Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Halaman ini menjelaskan cara membaca data yang dibagikan dengan Anda menggunakan protokol Delta Sharing berbagi terbuka dengan token pembawa. Ini termasuk instruksi untuk membaca data bersama menggunakan alat berikut:
Dalam model berbagi terbuka ini, Anda menggunakan file kredensial, dibagikan dengan anggota tim Anda oleh penyedia data, untuk mendapatkan akses baca yang aman ke data bersama. Akses bertahan selama kredensial valid dan penyedia terus berbagi data. Penyedia mengelola kedaluwarsa dan rotasi kredensial. Pembaruan pada data tersedia hampir secara real time. Anda dapat membaca dan membuat salinan data bersama, tetapi Anda tidak dapat mengubah data sumber.
Catatan
Jika data telah dibagikan dengan Anda menggunakan Databricks-to-Databricks Delta Sharing, Anda tidak memerlukan file kredensial untuk mengakses data, dan halaman ini tidak berlaku untuk Anda. Sebagai gantinya, lihat Membaca data yang dibagikan menggunakan Databricks Delta Sharing dari Databricks ke Databricks (untuk penerima).
Bagian berikut menjelaskan cara menggunakan klien Azure Databricks, Apache Spark, pandas, Power BI, dan Iceberg untuk mengakses dan membaca data bersama menggunakan file kredensial. Untuk daftar lengkap konektor Delta Sharing dan informasi tentang cara menggunakannya, lihat dokumentasi sumber terbuka Delta Sharing. Jika Anda mengalami masalah saat mengakses data yang dibagi, hubungi penyedia data.
Sebelum Anda memulai
Anggota tim Anda harus mengunduh file kredensial yang dibagikan oleh penyedia data dan menggunakan saluran aman untuk berbagi file atau lokasi file tersebut dengan Anda. Lihat Dapatkan akses pada model berbagi terbuka.
Untuk dokumentasi khusus konektor, lihat halaman unduh kredensial.
Azure Databricks: Membaca data bersama menggunakan konektor berbagi terbuka
Bagian ini menjelaskan cara mengimpor penyedia dan cara mengkueri data bersama di Catalog Explorer atau di buku catatan Python:
Jika ruang kerja Azure Databricks Anda diaktifkan untuk Katalog Unity, gunakan UI Penyedia impor di Catalog Explorer. Anda dapat melakukan hal berikut tanpa perlu menyimpan atau menentukan file kredensial:
- Buat katalog dari file berbagi hanya dengan sekali klik tombol.
- Gunakan kontrol akses Unity Catalog untuk memberikan akses ke tabel bersama.
- Kueri data yang dibagikan menggunakan sintaks Katalog Unity standar.
- Terapkan kredensial yang diputar ke objek penyedia yang ada tanpa membuat ulang katalog. Lihat Memutar kredensial untuk penerima terbuka.
Jika ruang kerja Azure Databricks Anda tidak diaktifkan untuk Katalog Unity, gunakan instruksi buku catatan Python sebagai contoh.
Eksplorer Katalog
Izin diperlukan: Seorang admin metastore atau pengguna yang memiliki hak istimewa CREATE PROVIDER dan USE PROVIDER pada metastore Katalog Unity Anda.
Di ruang kerja Azure Databricks Anda, klik
 Catalog untuk membuka Catalog Explorer.
Catalog untuk membuka Catalog Explorer.Di bagian atas panel Katalog klik
 dan pilih Berbagi Delta.
dan pilih Berbagi Delta.Atau, di sudut kanan atas, klik
Bagikan Delta Sharing . Pada tab Dibagikan dengan saya , klik Impor data.
Masukkan nama penyedia.
Nama tidak dapat menyertakan spasi.
Unggah file kredensial yang dibagikan penyedia dengan Anda.
Banyak penyedia memiliki jaringan Berbagi Delta mereka sendiri dari mana Anda dapat menerima pembagian. Untuk informasi selengkapnya, lihat konfigurasi khusus Penyedia .
(Opsional) Masukkan komentar.
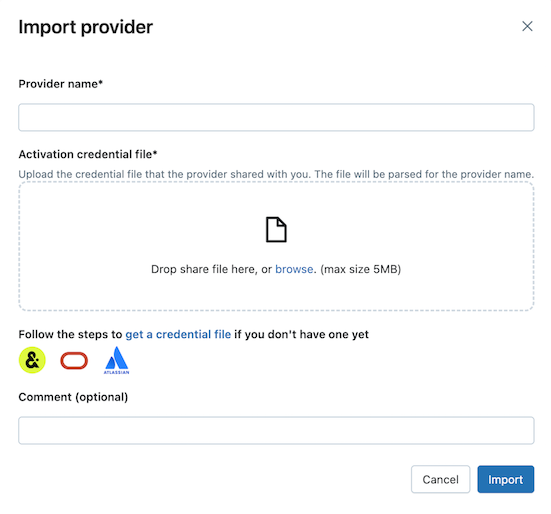
Klik Impor.
Buat katalog dari data bersama.
Pada tab Berbagi, klik Buat katalog pada baris berbagi.
Untuk informasi tentang menggunakan SQL atau Databricks CLI untuk membuat katalog dari berbagi, lihat Membuat katalog dari berbagi.
Berikan akses ke katalog.
Lihat Bagaimana cara menyediakan data yang dibagikan untuk tim saya? dan Mengelola izin untuk skema, tabel, dan volume dalam katalog Delta Sharing.
Baca objek data bersama seperti yang Anda lakukan pada objek data apa pun yang terdaftar di Unity Catalog.
Untuk detail dan contohnya, lihat Mengakses data dalam tabel atau volume bersama.
Python
Bagian ini menjelaskan cara menggunakan konektor berbagi terbuka untuk mengakses data bersama menggunakan buku catatan di ruang kerja Azure Databricks Anda. Anda atau anggota tim Anda lain menyimpan file kredensial di Azure Databricks, lalu menggunakannya untuk mengautentikasi ke akun Azure Databricks penyedia data dan membaca data yang dibagikan penyedia data dengan Anda.
Catatan
Instruksi ini mengasumsikan bahwa ruang kerja Azure Databricks Anda tidak diaktifkan untuk Katalog Unity. Jika Anda menggunakan Katalog Unity, Anda tidak perlu menunjuk ke file kredensial saat membaca dari sumber berbagi. Anda dapat membaca dari tabel bersama seperti yang Anda lakukan dari tabel apa pun yang terdaftar di Katalog Unity. Databricks merekomendasikan agar Anda menggunakan UI penyedia Impor di Catalog Explorer alih-alih instruksi yang diberikan di sini.
Pertama-tama simpan file kredensial sebagai file ruang kerja Azure Databricks sehingga pengguna di tim Anda dapat mengakses data bersama.
Untuk mengimpor file kredensial di ruang kerja Azure Databricks Anda, lihat Apor file.
Berikan izin kepada pengguna lain untuk mengakses file dengan mengklik
 Di samping file, lalu Bagikan (Izin). Masukkan identitas Azure Databricks yang harus memiliki akses ke file.
Di samping file, lalu Bagikan (Izin). Masukkan identitas Azure Databricks yang harus memiliki akses ke file.Untuk informasi selengkapnya tentang izin file, lihat ACL file.
Sekarang setelah file kredensial disimpan, gunakan buku catatan untuk mencantumkan dan membaca tabel bersama.
Di ruang kerja Azure Databricks Anda, klik Notebook Baru>.
Untuk informasi selengkapnya tentang buku catatan Azure Databricks, lihat buku catatan Databricks.
Untuk menggunakan Python atau
pandasuntuk mengakses data bersama, instal konektor Delta-Sharing Python. Di editor buku catatan, tempel perintah berikut:%sh pip install delta-sharingJalankan sel ini.
Pustaka Python
delta-sharingakan diinstal di kluster jika belum terpasang.Menggunakan Python, cantumkan tabel dalam berbagi.
Di sel baru, tempelkan perintah berikut. Ganti jalur ruang kerja dengan jalur menuju file kredensial Anda.
Saat kode berjalan, Python membaca file kredensial.
import delta_sharing client = delta_sharing.SharingClient(f"/Workspace/path/to/config.share") client.list_all_tables()Jalankan sel ini.
Hasilnya adalah array tabel, bersama dengan metadata untuk setiap tabel. Keluaran berikut menunjukkan dua tabel:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Jika output kosong atau tidak berisi tabel yang Anda harapkan, hubungi penyedia data.
Melakukan kueri pada tabel yang dibagikan.
Menggunakan Scala:
Di sel baru, tempelkan perintah berikut. Saat kode berjalan, file kredensial dibaca dari file ruang kerja.
Ganti variabel sebagai berikut:
-
<profile-path>: jalur ruang kerja file kredensial. Contohnya,/Workspace/Users/user.name@email.com/config.share. -
<share-name>: nilaishare=untuk tabel. -
<schema-name>: nilaischema=untuk tabel. -
<table-name>: nilainame=untuk tabel.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Jalankan sel ini. Setiap kali Memuat tabel yang dibagikan, Anda melihat data baru dari sumbernya.
Untuk mengkueri kolom pelacakan baris pada tabel bersama, lihat Membaca kolom pelacakan baris dalam tabel bersama.
-
Menggunakan SQL:
Untuk mengkueri data menggunakan SQL, Anda membuat tabel lokal di ruang kerja dari tabel bersama, lalu mengkueri tabel lokal. Data bersama tidak disimpan atau di-cache dalam tabel lokal. Setiap kali Anda menanyakan tabel lokal, Anda melihat status data yang dibagikan saat ini.
Di sel baru, tempelkan perintah berikut.
Ganti variabel sebagai berikut:
-
<local-table-name>: nama tabel lokal. -
<profile-path>: lokasi file kredensial. -
<share-name>: nilaishare=untuk tabel. -
<schema-name>: nilaischema=untuk tabel. -
<table-name>: nilainame=untuk tabel.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;Saat Anda menjalankan perintah, data yang dibagi akan dikueri secara langsung. Sebagai tes, tabel dikueri dan 10 hasil pertama dikembalikan.
-
Jika output kosong atau tidak berisi data yang Anda harapkan, hubungi penyedia data.
Klien Iceberg: Membaca data yang dibagikan
Penting
Fitur ini ada di Pratinjau Publik.
Gunakan klien Iceberg eksternal, seperti Snowflake, Trino, Flink, dan Spark, untuk membaca aset data bersama dengan akses nol salin menggunakan Apache Iceberg REST Catalog API.
Mendapatkan kredensial koneksi
Sebelum Anda mengakses aset data bersama dengan klien Iceberg eksternal, kumpulkan kredensial berikut:
- Titik akhir Iceberg REST Catalog
- Token Pembawa yang valid
- Nama berbagi jaringan
- (Opsional) Namespace layanan atau nama skema
- (Opsional) Nama tabel
Titik akhir Iceberg REST Catalog (icebergEndpoint) dan token Pembawa ditemukan dalam file kredensial yang dibagikan dengan Anda oleh penyedia data Anda. Untuk informasi selengkapnya, lihat Sebelum Memulai. Nama berbagi, namespace, dan nama tabel dapat ditemukan secara programatis menggunakan Delta Sharing API.
Penting
icebergEndpoint ditemukan dalam file kredensial dan memiliki format <workspace-url>/api/2.0/delta-sharing/metastores/<metastore-id>/iceberg.
Contoh berikut menunjukkan cara mendapatkan kredensial tambahan. Masukkan titik akhir, titik akhir Iceberg, dan token Pembawa dari file kredensial jika diperlukan:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
Catatan
Metode ini selalu mengambil daftar aset yang paling terkini. Namun, dibutuhkan akses internet dan bisa lebih sulit untuk diintegrasikan di lingkungan tanpa kode.
Mengonfigurasi katalog Iceberg
Setelah Anda mendapatkan kredensial koneksi yang diperlukan, konfigurasikan klien Anda untuk menggunakan titik akhir Iceberg REST Catalog untuk membuat dan mengkueri tabel.
Untuk setiap berbagi, buat integrasi katalog.
USE ROLE ACCOUNTADMIN; CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER> CATALOG_SOURCE = ICEBERG_REST TABLE_FORMAT = ICEBERG REST_CONFIG = ( CATALOG_URI = '<icebergEndpoint>', WAREHOUSE = '<share_name>', ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) REST_AUTHENTICATION = ( TYPE = BEARER, BEARER_TOKEN = '<bearerToken>' ) ENABLED = TRUE;Secara opsional, tambahkan
REFRESH_INTERVAL_SECONDSuntuk selalu memperbarui metadata. Atur nilai berdasarkan frekuensi pembaruan katalog Anda.REFRESH_INTERVAL_SECONDS = 30Setelah katalog dikonfigurasi, buat database dari katalog. Ini secara otomatis membuat semua skema dan tabel dalam katalog tersebut.
CREATE DATABASE <DATABASE_PLACEHOLDER> LINKED_CATALOG = ( CATALOG = <CATALOG_PLACEHOLDER> );Untuk mengonfirmasi bahwa berbagi berhasil, lakukan kueri dari tabel dalam database. Anda harus melihat data bersama dari Azure Databricks.
Jika hasilnya kosong atau terjadi kesalahan, ikuti langkah-langkah pemecahan masalah umum berikut:
- Periksa kembali hak istimewa, status pembuatan rekam jepret, dan kredensial REST.
- Hubungi penyedia data Anda.
- Lihat dokumentasi khusus untuk klien Iceberg Anda.
Contoh: Mengakses tabel bersama menggunakan klien Iceberg yang berbeda
Contoh berikut menunjukkan cara mengakses tabel bersama Delta menggunakan klien Iceberg eksternal, seperti Snowflake, Apache Spark, PyIceberg, dan REST API, setelah mendapatkan kredensial koneksi Anda. Untuk informasi selengkapnya tentang mendapatkan kredensial koneksi, lihat Sebelum Memulai.
Snowflake
Untuk membaca aset data bersama di Snowflake, unggah file kredensial yang Anda unduh dan hasilkan perintah SQL yang diperlukan:
Dari tautan aktivasi Berbagi Delta Anda, klik ikon Snowflake.
Pada halaman integrasi Snowflake, unggah file kredensial yang Anda terima dari penyedia data.
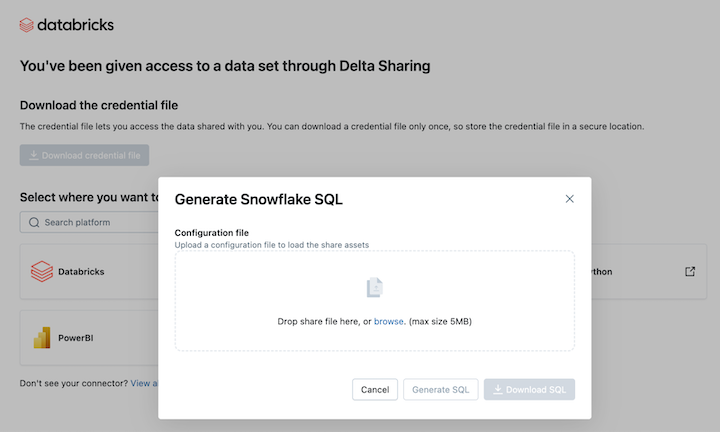
Setelah memuat kredensial, pilih bagian data yang ingin Anda akses di Snowflake.
Klik Buat SQL setelah memilih aset yang diinginkan.
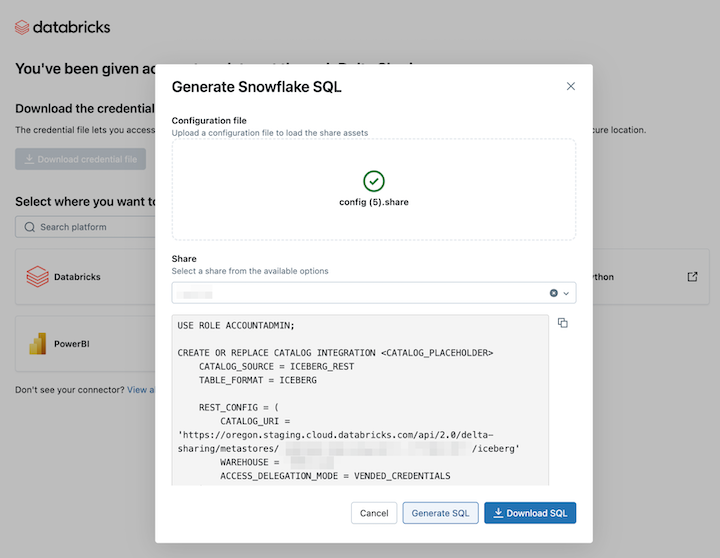
Salin dan tempel SQL yang dihasilkan ke lembar kerja Snowflake Anda. Ganti
CATALOG_PLACEHOLDERdengan nama katalog yang ingin Anda gunakan danDATABASE_PLACEHOLDERdengan nama database yang ingin Anda gunakan.
Keterbatasan
Menyambungkan ke Iceberg REST Catalog di Snowflake memiliki batasan berikut:
- File metadata tidak diperbarui secara otomatis dengan rekam jepret terbaru. Anda harus mengandalkan refresh otomatis atau refresh manual.
- R2 tidak didukung.
- Semua batasan klien Iceberg berlaku.
Apache Spark
Untuk mengakses tabel bersama menggunakan Apache Spark, konfigurasikan Iceberg REST Catalog API dengan pengaturan berikut. Ganti <spark-catalog-name> dengan nama untuk katalog Anda, dan berikan kredensial koneksi Anda:
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
# Configuration for accessing tables shared using Delta Sharing
"spark.sql.catalog.<spark-catalog-name>":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<spark-catalog-name>.type": "rest",
"spark.sql.catalog.<spark-catalog-name>.uri": "<icebergEndpoint>",
"spark.sql.catalog.<spark-catalog-name>.token": "<bearerToken>",
"spark.sql.catalog.<spark-catalog-name>.warehouse":"<share_name>",
"spark.sql.catalog.<spark-catalog-name>.scope":"all-apis"
PyIceberg
PyIceberg adalah implementasi Python untuk mengakses tabel Iceberg tanpa menggunakan JVM. PyIceberg memerlukan pyarrow operasi tabel seperti membaca data dan memeriksa metadata tabel. Instal PyIceberg dengan ekstensi pyarrow.
pip install "pyiceberg[pyarrow]"
Untuk mengakses tabel bersama, tambahkan konfigurasi katalog berikut ke file konfigurasi PyIceberg Anda:
catalog:
delta_sharing:
type: rest
uri: <icebergEndpoint>
warehouse: <share_name>
token: <bearerToken>
REST API
Gunakan panggilan REST API seperti contoh berikut curl untuk memuat tabel dan mengambil metadatanya bersama dengan kredensial sementara untuk mengakses file data:
curl -X GET -H "Authorization: Bearer <bearerToken>" -H "Accept: application/json" \
<icebergEndpoint>/v1/shares/<share_name>/namespaces/<schema_name>/tables/<table_name>
Responsnya mencakup metadata tabel Iceberg, lokasi S3, dan info masuk AWS sementara yang memungkinkan klien Anda membaca file data:
{
"metadata-location": "s3://bucket/path/to/iceberg/table/metadata/file",
"metadata": <iceberg-table-metadata-json>,
"config": {
"expires-at-ms": "<epoch-ts-in-millis>",
"s3.access-key-id": "<temporary-s3-access-key-id>",
"s3.session-token": "<temporary-s3-session-token>",
"s3.secret-access-key": "<temporary-secret-access-key>",
"client.region": "<aws-bucket-region-for-metadata-location>"
}
}
Batasan klien Iceberg
Batasan berikut berlaku saat mengkueri data Berbagi Delta dari klien Iceberg:
- Saat mencantumkan tabel di namespace, jika namespace berisi lebih dari 100 tampilan bersama, respons hanya mencakup 100 tampilan pertama.
Apache Spark: Membaca data bersama
Ikuti langkah-langkah ini untuk mengakses data bersama menggunakan Spark 3.x atau lebih tinggi.
Instruksi ini mengasumsikan bahwa Anda memiliki akses ke file kredensial yang dibagikan oleh penyedia data. Lihat Dapatkan akses pada model berbagi terbuka.
Penting
Pastikan file kredensial Anda dapat diakses oleh Apache Spark dengan menggunakan jalur absolut. Jalur dapat mengacu pada objek cloud atau volume Unity Catalog.
Catatan
Jika Anda menggunakan Spark pada ruang kerja Azure Databricks yang diaktifkan untuk Katalog Unity, dan Anda menggunakan UI penyedia impor untuk mengimpor penyedia dan berbagi, instruksi di bagian ini tidak berlaku untuk Anda. Anda dapat mengakses tabel bersama seperti tabel lain yang terdaftar di Unity Catalog. Anda tidak perlu menginstal konektor delta-sharing Python atau menyediakan jalur ke file kredensial. Lihat Azure Databricks: Baca data bersama menggunakan konektor pembagian terbuka.
Menginstal konektor Delta Sharing Python dan Spark
Untuk mengakses metadata yang terkait dengan data bersama, seperti daftar tabel yang dibagikan dengan Anda, lakukan hal berikut. Contoh ini menggunakan Python.
Instal konektor Python Delta Sharing. Untuk informasi tentang batasan konektor Python, lihat Delta Sharing Python connector limitations.
pip install delta-sharingPasang Konektor Apache Spark.
Menampilkan tabel yang dibagikan menggunakan Spark
Cantumkan tabel dalam berbagi. Dalam contoh di bawah ini, ganti <profile-path> dengan lokasi file kredensial.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Hasilnya adalah array tabel, bersama dengan metadata untuk setiap tabel. Keluaran berikut menunjukkan dua tabel:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Jika output kosong atau tidak berisi tabel yang Anda harapkan, hubungi penyedia data.
Mengakses data bersama menggunakan Spark
Jalankan yang berikut ini, ganti variabel ini:
-
<profile-path>: lokasi file kredensial. -
<share-name>: nilaishare=untuk tabel. -
<schema-name>: nilaischema=untuk tabel. -
<table-name>: nilainame=untuk tabel. -
<version-as-of>: opsional. Versi tabel untuk memasukkan data. Hanya berfungsi jika penyedia data berbagi riwayat tabel.delta-sharing-sparkMembutuhkan 0.5.0 atau lebih tinggi. -
<timestamp-as-of>: opsional. Muat data pada versi sebelum atau pada tanda waktu yang diberikan. Hanya berfungsi jika penyedia data berbagi riwayat tabel.delta-sharing-sparkMembutuhkan 0.6.0 atau lebih tinggi.
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
Scala
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Mengakses umpan data perubahan bersama menggunakan Spark
Jika riwayat tabel telah dibagikan dengan Anda dan mengubah umpan data (CDF) diaktifkan pada tabel sumber, akses umpan data perubahan dengan menjalankan yang berikut ini, menggantikan variabel ini.
delta-sharing-spark Membutuhkan 0.5.0 atau lebih tinggi.
Satu parameter mulai harus disediakan.
-
<profile-path>: lokasi file kredensial. -
<share-name>: nilaishare=untuk tabel. -
<schema-name>: nilaischema=untuk tabel. -
<table-name>: nilainame=untuk tabel. -
<starting-version>: opsional. Versi awal kueri, inklusif. Tentukan sebagai Panjang. -
<ending-version>: opsional. Versi akhir kueri, inklusif. Jika versi akhir tidak disediakan, API menggunakan versi tabel terbaru. -
<starting-timestamp>: opsional. Tanda waktu awal kueri, ini dikonversi ke versi yang dibuat lebih besar atau sama dengan tanda waktu ini. Tentukan sebagai string dalam formatyyyy-mm-dd hh:mm:ss[.fffffffff]. -
<ending-timestamp>: opsional. Tanda waktu akhir kueri, ini dikonversi ke versi yang dibuat sebelumnya atau sama dengan tanda waktu ini. Tentukan sebagai string dalam formatyyyy-mm-dd hh:mm:ss[.fffffffff]
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Jika output kosong atau tidak berisi data yang Anda harapkan, hubungi penyedia data.
Mengakses tabel bersama menggunakan Spark Structured Streaming
Jika riwayat tabel dibagikan dengan Anda, Anda dapat membaca data yang dibagikan secara langsung.
delta-sharing-spark Membutuhkan 0.6.0 atau lebih tinggi.
Opsi yang didukung:
-
ignoreDeletes: Abaikan transaksi yang menghapus data. -
ignoreChanges: Memproses ulang pembaruan jika file ditulis ulang dalam tabel sumber karena operasi perubahan data sepertiUPDATE, ,MERGE INTODELETE(dalam partisi), atauOVERWRITE. Baris yang tidak berubah masih dapat dikeluarkan. Oleh karena itu, konsumen hilir Anda harus dapat menangani duplikat. Penghapusan tidak diteruskan ke hilir.ignoreChangesmeliputiignoreDeletes. Oleh karena itu, jika Anda menggunakanignoreChanges, aliran Anda tidak terganggu oleh penghapusan atau pembaruan ke tabel sumber. -
startingVersion: Versi tabel gabungan untuk memulai. Semua perubahan tabel yang dimulai dari versi ini (inklusif) dibaca oleh sumber streaming. -
startingTimestamp: Penunjuk waktu untuk memulai. Semua perubahan tabel yang dilakukan pada atau setelah tanda waktu (inklusif) dibaca oleh sumber streaming. Contoh:"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: Jumlah file baru yang akan dipertimbangkan dalam setiap mikro-batch. -
maxBytesPerTrigger: Jumlah data yang diproses di setiap mikro-batch. Opsi ini menetapkan "maks lunak", yang berarti batch memproses kira-kira sejumlah data seperti ini dan dapat memproses lebih dari batas tersebut agar kueri streaming bergerak maju, dalam situasi ketika unit input terkecil lebih besar dari batas ini. -
readChangeFeed: Stream membaca umpan data perubahan dari tabel bersama.
Opsi yang tidak didukung:
Trigger.availableNow
Contoh Kueri Streaming Terstruktur
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Lihat juga Konsep Streaming Terstruktur.
Membaca tabel dengan vektor penghapusan atau pemetaan kolom yang diaktifkan
Penting
Fitur ini ada di Pratinjau Publik.
Vektor penghapusan adalah fitur pengoptimalan penyimpanan yang dapat diaktifkan penyedia Anda pada tabel Delta bersama. Lihat Vektor penghapusan di Databricks.
Azure Databricks juga mendukung pemetaan kolom untuk tabel Delta. Lihat mengganti nama dan menghapus kolom dengan menggunakan pemetaan kolom Delta Lake.
Jika penyedia Anda berbagi tabel dengan vektor penghapusan atau pemetaan kolom diaktifkan, Anda dapat membaca tabel menggunakan komputasi yang menjalankan delta-sharing-spark 3.1 atau lebih tinggi. Jika Anda menggunakan kluster Databricks, Anda dapat melakukan pembacaan batch menggunakan kluster yang menjalankan Databricks Runtime 14.1 atau lebih tinggi. Kueri CDF dan streaming memerlukan Databricks Runtime 14.2 atau lebih tinggi.
Anda dapat melakukan kueri batch apa adanya, karena kueri tersebut dapat diselesaikan responseFormat secara otomatis berdasarkan fitur tabel bersama.
Untuk membaca umpan data perubahan (CDF) atau untuk melakukan kueri streaming pada tabel bersama dengan vektor penghapusan atau pemetaan kolom diaktifkan, Anda harus mengatur opsi tambahan responseFormat=delta.
Contoh-contoh berikut menunjukkan kueri batch, CDF, dan streaming.
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Membaca kolom pelacakan baris dalam tabel yang dibagikan
Jika penyedia data telah mengaktifkan pelacakan baris pada tabel bersama, Anda dapat mengkueri kolom metadata pelacakan baris menggunakan Scala Spark. Lihat Pelacakan baris di Databricks untuk daftar kolom yang tersedia.
Anda harus mengatur opsi responseFormat ke delta.
spark.read.format("deltaSharing")
.option("responseFormat", "delta")
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.select("_metadata.row_id")
.show()
Catatan
Hanya format respons delta yang didukung untuk mengkueri kolom pelacakan baris di klien Spark. Konektor cadangan tidak didukung.
Pandas: Baca data yang dibagikan
Ikuti langkah-langkah ini untuk mengakses data bersama di pandas 0.25.3 atau lebih tinggi.
Instruksi ini mengasumsikan bahwa Anda memiliki akses ke file kredensial yang dibagikan oleh penyedia data. Lihat Dapatkan akses pada model berbagi terbuka.
Catatan
Jika Anda menggunakan pandas pada ruang kerja Azure Databricks yang diaktifkan untuk Katalog Unity, dan Anda menggunakan UI penyedia impor untuk mengimpor penyedia dan berbagi, instruksi di bagian ini tidak berlaku untuk Anda. Anda dapat mengakses tabel bersama seperti tabel lain yang terdaftar di Unity Catalog. Anda tidak perlu menginstal konektor delta-sharing Python atau menyediakan jalur ke file kredensial. Lihat Azure Databricks: Baca data bersama menggunakan konektor pembagian terbuka.
menginstal Delta Sharing Python connector
Untuk mengakses metadata yang terkait dengan data bersama, seperti daftar tabel yang dibagikan dengan Anda, Anda harus menginstal konektor Python berbagi delta. Untuk informasi tentang batasan konektor Python, lihat Delta Sharing Python connector limitations.
pip install delta-sharing
Mencantumkan tabel bersama menggunakan pandas
Untuk mencantumkan tabel dalam penyimpanan bersama, jalankan perintah berikut, ganti <profile-path>/config.share dengan lokasi file kredensial.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Jika output kosong atau tidak berisi tabel yang Anda harapkan, hubungi penyedia data.
Mengakses data bersama menggunakan pandas
Untuk mengakses data bersama di pandas menggunakan Python, jalankan hal berikut, ganti variabel sebagai berikut:
-
<profile-path>: lokasi file kredensial. -
<share-name>: nilaishare=untuk tabel. -
<schema-name>: nilaischema=untuk tabel. -
<table-name>: nilainame=untuk tabel.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Mengakses umpan data perubahan bersama menggunakan pandas
Untuk mengakses umpan data perubahan untuk tabel bersama di pandas menggunakan Python jalankan hal berikut, ganti variabel sebagai berikut. Umpan data perubahan mungkin tidak tersedia, tergantung pada apakah penyedia data berbagi umpan data perubahan untuk tabel atau tidak.
-
<starting-version>: opsional. Versi awal kueri, inklusif. -
<ending-version>: opsional. Versi akhir kueri, inklusif. -
<starting-timestamp>: opsional. Tanda waktu awal kueri. Ini dikonversi ke versi yang dibuat lebih besar atau sama dengan tanda waktu ini. -
<ending-timestamp>: opsional. Tanda waktu akhir kueri. Ini dikonversi ke versi yang dibuat sebelumnya atau sama dengan tanda waktu ini.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Jika output kosong atau tidak berisi data yang Anda harapkan, hubungi penyedia data.
Power BI: Membaca data bersama
Konektor Berbagi Delta Power BI memungkinkan Anda menemukan, menganalisis, dan memvisualisasikan himpunan data yang dibagikan dengan Anda melalui protokol terbuka Berbagi Delta.
Persyaratan
- Power BI Desktop 2.99.621.0 atau lebih tinggi.
- Akses ke file kredensial yang dibagikan oleh penyedia data. Lihat Dapatkan akses pada model berbagi terbuka.
Menghubungkan ke Databricks
Untuk menyambungkan ke Azure Databricks menggunakan konektor Berbagi Delta, lakukan hal berikut:
- Buka file kredensial yang dibagikan menggunakan editor teks untuk mengambil URL titik akhir dan token.
- Buka Power BI Desktop.
- Pada menu Dapatkan Data, cari Delta Sharing.
- Pilih konektor dan klik Sambungkan.
- Masukkan URL titik akhir yang Anda salin dari file kredensial ke bidang URL Delta Sharing Server.
- Secara opsional, di tab Opsi Lanjutan, tetapkan Batas Baris untuk jumlah baris maksimum yang dapat Anda unduh. Ini diatur ke 1 juta baris secara default.
- Klik OK.
- Untuk Autentikasi, salin token yang Anda ambil dari file kredensial ke Bearer Token.
- Klik Sambungkan.
Batasan konektor Berbagi Delta Power BI
Konektor Berbagi Delta Power BI memiliki batasan berikut:
- Data yang dimuat konektor harus sesuai dengan memori komputer Anda. Untuk mengelola persyaratan ini, konektor membatasi jumlah baris yang diimpor ke batas Row yang Anda tetapkan di bawah tab Opsi Tingkat Lanjut di Power BI Desktop.
Tableau: Membaca data yang dibagikan
Konektor Berbagi Tableau Delta memungkinkan Anda menemukan, menganalisis, dan memvisualisasikan himpunan data yang dibagikan dengan Anda melalui protokol terbuka Berbagi Delta.
Persyaratan
- Tableau Desktop dan Tableau Server versi 2024.1 atau yang lebih baru
- Akses ke file kredensial yang dibagikan oleh penyedia data. Lihat Dapatkan akses pada model berbagi terbuka.
Menyambungkan ke Azure Databricks
Untuk menyambungkan ke Azure Databricks menggunakan konektor Berbagi Delta, lakukan hal berikut:
- Buka Tableau Exchange, ikuti instruksi untuk mengunduh Konektor Berbagi Delta, dan letakkan di folder desktop yang sesuai.
- Buka Tableau Desktop.
- Pada halaman Konektor, cari "Delta Sharing by Databricks".
- Pilih Berbagi Unggah file, dan pilih file kredensial yang dibagikan oleh penyedia.
- Klik Dapatkan Data.
- Di Data Explorer, pilih tabel.
- Secara opsional tambahkan filter SQL atau batas baris.
- Klik Dapatkan Data Tabel.
Batasan
Konektor Berbagi Tableau Delta memiliki batasan berikut:
- Data yang dimuat konektor harus sesuai dengan memori komputer Anda. Untuk mengelola persyaratan ini, konektor membatasi jumlah baris yang diimpor ke batas baris yang Anda tetapkan di Tableau.
- Semua kolom dikembalikan sebagai jenis
String. - Filter SQL hanya berfungsi jika server Berbagi Delta Anda mendukung predicateHint.
- Vektor penghapusan tidak didukung.
- Pemetaan kolom tidak didukung.
Keterbatasan konektor Delta Sharing Python
Batasan ini khusus untuk konektor Delta Sharing Python:
- Konektor Python Berbagi Delta 1.1.0+ mendukung kueri rekam jepret pada tabel dengan pemetaan kolom tetapi kueri CDF pada tabel dengan pemetaan kolom tidak didukung.
- Konektor Delta Sharing untuk Python mengalami kegagalan saat melakukan kueri CDF dengan
use_delta_format=Truejika skema berubah selama rentang versi yang dikuerikan.
Batasan pada tabel streaming
Anda hanya dapat membaca rekam jepret tabel streaming bersama saat ini. Fitur berikut ini tidak didukung untuk tabel streaming dalam berbagi terbuka:
- Mengkueri data riwayat tabel
- Mengkueri umpan data perubahan tabel (CDF)
- Menggunakan tabel sebagai sumber untuk Spark Structured Streaming
Batasan tampilan materialisasi
Anda hanya dapat membaca rekam jepret tampilan terwujud bersama saat ini. Menggunakan tampilan materialisasi sebagai sumber dari Spark Structured Streaming tidak didukung dalam pembagian terbuka.
Meminta kredensial baru
Jika URL aktivasi kredensial atau kredensial yang diunduh hilang, rusak, atau disusupi, atau kredensial Anda kedaluwarsa tanpa penyedia mengirimi Anda info masuk baru, hubungi penyedia Anda untuk meminta kredensial baru.
Jika Anda adalah penerima Azure Databricks yang mengimpor kredensial sebagai objek penyedia di Unity Catalog, terapkan kredensial baru menggunakan Databricks REST API. Lihat Mengganti kredensial untuk penerima publik.