Memahami dan menyesuaikan unit streaming Azure Stream Analytics
Memahami unit streaming dan node streaming
Unit Streaming (SU) mewakili sumber daya komputasi yang dialokasikan untuk menjalankan pekerjaan Stream Analytics. Semakin tinggi jumlah SU, semakin banyak sumber daya CPU dan memori yang dialokasikan untuk pekerjaan Anda. Kapasitas ini memungkinkan Anda fokus pada logika kueri dan mengabstraksi kebutuhan untuk mengelola perangkat keras untuk menjalankan pekerjaan Stream Analytics Anda secara tepat waktu.
Azure Stream Analytics mendukung dua struktur unit streaming: SU V1(agar tidak digunakan lagi) dan SU V2(disarankan).
Model SU V1 adalah penawaran asli ASA di mana setiap 6 SU sesuai dengan satu simpul streaming untuk pekerjaan. Pekerjaan juga dapat berjalan dengan 1 dan 3 SU dan ini sesuai dengan simpul streaming pecahan. Penskalaan terjadi dalam kenaikan 6 di luar 6 pekerjaan SU, hingga 12, 18, 24 dan seterusnya dengan menambahkan lebih banyak simpul streaming yang menyediakan sumber daya komputasi terdistribusi.
Model SU V2 (disarankan) adalah struktur yang disederhanakan dengan harga yang menguntungkan untuk sumber daya komputasi yang sama. Dalam model SU V2, 1 SU V2 sesuai dengan satu simpul streaming untuk pekerjaan Anda. 2 SU V2 sesuai dengan 2, 3 hingga 3, dan sebagainya. Pekerjaan dengan 1/3 dan 2/3 SU V2 juga tersedia dengan satu simpul streaming tetapi sebagian kecil dari sumber daya komputasi. Pekerjaan SU V2 1/3 dan 2/3 menyediakan opsi hemat biaya untuk beban kerja yang membutuhkan skala yang lebih kecil.
Daya komputasi yang mendasar untuk unit streaming V1 dan V2 adalah sebagai berikut:
Untuk informasi tentang harga SU, kunjungi Halaman Harga Azure Stream Analytics.
Memahami konversi unit streaming dan di mana mereka menerapkannya
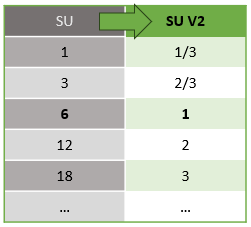
Ada konversi otomatis Unit Streaming yang terjadi dari lapisan REST API ke UI (Portal Microsoft Azure dan Visual Studio Code). Anda akan melihat konversi ini di log Aktivitas juga di mana nilai SU muncul berbeda dari nilai pada UI. Ini dirancang dan alasannya adalah karena bidang REST API terbatas pada nilai bilangan bulat dan pekerjaan ASA mendukung simpul pecahan (Unit Streaming 1/3 dan 2/3). UI ASA menampilkan nilai simpul 1/3, 2/3, 1, 2, 3, ... dll, sementara backend (log aktivitas, lapisan REST API) menampilkan nilai yang sama masing-masing dikalikan dengan 10 sebagai 3, 7, 10, 20, 30.
| Standard | Standar V2 (UI) | V2 Standar (Backend seperti log, Rest API, dll.) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Ini memungkinkan kami untuk menyampaikan granularitas yang sama dan menghilangkan titik desimal pada lapisan API untuk SKU V2. Konversi ini bersifat otomatis dan tidak berdampak pada performa pekerjaan Anda.
Memahami penggunaan konsumsi dan memori
Untuk mencapai pemrosesan aliran latensi rendah, pekerjaan Azure Stream Analytics melakukan semua pemrosesan dalam memori. Ketika kehabisan memori, pekerjaan streaming gagal. Akibatnya, untuk pekerjaan produksi, penting untuk memantau penggunaan sumber daya pekerjaan streaming dan memastikan ada cukup sumber daya yang dialokasikan agar pekerjaan tetap berjalan 24/7.
Metrik pemanfaatan SU%, yang berkisar antara 0% hingga 100%, menjelaskan konsumsi memori beban kerja Anda. Untuk pekerjaan streaming dengan jejak minimal, metrik ini biasanya antara 10% hingga 20%. Jika pemanfaatan SU% tinggi (di atas 80%), atau jika peristiwa input di-backlogged (bahkan dengan pemanfaatan SU% yang rendah karena tidak menunjukkan penggunaan CPU), beban kerja Anda kemungkinan memerlukan lebih banyak sumber daya komputasi, yang mengharuskan Anda untuk meningkatkan jumlah unit streaming. Sebaiknya jaga metrik SU di bawah 80% untuk memperhitungkan lonjakan sesekali. Untuk bereaksi terhadap peningkatan beban kerja dan meningkatkan unit streaming, pertimbangkan untuk mengatur peringatan 80% pada metrik Pemanfaatan SU. Selain itu, Anda dapat menggunakan metrik penundaan marka air dan peristiwa yang di-backlog untuk melihat apakah ada dampaknya.
Mengonfigurasi unit streaming (SU) Azure Stream Analytics
Masuk ke portal Microsoft Azure.
Dalam daftar sumber daya, temukan tugas Stream Analytics yang ingin Anda skalakan lalu buka.
Di halaman tugas, di bawah judul Konfigurasi, pilih Skalakan. Jumlah default SU adalah 1 saat membuat pekerjaan.
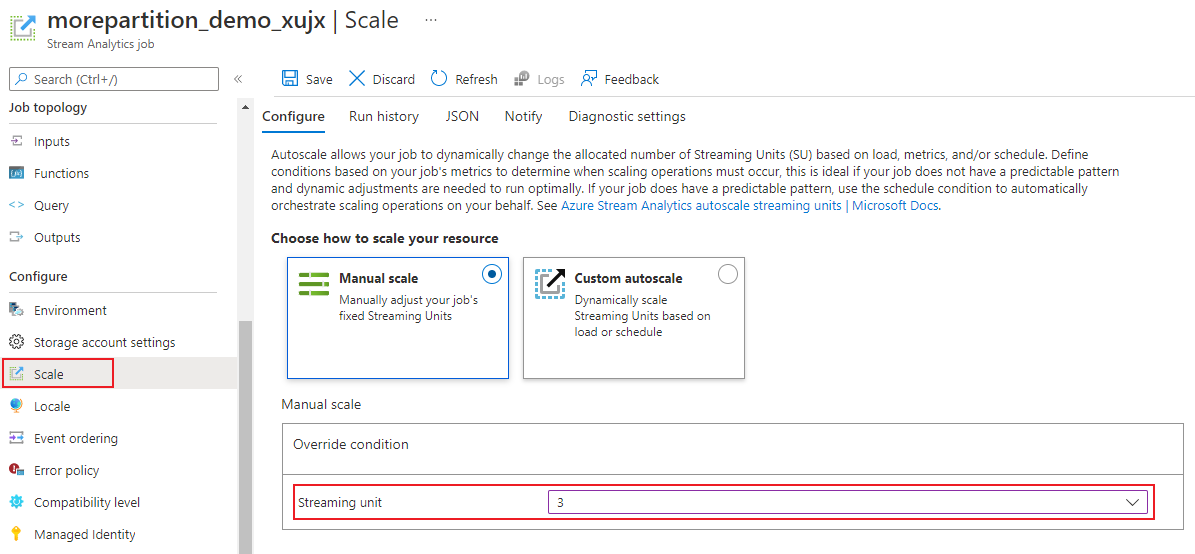
Pilih opsi SU di daftar drop-down untuk mengatur SU untuk pekerjaan tersebut. Perhatikan bahwa Anda terbatas pada rentang SU tertentu.
Anda dapat mengubah jumlah SU yang ditetapkan ke pekerjaan Anda saat sedang berjalan. Anda mungkin dibatasi untuk memilih dari sekumpulan nilai SU saat pekerjaan berjalan jika pekerjaan Anda menggunakan output yang tidak dipartisi. atau memiliki kueri multi-langkah dengan nilai PARTITION BY yang berbeda.
Memantau performa pekerjaan
Menggunakan portal Azure, Anda dapat melacak metrik terkait performa dari suatu pekerjaan. Untuk mempelajari definisi metrik, lihat Metrik pekerjaan Azure Stream Analytics. Untuk mempelajari selengkapnya pemantauan metrik di portal, lihat Memantau pekerjaan Azure Stream Analytics dengan portal Azure.
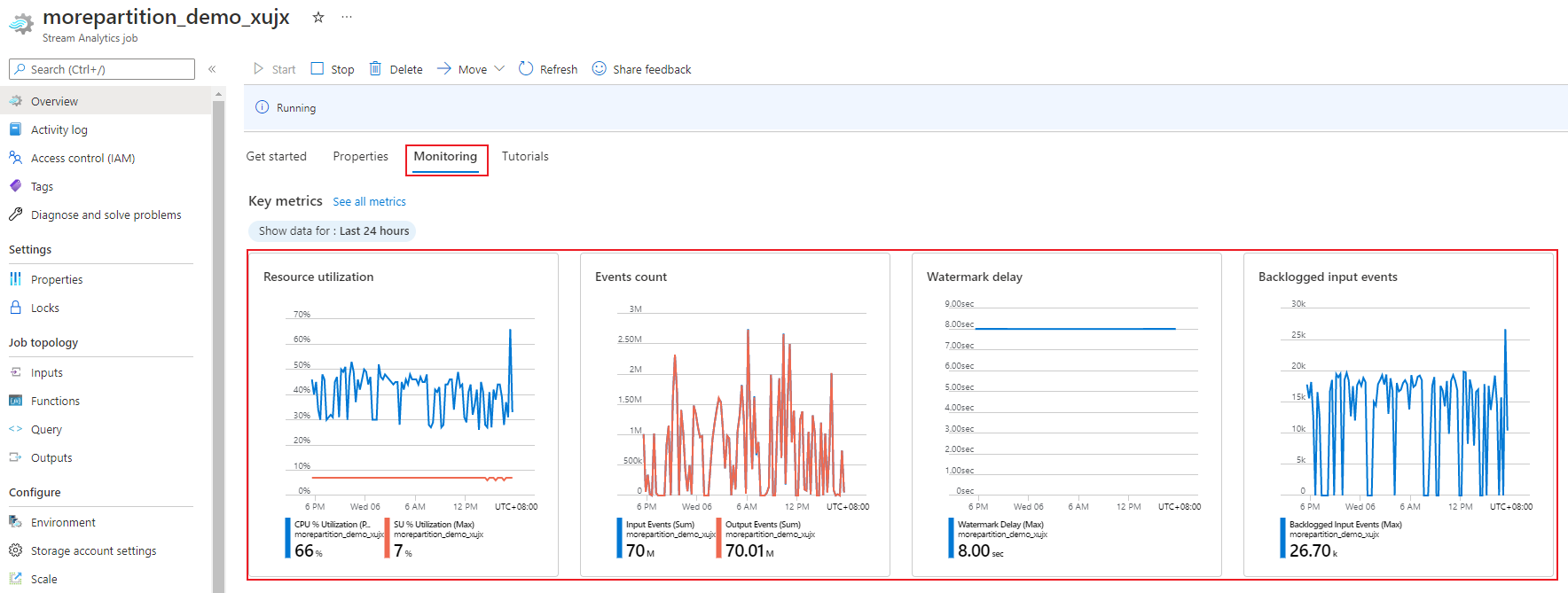
Menghitung throughput beban kerja yang diharapkan. Jika throughput kurang dari yang diharapkan, sesuaikan partisi input, sesuaikan kueri, dan tambahkan SU ke pekerjaan Anda.
Berapa banyak SU yang diperlukan untuk pekerjaan?
Memilih jumlah SU yang diperlukan untuk pekerjaan tertentu tergantung pada konfigurasi partisi untuk input dan kueri yang ditentukan untuk pekerjaan tersebut. Halaman Skalakan memungkinkan Anda untuk mengatur jumlah SU yang tepat. Ini adalah praktik terbaik untuk mengalokasikan lebih banyak SU daripada yang diperlukan. Mesin pemrosesan Stream Analytics mengoptimalkan latensi dan throughput dengan biaya penggunaan memori tambahan.
Secara umum, praktik terbaiknya adalah memulai dengan 1 SU V2 untuk kueri yang tidak menggunakan PARTITION BY. Kemudian tentukan sweet spot dengan menggunakan metode trial and error di mana Anda memodifikasi jumlah SU setelah meneruskan jumlah data yang representatif dan memeriksa metrik Pemanfaatan SU%. Jumlah maksimum unit streaming yang dapat digunakan oleh pekerjaan Stream Analytics bergantung pada jumlah langkah dalam kueri yang ditentukan untuk pekerjaan dan jumlah partisi di setiap langkah. Anda dapat mempelajari lebih lanjut tentang batasan di sini.
Untuk informasi selengkapnya tentang memilih jumlah SU yang tepat, lihat halaman ini: Menskalakan pekerjaan Azure Stream Analytics untuk meningkatkan throughput.
Catatan
Memilih berapa banyak SU yang diperlukan untuk pekerjaan tertentu tergantung pada konfigurasi partisi untuk input dan kueri yang ditentukan untuk pekerjaan tersebut. Anda dapat memilih hingga kuota di SU untuk pekerjaan. Untuk informasi tentang kuota langganan Azure Stream Analytics, kunjungi batas Azure Stream Analytics. Untuk menambah SU langganan Anda di luar kuota ini, hubungi Dukungan Microsoft. Nilai yang valid untuk SU per pekerjaan adalah 1/3, 2/3, 1, 2, 3, dan sebagainya.
Faktor yang meningkatkan pemanfaatan SU%
Elemen kueri Temporal (berorientasi waktu) adalah kumpulan inti operator berstatus yang disediakan Stream Analytics. Stream Analytics mengelola status operasi ini secara internal atas nama pengguna, dengan mengelola konsumsi memori, checkpointing untuk ketahanan, dan pemulihan status selama peningkatan layanan. Meskipun Azure Stream Analytics sepenuhnya mengelola status, ada sejumlah rekomendasi praktik terbaik yang harus dipertimbangkan pengguna.
Perhatikan bahwa pekerjaan dengan logika kueri yang kompleks dapat memiliki pemanfaatan SU% yang tinggi bahkan ketika tidak menerima peristiwa input secara terus-menerus. Ini dapat terjadi setelah lonjakan tiba-tiba dalam peristiwa input dan output. Pekerjaan tersebut mungkin terus mempertahankan status dalam memori jika kuerinya kompleks.
Pemanfaatan SU% mungkin tiba-tiba turun menjadi 0 untuk jangka pendek sebelum kembali ke level yang diharapkan. Ini terjadi karena kesalahan sementara atau peningkatan yang dimulai sistem. Meningkatkan jumlah unit streaming untuk pekerjaan mungkin tidak mengurangi Pemanfaatan SU% jika kueri Anda tidak sepenuhnya paralel.
Saat membandingkan pemanfaatan selama periode waktu tertentu, gunakan metrik tingkat peristiwa. Metrik InputEvents dan OutputEvents menunjukkan berapa banyak peristiwa yang dibaca dan diproses. Ada metrik yang menunjukkan jumlah peristiwa kesalahan juga, seperti kesalahan deserialisasi. Ketika jumlah peristiwa per unit waktu meningkat, SU% meningkat dalam banyak kasus.
Logika kueri berstatus dalam elemen temporal
Salah satu kemampuan unik pekerjaan Azure Stream Analytics adalah melakukan pemrosesan yang nyata, seperti agregat berjendela, gabungan temporal, dan fungsi analitik temporal. Masing-masing operator ini menyimpan informasi status. Ukuran jendela maksimum untuk elemen kueri ini adalah tujuh hari.
Konsep jendela temporal muncul di beberapa elemen kueri Analisis Aliran:
Agregat berjendela: GROUP BY jendela Tumbling, Hopping, dan Sliding
Gabungan temporal: JOIN dengan fungsi DATEDIFF
Fungsi analitik temporal: ISFIRST, LAST, dan LAG dengan LIMIT DURATION
Faktor-faktor berikut memengaruhi memori yang digunakan (bagian dari metrik unit streaming) oleh pekerjaan Stream Analytics:
Agregat berjendela
Memori yang digunakan (ukuran status) untuk agregat berjendela tidak selalu sebanding secara langsung dengan ukuran jendela. Sebaliknya, memori yang digunakan sebanding dengan kardinalitas data, atau jumlah grup di setiap jendela waktu.
Misalnya, dalam kueri berikut, angka yang terkait dengan clusterid adalah kardinalitas kueri.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Untuk mengurangi masalah yang disebabkan oleh kardinalitas tinggi dalam kueri sebelumnya, Anda dapat mengirim peristiwa ke Azure Event Hubs yang dipartisi oleh clusterid, serta memperluas skala kueri dengan memungkinkan sistem untuk memproses setiap partisi input secara terpisah menggunakan PARTITION BY seperti yang ditunjukkan dalam contoh di bawah ini:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
Setelah kueri dipartisi, kueri tersebut disebar di beberapa node. Akibatnya, jumlah nilai clusterid yang masuk ke setiap simpul berkurang sehingga mengurangi kardinalitas grup dengan operator.
Partisi Azure Event Hubs harus dipartisi oleh kunci pengelompokan untuk menghindari perlunya langkah pengurangan. Untuk informasi selengkapnya, lihat gambaran umum Event Hubs.
Gabungan temporal
Memori yang dikonsumsi (ukuran status) dari gabungan temporal sebanding dengan jumlah peristiwa di ruang gerak temporal dari gabungan, yaitu tingkat input peristiwa dikalikan dengan ukuran ruang gerak. Dengan kata lain, memori yang dikonsumsi oleh gabungan sebanding dengan rentang waktu DateDiff dikalikan dengan tingkat peristiwa rata-rata.
Jumlah peristiwa yang tidak cocok pada gabungan memengaruhi pemanfaatan memori untuk kueri. Kueri berikut ini ingin menemukan tayangan iklan yang menghasilkan klik:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
Dalam contoh ini, ada kemungkinan bahwa banyak iklan yang ditampilkan dan hanya sedikit orang yang mengekliknya dan ini diperlukan untuk menyimpan semua peristiwa dalam jendela waktu. Memori yang digunakan sebanding dengan ukuran jendela dan laju peristiwa.
Untuk meremediasi ini, kirim peristiwa ke Azure Event Hubs yang dipartisi oleh kunci gabungan (dalam hal ini ID), dan perluas skala kueri dengan memungkinkan sistem memproses setiap partisi input secara terpisah menggunakan PARTITION BY seperti yang ditunjukkan di bawah ini:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
Setelah kueri dipartisi, kueri tersebut disebar di beberapa node. Akibatnya, jumlah peristiwa yang masuk ke setiap simpul berkurang sehingga mengurangi ukuran status yang disimpan di jendela gabungan.
Fungsi analitik temporal
Memori yang dikonsumsi (ukuran status) dari fungsi analitik temporal sebanding dengan tingkat peristiwa yang dikalikan dengan durasi. Memori yang dikonsumsi oleh fungsi analitik tidak sebanding dengan ukuran jendela, melainkan jumlah partisi di setiap jendela waktu.
Remediasinya mirip dengan gabungan temporal. Anda dapat menskalakan kueri menggunakan PARTITION BY.
Buffer tidak berurutan
Pengguna dapat mengonfigurasi ukuran buffer yang rusak di panel konfigurasi Pemesanan Peristiwa. Buffer digunakan untuk menahan input selama durasi jendela, dan menyusun ulang. Ukuran buffer sebanding dengan laju input peristiwa yang dikalikan dengan ukuran jendela yang rusak. Ukuran jendela default adalah 0.
Untuk memulihkan overflow dari buffer yang rusak, skalakan kueri menggunakan PARTITION BY. Setelah kueri dipartisi, kueri tersebut disebar di beberapa node. Akibatnya, jumlah peristiwa yang masuk ke setiap simpul berkurang sehingga mengurangi ukuran buffer urutkan ulang.
Jumlah partisi input
Setiap partisi input pekerjaan memiliki buffer. Semakin banyak partisi input, semakin banyak sumber daya yang digunakan pekerjaan. Untuk setiap unit streaming, Azure Stream Analytics dapat memproses sekitar 7 MB/dtk input. Oleh karena itu, Anda dapat mengoptimalkan dengan mencocokkan jumlah unit streaming Azure Stream Analytics dengan jumlah partisi di hub peristiwa Anda.
Biasanya, pekerjaan yang dikonfigurasi dengan unit streaming 1/3 cukup untuk pusat aktivitas dengan dua partisi (yang merupakan minimum untuk pusat aktivitas). Jika hub peristiwa memiliki lebih banyak partisi, pekerjaan Azure Stream Analytics Anda akan menggunakan lebih banyak sumber daya, tetapi tidak harus menggunakan throughput tambahan yang disediakan oleh Azure Event Hubs.
Untuk pekerjaan dengan 1 unit streaming V2, Anda mungkin memerlukan 4 atau 8 partisi dari pusat aktivitas. Namun, hindari terlalu banyak partisi yang tidak perlu karena itu menyebabkan penggunaan sumber daya yang berlebihan. Misalnya, hub peristiwa dengan 16 partisi atau lebih besar dalam pekerjaan Azure Stream Analytics yang memiliki 1 unit streaming.
Data referensi
Data referensi dalam ASA dimuat ke dalam memori untuk pencarian cepat. Dengan implementasi saat ini, setiap operasi gabungan dengan data referensi menyimpan salinan data referensi dalam memori, bahkan jika Anda bergabung dengan data referensi yang sama beberapa kali. Untuk kueri dengan PARTITION BY, setiap partisi memiliki salinan data referensi, sehingga partisi sepenuhnya dipisahkan. Dengan efek pengganda, penggunaan memori dapat dengan cepat menjadi sangat tinggi jika Anda bergabung dengan data referensi beberapa kali dengan beberapa partisi.
Penggunaan fungsi UDF
Saat Anda menambahkan fungsi UDF, Azure Stream Analytics memuat runtime JavaScript ke dalam memori. Ini akan mempengaruhi SU%.
Langkah berikutnya
- Membuat kueri yang dapat disejajarkan di Azure Stream Analytics
- Menskalakan pekerjaan Azure Stream Analytics untuk meningkatkan throughput
- Metrik pekerjaan Azure Stream Analytics
- Dimensi metrik pekerjaan Azure Stream Analytics
- Memantau pekerjaan Azure Stream Analytics dengan portal Azure
- Menganalisis performa pekerjaan Azure Stream Analytics dengan dimensi metrik
- Memahami dan menyesuaikan Unit Streaming