Modelleredmények értelmezése a Machine Learning Studióban (klasszikus)
ÉRVÉNYES: Machine Learning Studio (klasszikus)
Machine Learning Studio (klasszikus)  Azure Machine Learning
Azure Machine Learning
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- A gépi tanulási projektek ML Studióból (klasszikus) Azure Machine Learningbe való áthelyezéséről szóló információk.
- További információ az Azure Machine Learningről
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
Ez a témakör azt ismerteti, hogyan jeleníthet meg és értelmezhet előrejelzési eredményeket a Machine Learning Studióban (klasszikus). Miután betanított egy modellt, és értékelte az előrejelzéseket rajta, meg kell értenie és értelmeznie az előrejelzés eredményét.
A Machine Learning Studióban négy fő gépi tanulási modell létezik (klasszikus):
- Osztályozás
- Klaszterezés
- Regresszió
- Ajánló rendszerek
Az előrejelzéshez használt modulok a következő modelleken alapulnak:
- Pontozási modell modul besoroláshoz és regresszióhoz
- Fürtökhöz való hozzárendelés modul a fürtözéshez
- Score Matchbox Recommender ajánlórendszerekhez
Megtudhatja, hogyan választhat paramétereket az algoritmusok optimalizálásához az ML Studio (klasszikus) alkalmazásban.
A modellek kiértékelésének módjáról a modell teljesítményének kiértékelése című témakörben olvashat.
Ha most ismerkedik az ML Studio (klasszikus) alkalmazással, megtudhatja, hogyan hozhat létre egy egyszerű kísérletet.
A besorolási problémáknak két alkategóriája van:
- A két osztályt érintő problémák (kétosztályos vagy bináris osztályozás esetén)
- Két osztálynál több osztály (többosztályos besorolás) problémái
A Machine Learning Studio (klasszikus) különböző modulokkal rendelkezik az ilyen típusú besorolások kezelésére, de az előrejelzési eredmények értelmezésének módszerei hasonlóak.
Példakísérlet
Egy kétosztályos besorolási problémára példa az íriszvirágok besorolása. A feladat az íriszvirágok besorolása a jellemzőik alapján. A Machine Learning Studióban (klasszikus) biztosított írisz adatkészlet a népszerű írisz adatkészlet egy része, amely csak két virágfaj példányait tartalmazza (0. és 1. osztály). Minden virághoz négy jellemző tartozik (a sepal hossza, a sepal szélessége, a szirom hossza és a sziromszélesség).
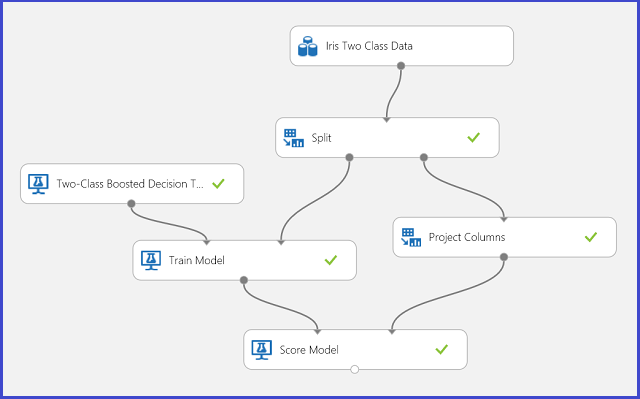
1. ábra Írisz kétosztályos besorolási problémakísérlet
Kísérlet történt a probléma megoldására az 1. ábrán látható módon. Betanítottunk és értékeltünk egy kétosztályos megerősített döntésifa-modellt. Most már vizualizálhatja az előrejelzési eredményeket a Score Model modulból a Score Model modul kimeneti portjára kattintva, majd a Vizualizáció gombra kattintva.
Ezzel a 2. ábrán látható pontozási eredmények jelennek meg.
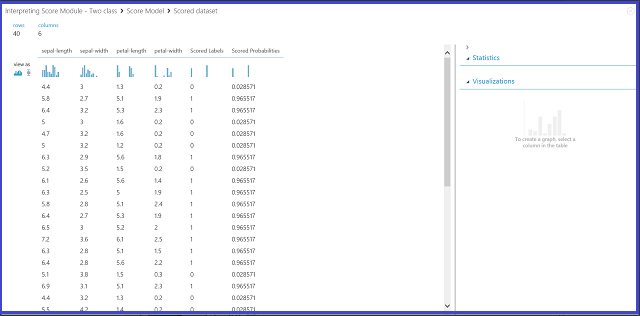
2. ábra Pontszámmodell eredményének vizualizációja kétosztályos besorolásban
Eredmény értelmezése
Az eredménytáblában hat oszlop található. A bal oldali négy oszlop a négy funkció. A jobb oldali két oszlop, a Pontozott címkék és a Pontozott valószínűségek az előrejelzési eredmények. A Pontozott valószínűségek oszlop azt a valószínűséget mutatja, hogy egy virág a pozitív osztályhoz tartozik (1. osztály). Az oszlop első száma (0,028571) például azt jelenti, hogy 0,028571 annak a valószínűsége, hogy az első virág az 1. osztályba tartozik. A Pontozott címkék oszlop az egyes virágok előrejelzett osztályát jeleníti meg. Ez a Pontozott valószínűség oszlopon alapul. Ha egy virág pontozott valószínűsége nagyobb, mint 0,5, akkor az 1. osztályként van előre jelezve. Ellenkező esetben a rendszer a 0. osztályt jelzi előre.
Webszolgáltatás publikáció
Miután az előrejelzési eredményeket megértettük és megbízhatónak ítéltük, a kísérlet közzétehető webszolgáltatásként, így üzembe helyezheti a különböző alkalmazásokban, és felhasználhatja osztályelőrejelzések beszerzésére bármely új íriszvirágon. Ha meg szeretné tudni, hogyan módosíthatja a betanítási kísérleteket pontozási kísérletté, és hogyan teheti közzé webszolgáltatásként, tekintse meg a 3. oktatóanyagot: Hitelkockázati modell üzembe helyezése. Ez az eljárás egy pontozási kísérletet biztosít a 3. ábrán látható módon.
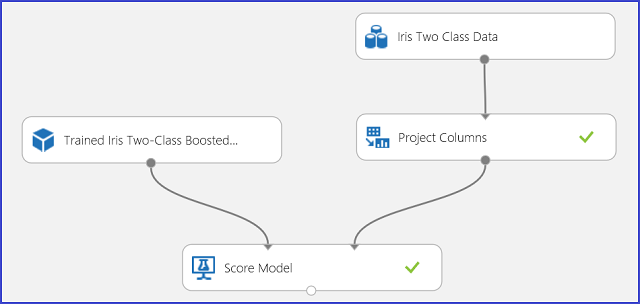
3. ábra Az írisz kétosztályos besorolási problémakísérletének pontozása
Most be kell állítania a webszolgáltatás bemenetét és kimenetét. A bemenet a Score Model jobb oldali bemeneti portja, amely az Írisz virág jellemzőinek bemenete. A kimenet kiválasztása attól függ, hogy érdekli-e az előrejelzett osztály (pontozott címke), a pontozott valószínűség vagy mindkettő. Ebben a példában feltételezzük, hogy mindkettő érdekli. A kívánt kimeneti oszlopok kiválasztásához használja az Oszlopok kijelölése az Adatkészlet modulban parancsot . Kattintson az Adathalmaz oszlopainak kiválasztására, kattintson az Oszlopkijelölő indítására, majd válassza ki a Pontozott címkéket és a Pontozott valószínűségeket. Miután beállította az Adathalmaz oszlopainak kijelölése kimeneti portját, és újra futtatta azt, készen kell állnia a pontozási kísérlet webszolgáltatásként való közzétételére a PUBLISH WEB SERVICE gombra kattintva. Az utolsó kísérlet a 4. ábrára hasonlít.
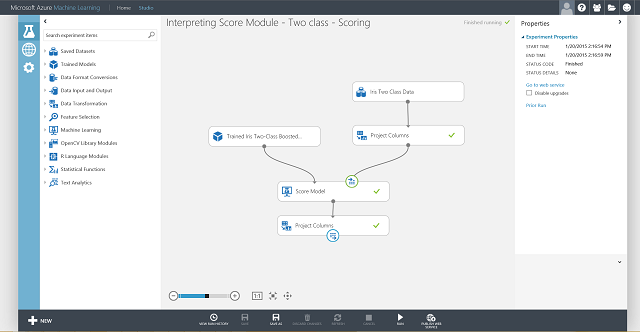
4. ábra Egy írisz kétosztályos besorolási probléma utolsó pontozási kísérlete
Miután futtatta a webszolgáltatást, és megadta egy tesztpéldány néhány funkcióértékét, az eredmény két számot ad vissza. Az első szám az értékelt címke, a második pedig az értékelt valószínűség. Ez a virág 0,9655-ös valószínűséggel 1. osztályként van előre jelezve.
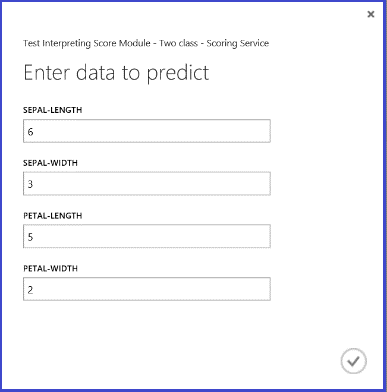

5. ábra Az írisz kétosztályos besorolásának webszolgáltatás-eredménye
Példakísérlet
Ebben a kísérletben egy betűfelismerő feladatot hajt végre a többosztályos besorolás példájaként. Az osztályozó megpróbál előrejelezni egy bizonyos %28class%29 betűt a kézzel írt képekből kinyert kézzel írt attribútumértékek alapján.
A betanítási adatokban 16 funkció van kinyerve kézzel írt levélképekből. A 26 betű alkotja a 26 osztályt. A 6. ábra egy olyan kísérletet mutat be, amely betanított egy többosztályos besorolási modellt a betűfelismeréshez, és előrejelezi a tesztadatkészlet ugyanazon funkciókészletét.
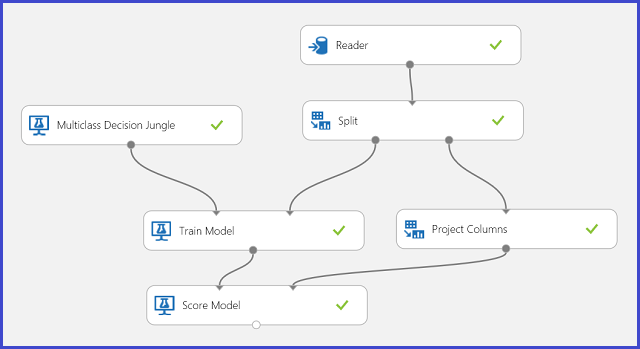
6. ábra Betűfelismerő többosztályos besorolási problémakísérlet
A Score Model modul eredményeinek vizualizációja a Score Model modul kimeneti portjára kattintva, majd a Vizualizáció gombra kattintva a 7. ábrán látható tartalomnak kell megjelennie.
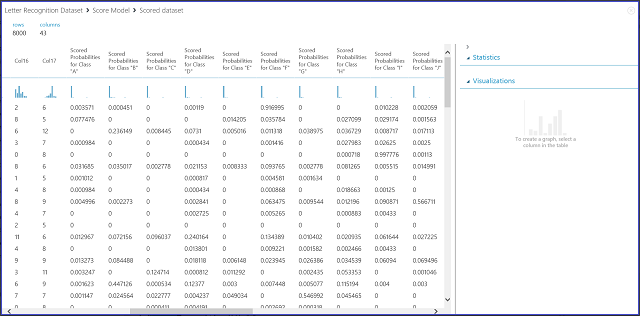
7. ábra Pontszámmodell eredményeinek vizualizációja többosztályos besorolásban
Eredmény értelmezése
A bal oldali 16 oszlop a tesztkészlet funkcióértékét jelöli. Az olyan nevű oszlopok, mint a "XX" osztályhoz tartozó pontozott valószínűségek, ugyanolyanok, mint a kétosztályos esetben a Pontozott valószínűség oszlop. Azt a valószínűséget mutatják, hogy a megfelelő bejegyzés egy adott osztályba tartozik. Az első bejegyzés esetében például 0,003571 valószínűsége van annak, hogy "A", 0,000451 valószínűsége, hogy "B" és így tovább. Az utolsó oszlop (Pontszám címkék) megegyezik a két osztályos esetben a Pontszám címkék oszlopával. A megfelelő bejegyzés előrejelzett osztályaként a legnagyobb pontozott valószínűséggel rendelkező osztályt választja ki. Az első bejegyzés esetében például a pontozott címke "F", mivel a legnagyobb valószínűséggel "F" (0,916995) lesz.
Webszolgáltatás közzététele
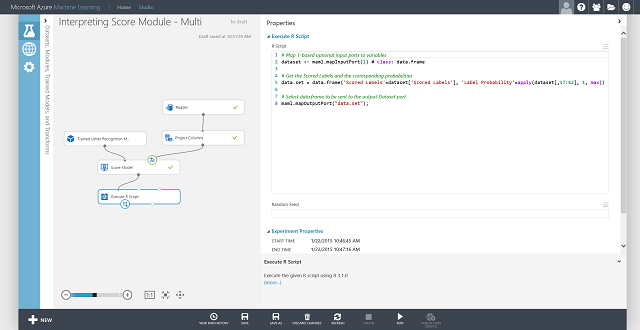
Az egyes bejegyzésekhez tartozó pontszámot és a pontozott címke valószínűségét is lekérheti. Az alaplogika az, hogy az összes pontozott valószínűség közül a legnagyobb valószínűséget kell megtalálni. Ehhez az R-szkript végrehajtása modult kell használnia. Az R-kód a 8. ábrán látható, a kísérlet eredménye pedig a 9. ábrán látható.

8. ábra R-kód a pontozott címkék kinyeréséhez és a címkék kapcsolódó valószínűségeihez
9. ábra A betűfelismerő többosztályos besorolási probléma utolsó pontozási kísérlete
Miután közzétette és futtatta a webszolgáltatást, és beírt néhány bemeneti funkcióértéket, a visszaadott eredmény a 10. ábrához hasonlóan néz ki. A kézírással készült levél, amelyből 16 jellemzőt vontak ki, 0,9715-es valószínűséggel "T" lesz.
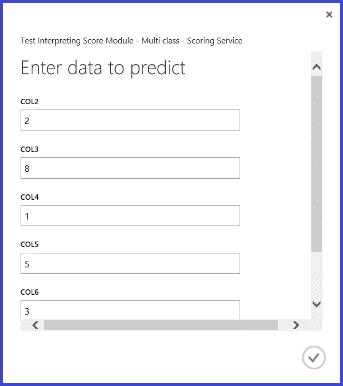

10. ábra A webszolgáltatás többosztályos besorolás eredménye
A regressziós problémák eltérnek a besorolási problémáktól. Besorolási probléma esetén diszkrét osztályokat próbál megjósolni, például azt, hogy melyik osztályhoz tartozik egy íriszvirág. De ahogy a regressziós probléma alábbi példájában látható, egy folyamatos változót próbál előrejelezni, például egy autó árát.
Példakísérlet
Használja az autóárak előrejelzését példaként a regresszióhoz. Megpróbáljuk előrejelezni az autó árát annak jellemzői alapján, beleértve a make, az üzemanyag típusát, a karosszéria típusát és a meghajtó kerekét. A kísérlet a 11. ábrán látható.
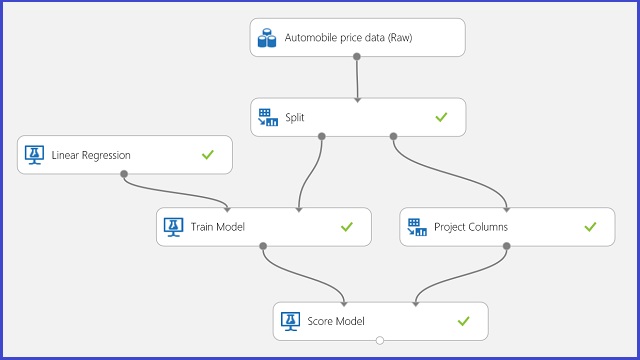
11. ábra Autóár-regressziós probléma kísérlet
A Pontozási modell modult vizualizálva az eredmény a 12. ábrához hasonlóan néz ki.
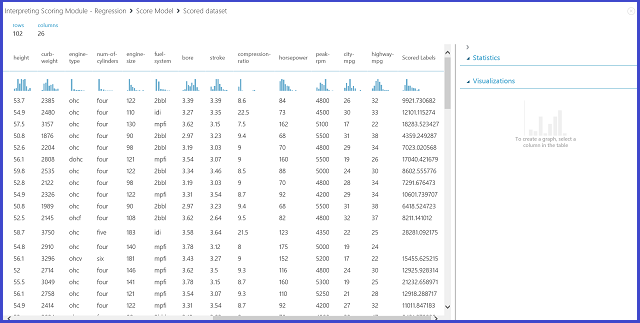
12. ábra. Az autóárak előrejelzési problémájának pontozási eredménye
Eredmény értelmezése
A "pontozott címkék" az eredményoszlop ebben a pontozási táblázatban. A számok az egyes autók előrejelzett ára.
Webszolgáltatás közzététele
A regressziós vizsgálatot közzéteheti egy webszolgáltatásban, és ugyanúgy használhatja az autóárak előrejelzéséhez, mint a kétosztályos besorolási esetben.
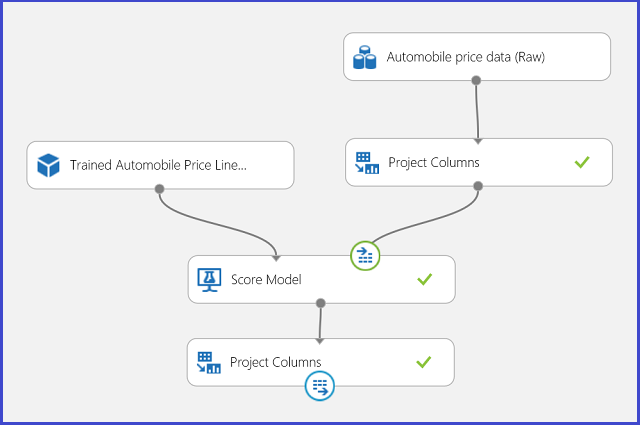
13. ábra. Egy autóárak regressziós problémájának pontozási kísérlete
A webszolgáltatás futtatása esetén a visszaadott eredmény a 14. ábrához hasonlóan néz ki. Az autó várható ára 15 085,52 dollár.
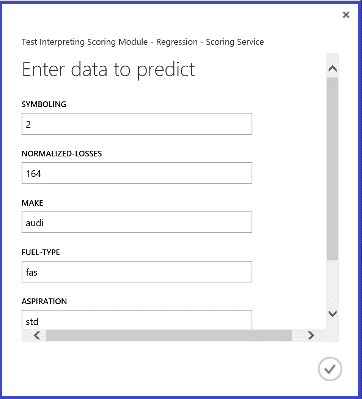

14. ábra. A webszolgáltatás egy autóárak regressziós problémájának eredménye
Példakísérlet
Használjuk újra az Írisz-adatkészletet egy fürtözési kísérlet létrehozásához. Itt kiszűrheti az osztálycímkéket az adatkészletből, hogy az csak a jellemzőket tartalmazza, és klaszterezésre használható legyen. Ebben az íriszhasználati esetben adja meg, hogy a betanítási folyamat során a fürtök száma kettő legyen, vagyis a virágokat két osztályba csoportosítja. A kísérlet a 15. ábrán látható.
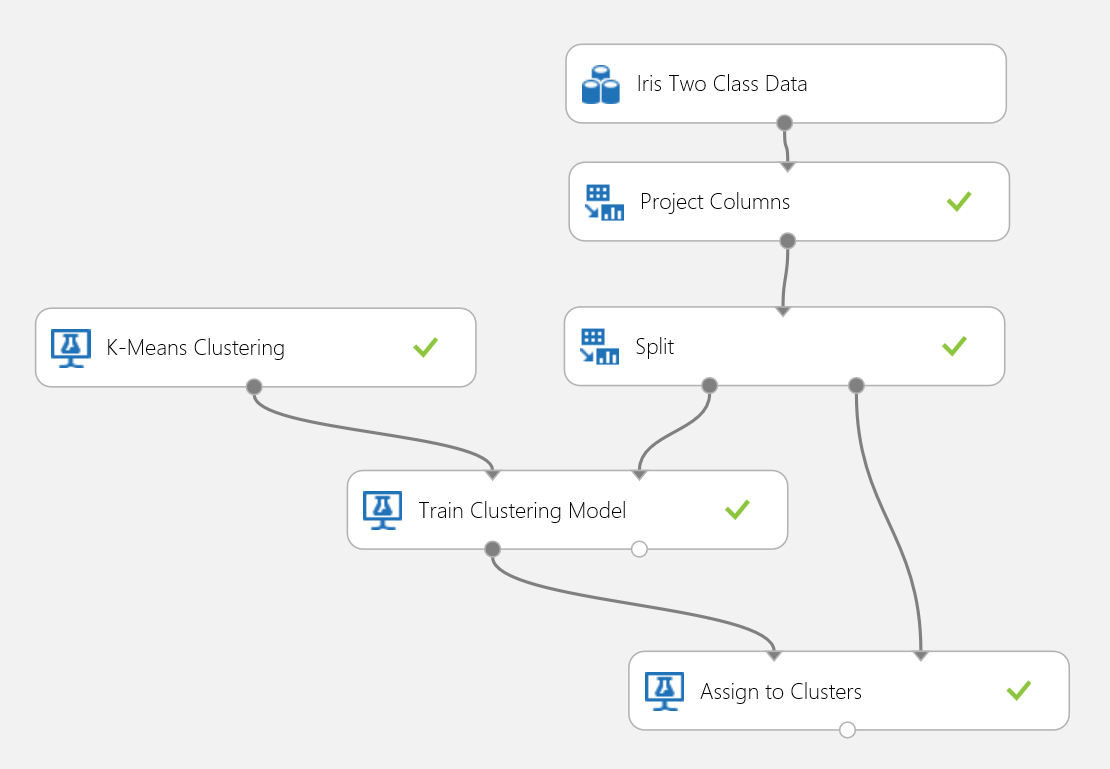
15. ábra. Írisz klaszterezési probléma kísérlete
A fürtözés abban különbözik a besorolástól, hogy a betanítási adatkészlet önmagában nem rendelkezik alapigaz címkékvel. A fürtözés a tanító adathalmaz példányait egyértelmű fürtökbe csoportosítja. A betanítási folyamat során a modell a funkciók közötti különbségek megismerésével címkézi a bejegyzéseket. Ezt követően a betanított modell használható a jövőbeli bejegyzések további besorolására. A fürtözési probléma eredményének két része van, amely minket érdekel. Az első rész a betanítási adatkészlet címkézése, a második pedig egy új adatkészlet besorolása a betanított modellel.
A Train Clustering Model bal oldali kimeneti portjára kattintva, majd a Vizualizálás gombra kattintva az eredmény első része vizualizálható. A vizualizáció a 16. ábrán látható.
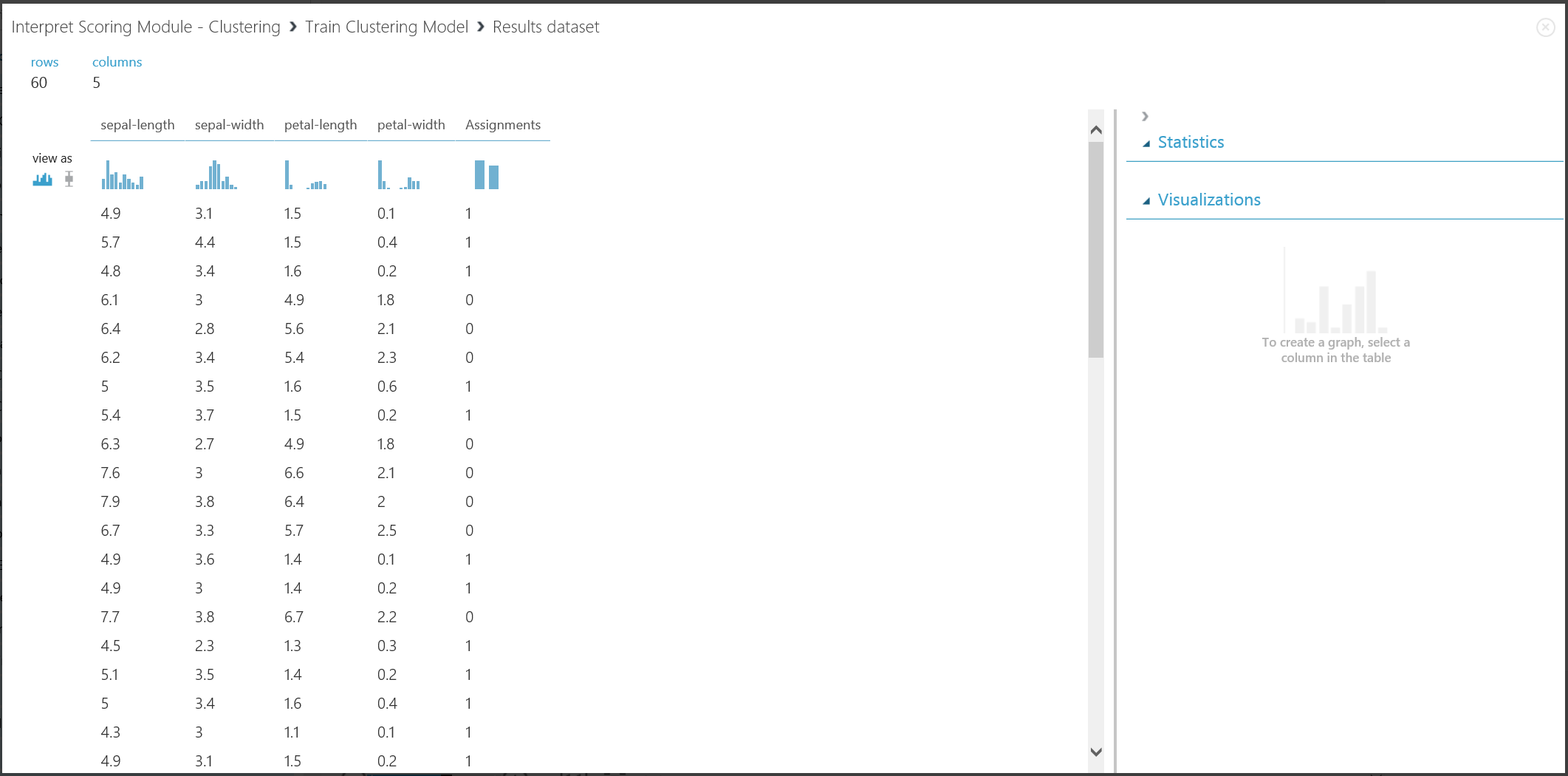
16. ábra. A betanítási adatkészlet fürtözési eredményének megjelenítése
A második rész eredménye, amely az új bejegyzések betanított fürtözési modellel történő csoportosítását mutatja be, a 17. ábrán látható.
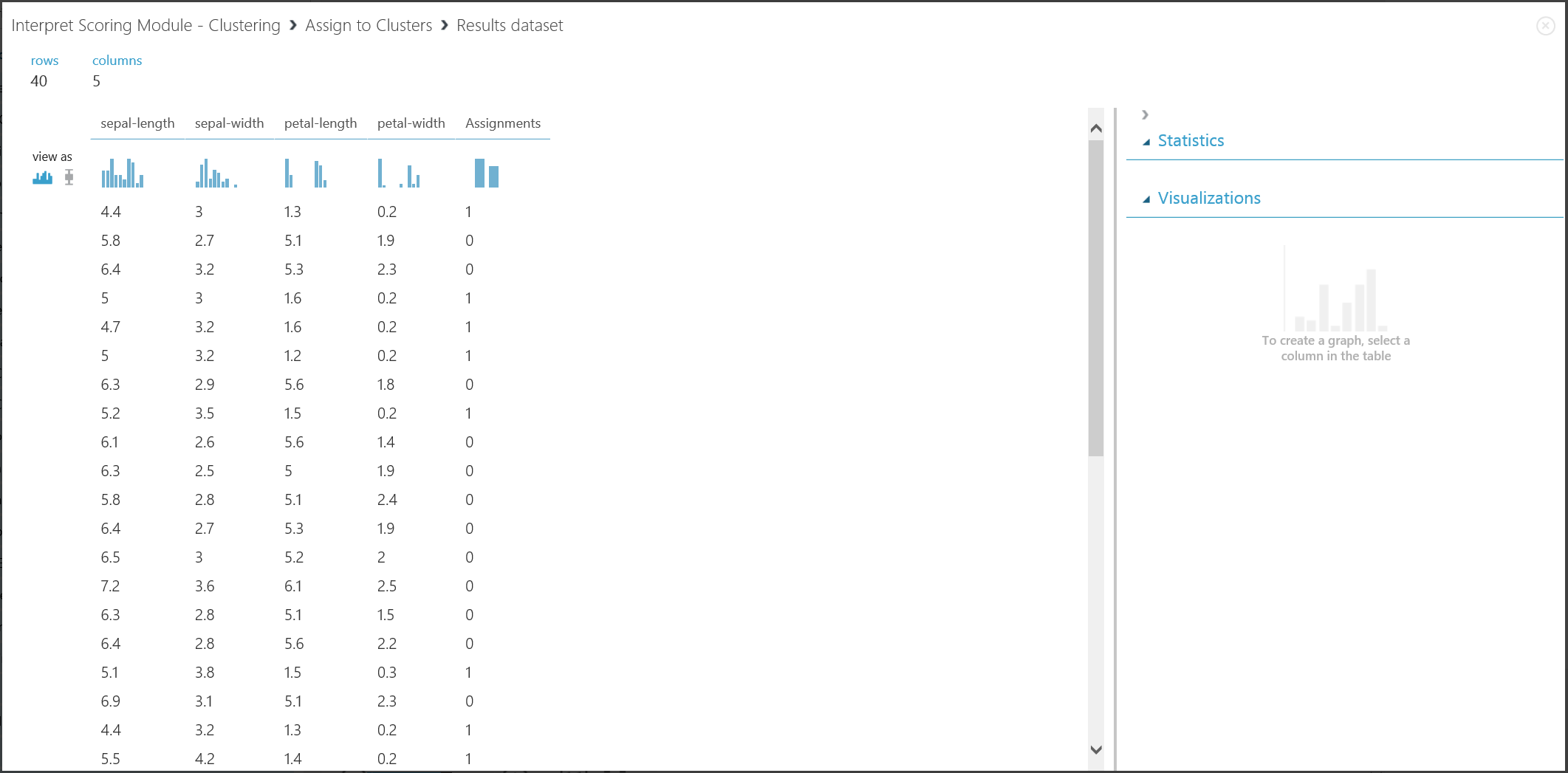
17. ábra. Az új adatkészleten a fürtözési eredmény megjelenítése
Eredmény értelmezése
Bár a két rész eredményei különböző kísérletszakaszokból származnak, ugyanúgy néznek ki, és ugyanúgy értelmezik őket. Az első négy oszlop jellemzők. Az utolsó oszlop, a Hozzárendelések az előrejelzés eredménye. Az azonos számmal hozzárendelt bejegyzések az előrejelzés szerint ugyanabban a fürtben vannak, vagyis valamilyen módon osztoznak a hasonlóságokon (ez a kísérlet az alapértelmezett euklideszi távolságmetrikát használja). Mivel a fürtök számát 2-nek adta meg, a hozzárendelések bejegyzései 0 vagy 1 címkével vannak ellátva.
Webszolgáltatás közzététele
A klaszterezési kísérletet közzéteheti egy webszolgáltatásban, és ugyanúgy meghívhatja a klaszterezési előrejelzések készítéséhez, mint a kétosztályos osztályozás használati esetében.
18. ábra. Írisz klaszterezési probléma értékelési kísérlete
A webszolgáltatás futtatása után a visszaadott eredmény a 19. ábrához hasonlóan néz ki. Ez a virág az előrejelzések szerint a 0. fürtben lesz.
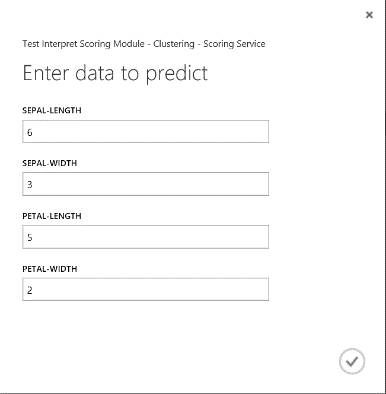

19. ábra. Az írisz kétosztályos besorolásának webszolgáltatás-eredménye
Példakísérlet
Az ajánlórendszerek esetében példaként használhatja az éttermi ajánlási problémát: a minősítési előzmények alapján javasolhat éttermeket az ügyfeleknek. A bemeneti adatok három részből állnak:
- Éttermi értékelések az ügyfelektől
- Ügyfélfunkciók adatai
- Éttermi szolgáltatási adatok
Számos dolgot tehetünk a Train Matchbox Recommender modullal a Machine Learning Studióban (klasszikus):
- Egy adott felhasználó és elem minősítésének előrejelzése
- Elemek ajánlása egy adott felhasználónak
- Adott felhasználóhoz kapcsolódó felhasználók keresése
- Adott elemhez kapcsolódó elemek keresése
A kívánt műveletet az Ajánló előrejelzési típus menüjében található négy lehetőség közül választhatja ki. Itt végigvezetheti mind a négy forgatókönyvet.
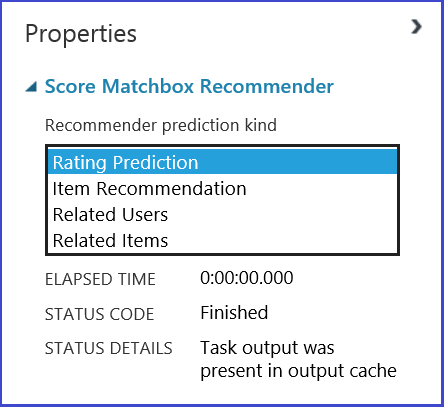
Egy ajánlórendszer tipikus Machine Learning Studio-kísérlete (klasszikus) a 20. ábrához hasonlóan néz ki. Az ajánló rendszermodulok használatáról további információt a Train matchbox recommender és a Score matchbox recommender részben talál.
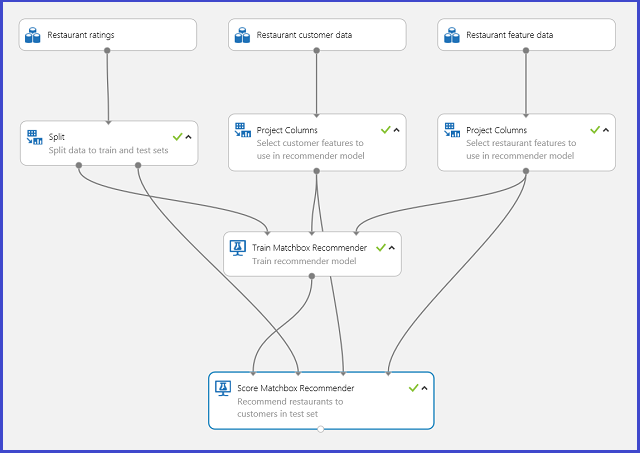
20. ábra. Ajánlórendszer kísérlet
Eredmény értelmezése
Egy adott felhasználó és elem minősítésének előrejelzése
Ha kiválasztja a Rating Prediction (Értékelés előrejelzése) lehetőséget az Ajánló előrejelzés típusa területen, arra kéri az ajánlórendszert, hogy előrejelezhesse az adott felhasználó és elem minősítését. A Score Matchbox Recommender kimenet vizualizációja a 21. ábrához hasonlóan néz ki.
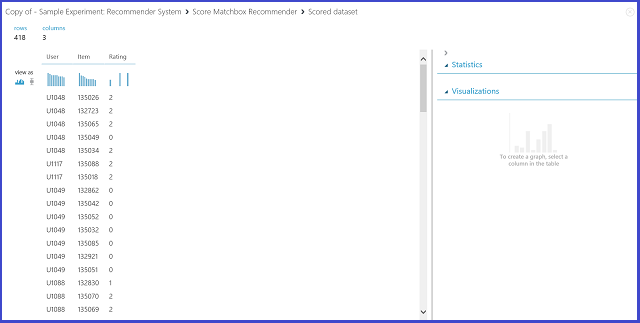
21. ábra. Az ajánló rendszer pontszámeredményének vizualizációja – értékelés előrejelzése
Az első két oszlop a bemeneti adatok által biztosított felhasználói-elem párok. A harmadik oszlop egy adott elem felhasználójának előrejelzett minősítése. Például, az első sorban az U1048-as ügyfél várhatóan 2-esre értékeli a 135026-os éttermet.
Elemek ajánlása egy adott felhasználónak
Ha az Ajánló előrejelzés típusa területen az Elemjavaslat lehetőséget választja, arra kéri az ajánlórendszert, hogy javasoljon elemeket egy adott felhasználónak. Ebben a forgatókönyvben az utolsó kiválasztandó paraméter az Ajánlott elem kiválasztása. A Besorolási elemekből (modellértékeléshez) lehetőség elsősorban a modellértékelésre használható a betanítási folyamat folyamán. Ebben az előrejelzési szakaszban az Összes elem közül választunk. A Score Matchbox Recommender kimenet vizualizációja a 22. ábrához hasonlóan néz ki.
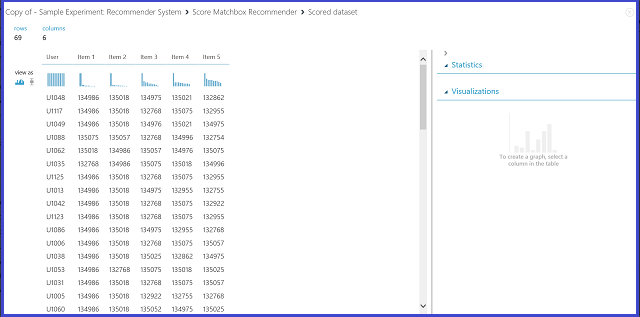
22. ábra. Az ajánló rendszer pontszámeredményének vizualizációja – elemjavaslat
A hat oszlop közül az első azokat a felhasználói azonosítókat jelöli, amelyekhez a bemeneti adatok által megadott elemeket javasolni kell. A másik öt oszlop azokat az elemeket jelöli, amelyek a felhasználó számára ajánlottak csökkenő relevancia szerint. Az első sorban például az U1048-ügyfél számára ajánlott étterem 134986, amelyet 135018, 134975, 135021 és 132862 követ.
Adott felhasználóhoz kapcsolódó felhasználók keresése
Ha a Kapcsolódó felhasználók lehetőséget választja az Ajánló előrejelzés típusa alatt, arra kéri az ajánlórendszert, hogy keresse meg az adott felhasználóhoz kapcsolódó felhasználókat. A kapcsolódó felhasználók azok a felhasználók, akik hasonló beállításokkal rendelkeznek. Ebben a forgatókönyvben az utolsó kiválasztandó paraméter a Kapcsolódó felhasználó kiválasztása. A felhasználók által minősített elemek (a modell kiértékeléséhez) lehetőség elsősorban a modell kiértékeléséhez használható a betanítási folyamat során. Ehhez az előrejelzési fázishoz válassza a Minden felhasználó lehetőséget. A Score Matchbox Recommender kimenet vizualizációja a 23. ábrához hasonlóan néz ki.
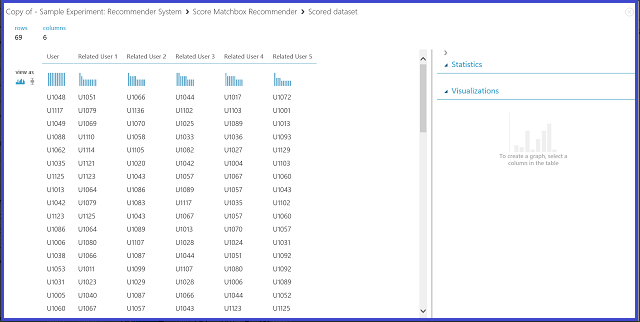
23. ábra. Az ajánló rendszerhez kapcsolódó felhasználók pontszámának megjelenítése
A hat oszlop közül az első a kapcsolódó felhasználók megkereséséhez szükséges felhasználói azonosítókat jeleníti meg, a bemeneti adatoknak megfelelően. A másik öt oszlop csökkenő fontosságú sorrendben tárolja a felhasználó előrejelzett kapcsolódó felhasználóit. Az első sorban például az U1048 ügyfél szempontjából a legrelevánsabb ügyfél az U1051, majd az U1066, az U1044, az U1017 és az U1072.
Adott elemhez kapcsolódó elemek keresése
Ha a Kapcsolódó elemek lehetőséget választja az Ajánló előrejelzés típusa területen, arra kéri az ajánlórendszert, hogy keresse meg az adott elemhez kapcsolódó elemeket. A kapcsolódó elemek azok az elemek, amelyeket valószínűleg ugyanaz a felhasználó kedvel. Ebben a forgatókönyvben az utolsó kiválasztandó paraméter a Kapcsolódó elem kiválasztása. A Besorolási elemekből (modellértékeléshez) lehetőséget elsősorban a modell értékelésére használják a betanítási folyamat során. Ehhez az előrejelzési fázishoz az Összes elem lehetőséget választjuk. A Score Matchbox Recommender kimenet vizualizációja a 24. ábrához hasonlóan néz ki.
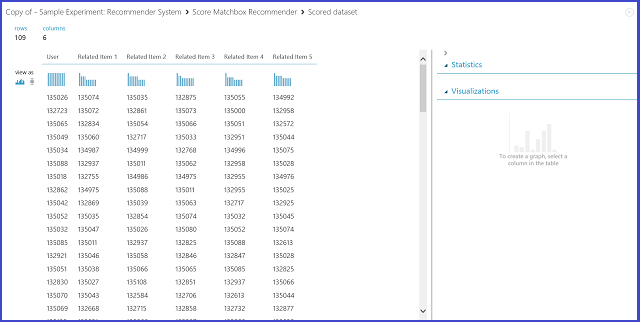
24. ábra. Az ajánló rendszerhez kapcsolódó elemek pontszámának megjelenítése
A hat oszlop közül az első a kapcsolódó elemek megkereséséhez szükséges adott elemazonosítókat jelöli a bemeneti adatoknak megfelelően. A másik öt oszlop a relevancia szempontjából csökkenő sorrendben tárolja az elem előrejelzett kapcsolódó elemeit. Az első sorban például az elem 135026 legrelevánsabb eleme a 135074, majd a 135035, 132875, 135055 és 134992.
Webszolgáltatás közzététele
A kísérletek webes szolgáltatásként való közzétételének folyamata az előrejelzések lekéréséhez hasonló a négy forgatókönyv mindegyikéhez. Ebben a példában a második forgatókönyvet vesszük példaként (elemeket ajánlunk egy adott felhasználónak). Ugyanezt az eljárást a másik háromnál is követheti.
A betanított ajánlórendszert betanított modellként mentve, és a bemeneti adatokat igény szerint egyetlen felhasználói azonosító oszlopra szűrve csatlakoztathatja a kísérletet a 25. ábrához hasonlóan, és közzéteheti webszolgáltatásként.
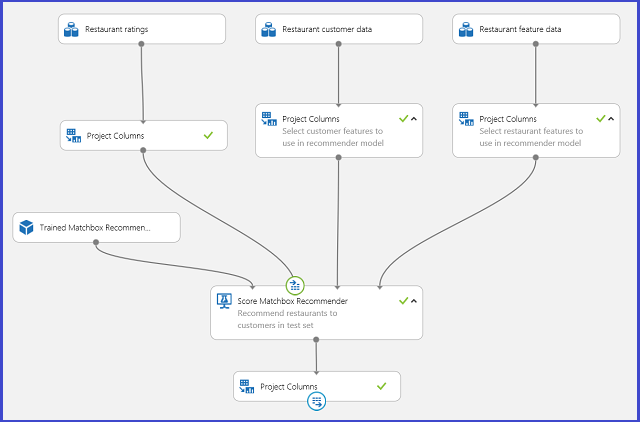
25. ábra. Az étterem ajánlási problémájának pontozási kísérlete
A webszolgáltatás futtatásával a visszaadott eredmény a 26. ábrához hasonlóan néz ki. Az U1048 felhasználóinak ajánlott öt étterem 134986, 135018, 134975, 135021 és 132862.
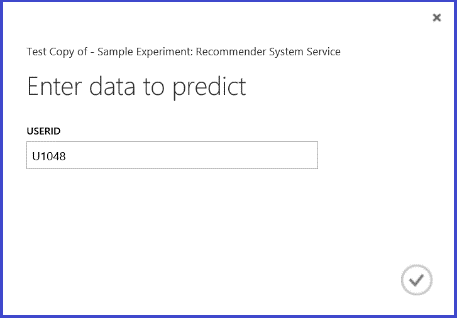

26. ábra. A webszolgáltatás éttermi javaslattal kapcsolatos problémájának eredménye