A Tidyverse használata
A Tidyverse olyan R-csomagok gyűjteménye, amelyeket az adattudósok gyakran használnak a mindennapi adatelemzésekben. Adatimportálási (), adatvizualizációs (readrggplot2), adatmanipulációs (dplyr, tidyrfunkcionális programozási (purrr) és modellépítési (tidymodels) csomagokat tartalmaz. A csomagokat tidyverse úgy tervezték, hogy zökkenőmentesen működjenek együtt, és egységes tervezési alapelveket kövessenek.
A Microsoft Fabric minden futtatókörnyezeti kiadással elosztja a legújabb stabil verziót tidyverse . Importálja és kezdje el használni az ismert R-csomagokat.
Előfeltételek
Microsoft Fabric-előfizetés lekérése. Vagy regisztráljon egy ingyenes Microsoft Fabric-próbaverzióra.
A kezdőlap bal oldalán található élménykapcsolóval válthat a Synapse Adattudomány felületre.

Nyisson meg vagy hozzon létre egy jegyzetfüzetet. A Microsoft Fabric-jegyzetfüzetek használatáról további információt a Microsoft Fabric-jegyzetfüzetek használata című témakörben talál.
Állítsa a nyelvi beállítást SparkR (R) értékre az elsődleges nyelv módosításához.
Csatolja a jegyzetfüzetet egy tóházhoz. A bal oldalon válassza a Hozzáadás lehetőséget egy meglévő tóház hozzáadásához vagy egy tóház létrehozásához.
Terhelés tidyverse
# load tidyverse
library(tidyverse)
Adatimportálás
readr Egy R-csomag, amely olyan négyszögletes adatfájlok olvasására szolgál, mint a CSV, a TSV és a rögzített szélességű fájlok. readr A négyszögletes adatfájlok, például a függvények read_csv() és a CSV- read_tsv() és TSV-fájlok olvasásának gyors és felhasználóbarát módját biztosítja.
Először hozzunk létre egy R data.frame-t, írjuk be a lakehouse-ba a segítségével readr::write_csv() , és olvassuk vissza a következővel readr::read_csv(): .
Feljegyzés
A Lakehouse-fájlok readreléréséhez a File API elérési útját kell használnia. A Lakehouse Explorerben kattintson a jobb gombbal arra a fájlra vagy mappára, amelyhez hozzá szeretne férni, és másolja a Fájl API elérési útját a helyi menüből.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Ezután írjuk az adatokat a Lakehouse-ba a File API elérési útján.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Olvassa el az adatokat a Lakehouse-ból.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Adatok rendezettsége
tidyr egy R-csomag, amely eszközöket biztosít a rendetlen adatok kezeléséhez. A fő függvények tidyr úgy vannak kialakítva, hogy segítsenek az adatok rendezett formátumba alakításában. A rendezett adatoknak van egy adott struktúrája, amelyben minden változó egy oszlop, és minden megfigyelés egy sor, ami megkönnyíti az adatok R-ben és más eszközökben való kezelését.
A benne lévő tidyr függvény például gather() a széles adatok hosszú adatokká alakítására használható. Példa:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Funkcionális programozás
purrr Egy R-csomag, amely javítja az R funkcionális programozási eszközkészletét azáltal, hogy teljes és konzisztens eszközöket biztosít a függvények és vektorok kezeléséhez. A legjobb kiindulópont purrr a függvénycsalád map() , amely lehetővé teszi, hogy sok hurkot helyettesítsen olyan kóddal, amely tömörebb és könnyebben olvasható. Íme egy példa map() egy függvény alkalmazására a lista minden elemére:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Adatkezelés
dplyr Egy R-csomag, amely konzisztens igéket biztosít, amelyek segítenek megoldani a leggyakoribb adatkezelési problémákat, például a nevek alapján változók kiválasztását, az értékeken alapuló esetek kiválasztását, több érték egyetlen összegzésre való csökkentését, valamint a sorok sorrendjének módosítását stb. Íme néhány példa:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Adatvizualizáció
ggplot2 Egy R-csomag, amely deklaratív módon hoz létre grafikus elemeket a grafikus nyelvhelyesség alapján. Adja meg az adatokat, mondja el ggplot2 , hogyan képezheti le a változókat esztétikára, milyen grafikus primitíveket használjon, és gondoskodik a részletekről. Íme néhány példa:
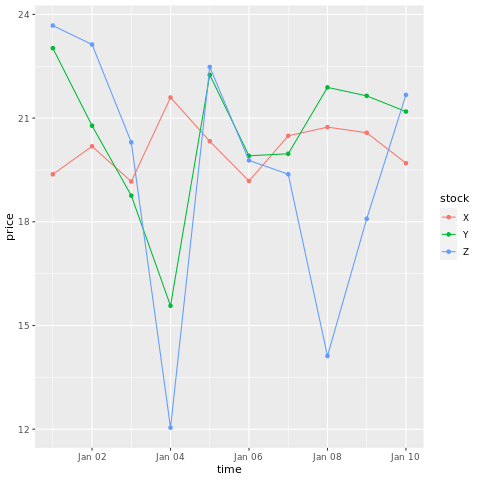
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
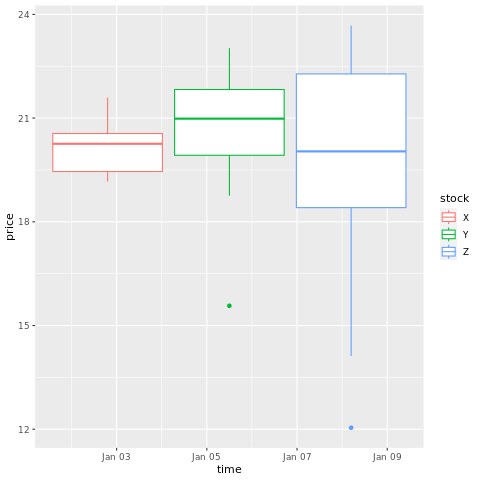
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Modellépítés
A tidymodels keretrendszer az alapelveket használó tidyverse modellezési és gépi tanulási csomagok gyűjteménye. A cikk a modellépítési feladatok széles körének alapvető csomagjait tartalmazza, például rsample a betanítási/tesztelési adathalmaz-minta felosztását, a modell specifikációját, parsnip az adatok előfeldolgozását, recipes a modellezési munkafolyamatokat, tuneworkflows a hiperparaméterek finomhangolását, yardstick a modell kiértékelését, broom a modellkimenetek szabályozását és dials a finomhangolási paraméterek kezelését. A csomagokkal kapcsolatos további információkért látogasson el a tidymodels webhelyére. Íme egy példa egy lineáris regressziós modell létrehozására, amely előrejelzi az autó gallononkénti mérföldjét (mpg) a súlya (wt) alapján:
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
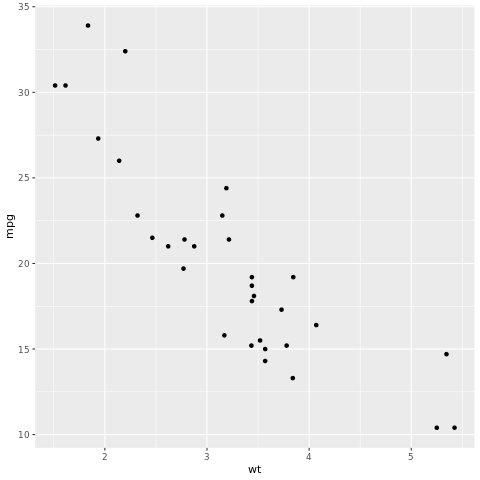
A pontdiagramon a kapcsolat hozzávetőlegesen lineárisnak, a varianciának pedig állandónak tűnik. Próbáljuk ezt lineáris regresszióval modellezni.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Alkalmazza a lineáris regressziós modellt a tesztadatkészlet előrejelzéséhez.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
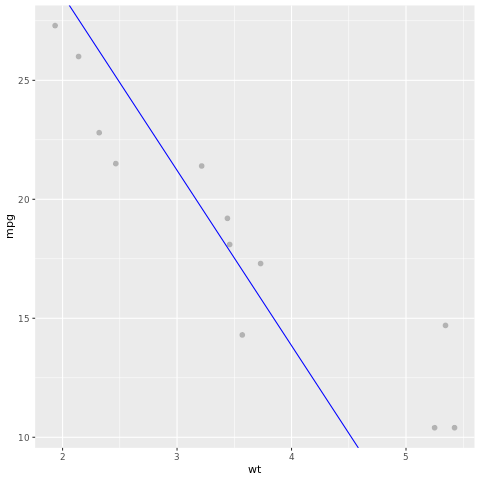
Tekintsük meg a modell eredményét. A modellt vonaldiagramként rajzolhatjuk meg, a teszt pedig az azonos diagramon lévő pontokra alapozza az igazságadatokat. A modell jól néz ki.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: