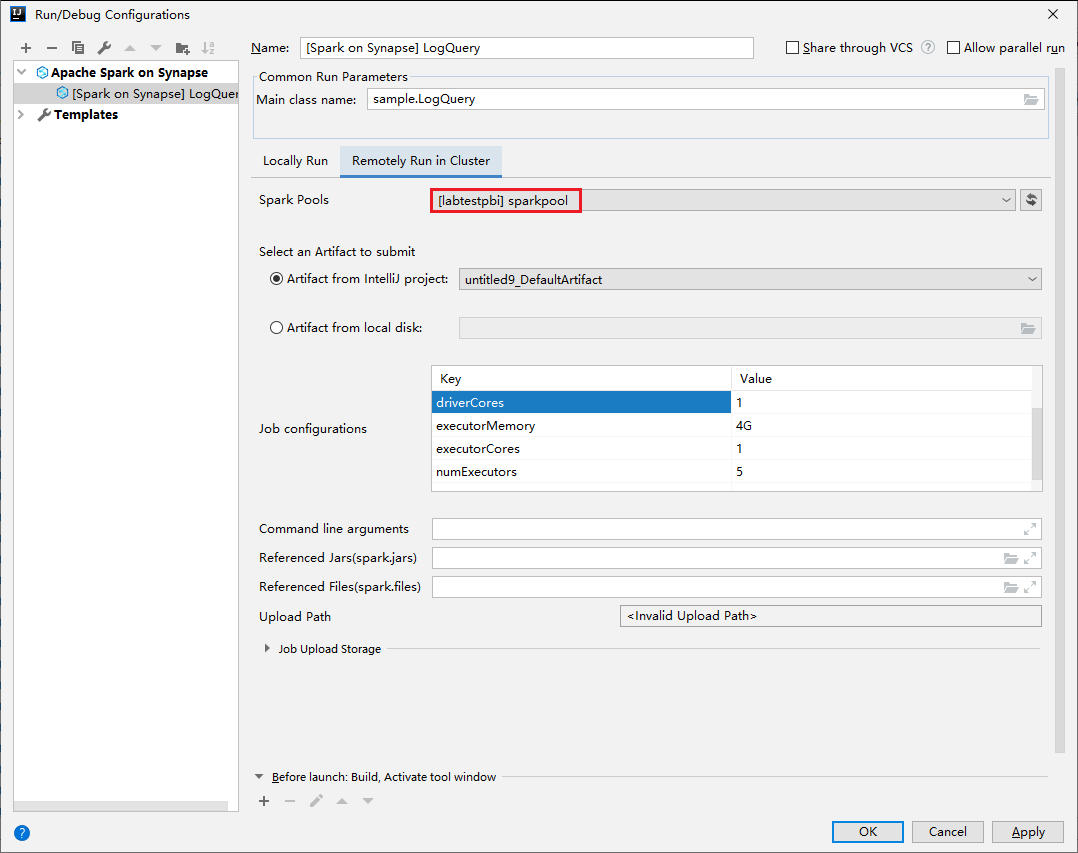
A Projectben keresse meg a myApp>src>fő>scala>myAppját.
A menüsávon navigáljon az Eszközök Spark-konzolra>>, amelyen a Spark Livy interaktív munkamenetkonzol (Scala) fut.
A konzolnak az alábbi képhez hasonlóan kell kinéznie. Írja be a konzolablak típusát
sc.appName, majd nyomja le a ctrl+Enter billentyűkombinációt. Az eredmény megjelenik. A helyi konzolt a piros gombra kattintva állíthatja le.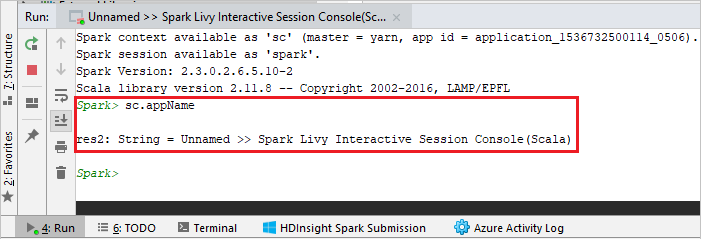
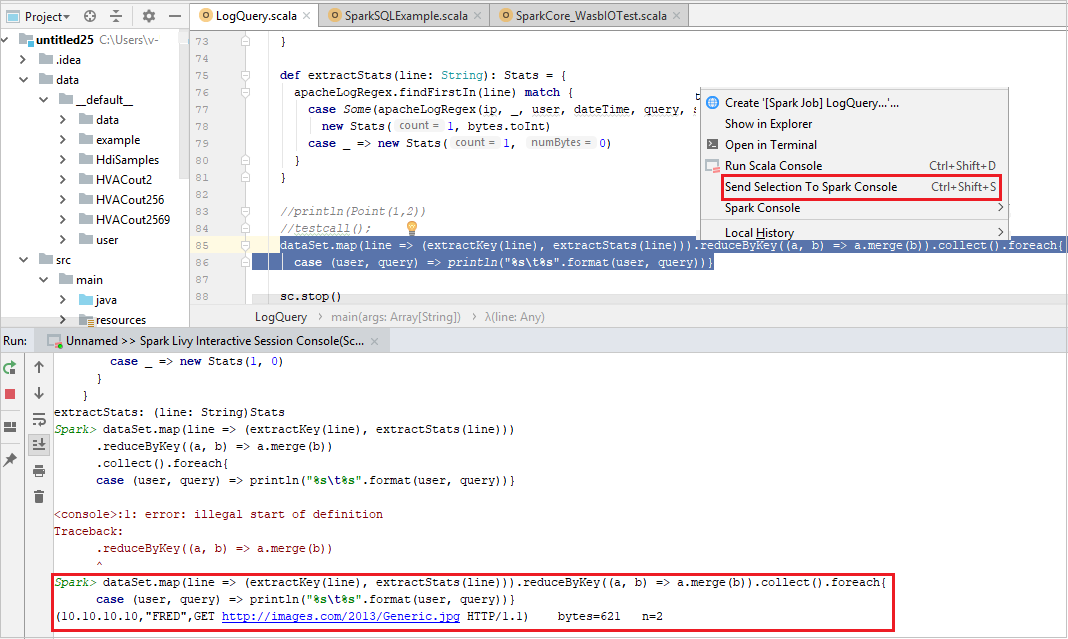
Kijelölés küldése a Spark-konzolra
Előfordulhat, hogy a szkript eredményét úgy szeretné megtekinteni, hogy elküld egy kódot a helyi konzolra vagy a Livy Interaktív munkamenet-konzolra (Scala). Ehhez kiemelhet néhány kódot a Scala-fájlban, majd kattintson a jobb gombbal a Kijelölés küldése a Spark-konzolra. A rendszer elküldi a kiválasztott kódot a konzolnak, és kész lesz. Az eredmény a kód után jelenik meg a konzolon. A konzol ellenőrzi a meglévő hibákat.