Adatok elemzése Azure Machine Learning segítségével
Ez az oktatóanyag az Azure Machine Learning Designer használatával hoz létre egy prediktív gépi tanulási modellt. A modell a Azure Synapse tárolt adatokon alapul. Az oktatóanyag forgatókönyve annak előrejelzése, hogy az ügyfél valószínűleg kerékpárt vásárol-e, vagy sem, így az Adventure Works, a kerékpárbolt célzott marketingkampányt hozhat létre.
Előfeltételek
Az oktatóanyag teljesítéséhez a következőkre lesz szüksége:
- az AdventureWorksDW mintaadatokkal előre betöltött SQL-készlet. Az SQL-készlet kiépítéséhez lásd: SQL-készlet létrehozása és a mintaadatok betöltésének kiválasztása. Ha már rendelkezik adattárházzal, de nem rendelkezik mintaadatokkal, manuálisan is betöltheti a mintaadatokat.
- Egy Azure Machine Learning-munkaterület. Ezt az oktatóanyagot követve hozzon létre egy újat.
Az adatok lekérése
A használt adatok az AdventureWorksDW dbo.vTargetMail nézetében láthatók. A Datastore használatához ebben az oktatóanyagban az adatok először Azure Data Lake Storage fiókba lesznek exportálva, mivel Azure Synapse jelenleg nem támogatják az adatkészleteket. Azure Data Factory adatok exportálására használható az adattárházból a másolási tevékenységgel Azure Data Lake Storage. Az importáláshoz használja a következő lekérdezést:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Miután az adatok elérhetővé válnak Azure Data Lake Storage, az Azure Machine Learning adattárai az Azure Storage-szolgáltatásokhoz való csatlakozásra szolgálnak. Az alábbi lépéseket követve hozzon létre egy adattárat és egy megfelelő adatkészletet:
Indítsa el Azure Machine Learning stúdió Azure Portal vagy jelentkezzen be a Azure Machine Learning stúdió.
Kattintson a Bal oldali panelEn az Adattárak elemre a Kezelés szakaszban, majd kattintson az Új adattár elemre.
Adja meg az adattár nevét, válassza ki a típust "Azure Blob Storage", adja meg a helyet és a hitelesítő adatokat. Ezután kattintson a Létrehozás gombra.
Ezután kattintson a bal oldali panel Adathalmazok elemére az Eszközök szakaszban. Válassza az Adathalmaz létrehozása lehetőséget az Adattárból lehetőséggel.
Adja meg az adathalmaz nevét, és válassza ki a táblázatos típust. Ezután kattintson a Tovább gombra a továbblépéshez.
Az Adattár kiválasztása vagy létrehozása szakaszban válassza a Korábban létrehozott adattár lehetőséget. Válassza ki a korábban létrehozott adattárat. Kattintson a Tovább gombra, és adja meg az elérési utat és a fájlbeállításokat. Ügyeljen arra, hogy oszlopfejlécet adjon meg, ha a fájlok tartalmaznak egyet.
Végül kattintson a Létrehozás gombra az adathalmaz létrehozásához.
Tervezői kísérlet konfigurálása
Ezután kövesse az alábbi lépéseket a tervezők konfigurálásának érdekében:
Kattintson Tervező fülre a bal oldali panel Szerző szakaszában.
Új folyamat létrehozásához válassza az Könnyen használható előre összeállított összetevők lehetőséget.
A jobb oldali beállítások panelen adja meg a folyamat nevét.
Emellett válasszon ki egy cél számítási fürtöt a teljes kísérlethez a Beállítások gombra kattintva egy korábban kiépített fürtre. Zárja be a Beállítások panelt.
Adatok importálása
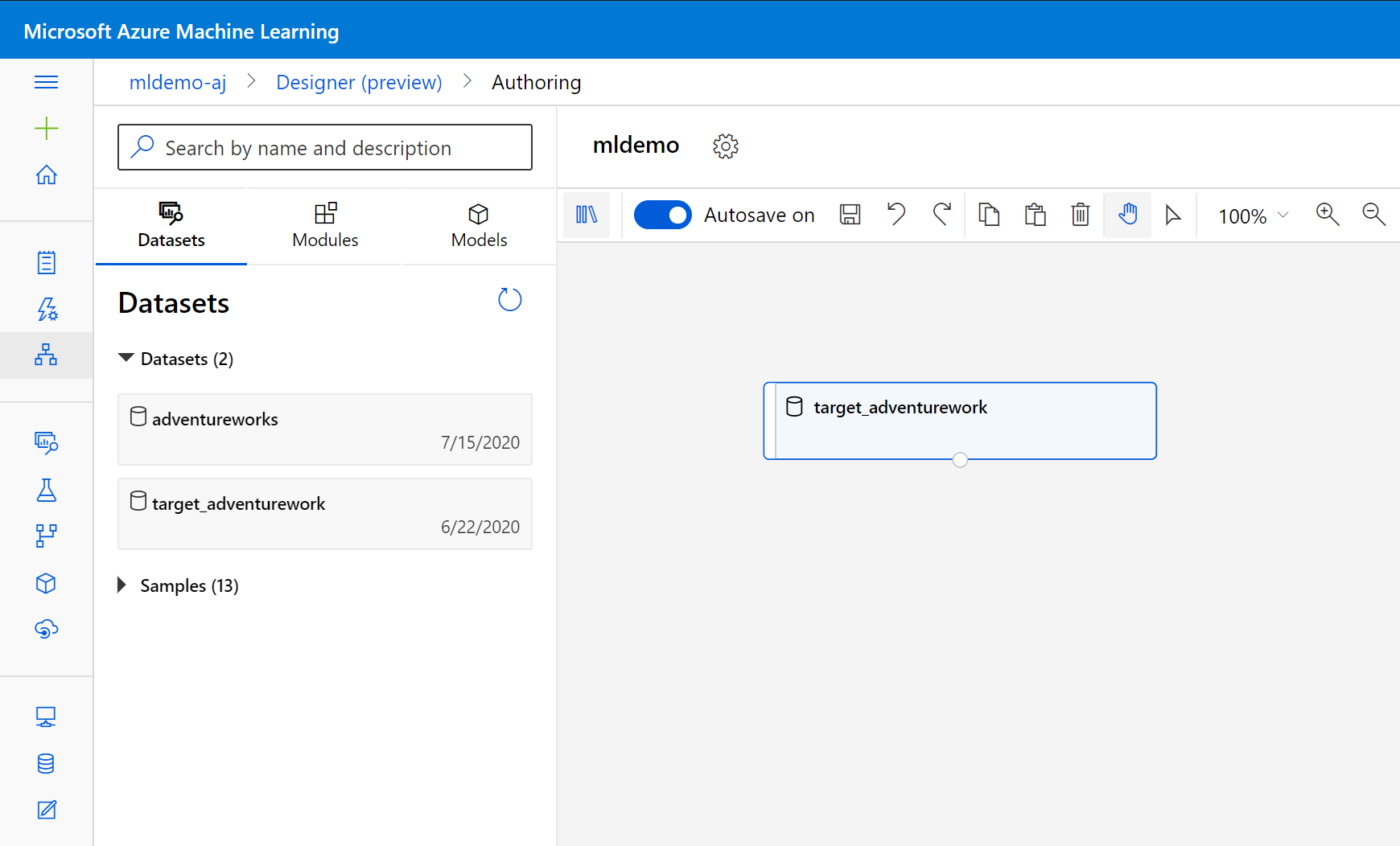
Válassza ki az Adathalmazok altáblát a keresőmező alatti bal oldali panelen.
Húzza a korábban létrehozott adathalmazt a vászonra.
Az adatok megtisztítása
Az adatok tisztításához olyan oszlopokat helyezzen el, amelyek nem relevánsak a modell szempontjából. Kövesse az alábbi lépéseket:
Válassza ki az Összetevők altáblát a bal oldali panelen.
Húzza a vászonra az Adathalmaz oszlopainak kijelölése összetevőt az Adatátalakítási < manipuláció területen. Csatlakoztassa ezt az összetevőt az Adathalmaz összetevőhöz.
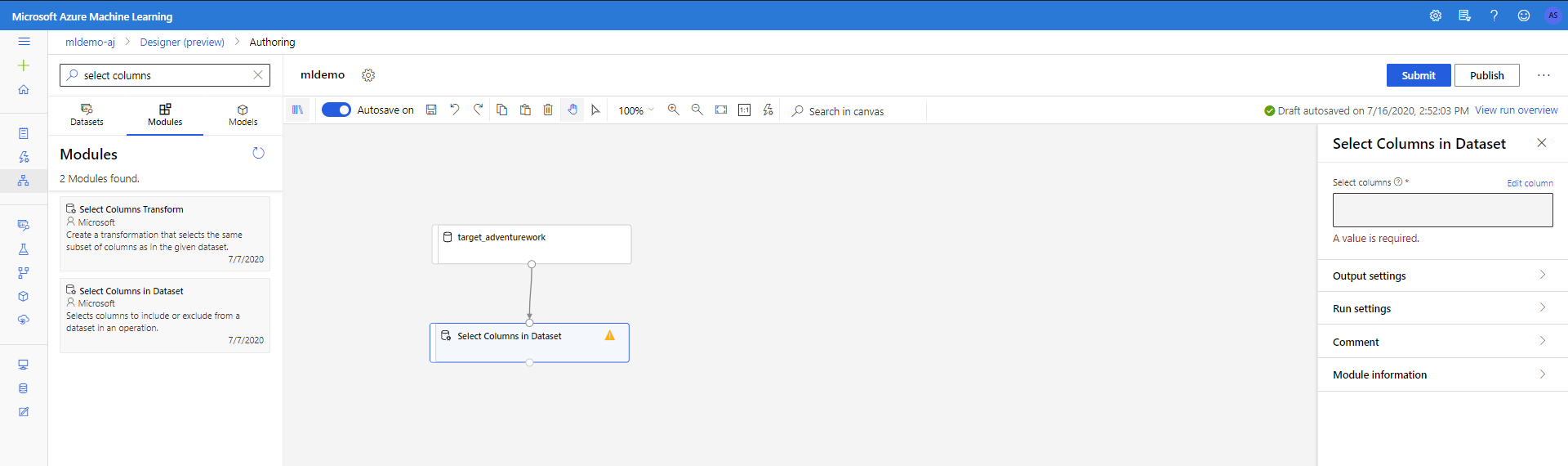
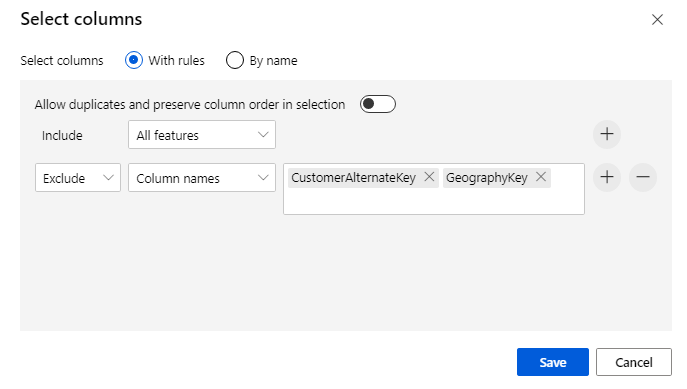
Kattintson az összetevőre a Tulajdonságok panel megnyitásához. Kattintson az Oszlop szerkesztése elemre az elvetni kívánt oszlopok megadásához.
Két oszlop kizárása: CustomerAlternateKey és GeographyKey. Kattintson a Mentés gombra.

A modell létrehozása
Az adatok felosztása 80–20: 80% egy gépi tanulási modell betanításához, 20% a modell teszteléséhez. Ebben a bináris besorolási problémában "kétosztályos" algoritmusokat használunk.
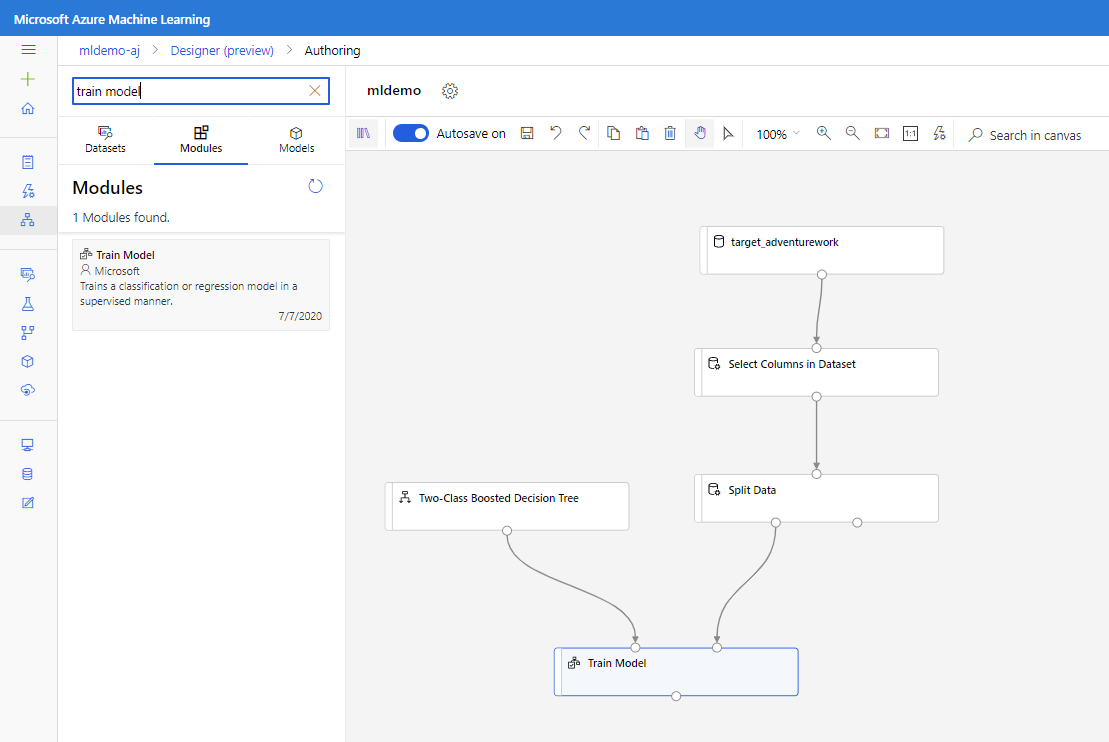
Húzza az Adatok felosztása összetevőt a vászonra.
A tulajdonságok panelen adja meg a 0,8 értéket az első kimeneti adathalmaz sorainak törtrésze mezőben.
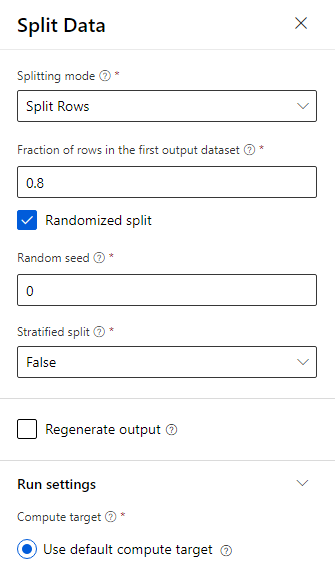
Húzza a kétosztályos kiemelt döntési fa összetevőt a vászonra.
Húzza a Modell betanítása összetevőt a vászonra. Adja meg a bemeneteket a kétosztályos kiemelt döntési fához (ML-algoritmus ) és az Adatok felosztása (az algoritmus betanításához szükséges adatok) összetevőkhöz való csatlakoztatásával.
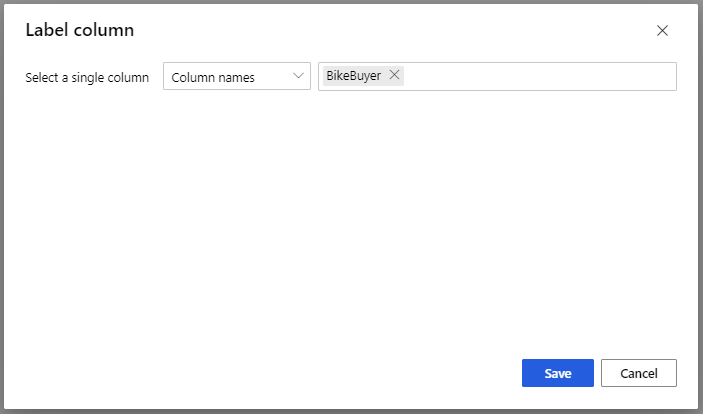
A Modell betanítása modell esetében a Tulajdonságok panel Címke oszlop lehetőségében válassza az Oszlop szerkesztése lehetőséget. Válassza ki a BikeBuyer oszlopot az előrejelzéshez, majd válassza a Mentés lehetőséget.
A modell pontozása
Most tesztelje, hogyan teljesít a modell a tesztadatokon. A rendszer két különböző algoritmust hasonlít össze annak megtekintéséhez, hogy melyik teljesít jobban. Kövesse az alábbi lépéseket:
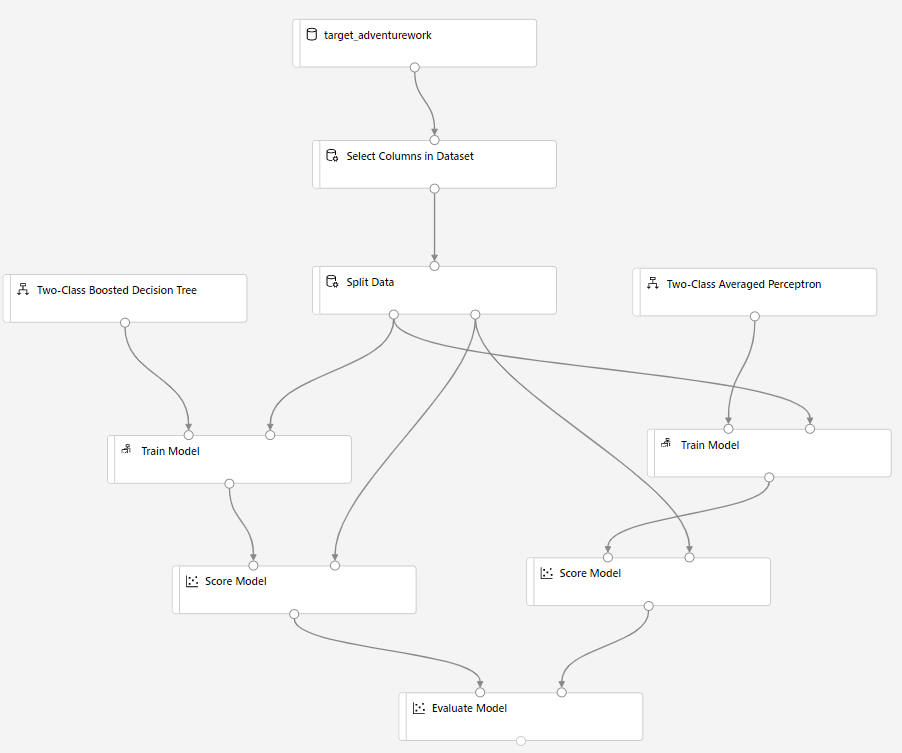
Húzza a Score Model összetevőt a vászonra, és csatlakoztassa a Modell betanítása és az Adatok felosztása összetevőkhöz.
Húzza a kétosztályos Bayes Averaged Perceptront a kísérletvászonra. Összehasonlíthatja, hogy ez az algoritmus hogyan teljesít a Two-Class Tolható döntési fával összehasonlítva.
Másolja és illessze be a modell betanítása és a modell pontozása összetevőket a vásznon.
Húzza a Modell kiértékelése összetevőt a vászonra a két algoritmus összehasonlításához.
Kattintson a Küldés gombra a folyamatfuttatás beállításához.
A futtatás befejezése után kattintson a jobb gombbal a Modell kiértékelése összetevőre, és válassza a Kiértékelési eredmények megjelenítése parancsot.
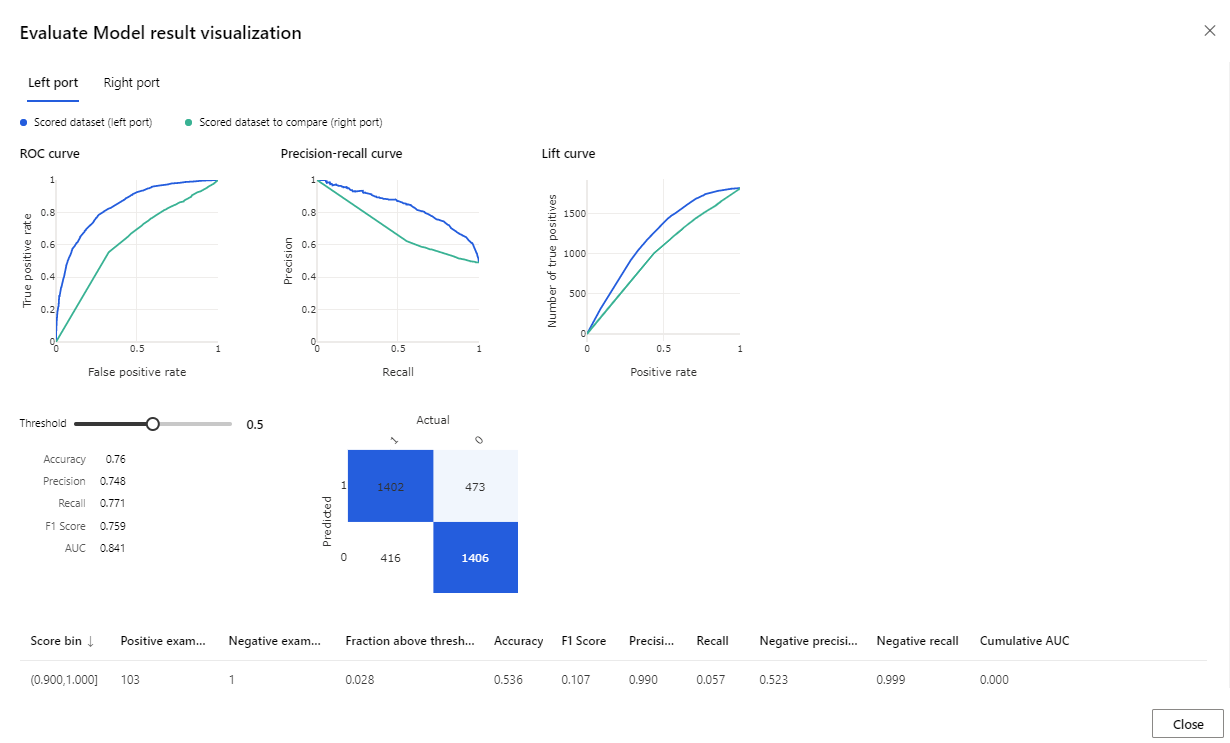

A megadott metrikák a ROC-görbe, a pontossági visszahívási diagram és az emelési görbe. Tekintse meg ezeket a metrikákat, és ellenőrizze, hogy az első modell jobban teljesített-e, mint a második. Az első modell előrejelzésének megtekintéséhez kattintson a jobb gombbal a Modell pontozása összetevőre, majd kattintson a Pontozott adatkészlet megjelenítése elemre az előrejelzett eredmények megtekintéséhez.
Két további oszlopot fog látni a tesztadatkészlethez.
- Pontozott valószínűség: annak valószínűsége, hogy az ügyfél kerékpárvásárló.
- Pontozott címkék: a modell által elvégzett osztályozás – kerékpárvásárló (1) vagy sem (0). A címkézés valószínűségi küszöbértéke 50 százalékra van beállítva és módosítható.
Hasonlítsa össze a BikeBuyer (tényleges) oszlopot a pontozott címkékkel (előrejelzés), hogy lássa, mennyire teljesített a modell. Ezután ezzel a modellel előrejelzéseket készíthet az új ügyfelek számára. Ezt a modellt közzéteheti webszolgáltatásként, vagy visszaírhatja az eredményeket Azure Synapse.
Következő lépések
További információ az Azure Machine Learningről: Bevezetés az Azure-beli gépi tanulásba.
Itt megismerheti az adattárház beépített pontozását.