Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tip
Microsoft Fabric Data Warehouse egy nagyvállalati szintű relációs raktár egy Data Lake-alaprendszeren, jövőre kész architektúrával, beépített AI-vel és új funkciókkal. Ha még nem ismerkedik adattárházzal, kezdje a Fabric Data Warehouse. A meglévő dedikált SQL-készlet számítási feladatai frissíthetők Fabric az adatelemzés, a valós idejű elemzés és a jelentéskészítés új képességeinek eléréséhez.
Ebben a cikkben megtudhatja, hogyan írhat lekérdezést kiszolgáló nélküli Synapse SQL-készlet használatával a Delta Lake-fájlok olvasásához. A Delta Lake egy nyílt forráskódú tárolási réteg, amely ACID-tranzakciókat (atomitást, konzisztenciát, elkülönítést és tartósságot) hoz létre az Apache Spark és a big data számítási feladatok számára. A Delta Lake-táblák lekérdezésével kapcsolatos videóból többet is megtudhat.
Fontos
A kiszolgáló nélküli SQL-készletek lekérdezhetik a Delta Lake 1.0-s verzióját. A Delta Lake 1.2-es verziója (például oszlopok átnevezése) óta bevezetett módosítások kiszolgáló nélküli környezetben nem támogatottak. Ha a Delta magasabb verzióit használja törlési vektorokkal, v2-ellenőrzőpontokkal és másokkal, fontolja meg más lekérdezési motor, például a Lakehouse-hoz készült Microsoft Fabric SQL-végpont használatát.
A Synapse-munkaterület kiszolgáló nélküli SQL-készlete lehetővé teszi a Delta Lake formátumban tárolt adatok olvasását és jelentéskészítési eszközökhöz való kiszolgálását. A kiszolgáló nélküli SQL-készlet képes olvasni az Apache Spark, az Azure Databricks vagy a Delta Lake formátum bármely más gyártója által létrehozott Delta Lake-fájlokat.
Az Azure Synapse Apache Spark-készletei lehetővé teszik az adatmérnökök számára, hogy a Scala, a PySpark és a .NET használatával módosítsák a Delta Lake-fájlokat. A kiszolgáló nélküli SQL-készletek segítségével az adatelemzők jelentéseket hozhatnak létre az adatmérnökök által létrehozott Delta Lake-fájlokról.
Fontos
A Delta Lake-formátum lekérdezése a kiszolgáló nélküli SQL-készlet használatával általánosan elérhető funkció. A Spark Delta-táblák lekérdezése azonban továbbra is nyilvános előzetes verzióban érhető el, és nem áll készen az éles üzemre. Vannak ismert problémák, amelyek akkor fordulhatnak elő, ha a Spark-készletek használatával létrehozott Delta-táblákat kérdezi le. Tekintse meg a kiszolgáló nélküli SQL-készlet ismert problémáinak önsegítő súgóját.
Előfeltételek
Fontos
Az adatforrások csak egyéni adatbázisokban hozhatók létre (a főadatbázisban vagy az Apache Spark-készletekből replikált adatbázisokban nem).
A cikkben szereplő minták használatához a következő lépéseket kell elvégeznie:
- Hozzon létre egy adatbázist egy olyan adatforrással, amely NYC Yellow Taxi Storage-fiókra hivatkozik.
- Inicializálja az objektumokat az 1. lépésben létrehozott adatbázis telepítőszkriptjének végrehajtásával. Ez a beállítási szkript létrehozza az ezekben a mintákban használt adatforrásokat, adatbázis-hatókörű hitelesítő adatokat és külső fájlformátumokat.
Ha létrehozta az adatbázist, és a környezetet az adatbázisra állította át (egy lekérdezésszerkesztőben az adatbázis kiválasztására szolgáló utasítás vagy legördülő lista használatával USE database_name ), létrehozhatja a gyökér URI-t tartalmazó külső adatforrást az adatkészletre, és használhatja a Delta Lake-fájlok lekérdezésére. Példa:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Ha egy adatforrás SAS-kulccsal vagy egyéni identitással van védve, az adatforrást adatbázis-hatókörű hitelesítő adatokkal konfigurálhatja.
Létrehozhat egy külső adatforrást, amelynek a helye a tároló gyökérmappájára mutat. Miután létrehozta a külső adatforrást, használja az adatforrást és a függvényben lévő OPENROWSET fájl relatív elérési útját. Így nem kell a teljes abszolút URI-t használnia a fájlokhoz. Ezután egyéni hitelesítő adatokat is meghatározhat a tárolási hely eléréséhez.
A Delta Lake mappa olvasása
Fontos
A minta adatforrások és táblák beállításához használja a beállítási szkriptet az előfeltételekben .
Az OPENROWSET függvény lehetővé teszi a Delta Lake-fájlok tartalmának olvasását a gyökérmappa URL-címének megadásával.
A legegyszerűbben úgy tekintheti meg DELTA fájl tartalmát, ha megadja a fájl URL-címét az OPENROWSET függvénynek, és megadja a DELTA formátumot. Ha a fájl nyilvánosan elérhető, vagy ha a Microsoft Entra-identitása hozzáfér ehhez a fájlhoz, a fájl tartalmát egy lekérdezéssel kell látnia, mint az alábbi példában látható:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Az oszlopnevek és adattípusok automatikusan beolvashatók a Delta Lake-fájlokból. A OPENROWSET függvény feltételezett adattípusokat használ, például VARCHAR(1000) a sztringoszlopokhoz.
A függvény URI-jának OPENROWSET hivatkoznia kell a Delta Lake gyökérmappára, amely egy úgynevezett _delta_logalmappát tartalmaz.
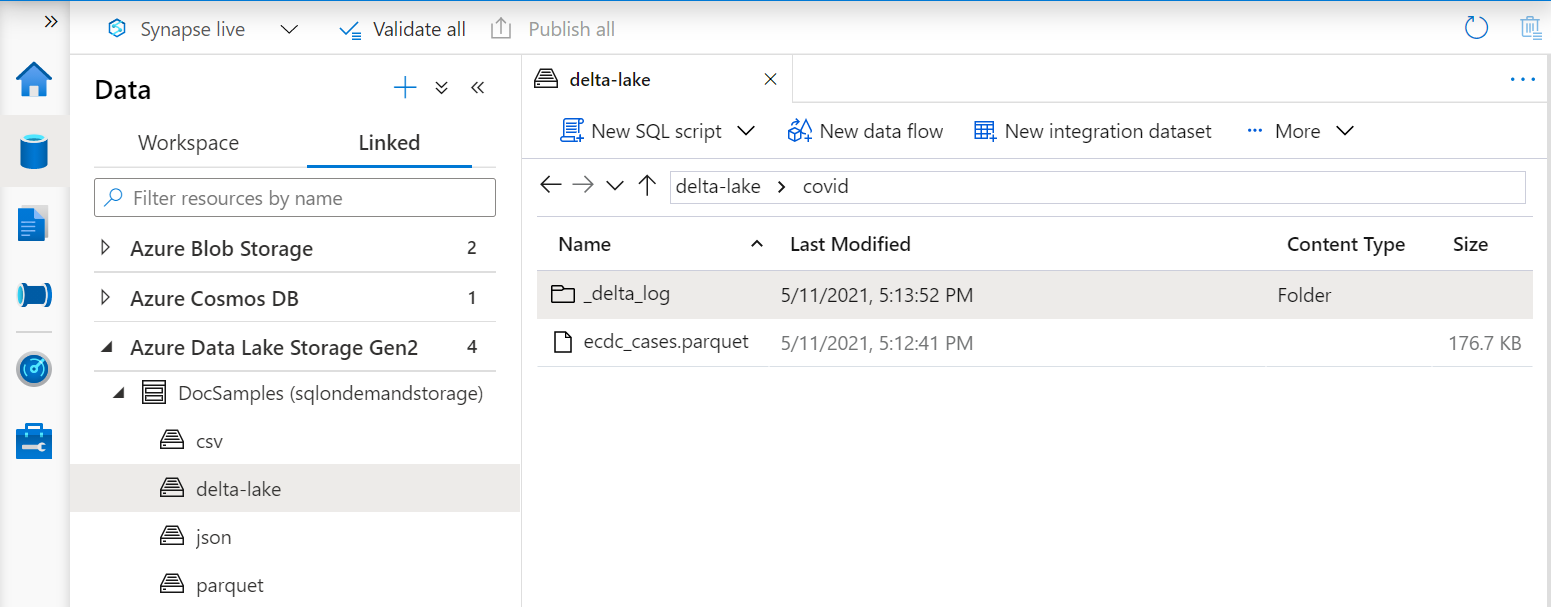
Ha nem létezik ez az almappa, akkor nem használ Delta Lake-formátumot. A mappában lévő egyszerű Parquet-fájlokat Delta Lake formátumba konvertálhatja az alábbi példa Apache Spark Python-szkripthez hasonló szkripttel:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
A lekérdezések teljesítményének javítása érdekében fontolja meg explicit típusok megadását a WITH záradékban.
Note
A kiszolgáló nélküli Synapse SQL-készlet sémakövetkeztetést használ az oszlopok és típusaik automatikus meghatározásához. A sémakövetkeztetés szabályai megegyeznek a Parquet-fájlokéval. Ha a Delta Lake-típust natív SQL-típusra szeretné megfeleltetni, ellenőrizze a Parquet típusleképezését.
Győződjön meg arról, hogy hozzáfér a fájlhoz. Ha a fájl SAS-kulccsal vagy egyéni Azure-identitással van védve, kiszolgálószintű hitelesítő adatokat kell beállítania az SQL-bejelentkezéshez.
Fontos
Győződjön meg arról, hogy UTF-8 adatbázis-rendezést használ (például Latin1_General_100_BIN2_UTF8), mert a Delta Lake-fájlok sztringértékei UTF-8 kódolással vannak kódolva.
A Delta Lake-fájl szövegkódolása és a rendezés közötti eltérés váratlan konverziós hibákat okozhat.
Az aktuális adatbázis alapértelmezett rendezése egyszerűen módosítható a következő T-SQL utasítással:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; A rendezésekkel kapcsolatos további információkért lásd a Synapse SQL által támogatott rendezési típusokat.
Explicit módon adja meg a sémát
OPENROWSET lehetővé teszi, hogy explicit módon adja meg, hogy milyen oszlopokat szeretne olvasni a fájlból záradék használatával WITH :
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Az eredményhalmaz sémájának explicit specifikációjával minimalizálhatja a típusméreteket, és a pesszimista VARCHAR(1000) helyett a sztringoszlopokhoz a VARCHAR(6) pontosabb típusokat használhatja. A típusok minimalizálása jelentősen javíthatja a lekérdezések teljesítményét.
Fontos
Győződjön meg arról, hogy a(z) WITH záradék összes sztringoszlopához explicit megadja az UTF-8 rendezést (például Latin1_General_100_BIN2_UTF8), vagy beállít egy UTF-8 rendezést adatbázis szinten.
A fájl szövegkódolása és a sztringoszlopok rendezése közötti eltérés váratlan konverziós hibákat okozhat.
Az aktuális adatbázis alapértelmezett rendezése egyszerűen módosítható a következő T-SQL utasítással:
alter database current collate Latin1_General_100_BIN2_UTF8 A következő definícióval egyszerűen állíthatja be az oszloptípusok rendezést: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Dataset
Az NYC sárga taxi adatkészletet használtunk ebben a mintában. A rendszer az eredeti PARQUET adatkészletet formátummá DELTA alakítja, és a DELTA verziót használja a példákban.
Particionált adatok lekérdezése
A mintában megadott adatkészlet külön almappákra van osztva.
A Parquettől eltérően használatával. A OPENROWSET rendszer azonosítja a particionálási oszlopokat a Delta Lake mappastruktúrájában, és lehetővé teszi az adatok közvetlen lekérdezését ezekkel az oszlopokkal. Ez a példa 2017 első három hónapjának viteldíjösszegét mutatja be év, hónap és payment_type szerint.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
A OPENROWSET függvény megszünteti azokat a partíciókat, amelyek nem felelnek meg a year és month feltételeknek a WHERE záradékban. Ez a fájl/partíció metszési technika jelentősen csökkenti az adatkészletet, javítja a teljesítményt, és csökkenti a lekérdezés költségeit.
A OPENROWSET függvény mappaneve (ebben a példában a yellow) az LOCATION adatforrásban a DeltaLakeStorage segítségével van összefűzve, és hivatkoznia kell a Delta Lake gyökérmappára, amely tartalmaz egy _delta_log nevű almappát.
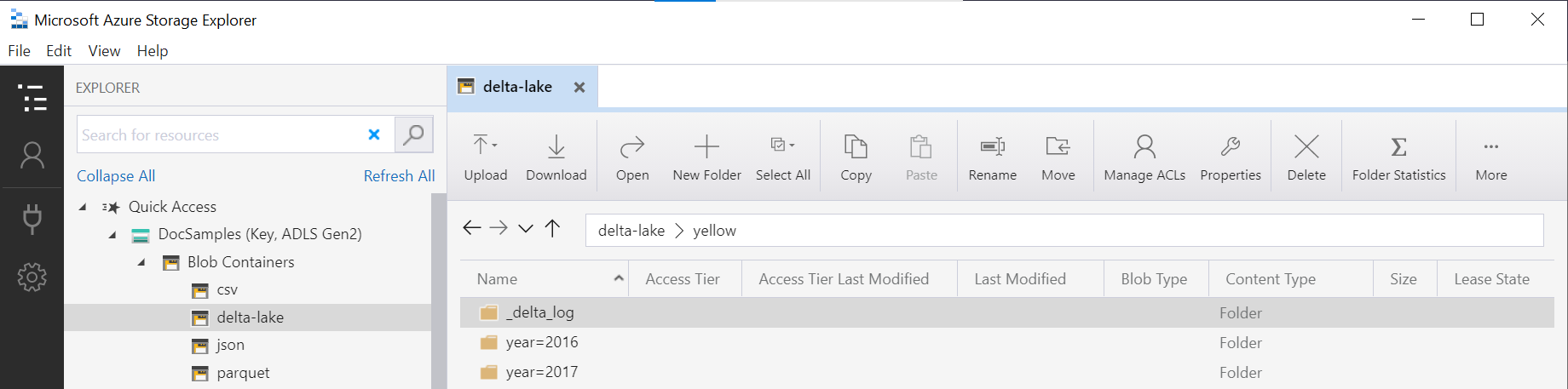
Ha nem rendelkezik ezzel az almappával, akkor nem a Delta Lake formátumot használja. A mappában lévő egyszerű Parquet-fájlokat Delta Lake formátumba konvertálhatja a következő Apache Spark Python-szkripttel:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
A DeltaTable.convertToDeltaLake függvény második argumentuma a mappaminta, ebben a példában year=*/month=*, részét képező particionálási oszlopokat (év és hónap) és azok típusait határozza meg.
Korlátozások
- Tekintse át a Synapse kiszolgáló nélküli SQL-készlet önsegítő oldalán található korlátozásokat és ismert problémákat.
Kapcsolódó tartalom
A következő cikkből megtudhatja, hogyan kérdezheti le a parquet beágyazott típusait. Ha folytatni szeretné a Delta Lake-megoldás létrehozását, megtudhatja, hogyan hozhat létre nézeteket vagy külső táblákat a Delta Lake mappában.