Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tip
Microsoft Fabric Data Warehouse egy nagyvállalati szintű relációs raktár egy Data Lake-alaprendszeren, jövőre kész architektúrával, beépített AI-vel és új funkciókkal. Ha még nem ismerkedik adattárházzal, kezdje a Fabric Data Warehouse. A meglévő dedikált SQL-készlet számítási feladatai frissíthetők Fabric az adatelemzés, a valós idejű elemzés és a jelentéskészítés új képességeinek eléréséhez.
Ebben a cikkben megtudhatja, hogyan kérdezhet le egyetlen CSV-fájlt kiszolgáló nélküli SQL-készlet használatával az Azure Synapse Analyticsben. A CSV-fájlok formátuma eltérő lehet:
- Fejlécsorsal és anélkül
- Vesszővel és tabulátorral elválasztott értékek
- Windows és Unix stílusú vonalvégződések
- Nem idézett és idézett értékek, valamint a speciális karakterek kezelése
Az alábbiakban a fenti változatok mindegyikét bemutatjuk.
Gyorsindítási példa
OPENROWSET függvény lehetővé teszi a CSV-fájl tartalmának olvasását a fájl URL-címének megadásával.
Csv-fájl olvasása
A legegyszerűbben úgy tekintheti meg a fájl tartalmát CSV, ha megadja a fájl URL-címét a OPENROWSET funkciónak, adja meg a csv formátumot FORMAT, és a 2.0 verziót PARSER_VERSION. Ha a fájl nyilvánosan elérhető, vagy ha a Microsoft Entra-identitása hozzáfér ehhez a fájlhoz, akkor a következő példában látható lekérdezéshez hasonlóan a fájl tartalmát is látnia kell:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
A beállítással firstrow kihagyhatja a CSV-fájl első olyan sorát, amely ebben az esetben a fejlécet jelöli. Győződjön meg arról, hogy hozzáfér ehhez a fájlhoz. Ha a fájl SAS-kulccsal vagy egyéni identitással van védve, kiszolgálószintű hitelesítő adatokat kell beállítania az SQL-bejelentkezéshez.
Fontos
Ha a CSV-fájl UTF-8 karaktert tartalmaz, győződjön meg arról, hogy UTF-8 adatbázis-rendezést használ (például Latin1_General_100_CI_AS_SC_UTF8).
A fájl szövegkódolása és a rendezés közötti eltérés váratlan konverziós hibákat okozhat.
Az aktuális adatbázis alapértelmezett rendezése egyszerűen módosítható a következő T-SQL utasítással: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Adatforrások használata
Az előző példa a fájl teljes elérési útját használja. Másik lehetőségként létrehozhat egy külső adatforrást a tár gyökérmappájára mutató hellyel:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Miután létrehozott egy adatforrást, használhatja ezt az adatforrást és a függvényben lévő OPENROWSET fájl relatív elérési útját:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Ha egy adatforrás SAS-kulccsal vagy egyéni identitással van védve, az adatforrást adatbázis-hatókörű hitelesítő adatokkal konfigurálhatja.
Explicit módon adja meg a sémát
OPENROWSET lehetővé teszi, hogy explicit módon adja meg, hogy milyen oszlopokat szeretne olvasni a fájlból záradék használatával WITH :
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
A záradékban szereplő adattípus utáni számok a WITH CSV-fájl oszlopindexét jelölik.
Fontos
Ha a CSV-fájl UTF-8 karaktert tartalmaz, győződjön meg arról, hogy kifejezetten UTF-8 rendezést (például Latin1_General_100_CI_AS_SC_UTF8) ad meg WITH záradék összes oszlopához, vagy állítson be valamilyen UTF-8 rendezést adatbázisszinten.
A fájl szövegkódolása és a rendezés közötti eltérés váratlan konverziós hibákat okozhat.
Az aktuális adatbázis alapértelmezett rendezése egyszerűen módosítható a következő T-SQL utasítással:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 A következő definícióval egyszerűen állíthatja be az oszloptípusok rendezést: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
A következő szakaszokban megtudhatja, hogyan kérdezhet le különböző TÍPUSÚ CSV-fájlokat.
Előfeltételek
Első lépésként hozzon létre egy adatbázist , amelyben a táblák létre lesznek hozva. Ezután inicializálja az objektumokat az adatbázis telepítőszkriptjének végrehajtásával. Ez a beállítási szkript létrehozza az ezekben a mintákban használt adatforrásokat, adatbázis-hatókörű hitelesítő adatokat és külső fájlformátumokat.
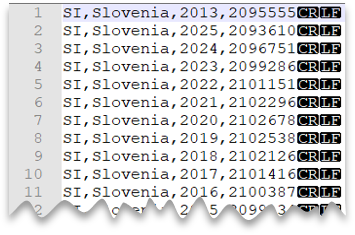
Windows stílusú új sor
Az alábbi lekérdezés bemutatja, hogyan olvasható egy CSV-fájl fejlécsor nélkül, windowsos stílusú új vonallal és vesszővel tagolt oszlopokkal.
Fájl előnézete:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
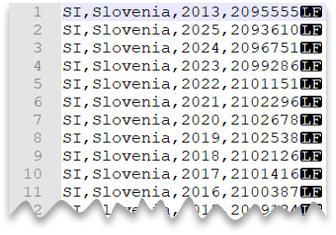
Unix stílusú új sor
Az alábbi lekérdezés bemutatja, hogyan olvashatja be a fejlécsor nélküli fájlokat unix stílusú új sorokkal és vesszővel tagolt oszlopokkal. Figyelje meg a fájl különböző helyét a többi példához képest.
Fájl előnézete:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
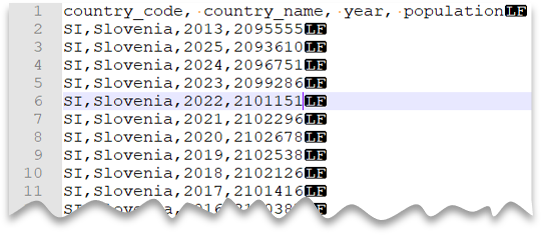
Fejlécsor
Az alábbi lekérdezés bemutatja, hogyan olvashat be egy fejlécsort tartalmazó, Unix stílusú új sort és vesszővel tagolt oszlopokat tartalmazó fájlt. Figyelje meg a fájl különböző helyét a többi példához képest.
Fájl előnézete:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
A beállítás HEADER_ROW = TRUE az oszlopnevek beolvasását eredményezi a fájl fejlécsorából. Kiválóan alkalmas feltárási célokra, ha nem ismeri a fájltartalmat. A legjobb teljesítmény érdekében nézze meg az Ajánlott eljárások -en belül a, A megfelelő adattípusok használata részt. Az OPENROWSET szintaxisáról itt olvashat bővebben.
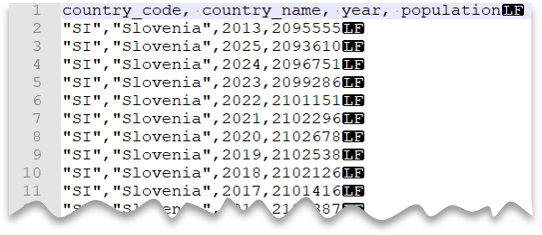
Egyéni idézőjel
Az alábbi lekérdezés bemutatja, hogyan lehet egy fejlécsorral rendelkező fájlt beolvasni, amely Unix-stílusú újsorokat, vesszővel elválasztott oszlopokat és idézőjelek közötti értékeket tartalmaz. Figyelje meg a fájl különböző helyét a többi példához képest.
Fájl előnézete:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Note
Ez a lekérdezés ugyanazokat az eredményeket adja vissza, ha nem adja meg a FIELDQUOTE paramétert, mivel a FIELDQUOTE alapértelmezett értéke egy dupla idézőjel.
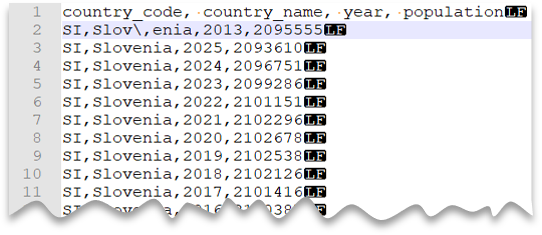
** Vezérlő karakterek
Az alábbi lekérdezés bemutatja, hogyan olvasható be egy fejlécsort tartalmazó fájl unix stílusú új vonallal, vesszővel tagolt oszlopokkal és az értékeken belüli mezőelválasztóhoz (vesszőhöz) használt feloldó karakterrel. Figyelje meg a fájl különböző helyét a többi példához képest.
Fájl előnézete:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Note
Ez a lekérdezés sikertelen lenne, ha az ESCAPECHAR nincs megadva, mivel a "Slov,enia" vessző az ország/régió neve helyett mezőelválasztóként lesz kezelve. A "Slov,enia" két oszlopként lesz kezelve. Ezért az adott sornak több oszlopa lenne, mint a többi sornak, és egy oszloptal több, mint amit a WITH záradékban definiált.
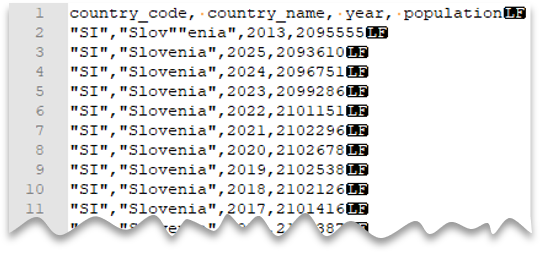
Idézőjelek feloldása
Az alábbi lekérdezés bemutatja, hogyan olvashat be egy fejlécsort tartalmazó fájlt, egy Unix-stílusú új sort, vesszővel tagolt oszlopokat és egy szökött dupla idézőjel karaktert az értékeken belül. Figyelje meg a fájl különböző helyét a többi példához képest.
Fájl előnézete:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Note
Az idézőjelet egy másik idézőjellel kell kivédeni. Az idézőjel csak akkor jelenhet meg az oszlopértékben, ha az érték idéző karakterekkel van beágyazva.
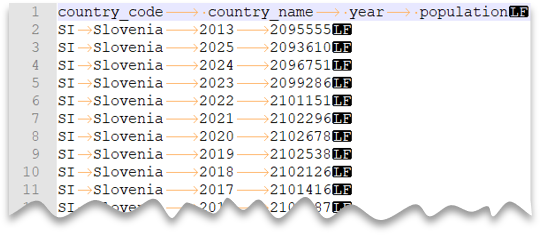
Tabulátorral tagolt fájlok
Az alábbi lekérdezés bemutatja, hogyan lehet beolvasni egy fejlécsort tartalmazó, Unix stílusú újsorral és tabulátorral elválasztott oszlopokkal rendelkező fájlt. Figyelje meg a fájl különböző helyét a többi példához képest.
Fájl előnézete:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Oszlopok részhalmazának visszaadása
Eddig a WITH használatával adta meg a CSV-fájlsémát, és az összes oszlopot listázta. A lekérdezésben ténylegesen szükséges oszlopokat csak az egyes szükséges oszlopokhoz tartozó sorszámmal adhatja meg. A nem érdekes oszlopokat is kihagyja.
Az alábbi lekérdezés a fájlban lévő különböző ország-/régiónevek számát adja vissza, és csak a szükséges oszlopokat adja meg:
Note
Tekintse meg az alábbi lekérdezés WITH záradékát, és figyelje meg, hogy a sor végén "2" (idézőjelek nélkül) található, ahol a [country_name] oszlopot definiálja. Ez azt jelenti, hogy a [country_name] oszlop a fájl második oszlopa. A lekérdezés figyelmen kívül hagyja a fájl összes oszlopát, kivéve a másodikat.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Hozzáfűzhető fájlok lekérdezése
A lekérdezésben használt CSV-fájlokat nem szabad módosítani, amíg a lekérdezés fut. A hosszú ideig futó lekérdezésben előfordulhat, hogy az SQL-készlet újra megkísérli az olvasást, beolvassa a fájlok részeit, vagy akár többször is felolvassa a fájlt. A fájltartalom módosítása rossz eredményt eredményezne. Ezért az SQL-készlet meghiúsul a lekérdezésben, ha azt észleli, hogy bármely fájl módosítási ideje módosul a lekérdezés végrehajtása során.
Bizonyos esetekben érdemes lehet elolvasni a folyamatosan hozzáfűzött fájlokat. A folyamatosan hozzáfűzött fájlokból eredő lekérdezési hibák elkerülése érdekében engedélyezheti, hogy a függvény figyelmen kívül hagyja a OPENROWSET lehetséges inkonzisztens olvasásokat a ROWSET_OPTIONS beállítással.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
Az ALLOW_INCONSISTENT_READS olvasási beállítás letiltja a fájlmódosítási idő ellenőrzését a lekérdezés életciklusa során, és beolvassa a fájlban elérhető összes beállítást. A hozzáfűzhető fájlokban a meglévő tartalom nem frissül, és csak új sorokat ad hozzá. Ezért a hibás eredmények valószínűsége a frissíthető fájlokhoz képest minimálisra csökken. Ez a beállítás lehetővé teheti a gyakran hozzáfűzött fájlok olvasását a hibák kezelése nélkül. A legtöbb esetben az SQL-készlet figyelmen kívül hagy néhány sort, amelyeket a lekérdezés végrehajtása során hozzáfűznek a fájlokhoz.
Kapcsolódó tartalom
A következő cikkek bemutatják, hogyan: