Jegyzet
Az oldalhoz való hozzáférés engedélyezést igényel. Próbálhatod be jelentkezni vagy könyvtárat váltani.
Az oldalhoz való hozzáférés engedélyezést igényel. Megpróbálhatod a könyvtár váltását.
A Microsoft Fabric lehetővé teszi a felhasználók számára a gépi tanulási modellek üzembe helyezése a méretezhető PREDICT függvénnyel. Ez a függvény támogatja a kötegelt pontozást bármely számítási motorban. A felhasználók közvetlenül egy Microsoft Fabric-jegyzetfüzetből vagy egy adott ML-modell elemlapjáról hozhatnak létre kötegelt előrejelzéseket.
Ebben a cikkben megtudhatja, hogyan alkalmazhatja a PREDICT-t úgy, hogy saját maga ír kódot, vagy egy irányított felhasználói felület használatával, amely kezeli a kötegelt pontozást.
Előfeltételek
Microsoft Fabric-előfizetés lekérése. Vagy regisztráljon egy ingyenes Microsoft Fabric-próbaverzióra.
Váltson Fabricre a kezdőlap bal alsó részén található élménykapcsolóval.

Korlátozások
- A PREDICT függvény jelenleg támogatott az ML-modell ezen korlátozott ízeihez:
- CatBoost
- Keras
- LightGBM
- ONNX
- Próféta
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- A PREDICT megköveteli , hogy az ML-modelleket MLflow formátumban mentse az aláírásukkal együtt.
- A PREDICT nem támogatja a több tenzoros bemenetekkel vagy kimenetekkel rendelkező ML-modelleket
A PREDICT hívása jegyzetfüzetből
A PREDICT támogatja az MLflow-csomagba csomagolt modelleket a Microsoft Fabric beállításjegyzékében. Ha már betanított és regisztrált ml-modell található a munkaterületen, ugorjon a 2. lépésre. Ha nem, az 1. lépés mintakódot biztosít, amely végigvezeti egy logisztikai regressziós mintamodell betanításán. Ezzel a modellel kötegelt előrejelzéseket hozhat létre az eljárás végén.
Gépi tanulási modell betanítása és regisztrálása az MLflow-jal. A következő kódminta az MLflow API használatával hoz létre egy gépi tanulási kísérletet, majd elindít egy MLflow-futtatást egy scikit-learn logisztikai regressziós modellhez. A modellverzió ezután a Microsoft Fabric beállításjegyzékében lesz tárolva és regisztrálva. Az ml-modellek scikit-learn erőforrással való betanításával kapcsolatos további információkért és saját kísérletek nyomon követéséért látogasson el az ML-modellek betanítására.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Töltse be a tesztadatokat Spark DataFrame-ként. Ha az előző lépésben betanított ML-modellel köteg-előrejelzéseket szeretne létrehozni, akkor Spark DataFrame formájában kell tesztelni az adatokat. Az alábbi kódban cserélje le a változó értékét a
testsaját adataira.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Hozzon létre egy objektumot
MLFlowTransformeraz ML-modell következtetéshez való betöltéséhez. Ha egy objektumotMLFlowTransformerszeretne létrehozni kötegelt előrejelzések létrehozásához, hajtsa végre az alábbi műveleteket:- adja meg a
testmodell bemeneteként szükséges DataFrame-oszlopokat (ebben az esetben az összeset) - válasszon nevet az új kimeneti oszlopnak (ebben az esetben
predictions) - adja meg az előrejelzések létrehozásához megfelelő modellnevet és modellverziót.
Ha saját ml-modellt használ, cserélje le a bemeneti oszlopok, a kimeneti oszlop neve, a modell neve és a modellverzió értékeit.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- adja meg a
Előrejelzések létrehozása a PREDICT függvény használatával. A PREDICT függvény meghívásához használja a Transformer API-t, a Spark SQL API-t vagy egy PySpark felhasználó által definiált függvényt (UDF). A következő szakaszok bemutatják, hogyan hozhat létre kötegelt előrejelzéseket az előző lépésekben definiált tesztadatokkal és ml-modellel a PREDICT függvény meghívásához használt különböző metódusokkal.
PREDICT a Transformer API-val
Ez a kód meghívja a PREDICT függvényt a Transformer API-val. Ha saját ml-modellt használ, cserélje le a modell értékeit, és tesztelje az adatokat.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT a Spark SQL API-val
Ez a kód meghívja a PREDICT függvényt a Spark SQL API-val. Ha saját gépi tanulási modellt használ, cserélje le az értékeket model_namea , model_versionés features a modell nevére, a modell verziójára és a funkcióoszlopokra.
Feljegyzés
A Spark SQL API előrejelzési generáláshoz való használatához továbbra is létre kell hoznia egy MLFlowTransformer objektumot (ahogy a 3. lépésben látható).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
ELŐREJELZÉS felhasználó által definiált függvénnyel
Ez a kód meghívja a PREDICT függvényt egy PySpark UDF használatával. Ha saját ml-modellt használ, cserélje le a modell és a funkciók értékeit.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
PREDICT-kód létrehozása egy ML-modell elemlapjáról
Bármelyik ML-modell elemlapján választhatja ki az alábbi lehetőségek egyikét, hogy elindítsa a kötegelt előrejelzés létrehozását egy adott modellverzióhoz, a PREDICT függvénnyel:
- Kódsablon másolása jegyzetfüzetbe, és a paraméterek testreszabása saját maga
- Irányított felhasználói felület használata PREDICT-kód létrehozásához
Irányított felhasználói felület használata
Az irányított felhasználói felület végigvezeti az alábbi lépéseken:
- A pontozás forrásadatainak kiválasztása
- Az adatok helyes leképezése az ML-modell bemeneteihez
- Adja meg a modell kimeneteinek célhelyét
- Olyan jegyzetfüzet létrehozása, amely a PREDICT használatával hoz létre és tárol előrejelzési eredményeket
Az irányított felület használatához
Keresse meg az adott ML-modellverzió elemoldalát.
A verzió alkalmazása legördülő listában válassza a Modell alkalmazása varázslóban lehetőséget.
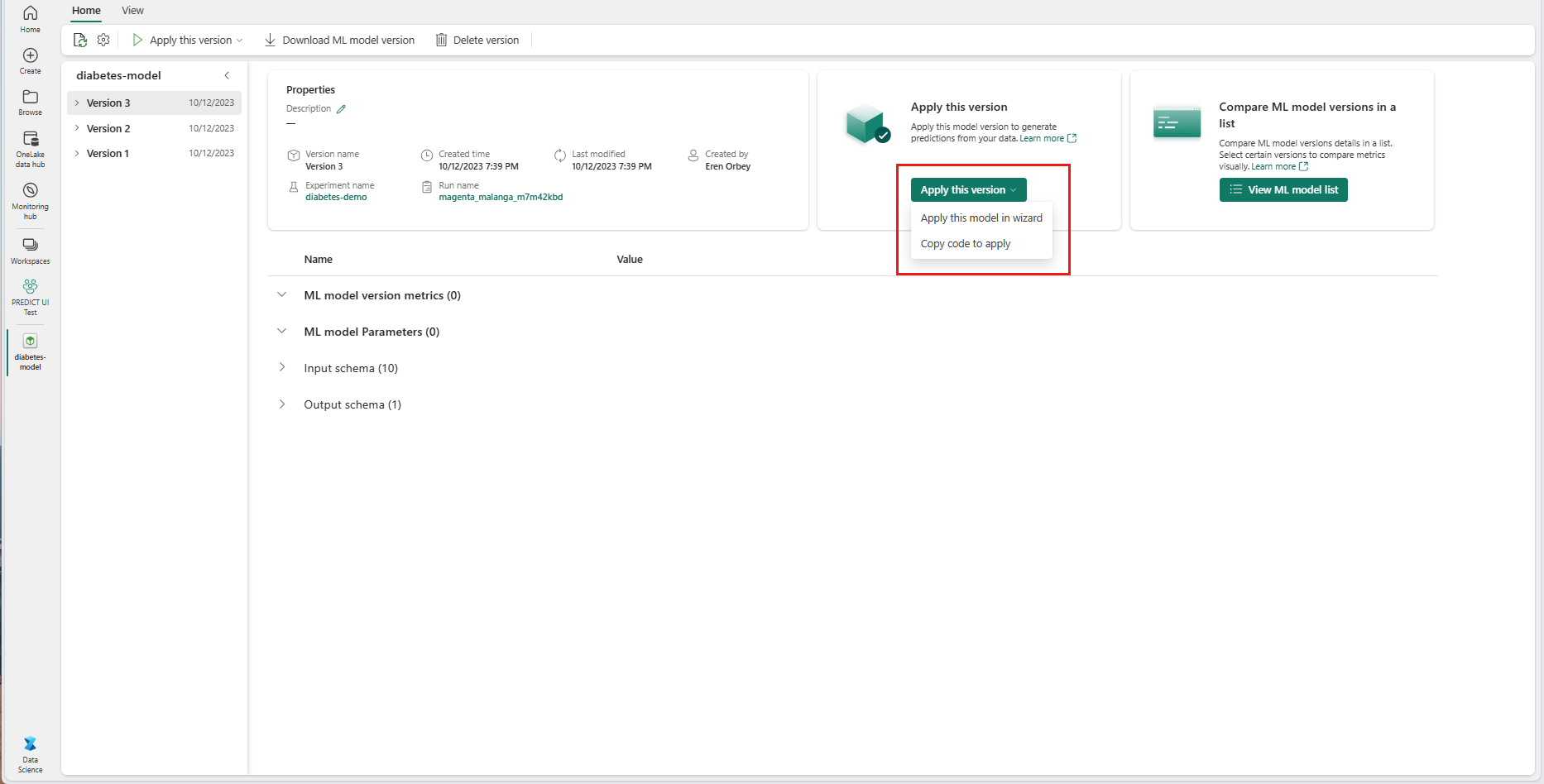
A "Bemeneti tábla kiválasztása" lépésben megnyílik az "ML-modell előrejelzéseinek alkalmazása" ablak.
Válasszon ki egy bemeneti táblát az aktuális munkaterület egyik tóépületéből.
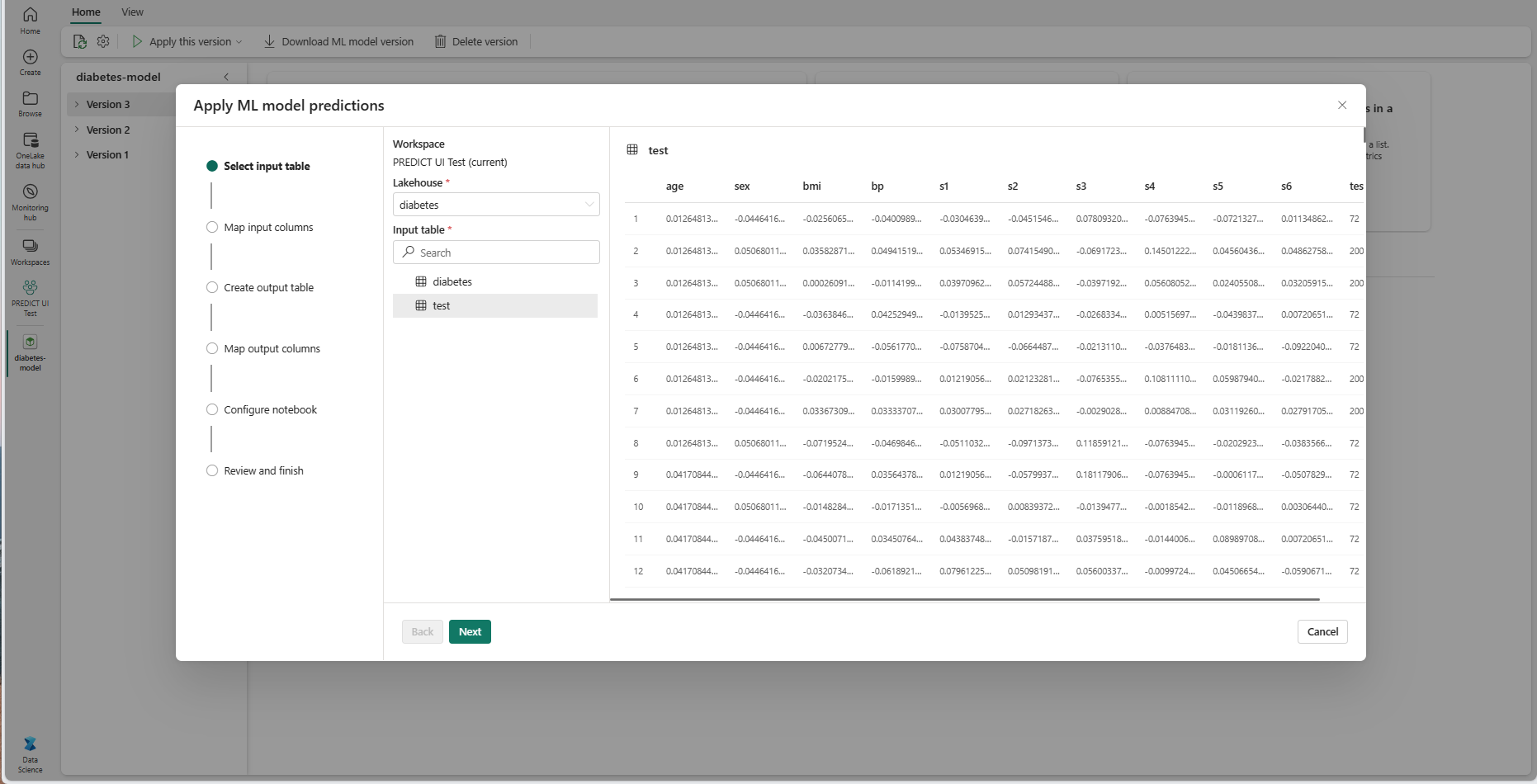
A Tovább gombra kattintva lépjen a "Bemeneti oszlopok leképezése" lépésre.
Az oszlopnevek leképezése a forrástáblából az ML-modell bemeneti mezőibe, amelyeket a rendszer a modell aláírásából von le. Meg kell adnia egy bemeneti oszlopot a modell összes szükséges mezőjéhez. Emellett a forrásoszlop adattípusainak meg kell egyeznie a modell várt adattípusával.
Tipp.
A varázsló előre feltölti ezt a leképezést, ha a bemeneti táblaoszlopok neve megegyezik az ML-modell aláírásában naplózott oszlopnevekkel.
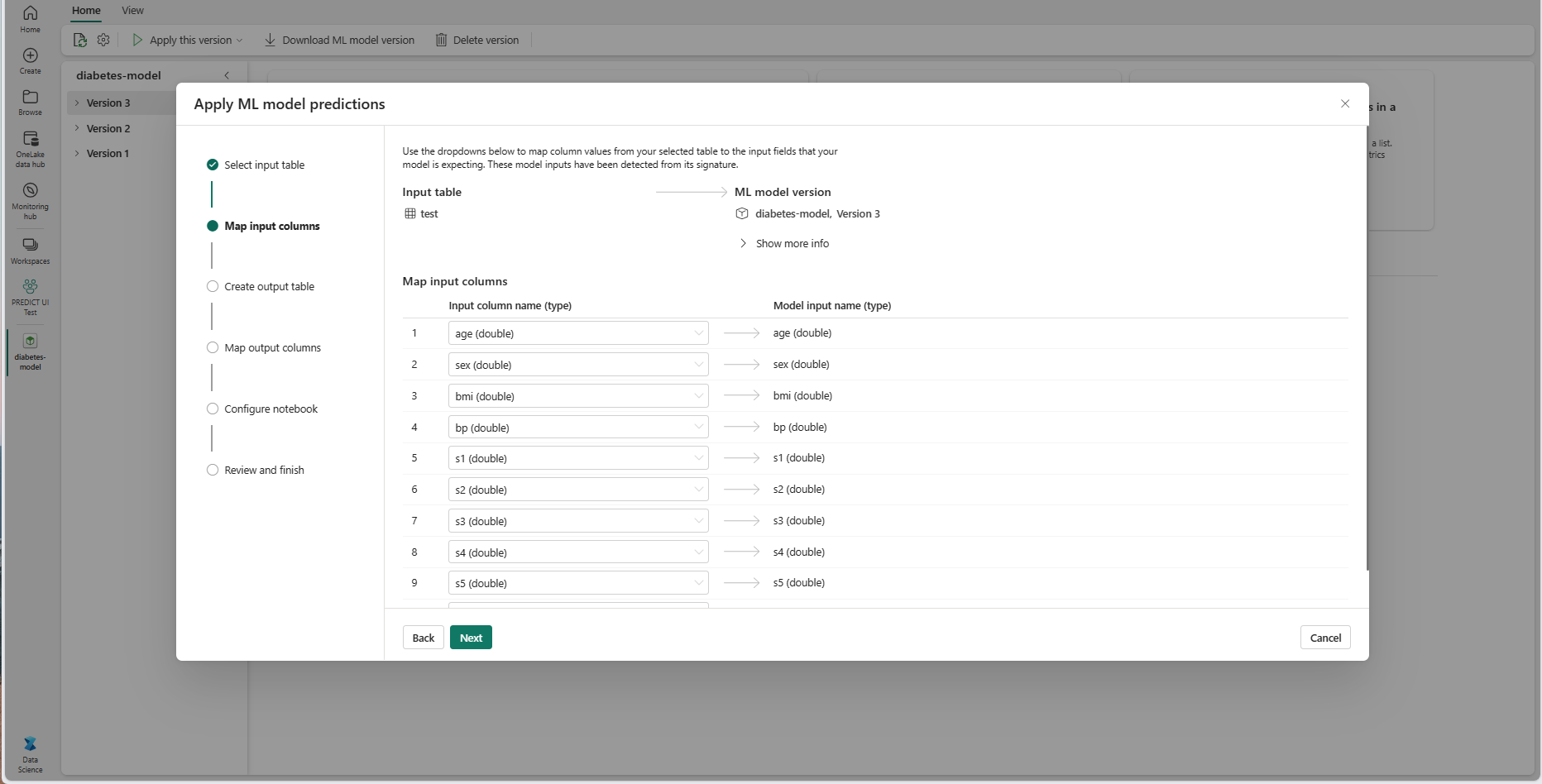
Válassza a Tovább lehetőséget a "Kimeneti tábla létrehozása" lépéshez.
Adjon nevet egy új táblának az aktuális munkaterület kijelölt tóházában. Ez a kimeneti tábla tárolja az ML-modell bemeneti értékeit, és hozzáfűzi az előrejelzési értékeket a táblához. Alapértelmezés szerint a kimeneti tábla ugyanabban a tóházban jön létre, mint a bemeneti tábla. Módosíthatja a céltóházat.
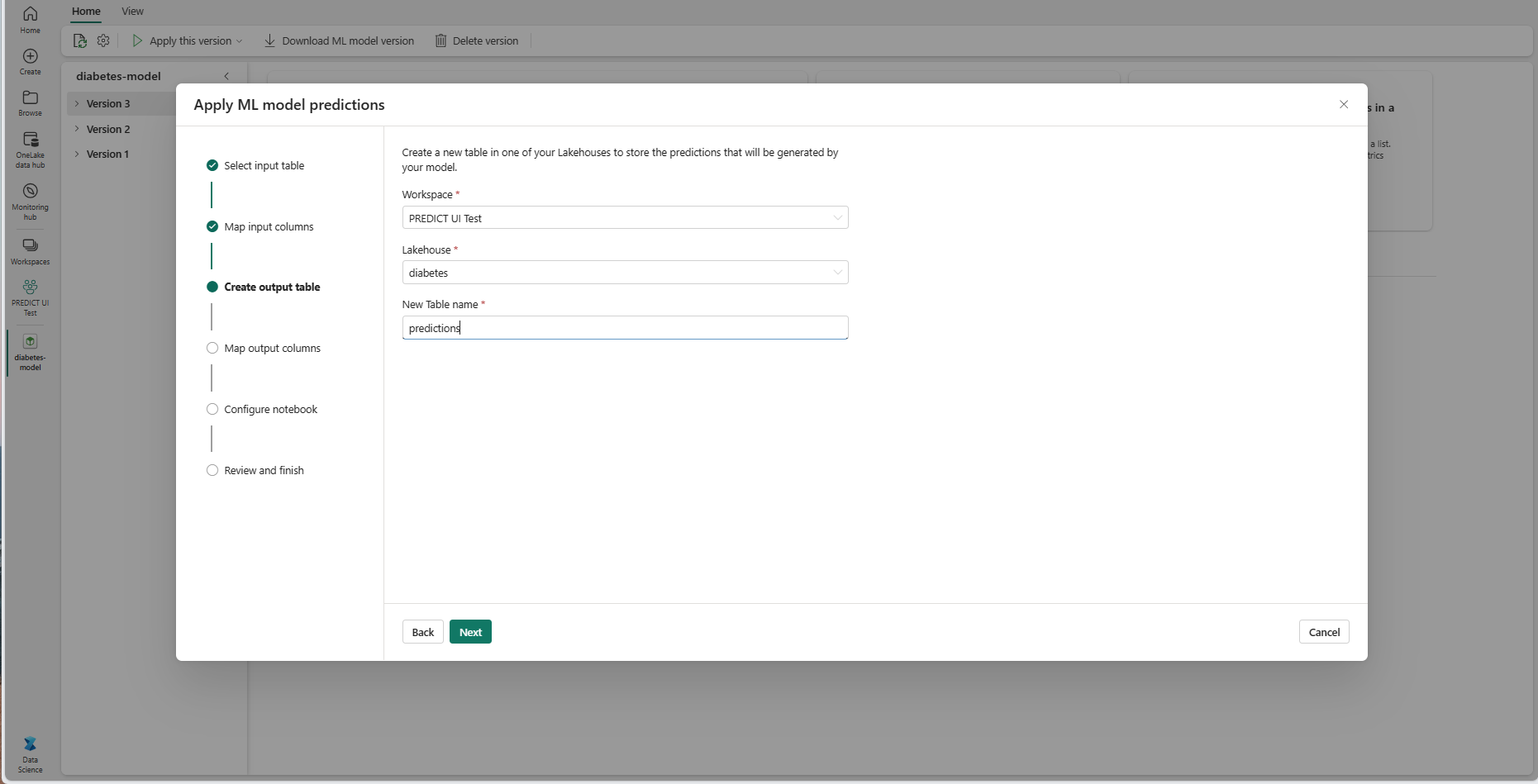
A Tovább gombra kattintva lépjen a "Kimeneti oszlopok leképezése" lépésre.
A megadott szövegmezőkkel nevezze el az ml-modell előrejelzéseit tároló kimeneti tábla oszlopait.
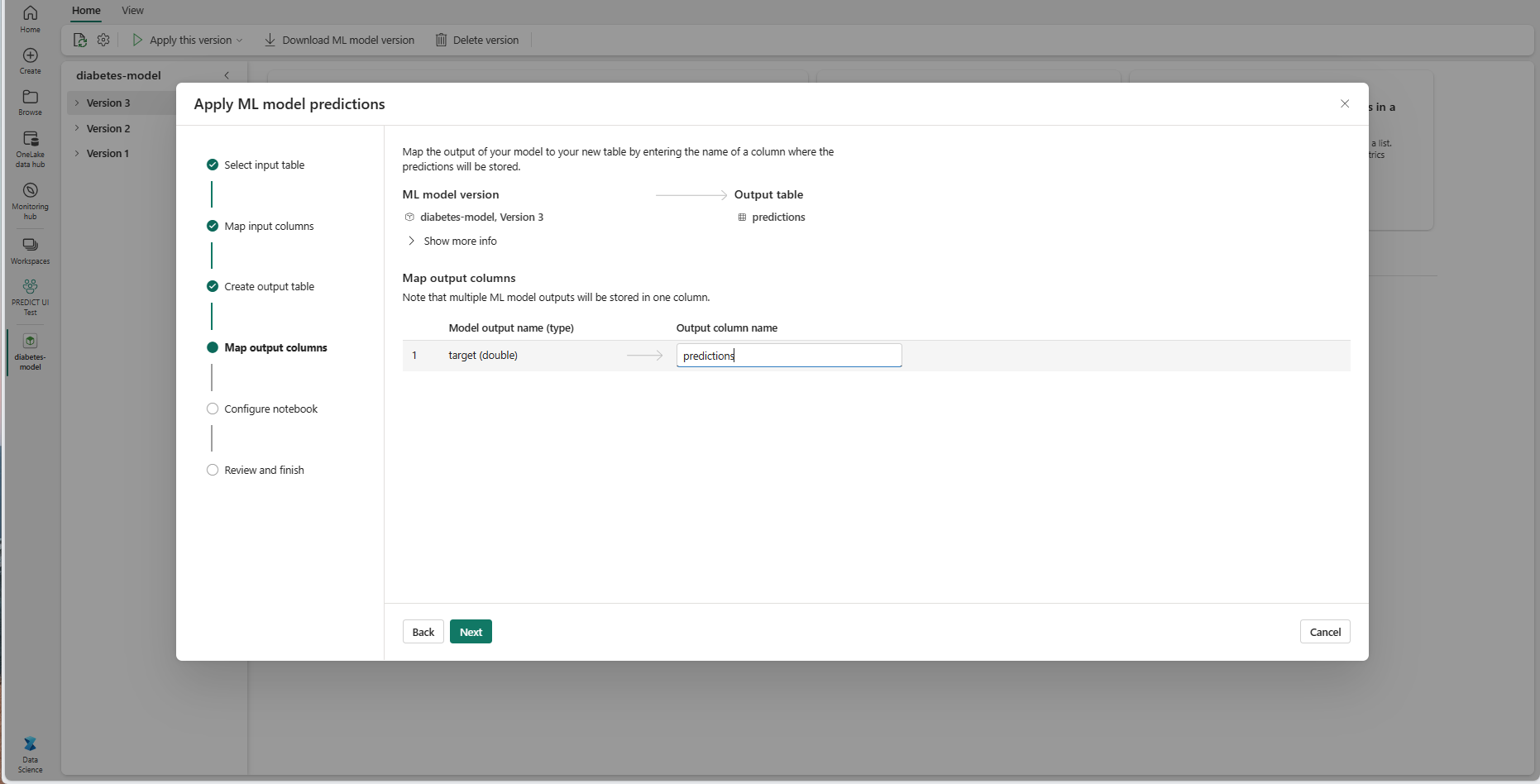
Válassza a Tovább lehetőséget a "Jegyzetfüzet konfigurálása" lépéshez.
Adja meg a létrehozott PREDICT-kódot futtató új jegyzetfüzet nevét. A varázsló ekkor megjeleníti a létrehozott kód előnézetét. Ha szeretné, átmásolhatja a kódot a vágólapra, és beillesztheti egy meglévő jegyzetfüzetbe.
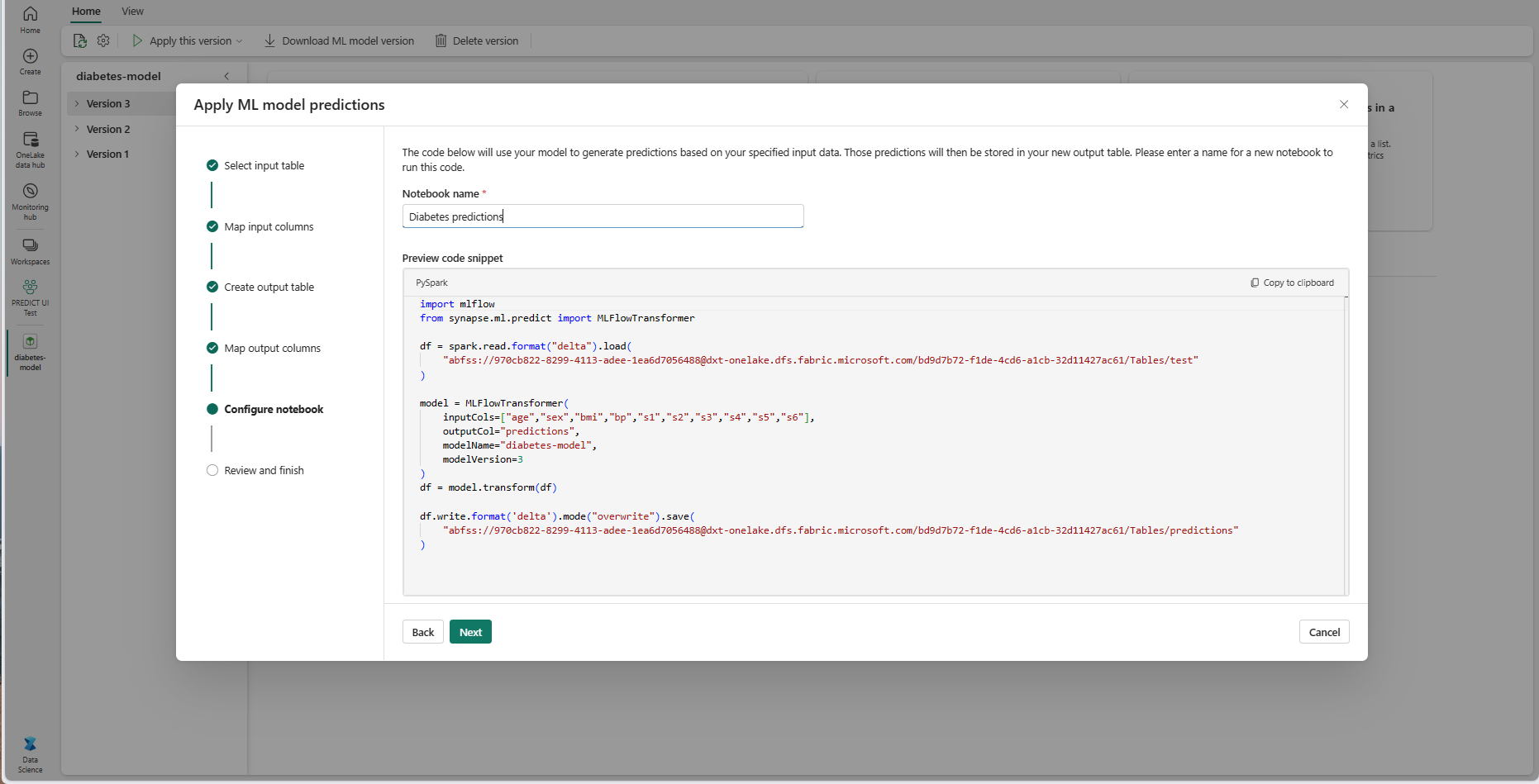
Válassza a Tovább lehetőséget a "Véleményezés és befejezés" lépéshez.
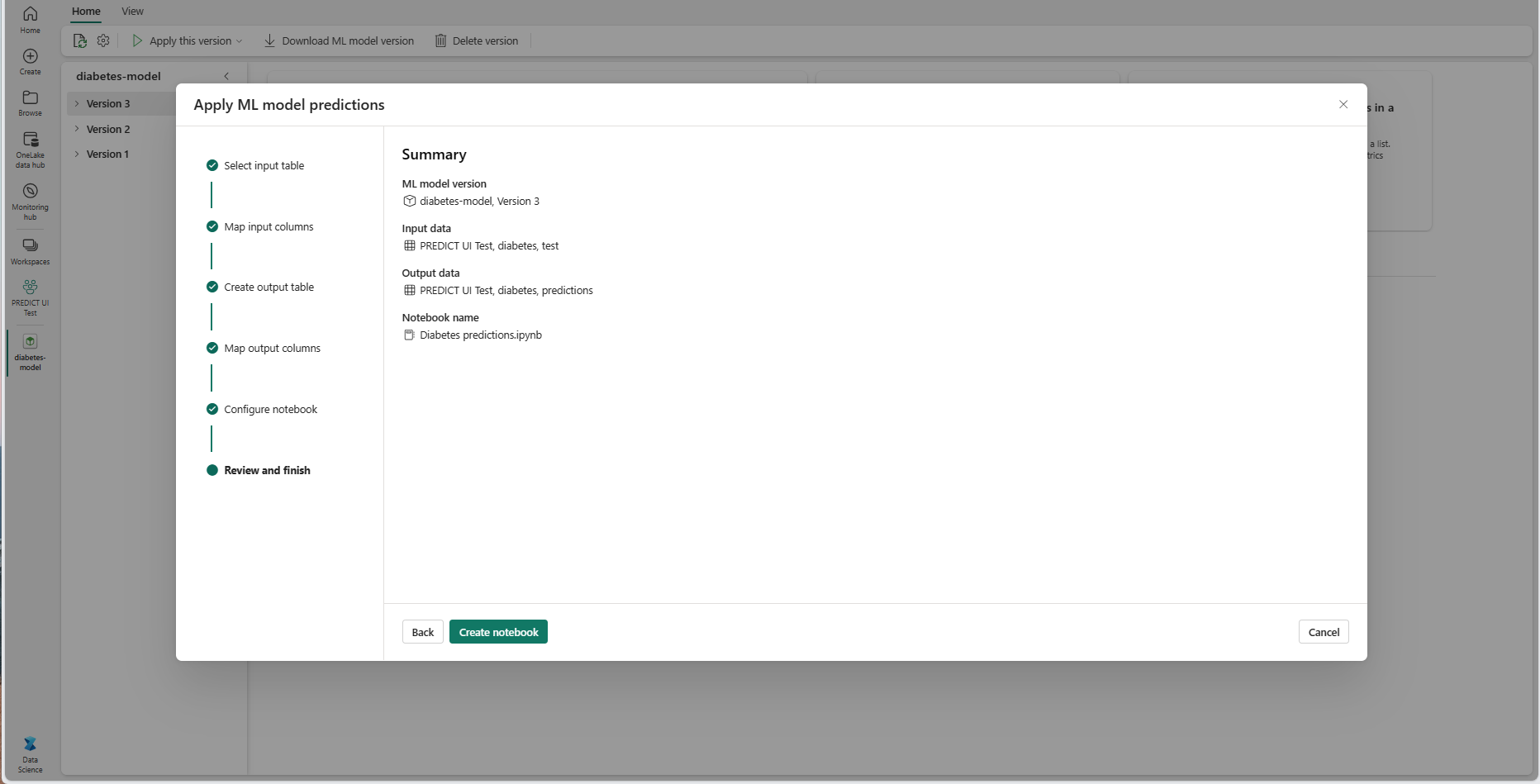
Tekintse át a részleteket az összefoglaló oldalon, és válassza a Jegyzetfüzet létrehozása lehetőséget, ha hozzáadja az új jegyzetfüzetet a létrehozott kóddal a munkaterülethez. A rendszer közvetlenül a jegyzetfüzetbe viszi, ahol futtathatja a kódot az előrejelzések létrehozásához és tárolásához.







Testre szabható kódsablon használata
Kódsablon használata kötegelt előrejelzések létrehozásához:
- Nyissa meg az adott ML-modellverzió elemoldalát.
- Válassza a Verzió alkalmazása legördülő listában az alkalmazáshoz használandó kód másolása lehetőséget. A kijelölés lehetővé teszi egy testre szabható kódsablon másolását.
Ezt a kódsablont beillesztheti egy jegyzetfüzetbe, hogy kötegelt előrejelzéseket hozzon létre az ML-modellel. A kódsablon sikeres futtatásához manuálisan kell lecserélnie a következő értékeket:
-
<INPUT_TABLE>: Az ML-modell bemeneteit biztosító táblázat fájlelérési útja -
<INPUT_COLS>: Oszlopnevek tömbje a bemeneti táblából az ML-modellbe való betöltéshez -
<OUTPUT_COLS>: Az előrejelzéseket tároló kimeneti tábla új oszlopának neve -
<MODEL_NAME>: Az előrejelzés létrehozásához használandó ml-modell neve -
<MODEL_VERSION>: Az előrejelzés létrehozásához használt ml-modell verziója -
<OUTPUT_TABLE>: Az előrejelzéseket tároló tábla fájlútvonala

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)