Tapasztalatspecifikus vészhelyreállítási útmutató
Ez a dokumentum tapasztalatspecifikus útmutatást nyújt a Fabric-adatok regionális katasztrófa esetén történő helyreállításához.
Mintaforgatókönyv
A dokumentum számos útmutató szakasza a következő példaforgatókönyvet használja magyarázat és illusztráció céljából. Szükség szerint térjen vissza erre a forgatókönyvre.
Tegyük fel, hogy rendelkezik egy C1 kapacitással az A régióban, amelynek W1 munkaterülete van. Ha bekapcsolta a C1 kapacitás vészhelyreállítását , a OneLake-adatok replikálódnak egy biztonsági mentésre a B régióban. Ha az A régió megszakad, a C1 hálószolgáltatása a B régióba lép át.
Az alábbi képen ez a forgatókönyv látható. A bal oldali mező a megszakított régiót jeleníti meg. A középső mező az adatok feladatátvétel utáni folyamatos rendelkezésre állását jelzi, a jobb oldali mezőben pedig a teljes körűen lefedett helyzet látható, miután az ügyfél a szolgáltatások teljes funkcióra való visszaállítására tett szolgáltatásokat.
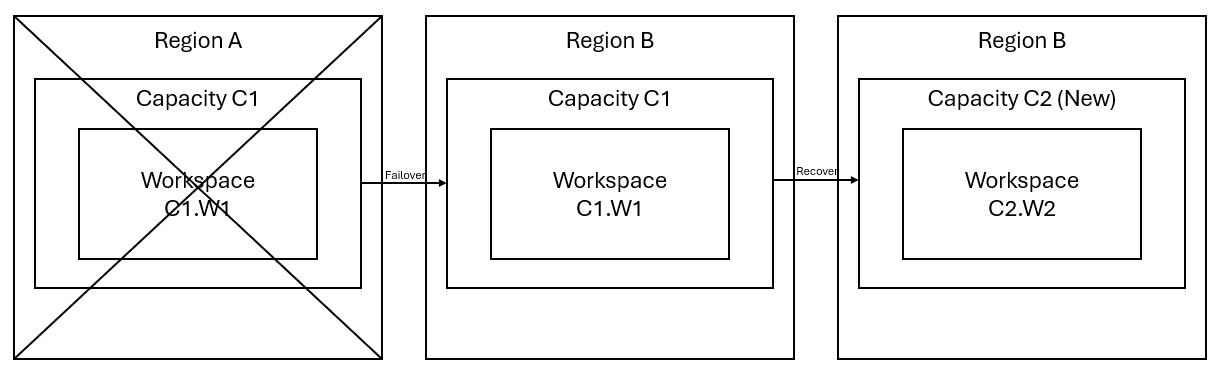
Íme az általános helyreállítási terv:
Hozzon létre egy új C2 hálókapacitást egy új régióban.
Hozzon létre egy új W2-munkaterületet a C2-ben, beleértve a megfelelő elemeket is, amelyek neve megegyezik a C1-ben leírtakkal. W1.
Adatok másolása a megszakított C1-ből. W1–C2. W2.
Kövesse az egyes összetevőkre vonatkozó utasításokat az elemek teljes funkcióra való visszaállításához.
Tapasztalatspecifikus helyreállítási tervek
Az alábbi szakaszok részletes útmutatókat nyújtanak az egyes Háló-élményekhez, hogy segítsenek az ügyfeleknek a helyreállítási folyamaton.
Adatfeldolgozás
Ez az útmutató végigvezeti a adatmérnök helyreállítási eljárásain. A lakehouse-okat, a jegyzetfüzeteket és a Spark-feladatdefiníciókat ismerteti.
Lakehouse
Az eredeti régióból származó lakehouse-k továbbra is nem érhetők el az ügyfelek számára. Egy tóház helyreállításához az ügyfelek újra létrehozhatják a C2 munkaterületen. W2. Két módszert ajánlunk a tóházak helyreállításához:
1. megközelítés: Egyéni szkript használata a Lakehouse Delta-táblák és -fájlok másolásához
Az ügyfelek egyéni Scala-szkripttel újra létrehozhatják a tóházakat.
Hozza létre a lakehouse-t (például LH1) az újonnan létrehozott C2 munkaterületen. W2.
Hozzon létre egy új jegyzetfüzetet a C2 munkaterületen. W2.
A táblák és fájlok eredeti lakehouse-ból való helyreállításához az ABFS elérési útját kell használnia az adatok eléréséhez (lásd Csatlakozás a Microsoft OneLake-hez való hozzáférést). Az alábbi kód példájával (lásd : Bevezetés a Microsoft Spark segédprogramok használatába) a jegyzetfüzetben lekérheti a fájlok és táblák ABFS-elérési útját az eredeti lakehouse-ból. (Cserélje le a C1-et. W1 a tényleges munkaterület nevével)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Az alábbi példakód használatával táblázatokat és fájlokat másolhat az újonnan létrehozott lakehouse-ba.
A Delta-táblák esetében egyenként kell átmásolnia a táblázatot az új tóházban való helyreállításhoz. Lakehouse-fájlok esetén a teljes fájlstruktúra egyetlen végrehajtással másolható az összes mögöttes mappával.
Lépjen kapcsolatba a támogatási csapattal a szkriptben szükséges feladatátvétel időbélyegéhez.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)A szkript futtatása után a táblák megjelennek az új tóházban.
2. megközelítés: Fájlok és táblák másolása az Azure Storage Explorerrel
Ha csak bizonyos Lakehouse-fájlokat vagy táblákat szeretne helyreállítani az eredeti lakehouse-ból, használja az Azure Storage Explorert. Részletes lépésekért tekintse meg a OneLake és az Azure Storage Explorer integrálását. Nagy adatméretekhez használja az 1. megközelítést.
Feljegyzés
A fent ismertetett két módszer a Delta formátumú táblák metaadatait és adatait is helyreállítja, mivel a metaadatok a OneLake-ben találhatók és tárolódnak az adatokkal együtt. A Spark Data Definition Language (DDL) szkriptekkel/parancsokkal létrehozott nem Delta formátumú táblák (e.g. CSV, Parquet stb.) esetében a felhasználó feladata a Spark DDL-szkriptek/parancsok karbantartása és újrafuttatása a helyreállításukhoz.
Jegyzetfüzet
Az elsődleges régióból származó jegyzetfüzetek továbbra sem érhetők el az ügyfelek számára, és a jegyzetfüzetekben lévő kód nem lesz replikálva a másodlagos régióba. A jegyzetfüzetkód új régióban történő helyreállításához két módszer létezik a jegyzetfüzetkód tartalmának helyreállítására.
1. megközelítés: Felhasználó által felügyelt redundancia a Git-integrációval (nyilvános előzetes verzióban)
A legegyszerűbb és leggyorsabb megoldás a Fabric Git-integráció használata, majd a jegyzetfüzet szinkronizálása az ADO-adattárral. Miután a szolgáltatás egy másik régióba nem úszott át, az adattár használatával újraépítheti a jegyzetfüzetet a létrehozott új munkaterületen.
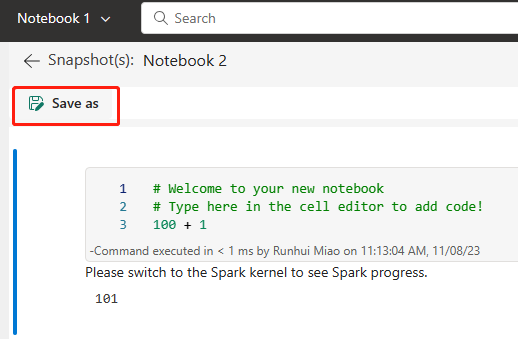
Állítsa be a Git-integrációt, és válassza ki a Csatlakozás és szinkronizálja az ADO-adattárral.
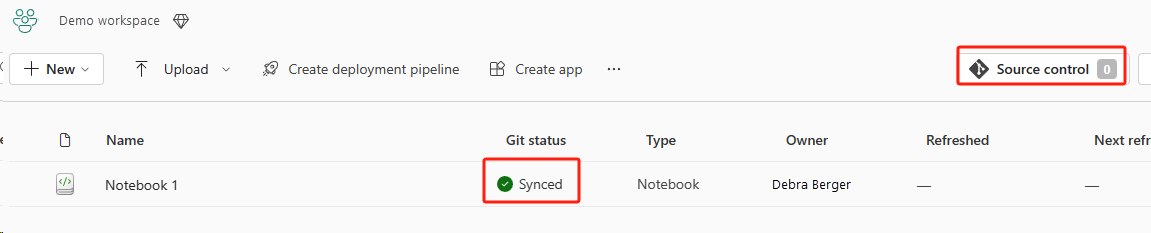
Az alábbi képen a szinkronizált jegyzetfüzet látható.
Állítsa helyre a jegyzetfüzetet az ADO-adattárból.
Az újonnan létrehozott munkaterületen csatlakozzon ismét az Azure ADO-adattárhoz.
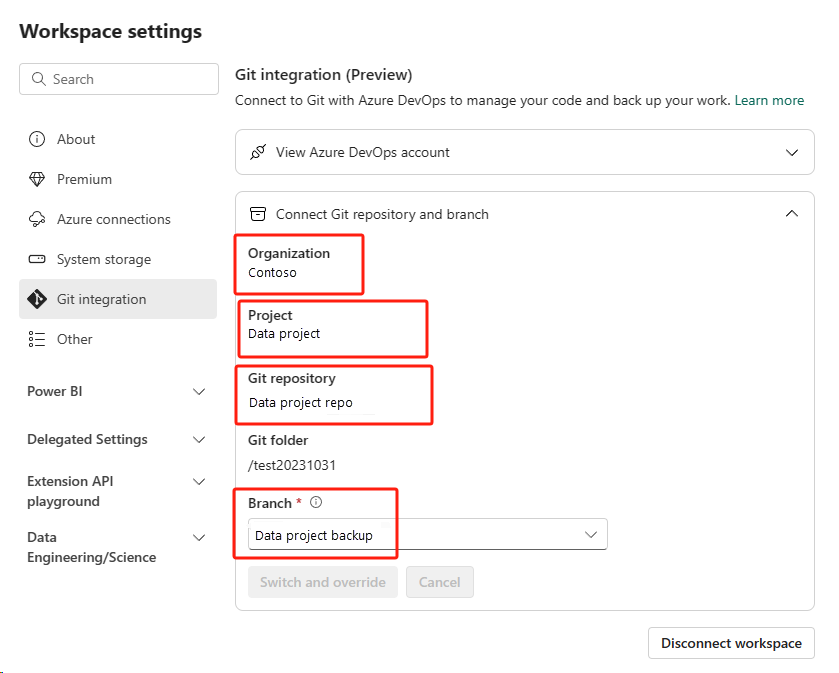
Válassza a Forrás vezérlőelem gombot. Ezután válassza ki az adattár megfelelő ágát. Ezután válassza az Összes frissítése lehetőséget. Ekkor megjelenik az eredeti jegyzetfüzet.
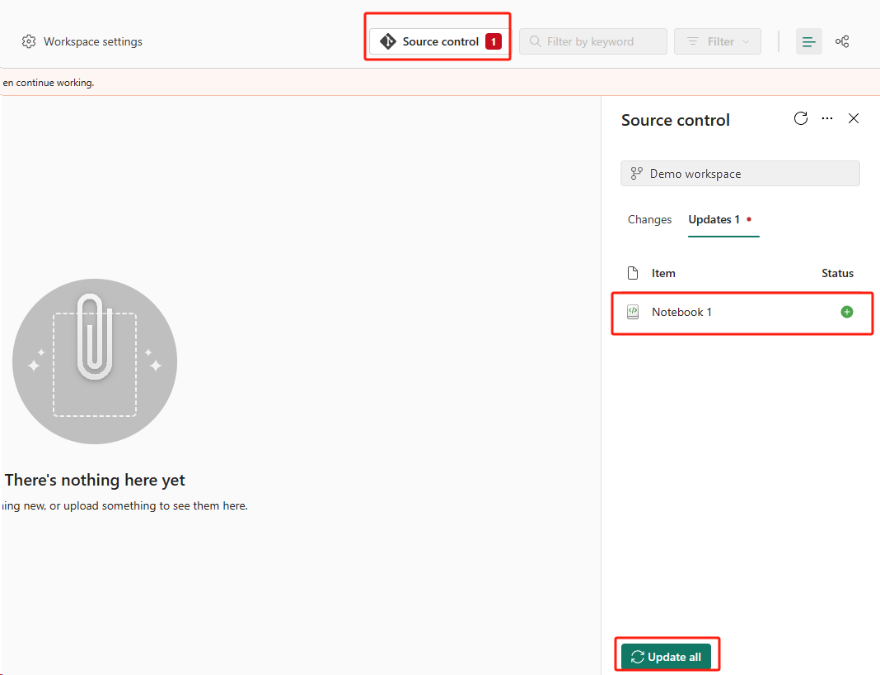
Ha az eredeti jegyzetfüzet alapértelmezett tóházzal rendelkezik, a felhasználók a Lakehouse szakaszra hivatkozva helyreállíthatják a lakehouse-t, majd csatlakoztathatják az újonnan helyreállított lakehouse-t az újonnan helyreállított jegyzetfüzethez.
A Git-integráció nem támogatja a fájlok, mappák vagy jegyzetfüzet-pillanatképek szinkronizálását a jegyzetfüzet erőforrás-kezelőjében.
Ha az eredeti jegyzetfüzet fájlokat tartalmaz a jegyzetfüzet erőforrás-kezelőjében:
Mindenképpen mentse a fájlokat vagy mappákat egy helyi lemezre vagy más helyre.
Töltse fel újra a fájlt a helyi lemezről vagy felhőbeli meghajtóról a helyreállított jegyzetfüzetbe.
Ha az eredeti jegyzetfüzet rendelkezik jegyzetfüzet-pillanatképtel, mentse a jegyzetfüzet pillanatképét a saját verziókövetési rendszerére vagy helyi lemezére is.
További információ a Git-integrációról: Bevezetés a Git-integrációba.
2. megközelítés: A kódtartalom biztonsági mentésének manuális megközelítése
Ha nem alkalmazza a Git-integrációs módszert, mentheti a kód legújabb verzióját, az erőforrás-kezelőben lévő fájlokat és a jegyzetfüzet pillanatképét egy verziókövetési rendszerben, például a Gitben, és manuálisan helyreállíthatja a jegyzetfüzet tartalmát egy katasztrófa után:
A helyreállítani kívánt jegyzetfüzetkód importálásához használja a "Jegyzetfüzet importálása" funkciót.
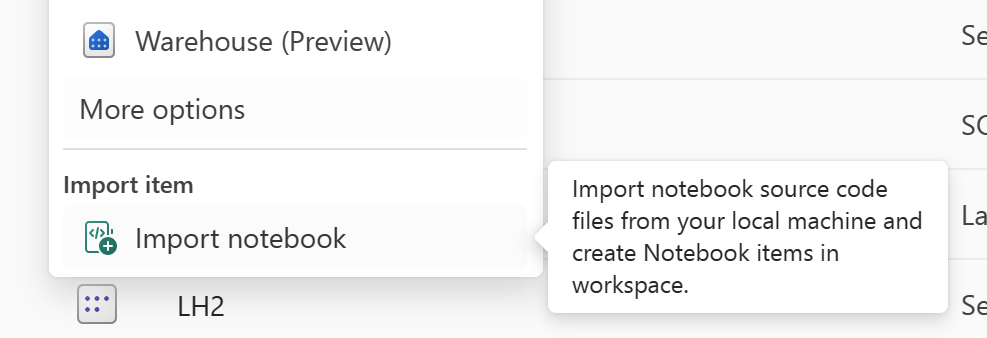
Az importálás után lépjen a kívánt munkaterületre (például "C2." W2") a hozzáféréshez.
Ha az eredeti jegyzetfüzet alapértelmezett lakehouse-zal rendelkezik, tekintse meg a Lakehouse szakaszt. Ezután csatlakoztassa az újonnan helyreállított lakehouse-t (amely ugyanazzal a tartalommal rendelkezik, mint az eredeti alapértelmezett lakehouse) az újonnan helyreállított jegyzetfüzethez.
Ha az eredeti jegyzetfüzetben vannak fájlok vagy mappák az erőforrás-kezelőben, töltse fel újra a felhasználó verziókövetési rendszerében mentett fájlokat vagy mappákat.
Spark-feladat definíciója
Az elsődleges régióból származó Spark-feladatdefiníciók (SJD) továbbra sem érhetők el az ügyfelek számára, és a jegyzetfüzet fő definíciós fájlja és referenciafájlja a OneLake-en keresztül replikálódik a másodlagos régióba. Ha az új régióban szeretné helyreállítani az SJD-t, kövesse az alábbi manuális lépéseket az SJD helyreállításához. Vegye figyelembe, hogy az SJD előzményfuttatásai nem lesznek helyreállítva.
Az SJD-elemek helyreállításához másolja a kódot az eredeti régióból az Azure Storage Explorer használatával, és manuálisan csatlakoztassa újra a Lakehouse-hivatkozásokat a katasztrófa után.
Hozzon létre egy új SJD-elemet (például SJD1) az új C2 munkaterületen. W2, ugyanazokkal a beállításokkal és konfigurációkkal, mint az eredeti SJD-elem (például nyelv, környezet stb.).
Az Azure Storage Explorer használatával másolja a Libs, Mains és Snapshots elemeket az eredeti SJD-elemből az új SJD-elemre.
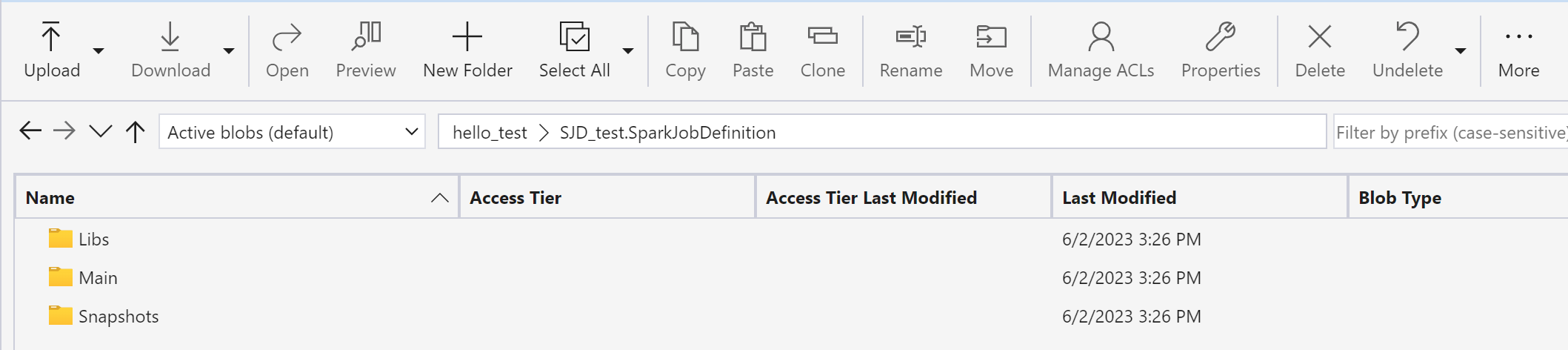
A kód tartalma megjelenik az újonnan létrehozott SJD-ben. Manuálisan kell hozzáadnia az újonnan helyreállított Lakehouse-hivatkozást a feladathoz (lásd a Lakehouse helyreállítási lépéseit). A felhasználóknak manuálisan kell újra megadniuk az eredeti parancssori argumentumokat.
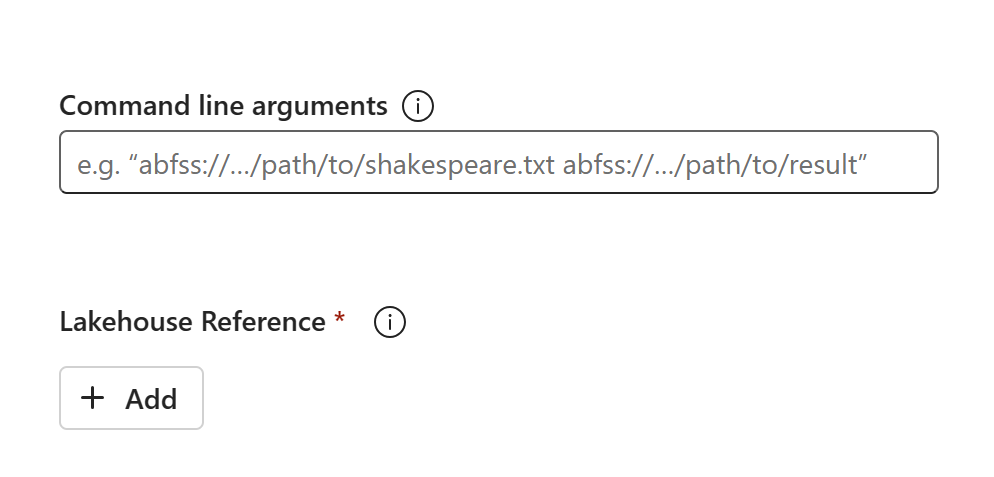
Most már futtathatja vagy ütemezheti az újonnan helyreállított SJD-t.
Az Azure Storage Explorerrel kapcsolatos részletekért lásd : OneLake integrálása az Azure Storage Explorerrel.
Adattudomány
Ez az útmutató végigvezeti a Adattudomány-élmény helyreállítási eljárásain. Ez az ml-modelleket és kísérleteket ismerteti.
ML-modell és kísérlet
Adattudomány elsődleges régió elemei nem érhetők el az ügyfelek számára, és az ML-modellek és kísérletek tartalma és metaadatai nem lesznek replikálva a másodlagos régióba. Az új régióban történő teljes helyreállításhoz mentse a kódtartalmat egy verziókövetési rendszerben (például a Gitben), és futtassa manuálisan újra a kód tartalmát a katasztrófa után.
Állítsa helyre a jegyzetfüzetet. Tekintse meg a Jegyzetfüzet helyreállítási lépéseit.
A konfiguráció, a korábban futtatott metrikák és metaadatok nem lesznek replikálva a párosított régióba. A katasztrófa után újra kell futtatnia az adatelemzési kód minden verzióját az ML-modellek és kísérletek teljes helyreállításához.
Adat tárház
Ez az útmutató végigvezeti az Adattárház-felület helyreállítási eljárásain. Lefedi a raktárakat.
Raktár
Az eredeti régióból származó raktárak továbbra sem érhetők el az ügyfelek számára. A raktárak helyreállításához kövesse az alábbi két lépést.
Hozzon létre egy új köztes tóházat a C2 munkaterületen. W2 az eredeti raktárból átmásolni kívánt adatokhoz.
Töltse ki a raktár Delta-tábláit a raktárkezelő és a T-SQL képességeinek kihasználásával (lásd : Táblák az adattárházakban a Microsoft Fabricben).
Feljegyzés
Javasoljuk, hogy a fejlesztési gyakorlatnak megfelelően a Warehouse-kódot (séma, tábla, nézet, tárolt eljárás, függvénydefiníciók és biztonsági kódok) biztonságos helyen (például Git) tárolja.
Adatbetöltés Lakehouse- és T-SQL-kóddal
Az újonnan létrehozott C2 munkaterületen. W2:
Hozzon létre egy köztes "LH2" tóházat a C2-ben. W2.
A Lakehouse helyreállítási lépéseit követve állítsa vissza az ideiglenes tóházban lévő Delta-táblákat az eredeti raktárból.
Hozzon létre egy új "WH2" raktárat a C2-ben. W2.
Csatlakozás a köztes tóházat a raktárkezelőben.
Attól függően, hogy hogyan fogja üzembe helyezni a tábladefiníciókat az adatimportálás előtt, az importáláshoz használt tényleges T-SQL eltérő lehet. Az IN Standard kiadás RT INTO, Standard kiadás LECT INTO vagy CREATE TABLE AS Standard kiadás LECT megközelítéssel helyreállíthatja a Lakehouse-ból származó Warehouse-táblákat. A példában az IN Standard kiadás RT INTO ízt használnánk. (Ha az alábbi kódot használja, cserélje le a mintákat a tényleges tábla- és oszlopnevekre)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOVégül módosítsa a kapcsolati sztring az alkalmazásokban a Fabric-raktár használatával.
Feljegyzés
Azoknak az ügyfeleknek, akiknek régiók közötti vészhelyreállításra és teljes mértékben automatizált üzletmenet-folytonosságra van szükségük, javasoljuk, hogy két Fabric Warehouse-beállítást tartsanak külön Fabric-régiókban, és fenntartsák a kód- és adatparitást úgy, hogy rendszeres üzembe helyezést és adatbetöltést végeznek mindkét helyen.
Data Factory
Az elsődleges régióból származó Data Factory-elemek nem érhetők el az ügyfelek számára, és az adatfolyamok vagy adatfolyam gen2 elemeinek beállításai és konfigurációja nem lesz replikálva a másodlagos régióba. Ha regionális hiba esetén szeretné helyreállítani ezeket az elemeket, újra létre kell hoznia a adatintegráció elemeket egy másik munkaterületen egy másik régióból. Az alábbi szakaszok ismertetik a részleteket.
Adatfolyamok Gen2
Ha egy Adatfolyam Gen2-elemet szeretne helyreállítani az új régióban, exportálnia kell egy PQT-fájlt egy verziókövetési rendszerbe, például a Gitbe, majd manuálisan helyre kell állítania az Adatfolyam Gen2 tartalmát a katasztrófa után.
Az Adatfolyam Gen2 elemében, a Power Query-szerkesztő Kezdőlap lapján válassza az Exportálás sablon lehetőséget.
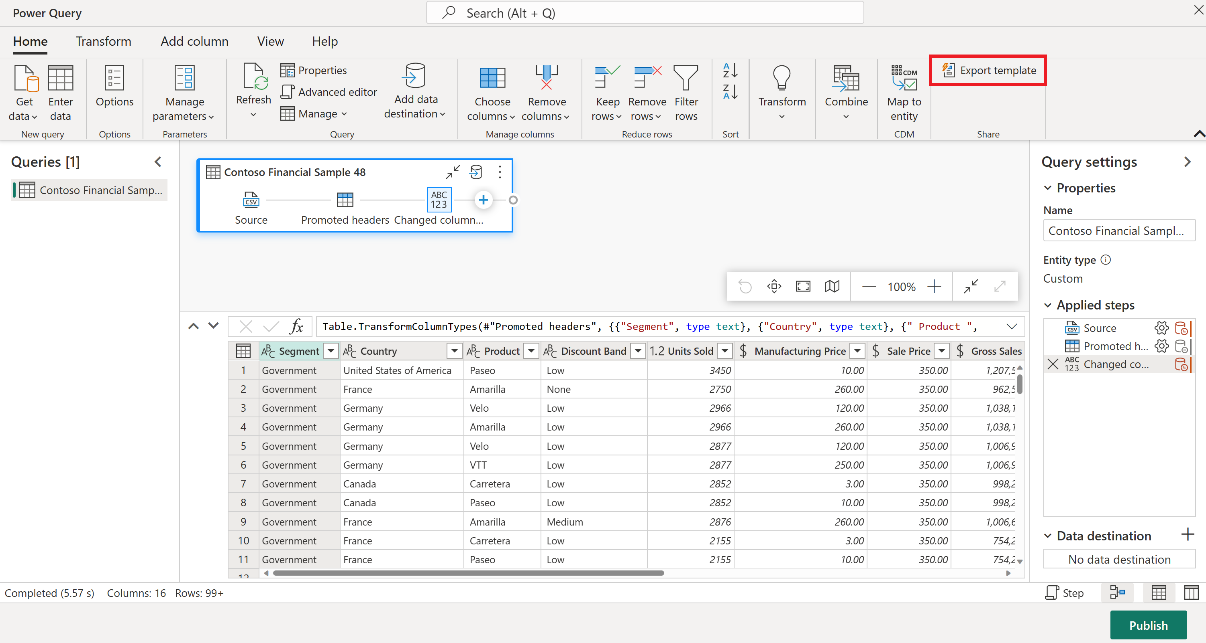
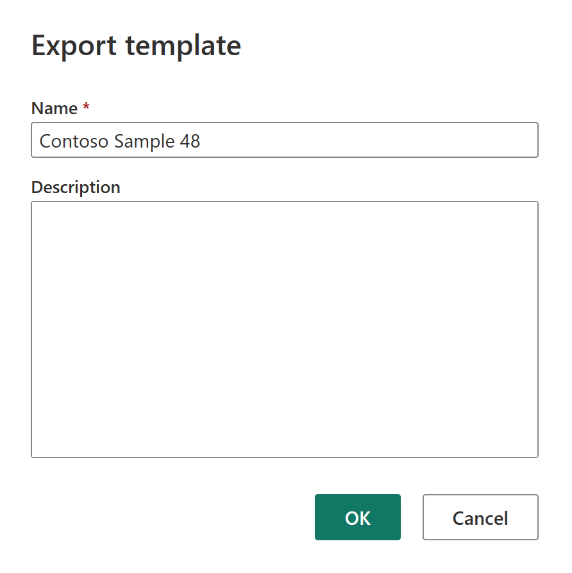
A Sablon exportálása párbeszédpanelen adja meg a sablon nevét (kötelező) és leírását (nem kötelező). Ha elkészült, kattintson az OK gombra.
A katasztrófa után hozzon létre egy új Adatfolyam Gen2-elemet az új "C2" munkaterületen. W2".
A Power Query-szerkesztő aktuális nézetpaneljén válassza az Importálás Power Query-sablonból lehetőséget.
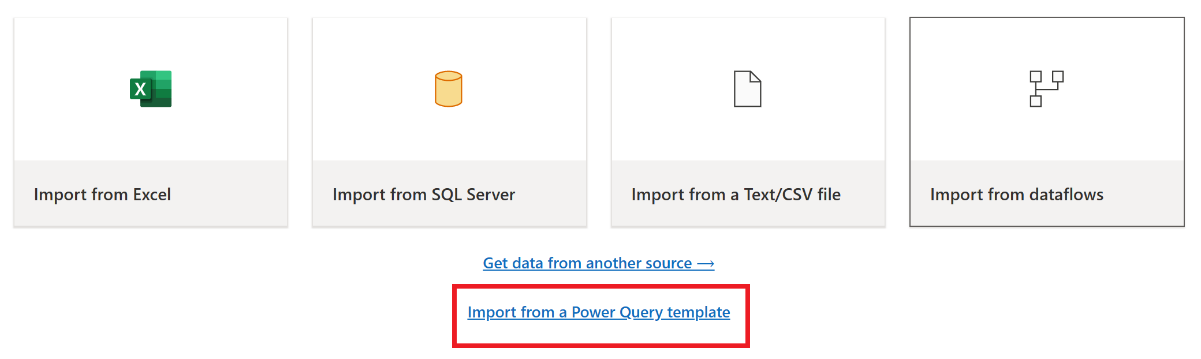
A Megnyitás párbeszédpanelen keresse meg az alapértelmezett letöltési mappát, és válassza ki az előző lépésekben mentett .pqt fájlt. Ezután válassza a Megnyitás lehetőséget.
A sablon ezután importálva lesz az új Adatfolyam Gen2-elembe.
Adatfolyamatok
Az ügyfelek regionális katasztrófa esetén nem férhetnek hozzá az adatfolyamokhoz, és a konfigurációk nem replikálódnak a párosított régióba. Javasoljuk, hogy a kritikus fontosságú adatfolyamokat több munkaterületen, különböző régiókban építse fel.
Valós idejű intelligencia
Ez az útmutató végigvezeti a valós idejűintelligencia-élmény helyreállítási eljárásain. A KQL-adatbázisokra/lekérdezéskészletekre és eseménystreamekre terjed ki.
KQL-adatbázis/lekérdezéskészlet
A KQL-adatbázis/lekérdezéskészlet felhasználóinak proaktív intézkedéseket kell tenni a regionális katasztrófák elleni védelem érdekében. Az alábbi megközelítés biztosítja, hogy regionális katasztrófa esetén a KQL-adatbázisok lekérdezéskészleteiben lévő adatok biztonságosak és hozzáférhetőek maradnak.
Az alábbi lépésekkel garantálhatja a KQL-adatbázisok és lekérdezéskészletek hatékony vészhelyreállítási megoldását.
Független KQL-adatbázisok létrehozása: Konfiguráljon két vagy több független KQL-adatbázist/lekérdezéskészletet dedikált hálókapacitásokon. Ezeket két különböző Azure-régióban (lehetőleg Azure-párosított régióban) kell beállítani a rugalmasság maximalizálása érdekében.
Felügyeleti tevékenységek replikálása: Az egyik KQL-adatbázisban végrehajtott felügyeleti műveletet tükrözni kell a másikban. Ez biztosítja, hogy mindkét adatbázis szinkronban maradjon. A replikálandó legfontosabb tevékenységek a következők:
Táblák: Győződjön meg arról, hogy a táblastruktúrák és a sémadefiníciók konzisztensek az adatbázisokban.
Leképezés: A szükséges leképezések duplikálása. Győződjön meg arról, hogy az adatforrások és a célhelyek megfelelően igazodnak egymáshoz.
Szabályzatok: Győződjön meg arról, hogy mindkét adatbázis hasonló adatmegőrzési, hozzáférési és egyéb vonatkozó szabályzatokkal rendelkezik.
Hitelesítés és engedélyezés kezelése: Minden replikához állítsa be a szükséges engedélyeket. Győződjön meg arról, hogy megfelelő engedélyezési szintek vannak kialakítva, biztosítva a hozzáférést a szükséges személyzet számára a biztonsági szabványok fenntartása mellett.
Párhuzamos adatbetöltés: Ha több régióban szeretné konzisztensen és készen tartani az adatokat, töltse be ugyanazt az adatkészletet az egyes KQL-adatbázisokba a betöltéssel egyidejűleg.
Eventstream
Az eventstream egy központosított hely a Fabric platformon, ahol valós idejű eseményeket rögzíthet, alakíthat át és irányíthat különböző célhelyekre (például tóházakba, KQL-adatbázisokba/lekérdezésekbe) kód nélküli felülettel. Amíg a vészhelyreállítás támogatja a célhelyeket, az eseménystreamek nem veszítik el az adatokat. Ezért az ügyfeleknek ezen célrendszerek vészhelyreállítási képességeivel kell biztosítaniuk az adatok rendelkezésre állását.
Az ügyfelek georedundanciát is elérhetnek, ha azonos Eventstream-számítási feladatokat helyeznek üzembe több Azure-régióban egy többhelyes aktív/aktív stratégia részeként. Többhelyes aktív/aktív megközelítéssel az ügyfelek bármelyik üzembe helyezett régióban hozzáférhetnek a számítási feladataikhoz. Ez a megközelítés a vészhelyreállítás legösszetettebb és legköltségesebb megközelítése, de a legtöbb esetben a helyreállítási időt nullára csökkentheti. A teljes georedundánsság érdekében az ügyfelek
Az adatforrások replikáinak létrehozása különböző régiókban.
Eventstream-elemek létrehozása a megfelelő régiókban.
Csatlakozás ezeket az új elemeket az azonos adatforrásokhoz.
Adjon hozzá azonos célhelyeket az egyes eseménystreamekhez különböző régiókban.