Modell teljesítményének kiértékelése a Machine Learning Studióban (klasszikus)
HATÓKÖR: A Machine Learning Studio (klasszikus)
A Machine Learning Studio (klasszikus)  Azure Machine Learning
Azure Machine Learning
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- A gépi tanulási projektek ml studióból (klasszikus) Azure Machine Learningbe való áthelyezéséről szóló információk.
- További információ az Azure Machine Learningről
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
Ebben a cikkben megismerheti a modell teljesítményének monitorozására használható metrikákat a Machine Learning Studióban (klasszikus). A modell teljesítményének értékelése az adatelemzési folyamat egyik alapvető szakasza. Azt jelzi, hogy egy adathalmaz pontozása (előrejelzései) mennyire voltak sikeresek egy betanított modellben. A Machine Learning Studio (klasszikus) két fő gépi tanulási moduljával támogatja a modellek kiértékelését:
Ezek a modulok lehetővé teszik a modell teljesítményének megtekintését a gépi tanulásban és a statisztikákban gyakran használt metrikák tekintetében.
A modellek kiértékelését a következőkkel együtt kell mérlegelni:
Három gyakori felügyelt tanulási forgatókönyvet mutatunk be:
- Regresszió
- bináris besorolás
- többosztályos besorolás
Kiértékelés és keresztérvényesítés
A kiértékelés és a keresztérvényesítés szabványos módszer a modell teljesítményének mérésére. Mindkettő olyan kiértékelési metrikákat hoz létre, amelyeket megvizsgálhat vagy összehasonlíthat más modellekéivel.
Az Evaluate Model egy pontozott adatkészletet vár bemenetként (vagy kettő, ha két különböző modell teljesítményét szeretné összehasonlítani). Ezért az eredmények kiértékelése előtt be kell tanítania a modellt a Modell betanítása modullal, és előrejelzéseket kell készítenie néhány adathalmazról a Modell pontozása modul használatával. A kiértékelés a pontozott címkéken/valószínűségeken és a valódi címkéken alapul, amelyek mindegyike a Modell pontozása modul kimenete.
Másik lehetőségként keresztellenőrzéssel automatikusan végrehajthat néhány betanított pontszám-kiértékelési műveletet (10 hajtást) a bemeneti adatok különböző részhalmazán. A bemeneti adatok 10 részre vannak felosztva, ahol az egyik tesztelésre, a másik 9 pedig betanításra van fenntartva. Ez a folyamat 10-szer ismétlődik, és a kiértékelési metrikák átlaga. Ez segít annak meghatározásában, hogy egy modell mennyire általánosítana az új adathalmazokra. A Modell keresztellenőrzése modul egy nem betanított modellt és néhány címkézett adatkészletet vesz fel, és az átlagolt eredmények mellett minden 10 hajtás kiértékelési eredményeit adja ki.
A következő szakaszokban egyszerű regressziós és besorolási modelleket hozunk létre, és kiértékeljük a teljesítményüket a Modell kiértékelése és a Modell keresztellenőrzése modul használatával.
Regressziós modell kiértékelése
Tegyük fel, hogy egy autó árát olyan jellemzőkkel szeretnénk előrejelezni, mint a méretek, a lóerő, a motor specifikációi stb. Ez egy tipikus regressziós probléma, ahol a célváltozó (ár) egy folyamatos numerikus érték. Olyan lineáris regressziós modellt illeszthetünk be, amely egy adott autó jellemzőértékei alapján előrejelezheti az adott autó árát. Ez a regressziós modell használható a betanított adathalmaz pontozására. Miután megvan az előrejelzett autóárak, kiértékelhetjük a modell teljesítményét, ha megnézzük, hogy az előrejelzések mennyiben térnek el az átlagos tényleges áraktól. Ennek szemléltetéséhez a Machine Learning Studio Mentett adathalmazok szakaszában (klasszikus) elérhető Automobile price data (Raw) adatkészletet használjuk.
A kísérlet létrehozása
Adja hozzá a következő modulokat a munkaterülethez a Machine Learning Studióban (klasszikus):
- Autóárak adatai (nyers)
- Lineáris regresszió
- Modell betanítása
- Relevanciamodell
- Modell értékelése
Csatlakoztassa a portokat az 1. ábrán látható módon, és állítsa a Modell betanítása modul Címke oszlopát az árra.
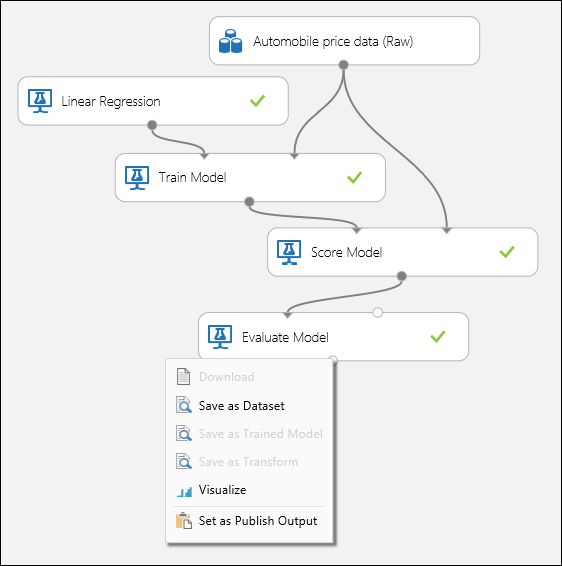
1. ábra Regressziós modell kiértékelése.
A kiértékelési eredmények vizsgálata
A kísérlet futtatása után kattintson a Modell kiértékelése modul kimeneti portjára, és válassza a Vizualizáció lehetőséget a kiértékelési eredmények megtekintéséhez. A regressziós modellekhez elérhető értékelési metrikák a következők: Átlagos abszolút hiba, Gyökér középértéke Abszolút hiba, Relatív abszolút hiba, Relatív négyzetes hiba és a meghatározási együttható.
Az itt látható "hiba" kifejezés az előrejelzett érték és a valódi érték közötti különbséget jelöli. Ennek a különbségnek az abszolút értékét vagy négyzetét általában úgy számítjuk ki, hogy az összes példányban rögzítse a hiba teljes nagyságát, mivel az előrejelzett és a valódi érték közötti különbség bizonyos esetekben negatív lehet. A hibametrikák a regressziós modell prediktív teljesítményét mérik az előrejelzései valós értékektől való átlagos eltérése alapján. Az alacsonyabb hibaértékek azt jelentik, hogy a modell pontosabb előrejelzéseket készít. A nulla általános hibametrika azt jelenti, hogy a modell tökéletesen illeszkedik az adatokhoz.
A meghatározási együttható, más néven R négyzetes, szintén szabványos módszer annak mérésére, hogy a modell mennyire illeszkedik az adatokhoz. Ez a modell által magyarázott variációk arányaként értelmezhető. Ebben az esetben a nagyobb arány jobb, ahol az 1 tökéletes illeszkedést jelez.
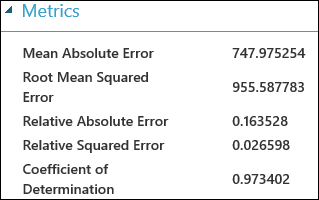
2. ábra Lineáris regresszióértékelési metrikák.
Keresztérvényesítés használata
Ahogy korábban említettük, a Modell keresztellenőrzése modullal automatikusan végezhet ismétlődő betanításokat, pontozásokat és értékeléseket. Ebben az esetben csak egy adathalmazra, egy nem betanított modellre és egy keresztellenőrzési modellmodulra van szüksége (lásd az alábbi ábrát). A címkeoszlopot árra kell állítania a Modell keresztellenőrzése modul tulajdonságai között.
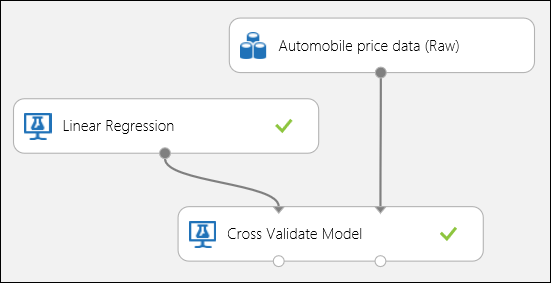
3. ábra Regressziós modell kereszt-érvényesítése.
A kísérlet futtatása után a modell keresztellenőrzése modul jobb oldali kimeneti portjára kattintva megvizsgálhatja a kiértékelési eredményeket. Ez részletes áttekintést nyújt az egyes iterációk (hajtások) metrikáiról, valamint az egyes metrikák átlagolt eredményeiről (4. ábra).
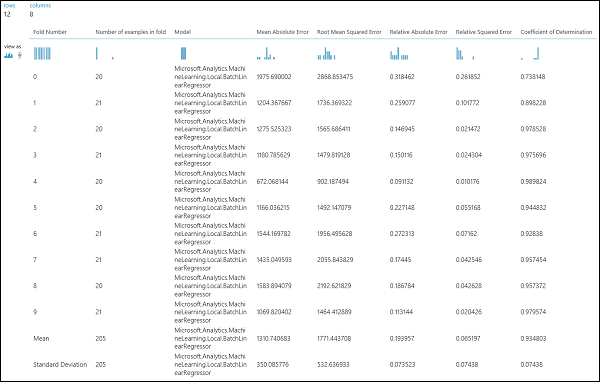
4. ábra Regressziós modell keresztérvényesítési eredményei.
Bináris besorolási modell kiértékelése
Bináris besorolási forgatókönyv esetén a célváltozónak csak két lehetséges eredménye lehet: {0, 1} vagy {false, true}, {negatív, pozitív}. Tegyük fel, hogy egy olyan felnőtt alkalmazottakból álló adatkészletet kap, amelynek demográfiai és foglalkoztatási változói vannak, és hogy a rendszer arra kéri, hogy előrejelezze a jövedelemszintet, egy bináris változót {"<=50 K", ">50 K"} értékekkel. Más szóval a negatív osztály azokat az alkalmazottakat jelöli, akik 50 K-nál kevesebbet vagy egyenlőt tesznek évente, a pozitív osztály pedig az összes többi alkalmazottat jelöli. A regressziós forgatókönyvhez hasonlóan betanítunk egy modellt, értékelnénk az adatokat, és kiértékelnénk az eredményeket. Itt a fő különbség a Machine Learning Studio (klasszikus) számításainak és kimeneteinek kiválasztása. A jövedelemszint-előrejelzési forgatókönyv szemléltetéséhez a Felnőtt adatkészlettel létrehozunk egy (klasszikus) Studio-kísérletet, és kiértékeljük egy kétosztályos logisztikai regressziós modell, egy gyakran használt bináris osztályozó teljesítményét.
A kísérlet létrehozása
Adja hozzá a következő modulokat a munkaterülethez a Machine Learning Studióban (klasszikus):
- Felnőtt Census Income Binary Classification adatkészlet
- Kétosztályos logisztikai regresszió
- Modell betanítása
- Relevanciamodell
- Modell értékelése
Csatlakoztassa a portokat az 5. ábrán látható módon, és állítsa a Modell betanítása modul Címke oszlopát bevételre.
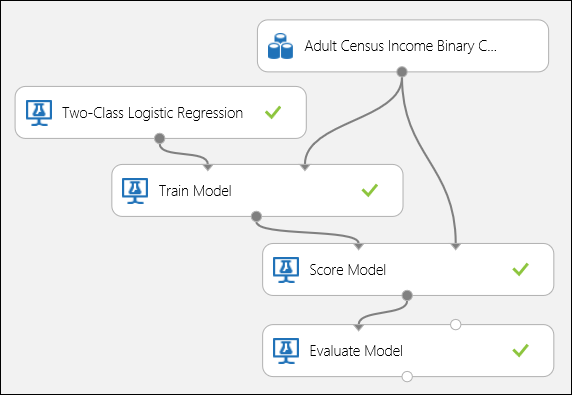
5. ábra Bináris besorolási modell kiértékelése.
A kiértékelési eredmények vizsgálata
A kísérlet futtatása után kattintson a Modell kiértékelése modul kimeneti portjára, és válassza a Vizualizáció lehetőséget a kiértékelési eredmények megtekintéséhez (7. ábra). A bináris besorolási modellekhez elérhető értékelési metrikák a következők: Pontosság, Pontosság, Visszahívás, F1 pontszám és AUC. Emellett a modul egy keveredési mátrixot ad ki, amely a valódi pozitívok, hamis negatívok, hamis pozitívok és valódi negatívok, valamint roc, precision/recall és lift görbék számát mutatja.
A pontosság egyszerűen a megfelelően besorolt példányok aránya. Általában ez az első metrika, amelyet az osztályozók kiértékelésekor vizsgál. Ha azonban a tesztadatok kiegyensúlyozatlanok (ahol a példányok többsége az egyik osztályhoz tartozik), vagy ha jobban érdekli bármelyik osztály teljesítménye, a pontosság nem igazán rögzíti az osztályozó hatékonyságát. A jövedelemszint-besorolási forgatókönyvben tegyük fel, hogy olyan adatokat tesztel, amelyekben a példányok 99%-a olyan személyeket jelöl, akik 50 000-nél kevesebbet keresnek évente. 0,99 pontosság érhető el az "<=50K" osztály előrejelzésével minden példányra. Ebben az esetben úgy tűnik, hogy az osztályozó összességében jó munkát végez, de valójában nem sorolja be helyesen a magas jövedelmű személyeket (az 1%-ot).
Ezért hasznos lehet további metrikákat kiszámolni, amelyek az értékelés konkrétabb aspektusait rögzítik. Az ilyen metrikák részleteinek megismerése előtt fontos megérteni a bináris besorolás kiértékelésének keveredési mátrixát. A betanítási készlet osztálycímkéi csak két lehetséges értéket tartalmazhatnak, amelyeket általában pozitívnak vagy negatívnak nevezünk. Az osztályozó által helyesen előrejelzett pozitív és negatív példányokat valódi pozitívoknak (TP) és valódi negatívoknak (TN) nevezzük. Hasonlóképpen, a helytelenül besorolt példányokat hamis pozitívnak (FP) és hamis negatívnak (FN) nevezzük. A keveredési mátrix egyszerűen egy táblázat, amely a négy kategória alá tartozó példányok számát mutatja. A Machine Learning Studio (klasszikus) automatikusan eldönti, hogy az adathalmaz két osztálya közül melyik a pozitív osztály. Ha az osztálycímkék logikai vagy egész számok, akkor az "igaz" vagy az "1" címkével ellátott példányok lesznek hozzárendelve a pozitív osztályhoz. Ha a címkék sztringek, például a jövedelem adathalmaz esetén, a címkék betűrendben vannak rendezve, és az első szint lesz a negatív osztály, a második szint pedig a pozitív osztály.
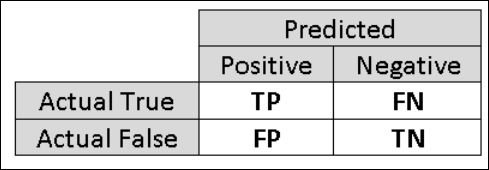
6. ábra Bináris besorolás keveredési mátrixa.
Visszatérve a jövedelembesorolási problémára, érdemes feltenni néhány kiértékelési kérdést, amelyek segítenek megérteni a használt osztályozó teljesítményét. Természetes kérdés: "Azon egyének közül, akiket a modell 50 K -os (TP+FP) bevételre >becsült, hányan lettek helyesen besorolva (TP)?" Erre a kérdésre a modell pontosságát vizsgálva lehet választ adni, amely a helyesen besorolt pozitívok aránya: TP/(TP+FP). Egy másik gyakori kérdés: "Az 50 ezer (TP+FN) jövedelemmel >rendelkező magas keresetű alkalmazottak közül hányat sorolt be helyesen az osztályozó (TP)". Ez valójában a Visszahívás, vagyis a valódi pozitív arány: az osztályozó TP/(TP+FN) értéke. Észreveheti, hogy a pontosság és a felidézés között nyilvánvaló kompromisszum áll fenn. Egy viszonylag kiegyensúlyozott adathalmaz esetén például a többnyire pozitív példányokat előrejelző osztályozó nagy mértékű visszahívást eredményezne, de meglehetősen alacsony pontosságú lenne, mivel a negatív példányok közül sok téves besorolást eredményezne, ami nagy számú téves pozitív eredményt eredményezne. Ha meg szeretné tekinteni a két metrika eltéréseit ábrázoló ábrát, kattintson a PONTOSSÁG/VISSZAHÍVÁS görbére a kiértékelési eredmény kimeneti oldalán (a 7. ábra bal felső részén).
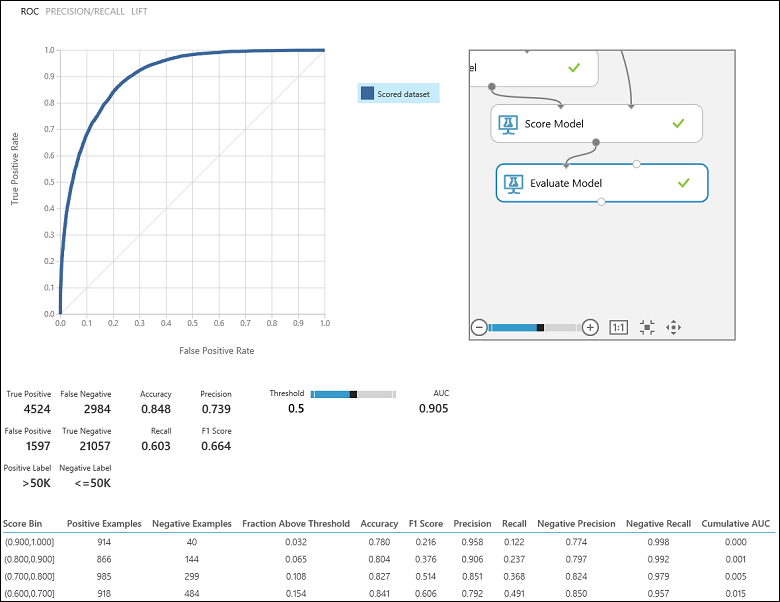
7. ábra Bináris besorolás kiértékelési eredményei.
Egy másik gyakran használt kapcsolódó metrika az F1 pontszám, amely a pontosságot és a visszahívást is figyelembe veszi. E két metrika harmonikus középértékét számítja ki: F1 = 2 (pontosság x visszahívás) / (pontosság + visszahívás). Az F1 pontszám jó módszer a kiértékelés egyetlen számban történő összegzésére, de mindig érdemes a pontosságot és együtt felidézni, hogy jobban megértsük, hogyan viselkedik az osztályozó.
Emellett megvizsgálhatjuk a valós pozitív arányt a fogadó működési jellemző (ROC) görbe hamis pozitív arányával és a görbe alatti terület (AUC) értékével. Minél közelebb van ez a görbe a bal felső sarokhoz, annál jobb az osztályozó teljesítménye (ez maximalizálja a valódi pozitív arányt, miközben minimalizálja a hamis pozitív arányt). A diagram átlójához közeli görbék, amelyek olyan osztályozókból származnak, amelyek hajlamosak véletlenszerű becsléshez közeli előrejelzéseket készíteni.
Keresztérvényesítés használata
A regressziós példához hasonlóan keresztellenőrzést is végezhetünk az adatok különböző részhalmazainak automatikus betanításához, pontozásához és kiértékeléséhez. Hasonlóképpen használhatjuk a Modell keresztellenőrzése modult, egy betanítatlan logisztikai regressziós modellt és egy adatkészletet. A címkeoszlopot bevételre kell állítani a Modell keresztellenőrzése modul tulajdonságai között. A kísérlet futtatása és a modell keresztellenőrzése modul jobb kimeneti portjára kattintva megtekintheti az egyes hajtások bináris besorolási metrikaértékét, valamint az egyes modellek középértékét és szórását.
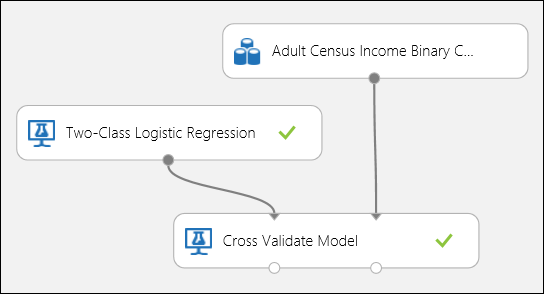
8. ábra Bináris besorolási modell keresztkontrasztja.
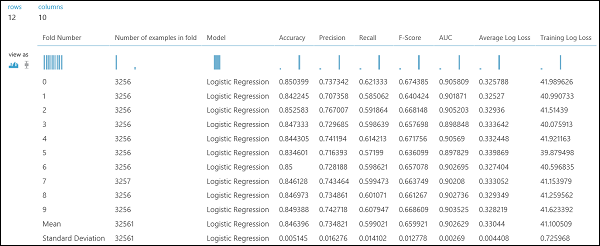
9. ábra. Bináris osztályozó keresztérvényesítési eredményei.
Többosztályos besorolási modell kiértékelése
Ebben a kísérletben a népszerű fogjuk használni, amely az írisz növény három különböző típusának (osztályának) példányait tartalmazza. Minden példányhoz négy jellemzőérték tartozik (a szekális hossz/szélesség és a szirom hossza/szélessége). Az előző kísérletekben ugyanezekkel az adathalmazokkal képeztük be és teszteltük a modelleket. Itt az Adatok felosztása modult fogjuk használni az adatok két részhalmazának létrehozásához, az első betanításához, valamint a második pontozásához és kiértékeléséhez. Az Írisz adatkészlet nyilvánosan elérhető az UCI Machine Learning-adattárban, és egy Adatimportálás modullal tölthető le.
A kísérlet létrehozása
Adja hozzá a következő modulokat a munkaterülethez a Machine Learning Studióban (klasszikus):
- Adatok importálása
- Többosztályos döntési erdő
- Adatok felosztása
- Modell betanítása
- Relevanciamodell
- Modell értékelése
Csatlakoztassa a portokat a 10. ábrán látható módon.
Állítsa a Modell betanítása modul Címke oszlopindexét 5-re. Az adatkészletnek nincs fejlécsora, de tudjuk, hogy az osztálycímkék az ötödik oszlopban találhatók.
Kattintson az Adatok importálása modulra, állítsa az Adatforrás tulajdonságot webes URL-címre HTTP-n keresztül, az URL-címet pedig a következőre http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Állítsa be a Split Data modulban a betanításhoz használandó példányok töredékét (például 0,7).
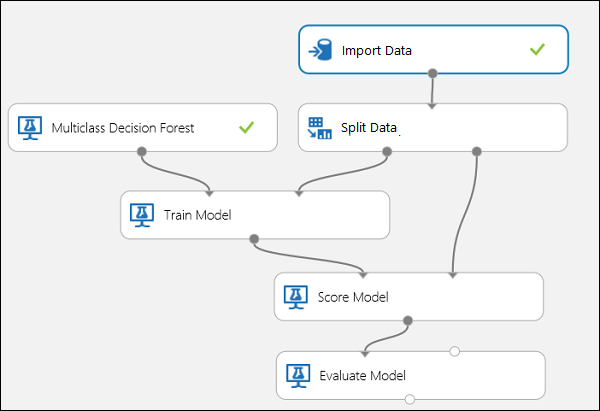
10. ábra. Többosztályos osztályozó kiértékelése
A kiértékelési eredmények vizsgálata
Futtassa a kísérletet, és kattintson a Modell kiértékelése kimeneti portjára. A kiértékelési eredmények ebben az esetben keveredési mátrix formájában jelennek meg. A mátrix mindhárom osztály tényleges és előrejelzett példányait mutatja.
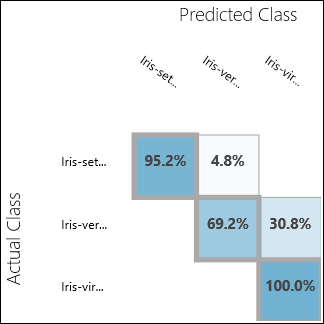
11. ábra. Többosztályos besorolás kiértékelési eredményei.
Keresztérvényesítés használata
Ahogy korábban említettük, a Modell keresztellenőrzése modul használatával automatikusan végezhet ismétlődő betanításokat, pontozásokat és értékeléseket. Szüksége lesz egy adatkészletre, egy nem betanított modellre és egy keresztellenőrzési modellmodulra (lásd az alábbi ábrát). Ismét be kell állítania a Modell keresztellenőrzése modul címkeoszlopát (ebben az esetben az 5. oszlopindexet). Miután futtatta a kísérletet, és a keresztellenőrzési modell megfelelő kimeneti portjára kattintott, megvizsgálhatja az egyes hajtások metrikaértékét, valamint a középértéket és a szórást. Az itt látható metrikák hasonlóak a bináris besorolási esetnél tárgyaltakhoz. A többosztályos besorolásban azonban a valódi pozitívok/negatívok és a hamis pozitívok/negatívok számítása osztályonként történik, mivel nincs általános pozitív vagy negatív osztály. Az "Iris-setosa" osztály pontosságának vagy visszahívásának kiszámításakor például azt feltételezik, hogy ez a pozitív osztály, a többi pedig negatív.
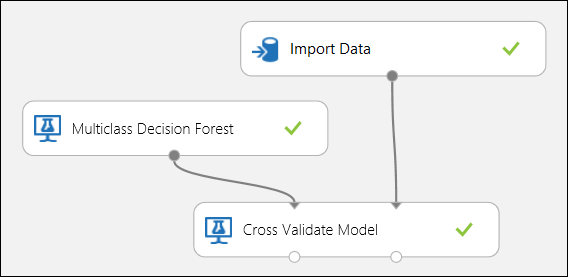
12. ábra. Többosztályos besorolási modell keresztkontrasztja.
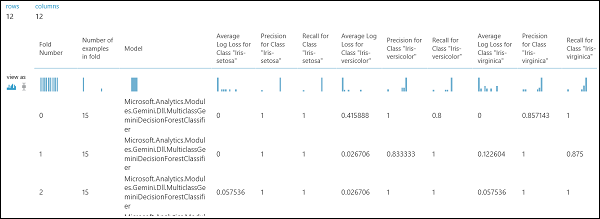
13. ábra. Többosztályos besorolási modell keresztérvényesítési eredményei.