Felhasználó által definiált összesítések
A Power BI összesítése javíthatja a lekérdezési teljesítményt a nagy DirectQuery szemantikai modelleken. Az aggregációk használatával a memóriában lévő összesített szinten gyorsítótárazhatja az adatokat. A Power BI aggregációi manuálisan konfigurálhatók az adatmodellben, a jelen cikkben leírtak szerint. Prémium szintű előfizetések esetén automatikusan engedélyezze az Automatikus összesítések funkciót a modell Gépház.
Összesítő táblák létrehozása
Az adatforrás típusától függően egy aggregációs tábla hozható létre az adatforrásban táblaként vagy nézetként, natív lekérdezésként. A legnagyobb teljesítmény érdekében hozzon létre egy aggregációs táblát importálási táblaként, amelyet a Power Queryben hoztak létre. Ezután a Power BI Desktop Összesítések kezelése párbeszédpaneljével összesítési, részlettáblázati és részletoszlop-tulajdonságokat tartalmazó összesítéseket határozhat meg az összesítő oszlopokhoz.
A dimenziós adatforrások, például az adattárházak és az adattárházak kapcsolatalapú összesítéseket használhatnak. A Hadoop-alapú big data-források gyakran GroupBy-oszlopokra alapozza az összesítéseket. Ez a cikk a Power BI adatmodellezési különbségeit ismerteti az egyes adatforrástípusok esetében.
Összesítések kezelése
Bármely Power BI Desktop-nézet Adat ablaktábláján kattintson a jobb gombbal az aggregációk táblára, majd válassza a Manage aggregations (Összesítések kezelése) lehetőséget.
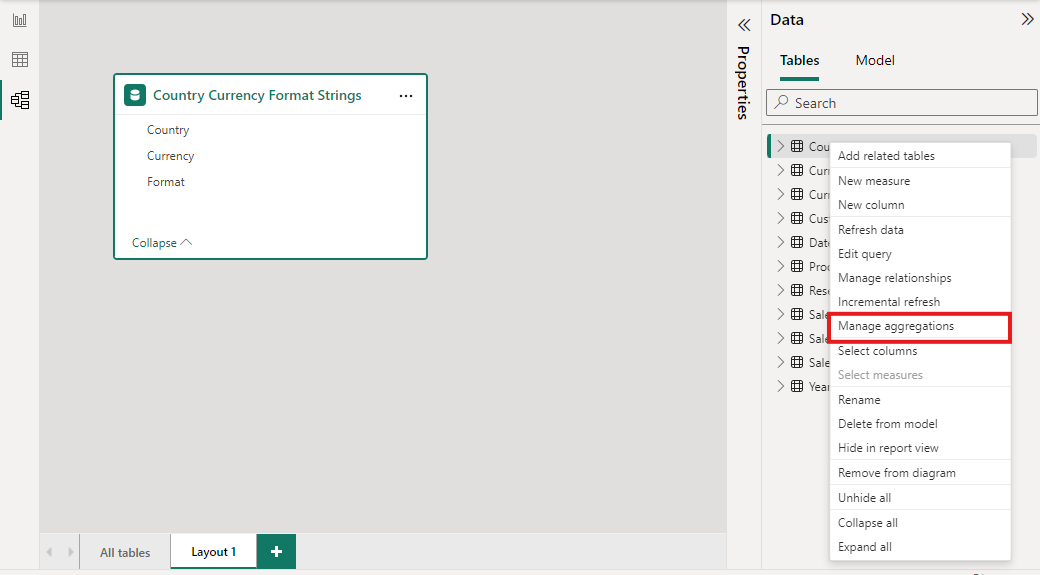
Az aggregációk kezelése párbeszédpanelen a táblázat minden oszlopának egy-egy sora látható, ahol megadhatja az összesítés viselkedését. Az alábbi példában a Sales detail táblába küldött lekérdezések belsőleg a Sales Agg aggregation táblába lesznek átirányítva.
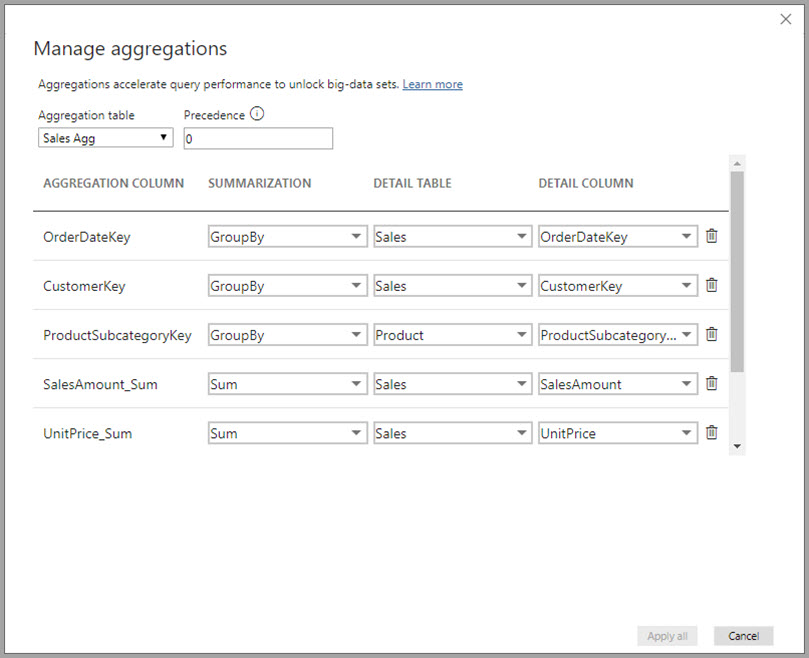
Ebben a kapcsolatalapú összesítési példában a GroupBy-bejegyzések nem kötelezőek. A DISTINCTCOUNT kivételével ezek nem befolyásolják az összesítés viselkedését, és elsősorban az olvashatóságra vonatkoznak. A GroupBy-bejegyzések nélkül az összesítések továbbra is találatot kapnak a kapcsolatok alapján. Ez eltér a jelen cikk későbbi, big data-példájától , ahol a GroupBy-bejegyzésekre van szükség.
Ellenőrzések
Az Összesítések kezelése párbeszédpanel érvényesíti az érvényesítést:
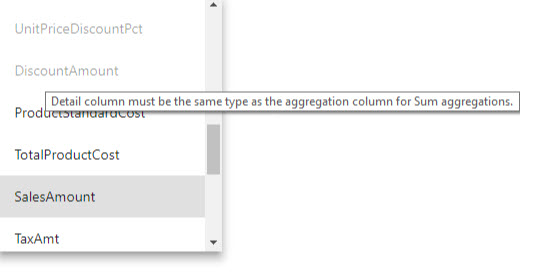
- A Részlet oszlopnak ugyanazzal az adattípussal kell rendelkeznie, mint az Aggregációs oszlop, kivéve a Darabszám és a Darabszám táblasorok összegzési függvényét. A Count and Count táblasorok csak egész szám aggregációs oszlopokhoz érhetők el, és nem igényelnek egyező adattípust.
- A három vagy több táblát lefedő láncolt aggregációk nem engedélyezettek. Az A táblában lévő aggregációk például nem hivatkozhatnak olyan B táblára, amely a C táblára hivatkozó összesítéseket tartalmaz.
- Az ismétlődő összesítések, amelyekben két bejegyzés ugyanazt az összegző függvényt használja, és ugyanarra a részlettáblára és részletoszlopra hivatkozik, nem engedélyezett.
- A részlettáblának DirectQuery tárolási módot kell használnia, nem importálást.
- Az inaktív kapcsolat által használt idegenkulcs-oszlop szerinti csoportosítás és az aggregációs találatok U Standard kiadás RELATIONSHIP függvényére való támaszkodás nem támogatott.
- A GroupBy-oszlopokon alapuló összesítések használhatják az összesítő táblák közötti kapcsolatokat, de az összesítő táblák közötti létrehozási kapcsolatok nem támogatottak a Power BI Desktopban. Szükség esetén kapcsolatokat hozhat létre az aggregációs táblák között egy külső eszköz vagy egy szkriptelési megoldás használatával az XML for Analysis (XMLA) végpontjaival.
A legtöbb ellenőrzés a legördülő értékek letiltásával és az elemleírás magyarázó szövegének megjelenítésével kényszeríthető ki.
Az összesítő táblák rejtettek
A modellhez írásvédett hozzáféréssel rendelkező felhasználók nem tudják lekérdezni az összesítő táblákat. Az írásvédett hozzáférés elkerüli a sorszintű biztonság (RLS) használatakor felmerülő biztonsági problémákat. A fogyasztók és a lekérdezések a részletes táblára hivatkoznak, nem az összesítő táblára, és nem kell tudniuk az aggregációs tábláról.
Ezért az összesítő táblák rejtettek a Jelentés nézetből. Ha a tábla még nincs elrejtve, az összesítés kezelése párbeszédpanel rejtettre állítja, amikor az Összes alkalmazása lehetőséget választja.
Tárolási módok
Az összesítési funkció a táblaszintű tárolási módokkal működik együtt. A Power BI-táblák DirectQuery, Import vagy Kettős tárolási módokat használhatnak. A DirectQuery közvetlenül lekérdezi a háttérrendszert, míg az Importálás gyorsítótárazza az adatokat a memóriában, és lekérdezéseket küld a gyorsítótárazott adatoknak. Minden Power BI-importálási és nem többdimenziós DirectQuery-adatforrás együttműködhet az aggregációkkal.
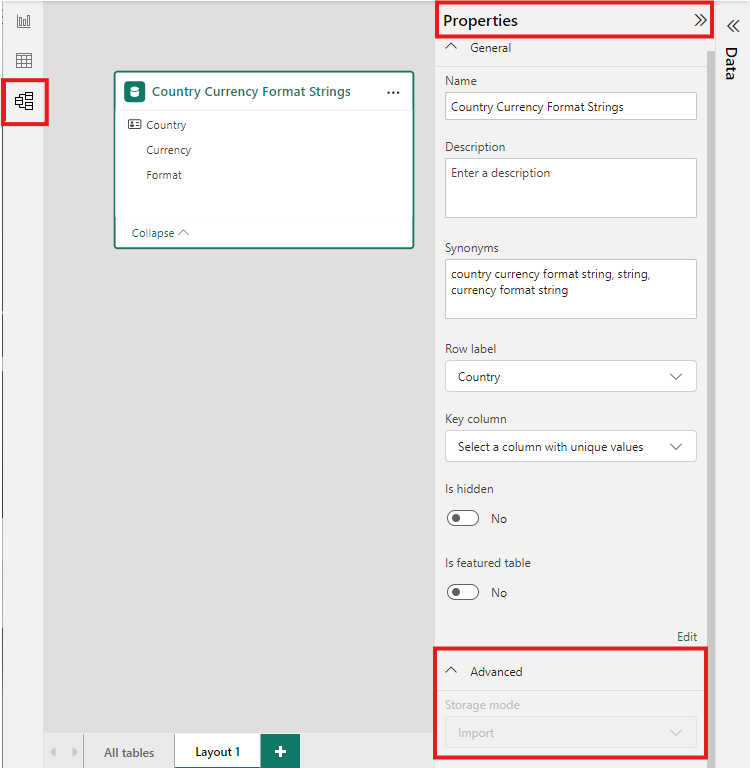
Ha egy összesített tábla tárolási módját importálásra szeretné állítani a lekérdezések felgyorsításához, válassza ki az összesített táblát a Power BI Desktop Modell nézetben. A Tulajdonságok panelen bontsa ki a Speciális elemet, legördülő listából válassza a Tárolási mód lehetőséget, majd válassza az Importálás lehetőséget. Az Importálás módosítása visszavonhatatlan.
A táblázatos tárolási módokkal kapcsolatos további információkért lásd a Tárolási mód kezelése a Power BI Desktopban című témakört.
RLS aggregációkhoz
Az összesítések megfelelő működéséhez az RLS-kifejezéseknek szűrnie kell az összesítő táblát és a részlettáblát.
Az alábbi példában a Geography tábla RLS-kifejezése aggregációkhoz használható, mivel a Geography a Sales és a Sales Agg táblához való kapcsolatok szűrési oldalán található. Az összesítő táblát elérő lekérdezések és az RLS-t nem sikeresen alkalmazó lekérdezések.
A Termék tábla RLS-kifejezései csak a részletes Sales táblát szűrik, az összesített Sales Agg táblát nem. Mivel az aggregációs tábla egy másik adatábrázolás a részlettáblában, nem lenne biztonságos a lekérdezések megválaszolása az aggregációs táblából, ha az RLS-szűrő nem alkalmazható. Nem ajánlott csak a részlettáblát szűrni, mert az ebből a szerepkörből származó felhasználói lekérdezések nem részesülnek az összesítési találatok előnyeiből.
Nem engedélyezett olyan RLS-kifejezés, amely csak a Sales Agg aggregation táblát szűri, a Sales detail táblát nem.
A GroupBy-oszlopokon alapuló összesítések esetében a részlettáblára alkalmazott RLS-kifejezés használható az aggregációs tábla szűrésére, mivel az aggregációs tábla Összes GroupBy-oszlopát lefedi a részlettábla. Az aggregációs táblán lévő RLS-szűrő azonban nem alkalmazható a részlettáblára, ezért nincs engedélyezve.
Kapcsolatokon alapuló összesítés
A dimenziós modellek általában kapcsolatokon alapuló összesítéseket használnak. Az adattárházakból és adattárházakból származó Power BI-modellek a csillag-/hópehely sémákhoz hasonlítanak, dimenziótáblák és ténytáblák közötti kapcsolatokkal.
Az alábbi példában a modell egyetlen adatforrásból szerez be adatokat. A táblák DirectQuery tárolási módot használnak. Az Értékesítési ténytábla több milliárd sort tartalmaz. Az Értékesítések importálás tárolási módjának gyorsítótárazáshoz való beállítása jelentős memóriát és erőforrásokat vonna maga után.
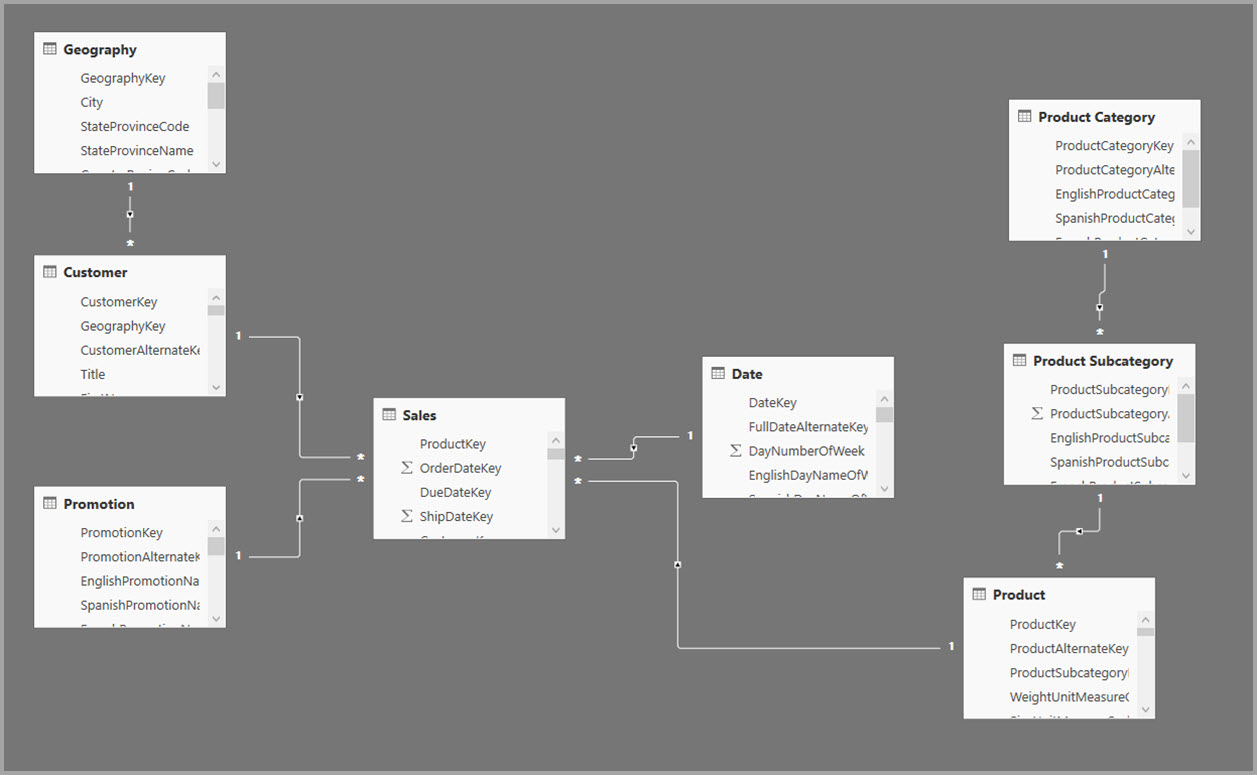
Ehelyett hozza létre a Sales Agg aggregation táblát. A Sales Agg táblában a sorok száma megegyezik a CustomerKey, a DateKey és a ProductSubcategoryKey szerint csoportosított SalesAmount összegével. A Sales Agg tábla nagyobb részletességgel rendelkezik, mint a Sales, így milliárdok helyett több millió sort tartalmazhat, amelyek könnyebben kezelhetők.
Ha a következő dimenziótáblákat használják leggyakrabban a magas üzleti értékkel rendelkező lekérdezésekhez, akkor a Sales Agget szűrhetik egy-a-többhöz vagy több-az-egyhez kapcsolatok használatával.
- Földrajzi hely
- Vevő
- Dátum
- Termékalkategória
- Termékkategória
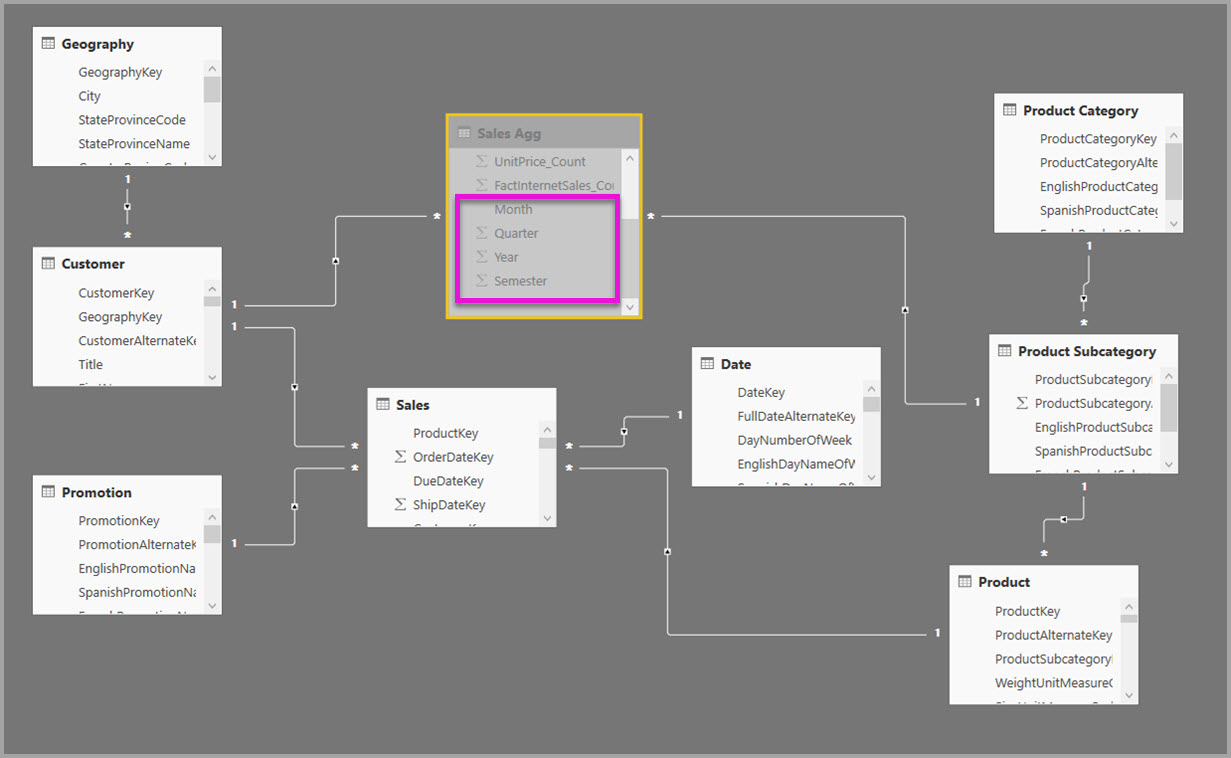
Az alábbi képen ez a modell látható.
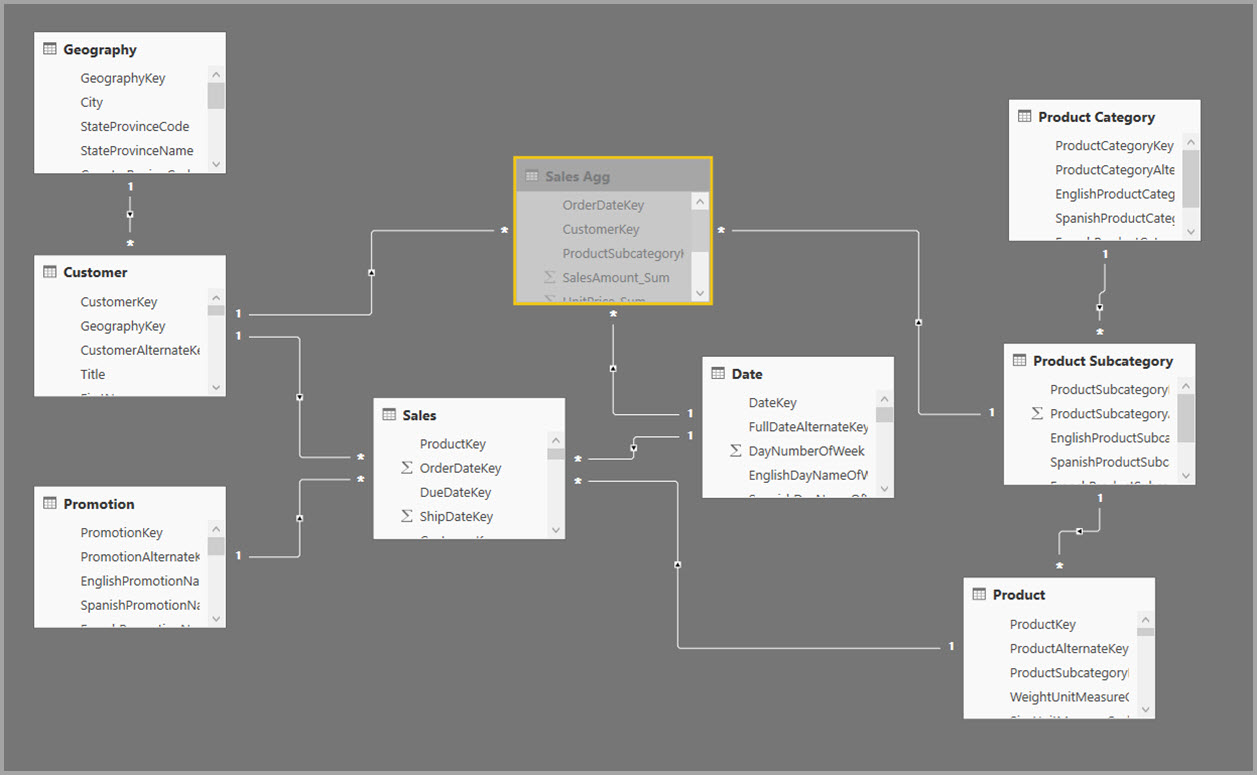
Az alábbi táblázat a Sales Agg tábla aggregációit mutatja be.
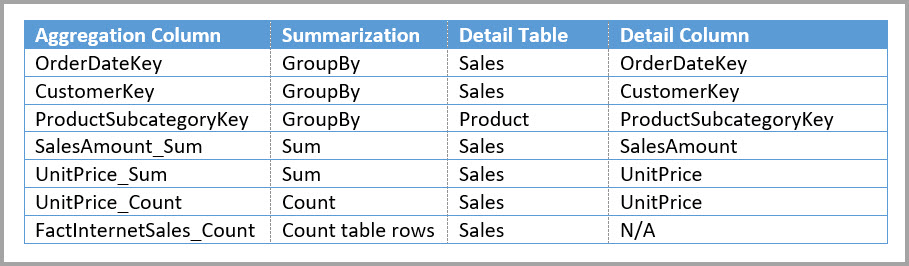
Feljegyzés
A Sales Agg tábla, mint bármely tábla, rugalmasan tölthető be különböző módokon. Az aggregáció a forrásadatbázisban ETL/ELT-folyamatokkal vagy a tábla M kifejezésével hajtható végre. Az összesített tábla használhatja az Importálás tárolási módot a szemantikai modellek növekményes frissítésével vagy anélkül, vagy használhatja a DirectQueryt, és oszlopcentrikus indexek használatával optimalizálható gyors lekérdezésekhez. Ez a rugalmasság lehetővé teszi a kiegyensúlyozott architektúrákat, amelyek a szűk keresztmetszetek elkerülése érdekében elosztják a lekérdezési terhelést.
Az összesített Értékesítési aggregátum tábla tárolási módjának importálásravaló módosításakor megnyílik egy párbeszédpanel, amely azt jelzi, hogy a kapcsolódó dimenziótáblák kettős tárolási módra állíthatók be.
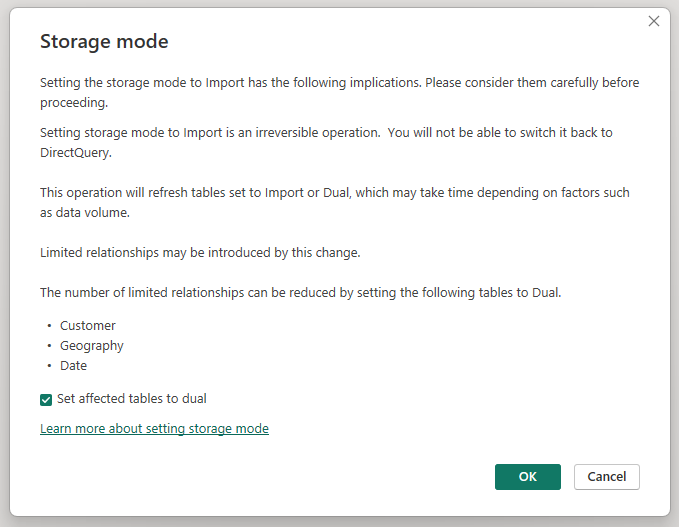
A kapcsolódó dimenziótáblák Kettős értékre állítása lehetővé teszi, hogy az alkikérdezéstől függően importálásként vagy DirectQueryként működjenek. A példában:
- Az importálási módú Sales Agg tábla metrikáit összesítő lekérdezések, valamint a kapcsolódó kettős táblák attribútuma(i) alapján csoportosított lekérdezések a memóriabeli gyorsítótárból adhatók vissza.
- A DirectQuery Sales tábla metrikáit összesítő lekérdezések, valamint a kapcsolódó kettős táblák attribútuma(i) alapján csoportosított lekérdezések DirectQuery módban is visszaadhatók. A lekérdezési logika, beleértve a GroupBy-műveletet is, a forrásadatbázisnak lesz átadva.
A kettős tárolási módról további információt a Power BI Desktop tárolási módjának kezelése című témakörben talál.
Normál és korlátozott kapcsolatok
A kapcsolatokon alapuló összesítési találatok rendszeres kapcsolatokat igényelnek.
A normál kapcsolatok a következő tárolási mód kombinációit tartalmazzák, ahol mindkét tábla egyetlen forrásból származik:
| Táblázat a több oldalon | Táblázat az 1 oldalon |
|---|---|
| Kettős | Kettős |
| Importálás | Importálás vagy kettős |
| DirectQuery | DirectQuery vagy Kettős |
A forrásközi kapcsolat csak akkor tekinthető szabályosnak, ha mindkét tábla Importálás értékre van állítva. A több-a-többhöz kapcsolatok mindig korlátozottak.
A kapcsolatoktól nem függő forrásközi összesítési találatokért tekintse meg a GroupBy-oszlopokon alapuló összesítéseket.
Kapcsolatalapú összesítési lekérdezési példák
Az alábbi lekérdezés az aggregációt éri el, mert a Dátum tábla oszlopai olyan részletesek, amelyek az összesítést elérhetik. A SalesAmount oszlop az Összeg aggregációt használja.

Az alábbi lekérdezés nem éri el az összesítést. A SalesAmount összegének kérése ellenére a lekérdezés Egy GroupBy műveletet hajt végre a Product tábla egyik oszlopán, amely nem olyan részletes, amely eléri az összesítést. Ha megfigyeli a modell kapcsolatait, egy termék alkategóriája több Terméksort is tartalmazhat. A lekérdezés nem tudja meghatározni, hogy melyik termékhez kell összesíteni. Ebben az esetben a lekérdezés visszaáll a DirectQueryre, és elküld egy SQL-lekérdezést az adatforrásnak.

Az aggregációk nem csak egyszerű számításokhoz használhatók, amelyek egyszerű összegeket hajtanak végre. Az összetett számítások is hasznosak lehetnek. Elméletileg egy összetett számítás minden SZUM, MIN, MAX és DARAB részösszetettre van bontva. A rendszer kiértékeli az egyes al lekérdezéseket, hogy megállapítsa, hogy az eléri-e az aggregációt. Ez a logika nem minden esetben igaz a lekérdezésterv optimalizálása miatt, de általában alkalmazni kell. Az alábbi példa az összesítésre mutat:

A COUNTROWS függvény kihasználhatja az összesítések előnyeit. Az alábbi lekérdezés azért éri el az aggregációt, mert a Sales táblához egy Darabszám táblasor-összesítésvan definiálva.

Az ÁTLAG függvény kihasználhatja az aggregációkat. Az alábbi lekérdezés azért éri el az aggregációt, mert az ÁTLAG belsőleg össze van hajtva egy DARABTEL osztva. Mivel a UnitPrice oszlop a SZUM és a DARAB függvényhez is definiált összesítéseket tartalmaz, a rendszer az összesítést eléri.

Bizonyos esetekben a DISTINCTCOUNT függvény kihasználhatja az összesítések előnyeit. Az alábbi lekérdezés azért éri el az aggregációt, mert a CustomerKey egy GroupBy bejegyzést tartalmaz, amely fenntartja a CustomerKey különbözőségét az aggregációs táblában. Ez a technika még mindig eléri a teljesítményküszöböt, ahol több mint két-öt millió különböző érték befolyásolhatja a lekérdezés teljesítményét. Olyan helyzetekben azonban hasznos lehet, amikor több milliárd sor található a részlettáblában, de az oszlopban két-öt millió különböző érték van. Ebben az esetben a DISTINCTCOUNT gyorsabb, mint a tábla több milliárd sorból álló vizsgálata, még akkor is, ha a memóriába gyorsítótárazták.

Az adatelemzési kifejezések (DAX) időintelligencia-függvényei az aggregációval tisztában vannak. Az alábbi lekérdezés azért éri el az aggregációt, mert a DATESYTD függvény létrehoz egy Naptárnap értékeket tartalmazó táblát, és az aggregációs tábla részletességben van, amely a Dátum tábla csoportosítási oszlopaihoz tartozik. Ez egy példa egy táblaértékű szűrőre a CALCULATE függvényre, amely képes az összesítések használatára.

Csoportosítási oszlopok alapján történő összesítés
A Hadoop-alapú big data modellek különböző jellemzőkkel rendelkeznek, mint a dimenziómodellek. A nagy táblák közötti illesztések elkerülése érdekében a big data modellek gyakran nem használnak kapcsolatokat, hanem denormalizálják a dimenzióattribútumokat a ténytáblákban. Az ilyen big data-modelleket interaktív elemzéshez a GroupBy-oszlopokon alapuló összesítések használatával oldhatja fel.
Az alábbi táblázat az összesítendő Mozgás numerikus oszlopot tartalmazza. Az összes többi oszlop olyan attribútum, amely szerint csoportosítható. A táblázat IoT-adatokat és nagy számú sort tartalmaz. A tárolási mód DirectQuery. Az adatforrás lekérdezései, amelyek a teljes modellben aggregátumot aggregáltak, a nagy mennyiségű adatmennyiség miatt lassúak.
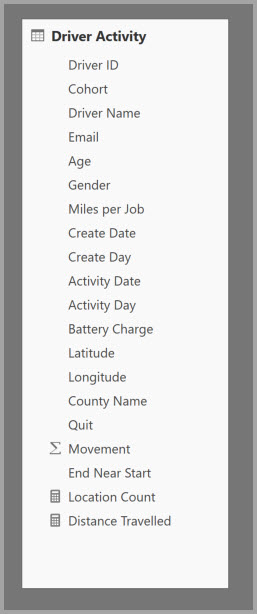
Ha interaktív elemzést szeretne engedélyezni ezen a modellen, hozzáadhat egy összesítő táblát, amely a legtöbb attribútum szerint csoportosít, de kizárja a magas számosságú attribútumokat, például a hosszúságot és a szélességet. Ez jelentősen csökkenti a sorok számát, és elég kicsi ahhoz, hogy kényelmesen elférjen a memóriabeli gyorsítótárban.
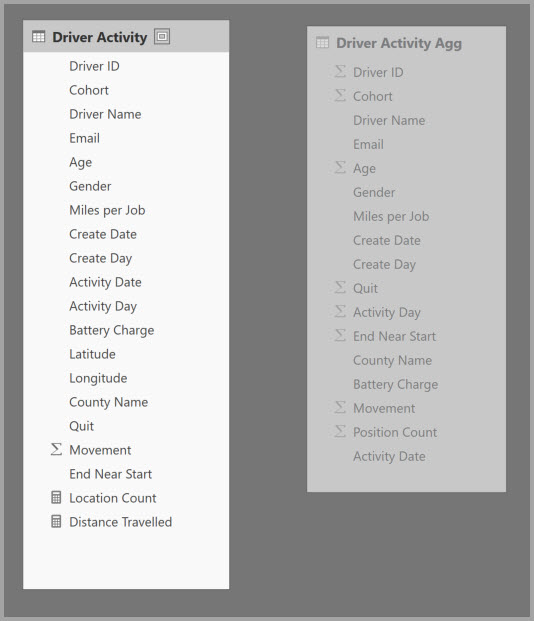
A Driver Activity Agg tábla összesítési leképezéseit az Összesítések kezelése párbeszédpanelen határozhatja meg.
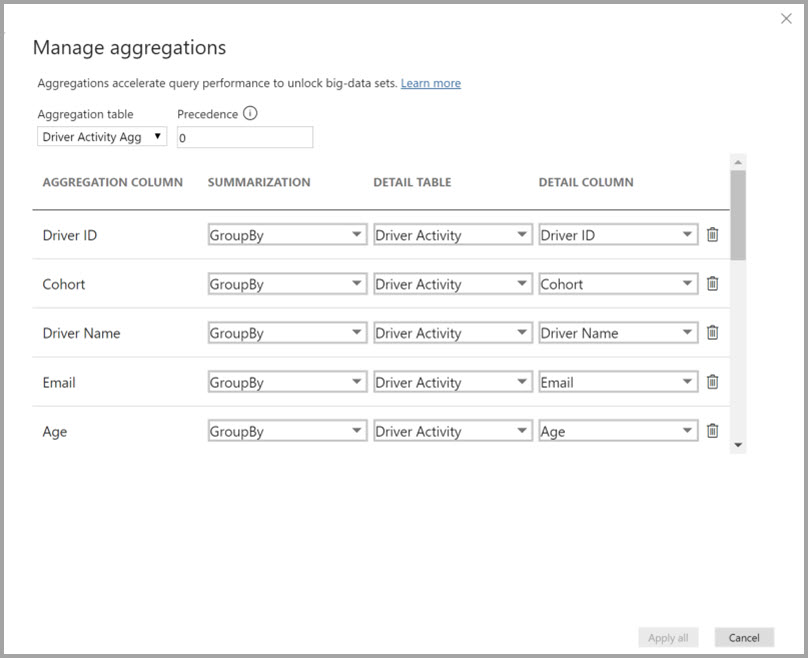
A GroupBy oszlopokon alapuló összesítésekben a GroupBy-bejegyzések nem választhatók. Nélkülük az összesítések nem lesznek találatok. Ez eltér a kapcsolatokon alapuló aggregációktól, ahol a GroupBy-bejegyzések megadása nem kötelező.
Az alábbi táblázat a Driver Activity Agg tábla összesítéseit mutatja be.
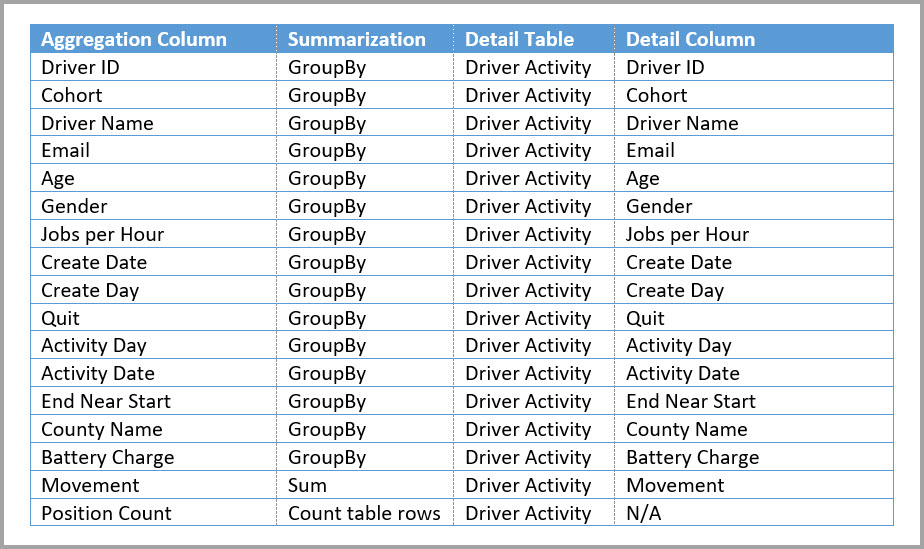
Az összesített Driver Activity Agg tábla tárolási módját importálásra állíthatja.
GroupBy aggregation query example
Az alábbi lekérdezés az aggregációt éri el, mert a Tevékenység dátuma oszlopot az összesítő tábla fedi le. A COUNTROWS függvény a Megszámlált táblasorok aggregációt használja.

Különösen a ténytáblákban szűrőattribútumokat tartalmazó modellek esetében érdemes a Count táblasor-összesítéseket használni. A Power BI a COUNTROWS használatával küldhet lekérdezéseket a modellnek olyan esetekben, amikor a felhasználó nem kéri kifejezetten. A szűrő párbeszédpanelen például az egyes értékek sorainak száma látható.
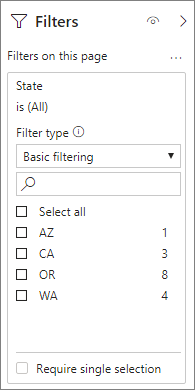
Kombinált összesítési technikák
Kombinálhatja a kapcsolatokat és a GroupBy oszloptechnikákat az összesítésekhez. A kapcsolatokon alapuló összesítésekhez szükség lehet a denormalizált dimenziótáblák több táblára való felosztására. Ha ez költséges vagy nem praktikus bizonyos dimenziótáblák esetében, replikálhatja a szükséges attribútumokat az aggregációs táblában ezekhez a dimenziókhoz, és használhat kapcsolatokat mások számára.
Az alábbi modell például a Sales Agg táblában replikálja a Hónap, a Negyedév, a Félév és az Év elemet. Nincs kapcsolat a Sales Agg és a Date tábla között, de az Ügyfél és a Termék alkategóriához vannak kapcsolatok. A Sales Agg tárolási módja az Importálás.
Az alábbi táblázat a Sales Agg tábla Összesítések kezelése párbeszédpaneljén beállított bejegyzéseket mutatja be. A GroupBy azon bejegyzései, amelyekben a Dátum a részletes tábla kötelező, a Dátum attribútumok szerint csoportosított lekérdezések összesítéseinek eléréséhez kötelező megadni. Az előző példához hasonlóan a CustomerKey és a ProductSubcategoryKey GroupBy bejegyzései nem befolyásolják az aggregációs találatokat, a DISTINCTCOUNT kivételével, a kapcsolatok jelenléte miatt.
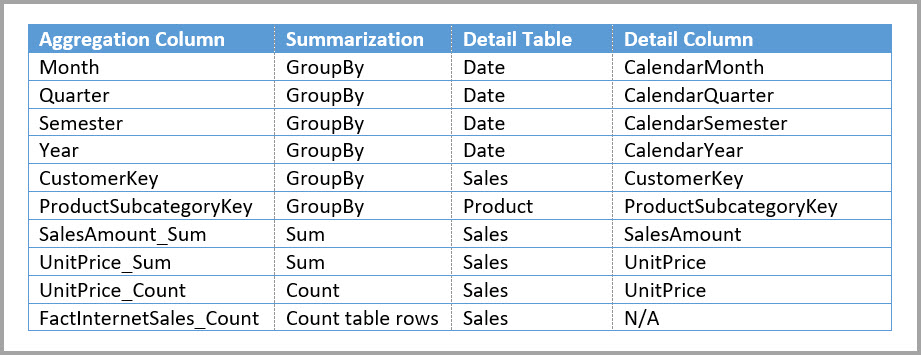
Kombinált aggregációs lekérdezési példák
Az alábbi lekérdezés az aggregációt érinti, mivel az összesítő tábla a CalendarMonthot fedi le, a CategoryName pedig egy-a-többhöz kapcsolatokon keresztül érhető el. A SalesAmount a SZUM összesítést használja.

Az alábbi lekérdezés nem éri el az aggregációt, mert az összesítő tábla nem fedi le a CalendarDayt.

A következő időintelligencia-lekérdezés nem éri el az aggregációt, mert a DATESYTD függvény létrehoz egy CalendarDay értékekből álló táblát, és az aggregációs tábla nem fedi le a CalendarDayt.

Az aggregáció elsőbbsége
Az aggregáció elsőbbsége lehetővé teszi, hogy több aggregációs táblát is figyelembe vehessenek egyetlen al lekérdezésben.
Az alábbi példa egy több forrást tartalmazó összetett modell :
- Az Illesztőprogram-tevékenység DirectQuery táblája több mint több ezer sornyi, big data-rendszerből származó IoT-adatot tartalmaz. Részletező lekérdezéseket kínál az egyes IoT-értékek ellenőrzött szűrőkörnyezetekben való megtekintéséhez.
- A Driver Activity Agg tábla egy köztes összesítő tábla DirectQuery módban. Több mint egy milliárd sort tartalmaz az Azure Synapse Analyticsben (korábban SQL Data Warehouse), és oszlopcentrikus indexek használatával optimalizálja a forrásra.
- A Driver Activity Agg2 Import tábla nagy részletességgel rendelkezik, mivel a csoportosítási attribútumok kevések és alacsony számosságúak. A sorok száma akár több ezer is lehet, így könnyen beilleszthető egy memóriabeli gyorsítótárba. Ezeket az attribútumokat egy magas szintű vezetői irányítópult használja, ezért az rájuk hivatkozó lekérdezéseknek a lehető leggyorsabban kell lenniük.
Feljegyzés
Azok a DirectQuery-aggregációs táblák, amelyek a részlettáblától eltérő adatforrást használnak, csak akkor támogatottak, ha az összesítő tábla SQL Server, Azure SQL vagy Azure Synapse Analytics -forrásból (korábbi nevén SQL Data Warehouse) származik.
A modell memóriaigénye viszonylag kicsi, de egy hatalmas modellt old fel. Kiegyensúlyozott architektúrát képvisel, mivel a lekérdezési terhelést az architektúra összetevőire osztva, az erősségeik alapján használja fel őket.

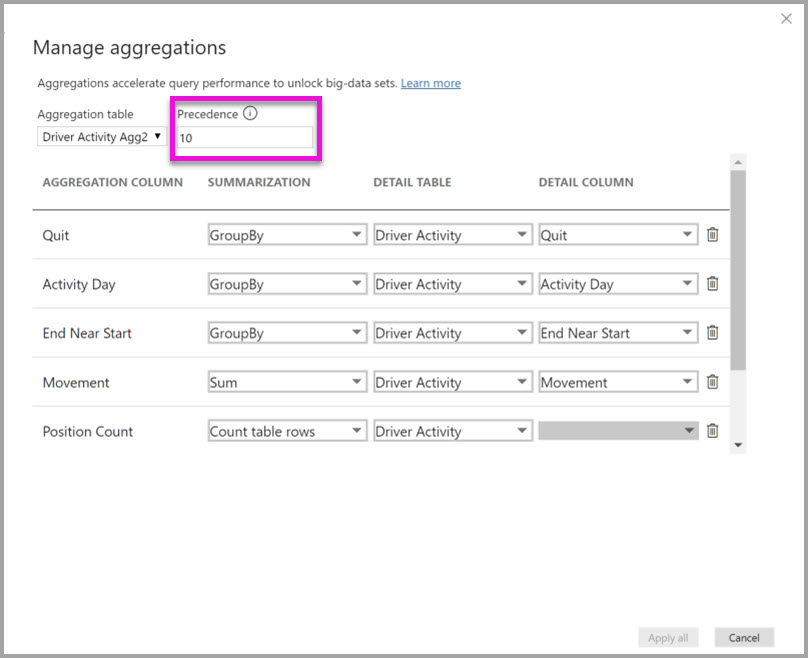
Az Illesztőprogram-tevékenység Agg2 felügyelt aggregációk párbeszédpanelje az Elsőbbség mezőt 10-es értékre állítja, ami magasabb, mint a Driver Activity Agg esetében. A magasabb elsőbbségi beállítás azt jelenti, hogy az összesítést használó lekérdezések elsőként az Illesztőprogram-tevékenység Agg2-t veszik figyelembe. Az Agg2 illesztőprogram-tevékenység által megválaszolható részletességi szinten nem szereplő albekérdezések inkább a Driver Activity Agg függvényt vehetik figyelembe. Az összesítő tábla által nem megválaszolható részletes lekérdezések közvetlenül az illesztőprogram-tevékenységhez irányíthatók.
A Részlettábla oszlopban megadott tábla illesztőprogram-tevékenység, nem pedig illesztőprogram-tevékenység aggregáció, mert a láncolt összesítések nem engedélyezettek.
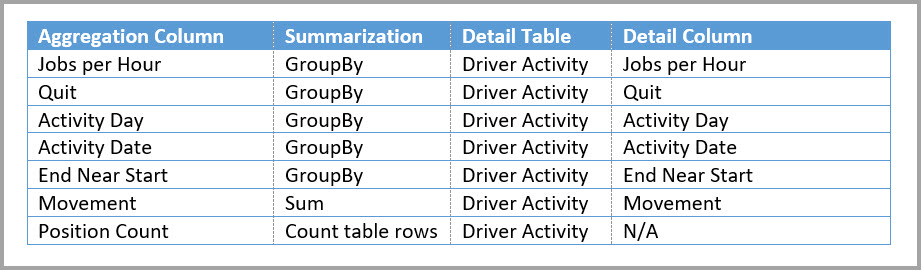
Az alábbi táblázat a Driver Activity Agg2 tábla összesítéseit mutatja.
Annak észlelése, hogy a lekérdezések elérik-e vagy kihagyják-e az összesítéseket
Az SQL Profiler képes észlelni, hogy a rendszer visszaadja-e a lekérdezéseket a memóriabeli gyorsítótár-tárolómotorból, vagy a DirectQuery leküldi az adatforrásba. Ugyanezt a folyamatot használhatja annak észlelésére, hogy az összesítések találatokat érnek-e el. További információ: A gyorsítótárat elérő vagy kihagyó lekérdezések.
Az SQL Profiler a kiterjesztett eseményt Query Processing\Aggregate Table Rewrite Query is biztosítja.
Az alábbi JSON-kódrészlet az esemény kimenetére mutat példát, amikor aggregációt használ.
- A matchingResult azt mutatja, hogy az allekérdezés összesítést használt.
- A dataRequest az allekérdezés GroupBy oszlopát és összesített oszlopát jeleníti meg.
- leképezés az aggregációs tábla azon oszlopait jeleníti meg, amelyekre megfeleltetve lettek leképezve.

Gyorsítótárak szinkronizálása
A DirectQuery, az Importálás és/vagy a Kettős tárolási módokat kombináló összesítések eltérő adatokat adhatnak vissza, kivéve, ha a memóriabeli gyorsítótár szinkronban marad a forrásadatokkal. A lekérdezés végrehajtása például nem próbálja elfedni az adatproblémákat a DirectQuery-eredmények gyorsítótárazott értékekre való szűrésével. Ha szükséges, léteznek olyan technikák, amelyek az ilyen problémákat a forrásnál kezelik. A teljesítményoptimalizálásokat csak olyan módon szabad használni, amely nem veszélyezteti az üzleti követelményeknek való megfelelést. Az Ön felelőssége, hogy megismerje az adatfolyamokat, és ennek megfelelően tervezzen.
Szempontok és korlátozások
Az összesítések nem támogatják a dinamikus M lekérdezési paramétereket.
2022 augusztusától a funkcióváltozások miatt a Power BI figyelmen kívül hagyja az egyszeri bejelentkezésre (SSO) engedélyezett adatforrásokkal rendelkező importálási módú összesítő táblákat a lehetséges biztonsági kockázatok miatt. Az aggregációk optimális lekérdezési teljesítményének biztosítása érdekében javasoljuk, hogy tiltsa le az egyszeri bejelentkezést ezekhez az adatforrásokhoz.
Közösség
A Power BI-nak élénk közössége van, ahol az MVP-k, a bi-szakemberek és a társviszonyok megosztják egymással a vitafórumokban, videókban, blogokban és egyebekben szerzett tapasztalatokat. Az aggregációk megismerése során mindenképpen tekintse meg az alábbi további forrásokat: