Idősor-előrejelzési modell betanítása és kiértékelése
Ebben a jegyzetfüzetben létrehozunk egy programot, amely szezonális ciklusokkal rendelkező idősoradatokat jelez előre. A NYC Property Sales adatkészletét a NYC Pénzügyi Osztálya által a NYC Open Data Portalon közzétett 2003-tól 2015-ig terjedő dátumokkal használjuk.
Előfeltételek
Microsoft Fabric-előfizetés lekérése. Vagy regisztráljon egy ingyenes Microsoft Fabric-próbaverzióra.
A kezdőlap bal oldalán található élménykapcsolóval válthat a Synapse Adattudomány felületre.

- A Microsoft Fabric-jegyzetfüzetek ismerete.
- A példa adatainak tárolására szolgáló tóház. További információ: Lakehouse hozzáadása a jegyzetfüzethez.
Követés jegyzetfüzetben
A jegyzetfüzetekben kétféleképpen követheti a lépéseket:
- Nyissa meg és futtassa a beépített jegyzetfüzetet a Synapse Adattudomány felületen.
- Töltse fel a jegyzetfüzetet a GitHubról a Synapse Adattudomány felületére.
A beépített jegyzetfüzet megnyitása
Az oktatóanyaghoz a time series mintajegyzetfüzet is hozzá van kísérve.
Az oktatóanyag beépített mintajegyzetfüzetének megnyitása a Synapse Adattudomány felületén:
Nyissa meg a Synapse Adattudomány kezdőlapját.
Válassza a Minta használata lehetőséget.
Válassza ki a megfelelő mintát:
- Ha a minta Python-oktatóanyaghoz készült, az alapértelmezett Végpontok közötti munkafolyamatok (Python) lapon.
- A végpontok közötti munkafolyamatok (R) lapról, ha a minta R-oktatóanyaghoz készült.
- A Gyors oktatóanyagok lapon, ha a minta egy gyors oktatóanyaghoz készült.
A kód futtatása előtt csatoljon egy lakehouse-t a jegyzetfüzethez .
A jegyzetfüzet importálása a GitHubról
Az AIsample – Time Series Forecasting.ipynb az oktatóanyagot kísérő jegyzetfüzet.
Az oktatóanyaghoz mellékelt jegyzetfüzet megnyitásához kövesse a Rendszer előkészítése adatelemzési oktatóanyagokhoz című témakör utasításait, és importálja a jegyzetfüzetet a munkaterületre.
Ha inkább erről a lapról másolja és illessze be a kódot, létrehozhat egy új jegyzetfüzetet.
A kód futtatása előtt mindenképpen csatoljon egy lakehouse-t a jegyzetfüzethez .
1. lépés: Egyéni kódtárak telepítése
Ha gépi tanulási modellt fejleszt, vagy alkalmi adatelemzést kezel, előfordulhat, prophet hogy gyorsan telepítenie kell egy egyéni kódtárat (például ebben a jegyzetfüzetben) az Apache Spark-munkamenethez. Ehhez két lehetősége van.
- Az új kódtárak gyors megkezdéséhez használhatja a helyszíni telepítési képességeket (például
%pip,%condastb.). Ez csak az aktuális jegyzetfüzetben telepíti az egyéni kódtárakat, a munkaterületen nem.
# Use pip to install libraries
%pip install <library name>
# Use conda to install libraries
%conda install <library name>
- Másik lehetőségként létrehozhat egy Fabric-környezetet, telepíthet nyilvános forrásokból származó kódtárakat, vagy feltölthet hozzá egyéni kódtárakat, majd a munkaterület rendszergazdája alapértelmezettként csatolhatja a környezetet a munkaterülethez. Ezután a környezet összes kódtára elérhetővé válik a munkaterület bármely jegyzetfüzetében és Spark-feladatdefiníciójában. A környezetekkel kapcsolatos további információkért tekintse meg a Környezetek létrehozását, konfigurálását és használatát a Microsoft Fabricben.
Ehhez a jegyzetfüzethez %pip install a prophet kódtárat kell telepítenie. A PySpark kernel a következő után %pip installújraindul. Ez azt jelenti, hogy minden más cella futtatása előtt telepítenie kell a tárat.
# Use pip to install Prophet
%pip install prophet
2. lépés: Az adatok betöltése
Adathalmaz
Ez a jegyzetfüzet az NYC Property Sales adatkészletet használja. A 2003 és 2015 közötti adatokat mutatja be, amelyeket a NYC Pénzügyi Osztálya tett közzé a NYC nyílt adatportálján.
Az adatkészlet tartalmazza a New York-i ingatlanpiacon 13 éven belüli összes ingatlanértékesítés rekordját. Az adathalmaz oszlopainak meghatározásához tekintse meg a tulajdonságeladási fájlok kifejezéseinek szószedetét.
| Borough | Környéken | building_class_category | tax_class | Blokk | Sok | keletre | building_class_at_present | Cím | apartment_number | zip_code | residential_units | commercial_units | total_units | land_square_feet | gross_square_feet | year_built | tax_class_at_time_of_sale | building_class_at_time_of_sale | sale_price | sale_date |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Manhattan | ALPHABET CITY | 07 BÉRLETI DÍJAK - WALKUP APARTMANOK | 0,0 | 384.0 | 17,0 | C4 | 225 EAST 2ND STR Enterprise kiadás T | 10009.0 | 10,0 | 0,0 | 10,0 | 2145.0 | 6670.0 | 1900.0 | 2,0 | C4 | 275000.0 | 2007-06-19 | ||
| Manhattan | ALPHABET CITY | 07 BÉRLETI DÍJAK - WALKUP APARTMANOK | 2,0 | 405.0 | 12.0 | C7 | 508 EAST 12TH STR Enterprise kiadás T | 10009.0 | 28.0 | 2,0 | 30,0 | 3872.0 | 15428.0 | 1930.0 | 2,0 | C7 | 7794005.0 | 2007-05-21 |
A cél egy olyan modell létrehozása, amely előrejelezi a havi összes értékesítést az előzményadatok alapján. Ehhez a Prophett, a Facebook által kifejlesztett nyílt forráskód előrejelzési könyvtárat használod. A Prophet egy additív modellen alapul, ahol a nemlineáris trendek napi, heti és éves szezonalitással és ünnepi hatásokkal felelnek meg. A Próféta az erős szezonális hatással rendelkező idősorozat-adathalmazokon és a történelmi adatok több évszakán dolgozik a legjobban. Emellett a Prophet robusztusan kezeli a hiányzó adatokat és az adat kiugró értékeket.
A Prophet egy három összetevőből álló, lebontható idősorozat-modellt használ:
- trend: Próféta feltételezi, hogy egy darab-bölcs állandó növekedési ütem, automatikus változáspont kiválasztása
- szezonalitás: A Próféta alapértelmezés szerint a Fourier Series-t használja a heti és az éves szezonalitáshoz
- ünnepnapok: Próféta megköveteli az ünnepnapok minden múltbeli és jövőbeli előfordulását. Ha egy ünnep nem ismétlődik meg a jövőben, próféta nem fogja belefoglalni az előrejelzésbe.
Ez a jegyzetfüzet havi rendszerességgel összesíti az adatokat, így figyelmen kívül hagyja az ünnepnapokat.
A Próféta modellezési technikáiról a hivatalos tanulmányban olvashat bővebben.
Töltse le az adathalmazt, és töltse fel a lakehouse-ba
Az adatforrás 15 .csv fájlból áll. Ezek a fájlok 2003 és 2015 között new yorki öt kerület ingatlaneladási rekordjait tartalmazzák. A kényelem érdekében a nyc_property_sales.tar fájl az összes .csv fájlt tartalmazza, és egyetlen fájlba tömöríti őket. Ezt a fájlt egy nyilvánosan elérhető blobtároló üzemelteti .tar .
Tipp.
A kódcellában látható paraméterekkel egyszerűen alkalmazhatja ezt a jegyzetfüzetet különböző adathalmazokra.
URL = "https://synapseaisolutionsa.blob.core.windows.net/public/NYC_Property_Sales_Dataset/"
TAR_FILE_NAME = "nyc_property_sales.tar"
DATA_FOLDER = "Files/NYC_Property_Sales_Dataset"
TAR_FILE_PATH = f"/lakehouse/default/{DATA_FOLDER}/tar/"
CSV_FILE_PATH = f"/lakehouse/default/{DATA_FOLDER}/csv/"
EXPERIMENT_NAME = "aisample-timeseries" # MLflow experiment name
Ez a kód letölti az adathalmaz nyilvánosan elérhető verzióját, majd egy Fabric Lakehouse-ban tárolja az adathalmazt.
Fontos
A futtatás előtt mindenképpen adjon hozzá egy lakehouse-t a jegyzetfüzethez. Ennek elmulasztása hibát fog eredményezni.
import os
if not os.path.exists("/lakehouse/default"):
# Add a lakehouse if the notebook has no default lakehouse
# A new notebook will not link to any lakehouse by default
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse for the notebook."
)
else:
# Verify whether or not the required files are already in the lakehouse, and if not, download and unzip
if not os.path.exists(f"{TAR_FILE_PATH}{TAR_FILE_NAME}"):
os.makedirs(TAR_FILE_PATH, exist_ok=True)
os.system(f"wget {URL}{TAR_FILE_NAME} -O {TAR_FILE_PATH}{TAR_FILE_NAME}")
os.makedirs(CSV_FILE_PATH, exist_ok=True)
os.system(f"tar -zxvf {TAR_FILE_PATH}{TAR_FILE_NAME} -C {CSV_FILE_PATH}")
Indítsa el a jegyzetfüzet futásidejének rögzítését.
# Record the notebook running time
import time
ts = time.time()
Az MLflow-kísérlet nyomon követésének beállítása
Az MLflow naplózási képességeinek bővítése érdekében az automatikus naplózás automatikusan rögzíti a gépi tanulási modell bemeneti paramétereinek és kimeneti metrikáinak értékeit a betanítás során. Ezt az információt ezután a rendszer naplózza a munkaterületre, ahol az MLflow API-k vagy a munkaterület megfelelő kísérlete elérheti és megjelenítheti azokat. Az automatikus kereséssel kapcsolatos további információkért látogasson el erre az erőforrásra .
# Set up the MLflow experiment
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Feljegyzés
Ha le szeretné tiltani a Microsoft Fabric automatikus keresését egy jegyzetfüzet-munkamenetben, hívja fel mlflow.autolog() és állítsa be a következőt disable=True:
Nyers dátumadatok olvasása a lakehouse-ból
df = (
spark.read.format("csv")
.option("header", "true")
.load("Files/NYC_Property_Sales_Dataset/csv")
)
3. lépés: Feltáró adatelemzés megkezdése
Az adathalmaz áttekintéséhez manuálisan megvizsgálhatja az adatok egy részhalmazát, hogy jobban megértse azt. A függvény használatával display kinyomtathatja a DataFrame-et. A Diagram nézeteket is megjelenítheti, így egyszerűen megjelenítheti az adathalmaz részhalmazait.
display(df)
Az adathalmaz manuális áttekintése néhány korai megfigyeléshez vezet:
0,00 USD eladási árak példányai. A kifejezések szószedete szerint ez a tulajdonjog készpénz ellenérték nélküli átruházását jelenti. Más szóval, a tranzakcióban nem áramlott pénz. Távolítsa el a 0,00
sales_priceUSD értékű értékesítéseket az adathalmazból.Az adatkészlet különböző épületosztályokat fed le. Ez a jegyzetfüzet azonban a lakóépületekre összpontosít, amelyek a kifejezések szószedete szerint "A" típusúként vannak megjelölve. Az adathalmazt úgy kell szűrni, hogy csak lakóépületeket tartalmazzon. Ehhez adja meg az oszlopokat vagy az
building_class_at_time_of_salebuilding_class_at_presentoszlopokat. Csak az adatokat kell tartalmazniabuilding_class_at_time_of_sale.Az adathalmaz olyan példányokat tartalmaz, ahol
total_unitsaz értékek 0, azgross_square_feetértékek pedig 0. Távolítsa el az összes olyan példányt, aholtotal_unitsvagygross_square_unitsahol az értékek értéke 0.Egyes oszlopok – például ,
apartment_numbertax_class,build_class_at_presentstb. – hiányzó vagy NULL értékekkel rendelkeznek. Tegyük fel, hogy a hiányzó adatok elírással vagy nem létező adatokkal járnak. Az elemzés nem függ ezektől a hiányzó értékektől, ezért figyelmen kívül hagyhatja őket.Az
sale_priceoszlop sztringként van tárolva, előre felfűzött "$" karakterrel. Az elemzés folytatásához adja meg ezt az oszlopot számként. Az oszlopotsale_priceegész számként kell leadnia.
Típuskonvertálás és szűrés
Az azonosított problémák megoldásához importálja a szükséges kódtárakat.
# Import libraries
import pyspark.sql.functions as F
from pyspark.sql.types import *
Értékesítési adatok sztringről egész számra történő levezetése
Használjon reguláris kifejezéseket a sztring numerikus részének a dollárjeltől való elválasztásához (például a "$300 000" sztringben a "$" és a "300 000" felosztásával), majd a numerikus részt egész számként adja meg.
Ezután szűrje az adatokat úgy, hogy csak az alábbi feltételeknek megfelelő példányokat tartalmazza:
- A
sales_pricenagyobb, mint 0 - A
total_unitsnagyobb, mint 0 - A
gross_square_feetnagyobb, mint 0 - Az
building_class_at_time_of_saleA típusú
df = df.withColumn(
"sale_price", F.regexp_replace("sale_price", "[$,]", "").cast(IntegerType())
)
df = df.select("*").where(
'sale_price > 0 and total_units > 0 and gross_square_feet > 0 and building_class_at_time_of_sale like "A%"'
)
Összesítés havi alapon
Az adaterőforrás napi rendszerességgel követi nyomon a tulajdonságeladásokat, de ez a megközelítés túl részletes ehhez a jegyzetfüzethez. Ehelyett havonta összesítheti az adatokat.
Először módosítsa a dátumértékeket úgy, hogy csak a hónap és az év adatait jelenítse meg. A dátumértékek továbbra is tartalmazzák az év adatait. Továbbra is különbséget tehet például 2005 decembere és 2006 decembere között.
Emellett csak az elemzés szempontjából fontos oszlopokat tartsa fontosnak. Ezek közé tartoznak a következők: sales_price, total_unitsgross_square_feet és sales_date. A nevet is át kell nevezniesales_date.month
monthly_sale_df = df.select(
"sale_price",
"total_units",
"gross_square_feet",
F.date_format("sale_date", "yyyy-MM").alias("month"),
)
display(monthly_sale_df)
Összesíti a sale_price, total_units és gross_square_feet az értékeket hónap szerint. Ezután csoportosítsa monthaz adatokat, és összegzi az egyes csoportokban lévő összes értéket.
summary_df = (
monthly_sale_df.groupBy("month")
.agg(
F.sum("sale_price").alias("total_sales"),
F.sum("total_units").alias("units"),
F.sum("gross_square_feet").alias("square_feet"),
)
.orderBy("month")
)
display(summary_df)
Pyspark–Pandas átalakítás
A Pyspark DataFrames jól kezeli a nagy adathalmazokat. Az adatösszesítés miatt azonban a DataFrame mérete kisebb. Ez arra utal, hogy mostantól használhatja a pandas DataFrame-eket.
Ez a kód egy pyspark DataFrame-ből egy pandas DataFrame-be helyezi át az adathalmazt.
import pandas as pd
df_pandas = summary_df.toPandas()
display(df_pandas)
Vizualizáció
Az adatok jobb megértéséhez megvizsgálhatja New York city ingatlankereskedelmi trendet. Ez a lehetséges minták és szezonalitási trendek elemzéséhez vezet. További információ a Microsoft Fabric adatvizualizációjáról ezen az erőforráson.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
f, (ax1, ax2) = plt.subplots(2, 1, figsize=(35, 10))
plt.sca(ax1)
plt.xticks(np.arange(0, 15 * 12, step=12))
plt.ticklabel_format(style="plain", axis="y")
sns.lineplot(x="month", y="total_sales", data=df_pandas)
plt.ylabel("Total Sales")
plt.xlabel("Time")
plt.title("Total Property Sales by Month")
plt.sca(ax2)
plt.xticks(np.arange(0, 15 * 12, step=12))
plt.ticklabel_format(style="plain", axis="y")
sns.lineplot(x="month", y="square_feet", data=df_pandas)
plt.ylabel("Total Square Feet")
plt.xlabel("Time")
plt.title("Total Property Square Feet Sold by Month")
plt.show()
A feltáró adatelemzés megfigyeléseinek összegzése
- Az adatok egyértelműen ismétlődő mintázatot mutatnak egy éves ütemben; ez azt jelenti, hogy az adatok éves szezonalitással
- A nyári hónapok úgy tűnik, hogy nagyobb értékesítési volument, mint a téli hónapok
- A magas értékesítéssel és az alacsony értékesítéssel rendelkező évekkel összehasonlítva a magas értékesítési hónapok és a magas értékesítési évek alacsony értékesítési hónapjai közötti bevételkülönbség abszolút értékben meghaladja a magas értékesítési hónapok és az alacsony értékesítési évek alacsony értékesítési hónapjai közötti bevételkülönbséget.
2004-ben például a legmagasabb értékesítési hónap és a legalacsonyabb értékesítési hónap közötti bevételkülönbség a következő:
$900,000,000 - $500,000,000 = $400,000,000
2011-ben ez a bevételkülönbség kiszámítása a következő:
$400,000,000 - $300,000,000 = $100,000,000
Ez később válik fontossá, amikor el kell döntenie a multiplikatív és az additív szezonalitás hatásai között.
4. lépés: Modell betanítása és nyomon követése
Modellillesztés
A prófétai bemenet mindig kétoszlopos DataFrame. Az egyik bemeneti oszlop egy időoszlop neve ds, egy bemeneti oszlop pedig egy névvel ellátott yértékoszlop. Az időoszlopnak dátum, idő vagy dátum/idő adatformátummal kell rendelkeznie (például YYYY_MM). Az adathalmaz megfelel ennek a feltételnek. Az értékoszlopnak numerikus adatformátumnak kell lennie.
A modellillesztéshez csak az időoszlopot kell átneveznie ds , az érték oszlopot ypedig át kell adnia a Prophetnak. További információért olvassa el a Prophet Python API dokumentációját .
df_pandas["ds"] = pd.to_datetime(df_pandas["month"])
df_pandas["y"] = df_pandas["total_sales"]
Próféta követi a scikit-learn konvenciót. Először hozzon létre egy új Prophet-példányt, állítson be bizonyos paramétereket (például),seasonality_mode majd illeszkedjen a példányhoz az adathalmazhoz.
Bár a Próféta esetében az állandó additív tényező az alapértelmezett szezonalitási hatás, a szezonalitás-effektus paraméteréhez a "multiplikatív" szezonalitást kell használnia. Az előző szakaszban végzett elemzés kimutatta, hogy a szezonalitás amplitúdójának változása miatt az egyszerű additív szezonalitás egyáltalán nem fér el az adatokhoz.
Állítsa ki a weekly_seasonality paramétert, mert az adatok hónap szerint összesítve lesznek. Emiatt a heti adatok nem érhetők el.
Használja a Markov Chain Monte Carlo (MCMC) metódusokat a szezonalitási bizonytalanság becsléseinek rögzítéséhez. Alapértelmezés szerint a Próféta bizonytalansági becslést tud adni a trendről és a megfigyelési zajról, de a szezonalitásra nem. Az MCMC több feldolgozási időt igényel, de lehetővé teszik az algoritmus számára, hogy bizonytalansági becslést adjon a szezonalitásról, valamint a trendről és a megfigyelési zajról. További információért olvassa el a Prophet Uncertainty Intervals dokumentációját .
Hangolja az automatikus változáspont-észlelési érzékenységet a changepoint_prior_scale paraméterrel. A Próféta algoritmus automatikusan megpróbál példányokat keresni azokban az adatokban, ahol a pályák hirtelen változnak. Nehéz lehet megtalálni a megfelelő értéket. A probléma megoldásához különböző értékeket próbálhat ki, majd kiválaszthatja a legjobb teljesítményt nyújtó modellt. További információért olvassa el a Prophet Trend Changepoints dokumentációját .
from prophet import Prophet
def fit_model(dataframe, seasonality_mode, weekly_seasonality, chpt_prior, mcmc_samples):
m = Prophet(
seasonality_mode=seasonality_mode,
weekly_seasonality=weekly_seasonality,
changepoint_prior_scale=chpt_prior,
mcmc_samples=mcmc_samples,
)
m.fit(dataframe)
return m
Keresztérvényesítés
A Prophet beépített keresztérvényesítési eszközzel rendelkezik. Ez az eszköz megbecsülheti az előrejelzési hibát, és megtalálhatja a modellt a legjobb teljesítménnyel.
A keresztérvényesítési technika képes ellenőrizni a modell hatékonyságát. Ez a technika betanítja a modellt az adathalmaz egy részhalmazára, és az adathalmaz egy korábban nem látott részhalmazán futtat teszteket. Ez a technika képes ellenőrizni, hogy egy statisztikai modell mennyire általánosít egy független adatkészletre.
Keresztérvényesítéshez tartsa fenn az adathalmaz egy adott mintáját, amely nem része a betanítási adathalmaznak. Ezután tesztelje a betanított modellt a mintán az üzembe helyezés előtt. Ez a megközelítés azonban nem működik az idősoros adatok esetében, mert ha a modell 2005. január és 2005. március hónap adatait látta, és a 2005. februári hónapra próbál előrejelzést adni, a modell lényegében csalhat, mert láthatja, hogy hová vezet az adattrend. A valós alkalmazásokban a cél az előrejelzés a jövőre, mint a nem látott régiókra.
Ennek kezeléséhez és a teszt megbízhatóvá tétele érdekében ossza fel az adathalmazt a dátumok alapján. Az adathalmazt egy bizonyos dátumig (például az adatok első 11 évében) használhatja betanításra, majd a fennmaradó nem látható adatokat használhatja előrejelzéshez.
Ebben a forgatókönyvben 11 év betanítási adattal kell kezdenie, majd havi előrejelzéseket kell készítenie egyéves horizont használatával. A betanítási adatok 2003 és 2013 között mindent tartalmaznak. Ezután az első futtatás kezeli a 2014. január és 2015. januári előrejelzéseket. A következő futtatás a 2014. február és 2015. februári előrejelzéseket kezeli, és így tovább.
Ismételje meg ezt a folyamatot mindhárom betanított modell esetében, hogy lássa, melyik modell teljesít a legjobban. Ezután hasonlítsa össze ezeket az előrejelzéseket valós értékekkel a legjobb modell előrejelzési minőségének megállapításához.
from prophet.diagnostics import cross_validation
from prophet.diagnostics import performance_metrics
def evaluation(m):
df_cv = cross_validation(m, initial="4017 days", period="30 days", horizon="365 days")
df_p = performance_metrics(df_cv, monthly=True)
future = m.make_future_dataframe(periods=12, freq="M")
forecast = m.predict(future)
return df_p, future, forecast
Log model with MLflow
Naplózza a modelleket, nyomon követheti a paramétereket, és mentheti a modelleket későbbi használatra. A rendszer minden releváns modellinformációt naplóz a munkaterületen, a kísérlet neve alatt. A modell, a paraméterek és a metrikák, valamint az MLflow automatikus kitöltési elemei egyetlen MLflow-futtatásban lesznek mentve.
# Setup MLflow
from mlflow.models.signature import infer_signature
Kísérletek végrehajtása
A gépi tanulási kísérlet az összes kapcsolódó gépi tanulási futtatás elsődleges szervezeti és vezérlési egysége. A futtatás a modellkód egyetlen végrehajtásának felel meg. A gépi tanulási kísérletek nyomon követése a különböző kísérletek és azok összetevőinek felügyeletére utal. Ez magában foglalja a paramétereket, metrikákat, modelleket és egyéb összetevőket, és segít egy adott gépi tanulási kísérlet szükséges összetevőinek rendszerezésében. A gépi tanulási kísérletek nyomon követése lehetővé teszi a múltbeli eredmények egyszerű duplikálását a mentett kísérletekkel. További információ a Microsoft Fabric gépi tanulási kísérleteiről. Miután meghatározta a belefoglalni kívánt lépéseket (például a Próféta modell illesztését és kiértékelését ebben a jegyzetfüzetben), futtathatja a kísérletet.
model_name = f"{EXPERIMENT_NAME}-prophet"
models = []
df_metrics = []
forecasts = []
seasonality_mode = "multiplicative"
weekly_seasonality = False
changepoint_priors = [0.01, 0.05, 0.1]
mcmc_samples = 100
for chpt_prior in changepoint_priors:
with mlflow.start_run(run_name=f"prophet_changepoint_{chpt_prior}"):
# init model and fit
m = fit_model(df_pandas, seasonality_mode, weekly_seasonality, chpt_prior, mcmc_samples)
models.append(m)
# Validation
df_p, future, forecast = evaluation(m)
df_metrics.append(df_p)
forecasts.append(forecast)
# Log model and parameters with MLflow
mlflow.prophet.log_model(
m,
model_name,
registered_model_name=model_name,
signature=infer_signature(future, forecast),
)
mlflow.log_params(
{
"seasonality_mode": seasonality_mode,
"mcmc_samples": mcmc_samples,
"weekly_seasonality": weekly_seasonality,
"changepoint_prior": chpt_prior,
}
)
metrics = df_p.mean().to_dict()
metrics.pop("horizon")
mlflow.log_metrics(metrics)
Modell vizualizációja a Prophet használatával
A Prophet beépített vizualizációs függvényekkel rendelkezik, amelyek megjeleníthetik a modell illesztési eredményeit.
A fekete pontok a modell betanítása során használt adatpontokat jelölik. A kék vonal az előrejelzés, a világoskék terület pedig a bizonytalansági intervallumokat mutatja. Három különböző changepoint_prior_scale értékkel rendelkező modellt készített. A három modell előrejelzései a kódblokk eredményeiben jelennek meg.
for idx, pack in enumerate(zip(models, forecasts)):
m, forecast = pack
fig = m.plot(forecast)
fig.suptitle(f"changepoint = {changepoint_priors[idx]}")
Az első grafikon legkisebb changepoint_prior_scale értéke a trendváltozások alulillesztéséhez vezet. A harmadik gráf legnagyobbja changepoint_prior_scale túlillesztést eredményezhet. Így úgy tűnik, hogy a második gráf az optimális választás. Ez azt jelenti, hogy a második modell a legmegfelelőbb.
Trendek és szezonalitás megjelenítése a Prófétával
A Próféta könnyen megjelenítheti a mögöttes trendeket és szezonalitásokat. A második modell vizualizációi a kódblokk eredményeiben jelennek meg.
BEST_MODEL_INDEX = 1 # Set the best model index according to the previous results
fig2 = models[BEST_MODEL_INDEX].plot_components(forecast)
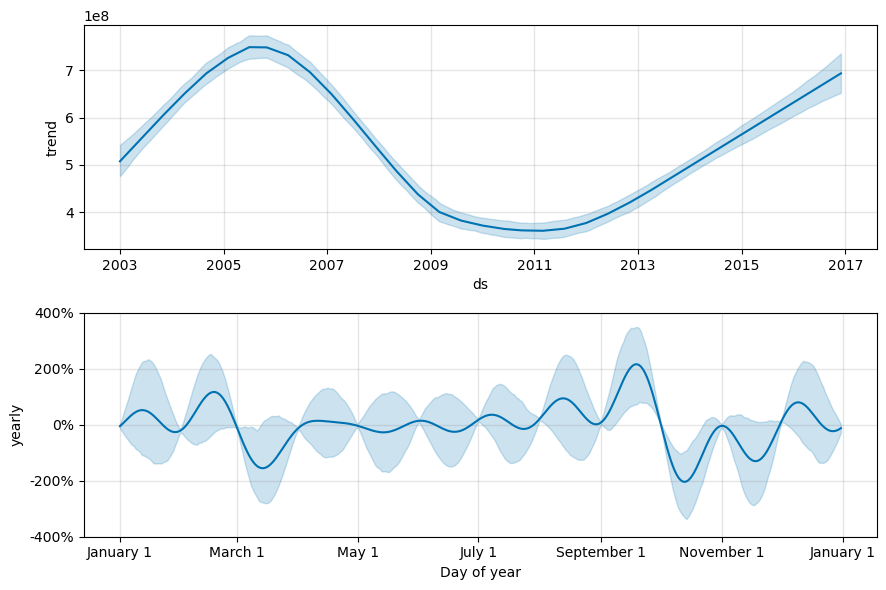
Ezekben a grafikonokon a világoskék árnyékolás a bizonytalanságot tükrözi. A felső grafikonon erős, hosszú távú oszcilláló trend látható. Néhány év alatt az értékesítési volumen emelkedik és csökken. Az alsó grafikon azt mutatja, hogy az értékesítések általában februárban és szeptemberben tetőznek, és elérik az adott hónapra vonatkozó maximális értékeket. Röviddel a hónapok után, márciusban és októberben az év minimális értékeire esnek.
Értékelje ki a modellek teljesítményét különböző metrikák használatával, például:
- középérték négyzetes hiba (M Standard kiadás)
- középérték négyzetes hiba (RM Standard kiadás)
- átlagos abszolút hiba (MAE)
- átlagos abszolút százalékos hiba (MAPE)
- medián abszolút százalékos hiba (MDAPE)
- szimmetrikus átlagos abszolút százalékos hiba (SMAPE)
Értékelje ki a lefedettséget a és yhat_upper a yhat_lower becslések alapján. Figyelje meg azokat a változó horizontokat, ahol egy évet előre jelezhet a jövőben, 12-szer.
display(df_metrics[BEST_MODEL_INDEX])
A MAPE-metrika esetében az előrejelzési modell esetében az egy hónapot a jövőbe nyúló előrejelzések általában körülbelül 8%-os hibákkal járnak. A jövőre vonatkozó előrejelzések esetében azonban a hiba körülbelül 10%-ra nő.
5. lépés: A modell pontszáma és az előrejelzési eredmények mentése
Most pontozza a modellt, és mentse az előrejelzési eredményeket.
Előrejelzések készítése a Predict Transformerrel
Most betöltheti a modellt, és előrejelzéseket készíthet vele. A felhasználók gépi tanulási modelleket is üzembe helyezhetnek a PREDICT használatával, amely egy méretezhető Microsoft Fabric-függvény, amely támogatja a kötegelt pontozást bármely számítási motorban. Ebben az erőforrásban további információt tudhat meg a PREDICTMicrosoft Fabricben való használatáról és használatáról.
from synapse.ml.predict import MLFlowTransformer
spark.conf.set("spark.synapse.ml.predict.enabled", "true")
model = MLFlowTransformer(
inputCols=future.columns.values,
outputCol="prediction",
modelName=f"{EXPERIMENT_NAME}-prophet",
modelVersion=BEST_MODEL_INDEX,
)
test_spark = spark.createDataFrame(data=future, schema=future.columns.to_list())
batch_predictions = model.transform(test_spark)
display(batch_predictions)
# Code for saving predictions into lakehouse
batch_predictions.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/batch_predictions"
)
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: