Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tipp.
Microsoft Fabric Data Warehouse egy nagyvállalati szintű relációs raktár egy Data Lake-alaprendszeren, jövőre kész architektúrával, beépített AI-vel és új funkciókkal. Ha még nem ismerkedik adattárházzal, kezdje a Fabric Data Warehouse. A meglévő dedikált SQL-készlet számítási feladatai frissíthetők Fabric az adatelemzés, a valós idejű elemzés és a jelentéskészítés új képességeinek eléréséhez.
A OPENROWSET(BULK...) függvény lehetővé teszi a fájlok elérését az Azure Storage-ban.
OPENROWSET a függvény beolvassa egy távoli adatforrás (például fájl) tartalmát, és sorhalmazként adja vissza a tartalmat. A kiszolgáló nélküli SQL-készlet erőforrásán belül az OPENROWSET tömeges sorkészlet-szolgáltató az OPENROWSET függvény meghívásával és a BULK beállítás megadásával érhető el.
A OPENROWSET függvényre úgy lehet hivatkozni a lekérdezés FROM záradékában, mintha egy táblanév OPENROWSET lenne. Támogatja a tömeges műveleteket egy beépített BULK-szolgáltatón keresztül, amely lehetővé teszi a fájlból származó adatok sorokként való olvasását és visszaadát.
Feljegyzés
Az OPENROWSET függvény nem támogatott a dedikált SQL-készletben.
Adatforrás
A Synapse SQL OPENROWSET függvénye beolvassa a fájlok tartalmát egy adatforrásból. Az adatforrás egy Azure Storage-fiók, amely kifejezetten hivatkozhat rá a OPENROWSET függvényben, vagy dinamikusan következtethet az olvasni kívánt fájlok URL-címére.
A OPENROWSET függvény opcionálisan tartalmazhat egy paramétert DATA_SOURCE a fájlokat tartalmazó adatforrás megadásához.
OPENROWSETDATA_SOURCEnélkül használható a fájlok tartalmának közvetlen beolvasására azBULKopcióként megadott URL-címről:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Ez egy gyors és egyszerű módja annak, hogy előre konfigurálás nélkül olvassa el a fájlok tartalmát. Ez a beállítás lehetővé teszi az alapszintű hitelesítési beállítás használatát a tároló eléréséhez (Microsoft Entra-átengedés a Microsoft Entra-bejelentkezésekhez és SAS-jogkivonat az SQL-bejelentkezésekhez).
OPENROWSETésDATA_SOURCEhasználatával hozzáférhet a megadott tárfiók fájljaihoz:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Ezzel a beállítással konfigurálhatja a tárfiók helyét az adatforrásban, és megadhatja a tárterület eléréséhez használni kívánt hitelesítési módszert.
Fontos
OPENROWSEThiányábanDATA_SOURCEgyors és egyszerű módot biztosít a tárfájlok elérésére, de korlátozott hitelesítési lehetőségeket kínál. A Microsoft Entra-tagok például csak a Microsoft Entra-identitásukkal vagy nyilvánosan elérhető fájljaikkal férhetnek hozzá a fájlokhoz. Ha hatékonyabb hitelesítési lehetőségekre van szüksége, használjaDATA_SOURCEa lehetőséget, és határozza meg a tárterület eléréséhez használni kívánt hitelesítő adatokat.
Biztonság
Az adatbázis-felhasználónak engedéllyel kell rendelkeznie ADMINISTER BULK OPERATIONS a OPENROWSET függvény használatához.
A tárolási rendszergazdának engedélyeznie kell a felhasználó számára a fájlok elérését érvényes SAS-jogkivonat megadásával vagy a Microsoft Entra-tag számára a tárfájlok elérésének engedélyezésével. Ebben a cikkben további információt talál a tárhozzáférés-vezérlésről.
OPENROWSET a következő szabályok segítségével állapítsa meg, hogyan kell hitelesítést végezni a tárterületen:
- A
OPENROWSEThitelesítési mechanizmus nélküli rendszer esetén aDATA_SOURCEfügg a hívó típusától.- Bármely felhasználó használhatja
OPENROWSETanélkül, hogyDATA_SOURCEolvasná az Azure-tárolón nyilvánosan elérhető fájlokat. - A Microsoft Entra-bejelentkezések a saját Microsoft Entra-identitásukkal férhetnek hozzá a védett fájlokhoz, ha az Azure Storage lehetővé teszi a Microsoft Entra-felhasználó számára a mögöttes fájlok elérését (például ha a hívó rendelkezik
Storage Readerengedéllyel az Azure Storage-ban). - Az SQL-bejelentkezések
OPENROWSEThasználatával elérhetik a nyilvánosan elérhető fájlokat, a SAS-jogkivonattal védett fájlokat vagy a Synapse munkaterület felügyelt identitásának fájljait,DATA_SOURCEnélkül. A tárolófájlokhoz való hozzáférés engedélyezéséhez kiszolgálói hatókörű hitelesítő adatokat kell létrehoznia.
- Bármely felhasználó használhatja
-
OPENROWSETADATA_SOURCEhitelesítési mechanizmust az adatbázis-hatókörű hitelesítő adatok határozzák meg, amelyek a hivatkozott adatforráshoz vannak rendelve. Ez a beállítás lehetővé teszi a nyilvánosan elérhető tároló elérését, vagy a tároló elérését SAS-jogkivonat, munkaterület felügyelt identitása vagy hívó Microsoft Entra-identitása használatával (ha a hívó a Microsoft Entra-tag). Ha aDATA_SOURCEhivatkozás nem nyilvános Azure Storage-ra mutat, szükséges adatbázis-hatókörű hitelesítő adatot létrehozni és aztDATA SOURCE-ban hivatkozni a tárolófájlokhoz való hozzáférés engedélyezéséhez.
A hívónak rendelkeznie kell REFERENCES engedéllyel a hitelesítő adatok használatához a tárhelyhez való hitelesítés során.
Szintaxis
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumentumok
A lekérdezés céladatait tartalmazó bemeneti fájlokhoz három lehetőség közül választhat. Az érvényes értékek a következők:
"CSV" – Tartalmaz minden olyan tagolt szövegfájlt, amely sor-/oszlopelválasztókkal rendelkezik. Bármely karakter használható mezőelválasztóként, például TSV: FIELDTERMINATOR = tab.
"PARQUET" – Bináris fájl Parquet formátumban.
"DELTA" – Parquet-fájlok készlete Delta Lake (előzetes verzió) formátumban.
Az üres szóközökkel rendelkező értékek érvénytelenek. A "CSV" például nem érvényes érték.
'nem_strukturált_adat_elérési_út'
Az adatok elérési útját megállapító unstructured_data_path lehet abszolút vagy relatív elérési út:
- A formátum
\<prefix>://\<storage_account_path>/\<storage_path>abszolút elérési útja lehetővé teszi a felhasználó számára a fájlok közvetlen olvasását. - Relatív elérési útvonal a
<storage_path>paraméterrel együtt kötelezően használandó formátumbanDATA_SOURCE, és leírja a fájlmintázatot a <storage_account_path> helyen, amely aEXTERNAL DATA SOURCEpontban van meghatározva.
Az alábbiakban megtalálja a tárfiók elérési útjának< megfelelő >értékeit, amelyek az adott külső adatforráshoz fognak kapcsolódni.
| Külső adatforrás | Előtag | Tárfiók elérési útja |
|---|---|---|
| Azure Blob Storage | http[s] | < >storage_account.blob.core.windows.net/path/file |
| Azure Blob Storage | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Storage Gen1 | http[s] | < >storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Storage Gen2 | http[s] | <tároló_fiók>.dfs.core.windows.net/path/file |
| Azure Data Lake Storage Gen2 | abfs[s] | <file_system>@<account_name.dfs.core.windows.net/path/file> |
"<tárolási_útvonal>"
Megadja a tárolón belüli elérési utat, amely az olvasni kívánt mappára vagy fájlra mutat. Ha az elérési út egy tárolóra vagy mappára mutat, az adott tárolóból vagy mappából minden fájl beolvasható. Az almappákban lévő fájlok nem lesznek szerepeltetve.
Helyettesítő karakterek használatával több fájlt vagy mappát is megcélzhat. Több nem egymást követő helyettesítő karakter használata engedélyezett.
Az alábbiakban egy példa látható, amely az összes csv-fájlt beolvassa a /csv/population fájltól kezdve az összes mappából:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Ha a „unstructured_data_path” megadásakor mappát ad meg, egy serverless SQL-készlet lekérdezése le fogja kérni a fájlokat az adott mappából.
A kiszolgáló nélküli SQL-készletet arra utasíthatja, hogy irányítsa át a mappákat úgy, hogy az elérési út végén a /* értéket adja meg, mint például: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Feljegyzés
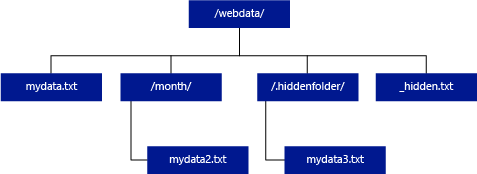
A Hadooptól és a PolyBase-től eltérően a kiszolgáló nélküli SQL-készlet csak akkor ad vissza almappákat, ha az elérési út végén megadja a /** értéket. A Hadoophoz és a PolyBase-hez hasonlóan nem ad vissza olyan fájlokat, amelyeknek a neve aláhúzással (_) vagy ponttal (.) kezdődik.
Az alábbi példában, ha az unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/, egy szerver nélküli SQL-adattárház lekérdezése sorokat jelenít meg a mydata.txt fájlból. Nem adja vissza mydata2.txt és mydata3.txt, mert egy almappában találhatók.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
A WITH záradék lehetővé teszi a fájlokból olvasni kívánt oszlopok megadását.
A CSV-adatfájlok esetében az összes oszlop beolvasásához adja meg az oszlopneveket és azok adattípusait. Ha az oszlopok egy részhalmazát szeretné használni, az ordinális számokkal az eredeti adatfájlokból származó oszlopokat sorszám szerint választhatja ki. Az oszlopokat a sorszám megjelölése köti össze. Ha HEADER_ROW = TRUE értéket használ, akkor az oszlopkötést oszlopnévvel hajtja végre a rendszer az ordinális pozíció helyett.
Tipp.
A CSV-fájlokHOZ tartozó WITH záradékot is kihagyhatja. Az adattípusokat automatikusan kikövetkeztetik a fájl tartalma alapján. HEADER_ROW argumentum használatával megadhatja, hogy létezik-e fejlécsor, amely esetben az oszlopnevek beolvashatók a fejlécsorból. A részletekért ellenőrizze az automatikus sémafelderítést.
Parquet- vagy Delta Lake-fájlok esetén adja meg azokat az oszlopneveket, amelyek megfelelnek az eredeti adatfájlok oszlopneveinek. Az oszlopok név szerint lesznek kötve, és megkülönböztetik a kis- és nagybetűk megkülönböztetésével. Ha a WITH záradék nincs megadva, a rendszer a Parquet-fájlok összes oszlopát visszaadja.
Fontos
A Parquet- és Delta Lake-fájlok oszlopnevei megkülönböztetik a kis- és nagybetűket. Ha az oszlopnév írásmódja eltér a fájlokban lévő oszlopnév írásmódjától, akkor az
NULLértékek lesznek visszatérítve az adott oszlopra.
column_name = A kimeneti oszlop neve. Ha meg van adva, ez a név felülbírálja a forrásfájl oszlopnevét, és ha van ilyen, akkor a JSON-elérési úton megadott oszlopnevet. Ha json_path nincs megadva, a rendszer automatikusan hozzáadja "$.column_name" néven. Ellenőrizze a json_path argumentum működését.
column_type = A kimeneti oszlop adattípusa. Itt történik az implicit adattípus-átalakítás.
column_ordinal = A forrásfájl(ok) oszlopának sorszáma. Ezt az argumentumot a rendszer figyelmen kívül hagyja a Parquet-fájlok esetében, mivel a kötés név szerint történik. Az alábbi példa csak EGY CSV-fájlból ad vissza egy második oszlopot:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = JSON-elérési út kifejezés oszlophoz vagy beágyazott tulajdonsághoz. Az alapértelmezett útvonal mód laza.
Feljegyzés
Szigorú módban a lekérdezés sikertelen lesz, ha a megadott elérési út nem létezik. Lax módban a lekérdezés sikeres lesz, és a JSON-elérési út kifejezése NULL értékre lesz kiértékelve.
<tömeges_opciók>
FIELDTERMINATOR ='mező_elválasztó'
Megadja a használni kívánt mező-terminátort. Az alapértelmezett mezőelválasztó egy vessző (",").
ROWTERMINÁTOR ='row_terminator'
A használni kívánt sor terminátorát adja meg. Ha nincs megadva sor-terminátor, a rendszer az egyik alapértelmezett terminátort használja. Az PARSER_VERSION = '1.0' alapértelmezett terminátorai a következők: \r\n, \n és \r. A PARSER_VERSION = '2.0' alapértelmezett terminátorai a \r\n és a \n.
Feljegyzés
Ha a PARSER_VERSION='1.0' beállítást használja, és a sor terminátoraként \n (új sor) értéket ad meg, az automatikusan \r (kocsivissza) karakterrel lesz előtaggal ellátva, ami az \r\n sor terminátort eredményezi.
ESCAPE_CHAR = "char"
A fájlban az a karakter van megadva, amely önmagát és a fájl összes elválasztó karakter szerepét kivételként kezeli. Ha a feloldó karaktert nem önmagától, vagy az elválasztó értékek bármelyikétől eltérő érték követi, a rendszer elveti a feloldó karaktert az érték olvasásakor.
Az ESCAPECHAR paraméter attól függetlenül lesz alkalmazva, hogy a FIELDQUOTE engedélyezve van-e. Nem fogják az idézőjelet escape karakterként használni. Az idézőjelet egy másik idéző karakterrel kell megszűkíteni. Az idézőjel csak akkor jelenhet meg az oszlopértékben, ha az érték idéző karakterekkel van beágyazva.
FIRSTROW = 'első_sor'
Megadja az első betöltendő sor számát. Az alapértelmezett érték 1, és a megadott adatfájl első sorát jelzi. A sorszámokat a sorok terminátorainak megszámlálásával határozzuk meg. A FIRSTROW egy alapú.
FIELDQUOTE = 'field_quote'
A CSV-fájlban idézőjelként használt karaktert ad meg. Ha nincs megadva, a program az idézőjelet (") használja.
DATA_COMPRESSION = "data_compression_method"
A tömörítési módszert adja meg. Csak PARSER_VERSION='1.0' támogatott. A következő tömörítési módszer támogatott:
- GZIP
PARSER_VERSION = "parser_version"
A fájlok olvasásához használandó elemzőverziót adja meg. A CSV-elemző jelenleg az 1.0-s és a 2.0-s verziót támogatja:
- PARSER_VERSION = '1,0'
- PARSER_VERSION = '2.0'
A CSV-elemző 1.0-s verziója alapértelmezett és funkciógazdag. A 2.0-s verzió teljesítményre készült, és nem támogatja az összes lehetőséget és kódolást.
A CSV-elemző 1.0-s verziójának jellemzői:
- A következő beállítások nem támogatottak: HEADER_ROW.
- Az alapértelmezett végjelek a következők: \r\n, \n és \r.
- Ha \n (új sor) karaktert ad meg a sor terminátoraként, a program automatikusan hozzáadja az \r (kocsivissza) karaktert előtagként, amely az \r\n sor terminátort eredményezi.
A CSV-elemző 2.0-s verziójának jellemzői:
- Nem minden adattípus támogatott.
- A karakteroszlopok maximális hossza 8000.
- A maximális sorméretkorlát 8 MB.
- A következő beállítások nem támogatottak: DATA_COMPRESSION.
- Az idézett üres karakterlánc ("") üresként van értelmezve.
- A DATEFORMAT SET beállítás nem érvényes.
- A DATE adattípus támogatott formátuma: YYYY-MM-DD
- A TIME-adattípus támogatott formátuma: HH:MM:SS[.tört másodperc]
- Támogatott formátum DATETIME2 adattípushoz: YYYYY-MM-DD HH:MM:SS[.tört másodperc]
- Az alapértelmezett terminátorok a következőek: \r\n és \n.
HEADER_ROW = { IGAZ | HAMIS }
Megadja, hogy egy CSV-fájl tartalmaz-e fejlécsort. Az alapértelmezett érték a FALSE. PARSER_VERSION='2.0' fájlban támogatott. Ha IGAZ, az oszlopnevek a FIRSTROW argumentum szerint az első sorból lesznek beolvasva. Ha TRUE, és a séma a WITH használatával van megadva, akkor az oszlopnevek hozzárendelése oszlopnév alapján történik, nem pedig sorszám szerint.
DATAFILETYPE = { 'char' | "widechar" }
Megadja a kódolást: char az UTF8-hoz widechar , UTF16-fájlokhoz használatos.
CODEPAGE = { 'ACP' | "OEM" | "RAW" | "code_page" }
Az adatfájlban lévő adatok kódlapját adja meg. Az alapértelmezett érték 65001 (UTF-8 kódolás). Erről a beállításról itt talál további részleteket.
ROWSET_OPTIONS = "{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}"
Ez a beállítás letiltja a fájlmódosítás ellenőrzését a lekérdezés végrehajtása során, és felolvassa a lekérdezés futtatása közben frissített fájlokat. Ez hasznos lehet, amikor olyan hozzáfűzhető fájlokat kell olvasnia, amelyek a lekérdezés futtatása közben kerülnek hozzáfűzésre. A hozzáfűzhető fájlokban a meglévő tartalom nem frissül, és csak új sorokat ad hozzá. Ezért a hibás eredmények valószínűsége a frissíthető fájlokhoz képest minimálisra csökken. Ez a beállítás lehetővé teheti a gyakran hozzáfűzött fájlok olvasását a hibák kezelése nélkül. További információ a hozzáfűzhető CSV-fájlok lekérdezéséről.
Elutasítási beállítások
Feljegyzés
Az elutasított sorok funkció nyilvános előzetes verzióban érhető el. Vegye figyelembe, hogy az elutasított sorok funkció tagolt szövegfájlokhoz és PARSER_VERSION 1.0-s verzióhoz használható.
Megadhatja az elutasítási paramétereket, amelyek meghatározzák, hogy a szolgáltatás hogyan fogja kezelni a külső adatforrásból lekért piszkos rekordokat. Az adatrekordok akkor minősülnek "piszkosnak", ha a tényleges adattípusok nem felelnek meg a külső tábla oszlopdefinícióinak.
Ha nem adja meg vagy módosítja az elutasítási beállításokat, a szolgáltatás az alapértelmezett értékeket használja. A szolgáltatás az elutasítási beállítások használatával határozza meg, hogy hány sor utasítható el a tényleges lekérdezés meghiúsulása előtt. A lekérdezés (részleges) eredményeket ad vissza az elutasítási küszöbérték túllépéséig. Ezután a megfelelő hibaüzenettel meghiúsul.
MAXERRORS = reject_value
Megadja azoknak a soroknak a számát, amelyeket a lekérdezés meghiúsulása előtt el lehet utasítani. A MAXERRORS értéknek 0 és 2 147 483 647 közötti egész számnak kell lennie.
ERRORFILE_DATA_SOURCE = adatforrás
Megadja az adatforrást, ahol az elutasított sorokat és a megfelelő hibafájlt meg kell írni.
ERRORFILE_LOCATION = Címtár helye
Adja meg a DATA_SOURCE-on belüli könyvtárat, vagy amennyiben meg van adva, az ERROR_FILE_DATASOURCE-t, ahová az elutasított sorok és a megfelelő hibafájl írásra kerüljenek. Ha a megadott elérési út nem létezik, a szolgáltatás létrehoz egyet az Ön nevében. A rendszer egy "rejectedrows" nevű gyermekkönyvtárat hoz létre. A "" karakter biztosítja, hogy a könyvtár figyelmen kívül legyen hagyva más adatfeldolgozáskor, kivéve, ha a helyparaméterben kifejezetten meg van adva. Ebben a könyvtárban van egy, a betöltési idő alapján létrehozott mappa, amely a YearMonthDay_HourMinuteSecond_StatementID formátumban van (például 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Az utasításazonosítóval korrelálhatja a mappát az azt létrehozó lekérdezéssel. Ebben a mappában két fájl van megírva: error.json fájl és az adatfájl.
error.json fájl olyan JSON-tömböt tartalmaz, amely az elutasított sorokkal kapcsolatos hibákat észlelt. A hibát képviselő minden elem a következő attribútumokat tartalmazza:
| Attribútum | Leírás |
|---|---|
| Hiba | A sor elutasításának oka. |
| Sor | Elutasított sor sorszáma a fájlban. |
| Oszlop | Elutasított oszlop sorszáma. |
| Érték | Elutasított oszlopérték. Ha az érték 100 karakternél nagyobb, csak az első 100 karakter jelenik meg. |
| Fájl | A sorhoz tartozó fájl elérési útja. |
Gyorsan tagolt szöveg elemzése
Két tagolt szövegelemző verziót használhat. A CSV-elemző 1.0-s verziója alapértelmezés szerint gazdag, míg az elemző 2.0-s verziója a teljesítményhez készült. A parser 2.0 teljesítménybeli javulása fejlett elemzési technikákból és többszálas feldolgozásból származik. A fájlméret növekedésével a sebességkülönbség nagyobb lesz.
Automatikus sémafelderítés
A CSV- és Parquet-fájlokat is egyszerűen lekérdezheti anélkül, hogy ismerné vagy meg tudná adni a sémát a WITH záradék kihagyásával. Az oszlopnevek és adattípusok a fájlokból lesznek levonva.
A parquet-fájlok oszlop-metaadatokat tartalmaznak, amelyek beolvashatók, a típusleképezések a Parquet típusleképezéseiben találhatók. Ellenőrizze a Parquet-fájlok olvasását anélkül, hogy sémát ad meg a mintákhoz.
A CSV-fájlok esetében az oszlopnevek olvashatók a fejlécsorból. Megadhatja, hogy létezik-e fejlécsor HEADER_ROW argumentum használatával. Ha HEADER_ROW = HAMIS, a rendszer általános oszlopneveket használ: C1, C2, ... Cn, ahol n a fájl oszlopainak száma. Az adattípusok az első 100 adatsorból lesznek levonva. Ellenőrizze a CSV-fájlok olvasását a minták sémájának megadása nélkül.
Ne feledje, hogy ha egyszerre olvas be fájlokat, a sémát az első fájlból fogják kikövetkeztetni, amelyet a szolgáltatás a tárolóból olvas be. Ez azt jelentheti, hogy a várt oszlopok némelyike hiányzik, mindezt azért, mert a szolgáltatás által a séma meghatározására használt fájl nem tartalmazza ezeket az oszlopokat. Ebben az esetben használja az OPENROWSET WITH záradékot.
Fontos
Vannak olyan esetek, amikor a megfelelő adattípus nem következtethető ki az információ hiánya miatt, és ehelyett nagyobb adattípust használnak. Ez többletterhelést okoz a teljesítmény szempontjából, és különösen fontos a karakteroszlopok esetében, amelyek varchar(8000) néven lesznek kikövetkeztetve. Az optimális teljesítmény érdekében ellenőrizze a kikövetkeztetett adattípusokat, és használja a megfelelő adattípusokat.
A Parquet típusleképezése
A parquet- és Delta Lake-fájlok minden oszlophoz tartalmaznak típusleírásokat. Az alábbi táblázat azt ismerteti, hogy a Parquet-típusok hogyan vannak megfeleltetve natív SQL-típusokra.
| Parquet típusa | Parquet logikai típus (annotáció) | SQL-adattípus |
|---|---|---|
| LOGIKAI ÉRTÉK | bit | |
| BINÁRIS / BÁJT_TÖMB | varbinary | |
| DUPLA | float | |
| LEBEG | valós | |
| INT32 | egész | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | bináris | |
| BINÁRIS | UTF8 | varchar *(UTF8 kódolás) |
| BINÁRIS | HÚR | varchar *(UTF8 kódolás) |
| BINÁRIS | ENUM | varchar *(UTF8 kódolás) |
| FIXED_LEN_BYTE_ARRAY | Egyetemes Egyedi Azonosító (UUID) | egyedi azonosító |
| BINÁRIS | TIZEDES | decimális |
| BINÁRIS | JSON | varchar(8000) *(UTF8 karakterkészlet) |
| BINÁRIS | BSON | Nem támogatott |
| FIXED_LEN_BYTE_ARRAY | TIZEDES | decimális |
| BYTE_TÖMB | INTERVALLUM | Nem támogatott |
| INT32 | INT(8; igaz) | smallint |
| INT32 | INT(16; igaz) | smallint |
| INT32 | INT(32; igaz) | egész |
| INT32 | INT(8, HAMIS) | tinyint |
| INT32 | INT(16; hamis) | egész |
| INT32 | INT(32; hamis) | bigint |
| INT32 | DÁTUM | dátum: |
| INT32 | TIZEDES | decimális |
| INT32 | IDŐ (MILLIS) | idő |
| INT64 | INT(64; igaz) | bigint |
| INT64 | INT(64; hamis) | decimális(20,0) |
| INT64 | TIZEDES | decimális |
| INT64 | IDŐ (MIKROSZEKUNDUMOK) | idő |
| INT64 | IDŐ (NANOMÁSODPERC) | Nem támogatott |
| INT64 | TIMESTAMP (NORMALIZÁLT UTC) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (nem normalizált UTC-hez) (MILLIS / MICROS) | bigint – győződjön meg arról, hogy az időzóna eltolásával explicit módon módosítja az bigint értéket, mielőtt dátum-idő értékké konvertálja. |
| INT64 | IDŐBÉLYEGZŐ (Nanomásodperc) | Nem támogatott |
| Összetett típus | LISTA | varchar(8000), JSON-ra szerializálva |
| Összetett típus | TÉRKÉP | varchar(8000), JSON-ra szerializálva |
Példák
CSV-fájlok olvasása séma megadása nélkül
Az alábbi példa olyan CSV-fájlt olvas be, amely oszlopnevek és adattípusok megadása nélkül tartalmaz fejlécsort:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
Az alábbi példa olyan CSV-fájlt olvas be, amely nem tartalmaz fejlécsort oszlopnevek és adattípusok megadása nélkül:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Parquet-fájlok olvasása séma megadása nélkül
Az alábbi példa az első sor összes oszlopát adja vissza a census adatkészletéből Parquet formátumban, oszlopnevek és adattípusok megadása nélkül:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Delta Lake-fájlok olvasása séma megadása nélkül
Az alábbi példa az első sor összes oszlopát visszaadja a census adatkészletből Delta Lake formátumban, oszlopnevek és adattípusok megadása nélkül:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Adott oszlopok beolvasása CSV-fájlból
Az alábbi példa csak a 1 és 4 sorszámokkal rendelkező két oszlopot adja vissza a populáció*.csv fájlokból. Mivel nincs fejlécsor a fájlokban, az első sorból kezdi az olvasást:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
A konkrét oszlopok olvasása Parquet-fájlból
Az alábbi példa csak az első sor két oszlopát adja vissza a census adatkészletéből Parquet formátumban:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Oszlopok megadása JSON-elérési utak használatával
Az alábbi példa bemutatja, hogyan használhat JSON-elérésiút-kifejezéseket a WITH záradékban, és hogyan mutatja be a szigorú és a hasadt elérési út mód közötti különbséget:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Több fájl/mappa megadása TÖMEGES elérési úton
Az alábbi példa bemutatja, hogyan használható több fájl/mappa elérési útja a BULK paraméterben:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Következő lépések
További példákért tekintse meg a lekérdezési adattároló rövid útmutatójában a CSV, PARQUET, OPENROWSETDELTA LAKE és JSON fájlformátumok olvasásának módját. Tekintse át az optimális teljesítmény elérésére vonatkozó ajánlott eljárásokat . Azt is megtudhatja, hogyan mentheti a lekérdezés eredményeit az Azure Storage-ba a CETAS használatával.