Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik a következőkre:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analitikai Platform System (PDW)
Analitikai Platform System (PDW)![]() SQL adatbázis a Microsoft Fabric-ben
SQL adatbázis a Microsoft Fabric-ben
Az SQL Server összekapcsolásokkal kér le adatokat több táblából a közöttük lévő logikai kapcsolatok alapján. Az illesztések alapvető fontosságúak a relációs adatbázis műveleteihez, és lehetővé teszik, hogy két vagy több tábla adatait egyetlen eredményhalmazba egyesítse.
Az SQL Server mind a (Transact-SQL szintaxis által meghatározott) logikai illesztési műveleteket, mind a fizikai illesztési műveleteket (az illesztések végrehajtásához használt tényleges algoritmusokat) implementálja. Mindkét szempont megértése segít a hatékony lekérdezések írásában és az adatbázis teljesítményének optimalizálásában.
A logikai illesztési műveletek a következők:
- Belső illesztések
- Bal, jobb és teljes külső illesztések
- Keresztcsatlakozások
A fizikai illesztési műveletek a következők:
- Beágyazott hurkok illesztései
- Illesztések egyesítése
- Kivonat illesztések
- Adaptív illesztések (a következőkre vonatkozik: SQL Server 2017 (14.x) és újabb verziók)
Ez a cikk bemutatja az illesztések működését, a különböző illesztési típusok használatát, valamint azt, hogy a Lekérdezésoptimalizáló hogyan választja ki a leghatékonyabb illesztési algoritmust olyan tényezők alapján, mint a táblázatméret, az elérhető indexek és az adateloszlás.
Note
További információ az illesztés szintaxisáról: FROM záradék plusz JOIN, APPLY, PIVOT.
Csatlakozás alapjai
Az illesztések használatával két vagy több táblából is lekérhet adatokat a táblák közötti logikai kapcsolatok alapján. Az illesztések azt jelzik, hogy az SQL Server hogyan használja az egyik tábla adatait egy másik tábla sorainak kijelöléséhez.
Az illesztés feltétele határozza meg, hogyan kapcsolódik két tábla egy lekérdezéshez a következő módon:
- Az illesztéshez használni kívánt táblák oszlopának megadása. Egy tipikus illesztésfeltétel egy idegen kulcsot határoz meg az egyik táblából, a másik táblában pedig annak társított kulcsát.
- Az oszlopok értékeinek összehasonlításához használandó logikai operátor (például = vagy <>,) megadása.
Az illesztések logikailag vannak kifejezve az alábbi Transact-SQL szintaxissal:
[ INNER ] JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
A belső illesztések megadhatók vagy a FROM vagy a WHERE záradékokban.
Külső illesztések és keresztillesztések csak a FROM záradékban adhatók meg. Az csatlakozási feltételek kombinálódnak a WHERE és HAVING keresési feltételekkel, hogy szabályozzák azokat a sorokat, amelyeket az alaptáblákból választanak ki a FROM záradék alapján.
A záradék illesztési FROM feltételeinek megadása segít elválasztani őket a záradékban WHERE esetleg megadott keresési feltételektől, és ez az illesztések megadásának ajánlott módja. Az egyszerűsített ISO-záradék FROM illesztési szintaxisa a következő:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- A join_type határozza meg, hogy milyen típusú illesztést hajt végre: belső, külső vagy keresztillesztést. A különböző típusú illesztések magyarázatát lásd a FROM záradékban.
- A join_condition határozza meg a kiértékelendő predikátumot az egyes illesztett sorok párjaihoz.
Az alábbi kód egy példa egy FROM záradék illesztési specifikációjára:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
Az alábbi kód egy egyszerű SELECT utasítás az illesztés használatával:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
Az SELECT utasítás a termék és a szállító adatait adja vissza az olyan vállalat által megadott alkatrészek kombinációjára vonatkozóan, amelyeknél a vállalat neve F betűvel kezdődik, és a termék ára meghaladja a 10 usd-t.
Ha egyetlen lekérdezés több táblára is hivatkozik, minden oszlophivatkozásnak egyértelműnek kell lennie. Az előző példában mind a ProductVendor és a Vendor tábla tartalmaz egy BusinessEntityID nevű oszlopot. A lekérdezésben hivatkozott két vagy több tábla között duplikált összes oszlopnevet a tábla nevével kell minősíteni. A példában szereplő Vendor oszlopokra mutató összes hivatkozás minősített.
Ha egy oszlopnév nem duplikálva van a lekérdezésben használt két vagy több táblában, az arra mutató hivatkozásokat nem kell a tábla nevével minősíteni. Ez az előző példában látható. Egy ilyen záradékot SELECT néha nehéz megérteni, mert semmi sem utal az egyes oszlopokat tartalmazó táblára. A lekérdezés olvashatósága javul, ha az összes oszlop megfelel a táblaneveinek. Az olvashatóság tovább javul, ha álneveket használunk táblákhoz, különösen akkor, amikor a tábla neveit magával az adatbázissal és a tulajdonosnevekkel kell megadni. A következő kód ugyanaz a példa, azzal a kivétellel, hogy a tábla aliasai hozzá lettek rendelve, és az oszlopok táblaaliasokkal vannak minősítve az olvashatóság javítása érdekében:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
Az előző példák az illesztési feltételeket határozták meg a FROM záradékban, amely az előnyben részesített módszer. A következő lekérdezés ugyanazt az illesztési feltételt tartalmazza, amit az WHERE záradékban adtak meg.
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
Az SELECT illesztések listája hivatkozhat az összekapcsolt táblák összes oszlopára vagy az oszlopok bármely részhalmazára. A SELECT listának nem kell oszlopokat tartalmaznia az illesztés minden táblájából. Egy háromtáblás illesztésben például csak egy tábla használható a másik tábla egyikéről a harmadik táblára való hídhoz, és a középső tábla egyik oszlopára sem kell hivatkozni a kijelölési listában. Ezt anti semi join-nak is nevezik.
Bár az illesztés feltételei általában egyenlőségi összehasonlításokkal (=) rendelkeznek, más összehasonlítási vagy relációs operátorok is megadhatóak, ahogyan más predikátumok is. További információ: Összehasonlító operátorok és HOL.
Amikor az SQL Server feldolgozza az illesztéseket, a Lekérdezésoptimalizáló kiválasztja az illesztés feldolgozásának leghatékonyabb módszerét (több lehetőség közül). Ez magában foglalja a fizikai illesztés leghatékonyabb típusának kiválasztását, a táblák összekapcsolásának sorrendjét, valamint olyan logikai illesztési műveletek használatát is, amelyek nem fejezhetők ki közvetlenül Transact-SQL szintaxissal, például félillesztésekkel és anti-félillesztésekkel. A különböző illesztések fizikai végrehajtása számos különböző optimalizálást használhat, ezért nem lehet megbízhatóan előrejelezni. A félillesztésekkel és az anti-félillesztésekkel kapcsolatos további információkért lásd a logikai és a fizikai showplan operátorra vonatkozó referenciát.
Az illesztési feltételben használt oszlopoknak nem kell ugyanazzal a névvel vagy adattípussal rendelkezniük. Ha azonban az adattípusok nem azonosak, kompatibilisnek kell lenniük, vagy olyan típusoknak kell lenniük, amelyeket az SQL Server implicit módon konvertálhat. Ha az adattípusok nem konvertálhatók implicit módon, az illesztési feltételnek explicit módon konvertálnia kell az adattípust a CAST függvény használatával. Az implicit és explicit konverziókkal kapcsolatos további információkért lásd az adattípus-átalakítást (adatbázismotort) ismertető témakört.
Az illesztéseket használó lekérdezések többsége újraírható egy al lekérdezéssel (egy másik lekérdezésbe ágyazott lekérdezéssel), és a legtöbb al lekérdezés illesztésként újraírható. További információ az albekérdezésekről: Subqueries (SQL Server).
Note
A táblázatok nem csatlakoztathatók közvetlenül ntext, szöveg vagy képoszlopokhoz. A táblázatok azonban közvetett módon is összekapcsolhatók az ntext, szöveg vagy kép oszlopon a SUBSTRING használatával.
Például a SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) kéttáblás belső illesztést hajt végre a t1 és t2 táblázatok szövegoszlopainak első 20 karakterén.
Emellett az ntext vagy szöveges oszlopok két táblázatból való összehasonlításának másik lehetősége az oszlopok hosszának összehasonlítása egy WHERE záradékkal, például: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Beágyazott hurkok illesztéseinek ismertetése
Ha az egyik illesztési bemenet kicsi (kevesebb, mint 10 sor), a másik illesztési bemenet pedig meglehetősen nagy és indexelt az illesztési oszlopokon, akkor az indexbe ágyazott hurkok illesztése a leggyorsabb illesztési művelet, mivel a legkisebb I/O-t és a legkevesebb összehasonlítást igénylik.
A beágyazott hurkok illesztése, más néven beágyazott iteráció egy illesztési bemenetet használ külső bemeneti táblaként (a grafikus végrehajtási terv felső bemeneteként), egy pedig a belső (alsó) bemeneti táblázatként. A külső hurok sorról sorra használja fel a külső bemeneti táblázatot. Az egyes külső sorokhoz végrehajtott belső hurok megkeresi az egyező sorokat a belső bemeneti táblában.
A legegyszerűbb esetben a keresés egy teljes táblát vagy indexet vizsgál; ezt naiv beágyazott hurkoknak nevezzük. Ha a keresés kihasznál egy indexet, azt indexbe ágyazott hurkoknak nevezzük. Ha az index a lekérdezési terv részeként van létrehozva (és a lekérdezés befejezésekor megsemmisül), akkor ideiglenes indexbe ágyazott hurkoknak nevezzük. Ezeket a változatokat a Lekérdezésoptimalizáló veszi figyelembe.
A beágyazott hurkok illesztése különösen akkor hatékony, ha a külső bemenet kicsi, a belső bemenet pedig előre indexelt és nagy. Sok kis tranzakcióban, például a csak kis sorhalmazt érintő tranzakciókban az indexbe ágyazott hurkok illesztései jobbak az egyesítési illesztéseknél és a kivonat-illesztéseknél. Nagy lekérdezések esetén azonban a beágyazott hurkokkal végzett illesztés gyakran nem optimális választás.
Ha a beágyazott hurkok illesztési operátorának OPTIMALIZÁLT attribútuma Igaz értékre van állítva, az azt jelenti, hogy a rendszer optimalizált beágyazott hurkokat (vagy Batch Sort) használ az I/O minimalizálására, ha a belső oldaltábla nagy, függetlenül attól, hogy párhuzamos-e vagy sem. Előfordulhat, hogy az optimalizálás egy adott tervben való jelenléte nem túl nyilvánvaló egy végrehajtási terv elemzésekor, mivel maga a rendezés rejtett művelet. Az OPTIMALIZÁLT attribútum terv XML-fájljának megtekintésével azonban ez azt jelzi, hogy a beágyazott hurkok illesztése megpróbálhatja átrendezni a bemeneti sorokat az I/O-teljesítmény javítása érdekében.
Illesztések egyesítése
Ha a két illesztési bemenet nem kicsi, de az illesztési oszlopban vannak rendezve (például ha rendezett indexek vizsgálatával szerezték be őket), az egyesítési illesztés a leggyorsabb illesztési művelet. Ha mindkét csatlakozási bemenet nagy, és a két bemenet hasonló méretű, az összevonásos csatlakozás korábbi rendezéssel és a hash illesztéssel hasonló teljesítményt nyújt. A kivonat-illesztési műveletek azonban gyakran sokkal gyorsabbak, ha a két bemeneti méret jelentősen eltér egymástól.
Az egyesítési illesztéshez mindkét bemenetet az egyesítési oszlopokra kell rendezni, amelyeket az illesztési predikátum egyenlőségi (ON) záradékai határoznak meg. A lekérdezésoptimalizáló általában egy indexet vizsgál, ha van ilyen a megfelelő oszlopkészleten, vagy rendezési operátort helyez el az egyesítési illesztés alatt. Ritkán több egyenlőségi záradék is lehet, de az egyesítési oszlopok csak néhány rendelkezésre álló egyenlőségi záradékból származnak.
Mivel minden bemenet rendezve van, az Egyesítéses összevonás operátor minden bemenetből kap egy sort, és összehasonlítja őket. Belső illesztési műveletek esetén például a sorok akkor lesznek visszaadva, ha egyenlőek. Ha nem egyenlők, a rendszer elveti az alsó értéket, és egy másik sort szerez be ebből a bemenetből. Ez a folyamat addig ismétlődik, amíg az összes sort fel nem dolgozzák.
Az egyesítési illesztési művelet normál vagy több-a-többhöz művelet. A több-a-többhöz egyesítési illesztés egy ideiglenes táblát használ a sorok tárolásához. Ha az egyes bemenetek értékei duplikáltak, az egyik bemenetnek vissza kell kapcsolódnia az ismétlődések elejére, mivel a másik bemenet minden duplikáltja feldolgozásra kerül.
Ha reziduális predikátum van jelen, az egyesítési predikátumnak megfelelő összes sor kiértékeli a reziduális predikátumot, és csak azokat a sorokat adja vissza, amelyek megfelelnek annak.
Maga az egyesítés nagyon gyors, de költséges választás lehet, ha rendezési műveletekre van szükség. Ha azonban az adatmennyiség nagy, és a kívánt adatok előválogathatók a meglévő B-fa indexekből, az egyesítési illesztés gyakran a leggyorsabb elérhető illesztési algoritmus.
Kivonat illesztések
A hash join-ek hatékonyan feldolgozhatják a nagy, rendezetlen, nem indexelt bemeneteket. Összetett lekérdezésekben a köztes eredményekhez hasznosak, mert:
- A köztes eredmények nem indexelhetők (kivéve, ha kifejezetten lemezre mentik, majd indexelik), és gyakran nem megfelelően rendezik őket a lekérdezésterv következő műveletéhez.
- A lekérdezés-optimalizálók csak a köztes eredményméreteket becsülik meg. Mivel a becslések nagyon pontatlanok lehetnek az összetett lekérdezések esetében, a köztes eredmények feldolgozására szolgáló algoritmusoknak nem csak hatékonynak kell lenniük, hanem kecsesen kell csökkenniük, ha egy köztes eredmény a vártnál sokkal nagyobbnak bizonyul.
A hash illesztés lehetővé teszi a denormalizálás használatának csökkentését. A denormalizálást általában a jobb teljesítmény eléréséhez használják az illesztési műveletek csökkentésével, a redundancia veszélyei ellenére, például inkonzisztens frissítések ellenére. A hash join-ok csökkentik a denormalizálás szükségességét. A hash illesztések lehetővé teszik, hogy a függőleges particionálás (ahol egyetlen táblából származó oszlopcsoportok külön fájlokban vagy indexekben kerülnek ábrázolásra) életképes opcióvá váljon a fizikai adatbázis tervezésében.
A hash csatolás két bemenettel rendelkezik: build bemenettel és probe bemenettel. A lekérdezésoptimalizáló hozzárendeli ezeket a szerepköröket, így a két bemenet közül a kisebb a buildbemenet.
A hash illesztések számos típusú készletegyeztetési művelethez használhatók: belső illesztés; bal, jobb és teljes külső illesztés; bal és jobb félillesztés; metszet; unió; és különbség. Ezenkívül a hash join egy változata duplikátumok eltávolítását és csoportosítást is végezheti, mint SUM(salary) GROUP BY department. Ezek a módosítások csak egy bemenetet használnak mind a buildelési, mind a mintavételi szerepkörökhöz.
A következő szakaszok a hash csatlakozások különböző típusait ismertetik: a memóriaalapú hash csatlakozás, a Grace hash csatlakozás és a rekurzív hash csatlakozás.
Memóriabeli kivonat illesztés
A hash illesztés először megvizsgálja a teljes build bemenetet, vagy azt kiszámítja, majd létrehoz egy hashtáblát a memóriában. A rendszer minden sort beszúr egy kivonatgyűjtőbe a kivonatkulcshoz kiszámított kivonatértéktől függően. Ha a teljes buildbemenet kisebb, mint a rendelkezésre álló memória, az összes sor beilleszthető a kivonattáblába. Ezt a buildelési fázist a mintavételi fázis követi. A rendszer egyszerre egy sorban ellenőrzi vagy kiszámítja a teljes mintavételi bemenetet, és minden mintavételi sor esetében kiszámítja a kivonatkulcs értékét, beolvasja a megfelelő kivonatgyűjtőt, és létre lesznek hozva az egyezések.
Grace hash illesztés
Ha a buildbemenet nem fér el a memóriában, a kivonat-illesztés több lépésben is folytatódik. Ezt grace hash joinnak nevezzük. Minden lépéshez tartozik egy összeállítási fázis és egy mintavételi fázis. Kezdetben a rendszer a teljes build- és mintavételi bemenetet felhasználja és particionálta (kivonatfüggvény használatával a kivonatkulcsokon) több fájlba. A hashkulcsok hashfüggvényének használata garantálja, hogy bármely két illesztő rekordnak ugyanabban a fájlpárban kell lennie. Ezért a két nagy bemenet összekapcsolásának feladata ugyanazon tevékenységek több, de kisebb példányára csökkent. A kivonat illesztése ezután minden particionált fájlpárra alkalmazva lesz.
Rekurzív kivonat illesztés
Ha a buildbemenet olyan nagy, hogy egy szabványos külső egyesítés bemenetei több egyesítési szintet igényelnek, több particionálási lépésre és több particionálási szintre van szükség. Ha csak néhány partíció nagy, akkor a rendszer csak az adott partíciókhoz használ további particionálási lépéseket. Annak érdekében, hogy az összes particionálási lépés a lehető leggyorsabb legyen, a rendszer nagy, aszinkron I/O-műveleteket használ, hogy egyetlen szál több lemezmeghajtót is lefoglalhasson.
Note
Ha a build bemenete csak valamivel nagyobb a rendelkezésre álló memóriánál, akkor a memória-beli hash összekapcsolás és a Grace hash összekapcsolás elemei egyetlen lépésben kombinálódnak, így hibrid hash összekapcsolást eredményeznek.
Az optimalizálás során nem mindig állapítható meg, hogy melyik kivonat-illesztés van használatban. Ezért az SQL Server egy memórián belüli hash illesztéssel kezd, és fokozatosan áttér a grace hash illesztésre, valamint a rekurzív hash illesztésre, a buildbemenet méretétől függően.
Ha a Lekérdezésoptimalizáló helytelenül számít arra, hogy a két bemenet közül melyik kisebb, és ezért a buildbemenetnek kellett volna lennie, a build- és mintavételi szerepkörök dinamikusan megfordulnak. A hash összekapcsolás biztosítja, hogy a kisebb átmeneti fájlt használja bemeneti adatként. Ezt a technikát szerepkör-megfordításnak nevezzük. A szerepcsere a hash illesztésen belül történik, miután legalább egyszer adatot lemezen tárolnak.
Note
A szerepkör-felcserélés független minden lekérdezési tipp vagy struktúrától történik. A szerepkör-visszaverés nem jelenik meg a lekérdezési tervben; amikor bekövetkezik, az átlátható lesz a felhasználó számára.
Kivonatos mentőcsomag
A hash bailout kifejezést néha a grace hash join vagy rekurzív hash join leírására használják.
Note
A rekurzív hash csatlakozások vagy hash megszakítások csökkenthetik a kiszolgáló teljesítményét. Ha egy naplófájlban számos Hash figyelmeztető eseményt lát, frissítse a csatlakoztatott oszlopok statisztikáit.
A hash kivonásról további információt a Hash figyelmeztető esemény osztályban talál.
Adaptív illesztések
Batch mód Az adaptív illesztések lehetővé teszik a hash illesztés vagy a beágyazott hurkok illesztési módszerének kiválasztását az első bemenet beolvasásáig. Az Adaptív illesztés operátor egy küszöbértéket határoz meg, amellyel eldönthető, hogy mikor váltson a Beágyazott Hurok tervre. A lekérdezéstervek ezért dinamikusan válthatnak jobb illesztési stratégiára a végrehajtás során anélkül, hogy újrafordítást kellene végrehajtaniuk.
Tip
A funkció leginkább a kis és nagy illesztésű bemeneti vizsgálatok közötti gyakori oszcillációval rendelkező számítási feladatok számára előnyös.
A futtatókörnyezeti döntés a következő lépéseken alapul:
- Ha a build join bemenetének sorainak száma elég kicsi ahhoz, hogy a beágyazott hurkok összekapcsolása optimálisabb legyen, mint egy Hash illesztés, a terv a Beágyazott hurkok algoritmus használatára vált át.
- Ha a build join bemenete túllép egy adott sor szám küszöbértéket, nem történik váltás, és a terv hash joinnal folytatódik.
A következő lekérdezés egy adaptív illesztési példa szemléltetésére szolgál:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
A lekérdezés 336 sort ad vissza. Az élő lekérdezési statisztikák engedélyezése a következő tervet jeleníti meg:

A tervben jegyezze fel a következőket:
- Oszlopbeli indexlekérdezés szolgáltat sorokat a hash csatolási fázis buildeléséhez.
- Az új Adaptív illesztés operátor. Ez az operátor meghatároz egy küszöbértéket, amelyet arra használnak, hogy eldöntsék, mikor váltson beágyazott ciklusok tervre. Ebben a példában a küszöbérték 78 sor. Bármelyik >= 78 sorral rendelkező esetében Hash join-t fog használni. Ha kisebb a küszöbértéknél, beágyazott hurkok illesztése lesz használva.
- Mivel a lekérdezés 336 sort ad vissza, ez túllépte a küszöbértéket, így a második ág egy szabványos hash illesztési művelet keresési fázisát jelöli. Az élő lekérdezési statisztikák az operátorokon áthaladó sorokat jelenítik meg – ebben az esetben "672/672".
- Az utolsó ág pedig egy csoportosított index keresés, amelyet a beágyazott hurkok illesztése használ, ha nem lépték túl a küszöbértéket. Megjelenik a "0 a 336-ból" sor (az ág nincs használatban).
Most kontrasztosítsd a tervet ugyanazzal a lekérdezéssel, de ha az Quantity értéknek csak egy sora van a táblában:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
A lekérdezés egy sort ad vissza. Az élő lekérdezési statisztikák engedélyezése a következő tervet jeleníti meg:

A tervben jegyezze fel a következőket:
- Ha egy sort ad vissza, a fürtözött indexkeresés mostantól sorokat halad át rajta.
- Mivel a Hash Join összeállítási fázisa nem folytatódott, a második ágon nincsenek sorok.
Adaptív illesztési megjegyzések
Az adaptív illesztések nagyobb memóriaigényt igényelnek, mint az indexelt Nested Loops Join egyenértékű terve. A rendszer úgy kéri a további memóriát, mintha a Nested Loops Hash Join lenne. A buildelési fázisra is van többletterhelés, mint egy stop-and-go művelet, szemben a beágyazott hurkok streameléssel egyenértékű illesztésével. Ezzel a további költségek rugalmasságot biztosítanak az olyan helyzetekben, ahol a sorok száma ingadozik a build bemenetében.
A Batch módú adaptív illesztések egy utasítás kezdeti végrehajtásához működnek, és a fordítás után az egymást követő végrehajtások adaptívak maradnak a lefordított adaptív illesztési küszöbérték és a külső bemenet buildelési fázisán áthaladó futtatókörnyezeti sorok alapján.
Ha egy Adaptív illesztés másodlagos hurkok műveletre vált, akkor a Hash illesztése build által már beolvasott sorokat használja. Az operátor nem olvassa újra újra a külső referenciasorokat.
Adaptív illesztési tevékenység nyomon követése
Az Adaptív illesztés operátor a következő tervoperátor-attribútumokkal rendelkezik:
| Plan attribútum | Description |
|---|---|
| AdaptiveThresholdRows | A küszöbértéket mutatja, amelyet a hash join és az egymásba ágyazott ciklus csatlakozás közötti váltáshoz használnak. |
| BecsültjoinType | Az illesztés típusa valószínűleg a következő lesz. |
| ActualJoinType | Egy tényleges tervben azt mutatja be, hogy végül melyik illesztési algoritmus lett kiválasztva a küszöbérték alapján. |
A becsült terv az Adaptív illesztési terv alakzatot, valamint egy meghatározott adaptív illesztési küszöbértéket és becsült illesztési típust jeleníti meg.
Tip
A Lekérdezéstár rögzíti a köteg módú adaptív illesztési tervet, és képes kényszeríteni a végrehajtását.
Adaptív összekapcsolási alkalmas utasítások
Néhány feltétel feljogosítja a logikai illesztéseket a kötegelt módú adaptív illesztéshez:
- Az adatbázis kompatibilitási szintje 140 vagy magasabb.
- A lekérdezés egy
SELECTutasítás (az adatmódosítási utasítások jelenleg nem használhatók). - Az illesztés az indexelt beágyazott hurkok illesztésével vagy a hash illesztés fizikai algoritmusával is végrehajtható.
- A hash illesztés Batch módot használ, amelyet egy oszlopbolt index megléte teszi lehetővé a lekérdezésben általában, vagy egy oszlopbolt indexelt táblán keresztül, amelyre az illesztés közvetlenül hivatkozik, vagy a Batch mód a sorbolt használatával.
- A Beágyazott hurok illesztés és Hash illesztés generált alternatív megoldásainak ugyanazzal az első gyermekkel kell rendelkezniük (külső referencia).
Adaptív küszöbértéksorok
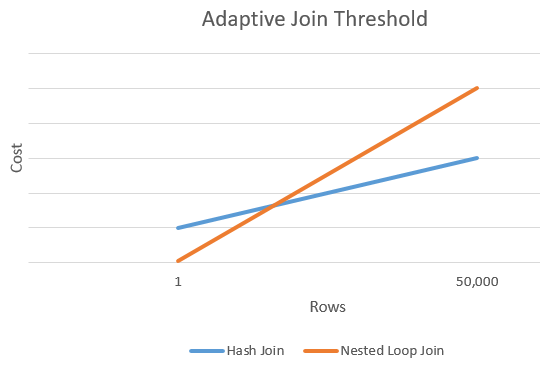
Az alábbi diagram egy példa metszetet mutat be a hash összekapcsolás költsége és a beágyazott hurkok összekapcsolás költsége között. Ezen a metszeti ponton a rendszer meghatározza a küszöbértéket, amely az illesztési művelethez használt tényleges algoritmust határozza meg.
Adaptív illesztések letiltása a kompatibilitási szint módosítása nélkül
Az adaptív illesztések letilthatók az adatbázis vagy az utasítás hatókörében, miközben továbbra is fenntartják a 140-es és magasabb szintű adatbázis-kompatibilitási szintet.
Ha le szeretné tiltani az adaptív illesztéseket az adatbázisból származó összes lekérdezésvégrehajtáshoz, hajtsa végre a következőket az alkalmazandó adatbázis kontextusában:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Ha engedélyezve van, ez a beállítás engedélyezve jelenik meg a sys.database_scoped_configurations.
Ha újra engedélyezni szeretné az adaptív illesztéseket az adatbázisból származó összes lekérdezésvégrehajtáshoz, hajtsa végre a következőket az alkalmazandó adatbázis kontextusában:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
Az adaptív illesztések le is tilthatók egy adott lekérdezés esetében a DISABLE_BATCH_MODE_ADAPTIVE_JOINS tippként való kiválasztásával. Például:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
A USE HINT lekérdezési tippek elsőbbséget élveznek az adatbázis hatókörébe tartozó konfigurációval vagy nyomkövetési jelző beállítással szemben.
Null értékek és összekapcsolások
Ha az összekapcsolt táblák oszlopaiban null érték van, a null értékek nem egyeznek egymással. Az oszlopban lévő null értékek jelenléte az összekapcsolt táblák egyikéből csak külső illesztés használatával adható vissza (kivéve, ha a záradék kizárja a WHERE null értékeket).
Az alábbiakban két táblát talál, amelyek NULL oszlopot tartalmaznak, és részt vesznek az illesztésben.
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Az oszlop a értékeit oszlophoz c hasonlító illesztés nem kap egyezést a következő értékeket NULLtartalmazó oszlopokon:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Csak egy sor lesz visszaadva, amelynek 4 értéke van a és c oszlopokban.
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Az alaptáblából visszaadott null értékek szintén nehezen különböztethetők meg a külső illesztésből visszaadott null értékektől. Az alábbi SELECT utasítás például bal oldali külső illesztést végez ezen a két táblán:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Itt van az eredmények összessége.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
Az eredmények nem teszik könnyen megkülönböztethetővé az adatokban lévő adatokat NULL az NULL illesztés meghiúsulását jelzőtől. Ha NULL az adatok összeillesztésében értékek vannak jelen, általában célszerű kihagyni őket az eredményekből egy normál illesztés használatával.