Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini menggunakan desainer Azure Machine Learning untuk membangun model pembelajaran mesin yang prediktif. Model ini didasarkan pada data yang disimpan pada Azure Synapse. Skenario bagi tutorial adalah memprediksi apakah pelanggan cenderung membeli sepeda atau tidak sehingga Adventure Works, sebuah toko sepeda, dapat membangun kampanye pemasaran yang ditargetkan.
Prasyarat
Untuk mengikuti tutorial ini, Anda membutuhkan:
- Kumpulan SQL yang telah dimuat sebelumnya dengan data contoh AdventureWorksDW. Untuk menyediakan Kumpulan SQL ini, lihat Membuat kumpulan SQL dan pilihlah untuk memuat data sampel. Jika Anda sudah memiliki gudang data namun tidak memiliki data sampel, Anda dapat memuat data sampel secara manual.
- Ruang kerja Azure Machine Learning. Ikuti tutorial ini untuk membuat yang baru.
Mendapatkan data
Data yang digunakan berada di dalam tampilan dbo.vTargetMail pada AdventureWorksDW. Untuk menggunakan Datastore dalam tutorial ini, data pertama kali akan diekspor ke akun Azure Data Lake Storage karena Azure Synapse saat ini tidak mendukung set data. Azure Data Factory dapat digunakan untuk mengekspor data dari gudang data ke Azure Data Lake Storage menggunakan aktivitas salin. Gunakan kueri berikut untuk mengimpor:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Setelah data tersedia pada Azure Data Lake Storage, Datastores di Azure Machine Learning digunakan untuk menghubungkan ke layanan penyimpanan Azure. Ikuti langkah-langkah berikut ini untuk membuat Datastore dan kumpulan Data yang terkait:
Luncurkan studio Azure Machine Learning baik dari portal Microsoft Azure atau masuk melalui studio Azure Machine Learning.
Klik Datastores di panel kiri pada bagianKelola lalu klik pada Datastore Baru.
Berikan nama untuk datastore, pilih jenis 'Azure Blob Storage', sediakan lokasi dan kredensial. Lalu, klik Buat.
Selanjutnya, klik Kumpulan Data di panel kiri pada bagian Aset. Pilih Buat dataset dengan opsi Dari datastore.
Tentukan nama set data dan pilih jenis yang akan menjadi Tabel. Lalu, klik Berikutnya untuk maju.
Di Pilih atau buat bagian datastore, pilih opsi Datastore yang telah dibuat sebelumnya. Pilih datastore yang telah dibuat sebelumnya. Klik Berikutnya dan tentukan jalur serta pengaturan file. Pastikan untuk menentukan header kolom jika file berisi hal tersebut.
Terakhir, klik Buat untuk membuat set data.
Mengonfigurasikan eksperimen desainer
Selanjutnya, ikuti langkah-langkah berikut ini untuk konfigurasi desainer:
Klik tab Desainer di panel kiri pada bagian Penulis.
Pilih Komponen yang dibangun sebelumnya dan mudah digunakan untuk membangun alur baru.
Pada panel pengaturan di sebelah kanan, tentukan nama alur.
Selain itu, pilih kluster komputasi target untuk seluruh eksperimen melalui tombol pengaturan, pada kluster yang telah disediakan sebelumnya. Silakan tutup panel Pengaturan.
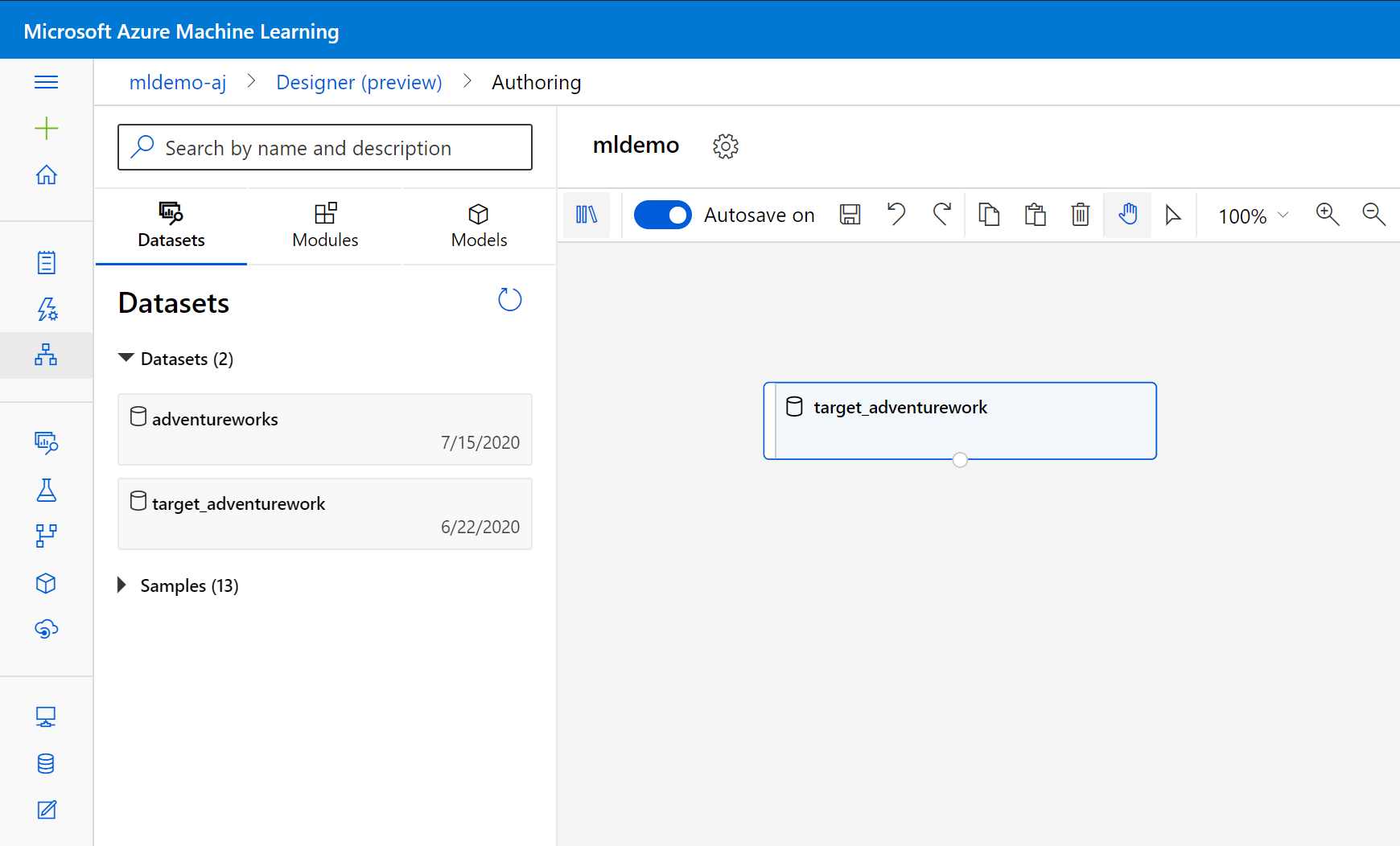
Mengimpor data
Pilih subtab Set data di panel kiri di bawah kotak pencarian.
Seret set data yang telah Anda buat sebelumnya ke kanvas.
Bersihkan data
Untuk membersihkan data, hilangkan kolom yang tidak relevan bagi model. Ikuti langkah berikut:
Pilih subtab Komponen di panel kiri.
Seret komponen Pilih Kolom dalam Himpunan Data pada bagian Transformasi Data < Manipulasi ke dalam kanvas. Sambungkan komponen ini ke komponen Himpunan data.
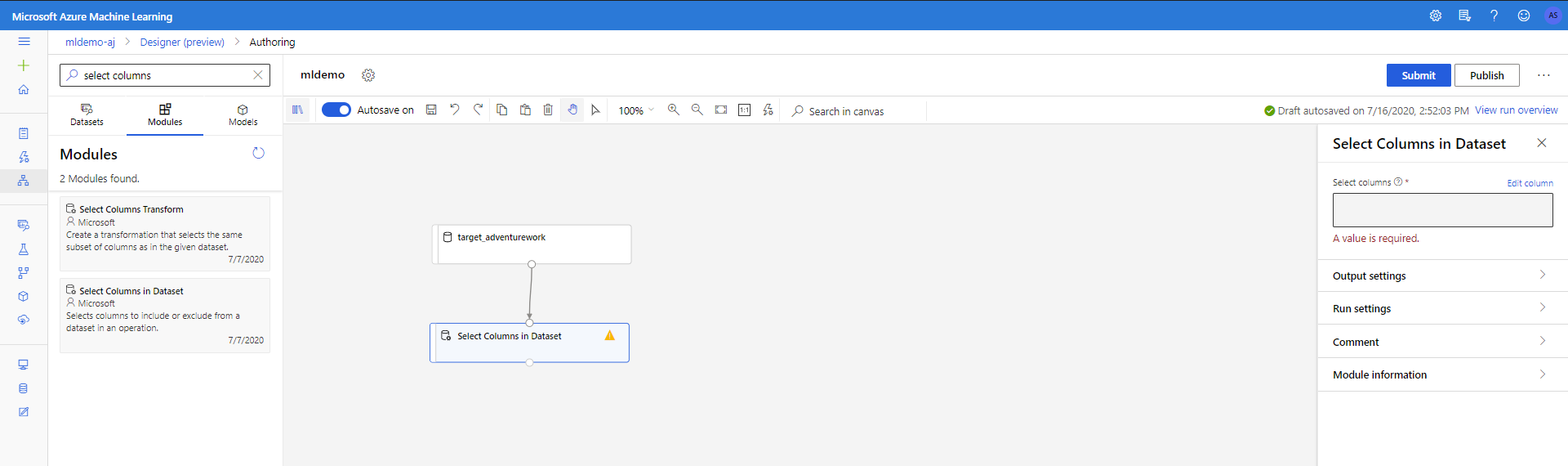
Klik komponen untuk membuka panel properti. Klik Edit kolom untuk menentukan kolom mana yang ingin dihapus.
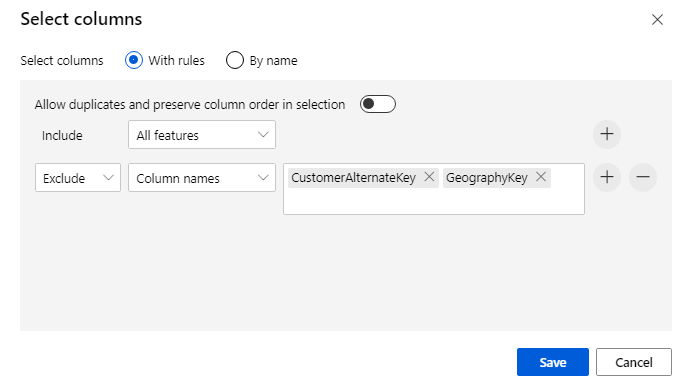
Mengecualikan dua kolom: CustomerAlternateKey serta GeographyKey. Klik Simpan

Pembangunan model
Data dibagi dengan rasio 80-20: 80% untuk melatih model pembelajaran mesin dan 20% untuk menguji model. Algoritma "Dua Kelas" akan digunakan dalam masalah klasifikasi biner ini.
Seret komponen Bagi Data ke kanvas.
Di panel properti, masukkan angka 0,8 untuk Pecahan baris dalam kumpulan data output pertama.
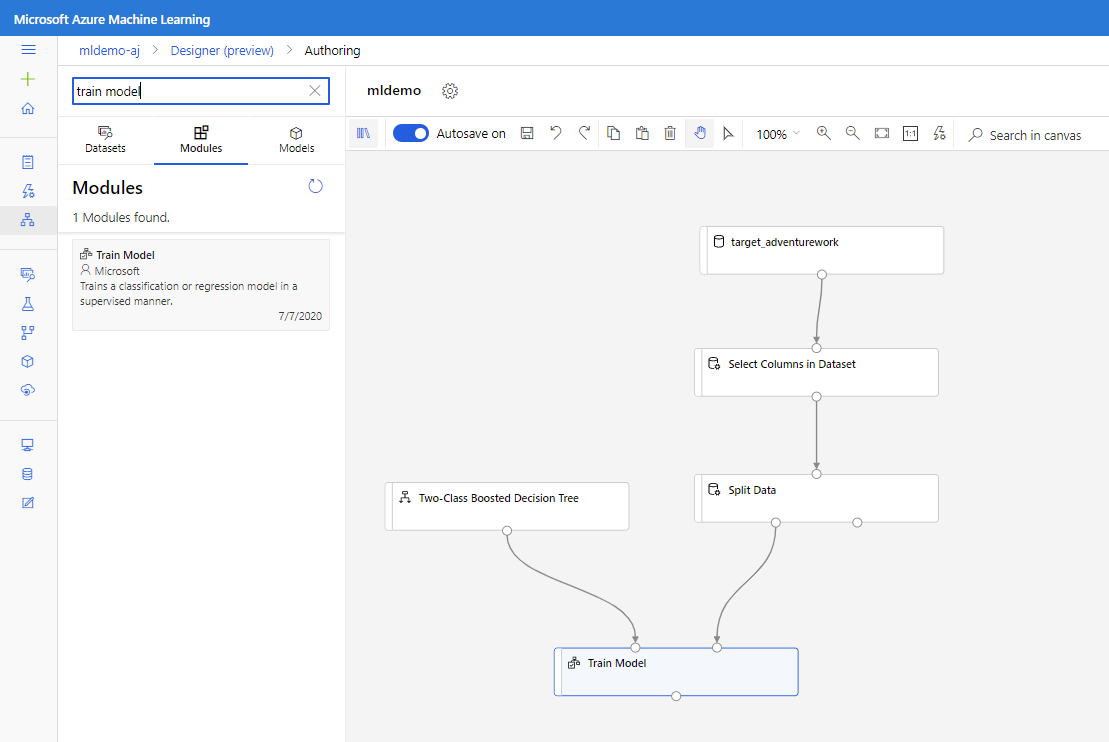
Seret komponen Pohon Keputusan Dua Kelas yang Ditingkatkan ke kanvas.
Seret komponen Latih Model ke kanvas. Tentukan input dengan menyambungkannya ke komponen Pohon Keputusan Dua Kelas yang Ditingkatkan (algoritma ML) serta Bagi Data (data untuk melatih algoritma).
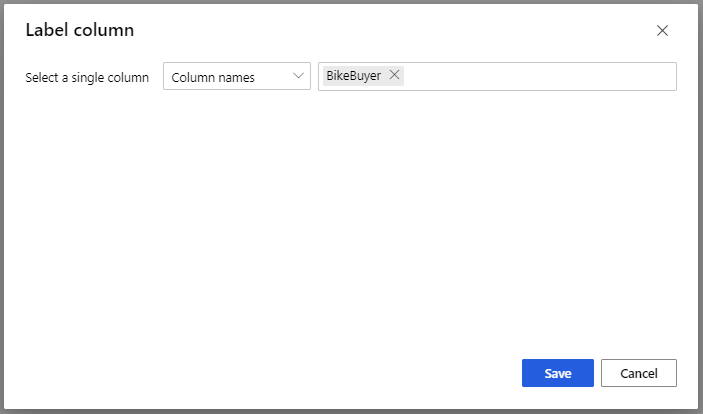
Untuk model Train Model, pada opsi Kolom Label di panel Property, pilih Edit Column. Pilih kolom BikeBuyer sebagai kolom untuk diprediksi serta pilih Simpan.
Beri nilai pada model
Sekarang, ujilah kinerja model pada data pengujian. Dua algoritma yang berbeda akan dibandingkan untuk melihat mana yang memiliki kinerja lebih baik. Ikuti langkah berikut:
Seret Nilai Model ke kanvas dan sambungkan ke komponen Latih Model dan Bagi Data.
Seret Two-Class Bayes Averaged Perceptron ke kanvas percobaan. Anda akan membandingkan kinerja algoritma ini dibandingkan Two-Class Boosted Decision Tree.
Salin dan tempel komponen Latih Model dan Nilai Model di kanvas.
Seret komponen Evaluasi Model ke dalam kanvas untuk membandingkan dua algoritma.
Klik simpan untuk menyiapkan menjalankan pipeline.
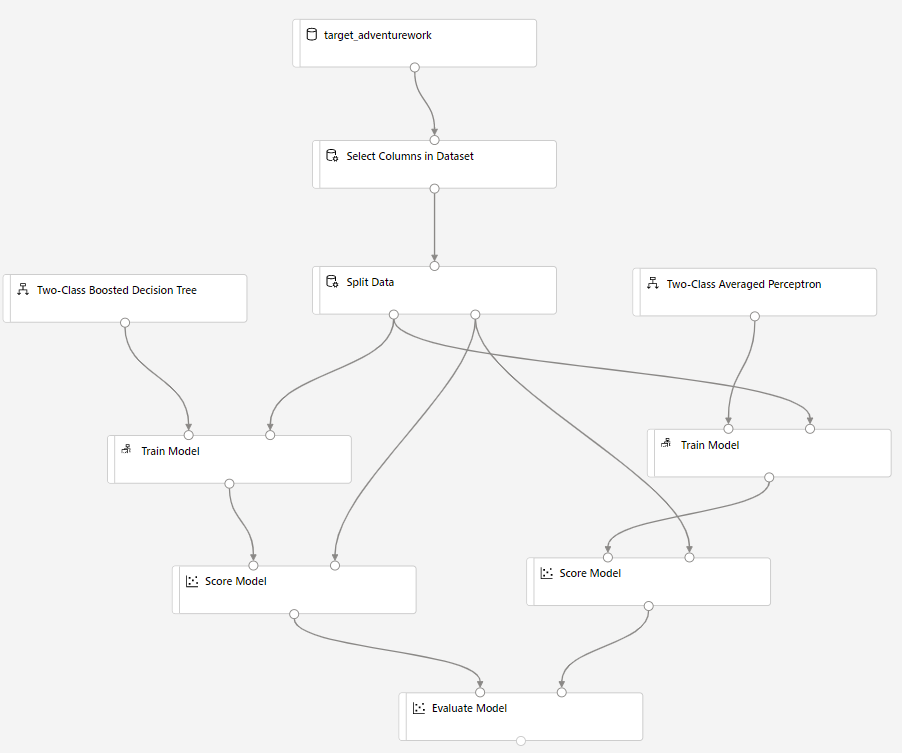
Setelah proses selesai, klik kanan pada komponen Evaluasi Model dan klik Visualisasikan hasil Evaluasi.
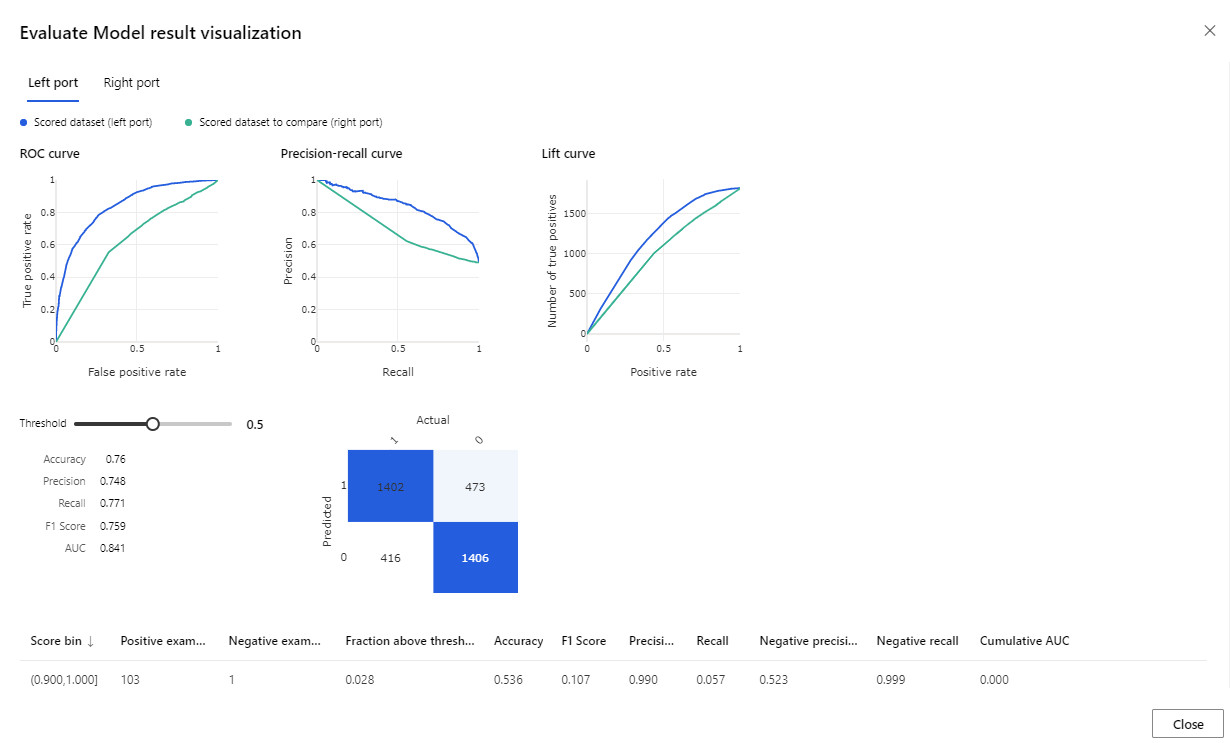

Metrik yang disediakan merupakan kurva ROC, diagram penarikan kembali dengan presisi, dan kurva angkat. Lihatlah metrik ini untuk mengetahui bahwa model pertama memiliki kinerja lebih baik daripada yang kedua. Untuk melihat apa yang diprediksi model pertama, klik kanan pada Komponen Nilai Model dan klik Visualisasikan Himpunan data yang Dinilai untuk melihat hasil yang diprediksi.
Anda akan melihat dua kolom lagi yang telah ditambahkan ke set data pengujian Anda.
- Probabilitas yang Dinilai: kemungkinan pelanggan adalah pembeli sepeda.
- Label yang Dinilai: hasil klasifikasi yang dilakukan oleh model – pembeli sepeda (1) atau tidak (0). Ambang batas probabilitas untuk pelabelan ini diatur ke nilai 50% dan dapat disesuaikan.
Bandingkan kolom BikeBuyer (aktual) dengan Label Yang Dinilai (prediksi) untuk menilai seberapa baik model tersebut berfungsi. Selanjutnya, Anda dapat menggunakan model ini dengan tujuan membuat prediksi bagi pelanggan baru. Anda dapat menerbitkan model ini sebagai layanan web atau menulis hasil kembali ke Azure Synapse.
Langkah berikutnya
Untuk mempelajari selengkapnya tentang Azure Machine Learning, lihat Pendahuluan Pembelajaran Mesin di Azure.
Pelajari tentang penilaian bawaan di gudang data di sini.