Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure Synapse Analytics különböző elemzési motorokat kínál az adatok betöltéséhez, átalakításához, modellezéséhez, elemzéséhez és kiszolgálásához. Az Apache Spark-készlet nyílt forráskódú big data számítási képességeket kínál. Miután létrehozott egy Apache Spark-készletet a Synapse-munkaterületen, az adatok betölthetők, modellezhetők, feldolgozhatók és kiszolgálhatók az elemzések lekéréséhez.
Ez a rövid útmutató az Apache Spark-készlet Synapse-munkaterületen a Synapse Studio használatával történő létrehozásának lépéseit ismerteti.
Fontos
A Spark-példányok számlázása percenként történik, függetlenül attól, hogy ön használja-e őket. Mindenképpen állítsa le a Spark-példányt a használat befejezése után, vagy állítson be egy rövid időtúllépést. További információkért lásd a cikk Az erőforrások eltávolítása című szakaszát.
Feljegyzés/Jegyzet
A Synapse Studio továbbra is támogatja a terraform- vagy bicepszalapú konfigurációs fájlokat.
Ha még nincs Azure-előfizetése, kezdés előtt hozzon létre egy ingyenes fiókot.
Előfeltételek
- Szüksége lesz Azure-előfizetésre. Szükség esetén hozzon létre egy ingyenes Azure-fiókot
- A Synapse-munkaterületet fogja használni.
Jelentkezzen be az Azure Portalra
Jelentkezzen be az Azure Portalra
Ugrás a Synapse-munkaterületre
Lépjen arra a Synapse-munkaterületre, ahol az Apache Spark-készlet létrejön, ha beírja a szolgáltatás nevét (vagy közvetlenül az erőforrás nevét) a keresősávba.
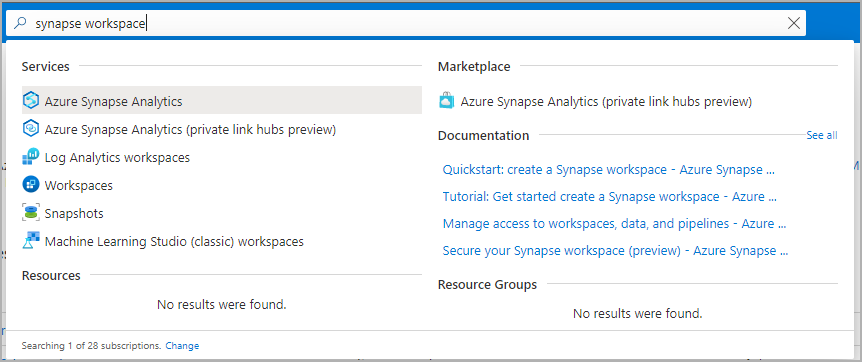
A munkaterületek listájából írja be a megnyitni kívánt munkaterület nevét (vagy a név egy részét). Ebben a példában egy contosoanalytics nevű munkaterületet használunk.
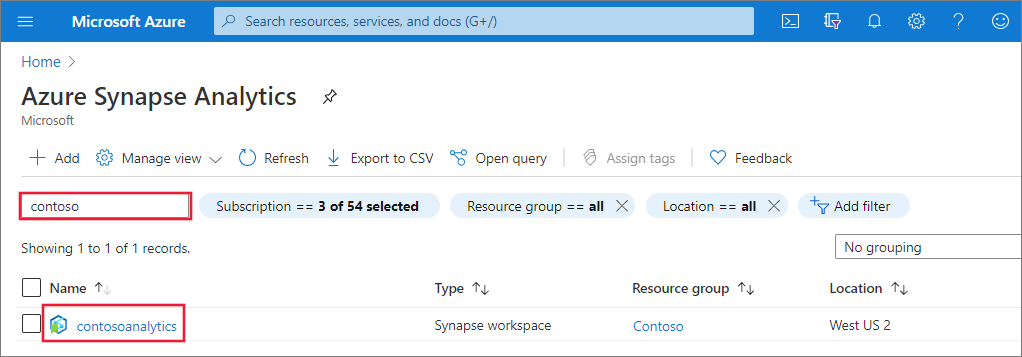


A Synapse Studio indítása
A munkaterület áttekintésében válassza ki a Munkaterület webes URL-címét a Synapse Studio megnyitásához.

Az Apache Spark-készlet létrehozása a Synapse Studióban
Fontos
Az Apache Spark 2.4-hez készült Azure Synapse Runtime 2023 szeptembere óta elavult, és hivatalosan nem támogatott. Mivel a Spark 3.1 és a Spark 3.2 is támogatás megszűnik, javasoljuk, hogy az ügyfelek migráljanak a Spark 3.3-ra.
A Synapse Studio kezdőlapján a Bal oldali navigációs sávOn keresse meg a Felügyeleti központot a Kezelés ikonra kattintva.
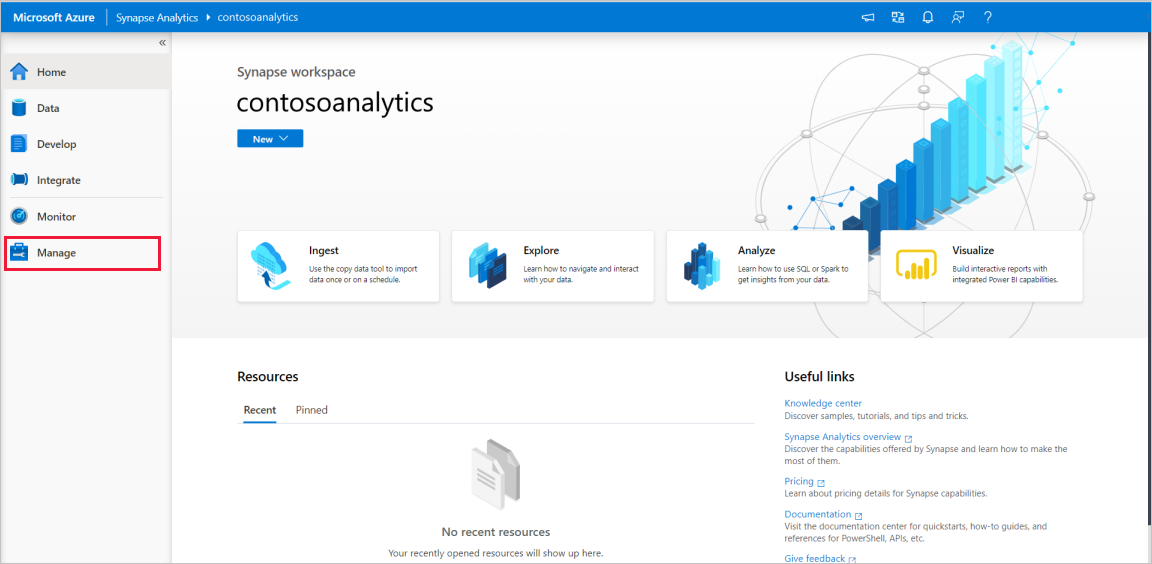
A Felügyeleti központban lépjen az Apache Spark-készletek szakaszra a munkaterületen elérhető Apache Spark-készletek aktuális listájának megtekintéséhez.
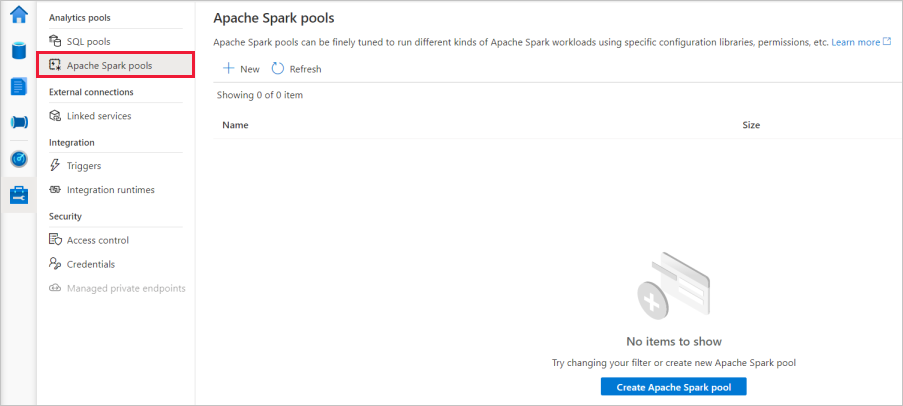
Válassza az + Új lehetőséget, és megjelenik az új Apache Spark-készlet létrehozó varázsló.
Adja meg a következő adatokat az Alapismeretek lapon:
Beállítás Ajánlott érték Leírás Apache Spark-készlet neve Érvényes készletnév, például contososparkEz lesz az Apache Spark pool neve. Csomópont mérete Kicsi (4 vCPU / 32 GB) Állítsa ezt a legkisebb méretre a gyorsindítás költségeinek csökkentése érdekében. Automatikus méretezés Letiltva Ebben a rövid útmutatóban nem lesz szükség automatikus skálázásra Csomópontok száma 8 A költségek korlátozásához használjon kis méretet ebben a gyorsindításban Végrehajtók dinamikus kiosztása Letiltva Ez a beállítás a Spark-alkalmazás-végrehajtók lefoglalásának Spark-konfigurációban lévő dinamikus foglalási tulajdonságához lesz megfeleltetve. Ebben a rövid útmutatóban nem lesz szükség automatikus skálázásra. 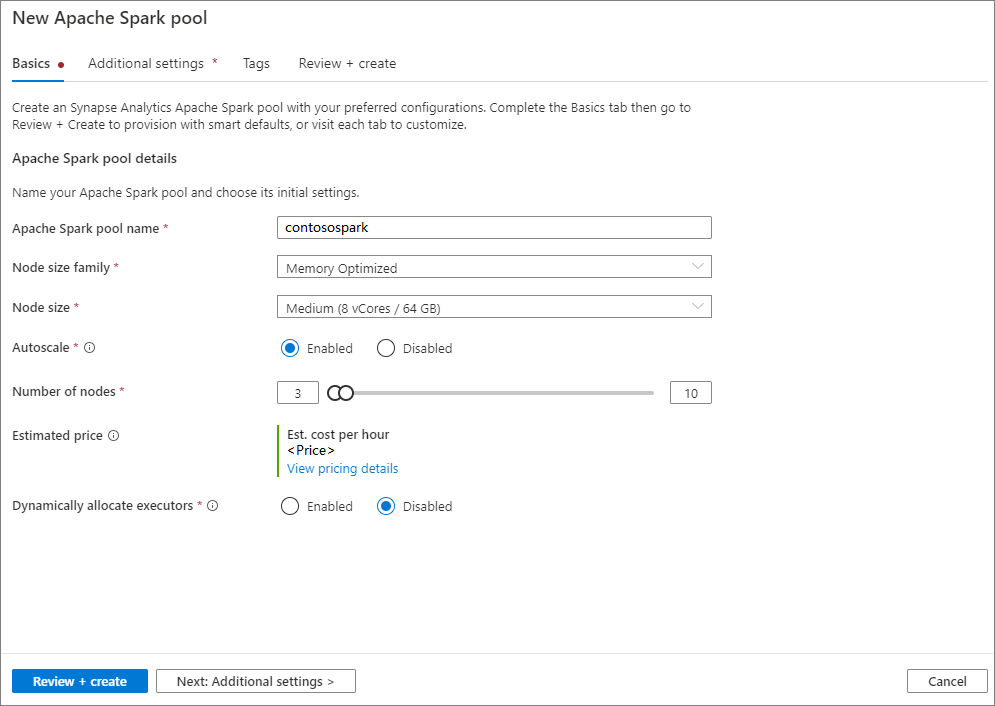
Fontos
Az Apache Spark-készletek által használható nevekre meghatározott korlátozások vonatkoznak. A neveknek csak betűket vagy számokat kell tartalmazniuk, 15 vagy annál kevesebb karakternek kell lenniük, betűvel kell kezdődniük, nem tartalmazhatnak fenntartott szavakat, és egyedinek kell lenniük a munkaterületen.
A következő lapon a További beállítások területen hagyja meg az összes beállítást alapértelmezettként.
Válassza a Címkék lehetőséget. Fontolja meg az Azure-címkék használatát. A "Tulajdonos" vagy a "CreatedBy" címke például azonosítja, hogy ki hozta létre az erőforrást, és a "Környezet" címkével azonosíthatja, hogy ez az erőforrás éles környezetben, fejlesztésben stb. található-e. További információ: Az Azure-erőforrások elnevezési és címkézési stratégiájának fejlesztése. Ha elkészült, válassza a Véleményezés + létrehozás lehetőséget.
A Véleményezés + létrehozás lapon győződjön meg arról, hogy a korábban megadott adatok helyesen jelennek meg, majd nyomja le a Létrehozás billentyűt.
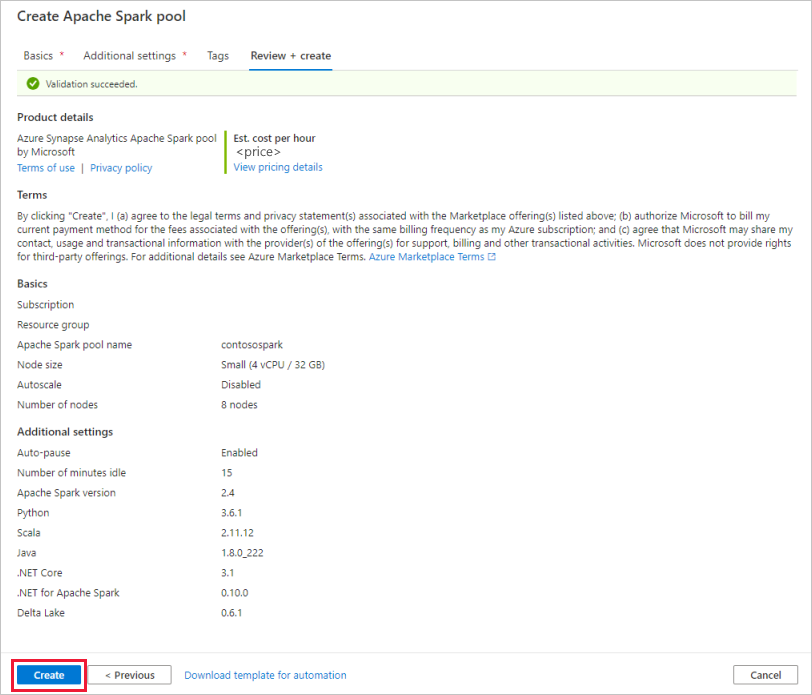
Az Apache Spark-készlet elindítja a kiépítési folyamatot.
A kiépítés befejezése után az új Apache Spark-készlet megjelenik a listában.
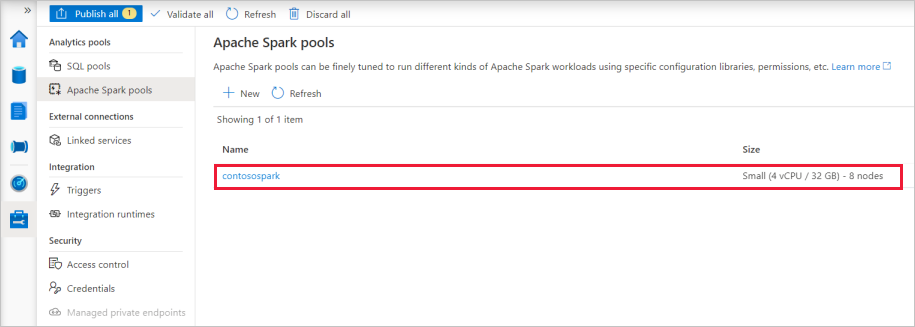





Apache Spark-készlet erőforrásainak törlése a Synapse Studióval
Az alábbi lépések törlik az Apache Spark-készletet a munkaterületről a Synapse Studióval.
Figyelmeztetés
A Spark-készlet törlése eltávolítja az elemzési motort a munkaterületről. A továbbiakban nem lehet csatlakozni a készlethez, és a Spark-készletet használó összes lekérdezés, folyamat és jegyzetfüzet nem fog működni.
Ha törölni szeretné az Apache Spark-készletet, hajtsa végre a következő lépéseket:
Lépjen az Apache Spark-készletek irányítópultjára a Synapse Studióban található irányítópultban.
Válassza ki a törölni kívánt Apache-készlet melletti három pontot (ebben az esetben a contososparkot) az Apache Spark-készlet parancsainak megjelenítéséhez.
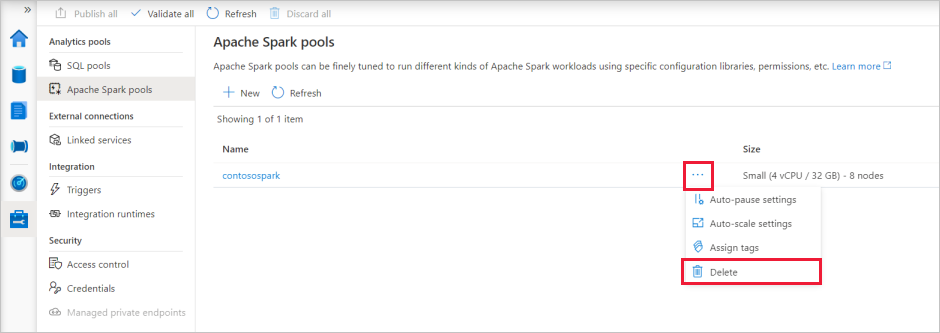
Válassza a Törlés lehetőséget.
Erősítse meg a törlést, és nyomja le a Delete gombot.
Ha a folyamat sikeresen befejeződött, az Apache Spark-készlet már nem fog szerepelni a munkaterület erőforrásai között.
