Adatfolyamok frissítésének ismertetése és optimalizálása
A Power BI-adatfolyamok lehetővé teszik az adatok csatlakoztatását, átalakítását, összevonását és terjesztését az alsóbb rétegbeli elemzésekhez. Az adatfolyamok egyik kulcsfontosságú eleme a frissítési folyamat, amely alkalmazza az adatfolyamokban létrehozott átalakítási lépéseket, és frissíti az adatokat magukban az elemekben.
Az adatfolyam frissítése után letöltheti a frissítési előzményeket, hogy megismerje a futtatási időket, a teljesítményt és azt, hogy kihozta-e a legtöbbet az adatfolyamból.
A frissítések ismertetése
Az adatfolyamokra kétféle frissítés alkalmazható:
Teljes, amely elvégzi az adatok teljes kiürítét és újratöltését.
Növekményes (csak prémium), amely az adatok egy részét dolgozza fel időalapú szabályok alapján, szűrőként kifejezve, amelyet ön konfigurál. A dátumoszlop szűrője dinamikusan particionálja az adatokat a Power BI szolgáltatás tartományaiba. A növekményes frissítés konfigurálása után az adatfolyam automatikusan módosítja a lekérdezést, hogy dátum szerint szűrjön. Az automatikusan létrehozott lekérdezést a Power Query Speciális szerkesztő használatával szerkesztheti a frissítés finomhangolásához vagy testreszabásához. Ha saját Azure Data Lake Storage-t hoz, a beállított frissítési szabályzat alapján láthatja az adatok időszeleteit.
Feljegyzés
További információ a növekményes frissítésről és annak működéséről: Növekményes frissítés használata adatfolyamokkal.
A növekményes frissítés nagy adatfolyamokat tesz lehetővé a Power BI-ban az alábbi előnyökkel:
A frissítések gyorsabbak az első frissítés után, az alábbi tények miatt:
- A Power BI frissíti a felhasználó által megadott utolsó N partíciókat (ahol a partíció nap/hét/hónap stb.), vagy
- A Power BI csak a frissíteni kívánt adatokat frissíti. Például csak a 10 éves szemantikai modell utolsó öt napjának frissítése.
- A Power BI csak addig frissíti a módosított adatokat, amíg megadja a módosításokat ellenőrizni kívánt oszlopot.
A frissítések megbízhatóbbak – már nem szükséges hosszú ideig futó kapcsolatokat fenntartani az illékony forrásrendszerekhez.
Az erőforrás-felhasználás csökken – a kevesebb frissítési adat csökkenti a memória és más erőforrások általános használatát.
Ahol csak lehetséges, a Power BI párhuzamos feldolgozást alkalmaz a partíciókon, ami gyorsabb frissítéshez vezethet.
Ezen frissítési forgatókönyvek bármelyikében, ha egy frissítés meghiúsul, az adatok nem frissülnek. Előfordulhat, hogy az adatok elavultak, amíg a legújabb frissítés be nem fejeződik, vagy manuálisan is frissítheti azokat, majd hiba nélkül befejeződhetnek. A frissítés egy partíción vagy entitáson történik, ezért ha egy növekményes frissítés meghiúsul, vagy egy entitás hibát jelez, akkor a teljes frissítési tranzakció nem következik be. Másként fogalmazva, ha egy partíció (növekményes frissítési szabályzat) vagy entitás meghibásodik egy adatfolyam esetében, a teljes frissítési művelet meghiúsul, és nem frissülnek az adatok.
Frissítések ismertetése és optimalizálása
Az adatfolyam frissítési műveletének jobb megismeréséhez tekintse át az adatfolyam frissítési előzményeit az egyik adatfolyamra való navigálással. Válassza a További lehetőségek (...) lehetőséget az adatfolyamhoz. Ezután válassza Gépház > Frissítési előzmények lehetőséget. Az adatfolyamot a munkaterületen is kiválaszthatja. Ezután válassza a További beállítások (...) lehetőséget . > Frissítési előzmények.
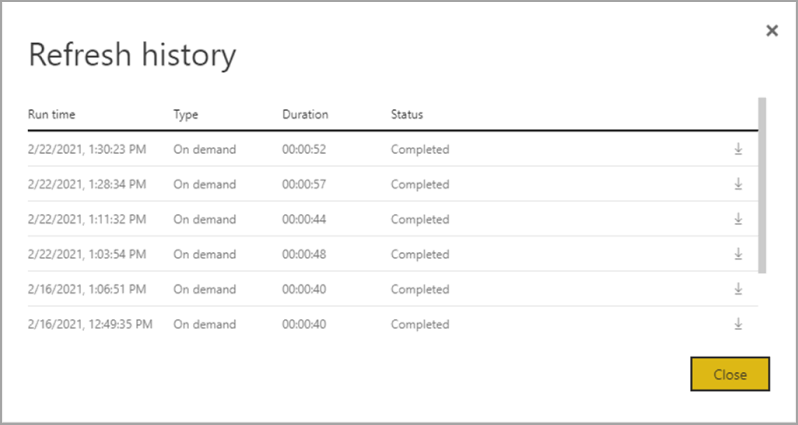
A frissítési előzmények áttekintést nyújtanak a frissítésekről, beleértve az igény szerinti vagy ütemezett típust, az időtartamot és a futtatás állapotát. Ha CSV-fájl formájában szeretné megtekinteni a részleteket, válassza a letöltés ikont a frissítés leírásának jobb szélén. A letöltött CSV az alábbi táblázatban leírt attribútumokat tartalmazza. A prémium szintű frissítések további információkat nyújtanak a további számítási és adatfolyam-képességek alapján, szemben a megosztott kapacitáson található Pro-alapú adatfolyamokkal. Ezért az alábbi metrikák némelyike csak Prémium verzióban érhető el.
| Tétel | Leírás | Pro | Prémium |
|---|---|---|---|
| A kérelem bekapcsolva | Az időfrissítés ütemezése megtörtént, vagy a frissítésre helyi idő szerint kattintott. | ✔ | ✔ |
| Adatfolyam neve | Az adatfolyam neve. | ✔ | ✔ |
| Adatfolyam frissítési állapota | A befejezett, a sikertelen vagy a kihagyott (entitás esetén) lehetséges állapotok. Az olyan esetek használata, mint a csatolt entitások, az oka annak, hogy valaki kihagyva jelenik meg. | ✔ | ✔ |
| Entitásnév | Tábla neve. | ✔ | ✔ |
| Partíció neve | Ez az elem attól függ, hogy az adatfolyam prémium szintű-e vagy sem, és ha a Pro na-ként jelenik meg, mert nem támogatja a növekményes frissítéseket. A Premium a FullRefreshPolicyPartition vagy az IncrementalRefreshPolicyPartition-[DateRange] értékeket jeleníti meg. | ✔ | |
| Frissítés állapota | Az egyes entitások vagy partíciók frissítési állapota, amely a frissítendő adatok adott időszeletének állapotát adja meg. | ✔ | ✔ |
| Kezdési idő | A Prémium verzióban ez az elem az az idő, amikor az adatfolyam várólistára került az entitás vagy partíció feldolgozásához. Ez az idő eltérhet, ha az adatfolyamok függőségekkel rendelkeznek, és várniuk kell, amíg az adatfolyam eredményhalmaza megkezdi a feldolgozást. | ✔ | ✔ |
| Befejezési idő | A befejezési idő az adatfolyam-entitás vagy -partíció befejezésének időpontja, ha van ilyen. | ✔ | ✔ |
| Időtartam | Az adatfolyam frissítésének teljes időtartama HH:MM:SS formátumban kifejezve. | ✔ | ✔ |
| Feldolgozott sorok | Egy adott entitás vagy partíció esetében az adatfolyam-motor által beolvasott vagy írt sorok száma. Előfordulhat, hogy ez az elem nem mindig tartalmaz adatokat a végrehajtott művelet alapján. Előfordulhat, hogy az adatok kimaradnak, ha a számítási motor nincs használatban, vagy amikor átjárót használ az adatok ott történő feldolgozásakor. | ✔ | |
| Feldolgozott bájtok | Egy adott entitás vagy partíció esetében az adatfolyam-motor által írt adatok bájtban kifejezve. Ha átjárót használ ezen az adatfolyamon, ez az információ nem lesz megadva. |
✔ | |
| Véglegesítés maximális mérete (KB) | A maximális véglegesítés a memóriakimaradások diagnosztizálásakor hasznos maximális véglegesítési memória, ha az M-lekérdezés nincs optimalizálva. Ha átjárót használ ezen az adatfolyamon, ez az információ nem lesz megadva. |
✔ | |
| A processzor kihasználtsága | Egy adott entitás vagy partíció esetében a HH:MM:SS-ben kifejezett idő, amelyet az adatfolyam-motor átalakítások végrehajtásával töltött. Ha átjárót használ ezen az adatfolyamon, ez az információ nem lesz megadva. |
✔ | |
| Várakozási idő | Egy adott entitás vagy partíció esetében az az idő, amelyet egy entitás várakozási állapotban töltött a prémium szintű kapacitás számítási feladatai alapján. | ✔ | |
| Számítási motor | Egy adott entitás vagy partíció esetében a frissítési művelet számítási motor használatával kapcsolatos részletek. Az értékek a következők: -NA -Hajtogatott -Gyorsítótárazott - Gyorsítótárazott és hajtogatott Ezeket az elemeket a cikk későbbi részében részletesebben ismertetjük. |
✔ | |
| Hiba | Ha lehetséges, a részletes hibaüzenet entitásonként vagy partíciónként lesz ismertetve. | ✔ | ✔ |
Adatfolyam-frissítési útmutató
A frissítési statisztikák értékes információkat nyújtanak az adatfolyamok teljesítményének optimalizálásához és felgyorsításához. A következő szakaszokban bemutatunk néhány forgatókönyvet, mit kell figyelni, és hogyan optimalizálhatók a megadott információk alapján.
Vezénylés
Az adatfolyamok ugyanazon a munkaterületen való használata egyszerű vezénylést tesz lehetővé. Előfordulhat például, hogy az A, B és C adatfolyamok egyetlen munkaterületen vannak, és úgy vannak láncolva, mint az A > B > C. Ha frissíti a forrást (A), az alsóbb rétegbeli entitások is frissülnek. Ha azonban a C-t frissíti, akkor egymástól függetlenül kell frissítenie másokat. Ha új adatforrást ad hozzá a B adatfolyamhoz (amely nem szerepel az A-ben), akkor az adatok nem frissülnek a vezénylés részeként.
Előfordulhat, hogy olyan elemeket szeretne összeláncolni, amelyek nem felelnek meg a Power BI által végrehajtott felügyelt vezénylésnek. Ilyen esetekben használhatja az API-kat és/vagy a Power Automate-et. A programozott frissítéshez tekintse meg az API dokumentációját és a PowerShell-szkriptet . Van egy Power Automate-összekötő, amely kód írása nélkül teszi lehetővé ezt az eljárást. Részletes mintákat tekinthet meg, amelyek a szekvenciális frissítések konkrét útmutatóit ismertetik.
Figyelés
A cikk korábbi részében ismertetett továbbfejlesztett frissítési statisztikák használatával részletes adatfolyam-frissítési információkat kaphat. Ha azonban a frissítések bérlői vagy munkaterületszintű áttekintésével szeretné megtekinteni az adatfolyamokat, például egy monitorozási irányítópult létrehozásához, használhatja az API-kat vagy a PowerAutomate-sablonokat. Hasonlóképpen, az olyan használati esetekben, mint az egyszerű vagy összetett értesítések küldése, használhatja a PowerAutomate-összekötőt, vagy létrehozhat saját egyéni alkalmazást az API-k használatával.
Időtúllépési hibák
Ideális az ETL-forgatókönyvek kinyeréséhez, átalakításához és betöltéséhez szükséges idő optimalizálása. A Power BI-ban a következő esetek érvényesek:
- Egyes összekötők explicit időtúllépési beállításokkal rendelkeznek, amelyeket konfigurálhat. További információ: Csatlakozás orok a Power Queryben.
- A Power BI-adatfolyamok a Power BI Pro használatával időtúllépéseket is tapasztalhatnak egy entitáson vagy adatfolyamon belüli hosszú ideig futó lekérdezésekhez. Ez a korlátozás nem létezik a Power BI Premium-munkaterületeken.
Időtúllépési útmutató
A Power BI Pro-adatfolyamok időtúllépési küszöbértékei a következők:
- Két óra az egyes entitások szintjén.
- Három óra az adatfolyam teljes szintjén.
Ha például egy három táblával rendelkező adatfolyam van, egyetlen tábla sem tarthat két óránál hosszabb ideig, és a teljes adatfolyam időtúllépést okozhat, ha az időtartam meghaladja a három órát.
Ha időtúllépést tapasztal, fontolja meg az adatfolyam-lekérdezések optimalizálását, és fontolja meg a lekérdezések összecsukását a forrásrendszereken.
Külön érdemes lehet felhasználónként prémium verzióra frissíteni, amely nem vonatkozik ezekre az időtúllépésekre, és számos Felhasználónkénti Power BI Premium-funkciónak köszönhetően nagyobb teljesítményt nyújt.
Hosszú időtartamok
Az összetett vagy nagy adatfolyamok frissítése több időt vehet igénybe, ahogy a rosszul optimalizált adatfolyamok is. A következő szakaszok útmutatást nyújtanak a hosszú frissítési időtartamok csökkentéséhez.
Útmutatás a hosszú frissítési időtartamokhoz
Az adatfolyamok hosszú frissítési időtartamának javításának első lépése az adatfolyamok létrehozása az ajánlott eljárásoknak megfelelően. A figyelemre méltó minták a következők:
- Csatolt entitások használata olyan adatokhoz, amelyek később más átalakításokban is felhasználhatók.
- Számítási entitások használata az adatok gyorsítótárazásához, így csökkentve az adatok betöltésének és az adatok betöltésének a forrásrendszerekre nehezedő terheit.
- Adatok felosztása átmeneti adatfolyamokra és adatfolyamok átalakítására, az ETL különböző adatfolyamokra való elválasztásával.
- A bővítő táblaműveletek optimalizálása.
- Kövesse az összetett adatfolyamok útmutatását.
Ezután segíthet annak kiértékelésében, hogy használhat-e növekményes frissítést.
A növekményes frissítés javíthatja a teljesítményt. Fontos, hogy a rendszer leküldje a partíciószűrőket a forrásrendszerbe, amikor a rendszer lekérdezéseket küld a frissítési műveletekhez. A leküldéses szűrés azt jelenti, hogy az adatforrásnak támogatnia kell a lekérdezések összecsukását, vagy üzleti logikát fejezhet ki egy olyan függvénnyel vagy más eszközzel, amely segíthet a Power Querynek a fájlok vagy mappák eltávolításában és szűrésében. Az SQL-lekérdezéseket támogató legtöbb adatforrás támogatja a lekérdezések összecsukását, és egyes OData-hírcsatornák a szűrést is támogatják.
Az olyan adatforrások, mint az egybesimított fájlok, blobok és API-k azonban általában nem támogatják a szűrést. Olyan esetekben, amikor az adatforrás háttérrendszere nem támogatja a szűrőt, nem lehet leküldésesen leküldni. Ilyen esetekben a egyesítési motor kompenzálja és helyileg alkalmazza a szűrőt, ami szükségessé teheti a teljes szemantikai modell lekérését az adatforrásból. Ez a művelet lassú növekményes frissítést okozhat, és a folyamat elfogyhat az erőforrásokból a Power BI szolgáltatás vagy a helyszíni adatátjáróban, ha használják.
Tekintettel az egyes adatforrások lekérdezés-összecsukási támogatásának különböző szintjeire, ellenőriznie kell, hogy a szűrőlogika szerepel-e a forrás lekérdezésekben. Ennek megkönnyítése érdekében a Power BI a Power Query Online lépésenkénti összecsukási mutatóival próbálja elvégezni ezt az ellenőrzést. Ezen optimalizálások közül sok tervezési idejű élmény, de a frissítés után lehetősége van elemezni és optimalizálni a frissítési teljesítményt.
Végül fontolja meg a környezet optimalizálását. A Power BI-környezetet optimalizálhatja a kapacitás skálázásával, az adatátjárók megfelelő méretezésével és a hálózati késés csökkentésével az alábbi optimalizálásokkal:
A Power BI Premium vagy a Felhasználónkénti Prémium verzióban elérhető kapacitások használata esetén növelheti a teljesítményt a Premium-példány növelésével, vagy a tartalom másik kapacitáshoz való hozzárendelésével.
Átjáróra van szükség, amikor a Power BI-nak olyan adatokat kell elérnie, amelyek nem érhetők el közvetlenül az interneten keresztül. A helyszíni adatátjárót helyszíni kiszolgálóra vagy virtuális gépre is telepítheti.
- Az átjáró számítási feladatainak és a méretezési javaslatok megismeréséhez tekintse meg a helyszíni adatátjáró méretezését.
- Azt is kiértékelheti, hogy az adatok először egy átmeneti adatfolyamba kerülnek, és csatolt és számított entitások használatával hivatkoznak rá az alsóbb rétegben.
A hálózati késés hatással lehet a frissítési teljesítményre azáltal, hogy növeli a kérések Power BI szolgáltatás való eléréséhez és a válaszok kézbesítéséhez szükséges időt. A Power BI-bérlők egy adott régióhoz vannak rendelve. Ha meg szeretné állapítani, hogy hol található a bérlő, olvassa el a szervezet alapértelmezett régiójának megkeresését. Amikor egy bérlő felhasználói hozzáférnek a Power BI szolgáltatás, a kéréseik mindig erre a régióra irányítják. Amikor a kérések elérik a Power BI szolgáltatás, előfordulhat, hogy a szolgáltatás további kéréseket küld például a mögöttes adatforrásnak vagy egy adatátjárónak, amelyek szintén hálózati késésnek vannak kitéve.
- Az olyan eszközök, mint az Azure Speed Test , jelzik az ügyfél és az Azure-régió közötti hálózati késést. Általánosságban elmondható, hogy a hálózati késés hatásának minimalizálása érdekében törekedjen arra, hogy az adatforrások, az átjárók és a Power BI-fürt a lehető legközelebb legyen. Az azonos régióban való tartózkodás előnyösebb. Ha a hálózati késés probléma, próbálja meg közelebb helyezni az átjárókat és az adatforrásokat a Power BI-fürthöz úgy, hogy a felhőben üzemeltetett virtuális gépeken helyezi el őket.
Magas processzoridő
Ha magas processzoridőt lát, valószínűleg költséges átalakításokkal rendelkezik, amelyeket nem hajtanak össze. A magas processzoridő vagy az alkalmazott lépések száma, vagy a végrehajtott átalakítások típusa miatt van. Ezek a lehetőségek magasabb frissítési időt eredményezhetnek.
Útmutatás a magas processzoridőhöz
A magas processzoridő optimalizálásának két lehetősége van.
Először is használja az adatforráson belüli lekérdezés-összecsukást, amely közvetlenül csökkenti az adatfolyam számítási motorjának terhelését. Az adatforráson belüli lekérdezések összecsukásával a forrásrendszer elvégezheti a munka nagy részét. Az adatfolyam ezután a forrás anyanyelvén továbbíthatja a lekérdezéseket ahelyett, hogy a kezdeti lekérdezés után a memóriában kellene elvégeznie az összes számítást.
Nem minden adatforrás hajthat végre lekérdezés-összecsukást, és még ha lehetséges is a lekérdezés összecsukása, előfordulhatnak olyan adatfolyamok, amelyek bizonyos átalakításokat hajtanak végre, amelyek nem hajthatók végre a forráshoz. Ilyen esetekben a továbbfejlesztett számítási motor a Power BI által bevezetett képesség, amely akár 25-ször is javíthatja a teljesítményt, kifejezetten átalakítások esetén.
A számítási motor használata a teljesítmény maximalizálásához
Bár a Power Query tervezési ideje látható a lekérdezések összecsukása során, a számítási motor oszlopa részletesen ismerteti, hogy maga a belső motor van-e használatban. A számítási motor akkor hasznos, ha összetett adatfolyamot használ, és átalakításokat hajt végre a memóriában. Ez az a helyzet, amikor a továbbfejlesztett frissítési statisztikák hasznosak lehetnek, mivel a számítási motor oszlopa részletesen ismerteti, hogy maga a motor volt-e használatban.
A következő szakaszok útmutatást nyújtanak a számítási motor és statisztikái használatához.
Figyelmeztetés
A tervezési idő alatt a szerkesztő összecsukható jelzője azt jelezheti, hogy a lekérdezés nem hajtható le, amikor egy másik adatfolyamból származó adatokat használ fel. Ellenőrizze a forrás adatfolyamát, ha engedélyezve van a továbbfejlesztett számítás, hogy engedélyezve legyen a forrás adatfolyamon való összecsukás.
Útmutató a számítási motor állapotához
A továbbfejlesztett számítási motor bekapcsolása és a különböző állapotok megértése hasznos. A továbbfejlesztett számítási motor belsőleg SQL-adatbázist használ az adatok olvasásához és tárolásához. Itt a legjobb, ha az átalakításokat a lekérdezési motoron hajtja végre. A következő bekezdések különböző helyzeteket és útmutatást nyújtanak az egyes műveletekhez.
NA – Ez az állapot azt jelenti, hogy a számítási motort nem használták, mert:
- Power BI Pro-adatfolyamokat használ.
- Explicit módon kikapcsolta a számítási motort.
- Lekérdezésátadást használ az adatforráson.
- Összetett átalakításokat hajt végre, amelyek nem tudják használni a lekérdezések felgyorsításához használt SQL-motort.
Ha hosszú időtartamot tapasztal, és továbbra is na állapotú, győződjön meg arról, hogy be van kapcsolva, és nem véletlenül ki van kapcsolva. Az egyik ajánlott minta az átmeneti adatfolyamok használata az adatok kezdeti beolvasásához a Power BI szolgáltatás, majd adatfolyamok létrehozása az adatok tetejére, miután az átmeneti adatfolyamban van. Ez a minta csökkentheti a forrásrendszerek terhelését, és a számítási motorral együtt felgyorsíthatja az átalakításokat, és javíthatja a teljesítményt.
Gyorsítótárazott – Ha a gyorsítótárazott állapot jelenik meg, az adatfolyam-adatokat a számítási motor tárolja, és egy másik lekérdezés részeként elérhető. Ez a helyzet akkor ideális, ha csatolt entitásként használja, mert a számítási motor gyorsítótárazza az adatokat az alsóbb rétegben való használathoz. A gyorsítótárazott adatokat nem kell többször frissíteni ugyanabban az adatfolyamban. Ez a helyzet akkor is ideális lehet, ha DirectQueryhez szeretné használni.
Gyorsítótárazás esetén a kezdeti betöltési teljesítményre gyakorolt hatás később, ugyanabban az adatfolyamban vagy egy másik adatfolyamban, ugyanabban a munkaterületen megtérül.
Ha nagy időtartamú az entitás, érdemes kikapcsolni a számítási motort. Az entitás gyorsítótárazásához a Power BI a tárolóba és az SQL-be írja. Ha egyszeri használatú entitásról van szó, előfordulhat, hogy a felhasználók teljesítménybeli előnye nem éri meg a kettős betöltés büntetését.
Összehajtva – A hajtogatott érték azt jelenti, hogy az adatfolyam sql-számítást tudott használni az adatok olvasásához. A számított entitás az SQL tábláját használta az adatok olvasására, a használt SQL pedig a lekérdezés szerkezetéhez kapcsolódik.
Az összecsukott állapot akkor jelenik meg, ha helyszíni vagy felhőbeli adatforrásokat használ, először betöltötte az adatokat egy átmeneti adatfolyamba, és erre hivatkozott ebben az adatfolyamban. Ez az állapot csak olyan entitásokra vonatkozik, amelyek egy másik entitásra hivatkoznak. Ez azt jelenti, hogy a lekérdezések az SQL-motor tetején futottak, és az SQL-számítással fejleszthetők. Annak érdekében, hogy az SQL-motor feldolgozza az átalakításokat, használjon olyan átalakításokat, amelyek támogatják az SQL összecsukását, például az egyesítést (illesztést), a csoportosítást (összesítés) és a hozzáfűző (egyesítő) műveleteket a Lekérdezésszerkesztő.
Gyorsítótárazott + összecsukott – Ha gyorsítótárazott + hajtogatott állapotot lát, valószínű, hogy az adatfrissítés optimalizálva van, mivel olyan entitással rendelkezik, amely mindkettő egy másik entitásra hivatkozik, és amelyre egy másik entitás hivatkozik a felsőbb rétegben. Ez a művelet az SQL-n is fut, és mint ilyen, az SQL-számítással is fejleszthet. Annak érdekében, hogy a lehető legjobb teljesítményt kapja, használjon olyan átalakításokat, amelyek támogatják az SQL-összecsukást, például az egyesítést (illesztést), a csoportosítást (összesítés) és a hozzáfűző (egyesítő) műveleteket a Lekérdezésszerkesztő.
Útmutató a számítási motor teljesítményoptimalizálásához
Az alábbi lépések lehetővé teszik, hogy a számítási feladatok aktiválják a számítási motort, és ezáltal mindig javíthassák a teljesítményt.
Számított és csatolt entitások ugyanabban a munkaterületen:
A betöltéshez koncentráljon arra, hogy az adatokat a lehető leggyorsabban a tárolóba juttassa, csak akkor használjon szűrőket, ha csökkentik a teljes szemantikai modellméretet. Az átalakítási logikát tartsa távol ettől a lépéstől. Ezután különítse el az átalakítást és az üzleti logikát egy külön adatfolyamra ugyanabban a munkaterületen. Csatolt vagy számított entitások használata. Ez lehetővé teszi a motor számára a számítások aktiválását és felgyorsítását. Egy egyszerű analógia, ez olyan, mint az élelmiszer-előkészítés a konyhában: az élelmiszer-előkészítés általában egy külön és különálló lépés összegyűjtése a nyers összetevők, és előfeltétele annak, hogy az élelmiszer a sütőben. Hasonlóképpen külön kell előkészítenie a logikát, mielőtt kihasználhatja a számítási motor előnyeit.
Győződjön meg arról, hogy végrehajtja az összecsukható műveleteket, például az egyesítéseket, az illesztéseket, a konvertálást és más műveleteket.
Emellett adatfolyamokat is létrehozhat a közzétett irányelvekben és korlátozásokban.
Ha a számítási motor be van kapcsolva, de a teljesítmény lassú:
A számítási motor bekapcsolt állapotában lévő forgatókönyvek vizsgálatakor hajtsa végre a következő lépéseket, de gyenge teljesítményt tapasztal:
- Korlátozza a munkaterületen létező számított és csatolt entitásokat.
- Ha a kezdeti frissítés be van kapcsolva a számítási motorral, az adatok a tóban és a gyorsítótárban lesznek megírva. Ez a dupla írás azt eredményezi, hogy a frissítések lassabbak lesznek.
- Ha egy adatfolyam több adatfolyamhoz kapcsolódik, ügyeljen arra, hogy ütemezze a forrás adatfolyamok frissítéseit, hogy ne frissüljenek egyszerre.
Szempontok és korlátozások
A Power BI Pro-licencek adatfolyamainak frissítési korlátja naponta 8.
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: