Magyarázattípusok a Microsoft Syntex
A következőkre vonatkozik: ✓ Strukturálatlan dokumentumfeldolgozás
A magyarázatok segítségével meghatározhatja a strukturálatlan dokumentumfeldolgozási modellekben címkézni és kinyerni kívánt információkat a Microsoft Syntex. Magyarázat létrehozásakor ki kell választania egy magyarázattípust. Ez a cikk segít megérteni a különböző magyarázattípusokat és azok használatát.
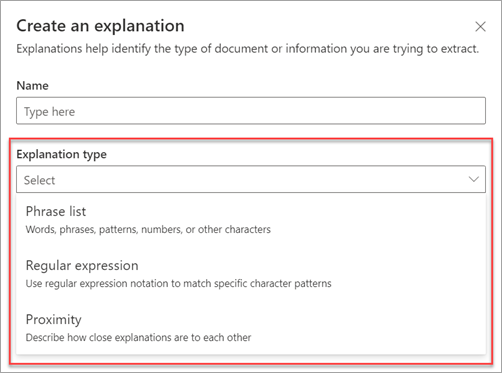
Ezek a magyarázattípusok érhetők el:
Kifejezéslista: Azoknak a szavaknak, kifejezéseknek, számoknak és egyéb karaktereknek a listája, amelyeket felhasználhat a kinyerni kívánt dokumentumban vagy információkban. Az orvosra hivatkozó szöveges sztring például az ön által azonosított összes orvosi javaslati dokumentumban szerepel. Vagy a beutaló orvos telefonszámát az ön által azonosított összes orvosi beutaló dokumentumból.
Reguláris kifejezés: Mintaegyeztetési jelölést használ adott karakterminták kereséséhez. Egy reguláris kifejezéssel például megkeresheti egy e-mail-címminta összes példányát egy dokumentumkészletben.
Közelség: Azt ismerteti, hogy milyen közel állnak egymáshoz a magyarázatok. Egy utcanév-kifejezéslista például közvetlenül az utcanév-kifejezéslista elé kerül, és nincs közötte token (a jelen cikk későbbi részében megismerheti a jogkivonatokat). A közelségi típus használatához legalább két magyarázatot kell megadnia a modellben, különben a beállítás le lesz tiltva.
Kifejezéslista
A kifejezéslista magyarázattípusa általában egy dokumentum azonosítására és besorolására szolgál a modellen keresztül. A hivatkozó orvos címkéjének példájában leírtak szerint ez egy olyan szavakból, kifejezésekből, számokból vagy karakterekből álló sztring, amely következetesen szerepel az Ön által azonosított dokumentumokban.
Bár nem követelmény, a magyarázattal jobb sikert érhet el, ha a rögzített kifejezés a dokumentumban konzisztens helyen található. Előfordulhat például, hogy a hivatkozó orvos címkéje következetesen a dokumentum első bekezdésében található. A dokumentum speciális beállításában a Kifejezések helyének konfigurálása beállítással is kijelölhet bizonyos területeket, ahol a kifejezés található, különösen akkor, ha fennáll annak az esélye, hogy a kifejezés a dokumentum több helyén is előfordul.
Ha a kis- és nagybetűk megkülönböztetése követelmény a címke azonosításában, a kifejezéslista típusának használatával megadhatja azt a magyarázatban a Csak a pontos kis- és nagybetűk jelölőnégyzet bejelölésével.

A kifejezéstípus különösen akkor hasznos, ha olyan magyarázatot hoz létre, amely különböző formátumban azonosítja és kinyeri az információkat, például dátumokat, telefonszámokat és hitelkártyaszámokat. Egy dátum például sokféle formátumban megjeleníthető (2020. 01. 01., 2020. 01. 01., 2020. 01. 01. vagy 2020. január 1.). A kifejezéslista definiálása hatékonyabbá teszi a magyarázatát az azonosítani és kinyerni kívánt adatok esetleges változatainak rögzítésével.
A telefonszámra vonatkozó példában minden egyes beutaló orvos telefonszámát ki kell nyernie a modell által azonosított összes orvosi javaslati dokumentumból. A magyarázat létrehozásakor írja be azokat a formátumokat, amelyeket egy telefonszám megjeleníthet a dokumentumban, hogy rögzíthesse a lehetséges változatokat.
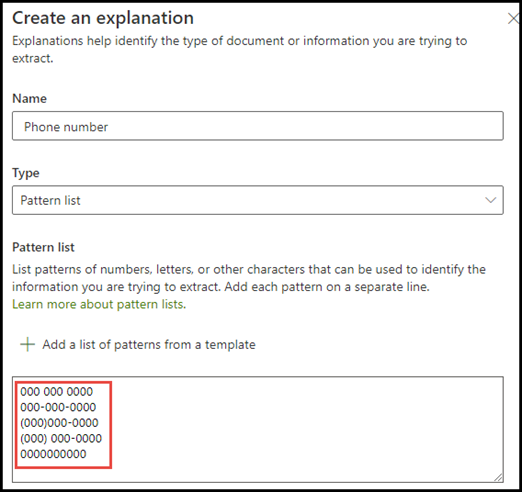
Ebben a példában a Speciális beállítások területen jelölje be a Bármely számjegy 0 és 9 között jelölőnégyzetet, hogy felismerje a kifejezéslistában használt "0" értékeket, hogy azok 0 és 9 közötti számjegyek legyenek.

Hasonlóképpen, ha szöveges karaktereket tartalmazó kifejezéslistát hoz létre, jelölje be a Bármely betű a-z-ből jelölőnégyzetet, hogy felismerje a kifejezéslistában használt minden "a" karaktert, hogy az "a" és a "z" karakter között bármilyen karakter legyen.
Ha például létrehoz egy dátumkifejezés-listát , és meg szeretne győződni arról, hogy a 2020. január 1 . dátumformátum felismerhető, a következőt kell tennie:
- Adja hozzá az aaa 0, 0000 és aaa 00, 0000 kifejezéseket a kifejezéslistához.
- Győződjön meg arról, hogy az a-z bármely betűje is ki van jelölve.

Ha a kifejezéslistában szerepelnek a nagybetűkre vonatkozó követelmények, jelölje be a Csak a pontos nagybetűk jelölőnégyzetet. Ha például a hónap első betűje nagybetűsre van állítva, akkor a következőt kell megadnia:
- Adja hozzá az Aaa 0, 0000 és Aaa 00, 0000 kifejezéseket a kifejezéslistához.
- Győződjön meg arról, hogy a Csak a pontos nagybetűk beállítás is ki van jelölve.

Megjegyzés:
Ahelyett, hogy manuálisan hoz létre kifejezéslistamagyarázatot, a magyarázattár használatával kifejezéslistasablonokat használhat egy gyakori kifejezéslistához, például dátumhoz, telefonszámhoz vagy hitelkártyaszámhoz.
Reguláris kifejezés
A reguláris kifejezésmagyarázat-típussal olyan mintákat hozhat létre, amelyek segítenek megtalálni és azonosítani bizonyos szöveges sztringeket a dokumentumokban. Reguláris kifejezésekkel gyorsan elemezhet nagy mennyiségű szöveget a következőre:
- Adott karakterminták keresése.
- Ellenőrizze, hogy a szöveg megfelel-e egy előre definiált mintának (például egy e-mail-címnek).
- Szövegrészek kinyerése, szerkesztése, cseréje vagy törlése.
A reguláris kifejezéstípus különösen akkor hasznos, ha olyan magyarázatot hoz létre, amely hasonló formátumú információkat azonosít és nyer ki, például e-mail-címeket, bankszámlaszámokat vagy URL-címeket. Egy e-mail-cím megan@contoso.compéldául egy bizonyos mintában jelenik meg ("megan" az első rész, a "com" pedig az utolsó rész).
Az e-mail-címek reguláris kifejezése: [A-Za-z0-9._%-]+@[A-Za-z0-9.-]+.[ A-Za-z]{2,6}.
Ez a kifejezés öt részből áll, ebben a sorrendben:
A következő karakterek tetszőleges száma:
a. Betűk a-tól z-ig
b. Számok 0 és 9 között
c. Pont, aláhúzásjel, százalék vagy kötőjel
A @ szimbólum
Az e-mail-cím első részével megegyező karakterek bármilyen mennyisége
Időszak
Két-hat betű
Reguláris kifejezésmagyarázat-típus hozzáadása:
A Magyarázat létrehozása panel Magyarázat típusa területén válassza a Reguláris kifejezés lehetőséget.
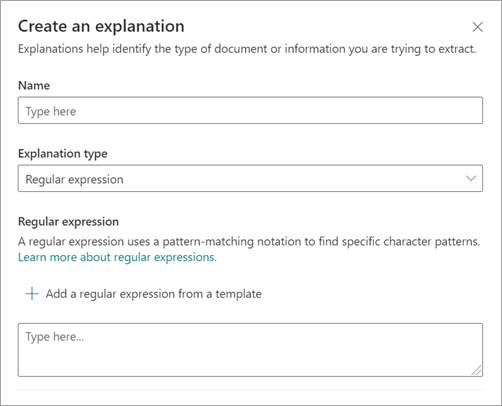
Beírhat egy kifejezést a Reguláris kifejezés szövegmezőbe, vagy kiválaszthatja a Reguláris kifejezés hozzáadása sablonból lehetőséget.
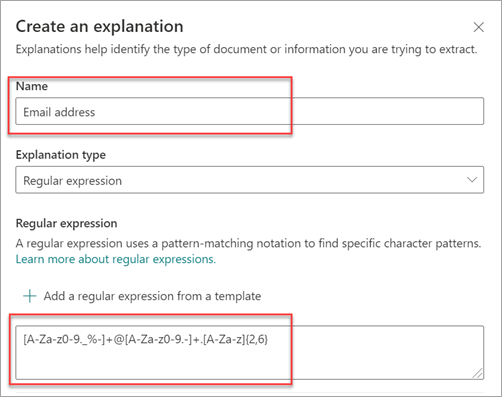
Ha sablon használatával ad hozzá reguláris kifejezést, az automatikusan hozzáadja a nevet és a reguláris kifejezést a szövegmezőhöz. Ha például a Email címsablont választja, a Magyarázat létrehozása panel lesz kitöltve.
Korlátozások
Az alábbi táblázat olyan beágyazott karakterbeállításokat mutat be, amelyek jelenleg nem használhatók a reguláris kifejezések mintáiban.
| Választási lehetőség | Állapot | Jelenlegi funkciók |
|---|---|---|
| Kis- és nagybetűk érzékenysége | Jelenleg nem támogatott. | Minden végrehajtott egyezés nem különbözteti meg a kis- és nagybetűket. |
| Vonalhorgonyok | Jelenleg nem támogatott. | Nem lehet megadni egy adott pozíciót egy sztringben, ahol egyezésnek kell történnie. |
Közelség
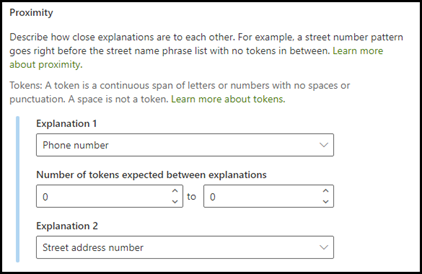
A közelségi magyarázat típusa segít a modellnek az adatok azonosításában azáltal, hogy meghatározza, milyen közel van hozzá egy másik adat. Tegyük fel például, hogy a modellben két olyan magyarázatot határozott meg, amelyek az ügyfél házszámát és telefonszámát is felcímkézik.
Figyelje meg, hogy az ügyfél telefonszámai mindig a házszám előtt jelennek meg.
Alex Wilburn
555-555-5555
One Microsoft Way
Redmond, WA 98034
A közelségi magyarázat segítségével meghatározhatja, hogy milyen messze van a telefonszám magyarázata, hogy jobban azonosíthassa az utcacímszámot a dokumentumokban.
Megjegyzés:
A reguláris kifejezések jelenleg nem használhatók a közelségi magyarázat típusával.
Mik azok a jogkivonatok?
A közelségi magyarázat típusának használatához meg kell értenie, hogy mi az a token. A tokenek száma az, hogy a közelségi magyarázat hogyan méri a távolságokat az egyik magyarázattól a másikig. A token betűk és számok folytonos kiterjedése (szóközöket és írásjeleket nem beleértve).
Az alábbi táblázat példákat mutat be a kifejezésekben lévő tokenek számának meghatározására.
| Frázis | Jogkivonatok száma | Magyarázat |
|---|---|---|
Dog |
1 | Egyetlen szó írásjelek és szóközök nélkül. |
RMT33W |
1 | Rekord lokátorszáma. Tartalmazhat számokat és betűket, de nem tartalmaz írásjeleket. |
425-555-5555 |
5 | Egy telefonszám. Minden írásjel egyetlen token, tehát 425-555-5555 5 token:425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
A közelségi magyarázat típusának konfigurálása
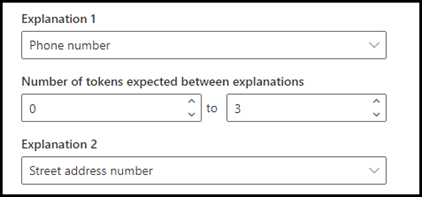
A példában konfigurálja a közelségi beállítást úgy, hogy meghatározza a telefonszám magyarázatában szereplő tokenek számtartományát a házszám magyarázatából . Figyelje meg, hogy a minimális tartomány "0", mivel a telefonszám és a házszám között nincs token.
A mintadokumentumokban szereplő telefonszámok egy része azonban hozzá van fűzve a (mobil)-hez.
Nestor Wilke
111-111-1111 (mobil)
One Microsoft Way
Redmond, WA 98034
A (mobil)-ban három token található:
| Frázis | Jogkivonatok száma |
|---|---|
| ( | 1 |
| mobil | 2 |
| ) | 3 |
Konfigurálja úgy a közelségi beállítást, hogy a tartománya 0 és 3 között legyen.
Kifejezések előfordulásának konfigurálása a dokumentumban
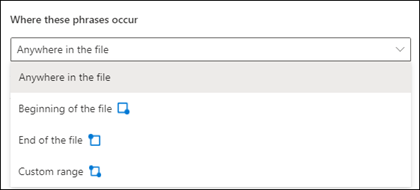
Magyarázat létrehozásakor a rendszer alapértelmezés szerint a teljes dokumentumban megkeresi a kinyerni kívánt kifejezést. A Where these phrases occur speciális beállítással azonban elkülönítheti a dokumentumban egy adott helyet, ahol egy kifejezés előfordul. Ez a beállítás olyan helyzetekben hasznos, amikor egy kifejezés hasonló példányai megjelenhetnek valahol a dokumentumban, és meg szeretné győződni arról, hogy a megfelelőt választotta ki.
Az Orvosi beutaló dokumentum példájára hivatkozva a hivatkozó orvost mindig megemlítik a dokumentum első bekezdésében. A Where these phrases occur (Hol fordulnak elő ezek a kifejezések ) beállítással ebben a példában úgy konfigurálhatja a magyarázatát, hogy csak a dokumentum első szakaszában vagy bármely más helyen keressen rá erre a címkére.
Ehhez a beállításhoz a következő lehetőségek közül választhat:
Bárhol a fájlban: A rendszer a teljes dokumentumra rákeres a kifejezésre.
A fájl kezdete: A rendszer az elejétől a kifejezés helyére keres a dokumentumban.
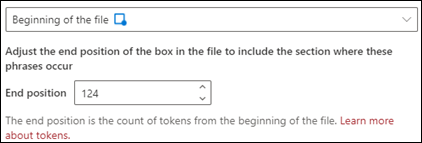
A megjelenítőben manuálisan módosíthatja a választómezőt, hogy tartalmazza a fázis helyét. A Végpozíció érték frissül, hogy megjelenítse a kijelölt terület tokenjeinek számát. A Kijelölt terület módosításához a Záró pozíció értékét is módosíthatja.
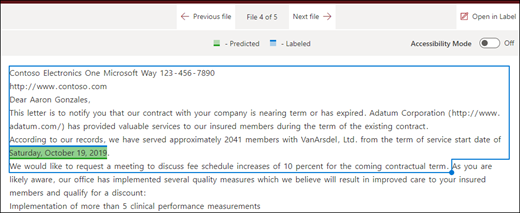
A fájl vége: A dokumentum a végétől a kifejezés helyénekig keres.
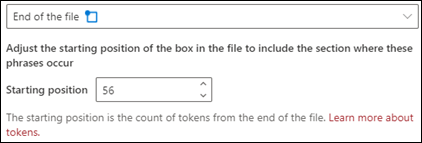
A megjelenítőben manuálisan módosíthatja a választómezőt, hogy tartalmazza a fázis helyét. A Kezdő pozíció érték frissül, hogy megjelenítse a kijelölt terület tokenjeinek számát. A Kezdő pozíció értékét is frissítheti a kijelölt terület módosításához.

Egyéni tartomány: A dokumentum egy megadott tartományon belül keres a kifejezés helyeként.
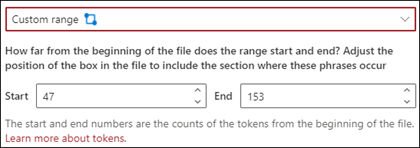
A megjelenítőben manuálisan módosíthatja a választómezőt, hogy tartalmazza a fázis helyét. Ehhez a beállításhoz ki kell választania egy Kezdő és egy Záró pozíciót. Ezek az értékek a dokumentum elejéről származó tokenek számát jelölik. Bár manuálisan is beírhatja ezeket az értékeket, egyszerűbb manuálisan módosítani a választómezőt a megtekintőben.
Magyarázatok konfigurálásakor megfontolandó szempontok
Az osztályozók betanításakor figyelembe kell venni néhány dolgot, amelyek kiszámíthatóbb eredményeket eredményeznek:
Minél több dokumentumot tanít be, annál pontosabb lesz az osztályozó. Ha lehetséges, használjon ötnél több jó dokumentumot, és használjon egynél több rossz dokumentumot. Ha a kódtárakban több különböző dokumentumtípus található, az egyes típusok közül több is kiszámíthatóbb eredményeket eredményez.
A dokumentum címkézése fontos szerepet játszik a betanítási folyamatban. Ezeket a modell betanítása magyarázatokkal együtt használják. Előfordulhat, hogy rendellenességek jelennek meg, amikor egy osztályozót olyan dokumentumokkal képez be, amelyekben nincs sok tartalom. Előfordulhat, hogy a magyarázat nem felel meg a dokumentumban szereplő adatoknak, de mivel "jó" dokumentumként címkézték, előfordulhat, hogy a betanítás során egyezésnek látja.
Magyarázatok létrehozásakor a VAGY logikát használja a címkével együtt annak meghatározásához, hogy egyezés-e. Az AND logikát használó reguláris kifejezés kiszámíthatóbb lehet. Íme egy reguláris kifejezésminta, amelyet valós dokumentumokon használhat betanításként. Figyelje meg, hogy a pirossal kiemelt szöveg a keresett kifejezés vagy kifejezés.
(?=.*network provider)(?=.*participating providers).*
A címkék és magyarázatok együtt működnek, és a modell betanításához használhatók. Ez nem olyan szabálysorozat, amely összekapcsolható, és pontos súlyozást vagy előrejelzést alkalmazhat az egyes konfigurált változókra. Minél nagyobb a betanításban használt dokumentumok variációja, annál pontosabb lesz a modell.