Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tip
Microsoft Fabric Data Warehouse egy nagyvállalati szintű relációs raktár egy Data Lake-alaprendszeren, jövőre kész architektúrával, beépített AI-vel és új funkciókkal. Ha még nem ismerkedik adattárházzal, kezdje a Fabric Data Warehouse. A meglévő dedikált SQL-készlet számítási feladatai frissíthetők Fabric az adatelemzés, a valós idejű elemzés és a jelentéskészítés új képességeinek eléréséhez.
Egy külső tábla a Hadoopban, az Azure Storage-blobban vagy az Azure Data Lake Storage-ban (ADLS) található adatokra mutat.
Külső táblák használatával adatokat olvashat fájlokból, vagy adatokat írhat az Azure Storage-fájlokba. Az Azure Synapse SQL-ben külső táblákkal olvashatja a külső adatokat dedikált SQL-készlet vagy kiszolgáló nélküli SQL-készlet használatával.
A külső adatforrás típusától függően kétféle külső táblát használhat:
- Hadoop külső táblák , amelyekkel adatokat olvashat és exportálhat különböző adatformátumokban, például CSV, Parquet és ORC formátumban. A Hadoop külső táblák dedikált SQL-készletekben érhetők el, de kiszolgáló nélküli SQL-készletekben nem érhetők el.
- Natív külső táblák , amelyekkel adatokat olvashat és exportálhat különböző adatformátumokban, például CSV-ben és Parquetben. A natív külső táblák kiszolgáló nélküli SQL-készletekben és dedikált SQL-készletekben érhetők el. Adatok írása/exportálása a CETAS és a natív külső táblák használatával csak a kiszolgáló nélküli SQL-készletben érhető el, a dedikált SQL-készletekben azonban nem.
A Hadoop és a natív külső táblák közötti főbb különbségek:
| Külső tábla típusa | Hadoop | Natív |
|---|---|---|
| Dedikált SQL-készlet | Rendelkezésre áll | Csak parquet |
| Kiszolgáló nélküli SQL-készlet | Nem elérhető | Rendelkezésre áll |
| Támogatott formátumok | Tagolt fájlformátumok/CSV, Parquet, ORC, Hive RC és RC | Kiszolgáló nélküli SQL-készlet: Tagolt/CSV, Parquet és Delta Lake Dedikált SQL-készlet: Parquet |
| Mappapartíció eltávolítása | Nem | A particionálás megszüntetése csak az Apache Spark-készletekből szinkronizált Parquet- vagy CSV-formátumokon létrehozott particionált táblákban érhető el. Lehet, hogy külső táblákat hoz létre a Parquet particionált mappáiban, de a particionálási oszlopok elérhetetlenek és figyelmen kívül vannak hagyva, míg a partícióelimináció nem kerül alkalmazásra. Ne hozzon létre külső táblákat a Delta Lake-mappákban , mert azok nem támogatottak. Ha particionált Delta Lake-adatokat szeretne lekérdezni, használja a Delta particionált nézeteit . |
| Fájl eltávolítás (predikátum leküldése) | Nem | Igen a kiszolgáló nélküli SQL-készletben. Az adatleküldés érdekében a Latin1_General_100_BIN2_UTF8 oszlopokon a VARCHAR rendezést kell alkalmaznia. A rendezésekkel kapcsolatos további információkért tekintse meg a Synapse SQL adatbázis-rendezési támogatását az Azure Synapse Analyticsben. |
| Egyéni formátum helyszínhez | Nem | Igen, helyettesítő karakterek használata, például /year=*/month=*/day=* Parquet- vagy CSV-formátumokhoz. Az egyéni könyvtár elérési útjai nem érhetők el a Delta Lake-ben. A kiszolgáló nélküli SQL-készletben rekurzív helyettesítő karakterek /logs/** használatával is hivatkozhat parquet- vagy CSV-fájlokra a hivatkozott mappa alatti almappákban. |
| Rekurzív mappavizsgálat | Igen | Igen. A kiszolgáló nélküli SQL-készletekben a hely elérési útjának végén kell megadni /** . A dedikált munkakészletben a mappákat mindig rekurzívan olvassák be. |
| Tárhitelesítés | Storage Access Key(SAK), Microsoft Entra átengedése, felügyelt identitás, egyéni alkalmazás Microsoft Entra-identitása | Közös hozzáférésű jogosultságkód (SAS), Microsoft Entra átengedés, felügyelt identitás, egyéni alkalmazás Microsoft Entra-identitása. |
| Oszlopok leképezése | Ordinal – A külső tábladefinícióban szereplő oszlopok pozíció alapján kerülnek megfeleltetésre az alapul szolgáló Parquet-fájlok oszlopainak. | Kiszolgáló nélküli készlet: név szerint. A külső tábladefiníció oszlopai oszlopnévegyeztetés alapján vannak megfeleltetve az alapul szolgáló Parquet-fájlok oszlopaihoz. Dedikált készlet: sorszám szerinti egyezés. A külső tábladefiníció oszlopait az alapul szolgáló Parquet-fájlok oszlopaihoz való pozíciójuk alapján képezzük le. |
| CETAS (exportálás/átalakítás) | Igen | A célként megadott natív táblákkal rendelkező CETAS csak a kiszolgáló nélküli SQL-készletben működik. A dedikált SQL-készletek nem használhatók az adatok natív táblákkal való exportálására. |
Feljegyzés
A natív külső táblák az a megoldás, amelyet ajánlanak az olyan készletekhez, amelyek általánosan elérhetők. Ha külső adatokhoz kell hozzáférnie, mindig használja a natív táblákat kiszolgáló nélküli vagy dedikált készletekben. A Hadoop-táblákat csak akkor használja, ha olyan típusokat kell elérnie, amelyek nem támogatottak a natív külső táblákban (például - ORC, RC), vagy ha a natív verzió nem érhető el.
Külső táblák dedikált SQL-készletben és kiszolgáló nélküli SQL-készletben
Külső táblákat a következőre használhat:
- Az Azure Blob Storage és az ADLS Gen2 lekérdezése Transact-SQL utasításokkal.
- A lekérdezési eredmények tárolása fájlokba az Azure Blob Storage-ban vagy az Azure Data Lake Storage-ban a CETAS és a Synapse SQL használatával.
- Importálja az adatokat az Azure Blob Storage-ból és az Azure Data Lake Storage-ból, és tárolja egy dedikált SQL-készletben (csak Hadoop-táblák dedikált készletben).
Feljegyzés
Ha a CREATE TABLE AS SELECT utasítással használja, a külső tábla kiválasztásával adatokat importál egy táblába a dedikált SQL-készleten belül.
Ha a hadoop külső táblák teljesítménye a dedikált készletekben nem felel meg a teljesítménycéloknak, fontolja meg a külső adatok betöltését az Adattárház táblákba a COPY utasítással.
A betöltési útmutatóért lásd: Adatok betöltése PolyBase használatával az Azure Blob Storage-ból.
A Synapse SQL-készletekben a következő lépésekkel hozhat létre külső táblákat:
- KÜLSŐ ADATFORRÁS LÉTREHOZÁSA külső Azure-tárolóra való hivatkozáshoz, és adja meg a tár eléréséhez használandó hitelesítő adatokat.
- CREATE EXTERNAL FILE FORMAT a CSV vagy Parquet fájlok formátumának leírásához.
- CREATE EXTERNAL TABLE a fájlok felett, amelyek a forrásban vannak elhelyezve ugyanazzal a fájlformátummal.
Mappapartíció eltávolítása
A Synapse-készletek natív külső táblái figyelmen kívül hagyhatják a lekérdezések szempontjából nem releváns mappákban elhelyezett fájlokat. Ha a fájlok mappahierarchiában vannak tárolva (például - /year=2020/month=03/day=16) és a year, és monthday oszlopokként vannak közzétéve, a szűrőket year=2020 tartalmazó lekérdezések csak a mappában elhelyezett almappákból olvassák be a year=2020 fájlokat. A lekérdezés figyelmen kívül hagyja a más mappákban (year=2021 vagy ) elhelyezett fájlokat és year=2022mappákat. Ezt az eliminációt partícióeliminálásnak nevezzük.
A mappapartíció eltávolítása a Synapse Spark-készletekből szinkronizált natív külső táblákban érhető el. Ha particionált adatkészlettel rendelkezik, és a partíció eltávolítását a létrehozott külső táblákkal szeretné használni, használja a particionált nézeteket a külső táblák helyett.
Fájl eltávolítása
Egyes adatformátumok, például a Parquet és a Delta fájlstatisztikákat tartalmaznak az egyes oszlopokhoz (például az egyes oszlopok minimális/maximális értékeihez). Az adatokat szűrő lekérdezések nem fogják olvasni azokat a fájlokat, amelyekben a szükséges oszlopértékek nem léteznek. A lekérdezés először megvizsgálja a lekérdezési predikátumban használt oszlopok minimális/maximális értékeit, hogy megkeresse azokat a fájlokat, amelyek nem tartalmazzák a szükséges adatokat. Ezeket a fájlokat a rendszer figyelmen kívül hagyja, és eltávolítja a lekérdezési tervből.
Ezt a módszert szűrő predikátum leküldésnek is nevezik, és javíthatja a lekérdezések teljesítményét. A szűrési feltételek leküldése elérhető a kiszolgáló nélküli SQL-készletekben a Parquet és Delta formátumok esetében. A karakterlánc típusok szűrőtolásának alkalmazásához használja a VARCHAR típust a Latin1_General_100_BIN2_UTF8 rendezési sorrenddel. A rendezésekkel kapcsolatos további információkért tekintse meg a Synapse SQL adatbázis-rendezési támogatását az Azure Synapse Analyticsben.
Biztonság
A felhasználónak engedéllyel kell rendelkeznie SELECT egy külső táblában az adatok olvasásához.
A külső táblák az adatforrásban definiált adatbázis-hatókörű hitelesítő adatokkal férnek hozzá a mögöttes Azure Storage-hez az alábbi szabályok használatával:
- A hitelesítő adatok nélküli adatforrás lehetővé teszi a külső táblák számára, hogy hozzáférjenek az Azure Storage nyilvánosan elérhető fájljaihoz.
- Az adatforrás rendelkezhet olyan hitelesítő adatokkal, amelyek lehetővé teszik, hogy a külső táblák csak az Azure Storage-ban lévő fájlokat érhessék el SAS-jogkivonat vagy munkaterület felügyelt identitás használatával – Ilyen például a Tárfájlok tárterület-hozzáférés-vezérlésének fejlesztése című cikk.
Megjegyzések
A megbízható lekérdezésvégrehajtás érdekében a külső táblák által hivatkozott forrásfájloknak és mappáknak a művelet teljes időtartama alatt változatlannak kell maradniuk.
- A hivatkozott fájlok vagy mappák módosítása, törlése vagy cseréje a lekérdezés futtatása közben hibákhoz vagy inkonzisztens eredményekhez vezethet.
- Mielőtt külső táblákat kérdez le egy dedikált SQL-készletben, ellenőrizze, hogy az összes forrásadat stabil-e, és a végrehajtás során nem változnak-e meg.
Példa a CREATE EXTERNAL DATA SOURCE (KÜLSŐ ADATFORRÁS LÉTREHOZÁSA) parancsra
Az alábbi példa létrehoz egy Hadoop külső adatforrást az ADLS Gen2 dedikált SQL-készletében, amely a nyilvános New York-i adatkészletre mutat:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
Az alábbi példa egy külső adatforrást hoz létre az ADLS Gen2 számára, amely a nyilvánosan elérhető New York-i adatkészletre mutat:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Példa a CREATE EXTERNAL FILE FORMAT (KÜLSŐ FÁJLFORMÁTUM LÉTREHOZÁSA) parancsra
Az alábbi példa egy külső fájlformátumot hoz létre a census fájlokhoz:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Példa CREATE EXTERNAL TABLE (KÜLSŐ TÁBLA LÉTREHOZÁSA)
Az alábbi példa egy külső táblát hoz létre. Az első sort adja vissza:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Külső táblák létrehozása és lekérdezése fájlból az Azure Data Lake-ben
A Synapse Studio Data Lake-felderítési képességeinek használatával mostantól létrehozhat és lekérdezhet egy külső táblát a Synapse SQL-készlettel, a fájlra való jobb kattintással. Az ADLS Gen2-tárfiókból külső táblák létrehozásához használt egykattintásos kézmozdulat csak Parquet-fájlok esetében támogatott.
Előfeltételek
Hozzáféréssel kell rendelkeznie a munkaterülethez legalább az
Storage Blob Data ContributorADLS Gen2-fiókhoz vagy a hozzáférés-vezérlési listákhoz (ACL) való hozzáférési szerepkörrel, amelyek lehetővé teszik a fájlok lekérdezését.Legalább engedéllyel kell rendelkeznie egy külső tábla létrehozásához és külső táblák lekérdezéséhez a Synapse SQL-készletben (dedikált vagy kiszolgáló nélküli).
Az Adatok panelen válassza ki azt a fájlt, amelyből létre szeretné hozni a külső táblát:

Ekkor megnyílik egy párbeszédpanel. Válassza ki a dedikált SQL-készletet vagy a kiszolgáló nélküli SQL-készletet, adjon nevet a táblának, és válassza a megnyitott szkriptet:
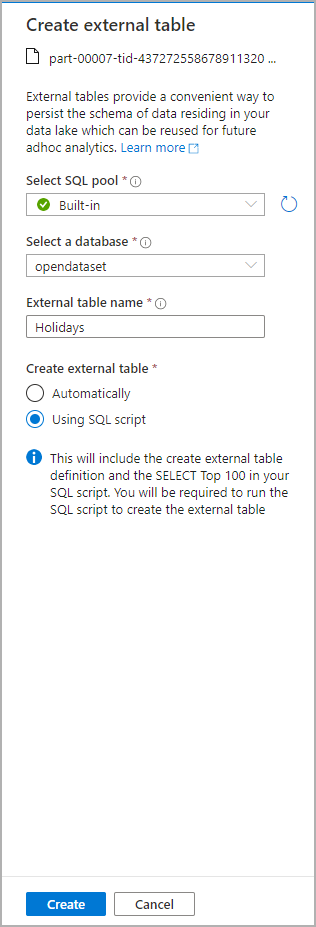
Az SQL-szkript automatikusan kinyeri a sémát a fájlból:

Futtassa a szkriptet. A szkript automatikusan futtat egy SELECT TOP 100 *:

Ekkor létrejön a külső tábla. Most már közvetlenül az Adatok panelről kérdezheti le a külső táblát.
Kapcsolódó tartalom
A lekérdezési eredmények Azure Storage-beli külső táblába való mentéséről a CETAS-cikkben olvashat. Vagy elkezdheti az Apache Spark lekérdezését az Azure Synapse külső tábláihoz.