Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Jótanács
Ez a tartalom a „Az Azure-hoz készült natív felhőalapú .NET-alkalmazások tervezése” című eBookból egy részlet, amely elérhető a .NET Docs oldalán, vagy ingyenesen letölthető PDF fájlként, amely offline módban is olvasható.

Ahogy a könyvben láthattuk, a natív felhőbeli megközelítés megváltoztatja az alkalmazások tervezésének, üzembe helyezésének és kezelésének módját. Emellett az adatok kezelésének és tárolásának módját is megváltoztatja.
Az 5–1. ábra a különbségeket mutatja.
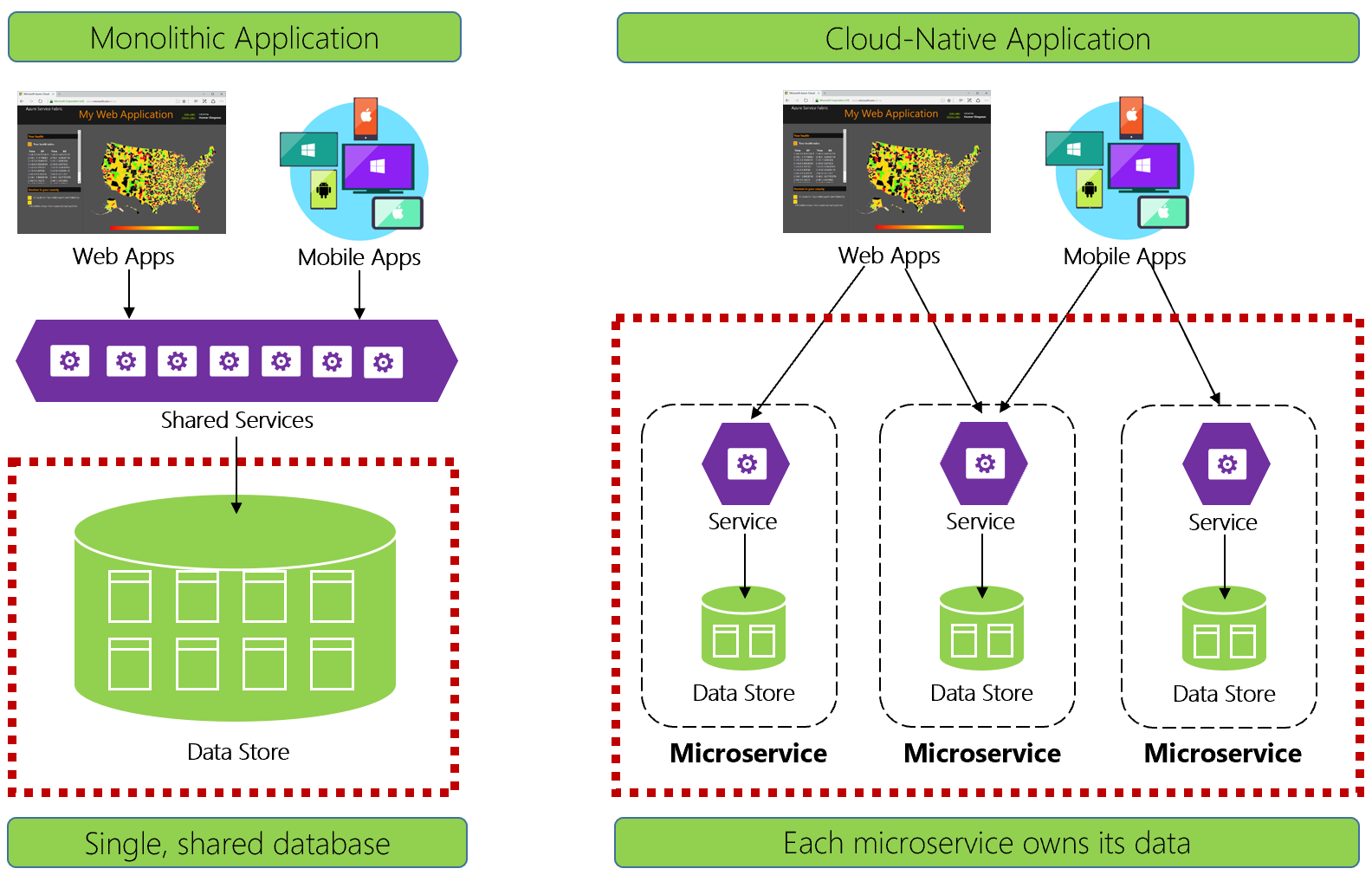
5-1. ábra. Adatkezelés natív felhőbeli alkalmazásokban
A tapasztalt fejlesztők könnyen felismerik az 5-1. ábra bal oldalán található architektúrát. Ebben a monolitikus alkalmazásban az üzleti szolgáltatás összetevői egy megosztott szolgáltatási rétegben osztják meg az adatokat egyetlen relációs adatbázisból.
Az egyetlen adatbázis sok szempontból egyszerűnek tartja az adatkezelést. Az adatok több tábla közötti lekérdezése egyszerű. Az adatfrissítések egyidejű módosítása vagy teljes visszaállításuk. Az ACID-tranzakciók erős és azonnali konzisztenciát garantálnak.
A natív felhő tervezésekor más megközelítést alkalmazunk. Az 5–1. ábra jobb oldalán figyelje meg, hogy az üzleti funkciók hogyan különülnek el kis, független mikroszolgáltatásokra. Minden mikroszolgáltatás egy adott üzleti képességet és saját adatait foglalja magában. A monolitikus adatbázis több kisebb adatbázissal rendelkező elosztott adatmodellre bomlik, és mindegyik egy mikroszolgáltatáshoz igazodik. Amikor a füst kitisztul, egy olyan kialakítással kelünk elő, amely mikroszolgáltatásonként elérhetővé tesz egy adatbázist.
Mikroszolgáltatásonkénti adatbázis, miért?
Ez az adatbázis mikroszolgáltatásonként számos előnnyel jár, különösen azoknak a rendszereknek, amelyeknek gyorsan kell fejlődniük és nagy léptékű támogatást kell nyújtaniuk. Ezzel a modellel...
- A tartományi adatok a szolgáltatáson belül lesznek beágyazva
- Az adatséma anélkül fejlődhet, hogy közvetlenül hatással lenne más szolgáltatásokra
- Az egyes adattárak egymástól függetlenül méretezhetők
- Az egyik szolgáltatásban lévő adattárhiba nem befolyásolja közvetlenül a többi szolgáltatást
Az adatok elkülönítése azt is lehetővé teszi, hogy minden mikroszolgáltatás megvalósítsa a számítási feladatához, tárolási igényeihez és olvasási/írási mintáihoz leginkább optimalizált adattártípust. A lehetőségek közé tartoznak a relációs, dokumentum-, kulcs-érték- és akár gráfalapú adattárak.
Az 5–2. ábra bemutatja a többplatformos adatmegőrzés elvét egy natív felhőrendszerben.
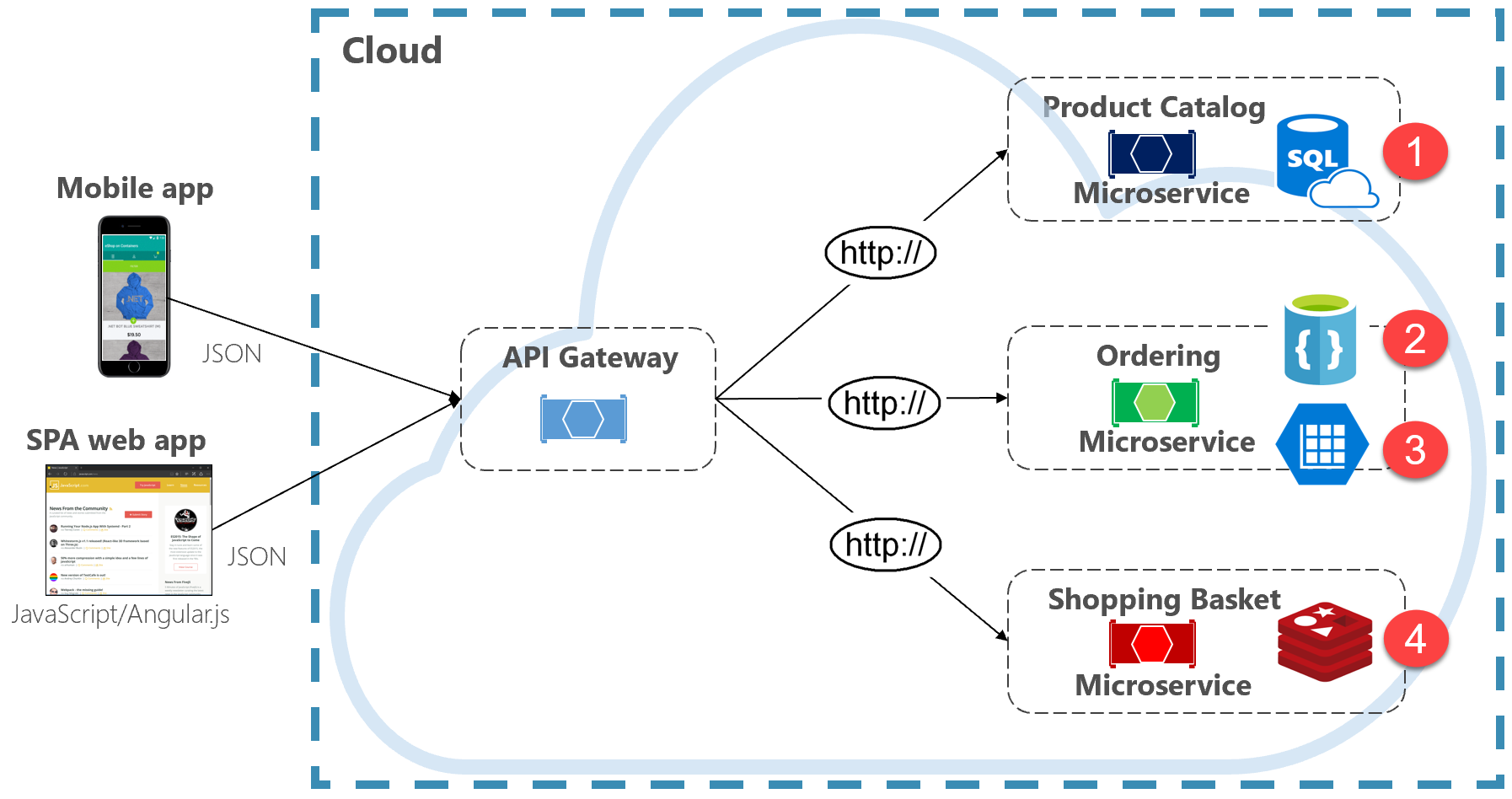
5-2. ábra. Többplatformos adatmegőrzés
Az előző ábrán látható, hogy az egyes mikroszolgáltatások hogyan támogatnak egy másik típusú adattárat.
- A termékkatalógus mikroszolgáltatása egy relációs adatbázist használ a mögöttes adatok gazdag relációs szerkezetének fogadására.
- A bevásárlókocsi mikroszolgáltatása egy elosztott gyorsítótárat használ, amely támogatja az egyszerű, kulcs-érték adattárat.
- A rendelési mikroszolgáltatás egy NoSql-dokumentumadatbázist is használ az írási műveletekhez, valamint egy magas denormalizált kulcs-/értéktárat is, amely nagy mennyiségű olvasási művelet tárolására alkalmas.
Bár a relációs adatbázisok továbbra is relevánsak maradnak az összetett adatokkal rendelkező mikroszolgáltatások esetében, a NoSQL-adatbázisok jelentős népszerűségre tettek szert. Nagy léptékű és magas rendelkezésre állást biztosítanak. Séma nélküli természetük lehetővé teszi a fejlesztők számára, hogy elmozduljanak a gépelt adatosztályok és ORM-ek architektúrájától, amelyek költségessé és időigényessé teszik a módosításokat. A Fejezet későbbi részében a NoSQL-adatbázisokat tárgyaljuk.
Bár az adatok különálló mikroszolgáltatásokba való beágyazása növelheti az agilitást, a teljesítményt és a méretezhetőséget, számos kihívást is jelent. A következő szakaszban ezeket a kihívásokat, valamint azokat a mintákat és gyakorlatokat tárgyaljuk, amelyek segítenek leküzdeni őket.
Szolgáltatásközi lekérdezések
Bár a mikroszolgáltatások függetlenek, és bizonyos funkcionális képességekre, például leltározásra, szállításra vagy megrendelésre összpontosítanak, gyakran más mikroszolgáltatásokkal való integrációt igényelnek. Az integráció során gyakran előfordul, hogy az egyik mikroszolgáltatás lekérdez egy másikat az adatokhoz. Az 5–3. ábra a forgatókönyvet mutatja be.
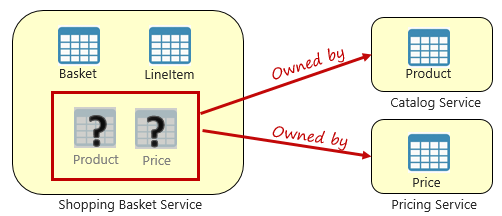
5-3. ábra. Lekérdezés mikroszolgáltatások között
Az előző ábrán egy bevásárlókosár mikroszolgáltatás látható, amely hozzáad egy elemet egy felhasználó bevásárlókosarahoz. Bár a mikroszolgáltatás adattára kosár- és sorelemadatokat tartalmaz, nem tart fenn termék- vagy díjszabási adatokat. Ehelyett ezek az adatelemek a katalógus és a díjszabási mikroszolgáltatások tulajdonában vannak. Ez a szempont problémát jelent. Hogyan adhat hozzá a bevásárlókosár mikroszolgáltatás egy terméket a felhasználó bevásárlókosarahoz, ha nem rendelkezik termék- és díjszabási adatokkal az adatbázisában?
A 4. fejezetben tárgyalt egyik lehetőség egy közvetlen HTTP-hívás a bevásárlókosárból a katalógusba és a mikroszolgáltatások díjszabására. A 4. fejezetben azonban azt mondtuk, hogy a szinkron HTTP-hívások összekapcsolják a mikroszolgáltatásokat , csökkentve az önállóságukat és csökkentik az architekturális előnyöket.
Az egyes szolgáltatásokhoz külön bejövő és kimenő üzenetsorokat tartalmazó kérés-válasz mintát is implementálhatunk. Ez a minta azonban bonyolult, és a kérések és válaszüzenetek összehangolásához infrastruktúrára van szükség. Bár leválasztja a háttérbeli mikroszolgáltatás-hívásokat, a hívószolgáltatásnak szinkron módon várnia kell a hívás befejezésére. Hálózati torlódás, átmeneti hibák vagy túlterhelt mikroszolgáltatások, és hosszú ideig futó, sőt sikertelen műveleteket eredményezhetnek.
Ehelyett a szolgáltatásközi függőségek eltávolításának széles körben elfogadott mintája a Materialized View Pattern(Materialized View Pattern), amely az 5–4. ábrán látható.
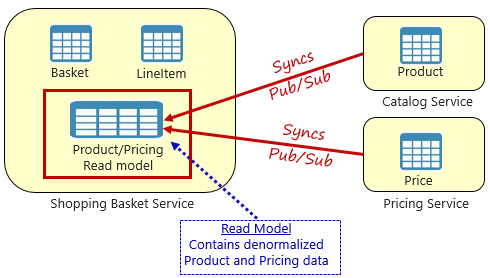
Ábra 5-4. Materializált Nézet Minta
Ezzel a mintával egy helyi adattáblát (más néven olvasási modellt) helyez el a bevásárlókosár szolgáltatásban. Ez a táblázat a termékből és a díjszabási mikroszolgáltatásokból szükséges adatok denormalizált másolatát tartalmazza. Ha az adatokat közvetlenül a bevásárlókosár mikroszolgáltatásba másolja, nincs szükség költséges szolgáltatásközi hívásokra. A szolgáltatás helyi adataival javíthatja a szolgáltatás válaszidejét és megbízhatóságát. Emellett az adatok saját másolatával rugalmasabbá teszi a bevásárlókosaras szolgáltatást. Ha a katalógusszolgáltatás elérhetetlenné válik, az nem lenne közvetlenül hatással a bevásárlókosár szolgáltatásra. Bevásárlókosár továbbra is használhatja saját áruházának adatait.
E megközelítés hátránya, hogy ezzel mostantól duplikált adatok lesznek a rendszerben. A natív felhőbeli rendszerekben azonban az adatok stratégiailag duplikálása bevált gyakorlat, és nem tekinthető mintaelkülönítésnek vagy rossz gyakorlatnak. Ne feledje, hogy egy és csak egy szolgáltatás rendelkezhet adatkészlettel, és rendelkezhet felette hatáskörrel. A rekordrendszer frissítésekor szinkronizálnia kell az olvasási modelleket. A szinkronizálást általában aszinkron üzenetküldéssel valósítják meg közzétételi/előfizetési mintával, ahogyan az 5.4. ábrán látható.
Elosztott tranzakciók
Bár az adatok mikroszolgáltatások közötti lekérdezése nehéz, a tranzakciók több mikroszolgáltatásban való implementálása még összetettebb. Nem szabad alábecsülni az adatok következetességének fenntartásával kapcsolatos kihívást a különböző mikroszolgáltatások független adatforrásaiban. Az elosztott tranzakciók hiánya a natív felhőbeli alkalmazásokban azt jelenti, hogy az elosztott tranzakciókat programozott módon kell kezelnie. Az azonnali konzisztencia világából a végleges konzisztencia világára válthat.
Az 5–5. ábra a problémát mutatja.
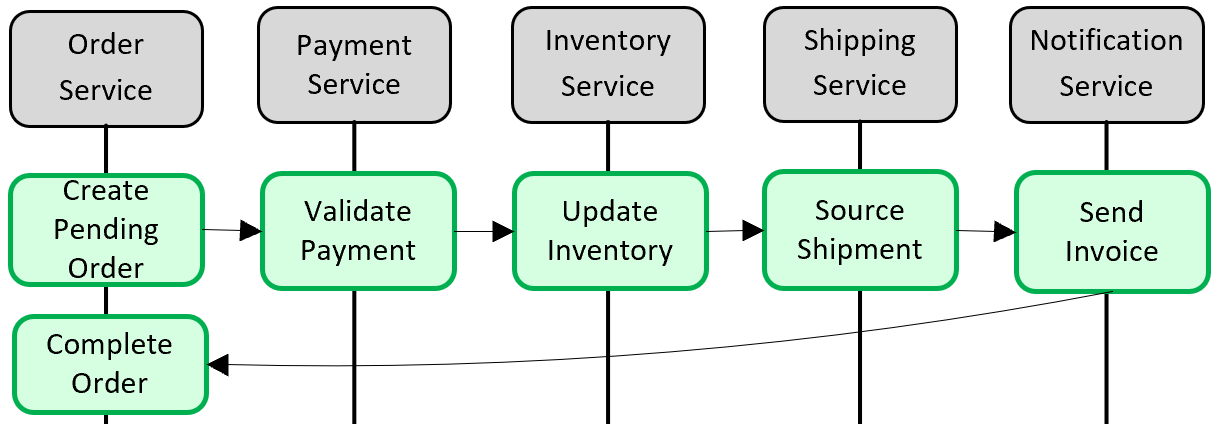
5–5. ábra. Tranzakció megvalósítása mikroszolgáltatások között
Az előző ábrán öt független mikroszolgáltatás vesz részt egy rendelést létrehozó elosztott tranzakcióban. Minden mikroszolgáltatás saját adattárat tart fenn, és helyi tranzakciót valósít meg a tárolóhoz. A rendelés létrehozásához az egyes mikroszolgáltatások helyi tranzakciójának sikeresnek kell lennie, vagy mindenkinek le kell állítania és vissza kell állítania a műveletet. Bár az egyes mikroszolgáltatásokban beépített tranzakciós támogatás érhető el, az elosztott tranzakciók nem támogatottak, amelyek mind az öt szolgáltatásra kiterjednek az adatok konzisztenssége érdekében.
Ehelyett ezt az elosztott tranzakciót programozott módon kell létrehoznia.
Az elosztott tranzakciós támogatás hozzáadásának népszerű mintája a Saga minta. A helyi tranzakciók programozott csoportosításával és egymás után történő meghívásával valósítható meg. Ha valamelyik helyi tranzakció meghiúsul, a Saga megszakítja a műveletet, és kompenzáló tranzakciókat hív meg. A kompenzáló tranzakciók visszavonják az előző helyi tranzakciók módosításait, és visszaállítják az adatkonzisztenciát. Az 5–6. ábra egy sikertelen tranzakciót mutat be a Saga mintával.
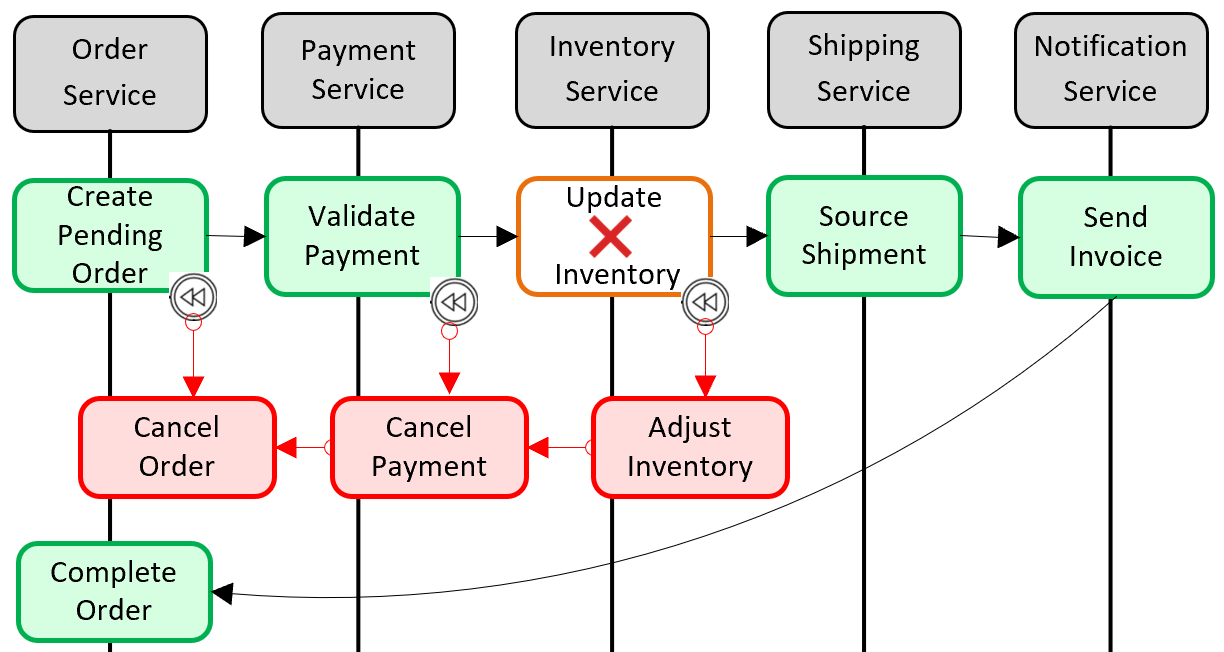
5–6. ábra. Tranzakció visszagördülése
Az előző ábrán az Inventory frissítése művelet meghiúsult az Inventory mikroszolgáltatásban. A Saga egy kompenzáló tranzakciókészletet hív meg (pirossal), hogy módosítsa a leltár számát, törölje a fizetést és a megrendelést, és az egyes mikroszolgáltatások adatait konzisztens állapotba állítsa vissza.
A sagamintákat általában kapcsolódó események sorozataként vagy kapcsolódó parancsok halmazaként koreografálják. A 4. fejezetben a szolgáltatásösszesítő mintával foglalkoztunk, amely egy orchestrált saga implementáció alapja lenne. Az Azure Service Bus és az Azure Event Grid témaköreivel együtt az eseményekkel is foglalkoztunk, amelyek a koreografált saga implementációjának alapjai lennének.
Nagy mennyiségű adat
A nagy felhőbeli natív alkalmazások gyakran támogatják a nagy mennyiségű adatkövetelményeket. Ezekben a forgatókönyvekben a hagyományos adattárolási technikák szűk keresztmetszeteket okozhatnak. A nagy léptékben üzembe helyezhető összetett rendszerek esetében a parancs- és lekérdezési felelősség elkülönítése (CQRS) és az Event Sourcing is javíthatja az alkalmazás teljesítményét.
CQRS
A CQRS egy architekturális minta, amely segít maximalizálni a teljesítményt, a méretezhetőséget és a biztonságot. A minta elválasztja az adatokat olvasó műveleteket az adatokat író műveletektől.
Normál forgatókönyvek esetén ugyanazt az entitásmodellt és adatadattár-objektumot használják olvasási és írási műveletekhez is .
A nagy mennyiségű adatforgatókönyv esetén előnyös lehet külön modellek és adattáblák alkalmazása az olvasásokhoz és írásokhoz. A teljesítmény javítása érdekében az olvasási művelet lekérdezheti az adatok nagy mértékben denormalizált ábrázolását, hogy elkerülje a költséges ismétlődő táblaillesztéseket és táblazárolásokat. A parancsként ismert írási művelet az adatok teljesen normalizált ábrázolására frissülne, amely garantálja a konzisztenciát. Ezután implementálnia kell egy mechanizmust, amely mindkét ábrázolás szinkronizálását lehetővé teszi. Az írási tábla módosításakor általában egy olyan eseményt tesz közzé, amely replikálja a módosítást az olvasási táblára.
Az 5–7. ábra a CQRS-minta implementációját mutatja be.
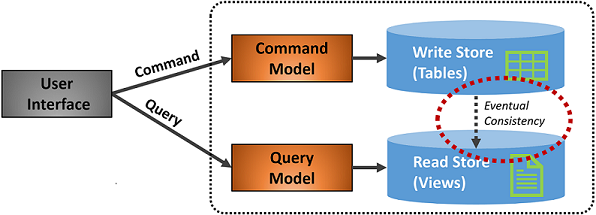
5-7. ábra. A CQRS implementálása
Az előző ábrán külön parancs- és lekérdezésmodellek implementálódnak. A rendszer minden adatírási műveletet az írási tárolóba ment, majd propagálja az olvasási tárolóba. Ügyeljen arra, hogy az adatterjesztési folyamat a végleges konzisztencia elvén működjön. Az olvasási modell végül szinkronizálva lesz az írási modellel, de a folyamat némi késéssel járhat. A végleges konzisztenciát a következő szakaszban tárgyaljuk.
Ez az elkülönítés lehetővé teszi az olvasási és írási skálázást egymástól függetlenül. Az olvasási műveletek lekérdezésekhez optimalizált sémát használnak, míg az írások frissítésekre optimalizált sémát használnak. Az olvasási lekérdezések a denormalizált adatokon mennek át, míg az összetett üzleti logika alkalmazható az írási modellre. Emellett szigorúbb biztonsági intézkedéseket alkalmazhat az írási műveletekre, mint az olvasási műveletekre.
A CQRS implementálása javíthatja a natív felhőszolgáltatások alkalmazásteljesítményét. Ez azonban összetettebb kialakítást eredményez. Ezt az elvet körültekintően és stratégiailag alkalmazza a natív felhőalkalmazás azon szakaszaira, amelyek hasznára lesznek. A CQRS-ről további információt a Microsoft .NET Microservices: Architecture for Containerized .NET Applications című könyvében talál.
Esemény forráskezelése
A nagy mennyiségű adatforgatókönyvek optimalizálásának másik megközelítése az Event Sourcing.
A rendszer általában egy adatentitás aktuális állapotát tárolja. Ha egy felhasználó módosítja például a telefonszámát, az ügyfélrekord frissül az új számmal. Mindig ismerjük az adatentitások aktuális állapotát, de minden frissítés felülírja az előző állapotot.
A legtöbb esetben ez a modell jól működik. A nagy volumenű rendszerekben azonban a tranzakciós zárolás és a gyakori frissítési műveletek többletterhelése hatással lehet az adatbázis teljesítményére, válaszképességére és a méretezhetőség korlátozására.
Az Event Sourcing más megközelítést alkalmaz az adatok rögzítéséhez. Minden olyan művelet, amely hatással van az adatokra, egy eseménytárolóban marad. Az adatrekordok állapotának frissítése helyett minden módosítást hozzáfűzünk a korábbi események szekvenciális listájához – hasonlóan a könyvelői főkönyvhez. Az Eseménytár lesz az adatok rekordrendszere. Különböző materializált nézetek propagálására szolgál egy mikroszolgáltatás korlátolt környezetében. Az 5.8. ábra a mintát mutatja.
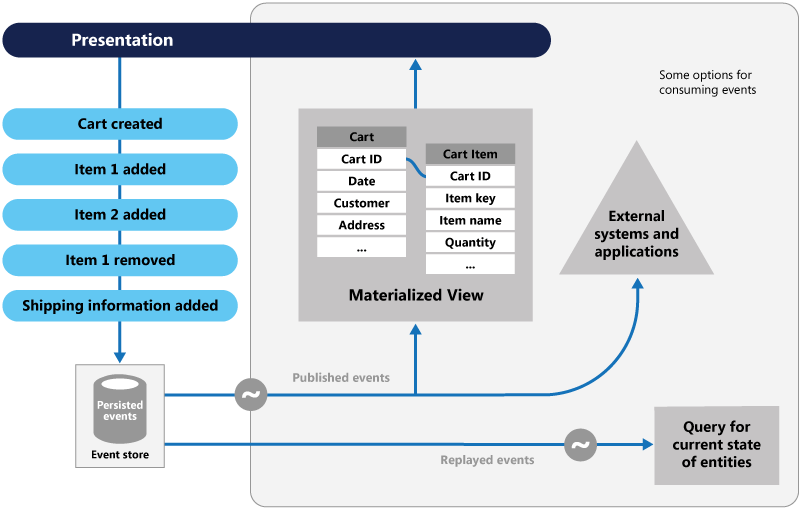
5-8. ábra. Eseményalapú tárolás (Event Sourcing)
Az előző ábrán figyelje meg, hogy a felhasználó bevásárlókocsijának egyes bejegyzései (kék színnel) hozzá lesznek fűzve egy mögöttes eseménytárolóhoz. A szomszédos materializált nézetben a rendszer az aktuális állapotot az egyes bevásárlókocsikhoz társított összes esemény ismétlésével jeleníti meg. Ez a nézet vagy az olvasási modell ezután ismét megjelenik a felhasználói felületen. Az események integrálhatók külső rendszerekkel és alkalmazásokkal is, vagy lekérdezhetők az entitás aktuális állapotának meghatározásához. Ezzel a módszerrel előzményeket tart fenn. Nem csak az entitás aktuális állapotát ismeri, hanem azt is, hogy hogyan érte el ezt az állapotot.
Mechanikai szempontból az eseményforrás leegyszerűsíti az adatírási modellt. Nincsenek frissítések vagy törlések. Az egyes adatbejegyzések nem módosítható eseményként való hozzáfűzése minimálisra csökkenti a relációs adatbázisokhoz társított versengést, zárolást és egyidejűségi ütközéseket. A materializált nézetmintával rendelkező olvasási modellek segítségével leválaszthatja a nézetet az írási modellről, és kiválaszthatja a legjobb adattárat az alkalmazás felhasználói felületének igényeinek optimalizálásához.
Az ebben a mintában vegyünk figyelembe egy olyan adattárat, amely közvetlenül támogatja az eseményforrás-kezelést. Az Azure Cosmos DB, a MongoDB, a Cassandra, a CouchDB és a RavenDB jó jelöltek.
Ez a minták és technológiák esetében úgy történhet meg, hogy szükség szerint és stratégiailag implementálják. Bár az esemény-forráskezelés nagyobb teljesítményt és méretezhetőséget biztosít, az összetettség és a tanulási görbe rovására megy.
Dolgozzon együtt velünk a GitHubon
A tartalom forrása a GitHubon található, ahol létrehozhat és áttekinthet problémákat és lekéréses kérelmeket is. További információért tekintse meg a közreműködői útmutatónkat.