Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Legalább minden SQL Server-adatbázis két operációsrendszer-fájllal rendelkezik: egy adatfájllal és egy naplófájllal. Az adatfájlok olyan adatokat és objektumokat tartalmaznak, mint a táblák, indexek, tárolt eljárások és nézetek. A naplófájlok tartalmazzák az adatbázis összes tranzakciójának helyreállításához szükséges információkat. Az adatfájlok fájlcsoportokba csoportosíthatók foglalási és adminisztrációs célokra.
Adatbázisfájlok
Az SQL Server-adatbázisok három fájltípussal rendelkeznek, ahogyan az az alábbi táblázatban is látható.
| File | Description |
|---|---|
| Elsődleges | Az adatbázis indítási adatait tartalmazza, és az adatbázis többi fájlra mutat. Minden adatbázis egy elsődleges adatfájllal rendelkezik. Az elsődleges adatfájlok ajánlott fájlnévkiterjesztése a következő .mdf: . |
| másodlagos | Nem kötelező, felhasználó által definiált adatfájlok. Az adatok több lemezen is eloszthatók, ha mindegyik fájlt egy másik lemezmeghajtóra helyezik. A másodlagos adatfájlok ajánlott fájlnévkiterjesztése a következő .ndf: . |
| Tranzakció-napló | A napló az adatbázis helyreállításához használt adatokat tartalmazza. Minden adatbázishoz legalább egy naplófájlnak kell lennie. A tranzakciónaplókhoz ajánlott fájlnévkiterjesztés a következő .ldf: . |
Egy egyszerű, elnevezett Sales adatbázis például egy elsődleges fájllal rendelkezik, amely tartalmazza az összes adatot és objektumot, valamint egy naplófájlt, amely tartalmazza a tranzakciónapló adatait. Egy összetettebb nevű Orders adatbázis hozható létre, amely egy elsődleges fájlt és öt másodlagos fájlt tartalmaz. Az adatbázisban lévő adatok és objektumok mind a hat fájlra kiterjednek, a négy naplófájl pedig a tranzakciónapló adatait tartalmazza.
Alapértelmezés szerint az adatok és a tranzakciónaplók ugyanarra a meghajtóra és elérési útra kerülnek az egylemezes rendszerek kezeléséhez. Lehet, hogy ez a választás nem optimális gyártási környezetekhez. Javasoljuk, hogy külön lemezekre helyezzen adatokat és naplófájlokat.
Logikai és fizikai fájlnevek
Az SQL Server-fájlok két fájlnévtípust különböztetnek meg:
logical_file_name: A fizikai fájlra való hivatkozáshoz használt név az összes Transact-SQL utasításban. A logikai fájlnévnek meg kell felelnie az SQL Server-azonosítókra vonatkozó szabályoknak, és egyedinek kell lennie az adatbázisban található logikai fájlnevek között.os_file_name: A fizikai fájl neve, beleértve a könyvtár elérési útját. Az operációsrendszer-fájlnevekre vonatkozó szabályokat kell követnie.
A NAME és FILENAME argumentumokról további információt az ALTER DATABASE fájl és fájlcsoport beállításai című témakörben talál.
Ha az SQL Server több példánya fut egyetlen számítógépen, minden példány egy másik alapértelmezett könyvtárat kap a példányban létrehozott adatbázisok fájljainak tárolásához. További információ: Az SQL Server alapértelmezett és elnevezett példányainak fájlhelyei.
Fájlrendszer-támogatás
Az SQL Server-adatok és naplófájlok FAT- vagy NTFS-fájlrendszereken is elhelyezhetők. Windows rendszereken a Microsoft az NTFS fájlrendszer használatát javasolja, mert az NTFS biztonsági szempontjait figyelembe véve.
Az olvasási/írási adatfájlcsoportok és naplófájlok ntfs tömörített fájlrendszereken nem támogatottak. Ntfs tömörített fájlrendszerre csak írásvédett adatbázisok és írásvédett másodlagos fájlcsoportok helyezhetők el. Helytakarékossághoz használjon adattömörítést a fájlrendszer tömörítése helyett.
Adatfájl-lapok
Az SQL Server-adatfájlban lévő lapok számozása sorrendben, nullával (0) kezdődik a fájl első oldalához. Az adatbázis minden fájlja egyedi fájlazonosítóval rendelkezik. Egy adatbázis lapjának egyedi azonosításához a fájlazonosítóra és az oldalszámra is szükség van. Az alábbi példa egy 4 MB elsődleges adatfájllal és egy 1 MB másodlagos adatfájllal rendelkező adatbázis oldalszámát mutatja be.
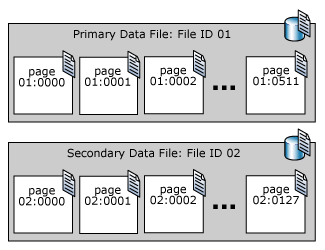
A fájlfejléclap az első oldal, amely a fájl attribútumairól tartalmaz információkat. A fájl elején található lapok közül több is tartalmaz rendszerinformációkat, például foglalási térképeket. Az elsődleges adatfájlban és az első naplófájlban tárolt rendszeroldalak egyike egy adatbázis-rendszerindító oldal, amely az adatbázis attribútumairól tartalmaz információkat.
Fájlméret
Az SQL Server-fájlok az eredetileg megadott méretüktől kezdve automatikusan növekedhetnek. Fájl definiálásakor megadhat egy adott növekedési növekményt. Minden alkalommal, amikor a fájl megtelik, a növekedés növekedésével növeli a méretét. Ha egy fájlcsoportban több fájl található, nem fognak automatikusan növekedni (méretben), amíg minden fájl meg nem telik.
Az oldalakról és az oldaltípusokról további információt a Pages and Extents architektúra útmutatójában talál.
Az egyes fájlok maximális mérete is megadható. Ha nincs megadva a maximális méret, a fájl tovább növekedhet, amíg a lemezen nem használja az összes rendelkezésre álló helyet. Ez a funkció különösen akkor hasznos, ha az SQL Servert olyan alkalmazásba beágyazott adatbázisként használják, amelyben a felhasználó nem rendelkezik megfelelő hozzáféréssel a rendszergazdához. A felhasználó engedélyezheti, hogy a fájlok szükség szerint automatikusan növekedjenek az adatbázis szabad területének felügyelete és a további tárhely manuális kiosztása adminisztrációs terheinek csökkentése érdekében.
A tranzakciónapló-fájlkezeléssel kapcsolatos további információkért lásd a tranzakciónapló-fájl méretének kezelését ismertető témakört.
Adatbázis-pillanatképfájlok
Az adatbázis-pillanatképek által az írásra másolt adatok tárolására használt fájl formája attól függ, hogy a pillanatképet egy felhasználó hozza-e létre, vagy belsőleg használja-e:
A felhasználó által létrehozott adatbázis-pillanatképek egy vagy több ritka fájlban tárolják az adatait. A ritka fájltechnológia az NTFS fájlrendszer egyik funkciója. Először a ritka fájlok nem tartalmaznak felhasználói adatokat, és a felhasználói adatok lemezterülete nem lett lefoglalva a ritka fájlhoz. A ritkán használt fájlok adatbázis-pillanatképekben való használatáról és az adatbázis-pillanatképek növekedéséről az adatbázis-pillanatképek ritkán használt fájljának méretének megtekintése című témakörben olvashat.
Az adatbázis-pillanatképeket egyes DBCC-parancsok belsőleg használják. Ezek a parancsok a következők:
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOCésDBCC CHECKFILEGROUP. Az adatbázis-pillanatképek belső készítése során az eredeti adatbázisfájlok ritka alternatív adatfolyamait használják. A ritka fájlokhoz hasonlóan a másodlagos adatfolyamok is az NTFS fájlrendszer egyik funkciója. A ritka alternatív adatfolyamok használata lehetővé teszi, hogy több adatfoglalás egyetlen fájlhoz vagy mappához legyen társítva anélkül, hogy ez hatással lenne a fájlméretre vagy a kötetstatisztikára.
Filegroups
- Az elsődleges fájlcsoport tartalmazza az elsődleges adatfájlt és azokat a másodlagos fájlokat, amelyek nem kerülnek más fájlcsoportokba.
- Felhasználó által definiált fájlcsoportok hozhatók létre az adatfájlok felügyeleti, adatelosztási és elhelyezési célokra való csoportosításához.
Például: Data1.ndf, Data2.ndfés Data3.ndf, három lemezmeghajtón hozható létre, és hozzárendelhető a fájlcsoporthoz fgroup1. Ezután létrehozhat egy táblát kifejezetten a fájlcsoporton fgroup1. A tábla adataira vonatkozó lekérdezések a három lemezen lesznek elosztva; javítja a teljesítményt. Ugyanez a teljesítménybeli javulás egy RAID (független lemezek redundáns tömbje) szalagkészleten létrehozott egyetlen fájllal is elvégezhető. A fájlok és a fájlcsoportok azonban lehetővé teszik új fájlok új lemezekhez való hozzáadását.
Az összes adatfájl az alábbi táblázatban felsorolt fájlcsoportokban van tárolva.
| Filegroup | Description |
|---|---|
| Elsődleges | Az elsődleges fájlt tartalmazó fájlcsoport. Minden rendszertábla az elsődleges fájlcsoport része. |
| Memóriaoptimalizált adatok | A memóriaoptimalizált fájlcsoport a FILESTREAM fájlcsoporton alapul |
| Filestream | A fájlrendszerkönyvtárakban tárolt strukturálatlan adatok. |
| Felhasználó által definiált | Minden olyan fájlcsoport, amelyet a felhasználó akkor hoz létre, amikor a felhasználó először létrehozza vagy később módosítja az adatbázist. |
Alapértelmezett (elsődleges) fájlcsoport
Ha az objektumok anélkül jönnek létre az adatbázisban, hogy meg nem adják, hogy melyik fájlcsoporthoz tartoznak, a rendszer az alapértelmezett fájlcsoporthoz rendeli őket. A rendszer bármikor pontosan egy fájlcsoportot jelöl ki alapértelmezett fájlcsoportként. Az alapértelmezett fájlcsoport fájljainak elég nagynak kell lenniük ahhoz, hogy minden olyan új objektumot tartsanak, amelyet más fájlcsoportok nem foglalnak le.
A PRIMARY fájlcsoport az alapértelmezett fájlcsoport, kivéve, ha az ALTER DATABASE utasítás használatával módosul. A rendszerobjektumok és táblák kiosztása a PRIMARY fájlcsoporton belül marad, nem pedig az új alapértelmezett fájlcsoportban.
Memóriaoptimalizált adatfájlcsoport
A memóriaoptimalizált fájlcsoportokról további információt a Memóriaoptimalizált fájlcsoport című témakörben talál.
FILESTREAM fájlcsoport
A FILESTREAM-fájlcsoportokról további információt a FILESTREAM és a FILESTREAM-Enabled-adatbázis létrehozása című témakörben talál.
Példa fájl- és fájlcsoportra
Az alábbi példa létrehoz egy adatbázist az SQL Server egy példányán. Az adatbázis elsődleges adatfájllal, felhasználó által definiált fájlcsoporttal és naplófájllal rendelkezik. Az elsődleges adatfájl az elsődleges fájlcsoportban található, a felhasználó által definiált fájlcsoport pedig két másodlagos adatfájllal rendelkezik. Egy ALTER DATABASE utasítás a felhasználó által definiált fájlcsoportot állítja alapértelmezettként. Ezután létrejön egy tábla, amely megadja a felhasználó által definiált fájlcsoportot. (Ez a példa egy általános elérési utat C:\Program Files\Microsoft SQL Server\MSSQL.1 használ az SQL Server verziójának megadásának elkerülése érdekében.)
USE master;
GO
-- Create the database with the default data
-- filegroup, FILESTREAM filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON
PRIMARY (
NAME = 'MyDB_Primary',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE = 4 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP MyDB_FG1 (
NAME = 'MyDB_FG1_Dat1',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB, FILEGROWTH = 1 MB
), (
NAME = 'MyDB_FG1_Dat2',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM (
NAME = 'MyDB_FG_FS',
FILENAME = 'C:\Data\filestream1'
)
LOG ON (
NAME = 'MyDB_log',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
);
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
-- Create a table in the user-defined filegroup.
USE MyDB;
GO
CREATE TABLE MyTable
(
cola INT PRIMARY KEY,
colb CHAR (8)
) ON MyDB_FG1;
GO
-- Create a table in the FILESTREAM filegroup
CREATE TABLE MyFSTable
(
cola INT PRIMARY KEY,
colb VARBINARY (MAX) FILESTREAM NULL
);
Az alábbi ábra az előző példa eredményeit foglalja össze (a FILESTREAM-adatok kivételével).

Fájl- és fájlcsoportkitöltési stratégia
A fájlcsoportok arányos kitöltési stratégiát használnak az egyes fájlcsoportokon belüli összes fájlra vonatkozóan. Mivel az adatok a fájlcsoportba íródnak, az SQL Server adatbázismotor a fájlban lévő szabad területtel arányos összeget ír a fájlcsoport minden fájljára, ahelyett, hogy az összes adatot az első fájlba írné, amíg meg nem telik. Ezután a következő fájlba ír. Ha például a fájl f1 100 MB szabad, és a fájl f2 200 MB szabad, akkor egy kiterjesztés adható meg a fájlból f1, két kiterjesztés a fájlból f2, és így tovább. Ily módon mindkét fájl körülbelül egy időben megtelik, és egyszerű csíkozás érhető el.
Egy fájlcsoport például három fájlból áll, és mindegyik automatikusan növekszik. Ha a fájlcsoport összes fájljában elfogy a hely, csak az első fájl lesz kibontva. Ha az első fájl megtelt, és nem lehet több adatot írni a fájlcsoportba, a második fájl ki lesz bontva. Ha a második fájl megtelt, és nem lehet több adatot írni a fájlcsoportba, a harmadik fájl ki lesz bontva. Ha a harmadik fájl megtelik, és nem lehet több adatot írni a fájlcsoportba, az első fájl újra ki lesz bontva, és így tovább.
Fájlok és fájlcsoportok tervezésének szabályai
A következő szabályok fájlokra és fájlcsoportokra vonatkoznak:
Több adatbázis nem használhat fájlokat vagy fájlcsoportokat. Az értékesítési adatbázisból származó adatokat és objektumokat tartalmazó fájlokat
sales.mdféssales.ndfobjektumokat például más adatbázisok nem használhatják.Egy fájl csak egy fájlcsoport tagja lehet.
A tranzakciós naplófájlok soha nem részei egyetlen fájlcsoportnak sem.
Recommendations
Javaslatok fájlok és fájlcsoportok használatakor:
A legtöbb adatbázis jól működik egyetlen adatfájllal és egyetlen tranzakciós naplófájllal.
Ha több adatfájlt használ, hozzon létre egy második fájlcsoportot a további fájlhoz, és állítsa a fájlcsoportot az alapértelmezett fájlcsoportra. Ily módon az elsődleges fájl csak rendszertáblákat és objektumokat fog tartalmazni.
A teljesítmény maximalizálása érdekében a lehető legtöbb rendelkezésre álló lemezen hozzon létre fájlokat vagy fájlcsoportokat. Helyezzen el olyan objektumokat, amelyek nagy mértékben versenyeznek a különböző fájlcsoportokban lévő térért.
Fájlcsoportok használatával engedélyezheti az objektumok adott fizikai lemezeken való elhelyezését.
Helyezzen el különböző táblákat, amelyeket ugyanabban az illesztő lekérdezésben használnak különböző fájlcsoportokban. Ez a lépés javítja a teljesítményt, mivel a párhuzamos lemez I/O az összekapcsolt adatokat keresi.
Helyezze a gyakran elért táblákat és a hozzájuk tartozó nem klaszteres indexeket külön fájlcsoportokba. A különböző fájlcsoportok használata a párhuzamos I/O miatt javítja a teljesítményt, ha a fájlok különböző fizikai lemezeken találhatók.
Ne helyezze a tranzakciónapló-fájlokat ugyanarra a fizikai lemezre, amelyen a többi fájl és fájlcsoport található.
Ha ki kell terjesztenie egy kötetet vagy partíciót, amelyen az adatbázisfájlok találhatók olyan eszközökkel, mint a diskpart, biztonsági másolatot kell készítenie az összes rendszer- és felhasználói adatbázisról, és először le kell állítania az SQL Server-szolgáltatásokat. A lemezkötetek sikeres kiterjesztése után érdemes a DBCC CHECKDB parancs futtatásával biztosítani a köteten található összes adatbázis fizikai integritását.
A tranzakciónapló-fájlkezelési javaslatokról további információt a tranzakciónapló-fájl méretének kezelése című témakörben talál.