Time Series Elemzések (TSI) Gen2 migrálása az Azure Data Explorerbe
Feljegyzés
A Time Series Elemzések (TSI) szolgáltatás 2025 márciusa után már nem támogatott. Fontolja meg a meglévő TSI-környezetek migrálását alternatív megoldásokba a lehető leghamarabb. Az elavulással és a migrálással kapcsolatos további információkért tekintse meg dokumentációnkat.
Áttekintés
Magas szintű migrálási javaslatok.
| Szolgáltatás | Gen2 állapot | Migrálás javasolt |
|---|---|---|
| JSON betöltése a központból lapított és menekülő állapotban | TSI-betöltés | ADX – OneClick Ingest /Wizard |
| Hidegáruház megnyitása | Ügyfél tárfiókja | Folyamatos adatexportálás az ügyfél által megadott külső táblába az ADLS-ben. |
| PBI-Csatlakozás or | Privát előzetes verzió | Használja az ADX PBI Csatlakozás ort. Írja át manuálisan a TSQ-t a KQL-be. |
| Spark-összekötő | Privát előzetes verzió. Telemetriaadatok lekérdezése. Modelladatok lekérdezése. | Adatok áttelepítése az ADX-be. Használja az ADX Spark-összekötőt telemetriai adatokhoz+ exportálja a modellt JSON-ba, és töltse be a Sparkban. Írja át a lekérdezéseket a KQL-ben. |
| Tömeges feltöltés | Privát előzetes verzió | Használja az ADX OneClick Ingest és LightIngest parancsot. Igény szerint állítsa be a particionálást az ADX-ben. |
| Time Series-modell | JSON-fájlként exportálható. Az ADX-be importálva illesztések végezhetők a KQL-ben. | |
| TSI Explorer | Meleg és hideg toggling | ADX-irányítópultok |
| Lekérdezés nyelve | Idősoros lekérdezések (TSQ) | Írja át a lekérdezéseket a KQL-ben. TSI-k helyett Kusto SDK-k használata. |
Telemetria migrálása
A PT=Time tárfiók mappájában kérje le a környezet összes telemetriájának másolatát. További információ: Data Storage.
1. migrálási lépés – A telemetriai adatok statisztikáinak lekérése
Adatok
- Az Env áttekintése
- A Data Access teljes tartománynevének első részéből származó környezeti azonosító rögzítése (például d390b0b0-1445-4c0c-8365-68d6382c1c2a From .env.crystal-dev.windows-int.net)
- Env – Áttekintés –> Tárkonfiguráció –> Tárfiók
- Mappastatisztikák lekérése a Storage Explorer használatával
- Rekordméret és a mappablobok
PT=Timeszáma. A Tömeges importálás privát előzetes verziójában lévő ügyfelek számára a blobok rekordméretePT=Importés száma is.
- Rekordméret és a mappablobok
2. migrálási lépés – Telemetriai adatok migrálása az ADX-be
ADX-fürt létrehozása
Adja meg a fürt méretét az adatméret alapján az ADX Költségbecslő használatával.
- Az Event Hubs (vagy az IoT Hub) metrikáiból lekérheti a naponta betöltött adatok arányát. A TSI-környezethez csatlakoztatott tárfiókból kérje le, hogy mennyi adat található a TSI által használt blobtárolóban. Ez az információ az ADX-fürt ideális méretének kiszámítására szolgál a környezet számára.
- Nyissa meg az Azure Data Explorer Költségbecslőt , és töltse ki a meglévő mezőket a talált információkkal. Állítsa be a "Számítási feladat típusa" értéket a "Tárolásra optimalizált" és a "Gyakori adatok" értékre az aktív lekérdezett adatok teljes mennyiségével.
- Az összes információ megadása után az Azure Data Explorer Költségbecslője javaslatot tesz a virtuális gép méretére és a fürt példányainak számára. Elemezze, hogy az aktív lekérdezett adatok mérete elfér-e a gyorsgyorsítótárban. Szorozza meg a javasolt példányok számát a virtuális gép méretének gyorsítótárméretével, példánként:
- Költségbecslő javaslat: 9x DS14 + 4 TB (gyorsítótár)
- Javasolt teljes gyorsgyorsítótár: 36 TB = [9x (példányok) x 4 TB (gyorsgyorsítótár csomópontonként)]
- További megfontolandó tényezők:
- Környezet növekedése: az ADX-fürt méretének tervezésekor vegye figyelembe az adatnövekedést az idő során.
- Hidratálás és particionálás: az ADX-fürtön lévő példányok számának meghatározásakor fontolja meg a további csomópontokat (2-3x-tal) a hidratálás és particionálás felgyorsítása érdekében.
- A számítási kijelölésről további információt az Azure Data Explorer-fürt megfelelő számítási termékváltozatának kiválasztása című témakörben talál.
A fürt és az adatbetöltés legjobb monitorozásához engedélyeznie kell a diagnosztikai Gépház, és el kell küldenie az adatokat egy Log Analytics-munkaterületre.
Az Azure Data Explorer panelen válassza a "Figyelés | Diagnosztikai beállítások", majd kattintson a "Diagnosztikai beállítás hozzáadása" elemre
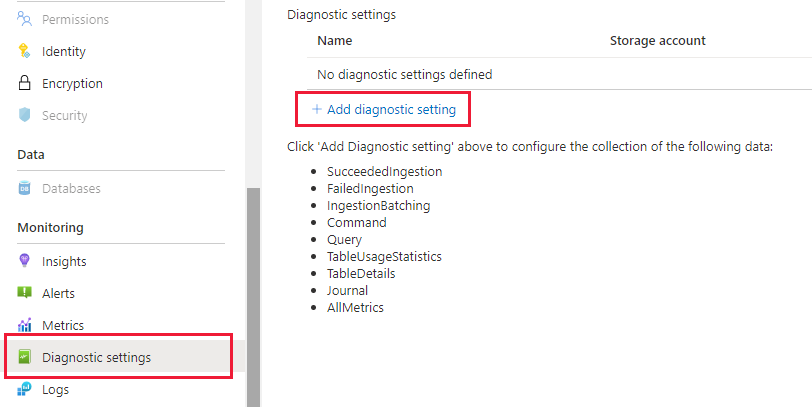
Töltse ki a következőt
- Diagnosztikai beállítás neve: A konfiguráció megjelenítendő neve
- Naplók: Legalább válassza a SucceededIngestion, FailedIngestion, IngestionBatching lehetőséget
- Válassza ki a Log Analytics-munkaterületet az adatok elküldéséhez (ha nem rendelkezik olyannal, amelybe a lépés előtt ki kell építenie egyet)

Adatparticionálás.
- A legtöbb adathalmaz esetében elegendő az alapértelmezett ADX-particionálás.
- Az adatparticionálás nagyon specifikus forgatókönyvekben hasznos, és másképpen nem alkalmazható:
- A lekérdezések késésének javítása olyan big data-készletekben, ahol a lekérdezések többsége nagy számosságú sztringoszlopra szűr, például idősorozat-azonosítóra.
- A rendelésen kívüli adatok betöltésekor, például amikor a múlt eseményei napokat vagy heteket is betölthetnek a forrásban lévő generáció után.
- További információt az ADX adatparticionálási szabályzatában talál.


Adatbetöltés előkészítése
Odamegy https://dataexplorer.azure.com.
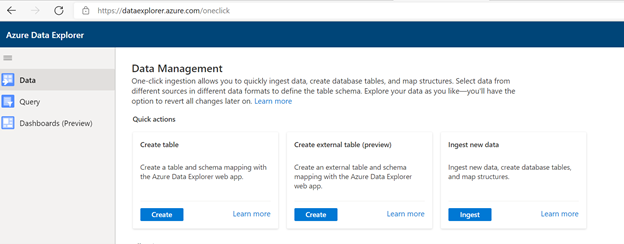
Lépjen az Adatok lapra, és válassza a "Betöltés blobtárolóból" lehetőséget

Válassza a Fürt, adatbázis lehetőséget, és hozzon létre egy új táblát a TSI-adatokhoz választott névvel
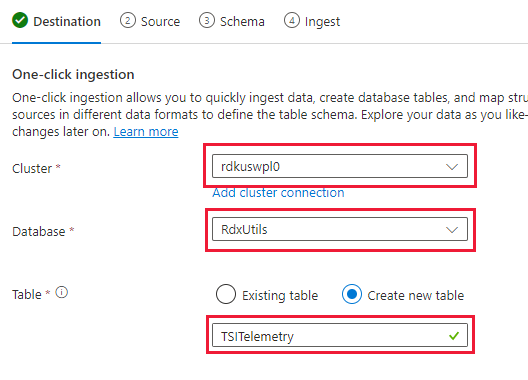
Válassza a Tovább elemet: Forrás
A Forrás lapon válassza a következőt:
- Történelmi adatok
- "Tároló kiválasztása"
- Válassza ki a TSI-adatok előfizetési és tárolási fiókját
- Válassza ki a TSI-környezettel korreláló tárolót

Kiválasztás a Speciális beállítások területen
- Létrehozási idő minta: '/'yyyyyMMddHmmssfff'_'
- Blobnévminta: *.parquet
- Válassza a "Ne várja meg, amíg a betöltés befejeződik" lehetőséget
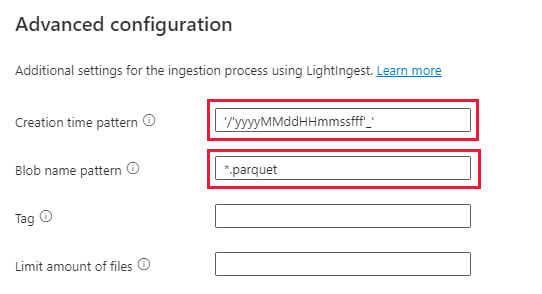
A Fájlszűrők csoportban adja hozzá a mappa elérési útját
V=1/PT=Time
Válassza a Tovább elemet: Séma
Feljegyzés
A TSI a Parquet-fájlok oszlopainak megőrzésekor alkalmaz némi simítást és menekülést. További részletekért tekintse meg ezeket a hivatkozásokat: összeolvasztási és menekülési szabályok, betöltési szabályok frissítései.






Ha a séma ismeretlen vagy változó
Távolítsa el a ritkán lekérdezett összes oszlopot, és hagyja meg legalább az időbélyeget és a TSID oszlop(ok)t.
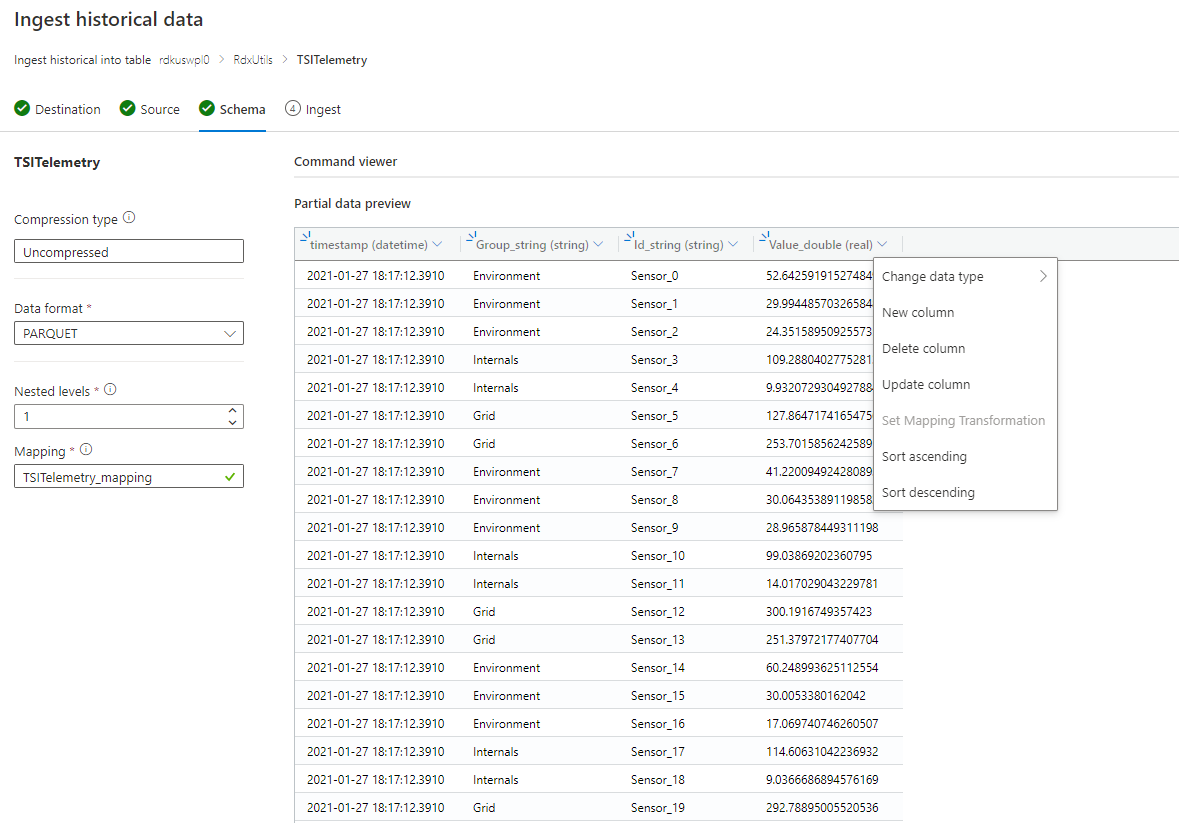
Adjon hozzá új dinamikus típusú oszlopot, és képezze le a teljes rekordra a $ elérési út használatával.

Példa:

Ha a séma ismert vagy javítva van
- Ellenőrizze, hogy az adatok helyesek-e. Szükség esetén javítsa ki a típusokat.
- Válassza a Tovább elemet: Összegzés



Másolja ki a LightIngest parancsot, és tárolja valahol, hogy a következő lépésben használhassa.

Adatfeldolgozás
Az adatok betöltése előtt telepítenie kell a LightIngest eszközt. A One-Click eszközből létrehozott parancs tartalmaz egy SAS-jogkivonatot. A legjobb, ha újat hoz létre, hogy szabályozhassa a lejárati időt. A portálon lépjen a TSI-környezet blobtárolójához, és válassza a "Megosztott hozzáférési jogkivonat" lehetőséget

Feljegyzés
Azt is javasoljuk, hogy skálázza fel a fürtöt, mielőtt elindít egy nagy betöltést. Például: D14 vagy D32 8+ példányokkal.
Az alábbiak beállítása
- Engedélyek: Olvasás és lista
- Lejárat: Állítson be egy olyan időszakot, amikor az adatok áttelepítése befejeződött

Válassza a "Sas-jogkivonat és URL-cím létrehozása" lehetőséget, és másolja a "Blob SAS URL-címet"

Lépjen a korábban másolt LightIngest parancsra. Cserélje le a -source paramétert a parancsban erre a "SAS Blob URL-címre"
1. lehetőség: Az összes adat betöltése. Kisebb környezetek esetén az összes adatot egyetlen paranccsal lehet betölteni.
- Nyisson meg egy parancssort, és váltson arra a könyvtárra, amelybe a LightIngest eszközt kinyerték. Miután ott volt, illessze be a LightIngest parancsot, és hajtsa végre.

2. lehetőség: Adatok betöltése év vagy hónap szerint. Nagyobb környezetek esetén vagy kisebb adathalmaz teszteléséhez tovább szűrheti a Lightingest parancsot.
Év szerint: Az -prefix paraméter módosítása
- Előtte:
-prefix:"V=1/PT=Time" - Utána:
-prefix:"V=1/PT=Time/Y=<Year>" - Példa:
-prefix:"V=1/PT=Time/Y=2021"
- Előtte:
Hónap szerint: Az -prefix paraméter módosítása
- Előtte:
-prefix:"V=1/PT=Time" - Utána:
-prefix:"V=1/PT=Time/Y=<Year>/M=<month #>" - Példa:
-prefix:"V=1/PT=Time/Y=2021/M=03"
- Előtte:



Miután módosította a parancsot, hajtsa végre a fentihez hasonlóan. Az egyik betöltés befejeződött (az alábbi monitorozási lehetőség használatával) módosítsa a következő évre és hónapra vonatkozó parancsot, amelyet be szeretne tölteni.
Figyelési betöltés
A LightIngest parancs tartalmazta a -dontWait jelzőt, így maga a parancs nem várja meg a betöltés befejezését. A folyamat előrehaladásának figyelésére a legjobb módszer a portálon belüli "Elemzések" fül használata. Nyissa meg az Azure Data Explorer-fürt portálon belüli szakaszát, és lépjen a "Figyelés | Elemzések'

A "Betöltés (előzetes verzió)" szakasz az alábbi beállításokkal figyelheti a betöltési folyamatokat.
- Időtartomány: Utolsó 30 perc
- A sikeres és a táblázatos keresés
- Ha bármilyen hibát észlel, tekintse meg a Sikertelen és a Táblázat szerint című
Tudni fogja, hogy a betöltési művelet befejeződött, amint a metrikák a táblához tartozó 0-ra kerülnek. Ha további részleteket szeretne látni, használhatja a Log Analyticset. Az Azure Data Explorer fürtszakaszában válassza a "Napló" fület:

Hasznos lekérdezések
A séma ismertetése dinamikus séma használata esetén
| project p=treepath(fullrecord)
| mv-expand p
| summarize by tostring(p)
Értékek elérése tömbben
| where id_string == "a"
| summarize avg(todouble(fullrecord.['nestedArray_v_double'])) by bin(timestamp, 1s)
| render timechart
Time Series Model (TSM) migrálása az Azure Data Explorerbe
A modell JSON formátumban letölthető a TSI-környezetből a TSI Explorer UX vagy a TSM Batch API használatával. Ezután a modell importálható egy másik rendszerbe, például az Azure Data Explorerbe.
Töltse le a TSM-et a TSI UX-ből.
Törölje az első három sort a VSCode vagy egy másik szerkesztő használatával.

A VSCode vagy más szerkesztő használatával keressen és cserélje le regexként
\},\n \{a következőre:}{
Betöltés JSON-ként az ADX-be külön táblázatként a fájlfunkciók feltöltésével.




Idősoros lekérdezések (TSQ) lefordítása KQL-be
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
GetEvents szűrővel
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
GetEvents előre jelzett változóval
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
AggregateSeries szűrővel
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Migrálás a TSI Power BI Csatlakozás orról az ADX Power BI Csatlakozás orra
A migrálás manuális lépései a következők:
- Power BI-lekérdezés konvertálása TSQ-ra
- TSQ átalakítása KQL Power BI-lekérdezéssé TSQ-vá: A TSI UX Explorerből másolt Power BI-lekérdezés az alábbi módon néz ki
Nyers adatokhoz (GetEvents API)
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"getEvents":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"take":250000}}]}
- TSQ-vá alakításához hozzon létre egy JSON-t a fenti hasznos adatokból. A GetEvents API dokumentációjában példák is vannak a jobb megértéshez. Lekérdezés – Végrehajtás – REST API (Azure Time Series Elemzések) | Microsoft Docs
- A konvertált TSQ az alább látható módon jelenik meg. Ez a JSON hasznos adata a "lekérdezésekben"
{
"getEvents": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"take": 250000
}
}
Aggradate Data (Aggregate Series API)
- Egyetlen beágyazott változó esetén a TSI UX Explorerből származó PowerBI-lekérdezés az alábbi módon néz ki:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}]}
- TSQ-vá alakításához hozzon létre egy JSON-t a fenti hasznos adatokból. Az AggregateSeries API dokumentációja példákat is ad a jobb megértéshez. Lekérdezés – Végrehajtás – REST API (Azure Time Series Elemzések) | Microsoft Docs
- A konvertált TSQ az alább látható módon jelenik meg. Ez a JSON hasznos adata a "lekérdezésekben"
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
}
},
"projectedVariables": [
"EventCount",
]
}
}
- Több beágyazott változó esetén fűzze hozzá a jsont az "inlineVariables" elemhez az alábbi példában látható módon. Egynél több beágyazott változó Power BI-lekérdezése a következőképpen néz ki:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com","queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}, {"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"Magnitude":{"kind":"numeric","value":{"tsx":"$event['mag'].Double"},"aggregation":{"tsx":"max($value)"}}},"projectedVariables":["Magnitude"]}}]}
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
},
"Magnitude": {
"kind": "numeric",
"value": {
"tsx": "$event['mag'].Double"
},
"aggregation": {
"tsx": "max($value)"
}
}
},
"projectedVariables": [
"EventCount",
"Magnitude",
]
}
}
- Ha le szeretné kérdezni a legújabb adatokat("isSearchSpanRelative": igaz), manuálisan számítsa ki a keresési adatokat az alábbiak szerint
- Keresse meg a Power BI hasznos adatai között a "from" és a "to" közötti különbséget. Nevezzük ezt a különbséget "D"-nek, ahol a "D" = "from" - "to"
- Vegye ki az aktuális időbélyeget("T"), és vonja ki az első lépésben kapott különbséget. Ez lesz az új "from"(F) a searchSpan ahol "F" = "T" - "D"
- Most az új "from" az "F" a 2. lépésben, az új "to" pedig "T" (aktuális időbélyeg)