Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Felügyelt Azure SQL-példány
Felügyelt Azure SQL-példány![]() SQL-adatbázis a Microsoft Fabricben
SQL-adatbázis a Microsoft Fabricben
Az SQL Server adatbázismotor különböző adattárolási architektúrák lekérdezéseit dolgozza fel, például helyi táblákat, particionált táblákat és több kiszolgáló között elosztott táblákat. Az alábbi szakaszok azt ismertetik, hogyan dolgozza fel az SQL Server a lekérdezéseket, és hogyan optimalizálja a lekérdezések újrafelhasználását a végrehajtási terv gyorsítótárazásával.
Végrehajtási módok
Az SQL Server adatbázismotor két különböző feldolgozási móddal képes feldolgozni Transact-SQL utasításokat:
- Soros üzemmód végrehajtása
- Kötegelt üzemmód végrehajtása
Soros üzemmód végrehajtása
A sor módú végrehajtás a hagyományos RDBMS-táblákhoz használt lekérdezésfeldolgozási módszer, ahol az adatok sorformátumban vannak tárolva. Amikor végrehajt egy lekérdezést, és hozzáfér a sortároló táblákban lévő adatokhoz, a végrehajtási fa operátorai és a gyermek operátorok felolvassák a szükséges sorokat a táblasémában megadott összes oszlopban. Az SQL Server minden beolvasott sorból lekéri az eredményhalmazhoz szükséges oszlopokat egy SELECT utasítás, JOIN predikátum vagy szűrő predikátum alapján.
Megjegyzés:
A sor mód végrehajtása nagyon hatékony az OLTP-forgatókönyvek esetében, de nagy mennyiségű adat beolvasása esetén kevésbé hatékony lehet, például adatraktározási forgatókönyvekben.
Kötegelt üzemmód végrehajtása
A batch módú végrehajtás egy lekérdezésfeldolgozási módszer, amellyel több sort dolgoznak fel együtt (tehát a köteg kifejezést). A köteg minden oszlopa vektorként van tárolva egy külön memóriaterületen, így a kötegelt mód feldolgozása vektoralapú. A Batch mód feldolgozása olyan algoritmusokat is használ, amelyek a modern hardvereken található többmagos processzorokra és nagyobb memória-átviteli sebességre vannak optimalizálva.
Első bevezetésekor a kötegelt módú végrehajtás szorosan integrálva lett az oszlopcentrikus tárolási formátummal, és optimalizálva lett. Azonban az SQL Server 2019 (15.x) verziótól és az Azure SQL Database-ben a kötegelt üzemmódú végrehajtáshoz már nincs szükség oszlopcentrikus indexekre. További információt a kötegelt üzemmódról a sor-tárolón talál.
A Kötegelt mód feldolgozása a tömörített adatokon működik, ha lehetséges, és kiküszöböli a sor mód végrehajtásához használt exchange-operátort . Az eredmény jobb párhuzamosság és gyorsabb teljesítmény.
Ha egy lekérdezés kötegelt módban van végrehajtva, és oszlophalmozott indexekben fér hozzá az adatokhoz, a végrehajtási fa operátorai és gyermek operátorai több sort egyszerre olvasnak oszlopszegmensekben. Az SQL Server csak az eredményhez szükséges oszlopokat olvassa be a SELECT utasítás, a JOIN predikátum vagy a szűrő predikátum alapján. Az oszlopcentrikus indexekre vonatkozó további információkért lásd: Oszlopcentrikus indexarchitektúra.
Megjegyzés:
A Batch mód végrehajtása nagyon hatékony Adatraktározási forgatókönyvek, ahol nagy mennyiségű adat olvasható és összesítve van.
SQL-utasítás feldolgozása
Egyetlen Transact-SQL utasítás feldolgozása az SQL Server Transact-SQL utasítások végrehajtásának legalapvetőbb módja. A csak helyi alaptáblákra hivatkozó egyetlen SELECT utasítás feldolgozásának lépései (nézetek és távoli táblák nélkül) szemléltetik az alapfolyamatot.
Logikai operátorok elsőbbsége
Ha egy utasításban egynél több logikai operátort használ, NOT a rendszer először kiértékeli, majd ANDvégül OR. Az aritmetikai és bitenkénti operátorokat a logikai operátorok előtt kezeli a rendszer. További információ: Operátorok elsőbbsége.
Az alábbi példában a színfeltétel a 21-ik termékmodellre vonatkozik, és nem a 20- s termékmodellre, mert AND elsőbbsége van a 20. termékmodelllel szemben OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
A lekérdezés jelentésének megváltoztatásához zárójelek hozzáadásával kényszerítheti az OR első kiértékelését. Az alábbi lekérdezés csak a 20-21- és a 21-ik modellben lévő termékeket keresi meg, amelyek pirosak.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Ha zárójeleket használ, még akkor is, ha nem szükséges, javíthatja a lekérdezések olvashatóságát, és csökkentheti az operátorok elsőbbsége miatti apró hibák esélyét. A zárójelek használata nem okoz jelentős teljesítménybeli hátrányt. Az alábbi példa olvashatóbb, mint az eredeti példa, bár szintaktikailag megegyeznek.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
SELECT utasítások optimalizálása
Az SELECT utasítás nem eljárási jellegű; nem tartalmazza azokat a lépéseket, amelyeket az adatbázis-kiszolgálónak a kért adatok lekéréséhez kell használnia. Ez azt jelenti, hogy az adatbázis-kiszolgálónak elemeznie kell az utasítást a kért adatok kinyerési leghatékonyabb módjának meghatározásához. Ezt úgy nevezzük, hogy optimalizálja az utasítást SELECT . Ezt az összetevőt lekérdezésoptimalizálónak nevezzük. A Lekérdezésoptimalizáló bemenete a lekérdezésből, az adatbázissémából (tábla- és indexdefiníciókból) és az adatbázis-statisztikákból áll. A Lekérdezésoptimalizáló kimenete lekérdezés-végrehajtási terv, más néven lekérdezésterv vagy végrehajtási terv. A végrehajtási terv tartalmát a cikk későbbi részében részletesebben ismertetjük.
A Lekérdezésoptimalizáló bemeneteit és kimeneteit egyetlen SELECT utasítás optimalizálása során az alábbi diagram szemlélteti:
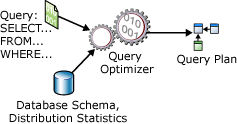
Egy SELECT utasítás csak a következőket határozza meg:
- Az eredményhalmaz formátuma. Ez többnyire a kiválasztási listában van megadva. Más záradékok, például
ORDER BYGROUP BYaz eredményhalmaz végső formájára is hatással vannak. - A forrásadatokat tartalmazó táblák. A
FROMzáradékban van megadva. - Hogyan kapcsolódnak a táblák logikailag az utasítás céljaihoz
SELECT. Ezt az illesztési specifikációk határozzák meg, amelyek megjelenhetnek aWHEREzáradékban, vagy egyONzáradékban, amely követi aFROMzáradékot. - Azok a feltételek, amelyeknek a forrástáblák sorainak meg kell felelniük ahhoz, hogy megfeleljenek az
SELECTutasításnak. Ezek vannak megadva aWHEREésHAVINGzáradékokban.
A lekérdezés-végrehajtási terv a következők definíciója:
A forrástáblák elérésének sorrendje.
Általában számos sorozat létezik, amelyekben az adatbázis-kiszolgáló hozzáférhet az alaptáblákhoz az eredményhalmaz létrehozásához. Ha például azSELECTutasítás három táblára hivatkozik, az adatbázis-kiszolgáló először hozzáférhetTableA, az adatokbólTableAkinyerheti az egyező sorokatTableB, majd az adatokbólTableBkinyerheti az adatokatTableC. A többi sorozat, amelyben az adatbázis-kiszolgáló hozzáférhet a táblákhoz, a következők:
TableC,TableB,TableAvagy
TableB,TableA,TableCvagy
TableB,TableC,TableAvagy
\Az egyes táblák adatainak kinyerésére használt módszerek.
Általában különböző módszerek vannak az egyes táblák adatainak elérésére. Ha csak néhány sorra van szükség meghatározott kulcsértékekkel, az adatbázis-kiszolgáló használhat indexet. Ha a tábla összes sorára szükség van, az adatbázis-kiszolgáló figyelmen kívül hagyhatja az indexeket, és elvégezhet egy táblavizsgálatot. Ha egy tábla összes sorára szükség van, de van egy olyan index, amelynek kulcsoszlopai egyORDER BYtáblában vannak, akkor a táblázatvizsgálat helyett indexvizsgálat végrehajtása az eredményhalmaz egy külön sorát mentheti. Ha egy táblázat nagyon kicsi, akkor a táblázatvizsgálatok lehetnek a leghatékonyabb módszer szinte minden hozzáféréshez a táblához.A számítások kiszámításához használt módszerek, valamint az egyes táblák adatainak szűrése, összesítése és rendezése.
Mivel az adatok táblákból érhetők el, különböző módszerekkel végezhet számításokat az adatokon, például skaláris értékek kiszámításán, valamint a lekérdezés szövegében meghatározott adatok összesítésére és rendezésére, példáulGROUP BYvagyORDER BYzáradék használatakor, valamint az adatok szűrésére, példáulWHEREvagyHAVINGzáradék használatakor.
Egy végrehajtási terv potenciálisan sok lehetséges tervből való kiválasztásának folyamatát optimalizálásnak nevezzük. A Lekérdezésoptimalizáló az adatbázismotor egyik legfontosabb összetevője. Bár a Lekérdezésoptimalizáló némi pótlólagos terhelést jelent a lekérdezés elemzése és egy terv kiválasztása során, ezt a terhelést általában többszörösen megtakarítja a rendszer, amikor a Lekérdezésoptimalizáló egy hatékony végrehajtási tervet választ ki. Két építőipari vállalat például azonos tervrajzokat kaphat egy házhoz. Ha az egyik vállalat az elején tölt néhány napot, hogy megtervezze, hogyan építi fel a házat, és a másik vállalat tervezés nélkül kezdi meg az építkezést, akkor valószínűleg az a vállalat fejeződik be, amely időt vesz igénybe a projekt megtervezéséhez.
Az SQL Server Query Optimizer egy költségalapú optimalizáló. Minden lehetséges végrehajtási tervhez kapcsolódó költségek vannak a felhasznált számítási erőforrások mennyisége tekintetében. A Lekérdezésoptimalizálónak elemeznie kell a lehetséges terveket, és ki kell választania azt, amelyik a legalacsonyabb becsült költséggel jár. Néhány összetett SELECT utasítás több ezer lehetséges végrehajtási tervből áll. Ezekben az esetekben a Lekérdezésoptimalizáló nem elemzi az összes lehetséges kombinációt. Ehelyett összetett algoritmusokkal keres olyan végrehajtási tervet, amelynek költsége ésszerűen megközelíti a lehető legkisebb költséget.
Az SQL Server Query Optimizer nem csak a legalacsonyabb erőforrásköltséggel rendelkező végrehajtási tervet választja; kiválasztja azt a tervet, amely ésszerű erőforrásköltséggel adja vissza az eredményeket a felhasználónak, és a leggyorsabb eredményt adja vissza. Egy lekérdezés párhuzamos feldolgozása például általában több erőforrást használ, mint a soros feldolgozás, de gyorsabban befejezi a lekérdezést. Az SQL Server Lekérdezésoptimalizáló egy párhuzamos végrehajtási tervet használ az eredmények visszaadásához, ha a kiszolgáló terhelése nem lesz hátrányosan érintve.
Az SQL Server Lekérdezésoptimalizáló akkor támaszkodik a terjesztési statisztikákra, amikor egy tábla vagy index információinak kinyerésére szolgáló különböző módszerek erőforrásköltségeit becsüli meg. A terjesztési statisztikák oszlopokra és indexekre vannak tárolva, és az alapul szolgáló adatok1 sűrűségére vonatkozó információkat tárolnak. Ez egy adott index vagy oszlop értékeinek szelektivitását jelzi. Az autókat ábrázoló táblázatban például sok autó ugyanazzal a gyártóval rendelkezik, de mindegyik autó egyedi járműazonosítóval (VIN) rendelkezik. A VIN indexe szelektívebb, mint a gyártó indexe, mivel a VIN sűrűsége alacsonyabb, mint a gyártóé. Ha az indexstatisztikák nem aktuálisak, előfordulhat, hogy a Lekérdezésoptimalizáló nem a legjobb választás a tábla aktuális állapotához. A sűrűségekről további információt a Statisztikák című témakörben talál.
1 A sűrűség az adatokban meglévő egyedi értékek eloszlását, vagy egy adott oszlop duplikált értékeinek átlagos számát határozza meg. A sűrűség csökkenésével az érték szelektivitása nő.
Az SQL Server Lekérdezésoptimalizáló azért fontos, mert lehetővé teszi, hogy az adatbázis-kiszolgáló dinamikusan alkalmazkodjon az adatbázis változó feltételeihez anélkül, hogy programozótól vagy adatbázis-rendszergazdától kellene bemenetet igényelnie. Ez lehetővé teszi, hogy a programozók a lekérdezés végeredményének leírására összpontosítsanak. Megbízhatnak abban, hogy az SQL Server Query Optimizer hatékony végrehajtási tervet fog készíteni az adatbázis állapotához minden alkalommal, amikor az utasítás fut.
Megjegyzés:
Az SQL Server Management Studio háromféleképpen jelenítheti meg a végrehajtási terveket:
- A Lekérdezésoptimalizáló által készített becsült végrehajtási terv, amely az összeállított terv.
- A tényleges végrehajtási terv, amely megegyezik a lefordított terv és annak végrehajtási környezetével. Ide tartoznak a végrehajtás befejeződése után elérhető futásidejű információk, például a végrehajtási figyelmeztetések, vagy az adatbázismotor újabb verzióiban a végrehajtás során felhasznált eltelt és cpu-idő.
- Az élő lekérdezési statisztikák, amelyek megegyeznek a lefordított tervvel és annak végrehajtási környezetével. Ide tartoznak a futásidejű adatok a végrehajtás során, és másodpercenként frissülnek. A futtatókörnyezet adatai közé tartozik például az operátorokon áthaladó sorok tényleges száma.
SELECT utasítás feldolgozása
Az SQL Server által egyetlen SELECT utasítás feldolgozásához használt alapvető lépések a következők:
- Az elemző megvizsgálja az
SELECTutasítást, és logikai egységekre bontja, például kulcsszavakra, kifejezésekre, operátorokra és azonosítókra. - A lekérdezési fa ( más néven szekvenciafa) a forrásadatok eredményhalmaz által megkövetelt formátummá alakításához szükséges logikai lépéseket írja le.
- A Lekérdezésoptimalizáló a forrástáblák elérésének különböző módjait elemzi. Ezután kiválasztja azokat a lépések sorozatát, amelyek az eredményeket a leggyorsabban visszaadják, miközben kevesebb erőforrást használnak. A lekérdezési fa frissül, hogy rögzítse ezt a pontos lépéssort. A lekérdezésfa végleges, optimalizált verzióját végrehajtási tervnek nevezzük.
- A relációs motor megkezdi a végrehajtási terv végrehajtását. Az alaptáblákból adatokat igénylő lépések feldolgozásakor a relációs motor kéri, hogy a tárolómotor adja át az adatokat a relációs motortól kért sorhalmazokból.
- A relációs motor feldolgozza a tárolómotorból visszaadott adatokat az eredményhalmazhoz meghatározott formátumba, és visszaadja az eredményhalmazt az ügyfélnek.
Konstans hajtogatás és kifejezés kiértékelése
Az SQL Server néhány állandó kifejezést korán kiértékel a lekérdezési teljesítmény növelése érdekében. A lekérdezésoptimalizáló által használt optimalizálási technika célja a kifejezések fordítási időben történő egyszerűsítése, nem pedig futásidőben. Ez magában foglalja az állandó kifejezések kiértékelését a lekérdezés-fordítás során, hogy az eredményül kapott végrehajtási terv hatékonyabb legyen. Ezt nevezik állandó hajtogatásnak. Az állandó egy Transact-SQL konstans, például 3, 'ABC', '2005-12-31', 1.0e3vagy 0x12345678. Vegyük például ezt a lekérdezést:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 30 * 12, '2020-01-01');
Itt a 30 * 12 állandó kifejezés. Az SQL Server a fordítás során kiértékelheti ezt, és belsőleg átírhatja a lekérdezést a következő módon:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 360, '2020-01-01');
Összecsukható kifejezések
Az SQL Server állandó összecsukást használ a következő típusú kifejezésekkel:
- Olyan aritmetikai kifejezések, például
1 + 1és5 / 3 * 2, amelyek csak állandókat tartalmaznak. - Olyan logikai kifejezések, például
1 = 1és1 > 2 AND 3 > 4, amelyek csak állandókat tartalmaznak. - Az SQL Server által összecsukhatónak ítélt beépített függvények, beleértve
CASTésCONVERT. Egy belső függvény általában összevonható, ha csak a bemenetek függvénye, és nem más környezetfüggő információé, mint például a SET-beállítások, a nyelvi beállítások, az adatbázis-opciók és a titkosítási kulcsok. A nemdeterminisztikus függvények nem hajthatók össze. A determinisztikus beépített függvények összecsukhatók, néhány kivételtől eltekintve. - A CLR felhasználó által definiált típusainak és a determinisztikus skaláris értékkel rendelkező, felhasználó által definiált CLR-függvények determinisztikus módszerei (az SQL Server 2012-től kezdve (11.x)). További információkért lásd: CLR User-Defined függvények és metódusok konstans összevonása.
Megjegyzés:
A nagyméretű objektumtípusok kivételt képeznek. Ha az összecsukási folyamat kimeneti típusa nagy objektumtípus (szöveg, ntext, kép, nvarchar(max), varchar(max), varbinary(max) vagy XML), akkor az SQL Server nem hajtja össze a kifejezést.
Nem bontható kifejezések
Az összes többi kifejezéstípus nem összehajtható. A következő típusú kifejezések nem összevonhatók:
- Nem konkonzisztens kifejezések, például egy olyan kifejezés, amelynek eredménye egy oszlop értékétől függ.
- Olyan kifejezések, amelyek eredményei helyi változótól vagy paramétertől függenek, például @x.
- Nemdeterminista függvények.
- Felhasználó által definiált Transact-SQL függvények1.
- Olyan kifejezések, amelyek eredményei a nyelvi beállításoktól függnek.
- Azok a kifejezések, amelyek eredményei a SET beállításoktól függnek.
- Olyan kifejezések, amelyek eredményei a kiszolgáló konfigurációs beállításaitól függnek.
1 Az SQL Server 2012 (11.x) előtt a determinisztikus skaláris értéket visszaadó, felhasználó által definiált CLR-függvények és a CLR felhasználó által definiált típusok metódusai nem voltak összecsukhatóak.
Példák összecsukható és nem cserélhető állandó kifejezésekre
Fontolja meg a következő lekérdezést:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Ha az PARAMETERIZATION adatbázis-beállítás nincs beállítva ehhez a lekérdezéshez FORCED , akkor a lekérdezés fordítása előtt a rendszer kiértékeli és lecseréli a kifejezést 117.00 + 1000.00 az eredményre 1117.00. Az állandó összecsukás előnyei közé tartoznak a következők:
- A kifejezést nem kell többször kiértékelni futásidőben.
- A lekérdezésoptimalizáló a kifejezés kiértékelése utáni értékét használja a lekérdezés
TotalDue > 117.00 + 1000.00eredményhalmazának méretének becsléséhez.
Másrészt, ha dbo.f egy skaláris felhasználó által definiált függvény, a kifejezés dbo.f(100) nem lesz összehajtva, mert az SQL Server nem hajtja össze a felhasználó által definiált függvényeket tartalmazó kifejezéseket, még akkor sem, ha determinisztikusak. A paraméterezésről a cikk későbbi, Kényszerített paraméterezés című szakaszában olvashat bővebben.
Kifejezés kiértékelése
Ezenkívül egyes kifejezések, amelyek nem állandó kihajtásúak, de amelyeket a fordítási időben ismert argumentumok befolyásolnak—függetlenül attól, hogy paraméterek vagy állandók—, az optimalizáló részét képező eredményhalmaz-méret (kardinalitás) becslő segítségével kerülnek kiértékelésre az optimalizálási folyamat során.
Pontosabban a következő beépített függvények és speciális operátorok kiértékelése fordításkor történik, ha az összes bemenet ismert: UPPER, , LOWER, RTRIM, DATEPART( YY only ), GETDATE, CASTés CONVERT. A következő operátorok fordításkor is kiértékelésre kerülnek, ha az összes bemenetük ismert:
- Számtani operátorok: +, -, *, /, unary -
- Logikai operátorok:
AND, ,ORNOT - Összehasonlító operátorok: <, >, <=, >= , <>,
LIKE,IS NULLIS NOT NULL
A lekérdezésoptimalizáló nem értékel ki más függvényeket vagy operátorokat a számosság becslése során.
Példák a fordítási idő alatti kifejezések kiértékelésére
Fontolja meg ezt a tárolt eljárást:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Az eljárásban lévő SELECT utasítás optimalizálása során a Lekérdezésoptimalizáló megpróbálja kiértékelni a feltételhez OrderDate > @d+1beállított eredménykészlet várt számosságát. A kifejezést @d+1 nem hajtják össze konstansként, mert a @d egy paraméter. Az optimalizálási időben azonban a paraméter értéke ismert. Ez lehetővé teszi, hogy a Lekérdezésoptimalizáló pontosan megbecsülje az eredményhalmaz méretét, ami segít kiválasztani a megfelelő lekérdezési tervet.
Most vegyük az előzőhöz hasonló példát, azzal a kivételével, hogy egy helyi változó @d2 lecseréli @d+1 a lekérdezést, és a kifejezés kiértékelése SET utasításban történik a lekérdezés helyett.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Ha az SELECT utasítás MyProc2 az SQL Serverben van optimalizálva, annak értéke @d2 nem ismert. Ezért a Lekérdezésoptimalizáló a OrderDate > @d2 szelektivitásának alapértelmezett becslését használja (ebben az esetben 30 százalék).
Más nyilatkozatok feldolgozása
Az SELECT utasítás feldolgozásához leírt alapvető lépések vonatkoznak más Transact-SQL utasításokra, mint például INSERT, UPDATE, és DELETE.
UPDATE és DELETE mindkét utasításnak meg kell céloznia a módosítani vagy törölni kívánt sorokat. A sorok azonosításának folyamata ugyanaz a folyamat, amely az utasítás eredményhalmazához SELECT hozzájáruló forrássorok azonosítására szolgál. Az UPDATE és INSERT az utasítások beágyazott utasításokat is tartalmazhatnak SELECT , amelyek biztosítják a frissíteni vagy beszúrni kívánt adatértékeket.
Még a Data Definition Language (DDL) utasítások is, mint például CREATE PROCEDURE vagy ALTER TABLE, végső soron relációs műveletekké alakulnak a rendszerkatalógus tábláin, és néha az adattáblákon (például ALTER TABLE ADD COLUMN).
Munkatáblák
Előfordulhat, hogy a relációs motornak egy Transact-SQL utasításban megadott logikai művelet végrehajtásához létre kell készítenie egy munkatáblát. A munkatáblák belső táblák, amelyek köztes eredmények tárolására szolgálnak. A munkatáblák bizonyos GROUP BY, ORDER BYvagy UNION lekérdezésekhez jönnek létre. Ha például egy ORDER BY záradék olyan oszlopokra hivatkozik, amelyeket nem fednek le indexek, előfordulhat, hogy a relációs motornak létre kell hoznia egy munkatáblát, amely az eredményhalmazt a kért sorrendbe rendezi. A munkatáblákat olyan várólistákként is használják, amelyek ideiglenesen egy lekérdezésterv egy részének végrehajtásának eredményét tartják. A munkatáblák beépítettek tempdb , és automatikusan el lesznek dobva, ha már nincs rájuk szükség.
Felbontás megtekintése
Az SQL Server lekérdezésfeldolgozója eltérően kezeli az indexelt és a nem indexelt nézeteket:
- Az indexelt nézet sorai ugyanabban a formátumban vannak tárolva az adatbázisban, mint egy tábla. Ha a Lekérdezésoptimalizáló úgy dönt, hogy indexelt nézetet használ egy lekérdezéstervben, az indexelt nézet ugyanúgy lesz kezelve, mint egy alaptábla.
- A rendszer csak a nem indexelt nézet definícióját tárolja, a nézet sorait nem. A Lekérdezésoptimalizáló beépíti a nézetdefiníció logikáját a nem indexelt nézetre hivatkozó Transact-SQL utasításhoz készült végrehajtási tervbe.
Az SQL Server Query Optimizer által az indexelt nézet használatának időpontjának meghatározására használt logika hasonló ahhoz a logikához, amely azt határozza meg, hogy mikor érdemes indexet használni egy táblán. Ha az indexelt nézetben lévő adatok a Transact-SQL utasítás egészét vagy egy részét lefedik, és a Lekérdezésoptimalizáló megállapítja, hogy a nézetben lévő index az alacsony költségű elérési út, a Lekérdezésoptimalizáló az indexet választja, függetlenül attól, hogy a nézet név alapján szerepel-e a lekérdezésben.
Ha egy Transact-SQL utasítás nem indexelt nézetre hivatkozik, az elemző és a Lekérdezésoptimalizáló elemzi a Transact-SQL utasítás és a nézet forrását, majd feloldja őket egyetlen végrehajtási tervben. Nincs külön terv a Transact-SQL nyilatkozathoz és a nézethez, csak egy közös terv van számukra.
Vegyük például a következő nézetet:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Ezen nézet alapján mindkét Transact-SQL utasítás ugyanazokat a műveleteket hajtja végre az alaptáblákon, és ugyanazokat az eredményeket eredményezi:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
Az SQL Server Management Studio Showplan funkciója azt mutatja, hogy a relációs motor mindkét utasításhoz ugyanazt a végrehajtási tervet készíti SELECT .
Tippek használata nézetekkel
A lekérdezésben nézetekre helyezett javaslatok ütközhetnek más, a nézet feltárásakor felfedezett javaslatokkal az alaptáblákhoz való hozzáféréskor. Ha ez történik, a lekérdezés hibát ad vissza. Vegyük például az alábbi nézetet, amely a definíciójában egy táblázatos tippet tartalmaz:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Tegyük fel, hogy a következő lekérdezést adja meg:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
A lekérdezés sikertelen, mert a nézet SERIALIZABLE-re alkalmazott utasítás Person.AddrState mindkét táblára Person.Address és Person.StateProvince is propagálásra kerül a nézet kibontásakor. A nézet kibontásával azonban a NOLOCK tipp is megjelenik a Person.Address-n. Mivel a SERIALIZABLE és a NOLOCK utasítások ütköznek, helytelen az eredményül kapott lekérdezés.
A PAGLOCK, NOLOCK, ROWLOCK, TABLOCK, vagy TABLOCKX táblamutatók ütköznek egymással, ahogy a HOLDLOCK, NOLOCK, , READCOMMITTED, REPEATABLEREADSERIALIZABLE táblamutatók is.
Az utalások beágyazott nézetek szintjein keresztül képesek propagálódni. Tegyük fel például, hogy egy lekérdezés egy HOLDLOCK nézetre alkalmazza a v1 utasítást. Ha v1 ki van bontva, azt tapasztaljuk, hogy a nézet v2 a definíció része.
v2 definíciója tartalmaz egy NOLOCK utalást az egyik alaptáblájára. Ez a tábla azonban a HOLDLOCK tippet örökli a v1 nézetre vonatkozó lekérdezésből. Mivel a NOLOCK és HOLDLOCK útmutatások ütköznek, a lekérdezés meghiúsul.
Ha egy FORCE ORDER nézetet tartalmazó lekérdezésben a tippet használják, a nézetben lévő táblák illesztésének sorrendjét a nézet a rendezett szerkezetben elfoglalt helye határozza meg. A következő lekérdezés például három táblából és egy nézetből választ:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
És View1 az alábbi módon van definiálva:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
A lekérdezési tervben az illesztés sorrendje: Table1, Table2, TableA, TableB, Table3.
Nézetek indexeinek megoldása
Mint minden indexnél, az SQL Server is csak akkor választ indexelt nézetet a lekérdezéstervében, ha a Lekérdezésoptimalizáló úgy ítéli meg, hogy ez előnyös.
Az indexelt nézetek az SQL Server bármely kiadásában létrehozhatóak. Az SQL Server néhány régebbi verziójának egyes kiadásaiban a Lekérdezésoptimalizáló automatikusan figyelembe veszi az indexelt nézetet. Az SQL Server néhány régebbi verziójának egyes kiadásaiban indexelt nézet használatához a NOEXPAND táblamutatót kell használni. Az indexelt nézet lekérdezésoptimalizáló általi automatikus használata csak az SQL Server adott kiadásaiban támogatott. Az Azure SQL Database és a felügyelt Azure SQL-példány az indexelt nézetek automatikus használatát is támogatja a NOEXPAND tipp megadása nélkül.
Az SQL Server Lekérdezésoptimalizáló indexelt nézetet használ a következő feltételek teljesülésekor:
- Ezek a munkamenet-beállítások a következőkre
ONvannak beállítva:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- A
NUMERIC_ROUNDABORTmunkamenet opciója KI van állítva. - A Lekérdezésoptimalizáló egyezést talál a nézetindex oszlopai és a lekérdezés elemei között, például a következőket:
- Keresési feltétel predikátumai a WHERE záradékban
- Csatlakozási műveletek
- Összesítő függvények
-
GROUP BYZáradékok - Táblahivatkozások
- Az index használatának becsült költsége a lekérdezésoptimalizáló által figyelembe vett hozzáférési mechanizmusok legalacsonyabb költségével rendelkezik.
- A lekérdezésben hivatkozott minden táblának (akár közvetlenül, akár egy nézet kiterjesztésével az alapul szolgáló táblák eléréséhez) az indexelt nézetben lévő táblahivatkozásnak megfelelő táblával ugyanazt az utasításhalmazt kell alkalmazni a lekérdezésben.
Megjegyzés:
A READCOMMITTED tippek és READCOMMITTEDLOCK a tippek ebben a kontextusban mindig különböző tippeknek számítanak, függetlenül az aktuális tranzakcióelkülönítési szinttől.
A beállításokra és a SET táblamutatókra vonatkozó követelményeken kívül ezek ugyanazok a szabályok, amelyeket a Lekérdezésoptimalizáló használ annak meghatározására, hogy egy táblaindex lefedi-e a lekérdezést. Az indexelt nézet használatához semmi mást nem kell megadni a lekérdezésben.
A lekérdezésnek nem kell explicit módon hivatkoznia egy indexelt nézetre a FROM Lekérdezésoptimalizáló záradékában az indexelt nézet használatához. Ha a lekérdezés az indexelt nézetben is megtalálható alaptáblák oszlopaira mutató hivatkozásokat tartalmaz, és a Lekérdezésoptimalizáló úgy becsüli meg, hogy az indexelt nézetben a legalacsonyabb költségelérési mechanizmus érhető el, a Lekérdezésoptimalizáló az indexelt nézetet választja, hasonlóan ahhoz, ahogyan az alaptábla-indexeket választja, ha nem hivatkoznak rájuk közvetlenül egy lekérdezésben. A Lekérdezésoptimalizáló akkor választhatja a nézetet, ha az olyan oszlopokat tartalmaz, amelyekre a lekérdezés nem hivatkozik, feltéve, hogy a nézet a lekérdezésben megadott oszlopok egy vagy több oszlopának lefedésére a legkisebb költséggel járó lehetőséget kínálja.
A Lekérdezésoptimalizáló a záradékban FROM hivatkozott indexelt nézetet standard nézetként kezeli. A Lekérdezésoptimalizáló az optimalizálási folyamat elején kibontja a nézet definícióját a lekérdezésbe. Ezután végbemegy az indexelt nézetegyezés. Az indexelt nézet használható a Lekérdezésoptimalizáló által kiválasztott végső végrehajtási tervben, vagy ehelyett a terv a nézet által hivatkozott alaptáblák elérésével a szükséges adatokat is hasznosíthatja a nézetből. A Lekérdezésoptimalizáló a legalacsonyabb költségű alternatívát választja.
Javaslatok használata indexelt nézetekhez
A lekérdezési tipp használatával EXPAND VIEWS megakadályozhatja, hogy a nézetindexek egy lekérdezéshez legyenek használva, vagy a NOEXPAND táblamutatóval kényszerítheti az index használatát egy, a FROM lekérdezés záradékában megadott indexelt nézethez. Lehetővé kell azonban tenni, hogy a Lekérdezésoptimalizáló dinamikusan határozza meg az egyes lekérdezésekhez használandó legjobb hozzáférési módszereket. Korlátozza a EXPAND és NOEXPAND használatát azokra az esetekre, amikor a tesztelés kimutatta, hogy jelentősen javítják a teljesítményt.
A
EXPAND VIEWSbeállítás azt határozza meg, hogy a Lekérdezésoptimalizáló ne használjon nézetindexeket a teljes lekérdezéshez.Ha
NOEXPANDmeg van adva egy nézethez, a Lekérdezésoptimalizáló figyelembe veszi a nézeten definiált indexek használatát.NOEXPANDa választhatóINDEX()záradékkal megadva a Lekérdezésoptimalizálót a megadott indexek használatára kényszeríti.NOEXPANDcsak indexelt nézethez adható meg, és nem adható meg nem indexelt nézethez. Az indexelt nézet lekérdezésoptimalizáló általi automatikus használata csak az SQL Server adott kiadásaiban támogatott. Az Azure SQL Database és a felügyelt Azure SQL-példány az indexelt nézetek automatikus használatát is támogatja aNOEXPANDtipp megadása nélkül.
Ha egy nézetet tartalmazó lekérdezésben sem NOEXPAND, sem EXPAND VIEWS nincs megadva, a nézet kibontásra kerül a mögöttes táblák eléréséhez. Ha a nézetet alkotó lekérdezés tartalmaz táblázatos tippeket, a rendszer propagálja ezeket a tippeket az alapul szolgáló táblákra. (Ezt a folyamatot részletesebben a Felbontás megtekintése című cikkben ismertetheti.) Mindaddig, amíg a nézet alapjául szolgáló táblákon található tippek egymással azonosak, a lekérdezés megfeleltethető egy indexelt nézetnek. A legtöbb esetben ezek az utalások összhangban vannak egymással, mivel közvetlenül a nézetből öröklődnek. Ha azonban a lekérdezés nézetek helyett táblákra hivatkozik, és a közvetlenül ezeken a táblákon alkalmazott tippek nem azonosak, akkor az ilyen lekérdezések nem alkalmasak az indexelt nézetekkel való egyeztetésre. Ha a INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCK, vagy XLOCK tippek a nézetbővítés után a lekérdezésben hivatkozott táblákra vonatkoznak, a lekérdezés nem jogosult indexelt nézetek illesztésére.
Ha egy INDEX (index_val[ ,...n] ) alakú táblahivatkozás egy lekérdezés nézetére utal, és nem adja meg a NOEXPAND utasítást, a rendszer figyelmen kívül hagyja az indexrelációt. Egy adott index használatának megadásához használja a következőt NOEXPAND: .
Ha a Lekérdezésoptimalizáló megfelel egy lekérdezés indexelt nézetének, a lekérdezés tábláiban vagy nézeteiben megadott tippeket a rendszer közvetlenül az indexelt nézetre alkalmazza. Ha a Lekérdezésoptimalizáló úgy dönt, hogy nem használ indexelt nézetet, a rendszer minden tippet közvetlenül a nézetben hivatkozott táblákra propagálja. További információ: Felbontás megtekintése. Ez a propagálás nem vonatkozik az illesztési tippekre. A rendszer csak a lekérdezés eredeti helyén alkalmazza őket. A lekérdezésoptimalizáló nem veszi figyelembe az illesztési tippeket, amikor a lekérdezéseket indexelt nézetekkel egyezteti. Ha egy lekérdezésterv olyan indexelt nézetet használ, amely megfelel egy illesztésmutatót tartalmazó lekérdezés egy részének, akkor a rendszer nem használja az illesztésmutatót a tervben.
A tippek nem használhatók az indexelt nézetek definícióiban. A 80-ás és újabb kompatibilitási módban az SQL Server figyelmen kívül hagyja az indexelt nézetdefiníciókon belüli tippeket a karbantartásukkor vagy az indexelt nézeteket használó lekérdezések végrehajtásakor. Bár az indexelt nézetdefiníciókban használt tippek nem okoznak szintaxishibát 80 kompatibilitási módban, a rendszer figyelmen kívül hagyja őket.
További információkért lásd: Tábla-javallatok (Transact-SQL).
Elosztott particionált nézetek feloldása
Az SQL Server lekérdezésfeldolgozója optimalizálja az elosztott particionált nézetek teljesítményét. Az elosztott particionált nézet teljesítményének legfontosabb szempontja a tagkiszolgálók között továbbított adatok mennyiségének minimalizálása.
Az SQL Server intelligens, dinamikus terveket hoz létre, amelyek hatékonyan használják az elosztott lekérdezéseket a távoli tagtáblák adatainak eléréséhez:
- A lekérdezésfeldolgozó először az OLE DB használatával kéri le az ellenőrzőkényszer-definíciókat az egyes tagtáblákból. Ez lehetővé teszi, hogy a lekérdezésfeldolgozó leképozza a kulcsértékek eloszlását a tagtáblák között.
- A lekérdezésfeldolgozó egy Transact-SQL utasítási
WHEREzáradékban megadott kulcstartományokat hasonlítja össze a leképezéssel, amely a sorok tagtáblákban való elosztását mutatja. A lekérdezésfeldolgozó ezután létrehoz egy lekérdezés-végrehajtási tervet, amely elosztott lekérdezéseket használ a Transact-SQL utasítás végrehajtásához szükséges távoli sorok lekéréséhez. A végrehajtási terv úgy is épül fel, hogy a távoli tagtáblákhoz való hozzáférés az adatok vagy metaadatok esetében mindaddig késik, amíg az információra nincs szükség.
Vegyük például azt a rendszert, amelyben a Customers rendszer egy táblát particionált a Server1 (CustomerID 1 és 3299999 között), a Server2 (CustomerID 3300000 és 6599999 közötti) és a Server3 (CustomerID 66000000 és 9999999 között).
Fontolja meg a Server1-en végrehajtott lekérdezéshez készült végrehajtási tervet:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
A lekérdezés végrehajtási terve kinyeri a 32000000 és 3299999 kulcsértékekkel rendelkező CustomerID sorokat a helyi tagtáblából, és elosztott lekérdezést ad ki a 3300000 és 3400000 közötti kulcsértékekkel rendelkező sorok lekéréséhez a Server2-ből.
Az SQL Server lekérdezésfeldolgozó dinamikus logikát is létrehozhat Transact-SQL olyan utasítások lekérdezés-végrehajtási terveibe, amelyekben a kulcsértékek nem ismertek, amikor létre kell készíteni a tervet. Vegyük például ezt a tárolt eljárást:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
Az SQL Server nem tudja előre jelezni, hogy a @CustomerIDParameter paraméter milyen kulcsértéket ad meg az eljárás minden végrehajtásakor. Mivel a kulcsértéket nem lehet előrejelezni, a lekérdezésfeldolgozó azt sem tudja megjósolni, hogy melyik tagtáblához kell hozzáférnie. Az eset kezeléséhez az SQL Server létrehoz egy olyan végrehajtási tervet, amely feltételes logikával( más néven dinamikus szűrőkkel) rendelkezik annak szabályozásához, hogy melyik tagtábla érhető el a bemeneti paraméter értéke alapján. Feltételezve, hogy a GetCustomer tárolt eljárás a Server1 kiszolgálón lett végrehajtva, a végrehajtási terv logikája az alábbi módon jeleníthető meg:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
Az SQL Server néha olyan lekérdezésekhez is létrehozza ezeket a dinamikus végrehajtási terveket, amelyek nincsenek paraméterezve. A Lekérdezésoptimalizáló paraméterezni tudja a lekérdezést, hogy a végrehajtási terv újra felhasználható legyen. Ha a Lekérdezésoptimalizáló paraméterez egy particionált nézetre hivatkozó lekérdezést, a Lekérdezésoptimalizáló már nem tudja feltételezni, hogy a szükséges sorok egy megadott alaptáblából származnak. Ezután dinamikus szűrőket kell használnia a végrehajtási tervben.
Tárolt eljárás és eseményindító végrehajtása
Az SQL Server csak a tárolt eljárások és triggerek forrását tárolja. A tárolt eljárás vagy eseményindító első végrehajtásakor a forrás egy végrehajtási tervbe lesz lefordítva. Ha a tárolt eljárást vagy eseményindítót ismét végrehajtja, mielőtt a végrehajtási terv elöregedik a memóriából, a relációs motor észleli a meglévő tervet, és újra felhasználja azt. Ha a terv elavult, egy új terv készül. Ez a folyamat hasonló ahhoz a folyamathoz, amelyet az SQL Server az összes Transact-SQL utasításhoz követ. Az SQL Serverben tárolt eljárások és eseményindítók fő teljesítményelőnyét a dinamikus Transact-SQL kötegekhez képest az biztosítja, hogy a Transact-SQL utasításaik mindig ugyanazok. Ezért a relációs motor könnyen megfelel az összes meglévő végrehajtási tervnek. A tárolt eljárás- és triggercsomagok könnyen újra felhasználhatók.
A tárolt eljárások és eseményindítók végrehajtási tervét a rendszer a tárolt eljárást meghívó vagy az eseményindítót indító köteg végrehajtási tervétől elkülönítve hajtja végre. Ez lehetővé teszi a tárolt eljárás nagyobb újrafelhasználását és a végrehajtási tervek aktiválását.
Végrehajtási terv gyorsítótárazása és újrafelhasználása
Az SQL Server rendelkezik memóriakészletekkel, amelyek a végrehajtási tervek és az adatpufferek tárolására szolgálnak. A végrehajtási tervekhez vagy adatpufferekhez lefoglalt készlet százalékos aránya a rendszer állapotától függően dinamikusan ingadozik. A memóriakészlet végrehajtási tervek tárolására használt részét tervgyorsítótárnak nevezzük.
A csomaggyorsítótár két tárolóval rendelkezik az összes lefordított csomaghoz:
- A tárolt objektumokhoz (tárolt eljárásokhoz, függvényekhez és eseményindítókhoz) kapcsolódó tervekhez használt Objektumtervek gyorsítótára (OBJCP).
- Az automatikusan parametrizált, dinamikus vagy előkészített lekérdezésekhez használt tervtároló SQL Plans cache (SQLCP).
Az alábbi lekérdezés a két gyorsítótár-tároló memóriahasználatával kapcsolatos információkat tartalmaz:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Megjegyzés:
A tervgyorsítótár két további tárolóval rendelkezik, amelyeket nem használnak a tervek tárolására.
- A terv összeállítása során használt adatstruktúrákhoz használt kötött fák gyorsítótára (PHDR) nézetekkel, korlátozásokkal és alapértelmezett értékekkel. Ezeket a szerkezeteket kötött fáknak vagy Algebrizer-fáknak nevezzük.
- Az kiterjesztett tárolt eljárások gyorsítótára (XPROC) az előre definiált,
sp_executeSqlvagyxp_cmdshellformájú rendszerműveletekhez van hozzárendelve, amelyeket DLL használatával definiálnak, nem pedig Transact-SQL utasításokkal. A gyorsítótárazott struktúra csak a függvény nevét és a DLL-nevet tartalmazza, amelyben az eljárás implementálva van.
Az SQL Server végrehajtási tervei a következő fő összetevőkkel rendelkeznek:
Lefordított terv (vagy lekérdezési terv)
A fordítási folyamat által létrehozott lekérdezési terv többnyire egy újra belépő, írásvédett adatstruktúra, amelyet tetszőleges számú felhasználó használ. A következő információk tárolására szolgál:A logikai operátorok által leírt műveletet megvalósító fizikai operátorok.
Az operátorok sorrendje, amely meghatározza az adatok elérésének, szűrésének és összesítésének sorrendjét.
Az operátorok által feldolgozott becsült sorok száma.
Megjegyzés:
Az adatbázismotor újabb verzióiban a számosságbecsléshez használt statisztikai objektumokkal kapcsolatos információk is tárolódnak.
Milyen támogatási objektumokat kell létrehozni, például munkatáblákat vagy munkafájlokat a fájlban
tempdb. A lekérdezési csomag nem tárol felhasználói környezetet vagy futtatókörnyezetet. A lekérdezési tervnek soha nem több példánya van a memóriában: egy példány az összes sorozatvégrehajtáshoz, a másik pedig az összes párhuzamos végrehajtáshoz. A párhuzamos másolat az összes párhuzamos végrehajtást lefedi, függetlenül a párhuzamosság fokától.
Végrehajtási környezet
A lekérdezést jelenleg végrehajtó összes felhasználó rendelkezik egy olyan adatstruktúrával, amely a végrehajtásukra jellemző adatokat tartalmazza, például paraméterértékeket. Ezt az adatstruktúrát végrehajtási környezetnek nevezzük. A végrehajtási környezet adatstruktúrái újra felhasználhatók, de a tartalmaik nem. Ha egy másik felhasználó ugyanazt a lekérdezést hajtja végre, az adatstruktúrák újrainicializálódnak az új felhasználó környezetével.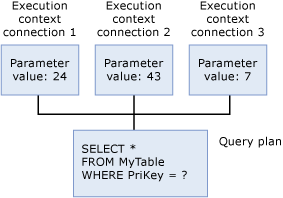
Amikor bármely Transact-SQL utasítást végrehajt az SQL Serveren, az adatbázismotor először a tervgyorsítótáron keresztül ellenőrzi, hogy létezik-e már végrehajtási terv ugyanahhoz a Transact-SQL utasításhoz. A Transact-SQL utasítás akkor minősül létezőnek, ha szó szerint megegyezik egy korábban végrehajtott Transact-SQL utasítással egy gyorsítótárazott tervvel, karakterenként karakterenként. Az SQL Server újra felhasználja a talált meglévő terveket, így a Transact-SQL utasítás újrafordításának többletterhelését takarítja meg. Ha nincs végrehajtási terv, az SQL Server létrehoz egy új végrehajtási tervet a lekérdezéshez.
Megjegyzés:
Néhány Transact-SQL utasítás végrehajtási tervei nem kerülnek tartósan a terv gyorsítótárba, például a sortáron futó tömeges műveleti utasítások vagy a 8 KB-nál nagyobb méretű szövegkonstansokat tartalmazó utasítások. Ezek a tervek csak a lekérdezés végrehajtása közben léteznek.
Az SQL Server egy hatékony algoritmussal rendelkezik, amely megkeresi az adott Transact-SQL utasításhoz tartozó végrehajtási terveket. A legtöbb rendszerben a vizsgálat során használt minimális erőforrások kisebbek, mint azok az erőforrások, amelyek megtakaríthatók azáltal, hogy a meglévő terveket újra felhasználják, és nem minden egyes Transact-SQL utasítást újra összeállítanak.
Az új Transact-SQL utasításoknak a tervgyorsítótárban meglévő, nem használt végrehajtási tervekhez való egyeztetéséhez az összes objektumhivatkozás teljes minősítése szükséges. Tegyük fel például, hogy Person az alábbi SELECT utasításokat végrehajtó felhasználó alapértelmezett sémája. Bár ebben a példában nincs szükség arra, hogy a Person tábla teljes mértékben végrehajtható legyen, ez azt jelenti, hogy a második utasítás nem egyezik meg egy meglévő tervvel, de a harmadik megfeleltetve van:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Az alábbi SET-beállítások egy adott végrehajtáshoz való módosítása hatással lesz a tervek újrafelhasználásának képességére, mivel az adatbázismotor folyamatosan hajtja végre az összecsukást , és ezek a beállítások befolyásolják az ilyen kifejezések eredményeit:
ANSI_NULL_DFLT_OFF (alapértelmezett ANSI NULL kikapcsolva)
FORCEPLAN
ARITHABORT
Első dátum
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
NYELV
KONKAT_NULL_AD_NULLT_AD
dátumformátum
ANSI_WARNINGS (ANSI figyelmeztetések)
IDÉZETES_AZONOSÍTÓ
ANSI_NULLS
NINCS_BETEKINTÉSI_TÁBLA
ANSI ALAPÉRTELMEZÉSEK
Több terv gyorsítótárazása ugyanazon lekérdezéshez
A lekérdezések és végrehajtási tervek egyedileg azonosíthatók az adatbázismotorban, hasonlóan az ujjlenyomathoz:
- A lekérdezési terv kivonata egy adott lekérdezés végrehajtási tervében kiszámított bináris kivonatérték, amely a hasonló végrehajtási tervek egyedi azonosítására szolgál.
- A lekérdezés kivonata egy olyan bináris kivonatérték, amely egy lekérdezés Transact-SQL szövegére van kiszámítva, és a lekérdezések egyedi azonosítására szolgál.
A lefordított terv lekérhető a tervgyorsítótárból egy Plan Handle használatával, amely egy átmeneti azonosító, amely csak akkor marad állandó, ha a terv a gyorsítótárban marad. A tervleíró a teljes köteg lefordított tervéből származtatott kivonatérték. A lefordított terv tervleírója ugyanaz marad, még akkor is, ha a kötegben lévő egy vagy több utasítás újrafordításra kerül.
Megjegyzés:
Ha egyetlen utasítás helyett köteghez állítottak össze tervet, a kötegben lévő egyes utasítások tervét lekérheti a tervleíró és az utasításeltolás használatával.
A sys.dm_exec_requests DMV az egyes rekordokhoz tartozó oszlopokat tartalmazza statement_start_offsetstatement_end_offset , amelyek egy jelenleg futó köteg vagy megőrzött objektum jelenleg végrehajtó utasítására vonatkoznak. További információ: sys.dm_exec_requests (Transact-SQL).
A sys.dm_exec_query_stats DMV ezeket az oszlopokat is tartalmazza az egyes rekordokhoz, amelyek egy utasítás pozíciójára hivatkoznak egy kötegen vagy egy megőrzött objektumon belül. További információ: sys.dm_exec_query_stats (Transact-SQL).
A köteg tényleges Transact-SQL szövege egy külön memóriaterületen van tárolva, elválasztva a terv gyorsítótárától, az SQL Manager gyorsítótárban (SQLMGR). A lefordított terv Transact-SQL szövege lekérhető az SQL Manager gyorsítótárból egy SQL Handle használatával, amely egy átmeneti azonosító, és csak akkor marad változatlan, amíg legalább egy terv, amely hivatkozik rá, a tervgyorsítótárban marad. Az SQL-fogantyú egy hash érték, amely a teljes csomagszövegből származik, és garantáltan egyedi minden egyes csomag esetében.
Megjegyzés:
Az összeállított tervhez hasonlóan a Transact-SQL szöveg kötegenként tárolódik, és tartalmazza a megjegyzéseket is. Az SQL fogantyú a teljes kötegszöveg MD5 hashét tartalmazza, és garantáltan egyedi minden egyes köteg számára.
Az alábbi lekérdezés az SQL Manager-gyorsítótár memóriahasználatával kapcsolatos információkat tartalmaz:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Az SQL-kezelők és a tervek kezelői között 1:N összefüggés áll fenn. Ilyen feltétel akkor fordul elő, ha a lefordított tervek gyorsítótárkulcsa eltérő. Ez a SET-beállítások ugyanazon köteg két végrehajtása közötti módosítása miatt fordulhat elő.
Fontolja meg a következő tárolt eljárást:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Ellenőrizze, hogy mi található a terv gyorsítótárban az alábbi lekérdezés segítségével:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Itt van az eredmények összessége.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Most hajtsa végre a tárolt eljárást egy másik paraméterrel, de a végrehajtási környezetben nincs más változás:
EXEC usp_SalesByCustomer 8
GO
Ellenőrizze újra, hogy mi található a tervgyorsítótárban. Itt van az eredmények összessége.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Figyelje meg, hogy a usecounts értéke 2-re nőtt, amit az jelent, hogy ugyanazt a gyorsítótárba mentett tervet újra felhasználták as-is, mert a végrehajtási kontextus adatszerkezeteit újrahasználták. Most módosítsa a beállítást, SET ANSI_DEFAULTS és hajtsa végre a tárolt eljárást ugyanazzal a paraméterrel.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Ellenőrizze újra, hogy mi található a tervgyorsítótárban. Itt van az eredmények összessége.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Figyelje meg, hogy most két bejegyzés található a sys.dm_exec_cached_plans DMV-kimenetben:
- Az
usecountsoszlop a1értéket jeleníti meg az első rekordban, amelyet egyszer hajtottak végre aSET ANSI_DEFAULTS OFFsegítségével. - Az
usecountsoszlop a második rekord értékét,2mutatja, amely aSET ANSI_DEFAULTS ONtervvel lett végrehajtva, mivel kétszer hajtották végre. - A különböző
memory_object_addressegy másik végrehajtási terv bejegyzésre utal a tervgyorsítótárban.sql_handleAz érték azonban mindkét tétel esetében ugyanaz, mert ugyanarra a kötegre hivatkoznak.- A végrehajtás, amelynek a
ANSI_DEFAULTSbeállítása KI van kapcsolva, újplan_handle-el rendelkezik, és újra felhasználható olyan hívásokhoz, amelyek ugyanazokkal a SET beállítási opciókkal rendelkeznek. Az új tervleíróra azért van szükség, mert a végrehajtási környezet újraindult a megváltozott SET-beállítások miatt. Ez azonban nem vált ki újrafordítást: mindkét bejegyzés ugyanarra a tervre és lekérdezésre hivatkozik, amelyet ugyanazquery_plan_hashésquery_hashértékek is igazolnak.
- A végrehajtás, amelynek a
Ez gyakorlatilag azt jelenti, hogy a gyorsítótárban két tervbejegyzés található, amelyek ugyanahhoz a köteghez tartoznak, és kiemeli annak fontosságát, hogy a SET-beállításokat érintő tervgyorsítótár ugyanaz legyen, amikor ugyanazokat a lekérdezéseket ismételten hajtják végre, hogy optimalizálni tudjuk a terv újrafelhasználását, és a tervgyorsítótár méretét a minimálisra csökkentsük.
Jótanács
Gyakori buktató, hogy a különböző ügyfelek eltérő alapértelmezett értékekkel rendelkezhetnek a SET beállításokhoz. Az SQL Server Management Studio használatával létrehozott kapcsolat például automatikusan a QUOTED_IDENTIFIER értéket BE állítja, míg az SQLCMD a QUOTED_IDENTIFIER értéket KI állítja. A két ügyfél ugyanazon lekérdezéseinek végrehajtása több csomagot eredményez (a fenti példában leírtak szerint).
Végrehajtási tervek eltávolítása a tervtárból
A végrehajtási tervek mindaddig a tervgyorsítótárban maradnak, amíg elegendő memória áll rendelkezésre a tárolásukhoz. Ha memóriaterhelés áll fenn, az SQL Server adatbázismotorja költségalapú megközelítést alkalmaz annak meghatározására, hogy mely végrehajtási tervek távolíthatók el a tervgyorsítótárból. A költségalapú döntés meghozatalához az SQL Server adatbázismotorja az alábbi tényezőknek megfelelően növeli és csökkenti az egyes végrehajtási tervek aktuális költségváltozóit.
Amikor egy felhasználói folyamat végrehajtási tervet szúr be a gyorsítótárba, a felhasználói folyamat az eredeti lekérdezés fordítási költségével megegyező aktuális költséget állítja be; az alkalmi végrehajtási tervek esetében a felhasználói folyamat nullára állítja az aktuális költséget. Ezután minden alkalommal, amikor egy felhasználói folyamat végrehajtási tervre hivatkozik, visszaállítja az aktuális költséget az eredeti fordítási költségre; alkalmi végrehajtási tervek esetén a felhasználói folyamat növeli az aktuális költséget. Az összes csomag esetében az aktuális költség maximális értéke az eredeti fordítási költség.
Ha memóriaterhelés áll fenn, az SQL Server adatbázismotor úgy válaszol, hogy eltávolítja a végrehajtási terveket a tervgyorsítótárból. Annak meghatározásához, hogy mely terveket szeretné eltávolítani, az SQL Server adatbázismotorja ismételten megvizsgálja az egyes végrehajtási tervek állapotát, és eltávolítja a terveket, ha az aktuális költség nulla. A memóriaterhelés fennállása esetén a rendszer nem távolít el automatikusan egy nulla aktuális költségű végrehajtási tervet; a rendszer csak akkor távolítja el, ha az SQL Server adatbázismotorja megvizsgálja a tervet, és az aktuális költség nulla. Végrehajtási terv vizsgálatakor az SQL Server adatbázismotor az aktuális költséget nullára küldi azáltal, hogy csökkenti az aktuális költséget, ha egy lekérdezés jelenleg nem használja a tervet.
Az SQL Server adatbázismotorja ismételten megvizsgálja a végrehajtási terveket, amíg elég el nem lettek távolítva a memóriakövetelmények teljesítéséhez. Bár a memóriaterhelés létezik, előfordulhat, hogy a végrehajtási terv költségei többször is növekednek és csökkennek. Ha már nincs memóriaterhelés, az SQL Server adatbázis-motor leállítja a fel nem használt végrehajtási tervek jelenlegi költségeinek csökkentését, és valamennyi végrehajtási terv a gyorsítótárban marad, még akkor is, ha a költségük nulla.
Az SQL Server adatbázismotorja az erőforrásmonitor és a felhasználói feldolgozó szálak segítségével szabadít fel memóriát a tervtárból a memóriára nehezedő nyomás enyhítése érdekében. Az erőforrásmonitor és a felhasználói munkavégző szálak megvizsgálhatják az egyidejűleg futtatott terveket az egyes fel nem használt végrehajtási tervek aktuális költségeinek csökkentése érdekében. Az erőforrásmonitor eltávolítja a végrehajtási terveket a tervgyorsítótárból, ha globális memóriaterhelés áll fenn. Memóriát szabadít fel a rendszermemória, a folyamatmemória, az erőforráskészlet memóriájának és az összes gyorsítótár maximális méretének kényszerítéséhez.
Az összes gyorsítótár maximális mérete a pufferkészlet méretének függvénye, és nem haladhatja meg a kiszolgáló maximális memóriáját. A maximális kiszolgálómemória konfigurálásáról további információt a következő helyen
A felhasználói munkavégző szálak eltávolítják a végrehajtási terveket a terv gyorsítótárából, ha egyetlen gyorsítótár-memóriaterhelés áll fenn. Politikai szabályokat kényszerítenek ki az egyedi gyorsítótár maximális méretére és az egyedi gyorsítótár maximális bejegyzéseire.
Az alábbi példák azt szemléltetik, hogy mely végrehajtási tervek lesznek eltávolítva a tervgyorsítótárból:
- A végrehajtási tervre gyakran hivatkoznak, hogy a költsége soha ne legyen nulla. A terv a terv gyorsítótárában marad, és csak akkor távolítja el, ha memóriaterhelés van, és az aktuális költség nulla.
- Beszúrnak egy alkalmi végrehajtási tervet, és nem hivatkoznak rá újra, amíg nem lép fel memóriaterhelés. Mivel az alkalmi tervek inicializálása a jelenlegi nulla költséggel történik, az SQL Server adatbázismotorja megvizsgálja a végrehajtási tervet, látni fogja a nulla aktuális költséget, és eltávolítja a tervet a terv gyorsítótárából. Az ad hoc végrehajtási terv a tervgyorsítótárban marad nulla aktuális költséggel, ha a memóriaterhelés nincs jelen.
Ha manuálisan szeretne eltávolítani egy csomagot vagy az összes csomagot a gyorsítótárból, használja a DBCC FREEPROCCACHE parancsot.
A DBCC FREESYSTEMCACHE a gyorsítótárak, beleértve a tárolási terv gyorsítótárát is, törlésére használható. Az SQL Server 2016 (13.x) verziótól kezdve a ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE az eljárások (tervek) gyorsítótárának törlésére a hatókörben lévő adatbázisban.
Egyes konfigurációs beállítások sp_configure és reconfigure révén történő módosítása azt is eredményezi, hogy a tervek törlődnek a cachéből. A konfigurációs beállítások listáját a DBCC FREEPROCCACHE cikk Megjegyzések szakaszában találja. Az ehhez hasonló konfigurációváltozások a következő tájékoztató üzenetet naplózják a hibanaplóban:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Végrehajtási tervek újrafordítása
Az adatbázis bizonyos változásai miatt a végrehajtási terv nem hatékony vagy érvénytelen lehet az adatbázis új állapota alapján. Az SQL Server észleli azokat a módosításokat, amelyek érvénytelenítenek egy végrehajtási tervet, és érvénytelenként jelöli meg a tervet. Ezután újra létre kell készíteni egy új tervet a lekérdezést végrehajtó következő kapcsolathoz. A terv érvénytelenítésének feltételei a következők:
- A lekérdezés (
ALTER TABLEésALTER VIEW) által hivatkozott táblán vagy nézeten végzett módosítások. - Egyetlen eljárás módosításai, amelyek az eljárás összes tervét elvetik a gyorsítótárból (
ALTER PROCEDURE). - A végrehajtási terv által használt indexek módosítása.
- A végrehajtási terv által használt statisztikák frissítései, amelyeket explicit módon, például egy utasításból, vagy
UPDATE STATISTICSautomatikusan generáltak. - A végrehajtási terv által használt index elvetése.
- Egy explicit hívás
sp_recompile. - A kulcsok nagy száma (lekérdezés által hivatkozott táblát módosító, más felhasználók által
INSERTvagyDELETEutasításokkal generált változások). - Az eseményindítókat tartalmazó táblák esetében, ha a beszúrt vagy törölt táblák sorainak száma jelentősen nő.
- Tárolt eljárás végrehajtása a
WITH RECOMPILEbeállítással.
A legtöbb újrafordításra vagy az utasítás helyességéhez, vagy a lekérdezések gyorsabb végrehajtási terveinek beszerzéséhez van szükség.
A 2005 előtti SQL Server-verziókban, amikor egy kötegen belüli utasítás újrafordítást okoz, a teljes köteg újrafordításra került, függetlenül attól, hogy tárolt eljárással, eseményindítóval, alkalmi köteggel vagy előkészített utasítással lett-e elküldve. Az SQL Server 2005 -től kezdve (9.x) csak az újrafordítást aktiváló kötegben lévő utasítás lesz újrafordítve. Emellett az SQL Server 2005 -ben (9.x) és újabb verziókban további típusú újrafordítások is léteznek a bővített funkciókészlet miatt.
Az utasításszintű újrafordítás azért előnyös a teljesítmény szempontjából, mert a legtöbb esetben kis számú utasítás okoz újrafordításokat és az azokhoz kapcsolódó büntetéseket a processzoridő és a zárolások szempontjából. Ezért elkerülhetők ezek a hátrányok a köteg többi olyan utasítása esetében, amelyeket nem kell újrafordítani.
A sql_statement_recompile kiterjesztett esemény (XEvent) utasításszintű újrafordításokat jelent. Ez az XEvent akkor fordul elő, ha bármilyen köteg utasításszintű újrafordítást igényel. Ide tartoznak a tárolt eljárások, eseményindítók, alkalmi kötegek és lekérdezések. A kötegek több felületen is beküldhetők, például sp_executesqldinamikus SQL-en, előkészítési módszereken vagy végrehajtási módszereken keresztül.
Az recompile_cause XEvent oszlopa sql_statement_recompile egy egész kódot tartalmaz, amely az újrafordítás okát jelzi. Az alábbi táblázat a lehetséges okokat tartalmazza:
Séma módosult
A statisztikák megváltoztak
Halasztott fordítás
A SET beállítás módosult
Ideiglenes tábla meg lett változtatva
A távoli sorok halmaza megváltozott
FOR BROWSE engedély módosult
Módosult a lekérdezésértesítési környezet
A particionált nézet megváltozott
A kurzor beállításai megváltoztak
OPTION (RECOMPILE) Kért
Paraméteres terv kiürítve
Az adatbázisverziót érintő terv módosult
Módosult a lekérdezéstár-terv kényszerítési szabályzata
A lekérdezéstár-terv kényszerítése nem sikerült
A Lekérdezéstárból hiányzik a csomag
Megjegyzés:
Az OLYAN SQL Server-verziókban, amelyekben az XEvents nem érhető el, az SQL Server Profiler SP:Recompile trace esemény használható az utasításszintű újrafordítások jelentésére.
A nyomkövetési esemény SQL:StmtRecompile az utasításszintű újrafordításokat is jelenti, és ez a nyomkövetési esemény az újrafordítások nyomon követésére és hibakeresésére is használható.
Miközben a SP:Recompile csak tárolt eljárásokhoz és eseményindítókhoz hozzárendel generálást, a SQL:StmtRecompile tárolt eljárásokhoz, eseményindítókhoz, alkalmi kötegekhez, sp_executesql segítségével végrehajtott kötegekhez, előkészített lekérdezésekkel és dinamikus SQL-lel hajt végre generálást.
Az EventSubClass oszlop egy SP:RecompileSQL:StmtRecompile egész kódból áll, amely az újrafordítás okát jelzi. A kódokat az SQL:StmtRecompile eseményosztály ismerteti.
Megjegyzés:
Amikor a AUTO_UPDATE_STATISTICS adatbázis-beállítás ON értékre van állítva, a lekérdezések újrafordításra kerülnek, ha olyan táblákat vagy indexelt nézeteket céloznak meg, amelyek statisztikáit frissítették, vagy amelyek számossága jelentősen megváltozott az utolsó végrehajtás óta.
Ez a viselkedés a szokásos, felhasználó által definiált táblákra, ideiglenes táblákra, valamint a DML-eseményindítók által létrehozott beszúrt és törölt táblákra vonatkozik. Ha a lekérdezés teljesítményét túlzott újrafordítások befolyásolják, módosítsa ezt a beállítást a következőre OFF: . Ha az AUTO_UPDATE_STATISTICS adatbázis-beállítás értéke be van állítva OFF, a DML-eseményindítók INSTEAD OF által létrehozott beszúrt és törölt táblák kivételével nem történik újrafordítás a statisztikák vagy számosságváltozások alapján. Mivel ezek a táblák létre vannak hozva tempdb, a hozzájuk hozzáférő lekérdezések újrafordítása a AUTO_UPDATE_STATISTICStempdb beállítástól függ.
Az SQL Server 2005 előtti részében a lekérdezések továbbra is újrafordítódnak a beszúrt és törölt DML trigger táblák számosságváltozásai alapján, még akkor is, ha ez a beállítás OFF értékre van állítva.
Paraméterek és végrehajtási terv újbóli felhasználása
A paraméterek használata, beleértve az ADO-, OLE DB- és ODBC-alkalmazások paraméterjelölőit, növelheti a végrehajtási tervek újrafelhasználását.
Figyelmeztetés
A végfelhasználók által beírt értékek tárolására használt paraméterek vagy paraméterjelölők biztonságosabbak, mint az értékek egy sztringbe való összefűzése, amelyet aztán egy adatelérési API-módszer, az EXECUTE utasítás vagy a sp_executesql tárolt eljárás használatával hajtanak végre.
A következő két SELECT utasítás között az egyetlen különbség az összehasonlítandó értékek a feltételben WHERE.
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
A lekérdezések végrehajtási tervei között az egyetlen különbség az a tárolt érték, amelyet a ProductSubcategoryID oszlop összehasonlításához használnak. Bár a cél az, hogy az SQL Server mindig felismerje, hogy az utasítások lényegében ugyanazt a tervet generálják, és újra felhasználják a terveket, az SQL Server néha nem észleli ezt összetett Transact-SQL utasításokban.
Az állandók Transact-SQL utasítástól paraméterekkel való elválasztása segít a relációs motornak felismerni az ismétlődő terveket. A paramétereket a következő módokon használhatja:
A Transact-SQL-n használja a
sp_executesql-t:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmEz a módszer Transact-SQL sql-utasításokat dinamikusan létrehozó szkriptekhez, tárolt eljárásokhoz vagy triggerekhez ajánlott.
Az ADO, az OLE DB és az ODBC paraméterjelölőket használ. A paraméterjelölők olyan kérdőjelek (?), amelyek egy SQL-utasítás állandóját cserélik le, és egy programváltozóhoz vannak kötve. Egy ODBC-alkalmazásban például a következőket teheti:
Az
SQLBindParameterhasználatával köt egy egész szám változót egy SQL-utasítás első paraméterjelölőjéhez.Helyezze az egész számot a változóba.
Hajtsa végre az utasítást, és adja meg a paraméterjelölőt (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
Az SQL Server natív ügyfél OLE DB-szolgáltatója és az SQL Server
sp_executesqlnatív ügyfél ODBC-illesztőprogramja utasításokat küld az SQL Servernek, amikor az alkalmazásokban paraméterjelölőket használnak.Tárolt eljárások tervezése, amelyek a paramétereket a tervezés alapján használják.
Ha nem épít ki explicit módon paramétereket az alkalmazások tervezésébe, az SQL Server Query Optimizer használatával automatikusan paraméterezhet bizonyos lekérdezéseket az egyszerű paraméterezés alapértelmezett viselkedésével. Másik lehetőségként kényszerítheti a Lekérdezésoptimalizálót, hogy paraméterezze az adatbázis PARAMETERIZATION összes lekérdezését az ALTER DATABASE utasítás PARAMETERIZATION opcióját -ra állítva.
Ha a kényszerített paraméterezés engedélyezve van, az egyszerű paraméterezés továbbra is előfordulhat. A következő lekérdezés például nem paraméterezhető a kényszerített paraméterezés szabályai szerint:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Az egyszerű paraméterezési szabályok szerint azonban paraméterezhető. Ha a kényszerített paraméterezést megpróbálják alkalmazni, de sikertelen, akkor ezután is megpróbálják az egyszerű paraméterezést alkalmazni.
Egyszerű paraméterezés
Az SQL Serverben a paraméterek vagy paraméterjelölők Transact-SQL utasításokban való használata növeli a relációs motor azon képességét, hogy az új Transact-SQL utasítások egyezzenek a meglévő, korábban lefordított végrehajtási tervekkel.
Figyelmeztetés
A végfelhasználók által beírt értékek tárolására használt paraméterek vagy paraméterjelölők biztonságosabbak, mint az értékek egy sztringbe való összefűzése, amelyet aztán egy adatelérési API-módszerrel, az EXECUTE utasítással vagy a sp_executesql tárolt eljárással hajtanak végre.
Ha egy Transact-SQL utasítás végrehajtása paraméterek nélkül történik, az SQL Server belsőleg paraméterezi az utasítást, hogy növelje a meglévő végrehajtási tervvel való egyeztetés lehetőségét. Ezt a folyamatot egyszerű paraméterezésnek nevezzük. Az SQL Server 2005 előtti verzióiban a folyamatot automatikus paraméterezésnek nevezték.
Vegye figyelembe ezt az állítást:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Az utasítás végén található 1 érték paraméterként adható meg. A relációs motor úgy hozza létre a köteg végrehajtási tervét, mintha az 1 érték helyett paraméter lett volna megadva. Ezen egyszerű paraméterezés miatt az SQL Server felismeri, hogy a következő két utasítás lényegében ugyanazt a végrehajtási tervet hozza létre, és újra felhasználja a második utasítás első tervét:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Összetett Transact-SQL utasítások feldolgozásakor a relációs motor nehezen állapíthatja meg, hogy mely kifejezések paraméterezhetők. Ha növelni szeretné a relációs motor azon képességét, hogy összetett Transact-SQL utasításoknak megfeleljen a meglévő, nem használt végrehajtási tervekhez, explicit módon adja meg a paramétereket vagy sp_executesql paraméterjelölőket használva.
Megjegyzés:
Ha a +, -, , */, vagy % aritmetikai operátorok az int, smallint, tinyint vagy bigint állandó értékek implicit vagy explicit konvertálására szolgálnak az lebegőpontos, valós, decimális vagy numerikus adattípusokra, az SQL Server meghatározott szabályokat alkalmaz a kifejezés eredményeinek típusának és pontosságának kiszámításához. Ezek a szabályok azonban eltérnek attól függően, hogy a lekérdezés paraméterezett-e vagy sem. Ezért a lekérdezésekben lévő hasonló kifejezések bizonyos esetekben eltérő eredményeket eredményezhetnek.
Az egyszerű paraméterezés alapértelmezett viselkedése alatt az SQL Server a lekérdezések viszonylag kis osztályát paraméterezi. Azonban megadhatja, hogy az adatbázis összes lekérdezése paraméteres legyen, bizonyos korlátozások figyelembevételével, ha a PARAMETERIZATION parancs lehetőségét a ALTER DATABASEFORCED értékre állítja. Ezzel javíthatja a nagy mennyiségű egyidejű lekérdezést használó adatbázisok teljesítményét a lekérdezés-fordítások gyakoriságának csökkentésével.
Másik lehetőségként megadhatja, hogy egyetlen lekérdezés és minden más, szintaktikailag egyenértékű, de csak a paraméterértékekben eltérő lekérdezés paraméterezhető legyen.
Jótanács
Az Object-Relational-leképezési (ORM-) megoldás, például az Entity Framework (EF) használatakor előfordulhat, hogy az alkalmazáslekérdezések, például a manuális LINQ-lekérdezési fák vagy bizonyos nyers SQL-lekérdezések nem paraméterezhetők, ami hatással van a terv újrahasználatára és a lekérdezések nyomon követésére a Lekérdezéstárban. További információ: EF-lekérdezések gyorsítótárazása és paraméterezése és EF Raw SQL-lekérdezések.
Kényszerített paraméterezés
Az SQL Server alapértelmezett egyszerű paraméterezési viselkedését felülbírálhatja úgy, hogy megadja, hogy az adatbázisban lévő összes SELECT, INSERT, UPDATE, és DELETE utasítás paraméterezhető legyen, bizonyos korlátozások figyelembevételével. A kényszerített paraméterezés engedélyezéséhez a PARAMETERIZATION utasításban állítsa be a FORCED opciót ALTER DATABASE. A kényszerített paraméterezés javíthatja bizonyos adatbázisok teljesítményét a lekérdezés-fordítások és újrafordítások gyakoriságának csökkentésével. A kényszerített paraméterezés előnyeit élvező adatbázisok általában azok, amelyek nagy mennyiségű egyidejű lekérdezést tapasztalnak olyan forrásokból, mint például az értékesítési pontok alkalmazásai.
Amikor a PARAMETERIZATION opció be van állítva FORCED-re, a lekérdezés fordítása során bármely formában elküldött, a SELECT, INSERT, UPDATE vagy DELETE utasításban megjelenő bármilyen literális érték paraméterrészé alakításra kerül. A kivételek a következő lekérdezési szerkezetekben megjelenő literálok:
-
INSERT...EXECUTENyilatkozatok. - Tárolt eljárások, eseményindítók vagy felhasználó által definiált függvények testén belüli utasítások. Az SQL Server már újra felhasználja a lekérdezési terveket ezekhez a rutinokhoz.
- Azok az előkészített utasítások, amelyeket már paramétereztek az ügyféloldali alkalmazásban.
- Az XQuery metódushívásokat tartalmazó utasítások, amelyekben a metódus olyan környezetben jelenik meg, amelyben az argumentumai általában paraméterezhetők, például egy
WHEREzáradék. Ha a metódus olyan környezetben jelenik meg, amelyben az argumentumai nem paraméterezhetők, az utasítás többi része paraméterezve lesz. - Egy Transact-SQL kurzoron belüli utasítások. (
SELECTaz API-kurzorokon belüli utasítások paraméteresen vannak megadva.) - Elavult lekérdezésszerkezetek.
- Bármelyik utasítás, amely
ANSI_PADDINGvagyANSI_NULLSkörnyezetében fut, vagy beállítva vanOFFértékre. - Olyan utasítások, amelyek több mint 2,097 literált tartalmaznak, jogosultak a paraméterezésre.
- Változókra hivatkozó utasítások, például
WHERE T.col2 >= @bb. - A lekérdezési
RECOMPILEtippet tartalmazó utasítások. - Állítások, amelyek egy
COMPUTEzáradékot tartalmaznak. - Állítások, amelyek egy
WHERE CURRENT OFzáradékot tartalmaznak.
Emellett a következő lekérdezési záradékok nincsenek paraméterezve. Ezekben az esetekben csak a záradékok nincsenek paraméterezve. Az ugyanazon lekérdezésen belüli egyéb záradékok is jogosultak lehetnek a kényszerített paraméterezésre.
- A <nyilatkozat> bármelyikének a
SELECTselect_list-je. Ide tartoznakSELECTaz albekérdezések ésSELECTaz utasításokon belüliINSERTlisták. - Részlekérdezés
SELECTutasítások, amelyek egyIFutasításon belül jelennek meg. - Egy
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOvagyFOR XMLzáradékok egy lekérdezésben. - Argumentumok közvetlen vagy alexpresszióként, a
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXMLvagy bármelyFULLTEXToperátorhoz. - A
LIKEzáradék mintája és menekülési karakter argumentumai. - A
CONVERTzáradék stílusargumentuma. - Egész szám állandók egy
IDENTITYkódblokkon belül. - ODBC-bővítmény szintaxisával megadott állandók.
- Konstans módon összecsukható kifejezések, amelyek a
+,-,*,/és%operátorok argumentumai. A kényszerített paraméterezésre való jogosultság mérlegelésekor az SQL Server konstansan összecsukhatónak tekint egy kifejezést, ha az alábbi feltételek valamelyike teljesül:- A kifejezésben nem jelennek meg oszlopok, változók vagy al lekérdezések.
- A kifejezés tartalmaz egy záradékot
CASE.
- A hint záradékok lekérdezéséhez használható argumentumok. Ezek közé tartozik a lekérdezési tipp number_of_rows argumentuma
FAST, a lekérdezési tipp number_of_processors argumentumaMAXDOP, és a lekérdezési tipp number argumentumaMAXRECURSION.
A paraméterezés az egyes Transact-SQL utasítások szintjén történik. Más szóval, a csomag egyes utasításai paraméterezve vannak. Az összeállítás után a rendszer egy paraméteres lekérdezést hajt végre annak a kötegnek a kontextusában, amelyben eredetileg el lett küldve. Ha egy lekérdezés végrehajtási tervét gyorsítótárazza a rendszer, a dinamikus felügyeleti nézet SQL-oszlopára sys.syscacheobjects hivatkozva meghatározhatja, hogy paraméterezett-e a lekérdezés. Ha egy lekérdezés paraméterezve van, a paraméterek neve és adattípusa a beküldött köteg szövege elé kerül ebben az oszlopban, például (@1 tinyint).
Megjegyzés:
A paraméternevek tetszőlegesek. A felhasználók vagy alkalmazások nem támaszkodhatnak egy adott elnevezési sorrendre. Az SQL Server és a Service Pack verziófrissítései között a következők is változhatnak: paraméternevek, a paraméteres konstansok kiválasztása és a paraméteres szöveg térköze.
Paraméterek adattípusai
Ha az SQL Server konstansokat paraméterez, a paraméterek a következő adattípusokká alakulnak:
- Minden olyan egész számkonstans, amely mérete alapján az int adattípusba férne, int adattípusra paramétereződik. Azok a nagyobb egész számkonstansok, amelyek predikátumok azon részei, amelyek összehasonlító operátort tartalmaznak (beleértve a következőket:
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEEN, ésIN), numerikus(38,0) típusra paramétereződnek. A nagyobb literálok, amelyek nem részei az összehasonlító operátorokat tartalmazó predikátumoknak, olyan numerikusra paramétereznek, amelynek pontossága elég nagy ahhoz, hogy támogassa a méretét, és amelynek mérete 0. - Olyan rögzített pontosságú numerikus literálok, amelyek predikátumok részei, amelyek összehasonlító operátorokat is magukban foglalnak, numerikus értékké paramétereződnek, amelynek pontossága 38, és mérete éppen elég nagy a számjegyek támogatásához. Az olyan rögzítettpontos numerikus literálok, amelyek nem részei a predikátumoknak, amelyek összehasonlító operátorokat foglalnak magukban, olyan numerikusra paramétereznek, amelynek pontossága és mérete elég nagy a méret támogatásához.
- A lebegőpontos numerikus literálok float(53) értékre paramétereznek.
- A nem Unicode-sztringkonstansok a varchar(8000) értékre paramétereznek, ha a literál 8000 karakteren belül elfér, és a 8000 karakternél nagyobb varchar(max) értékre.
- A Unicode-sztringkonstansok nvarchar(4000) értékre paramétereznek, ha a literál 4000 Unicode-karakteren belülre illeszkedik, és nvarchar(max) értékre, ha a literál 4000 karakternél nagyobb.
- A bináris literálok varbinary(8000) értékre paramétereznek, ha a literál 8000 bájton belülre illeszkedik. Ha 8000 bájtnál nagyobb, akkor a rendszer varbinary(max) értékre konvertálja.
- A pénz típusú literálok pénzre paramétereznek.
A kényszerített paraméterezés használatának irányelvei
Vegye figyelembe a következőket, amikor a PARAMETERIZATION beállítást KÖTELEZŐ-re állítja:
- A kényszerített paraméterezés hatására a lekérdezés összeállításakor a lekérdezésben levő literál konstansok paraméterekkel módosulnak. A Lekérdezésoptimalizáló ezért a lekérdezések optimálisnál rosszabb csomagjait is választhatja. A Lekérdezésoptimalizáló kevésbé valószínű, hogy egy indexelt nézethez vagy egy számított oszlop indexéhez hasonlítja a lekérdezést. A particionált táblákon és elosztott particionált nézetekben feltett lekérdezésekhez választhat optimálisnál rosszabb terveket. A kényszerített paraméterezés nem használható olyan környezetekhez, amelyek nagymértékben támaszkodnak az indexelt nézetekre és a számított oszlopok indexeire. Ezt a
PARAMETERIZATION FORCEDlehetőséget általában csak tapasztalt adatbázis-szakemberek használhatják, miután megállapítják, hogy ez nem befolyásolja hátrányosan a teljesítményt. - Az egynél több adatbázisra hivatkozó elosztott lekérdezések akkor jogosultak a kényszerített paraméterezésre
PARAMETERIZATION, ha aFORCEDbeállítás abban az adatbázisban van beállítva, amelyben a lekérdezés fut. - Ha az
PARAMETERIZATIONopciótFORCED-ra állítja, kiüríti az adatbázis tervgyorsítótárából az összes lekérdezési tervet, kivéve azokat, amelyek jelenleg fordítás, újrafordítás vagy futás alatt vannak. A beállításmódosítás során összeállított vagy futtatott lekérdezések tervei a lekérdezés következő végrehajtásakor lesznek paraméterezve. - A
PARAMETERIZATIONbeállítás egy online művelet, amelyhez nem szükséges adatbázisszintű kizárólagos zárolás. - Jelenlegi beállítása a
PARAMETERIZATIONopció megmarad az adatbázis újra csatlakoztatása vagy visszaállításakor.
A kényszerített paraméterezés viselkedését felülbírálhatja úgy, hogy megadhatja, hogy az egyszerű paraméterezést egyetlen lekérdezésen lehessen megkísérelni, és minden olyan más paramétert, amely szintaktikailag egyenértékű, de csak a paraméterértékekben különbözik. Ezzel szemben megadhatja, hogy a kényszerített paraméterezés csak szintaktikailag egyenértékű lekérdezések halmazán kísérelhető meg, még akkor is, ha a kényszerített paraméterezés le van tiltva az adatbázisban. Erre a célra terv útmutatókat használunk.
Megjegyzés:
Ha a PARAMETERIZATION opciót FORCED-re állítják, a hibaüzenetek jelentése eltérhet attól, amikor a PARAMETERIZATION opciót SIMPLE-re állítják: kényszerített paraméterezés esetén több hibaüzenet jelenthet meg, ahol kevesebb üzenet jelenne meg egyszerű paraméterezés esetén, és a hibák előfordulásának sorai helytelenül jelenthetők.
SQL-utasítások előkészítése
Az SQL Server relációs motorja teljes körű támogatást nyújt Transact-SQL utasítások előkészítéséhez a végrehajtás előtt. Ha egy alkalmazásnak többször is végre kell hajtania egy Transact-SQL utasítást, az adatbázis API-val a következőket teheti:
- A nyilatkozatot egyszer készítse elő. Ez a Transact-SQL utasítást végrehajtási tervbe állítja össze.
- Hajtsa végre az előre összeállított végrehajtási tervet minden alkalommal, amikor végre kell hajtania az utasítást. Ez megakadályozza a Transact-SQL utasítás újrafordítását az első végrehajtás után. Az utasítások előkészítését és végrehajtását API-függvények és metódusok vezérlik. Ez nem része a Transact-SQL nyelvnek. A Transact-SQL utasítások végrehajtásának előkészítő/végrehajtási modelljét az SQL Server natív ügyféloldali OLE DB-szolgáltatója és az SQL Server natív ügyfél ODBC-illesztőprogramja támogatja. Előkészítési kérelem esetén vagy a szolgáltató vagy az illesztőprogram elküldi az utasítást az SQL Servernek az utasítás előkészítésére vonatkozó kéréssel. Az SQL Server összeállít egy végrehajtási tervet, és visszaad egy fogantyút ehhez a tervhez a szolgáltatónak vagy az illesztőprogramnak. Végrehajtási kérelem esetén a szolgáltató vagy az illesztőprogram kérést küld a kiszolgálónak a leíróhoz társított terv végrehajtására.
Az előkészített utasítások nem használhatók ideiglenes objektumok létrehozására az SQL Serveren. Az előkészített utasítások nem hivatkozhatnak olyan rendszer által tárolt eljárásokra, amelyek ideiglenes objektumokat, például ideiglenes táblákat hoznak létre. Ezeket az eljárásokat közvetlenül kell végrehajtani.
Az előkészítési/végrehajtási modell túlzott használata csökkentheti a teljesítményt. Ha egy utasítás végrehajtása csak egyszer történik meg, a közvetlen végrehajtáshoz csak egy hálózati oda-visszaút szükséges a kiszolgálóhoz. A Transact-SQL utasítás előkészítése és egyszeri végrehajtása az extra hálózati körutat igényel; egy körutat az utasítás előkészítésére, és egy másikat annak végrehajtására.
Az utasítás előkészítése hatékonyabb, ha paraméterjelölőket használ. Tegyük fel például, hogy egy alkalmazásnak időnként termékinformációkat kell lekérnie a AdventureWorks mintaadatbázisból. Az alkalmazás kétféleképpen teheti ezt meg.
Az első módszer használatával az alkalmazás külön lekérdezést hajthat végre minden kért termékhez:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
A második módszer használatával az alkalmazás a következőket teszi:
Egy paraméterjelölőt (?) tartalmazó utasítást készít:
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Programváltozót köt a paraméterjelölőhöz.
Minden alkalommal, amikor termékinformációra van szükség, kitölti a kötött változót a kulcsértékkel, és végrehajtja az utasítást.
A második módszer hatékonyabb, ha az utasítás végrehajtása több mint háromszor történik.
Az SQL Serverben a előkészítési/végrehajtási modell nem rendelkezik jelentős teljesítményelőnyrel a közvetlen végrehajtással szemben, mivel az SQL Server újra felhasználja a végrehajtási terveket. Az SQL Server hatékony algoritmusokkal rendelkezik az aktuális Transact-SQL utasításoknak az ugyanazon Transact-SQL utasítás korábbi végrehajtásához létrehozott végrehajtási tervekkel való egyeztetéséhez. Ha egy alkalmazás többször hajt végre Transact-SQL utasítást paraméterjelölőkkel, az SQL Server újra felhasználja a végrehajtási tervet az első végrehajtásból a második és az azt követő végrehajtáshoz (kivéve, ha a terv a terv gyorsítótárából származik). A előkészítési/végrehajtási modell továbbra is az alábbi előnyökkel jár:
- A végrehajtási terv azonosítási leíróval való megkeresése hatékonyabb, mint a Transact-SQL utasítás meglévő végrehajtási tervekkel való egyeztetéséhez használt algoritmusok.
- Az alkalmazás szabályozhatja a végrehajtási terv létrehozását és újbóli felhasználását.
- Az előkészítési/végrehajtási modell más adatbázisokba is hordozható, beleértve az SQL Server korábbi verzióit is.
Paraméterérzékenység
A paraméterérzékenység, más néven "paraméterszniffing" olyan folyamatra utal, amelynek során az SQL Server az összeállítás vagy az újrafordítás során "szippantja" az aktuális paraméterértékeket, és átadja a Lekérdezésoptimalizálónak, hogy a lekérdezés-végrehajtási tervek potenciálisan hatékonyabbak legyenek.
A paraméterértékek a következő kötegtípusok fordítása vagy újrafordítása során lesznek kiszúrva:
- Tárolt eljárások
- A lekérdezések beküldése a
sp_executesql-on keresztül történik - Előkészített lekérdezések
A paraméter szimatolási problémák elhárításával kapcsolatos további információkért lásd:
- Paraméterérzékeny problémák kivizsgálása és megoldása
- Paraméterek és végrehajtási terv újrafelhasználása
- Paraméterérzékeny csomag optimalizálása
- Lekérdezések hibaelhárítása paraméterérzékeny lekérdezések végrehajtási tervével kapcsolatos problémák esetén az Azure SQL Database-ben
- Lekérdezések hibaelhárítása paraméterérzékeny lekérdezések végrehajtási tervével kapcsolatos problémák esetén a felügyelt Azure SQL-példányban
Amikor egy SQL Server-lekérdezés a OPTION (RECOMPILE) hintet használja, a lekérdezésoptimalizáló a paramétereket és a helyi változókat fordítási idejű konstansokká alakítja, amelyek összehajthatók és literálokká redukálhatók. Ez azt jelenti, hogy a fordítás során az optimalizáló ismeri és használhatja a paraméterek és a helyi változók aktuális futásidejű értékeit, mivel közvetlenül az utasítás előtt léteznek. Az OPTION (RECOMPILE) lehetővé teszi az optimalizáló számára, hogy az adott értékekre szabott optimálisabb lekérdezési tervet hozzon létre, és kihasználhassa a legjobb mögöttes indexeket futásidőben. A paraméterek esetében ez a folyamat nem a kötegnek vagy a tárolt eljárásnak eredetileg átadott értékekre vonatkozik, hanem az értékekre, amelyek az újrafordítás idején érvényesek. Előfordulhat, hogy ezek az értékek az eljáráson belül módosultak, mielőtt elérnék a beleértendő RECOMPILEutasítást. Ez a viselkedés javíthatja a nagy mértékben változó vagy ferde bemeneti adatokat tartalmazó lekérdezések teljesítményét.
Helyi változók
Ha egy lekérdezés helyi változókat használ, az SQL Server nem tudja kiszúrni az értékeit fordításkor, ezért számosságot becsül meg a rendelkezésre álló statisztikák vagy heurisztika alapján. Ha léteznek statisztikák, általában a statisztikai hisztogram all Density ( más néven átlagos sűrűség) értékét használja a predikátumnak megfelelő sorok számának becslésére. Ha azonban nem állnak rendelkezésre statisztikák az oszlophoz, az SQL Server a heurisztikus becslésekre támaszkodik, például 10% egyenlőségi predikátum kiválasztására, és 30% az egyenlőtlenségekre és tartományokra, ami kevésbé pontos végrehajtási tervekhez vezethet. Íme egy példa egy helyi változót használó lekérdezésre.
DECLARE @ProductId INT = 100;
SELECT * FROM Products WHERE ProductId = @ProductId;
Ebben az esetben az SQL Server nem használja a 100 értéket a lekérdezés optimalizálásához. Általános becslést használ.
Párhuzamos lekérdezésfeldolgozás
Az SQL Server párhuzamos lekérdezéseket biztosít a lekérdezések végrehajtásának és indexelési műveleteinek optimalizálásához egynél több mikroprocesszort (CPU-t) használó számítógépeken. Mivel az SQL Server több operációsrendszer-feldolgozó szál használatával párhuzamosan is végrehajthat lekérdezési vagy indexelési műveletet, a művelet gyorsan és hatékonyan elvégezhető.
A lekérdezésoptimalizálás során az SQL Server olyan lekérdezéseket vagy indexműveleteket keres, amelyek kihasználhatják a párhuzamos végrehajtás előnyeit. Ezekhez a lekérdezésekhez az SQL Server exchange-operátorokat szúr be a lekérdezés végrehajtási tervébe, hogy előkészítse a lekérdezést a párhuzamos végrehajtásra. Az exchange operátor egy olyan lekérdezés-végrehajtási terv operátora, amely folyamatkezelést, adatterjesztést és folyamatvezérlést biztosít. Az exchange operátor altípusként tartalmazza a Distribute Streams, Repartition Streamsés Gather Streams a logikai operátorokat, amelyek közül egy vagy több egy párhuzamos lekérdezéshez tartozó lekérdezésterv Showplan kimenetében jelenhet meg.
Fontos
Bizonyos szerkezetek gátolják az SQL Server azon képességét, hogy párhuzamosságot használjon a teljes végrehajtási terven vagy részeken vagy a végrehajtási terven.
A párhuzamosságot gátló szerkezetek a következők:
Skaláris UDF-ek
A felhasználó által definiált skaláris függvényekkel kapcsolatos további információkért lásd: Felhasználó által definiált függvények létrehozása. Az SQL Server 2019 -től (15.x) kezdődően az SQL Server adatbázismotorja képes beszedni ezeket a függvényeket, és feloldhatja a párhuzamosság használatát a lekérdezésfeldolgozás során. További információ a skaláris UDF-formázásról: Intelligens lekérdezésfeldolgozás SQL-adatbázisokban.Távoli lekérdezés
A távoli lekérdezésről további információt a Showplan Logikai és Fizikai operátorok hivatkozásában talál.Dinamikus kurzorok
A kurzorokról további információt a KURZOR DEKLARÁLÁSA című témakörben talál.Rekurzív lekérdezések
A rekurzióval kapcsolatos további információkért tekintse meg a rekurzív közös táblakifejezések és rekurziók meghatározására és használatára vonatkozó irányelveketa T-SQL-ben.Többutas táblaértékelt függvények (MSTVF-ek)
További információ az MSTVF-ekről: Felhasználó által definiált függvények (adatbázismotor) létrehozása.TOP kulcsszó
További információ: TOP (Transact-SQL).
A lekérdezés-végrehajtási terv tartalmazhatja a QueryPlan elem NonParallelPlanReason attribútumát, amely leírja, hogy miért nem használták a párhuzamosságot. Az attribútum értékei a következők:
| NonParallelPlanReason érték | Leírás |
|---|---|
| MaxDOPSetToOne | A párhuzamosság maximális foka 1. |
| BecsültDOPÉrtékEgy | A párhuzamosság becsült mértéke 1. |
| Nincs Párhuzamos Lekérdezés Távolival | A párhuzamosság távoli lekérdezésekhez nem támogatott. |
| Nincs párhuzamos dinamikus kurzor | Dinamikus kurzorokhoz nem támogatnak párhuzamos terveket. |
| NincsPárhuzamosGyorsElőretekerésiMutató | A párhuzamos tervek nem támogatottak a gyors előrelépő kurzorok esetében. |
| Párhuzamos kurzor leolvasás könyvjelző szerint nem lehetséges | A párhuzamos tervek nem támogatottak a könyvjelzővel beolvasható kurzorok esetében. |
| NincsPárhuzamosIndexLétrehozásNemVállalatiKiadásban | A párhuzamos indexlétrehozás nem támogatott a nem enterprise kiadás esetén. |
| Nincsenek párhuzamos tervek a Desktop vagy az Express kiadásban | A párhuzamos tervek nem támogatottak a Desktop és az Express kiadás esetében. |
| Nem párhuzamosítható belső függvény | A lekérdezés nem párhuzamos belső függvényre hivatkozik. |
| A felhasználó által definiált CLR függvény adathozzáférést igényel | A párhuzamosság nem támogatott olyan CLR UDF-hez, amely adathozzáférést igényel. |
| TSQLFelhasznaloAltalMeghatarozottFunkciokNemParalelizalhatok | A lekérdezés olyan T-SQL felhasználó által definiált függvényre hivatkozik, amely nem párhuzamosítható. |
| TáblázatVáltozóTranzakciókNemTámogatjákPárhuzamosBefoglaltTranzakció | A táblaváltozós tranzakciók nem támogatják a párhuzamos beágyazott tranzakciókat. |
| A DML lekérdezés kimenetet ad vissza a kliensnek | A DML-lekérdezés kimenetet ad vissza az ügyfélnek, és nem párhuzamosítható. |
| Vegyes soros és párhuzamos online indexkészítés nem támogatott | A soros és párhuzamos tervek nem támogatott keveréke egyetlen online index építéshez. |
| Nem sikerült érvényes párhuzamos tervet generálni | A párhuzamos terv ellenőrzése sikertelen volt, és nem sikerült visszakerülni a sorosra. |
| Nincs párhuzamos a memóriaoptimalizált táblákhoz | A párhuzamosság nem támogatott a hivatkozott In-Memory OLTP-táblák esetében. |
| Nincs párhuzamos DML memóriára optimalizált táblán | A párhuzamosság nem támogatott az In-Memory OLTP-táblák DML-hez. |
| Nincs párhuzamos a natívan fordított modulhoz | A párhuzamos feldolgozás nem támogatott a natívan lefordított hivatkozott modulok esetében. |
| NincsTartományokFolyamatosLétrehozás | A tartomány generálása nem sikerült a folytatható létrehozási művelethez. |
Az exchange operátorok beillesztése után az eredmény egy párhuzamos lekérdezések végrehajtási terve. A párhuzamos lekérdezések végrehajtási terve több munkaszálat is használhat. A nem párhuzamos (soros) lekérdezések által használt sorozatvégrehajtási terv csak egy munkavégző szálat használ a végrehajtáshoz. A párhuzamos lekérdezések által használt munkaszálak tényleges számát a lekérdezésterv végrehajtási inicializálása határozza meg, és a terv összetettsége és a párhuzamosság foka határozza meg.
A párhuzamosság foka (DOP) határozza meg a használt processzorok maximális számát; ez nem jelenti a használt munkaszálak számát. A DOP-korlát tevékenységenként van beállítva. Ez nem kérésenként vagy lekérdezési korlátonként. Ez azt jelenti, hogy egy párhuzamos lekérdezés végrehajtása során egyetlen kérelem több feladatot is létrehozhat, amelyek egy ütemezőhöz vannak rendelve. A MAXDOP által megadottnál több processzor használható egyidejűleg a lekérdezés végrehajtásának bármely pontján, amikor a különböző feladatok egyidejűleg lesznek végrehajtva. További információ: szál- és feladatarchitektúra-útmutató.
Az SQL Server Lekérdezésoptimalizáló nem használ párhuzamos végrehajtási tervet egy lekérdezéshez, ha az alábbi feltételek bármelyike teljesül:
- A soros végrehajtási terv triviális, vagy nem lépi túl a párhuzamossági beállítás költségküszöbét.
- A soros végrehajtási terv teljes becsült alstruktúra költsége alacsonyabb, mint bármely, az optimalizáló által feltárt párhuzamos végrehajtási tervé.
- A lekérdezés skaláris vagy relációs operátorokat tartalmaz, amelyek nem futtathatók párhuzamosan. Bizonyos operátorok okozhatják, hogy a lekérdezési terv egy része soros módban fusson, vagy akár az egész terv soros módban fusson.
Megjegyzés:
Egy párhuzamos terv becsült részösszegköltsége alacsonyabb lehet, mint a párhuzamossági beállítás költségküszöbe. Ez azt jelzi, hogy a sorozatterv becsült részösszegköltsége túllépte azt, és a lekérdezési terv az alacsonyabb becsült részösszegköltséggel lett kiválasztva.
A párhuzamossági fok (DOP)
Az SQL Server automatikusan észleli a párhuzamos lekérdezések végrehajtásának vagy az index adatdefiníciós nyelvének (DDL) minden egyes példányához a legjobb párhuzamosságot. Ezt a következő feltételek alapján végzi el:
Függetlenül attól, hogy az SQL Server egynél több mikroprocesszort vagy processzort tartalmazó számítógépen fut-e, például szimmetrikus többprocesszoros számítógépen (SMP). Csak az egynél több processzort használó számítógépek használhatnak párhuzamos lekérdezéseket.
Elegendő munkaszálak állnak-e rendelkezésre? Minden lekérdezési vagy indexelési művelethez bizonyos számú feldolgozószálat kell végrehajtani. A párhuzamos terv végrehajtásához több munkaszálra van szükség, mint egy soros tervre, és a szükséges munkaszálak száma a párhuzamosság mértékével nő. Ha a párhuzamos terv munkaszálra vonatkozó követelménye egy bizonyos fokú párhuzamosság esetén nem teljesíthető, az SQL Server adatbázismotorja automatikusan csökkenti a párhuzamosság mértékét, vagy teljesen megszakítja a párhuzamos tervet a megadott számítási feladatkörnyezetben. Ezután végrehajtja a soros tervet (egy feldolgozói szál).
A végrehajtott lekérdezés- vagy indexművelet típusa. Az indexet létrehozó vagy újraépítendő indexműveletek, illetve a fürtözött indexek elvetése és a cpu-ciklusokat erősen használó lekérdezések a legjobb jelöltek a párhuzamos tervhez. Például a nagy táblák egyesítése, a nagy aggregációk és a nagy eredményhalmazok rendezése ideális jelöltek. A tranzakciófeldolgozó alkalmazásokban gyakran előforduló egyszerű lekérdezések azt találják, hogy a lekérdezés párhuzamos végrehajtásához szükséges további koordináció több, mint az elérhető teljesítményjavulás. A párhuzamosság előnyeit élvező és a nem előnyös lekérdezések megkülönböztetéséhez az SQL Server adatbázismotor összehasonlítja a lekérdezés vagy indexelési művelet végrehajtásának becsült költségét a párhuzamossági érték költségküszöbével . A felhasználók módosíthatják az alapértelmezett 5 értéket az sp_configure használatával, ha a megfelelő tesztelés szerint egy másik érték jobban megfelel a futó számítási feladatnak.
Hogy elegendő számú sort kell-e feldolgozni. Ha a Lekérdezésoptimalizáló megállapítja, hogy a sorok száma túl alacsony, nem vezet be exchange operátorokat a sorok elosztásához. Így az operátorok végrehajtása soronként történik. Az operátorok soros tervben való végrehajtása elkerüli azokat a forgatókönyveket, amikor az indítási, terjesztési és koordinációs költségek meghaladják a párhuzamos operátor-végrehajtás által elért nyereséget.
Az aktuális terjesztési statisztikák rendelkezésre állnak-e. Ha a párhuzamosság legmagasabb foka nem lehetséges, a párhuzamos terv elhagyása előtt alacsonyabb fokokat is figyelembe kell venni. Ha például klaszteres indexet hoz létre egy nézeten, a terjesztési statisztikák nem értékelhetők ki, mert a klaszteres index még nem létezik. Ebben az esetben az SQL Server adatbázismotorja nem tudja a legmagasabb fokú párhuzamosságot biztosítani az indexművelethez. Egyes operátorok, például a rendezés és a vizsgálat azonban továbbra is kihasználhatják a párhuzamos végrehajtás előnyeit.
Megjegyzés:
A párhuzamos indexműveletek csak az SQL Server Enterprise, Developer és Evaluation kiadásokban érhetők el.
A végrehajtás során az SQL Server adatbázismotorja határozza meg, hogy a rendszer jelenlegi számítási feladatai és a korábban ismertetett konfigurációs információk lehetővé teszik-e a párhuzamos végrehajtást. Ha a párhuzamos végrehajtás indokolt, az SQL Server adatbázismotorja határozza meg a feldolgozói szálak optimális számát, és elterjeszti a párhuzamos terv végrehajtását ezeken a munkaszálakon. Ha egy lekérdezési vagy indexelési művelet több feldolgozószálon kezdi meg a párhuzamos végrehajtást, a művelet befejezéséig ugyanazt a számú munkaszálat használja a rendszer. Az SQL Server adatbázismotorja minden végrehajtási terv lekérésekor újra megvizsgálja a munkaszál-döntések optimális számát a terv gyorsítótárából. Egy lekérdezés egy végrehajtása például egy soros terv használatát eredményezheti, ugyanazon lekérdezés későbbi végrehajtása pedig egy párhuzamos tervet eredményezhet három feldolgozószál használatával, a harmadik végrehajtás pedig négy munkavégzőszálat használó párhuzamos tervet eredményezhet.
A párhuzamos lekérdezésvégrehajtási terv frissítési és törlési operátorait a rendszer sorosan hajtja végre, de egy WHEREUPDATE utasítás vagy DELETE utasítás záradéka párhuzamosan is végrehajtható. A tényleges adatváltozások ezután sorozatosan lesznek alkalmazva az adatbázisra.
Az SQL Server 2012-ig (11.x) a beszúrási operátor is sorosan lesz végrehajtva. Az INSERT utasítás SELECT része azonban párhuzamosan végrehajtható. A tényleges adatváltozások ezután sorozatosan lesznek alkalmazva az adatbázisra.
Az SQL Server 2014 -től (12.x) és az adatbázis-kompatibilitás 110-es szintjétől kezdve az SELECT ... INTO utasítás párhuzamosan is végrehajtható. Az egyéb beszúró operátorok ugyanolyan módon működnek, mint az SQL Server 2012 (11.x).
Az SQL Server 2016 (13.x) és az adatbázis-kompatibilitási szint 130-tól kezdve az INSERT ... SELECT utasítás párhuzamosan is végrehajtható a heap-ek vagy fürtözött oszlopcentrikus indexekbe (CCI) való beszúrást végezve, a TABLOCK utasítás használatával. A helyi ideiglenes táblákba (a #előtag által azonosított) és a globális ideiglenes táblákba (## előtagok által azonosított) beszúrások a TABLOCK-tipp használatával is engedélyezve vannak a párhuzamossághoz. További információ: INSERT (Transact-SQL).
A statikus és a kulcskészlet-vezérelt kurzorok párhuzamos végrehajtási tervekkel tölthetők fel. A dinamikus kurzorok viselkedését azonban csak soros végrehajtással lehet biztosítani. A Lekérdezésoptimalizáló mindig létrehoz egy sorozatvégrehajtási tervet egy dinamikus kurzor részét képező lekérdezéshez.
A párhuzamossági fok felülbírálása
A párhuzamosság mértéke beállítja a párhuzamos terv végrehajtásához használni kívánt processzorok számát. Ez a konfiguráció különböző szinteken állítható be:
Kiszolgálószint, a maximális párhuzamossági (MAXDOP)kiszolgálókonfigurációs beállítás használatával.
A következőkre vonatkozik: SQL ServerMegjegyzés:
Az SQL Server 2019 (15.x) automatikus javaslatokat vezet be a MAXDOP-kiszolgáló konfigurációs beállításának beállításához a telepítési folyamat során. A beállítási felhasználói felületen elfogadhatja az ajánlott beállításokat, vagy saját értéket adhat meg. További információ: Adatbázismotor konfigurációja – MaxDOP oldal.
Számítási feladatok szintje a MAX_DOPResource Governor számítási feladatcsoport konfigurációs beállításával.
A következőkre vonatkozik: SQL ServerAdatbázisszint a MAXDOP-adatbázishatókörű konfigurációjának használatával.
A következőkre vonatkozik: SQL Server és Azure SQL DatabaseLekérdezési vagy indexelési utasítás szintje a MAXDOPlekérdezési tipp vagy a MAXDOP index beállítás használatával. A MAXDOP beállítással például az online indexelési művelethez dedikált processzorok számának növelésével vagy csökkentésével szabályozható. Ily módon kiegyensúlyozhatja az indexművelet által használt erőforrásokat az egyidejű felhasználókéval.
A következőkre vonatkozik: SQL Server és Azure SQL Database
A párhuzamosság maximális fokának beállítása 0 -ra (alapértelmezett) lehetővé teszi, hogy az SQL Server az összes elérhető processzort legfeljebb 64 processzort használjon egy párhuzamos terv végrehajtásában. Bár az SQL Server 64 logikai processzor futásidejű célértéket állít be, ha a MAXDOP beállítás értéke 0, szükség esetén manuálisan is megadható egy másik érték. A MAXDOP 0 értékre állítása lekérdezésekhez és indexekhez lehetővé teszi, hogy az SQL Server az összes rendelkezésre álló processzort legfeljebb 64 processzort használjon az adott lekérdezésekhez vagy indexekhez egy párhuzamos terv végrehajtása során. A MAXDOP nem az összes párhuzamos lekérdezés kényszerített értéke, hanem a párhuzamosságra jogosult összes lekérdezés feltételes célja. Ez azt jelenti, hogy ha futásidőben nem áll rendelkezésre elegendő feldolgozószál, előfordulhat, hogy a lekérdezések a MAXDOP-kiszolgáló konfigurációs beállításánál alacsonyabb fokú párhuzamossággal futnak.
Jótanács
További információ: MAXDOP-javaslatok a MAXDOP kiszolgálói, adatbázis-, lekérdezés- vagy tippszintű konfigurálásával kapcsolatos irányelvekhez.
Párhuzamos lekérdezési példa
Az alábbi lekérdezés egy adott negyedévben leadott rendelések számát számítja ki 2000. április 1-jén kezdődően, és amelyben a rendelés legalább egy soreleme a véglegesített dátumnál később érkezett meg az ügyfélhez. Ez a lekérdezés felsorolja az ilyen rendelések számát az egyes rendelési prioritások szerint csoportosítva és növekvő prioritási sorrendben rendezve.
Ez a példa elméleti tábla- és oszlopneveket használ.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Tegyük fel, hogy a következő indexek vannak definiálva a lineitemorders táblákon:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Íme egy lehetséges párhuzamos terv, amely a korábban megjelenített lekérdezéshez jön létre:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
Az alábbi ábrán egy olyan lekérdezésterv látható, amely 4-es szintű párhuzamossággal és kéttáblás illesztéssel van végrehajtva.
A párhuzamos terv három párhuzamossági operátort tartalmaz. Az o_datkey_ptr index Indexkeresés operátora és a l_order_dates_idx index Indexvizsgálat operátora is párhuzamosan történik. Ez számos exkluzív streamet eredményez. Ezt az indexelési vizsgálat és indexkeresési operátorok feletti legközelebbi párhuzamossági operátorokból lehet meghatározni. Mindkettő a csere típusának újraparticionálását végzi. Vagyis csak átküldik az adatokat a streamek között, és ugyanannyi streamet termelnek a kimenetükön, mint a bemenetükön. Ez a streamek száma megegyezik a párhuzamosság mértékével.
Az Index-vizsgálat operátor fölötti l_order_dates_idx párhuzamossági operátor újraparticionálást végez a bemeneti adatfolyamokon a kulcs értéke L_ORDERKEY alapján. Így ugyanazok az értékek L_ORDERKEY ugyanabban a kimeneti adatfolyamban lesznek. Ugyanakkor a kimeneti streamek megtartják az oszlop sorrendjét a L_ORDERKEY helyen, hogy megfeleljenek a Merge Join operátor bemeneti követelményének.
Az Indexkeresés operátor fölötti párhuzamossági operátor a bemeneti adatfolyamokat a O_ORDERKEY érték alapján újraparticionálja. Mivel a bemenete nincs rendezve az O_ORDERKEY oszlopértékeken, és ez az Merge Join operátor illesztési oszlopa, a párhuzamos feldolgozás és az Egyesítési illesztés operátorai közötti Rendezés operátor gondoskodik arról, hogy a bemenet az illesztési oszlopok szerint az Merge Join operátor számára rendezve legyen. Az Sort operátor, mint a Merge Join operátor, párhuzamosan történik.
A legfelső párhuzamossági operátor több stream eredményeit gyűjti egyetlen streambe. A párhuzamossági operátor alatti Stream Aggregate operátor által végrehajtott részleges aggregációk ezután egyetlen SUM értékben kerülnek felhalmozásra a Stream Aggregate operátorban minden egyes különböző O_ORDERPRIORITY értékre a párhuzamossági operátor fölött. Mivel ennek a tervnek két csere szegmense van, és a párhuzamosság mértéke 4, nyolc munkaszálat használ.
A példában használt operátorokról további információt a Showplan Logikai és Fizikai operátorok hivatkozásában talál.
Párhuzamos indexműveletek
Az indexet létrehozó vagy újraépítő indexműveletekhez készült lekérdezési tervek, illetve a fürtözött index elvetése lehetővé teszik a párhuzamos, több feldolgozós szálas műveleteket a több mikroprocesszort tartalmazó számítógépeken.
Megjegyzés:
A párhuzamos indexműveletek csak az Enterprise Editionben érhetők el, kezdve az SQL Server 2008-tól (10.0.x).
Az SQL Server ugyanazokat az algoritmusokat használja a párhuzamosság mértékének (a futtatandó különálló feldolgozószálak teljes számának) meghatározásához az indexműveletek esetében, mint más lekérdezéseknél. Az indexműveletekben a párhuzamosság maximális foka a párhuzamosság kiszolgálójának konfigurációs beállításától függ. Az egyes indexműveletek maximális párhuzamossági értékét felülbírálhatja a MAXDOP index beállítás beállításával az INDEX LÉTREHOZÁSA, az ALTER INDEX, a DROP INDEX és az ALTER TABLE utasításokban.
Amikor az SQL Server adatbázismotor létrehoz egy index-végrehajtási tervet, a párhuzamos műveletek száma a legalacsonyabb értékre van állítva az alábbiak közül:
- A mikroprocesszorok vagy processzorok száma a számítógépen.
- A párhuzamossági kiszolgáló konfigurációs beállításának maximális fokában megadott szám.
- Az SQL Server-feldolgozószálak esetében még nem teljesített munka küszöbértéke feletti processzorok száma.
Például egy nyolc PROCESSZORt tartalmazó számítógépen, ahol azonban a párhuzamosság maximális foka 6, egy indexművelethez nem jön létre hatnál több párhuzamos feldolgozószál. Ha a számítógép öt processzora túllépi az SQL Server-munka küszöbértékét egy index-végrehajtási terv létrehozásakor, a végrehajtási terv csak három párhuzamos munkaszálat határoz meg.
A párhuzamos indexművelet fő fázisai a következők:
- A koordináló feldolgozói szál gyorsan és véletlenszerűen megvizsgálja a táblát az indexkulcsok eloszlásának becsléséhez. A koordináló munkaszál meghatározza azokat a kulcshatárokat, amelyek a párhuzamos műveletek mértékével megegyező számú kulcstartományt hoznak létre, ahol az egyes kulcstartományok a becslések szerint hasonló számú sort fednek le. Ha például négymillió sor van a táblában, és a párhuzamosság mértéke 4, akkor a koordináló munkaszál határozza meg azokat a fő értékeket, amelyek négy sorhalmazt és 1 millió sort különítenek el mindegyik halmazban. Ha nem hozható létre elegendő kulcstartomány az összes PROCESSZOR használatához, a párhuzamosság mértéke ennek megfelelően csökken.
- A koordináló munkaszál több munkaszálat küld, amely egyenlő a párhuzamos műveletek mértékével, és megvárja, amíg ezek a munkaszálak befejezik a munkájukat. Minden munkaszál egy szűrővel ellenőrzi az alaptáblát, amely csak a munkaszálhoz rendelt tartományon belüli kulcsértékekkel rendelkező sorokat kéri le. Minden munkaszál létrehoz egy indexstruktúrát a kulcstartományában lévő sorokhoz. Particionált indexek esetén minden feldolgozói szál meghatározott számú partíciót hoz létre. A partíciók nincsenek megosztva a feldolgozói szálak között.
- Miután az összes párhuzamos munkaszál befejeződött, a koordináló munkaszál egyetlen indexbe köti az indexalegységeket. Ez a fázis csak offline indexműveletekre vonatkozik.
Az egyes CREATE TABLE vagy ALTER TABLE utasítások több korlátozást is tartalmazhatnak, amelyek index létrehozását igénylik. Ezeket a több indexlétrehozási műveletet sorozatokban hajtja végre, bár minden egyes indexlétrehozási művelet párhuzamos művelet lehet egy olyan számítógépen, amelyen több PROCESSZOR található.
Elosztott lekérdezési architektúra
A Microsoft SQL Server két módszert támogat a heterogén OLE DB-adatforrások Transact-SQL utasításokban való hivatkozására:
Csatolt kiszolgálónevek
Rendszer tárolt eljárásoksp_addlinkedserveréssp_addlinkedsrvloginszolgálják az OLE DB-adatforrás szervernevének megadását. A csatolt kiszolgálók objektumaira Transact-SQL utasításokban hivatkozhat négyrészes nevek használatával. Ha például egy csatolt kiszolgáló neveDeptSQLSrvraz SQL Server egy másik példányán van definiálva, az alábbi utasítás hivatkozik egy táblára az adott kiszolgálón:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;A csatolt kiszolgáló neve is megadható egy
OPENQUERYutasításban az OLE DB adatforrásból származó sorkészlet megnyitásához. Ez a sorkészlet aztán hivatkozható táblázatként Transact-SQL utasításokban.Alkalmi összekötők nevei
Ha ritkán hivatkozunk egy adatforrásra, aOPENROWSETvagyOPENDATASOURCEfüggvényeket azzal az információval kell megadni, amely szükséges a csatolt kiszolgálóhoz való kapcsolódáshoz. A sorhalmazra ezután ugyanúgy hivatkozhat, mint egy táblára Transact-SQL utasításokban:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
Az SQL Server OLE DB-t használ a relációs motor és a tárolómotor közötti kommunikációhoz. A relációs motor az egyes Transact-SQL utasításokat műveletek sorozatára bontja a tárolómotor által az alaptáblákból megnyitott egyszerű OLE DB-sorokon. Ez azt jelenti, hogy a relációs motor bármilyen OLE DB-adatforráson megnyithat egyszerű OLE DB-sorkészleteket.
A relációs motor az OLE DB alkalmazásprogramozási felületével (API) nyitja meg a sorhalmazokat a csatolt kiszolgálókon, lekéri a sorokat, és kezeli a tranzakciókat.
A csatolt kiszolgálóként elért OLE DB-adatforrások esetében egy OLE DB-szolgáltatónak jelen kell lennie az SQL Servert futtató kiszolgálón. Az adott OLE DB-adatforráson használható Transact-SQL műveletek halmaza az OLE DB-szolgáltató képességeitől függ.
Az SQL Server minden példánya esetében a sysadmin rögzített kiszolgálói szerepkör tagjai engedélyezhetik vagy letilthatják az OLE DB-szolgáltató alkalmi összekötőneveinek használatát az SQL Server DisallowAdhocAccess tulajdonság használatával. Ha engedélyezve van az alkalmi hozzáférés, az adott példányba bejelentkezett felhasználók Transact-SQL alkalmi összekötőneveket tartalmazó utasításokat hajthatnak végre, hivatkozva a hálózaton található olyan adatforrásokra, amelyek az OLE DB-szolgáltatóval érhetők el. Az adatforrásokhoz való hozzáférés szabályozásához a szerepkör tagjai letilthatják az sysadmin adott OLE DB-szolgáltató alkalmi hozzáférését, ezáltal a felhasználókat csak a rendszergazdák által meghatározott társított kiszolgálónevek által hivatkozott adatforrásokra korlátozhatják. Alapértelmezés szerint az alkalmi hozzáférés engedélyezve van az SQL Server OLE DB-szolgáltatóhoz, és minden más OLE DB-szolgáltató esetében le van tiltva.
Az elosztott lekérdezések lehetővé teszik, hogy a felhasználók egy másik adatforráshoz (például fájlokhoz, nem relációs adatforrásokhoz, például Active Directoryhoz stb.) férhessenek hozzá annak a Microsoft Windows-fióknak a biztonsági környezetével, amelyen az SQL Server szolgáltatás fut. Az SQL Server megfelelően megszemélyesíti a bejelentkezést a Windows-bejelentkezésekhez; ez azonban az SQL Server-bejelentkezések esetében nem lehetséges. Ez lehetővé teheti az elosztott lekérdezési felhasználók számára, hogy hozzáférjenek egy másik adatforráshoz, amelyhez nem rendelkeznek engedélyekkel, de az SQL Server-szolgáltatás által futtatott fiók rendelkezik engedélyekkel. A sp_addlinkedsrvlogin használatával határozza meg azokat a konkrét bejelentkezéseket, amelyek jogosultak a kapcsolt kiszolgáló elérésére. Ez a vezérlő nem érhető el alkalmi nevekhez, ezért körültekintően engedélyezze az OLE DB-szolgáltatót az alkalmi hozzáféréshez.
Ha lehetséges, az SQL Server leküldi a relációs műveleteket, például illesztéseket, korlátozásokat, előrejelzéseket, rendezéseket és csoportosítási műveleteket az OLE DB-adatforrásba. Az SQL Server alapértelmezés szerint nem ellenőrzi az alaptáblát az SQL Serveren, és maga hajtja végre a relációs műveleteket. Az SQL Server lekérdezi az OLE DB-szolgáltatót, hogy meghatározza az általa támogatott SQL-nyelvhelyesség szintjét, és ezen információk alapján a lehető legtöbb relációs műveletet küldi el a szolgáltatónak.
Az SQL Server egy mechanizmust ad meg az OLE DB-szolgáltató számára, amely statisztikai adatokat ad vissza, amelyek jelzik, hogyan oszlanak el a kulcsértékek az OLE DB-adatforrásban. Ez lehetővé teszi, hogy az SQL Server Lekérdezésoptimalizáló jobban elemezze az adatforrásban lévő adatok mintáját az egyes Transact-SQL utasítások követelményeinek megfelelően, növelve a lekérdezésoptimalizáló képességét az optimális végrehajtási tervek létrehozására.
A particionált táblák és indexek lekérdezésfeldolgozási fejlesztései
Az SQL Server 2008 (10.0.x) továbbfejlesztett lekérdezésfeldolgozási teljesítményt nyújt a particionált táblákon számos párhuzamos terv esetében, megváltoztatja a párhuzamos és a soros tervek ábrázolásának módját, valamint bővítette a fordítási és futásidejű végrehajtási tervekben biztosított particionálási információkat. Ez a cikk ismerteti ezeket a fejlesztéseket, útmutatást nyújt a particionált táblák és indexek lekérdezés-végrehajtási terveinek értelmezéséhez, valamint ajánlott eljárásokat biztosít a particionált objektumok lekérdezési teljesítményének javításához.
Megjegyzés:
Az SQL Server 2014 (12.x) kiadásig a particionált táblák és indexek csak az SQL Server Enterprise, Developer és Evaluation kiadásaiban támogatottak. Az SQL Server 2016 (13.x) SP1-től kezdve a particionált táblák és indexek is támogatottak az SQL Server Standard kiadásban.
Új partícióérzékeny keresési művelet
Az SQL Serverben a particionált táblák belső ábrázolása megváltozik, így a tábla többoszlopos indexként PartitionID jelenik meg a lekérdezésfeldolgozóban, vezető oszlopként.
PartitionID egy rejtett számított oszlop, amely belsőleg egy adott sort tartalmazó partíciót jelöl ID . Tegyük fel például, hogy a T tábla az T(a, b, c)a oszlopban particionálva van, és a b oszlopban fürtözött index van. Az SQL Serverben ezt a particionált táblát a rendszer belsőleg nem particionált táblaként kezeli a sémával T(PartitionID, a, b, c) és az összetett kulcs (PartitionID, b)fürtözött indexével. Ez lehetővé teszi, hogy a Lekérdezésoptimalizáló bármilyen particionált tábla vagy index alapján PartitionID végezzen keresési műveleteket.
A partíciók kizárása most ebben a keresési műveletben történik.
Emellett a Lekérdezésoptimalizáló ki van bővítve, hogy egy keresési vagy vizsgálati művelet egy feltétellel elvégezhető legyen (logikai kezdőoszlopként) és esetleg más indexkulcsoszlopokon PartitionID , majd egy másik feltétellel rendelkező második szintű keresés egy vagy több további oszlopon is elvégezhető minden olyan különálló érték esetében, amely megfelel az első szintű keresési művelet minősítésének. Ez a kihagyási vizsgálatnak nevezett művelet lehetővé teszi, hogy a Lekérdezésoptimalizáló egy feltételen alapuló keresési vagy vizsgálati műveletet hajtson végre a elérni kívánt partíciók meghatározásához, valamint egy második szintű indexkeresési műveletet az operátoron belül, amely egy másik feltételnek megfelelő sorokat ad vissza ezekből a partíciókból. Vegyük például a következő lekérdezést.
SELECT * FROM T WHERE a < 10 and b = 2;
Ebben a példában tegyük fel, hogy a T tábla az T(a, b, c)a oszlopban van particionálva, és a b oszlopban fürtözött index van. A T tábla partícióhatárát a következő partíciófüggvény határozza meg:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
A lekérdezés megoldásához a lekérdezésfeldolgozó első szintű keresési műveletet hajt végre, hogy megkeresse a feltételnek T.a < 10megfelelő sorokat tartalmazó összes partíciót. Ez azonosítja a elérni kívánt partíciókat. Minden azonosított partíción belül a processzor egy második szintű kereséssel keresi meg a b oszlop fürtözött indexét, hogy megkeresse a feltételnek T.b = 2 megfelelő sorokat és T.a < 10.
Az alábbi ábra a kihagyásos beolvasási művelet logikai ábrázolása. A(z) T táblázatot mutatja, ahol az adatok a a és b oszlopokban találhatók. A partíciók száma 1–4, a partíció határai szaggatott függőleges vonalakkal jelennek meg. A partíciók első szintű keresési művelete (az ábrán nem látható) megállapította, hogy az 1., a 2. és a 3. partíció megfelel a táblához definiált particionálás és az oszlop apredikátuma által sugallt keresési feltételnek. Vagyis T.a < 10. A kihagyásos vizsgálati művelet második szintű keresési szakasza által bejárt útvonalat a görbe vonal szemlélteti. A kihagyásos átvizsgálási művelet lényegében minden partícióban keresi a b = 2 feltételnek megfelelő sorokat. A kihagyási keresés teljes költsége megegyezik három különálló indexkeresés költségével.
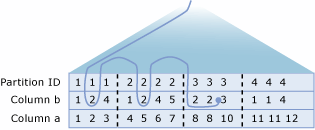
Particionálási információk megjelenítése a lekérdezés-végrehajtási tervekben
A particionált táblákon és indexeken lévő lekérdezések végrehajtási tervei a Transact-SQL SET utasítások SET SHOWPLAN_XMLSET STATISTICS XMLvagy az SQL Server Management Studio grafikus végrehajtási tervének kimenetével vizsgálhatók meg. A fordítási idő végrehajtási tervének megjelenítéséhez például válassza a Becsült végrehajtási terv megjelenítése a Lekérdezésszerkesztő eszköztárán és a futásidejű terv kiválasztásával a Tényleges végrehajtási terv belefoglalása lehetőséget.
Az alábbi eszközökkel a következő információkat állapíthatja meg:
- Az olyan műveletek, mint
scans,seeks,inserts,updates,mergesésdeletes, amelyek particionált táblákhoz vagy indexekhez férnek hozzá. - A lekérdezés által elért partíciók. A elért partíciók teljes száma és az egybefüggő partíciók tartományai például futásidejű végrehajtási tervekben érhetők el.
- Ha a vizsgálat kihagyási művelete egy keresési vagy vizsgálati műveletben egy vagy több partíció adatainak lekérésére szolgál.
Partícióinformációk fejlesztései
Az SQL Server továbbfejlesztett particionálási információkat biztosít a fordítási és futásidejű végrehajtási tervekhez. A végrehajtási tervek most a következő információkat adják meg:
- Nem kötelező
Partitionedattribútum, amely azt jelzi, hogy egy operátor, például egyseek,scan,insert,update,mergevagydelete, egy particionált táblán van végrehajtva. - Új
SeekPredicateNewelem egySeekKeysalelemmel, amely a vezető index kulcsoszlopként aPartitionID-t tartalmazza, és olyan szűrési feltételeket határoz meg, amelyek tartománykereséseket végeznek aPartitionIDsegítségével. KétSeekKeysalelem jelenléte azt jelzi, hogyPartitionIDkihagyásos vizsgálati műveletet használnak. - Összegző információk, amelyek az elért partíciók teljes számát megadják. Ez az információ csak futásidejű tervekben érhető el.
Annak bemutatásához, hogy ezek az információk hogyan jelennek meg mind a grafikus végrehajtási terv kimenetében, mind az XML Showplan kimenetében, vegye figyelembe a particionált tábla fact_saleskövetkező lekérdezését. Az adatokat két partíción frissíti ez a lekérdezés.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
Az alábbi ábrán az Clustered Index Seek operátor tulajdonságai láthatók a lekérdezés futtatókörnyezeti végrehajtási tervében. A tábla definíciójának és a fact_sales partíciódefiníciónak a megtekintéséhez tekintse meg a jelen cikkben található "Példa" című témakört.

Particionált attribútum
Ha egy operátort, például egy indexkeresést egy particionált táblán vagy indexen hajtanak végre, az Partitioned attribútum megjelenik a fordítási idő és a futási idő tervében, és az (1) értékre True van állítva. Az attribútum nem jelenik meg, ha (0) értékre False van állítva.
Az Partitioned attribútum a következő fizikai és logikai operátorokban jelenhet meg:
- Táblavizsgálat
- Indexvizsgálat
- Indexkeresés
- Beilleszt
- Frissítés
- Törlés
- Egyesítés
Az előző ábrán látható módon ez az attribútum annak az operátornak a tulajdonságaiban jelenik meg, amelyben definiálva van. Az XML Showplan kimenetében ez az attribútum úgy jelenik meg, mint Partitioned="1" annak az operátornak a RelOp csomópontjában, amelyben definiálva van.
Új keresési predikátum
Az XML Showplan kimenetében az SeekPredicateNew elem abban az operátorban jelenik meg, amelyben definiálva van. A SeekKeys al-eleme legfeljebb két előfordulást tartalmazhat. Az első SeekKeys elem a logikai index partícióazonosító szintjén adja meg az első szintű keresési műveletet. Ez a lekérdezés határozza meg azokat a partíciókat, amelyekhez hozzá kell férni a lekérdezés feltételeinek teljesítéséhez. A második SeekKeys elem a kihagyási vizsgálat művelet második szintű keresési részét adja meg, amely az első szintű keresésben azonosított partíciókon belül történik.
Partícióösszegzési információk
A futásidejű végrehajtási tervekben a partícióösszegzési információk a elért partíciók számát és a ténylegesen elért partíciók identitását biztosítják. Ezekkel az információkkal ellenőrizheti, hogy a megfelelő partíciók elérhetők-e a lekérdezésben, és hogy az összes többi partíció nincs-e figyelembe véve.
A rendszer a következő információkat adja meg: Actual Partition Countés Partitions Accessed.
Actual Partition Count A lekérdezés által elért partíciók teljes száma.
Partitions Accessedaz XML Showplan kimenetében a partícióösszegzési információ jelenik meg annak az operátornak az új RuntimePartitionSummary elemében RelOp , amelyben az operátor definiálva van. Az alábbi példa az RuntimePartitionSummary elem tartalmát mutatja be, amely azt jelzi, hogy két teljes partíció érhető el (2. és 3. partíció).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Partícióadatok megjelenítése más Showplan-metódusokkal
A Showplan metódusok SHOWPLAN_ALL, SHOWPLAN_TEXTés STATISTICS PROFILE nem jelentik a cikkben leírt partícióadatokat az alábbi kivétellel. A predikátum részeként a SEEK elérendő partíciókat a partícióazonosítót reprezentáló számított oszlop tartomány predikátuma azonosítja. Az alábbi példa egy SEEKClustered Index Seek operátor predikátumát mutatja be. A 2. és a 3. partíció elérhető, a keresési operátor pedig a feltételnek date_id BETWEEN 20080802 AND 20080902megfelelő sorokra szűr.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Particionált halom végrehajtási terveinek értelmezése
A particionált halom logikai indexként van kezelve a partícióazonosítón. A partíció megszüntetése egy particionált halomban a végrehajtási tervben Table Scan operátorként jelenik meg, amely a partícióazonosítón SEEK predikátummal rendelkezik. Az alábbi példa a Showplan megadott adatait mutatja be:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Az csoportosított illesztések végrehajtási terveinek értelmezése
Illesztési rendezés akkor fordulhat elő, ha két tábla particionálása ugyanazzal a vagy azzal egyenértékű particionálási függvénnyel történik, és az illesztés mindkét oldalának particionálási oszlopai a lekérdezés illesztési feltételében vannak megadva. A Lekérdezésoptimalizáló létrehozhat egy tervet, amelyben az egyenlő partícióazonosítóval rendelkező táblák partíciói külön csatlakoznak egymáshoz. Az csoportosított illesztések gyorsabbak lehetnek, mint a nem csoportosított illesztések, mivel kevesebb memóriát és feldolgozási időt igényelhetnek. A Lekérdezésoptimalizáló a költségbecslések alapján nem csoportosított vagy csoportosított tervet választ.
Egy csoportosított tervben az Nested Loops illesztés egy vagy több összekapcsolt tábla- vagy indexpartíciót olvas be a belső oldalról. Az operátorok számai a Constant Scan partíciószámokat jelölik.
Ha particionált táblákhoz vagy indexekhez párhuzamos tervek jönnek létre az csoportosított illesztésekhez, a párhuzamosság operátora jelenik meg az Constant ScanNested Loops illesztés operátorai között. Ebben az esetben az illesztés külső oldalán több feldolgozószál mindegyike más-más partíciót olvas és dolgozik fel.
Az alábbi ábra egy csoportosított illesztés párhuzamos lekérdezési tervét mutatja be.
Párhuzamos lekérdezésvégrehajtási stratégia particionált objektumokhoz
A lekérdezésfeldolgozó párhuzamos végrehajtási stratégiát használ a particionált objektumokból kiválasztott lekérdezésekhez. A végrehajtási stratégia részeként a lekérdezésfeldolgozó határozza meg a lekérdezéshez szükséges táblapartíciókat, valamint az egyes partíciókhoz lefoglalandó feldolgozói szálak arányát. A lekérdezésfeldolgozó a legtöbb esetben egyenlő vagy majdnem azonos számú feldolgozószálat foglal le az egyes partíciókhoz, majd párhuzamosan hajtja végre a lekérdezést a partíciók között. Az alábbi bekezdések részletesebben ismertetik a munkavégző szálak kiosztását.
Ha a munkavégző szálak száma kisebb, mint a partíciók száma, a lekérdezésfeldolgozó az egyes feldolgozói szálakat egy másik partícióhoz rendeli hozzá, és kezdetben egy vagy több partíciót hagy hozzárendelt munkaszál nélkül. Amikor egy feldolgozószál befejezi a partíción való végrehajtást, a lekérdezésfeldolgozó hozzárendeli azt a következő partícióhoz, amíg az egyes partíciókhoz egyetlen feldolgozószálat nem rendel. Ez az egyetlen eset, amikor a lekérdezésfeldolgozó más partíciókra helyezi át a feldolgozói szálakat.
A munkaszál újbóli hozzárendelését jeleníti meg a befejezés után. Ha a feldolgozószálak száma megegyezik a partíciók számával, a lekérdezésfeldolgozó minden partícióhoz egy feldolgozószálat rendel. Amikor egy feldolgozószál befejeződik, a rendszer nem helyezi át egy másik partícióra.

Ha a feldolgozószálak száma nagyobb, mint a partíciók száma, a lekérdezésfeldolgozó egyenlő számú feldolgozószálat foglal le az egyes partíciókhoz. Ha a munkavégző szálak száma nem a partíciók számának pontos többszöröse, a lekérdezésfeldolgozó egy további feldolgozói szálat rendel néhány partícióhoz az összes rendelkezésre álló munkaszál használatához. Ha csak egy partíció van, az összes feldolgozószál hozzá lesz rendelve ehhez a partícióhoz. Az alábbi ábrán négy partíció és 14 feldolgozószál található. Mindegyik partícióhoz 3 munkaszál van hozzárendelve, és két partícióhoz további feldolgozói szál tartozik, összesen 14 munkaszál-hozzárendeléshez. Amikor egy feldolgozószál befejeződik, a rendszer nem rendeli hozzá másik partícióhoz.

Bár a fenti példák egyszerű módot javasolnak a feldolgozói szálak lefoglalására, a tényleges stratégia összetettebb, és a lekérdezés végrehajtása során előforduló egyéb változókhoz is tartozik. Ha például a tábla particionálva van, és az A oszlopban fürtözött index van, és egy lekérdezés rendelkezik predikátumi záradékkal WHERE A IN (13, 17, 25), a lekérdezésfeldolgozó az egyes táblapartíciók helyett a három keresési érték (A=13, A=17 és A=25) mindegyikéhez lefoglal egy vagy több feldolgozószálat. Csak az ezeket az értékeket tartalmazó partíciókban kell végrehajtani a lekérdezést, és ha a keresési predikátumok mindegyike ugyanabban a táblapartícióban található, az összes feldolgozó szál ugyanahhoz a táblapartícióhoz lesz hozzárendelve.
Tegyük fel, hogy a tábla négy partícióval rendelkezik az A oszlopban határpontokkal (10, 20, 30), a B oszlop indexével, a lekérdezés pedig predikátum záradékkal WHERE B IN (50, 100, 150). Mivel a táblapartíciók az A értékeken alapulnak, a B értékek bármelyik táblapartícióban előfordulhatnak. Így a lekérdezésfeldolgozó a négy táblapartíció mindegyikében a B (50, 100, 150) mindhárom értékét keresi. A lekérdezésfeldolgozó a munkavégző szálakat arányosan rendeli hozzá, hogy párhuzamosan hajthassa végre a 12 lekérdezési vizsgálatot.
| Táblapartíciók az A oszlop alapján | A B oszlopot keresi az egyes táblapartíciókban |
|---|---|
| Táblapartíció 1: A < 10 | B=50, B=100, B=150 |
| 2. táblapartíció: A >= 10 ÉS A < 20 | B=50, B=100, B=150 |
| 3. táblapartíció: A >= 20 és A < 30 | B=50, B=100, B=150 |
| 4. tábla partíció: A >= 30 | B=50, B=100, B=150 |
Ajánlott eljárások
A nagyméretű particionált táblákból és indexekből nagy mennyiségű adatot elérő lekérdezések teljesítményének javítása érdekében az alábbi ajánlott eljárásokat javasoljuk:
- Az egyes partíciók több lemezen való csíkozása. Ez különösen fontos forgólemezek használatakor.
- Ha lehetséges, használjon olyan kiszolgálót, amely elegendő fő memóriával rendelkezik a gyakran használt partíciók vagy a memóriában lévő összes partíció elféréséhez az I/O-költségek csökkentése érdekében.
- Ha a lekérdezés adatai nem férnek el a memóriában, tömörítse a táblákat és az indexeket. Ez csökkenti az I/O-költségeket.
- Használjon olyan kiszolgálót, amely gyors processzorokkal és annyi processzormaggal rendelkezik, amennyit megengedhet magának, hogy kihasználhassa a párhuzamos lekérdezésfeldolgozási képességet.
- Győződjön meg arról, hogy a kiszolgáló rendelkezik elegendő I/O-vezérlő sávszélességével.
- Hozzon létre fürtözött indexet nagy particionált táblákon a B-fa keresési optimalizációk kihasználása érdekében.
- Kövesse az ajánlott eljárásokkal kapcsolatos ajánlásokat az Adatbetöltési teljesítmény útmutató című tanulmányban, amikor az adatok tömeges betöltése particionált táblákba történik.
példa
Az alábbi példa egy hét partícióval rendelkező táblát tartalmazó tesztadatbázist hoz létre. A példában a lekérdezések végrehajtásakor korábban ismertetett eszközökkel megtekintheti a particionálási információkat a fordítási és a futásidejű tervekhez.
Megjegyzés:
Ez a példa több mint 1 millió sort szúr be a táblázatba. A példa futtatása a hardvertől függően több percet is igénybe vehet. A példa végrehajtása előtt győződjön meg arról, hogy több mint 1,5 GB lemezterület áll rendelkezésre.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Kapcsolódó tartalom
- Logikai és fizikai showplan operátor referenciája
- bővített események áttekintése
- Legjobb gyakorlatok a számítási feladatok figyelésére a Lekérdezéstárral
- számosság becslése (SQL Server)
- intelligens lekérdezésfeldolgozás SQL-adatbázisokban
- Operátor elsőbbsége (Transact-SQL)
- végrehajtási terv áttekintése
- Teljesítmény Központ a SQL Server Database Engine és Azure SQL Database részére