Dedikált SQL-készlet (korábban SQL DW) architektúra az Azure Synapse Analyticsben
Az Azure Synapse Analytics egy olyan elemzési szolgáltatás, amely egyesíti a nagyvállalati adattárházakat és a Big Data-elemzéseket. Lehetővé teszi az adatok lekérdezését a feltételek alapján.
Megjegyzés:
Az Azure Synapse Analyticsről további információt az adatáthelyezési fejlesztésekről szóló videóban tekintheti meg.
Synapse SQL-architektúra összetevői
A dedikált SQL-készlet (korábbi nevén SQL DW) egy kibővített architektúrát használ az adatok számítási feldolgozásának több csomópont közötti elosztásához. A skálázási egység a számítási teljesítmény absztrakciója, amelyet adattárházegységnek nevezünk. A számítás elkülönül a tárolástól, ezáltal a számítások a rendszerben az adatoktól függetlenül skálázhatók.
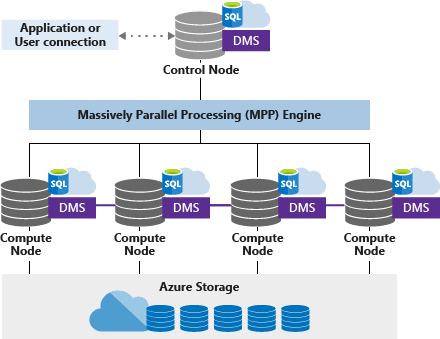
A dedikált SQL-készlet (korábbi nevén SQL DW) csomópontalapú architektúrát használ. Az alkalmazások T-SQL-parancsokat csatlakoztatnak és adnak ki egy vezérlőcsomóponthoz. A Vezérlő csomópont üzemelteti az elosztott lekérdezési motort, amely optimalizálja a lekérdezéseket a párhuzamos feldolgozáshoz, majd továbbítja a műveleteket a számítási csomópontoknak, hogy párhuzamosan végezhessék a munkájukat.
A számítási csomópontok az összes felhasználói adatot az Microsoft Azure Storage-ban tárolják, és futtatják a párhuzamos lekérdezéseket. Az adatáthelyezési szolgáltatás (DMS) egy rendszerszintű belső szolgáltatás, amely szükség szerint áthelyezi az adatokat a csomópontok között a lekérdezések párhuzamos futtatásához és pontos eredmények visszaadásához.
A leválasztott tárolás és számítás esetén dedikált SQL-készlet (korábbi nevén SQL DW) használata esetén a következőt teheti:
- Függetlenül méretezheti a számítási teljesítményt a tárolási igényektől függetlenül.
- Számítási teljesítmény növelése vagy zsugorítása dedikált SQL-készletben (korábban SQL DW) adatok áthelyezése nélkül.
- Szüneteltetheti a számítási kapacitást az adatok megőrzésével, hogy csak a tárterületért kelljen fizetnie.
- Működési időben újra aktiválhatja a számítási kapacitást.
Azure Storage
A dedikált SQL-készlet SQL (korábbi nevén SQL DW) az Azure Storage használatával tartja biztonságban a felhasználói adatokat. Mivel az adatokat az Azure Storage tárolja és kezeli, a tárterület-használatért külön díjat kell fizetnie. Az adatok eloszlásokra van osztva a rendszer teljesítményének optimalizálása érdekében. Hogy melyik horizontális skálázási mintát szeretné használni az adatok elosztásához, azt a tábla definiálásakor döntheti el. Ezek a horizontális skálázási minták támogatottak:
- Kivonat
- Ciklikus időszeletelés
- Replikálás
Vezérlő csomópont
A vezérlő csomópont az architektúra agya. Ez az az előtérbeli rendszer, amely az összes alkalmazással és kapcsolattal együttműködik. Az elosztott lekérdezési motor a Vezérlő csomóponton fut a párhuzamos lekérdezések optimalizálásához és koordinálásához. T-SQL-lekérdezés elküldésekor a Vezérlő csomópont az egyes disztribúciókon párhuzamosan futó lekérdezésekké alakítja át.
Számítási csomópontok
A számítási csomópontok biztosítják a számítási teljesítményt. A disztribúciók leképezése számítási csomópontokra feldolgozás céljából. A további számítási erőforrásokért való fizetéskor a disztribúciók az elérhető számítási csomópontokra lesznek leképezve. A számítási csomópontok száma 1 és 60 között mozog, és a Synapse SQL szolgáltatásszintje határozza meg.
Minden számítási csomópont rendelkezik egy csomópontazonosítóval, amely látható a rendszernézetekben. A számítási csomópont azonosítóját úgy tekintheti meg, hogy megkeresi a node_id oszlopot olyan rendszernézetekben, amelyeknek a neve sys.pdw_nodes kezdődik. A rendszernézetek listáját a Synapse SQL-rendszernézetekben találja.
Adatáthelyezési szolgáltatás (Data Movement Service, DMS)
Az adatáthelyezési szolgáltatás (DMS) a számítási csomópontok közötti adatáthelyezést koordináló adatátviteli technológia. Egyes lekérdezések adatáthelyezést igényelnek, hogy a párhuzamos lekérdezések pontos eredményeket adjanak vissza. Ha adatáthelyezésre van szükség, a DMS biztosítja, hogy a megfelelő adatok a megfelelő helyre kerülnek.
Disztribúciók
Az elosztás a tárolás és az elosztott adatokon futtatott párhuzamos lekérdezések feldolgozásának alapegysége. Amikor a Synapse SQL futtat egy lekérdezést, a munka 60 kisebb, párhuzamosan futó lekérdezésre oszlik.
A 60 kisebb lekérdezés mindegyike az egyik adateloszláson fut. Minden számítási csomópont egy vagy több 60 disztribúciót kezel. Egy dedikált SQL-készlet (korábbi nevén SQL DW) számítási erőforrások maximális száma számítási csomópontonként egy disztribúcióval rendelkezik. Egy dedikált SQL-készlet (korábbi nevén SQL DW) minimális számítási erőforrásokkal rendelkezik az összes disztribúcióval egy számítási csomóponton.
Megjegyzés:
A számítási feladatok alapján használható legjobb táblázatterjesztési stratégiával kapcsolatos javaslatokért tekintse meg az Azure Synapse SQL Distribution Advisort.
Kivonat alapján elosztott táblák
A kivonat alapján elosztott tábla nyújtja a legnagyobb lekérdezési teljesítményt az összekapcsolásoknál és aggregációknál nagy táblák esetén.
Az adatok kivonatelosztott táblába való felosztásához a kivonatfüggvények segítségével determinisztikus módon rendelhetők hozzá az egyes sorok egy eloszláshoz. A tábla definíciójában az oszlopok egyike elosztási oszlopként van megjelölve. A kivonatolási függvény az elosztási oszlop értékeit használja az egyes sorok elosztáshoz rendeléséhez.
Az alábbi ábra bemutatja, hogy a teljes (nem elosztott) táblák hogyan lesznek kivonatelosztott táblaként tárolva.

- Minden sor egy eloszláshoz tartozik.
- A determinisztikus kivonatoló algoritmus minden sort egy eloszláshoz rendel.
- A táblázatsorok eloszlásonkénti száma a táblák különböző méretétől függően változik.
A terjesztési oszlop kiválasztásának teljesítménybeli szempontjai vannak, például a különbözőség, az adateltérés és a rendszeren futó lekérdezések típusai.
Ciklikus időszeleteléssel elosztott táblák
A ciklikus időszeleteléses táblázat a legegyszerűbb tábla, amely gyors teljesítményt nyújt, ha előkészítési táblázatként használják a terhelésekhez.
Ciklikus időszeleteléses elosztott tábla egyenletesen osztja el az adatokat a táblázatban, de minden további optimalizálás nélkül. A rendszer először véletlenszerűen választ ki egy eloszlást, majd a sorok puffereit egymás után rendeli hozzá a disztribúciókhoz. Az adatok a ciklikus időszeleteléses táblába gyorsan betölthetők, de a lekérdezési teljesítmény gyakran jobb a kivonatelosztott táblák esetében. A ciklikus időszeleteléses táblákhoz való csatlakozáshoz újra kell írni az adatokat, ami további időt vesz igénybe.
Replikált táblák
A kisméretű tábláknál a replikált táblák nyújtják a leggyorsabb lekérdezési teljesítményt.
A replikált tábla minden számítási csomóponton gyorsítótárazza a tábla teljes másolatát. Ebből következően a replikál tábla esetében nincs szükség adatadásra a számítási csomópontok között az összekapcsolási vagy aggregációs művelet előtt. A replikált táblákat legjobban kisméretű táblákkal lehet kihasználni. Extra tárhelyre van szükség, és további többletterhelések merülnek fel az adatok írásakor, ami a nagy táblákat nem praktikussá teszi.
Az alábbi ábrán egy replikált tábla látható, amely az egyes számítási csomópontok első eloszlásán gyorsítótárazott.

További lépések
Most, hogy egy kicsit megismerkedett az Azure Synapse-rel, megtudhatja, hogyan hozhat létre gyorsan dedikált SQL-készletet (korábbi nevén SQL DW-t), és tölthet be mintaadatokat. Ha az Azure új felhasználója, hasznosnak találhatja az Azure szószedetét, amikor az új fogalmakkal ismerkedik. Vagy tekintse meg ezeket a többi Azure Synapse-erőforrást.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: