Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez az oktatóanyag egy Synapse Data Science-munkafolyamat végpontok közötti példáját mutatja be a Microsoft Fabricben. A forgatókönyv létrehoz egy előrejelzési modellt, amely az előzmény értékesítési adatokat használja a termékkategória-értékesítések előrejelzéséhez egy szuperadattárban.
Az előrejelzés kulcsfontosságú eszköz az értékesítésben. Az előzményadatokat és a prediktív módszereket kombinálva betekintést nyújt a jövőbeli trendekbe. Az előrejelzés képes elemezni a múltbeli értékesítéseket a minták azonosítása érdekében. Emellett megtanulhatja a fogyasztói viselkedést a leltár-, termelés- és marketingstratégiák optimalizálásához. Ez a proaktív megközelítés növeli az alkalmazkodóképességet, a válaszkészséget és az általános üzleti teljesítményt egy dinamikus piactéren.
Ez az oktatóanyag az alábbi lépéseket ismerteti:
- Adatok betöltése
- Feltáró adatelemzés használata az adatok megértéséhez és feldolgozásához
- Gépi tanulási modell betanítása nyílt forráskódú szoftvercsomaggal
- Kísérletek nyomon követése az MLflow és a Fabric automatikus naplózási funkciójával
- Mentse a végső gépi tanulási modellt, és készítsen előrejelzéseket
- A modell teljesítményének megjelenítése Power BI-vizualizációkkal
Előfeltételek
Microsoft Fabric-előfizetés lekérése. Vagy regisztráljon egy ingyenes Microsoft Fabric-próbaverzióra.
Jelentkezzen be a Microsoft Fabricbe.
A kezdőlap bal alsó részén található élménykapcsolóval válthat Fabricre.

- Szükség esetén hozzon létre egy Microsoft Fabric-tóházat a Microsoft Fabric-erőforrásban található Tóház létrehozása című cikkben leírtak szerint.
Kövesd nyomon egy jegyzetfüzetben
A jegyzetfüzet követéséhez választhat az alábbi lehetőségek közül:
- Nyissa meg és futtassa a beépített jegyzetfüzetet a Synapse Data Science felületén
- Jegyzetfüzet feltöltése a GitHubról a Synapse Data Science felületére
A beépített jegyzetfüzet megnyitása
Az oktatóanyagot a Sales előrejelzési mintajegyzetfüzete kíséri.
Az oktatóanyaghoz tartozó mintajegyzetfüzet megnyitásához kövesse a Rendszer előkészítése adatelemzési oktatóanyagokhoz című témakör utasításait.
A kód futtatása előtt mindenképpen csatoljon egy lakehouse-t a jegyzetfüzethez .
A jegyzetfüzet importálása a GitHubról
Az AIsample – Superstore Forecast.ipynb jegyzetfüzet ezt az oktatóanyagot kíséri.
Az oktatóanyaghoz mellékelt jegyzetfüzet megnyitásához kövesse a Rendszer előkészítése adatelemzési oktatóanyagokhoz című témakör utasításait a jegyzetfüzet munkaterületre való importálásához.
Ha inkább erről a lapról másolja és illessze be a kódot, létrehozhat egy új jegyzetfüzetet.
A kód futtatása előtt mindenképpen csatoljon egy lakehouse-t a jegyzetfüzethez .
1. lépés: Az adatok betöltése
Az adatkészlet 9995 különböző termék értékesítésével rendelkezik. Emellett 21 attribútumot is tartalmaz. A jegyzetfüzet egy Superstore.xlsxnevű fájlt használ. Ez a fájl a következő táblázatstruktúrával rendelkezik:
| Sorazonosító | Rendelés azonosítója | Rendelés dátuma | Szállítási dátum | Szállítási mód | Ügyfélazonosító | Ügyfél neve | Szegmens | Ország | Város | Állam | Irányítószám | Régió | Termékazonosító | Kategória | Sub-Category | Terméknév | Értékesítés | Mennyiség | Árengedmény | Nyereség |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Standard osztály | SO-20335 | Sean O'Donnell | Fogyasztó | Egyesült Államok | Fort Lauderdale | Florida | 33311 | Dél | FUR-TA-10000577 | Bútor | Táblázatok | Bretford CR4500 sorozat karcsú téglalap alakú asztal | 957,5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Standard osztály | Standard osztály | Brosina Hoffman | Fogyasztó | Egyesült Államok | Los Angeles | Kalifornia | 90032 | Nyugat | FUR-TA-10001539 | Bútor | Táblázatok | Chromcraft négyszögletes konferenciatáblák | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Standard osztály | TB-21520 | Tracy Blumstein | Fogyasztó | Egyesült Államok | Philadelphia | Pennsylvania | 19140 | Kelet | OFF-EN-10001509 | Irodaszerek | Borítékok | Poly String Tie borítékok | 3,264 | 2 | 0.2 | 1.1016 |
A következő kódrészlet meghatározott paramétereket határoz meg, így ezt a jegyzetfüzetet különböző adatkészletekkel használhatja:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Töltse le az adathalmazt, és töltse fel a lakehouse-ba
A következő kódrészlet letölti az adathalmaz nyilvánosan elérhető verzióját, majd egy Fabric lakehouse-ban tárolja az adathalmazt:
Fontos
A jegyzetfüzet futtatása előtt hozzá kell adnia egy lakehouse-t. Ellenkező esetben hibaüzenet jelenik meg.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
MLflow-kísérletkövetés beállítása
A Microsoft Fabric a betanítása során automatikusan rögzíti a gépi tanulási modell bemeneti paraméterértékeit és kimeneti metrikáit. Ez kibővíti az MLflow automatikus naplózási képességeit. Ezután a rendszer naplózza az adatokat a munkaterületre, ahol az MLflow API-kkal vagy a munkaterület megfelelő kísérletével érheti el és jelenítheti meg azokat. Az autologginggel kapcsolatos további információkért látogasson el a Microsoft Fabric autologging oldalára.
Ha ki szeretné kapcsolni a Microsoft Fabric automatikus naplózását egy jegyzetfüzet-munkamenetben, hívja meg mlflow.autolog() és állítsa be disable=Trueaz alábbi kódrészletben látható módon:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
A nyers adatok olvasása a lakehouse-ból
Az alábbi kódrészlet nyers adatokat olvas be a lakehouse Fájlok szakaszából. Emellett további oszlopokat is hozzáad a különböző dátumrészekhez. Ugyanezek az információk létrehoznak egy particionált deltatáblát. Mivel a nyers adatok Excel-fájlként lesznek tárolva, a pandas használatával kell elolvasnia őket.
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
2. lépés: Feltáró adatelemzés végrehajtása
Könyvtárak importálása
Az elemzés megkezdése előtt importálja a szükséges kódtárakat:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
A nyers adatok megjelenítése
Az adathalmaz jobb megértéséhez manuálisan tekintse át az adatok egy részhalmazát. A display függvényt használva nyomtassa ki a DataFrame-et. A Chart nézetek egyszerűen vizualizálhatják az adathalmaz részhalmazait:
display(df)
Ez az oktatóanyag egy olyan jegyzetfüzetet tartalmaz, amely elsősorban a kategóriaértékesítési előrejelzésekre Furniture összpontosít. Ez a megközelítés felgyorsítja a számítást, és segít a modell teljesítményének megjelenítésében. Ez a jegyzetfüzet azonban adaptálható technikákat használ. Ezeket a technikákat kiterjesztheti más termékkategóriák értékesítésének előrejelzésére. A következő kódrészlet a termékkategóriaként van kiválasztva Furniture :
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Az adatok előfeldolgozása
A valós üzleti forgatókönyveknek gyakran három különböző kategóriában kell előrejeleznie az értékesítéseket:
- Adott termékkategória
- Adott ügyfélkategória
- A termékkategória és az ügyfélkategória adott kombinációja
Az alábbi kódrészlet eltávolítja a felesleges oszlopokat az adatok előfeldolgozásához. Nem kell néhány oszlop (Row ID, Order ID,Customer ID, és Customer Name), mert nincs jelentőségük. Egy adott termékkategóriára (Furniture) vonatkozóan szeretnénk előrejelzni az összes értékesítést az állam és a régió között. Ezért elvethetjük a State, Region, Country, Cityés Postal Code oszlopokat. Előfordulhat, hogy egy adott hely vagy kategória értékesítéseinek előrejelzéséhez ennek megfelelően kell módosítanunk az előfeldolgozási lépést.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Az adathalmaz napi rendszerességgel van strukturálva. Újra kell adnunk az Order Date oszlopot, mert egy modellt szeretnénk létrehozni, amely havi rendszerességgel előrejelzést készít az értékesítésekről.
Először csoportosítsa a Furniture kategóriát Order Dateszerint. Ezután számítsa ki az Sales egyes csoportok oszlopának összegét az egyes egyedi Order Date értékek teljes értékesítésének meghatározásához. A Sales oszlop újraszámítása a MS gyakorisággal az adatok hónap szerinti összesítéséhez. Végül számítsa ki az egyes hónapok átlagos értékesítési értékét. A következő kódrészlet az alábbi lépéseket mutatja be:
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
A következő kódrészletben mutassa meg a Order Date hatását a Sales-re a Furniture kategóriában:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
A statisztikai elemzés előtt importálnia kell a statsmodels Python-modult. Ez a modul osztályokat és függvényeket biztosít számos statisztikai modell becsléséhez. Emellett osztályokat és funkciókat is biztosít a statisztikai tesztek és a statisztikai adatok feltárásához. A következő kódrészlet a következő lépést mutatja be:
import statsmodels.api as sm
Statisztikai elemzés végrehajtása
Az idősorok meghatározott időközönként nyomon követik ezeket az adatelemeket, hogy meghatározzák ezeknek az elemeknek a variációját az idősor mintájában:
Szint: Az alapvető összetevő, amely egy adott időszak átlagértékét jelöli
Trend: Azt írja le, hogy az idősor csökken,állandó marad-e, vagy az idő függvényében növekszik-e
Szezonalitás: Az idősor időszakos jelét írja le, és olyan ciklikus előfordulásokat keres, amelyek befolyásolják az idősorok növekvő vagy csökkenő mintáit
Zaj/reziduális: A modell által nem magyarázható idősoradatok véletlenszerű ingadozásait és variabilitását jelenti.
Az alábbi kódrészlet az adathalmaz ezen elemeit jeleníti meg az előfeldolgozás után:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
A diagramok az előrejelzési adatok szezonalitását, trendjeit és zaját írják le. Rögzítheti az alapul szolgáló mintákat, és olyan modelleket fejleszthet, amelyek pontos előrejelzéseket tesznek lehetővé, amelyek rugalmasak a véletlenszerű ingadozásokkal szemben.
3. lépés: A modell betanítása és nyomon követése
Most, hogy már rendelkezik az elérhető adatokkal, határozza meg az előrejelzési modellt. Ebben a jegyzetfüzetben alkalmazza a szezonális exogén tényezőkkel rendelkező autoregresszív integrált mozgóátlag (SARIMAX) előrejelzési modellt. A SARIMAX az autoregresszív (AR) és a mozgó átlag (MA) összetevőket, a szezonális különbségeket és a külső prediktorokat kombinálva pontos és rugalmas előrejelzéseket készít az idősoradatokhoz.
Az MLflow és a Fabric autonaplózását is használja a kísérletek nyomon követésére. Itt töltse be a delta táblát a tóházból. Használhat más deltatáblákat is, amelyek a lakehouse-t tekintik forrásnak. A következő kódrészlet importálja a szükséges kódtárakat:
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Hiperparaméterek hangolása
A SARIMAX figyelembe veszi a normál autoregresszív integrált mozgóátlag (ARIMA) modell paramétereit (p, d, q), és hozzáadja a szezonalitási paramétereket (P, D, Q, s). Ezek a SARIMAX-modell argumentumai a sorrend (p, d, q) és a szezonális sorrend (P, D, Q, s), illetve. Ezért a modell betanítása érdekében először hét paramétert kell hangolnunk.
A rendelés paraméterei:
p: Az AR-összetevő sorrendje, amely az aktuális érték előrejelzéséhez használt idősor korábbi megfigyeléseinek számát jelöli.Ennek a paraméternek általában nem negatív egész számértékkel kell rendelkeznie. A gyakori értékek a
0és a3tartományában találhatók. A konkrét adatjellemzőktől függően azonban magasabb értékek is lehetségesek. A magasabbpérték a modell korábbi értékeinek hosszabb memóriáját jelzi.d: A különbségi sorrend, amely azt jelzi, hogy az idősort hány alkalommal kell különbséget tenni a helyhez kötöttség eléréséhez.Ennek a paraméternek nem negatív egész számértékkel kell rendelkeznie. A gyakori értékek a
0és a2tartományában találhatók. Ad0értéke azt jelenti, hogy az idősor már stacionárius. A nagyobb értékek azt jelzik, hogy a helyhez kötöttséghez szükséges különbségi műveletek száma magasabb.q: Az MA-összetevő sorrendje. Ez a paraméter az aktuális érték előrejelzéséhez használt korábbi fehérzajú hibakifejezések számát jelöli.Ennek a paraméternek nem negatív egész számértékkel kell rendelkeznie. A gyakori értékek a
0tartományba tartoznak3, de bizonyos idősorok magasabb értékeket igényelhetnek. A magasabbqérték azt jelzi, hogy az előrejelzések készítésekor erősebben támaszkodnak a korábbi hibakifejezésekre.
A szezonális rendelés paraméterei:
-
P: Az AR-összetevő szezonális sorrendje, hasonlóan apparaméterhez, de lefedi a szezonális részt -
D: A különbség szezonális sorrendje, hasonló adparaméterhez, de lefedi a szezonális részt -
Q: Az MA-összetevő szezonális sorrendje a paraméterhezqhasonlóan, de a szezonális részre terjed ki -
s: A szezonális ciklusonkénti időlépések száma (például 12 az éves szezonalitással rendelkező havi adatok esetében)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
A SARIMAX más paraméterekkel is rendelkezik:
enforce_stationarity: A modellnek meg kell-e követelnie az idősoradatok stacionaritását a SARIMAX-modell illesztése előtt?Az
enforce_stationarity(alapértelmezett) értékTrueazt jelzi, hogy a SARIMAX-modellnek az idősoradatokon az állomásaritást kell kikényszerítenie. A modell illesztése előtt a SARIMAX modell automatikusan differenciálást alkalmaz az adatokon, hogy azok időben állandóak legyenek, ahogyan azt adésDrendelések meghatározzák. Ez gyakori gyakorlat, mivel számos idősorozat-modell, köztük a SARIMAX is feltételezi, hogy a helyhez kötött adatok.Egy nem stacionárius idősor esetén (például trendeket vagy szezonalitást mutató sorozat), érdemes beállítani
enforce_stationarityTrue, és hagyni, hogy a SARIMAX modell kezelje az eltéréseket a stacionaritás eléréséhez. A helyhez kötött idősorok (például trendek vagy szezonalitás nélküliek) esetében állítsaenforce_stationarityFalseértékre a szükségtelen eltérés elkerülése érdekében.enforce_invertibility: Azt határozza meg, hogy a modell kényszerítse-e az inverzitást a becsült paraméterekre az optimalizálási folyamat során.Az
enforce_invertibility(alapértelmezett) értékTrueazt jelzi, hogy a SARIMAX modellnek inverzitást kell érvényesítenie a becsült paramétereken. Az invertálhatóság biztosítja, hogy egy jól definiált modell, valamint a becsült AR- és MA-együttható az állandóság tartományán belülre húzódjon.Az invertálhatóság kényszerítése segít biztosítani, hogy a SARIMAX modell megfeleljen a stabil idősorozat-modell elméleti követelményeinek. Emellett segít megelőzni a modell becslésével és stabilitásával kapcsolatos problémákat.
Az AR(1) modell az alapértelmezett. Ez a (1, 0, 0)-re utal. Általános gyakorlat azonban a rendelési paraméterek és a szezonális rendelési paraméterek különböző kombinációinak kipróbálása, valamint az adathalmaz modellteljesítményének kiértékelése. A megfelelő értékek idősoronként eltérőek lehetnek.
Az optimális értékek meghatározása gyakran magában foglalja az idősoradatok automatikus javítási függvényének (ACF) és részleges automatikus javítási függvényének (PACF) elemzését. Gyakran használ modellkiválasztási kritériumokat is – például az Akaike információs kritériumot (AIC) vagy a Bayes-féle információs kritériumot (BIC).
Hangolja a hiperparamétereket az alábbi kódrészletben látható módon:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Az előző eredmények kiértékelése után a rendelési paraméterek és a szezonális rendelési paraméterek értékeit is meghatározhatja. A választás order=(0, 1, 1), és seasonal_order=(0, 1, 1, 12), amelyek a legalacsonyabb AIC-értékkel rendelkeznek (például 279,58). Ezekkel az értékekkel taníthatja be a modellt. A következő kódrészlet a következő lépést mutatja be:
A modell betanítása
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Ez a kód a bútorértékesítési adatok idősor-előrejelzését jeleníti meg. A ábrázolt eredmények a megfigyelt adatokat és az egylépéses előrejelzést is megjelenítik, egy árnyékolt régióval a megbízhatósági intervallumhoz. A vizualizációt az alábbi kódrészletek mutatják be:
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Az alábbi kódrészlet a modell teljesítményének felmérésére használja predictions, összehasonlítva a tényleges értékekkel. A predictions_future érték a jövőbeli előrejelzést jelzi.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
4. lépés: A modell pontszáma és az előrejelzések mentése
Az alábbi kódrészlet integrálja a tényleges értékeket az előrejelzett értékekkel egy Power BI-jelentés létrehozásához. Emellett ezeket az eredményeket egy táblázatban tárolja a lakehouse-ban.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
5. lépés: Vizualizáció a Power BI-ban
A Power BI-jelentés 16,58 százalékos átlagos abszolút százalékos hibát (MAPE) mutat. A MAPE metrika határozza meg az előrejelzési módszer pontosságát. Ez az előrejelzett mennyiségek pontosságát jelöli a tényleges mennyiségekkel összehasonlítva.
A MAPE egy egyszerű metrika. A 10% MAPE azt jelzi, hogy az előrejelzett értékek és a tényleges értékek közötti átlagos eltérés 10%, függetlenül attól, hogy az eltérés pozitív vagy negatív volt-e. A kívánatos MAPE-értékek szabványai iparágonként eltérőek.
A gráf világoskék vonala a tényleges értékesítési értékeket jelöli. A sötétkék vonal az előrejelzett értékesítési értékeket jelöli. A tényleges és az előrejelzett értékesítések összehasonlítása azt mutatja, hogy a modell 2023 első hat hónapjában hatékonyan előrejelzi a Furniture kategória értékesítéseit.
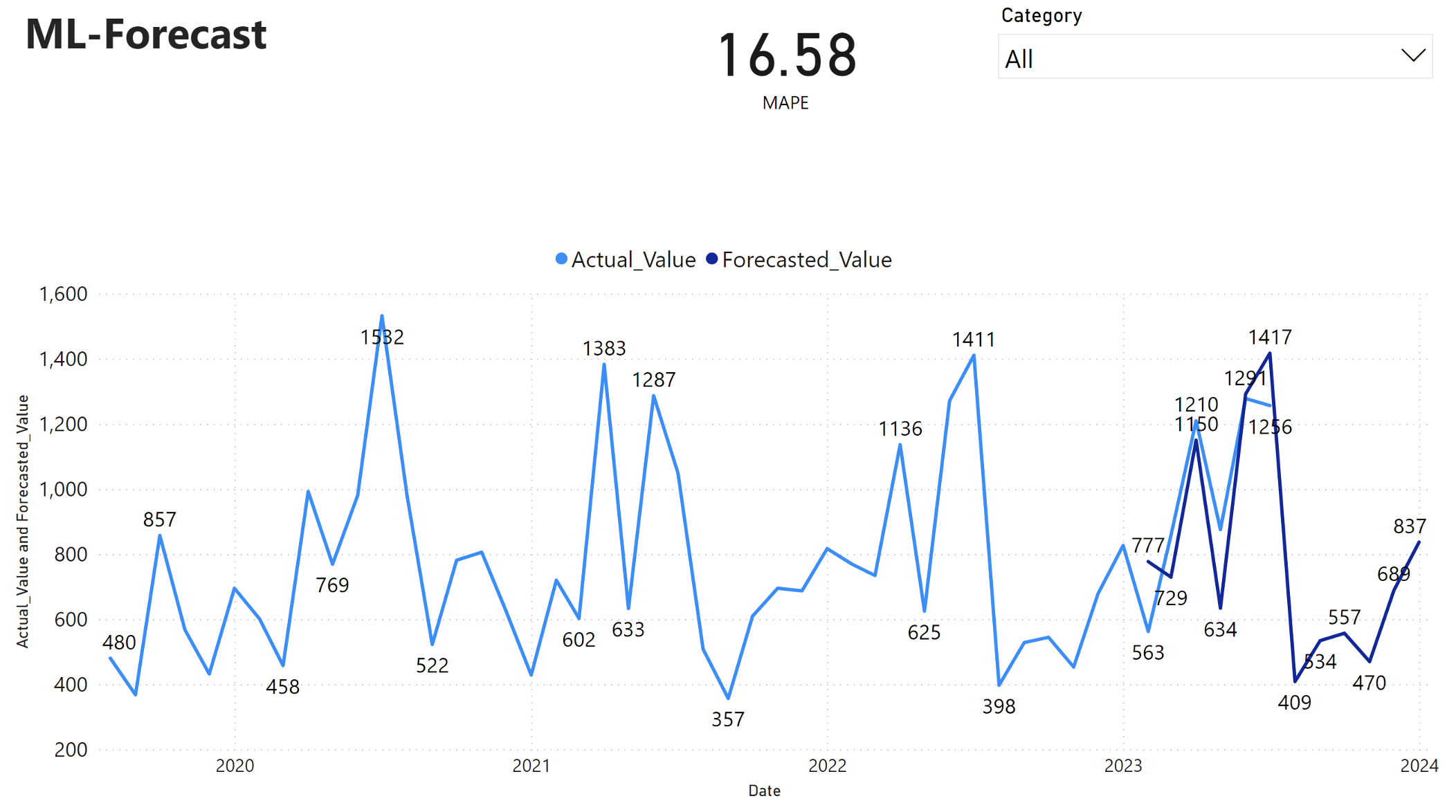
E megfigyelés alapján megbízhatunk a modell előrejelzési képességeiben a 2023 utolsó hat hónapjának teljes értékesítésére vonatkozóan, és 2024-ig terjedhet. Ez a bizalom képes tájékoztatni a stratégiai döntéseket a készletkezelésről, a nyersanyagok beszerzéséről és más üzleti szempontokról.