Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Fitur ini ada di Pratinjau Publik.
Penting
Artikel ini menjelaskan pengalaman menggunakan tabel inferensi versi lama, yang hanya relevan untuk throughput yang telah ditetapkan dan titik akhir penyajian model kustom.
- Mulai 20 Februari 2026, tabel inferensi warisan tidak dapat diaktifkan pada model baru atau yang sudah ada yang melayani titik akhir.
- Mulai 30 April 2026, pengalaman tabel inferensi warisan tidak akan lagi didukung.
Databricks merekomendasikan tabel inferensi yang didukung AI Gateway untuk ketersediaannya pada model kustom, model fondasi, dan agen yang melayani titik akhir. Lihat Memigrasikan ke tabel inferensi Gateway AI untuk instruksi tentang migrasi ke tabel inferensi dengan dukungan Gateway AI.
Catatan
Jika Anda melayani aplikasi AI gen di Databricks, Anda dapat menggunakan pemantauan AI gen Databricks untuk menyiapkan tabel inferensi secara otomatis dan melacak metrik operasional dan kualitas untuk aplikasi Anda.
Artikel ini menjelaskan tabel inferensi untuk memantau model yang dilayani. Diagram berikut menunjukkan alur kerja umum dengan tabel inferensi. Tabel inferensi secara otomatis menangkap permintaan masuk dan respons keluar untuk endpoint layanan model dan mencatatnya sebagai tabel Delta Unity Catalog. Anda dapat menggunakan data dalam tabel ini untuk memantau, men-debug, dan meningkatkan model ML.
alur kerja tabel Inferensi
Apa itu tabel inferensi?
Memantau performa model dalam alur kerja produksi adalah aspek penting dari siklus hidup model AI dan ML. Tabel inferensi mempermudah pemantauan dan diagnostik untuk model dengan terus mencatat input permintaan dan respons (prediksi) dari endpoint Model Serving AI Mosaic dan menyimpannya ke dalam tabel Delta di Unity Catalog. Anda kemudian dapat menggunakan semua kemampuan platform Databricks, seperti kueri Databricks SQL, notebook, dan pembuatan profil data untuk memantau, men-debug, dan mengoptimalkan model Anda.
Anda dapat mengaktifkan tabel inferensi pada model yang sudah ada atau yang baru dibuat yang melayani titik akhir, dan permintaan ke titik akhir tersebut kemudian secara otomatis dicatat ke tabel di UC.
Beberapa aplikasi umum untuk tabel inferensi adalah sebagai berikut:
- Memantau data dan kualitas model. Anda dapat terus memantau performa model dan penyimpangan data menggunakan pembuatan profil data. Pembuatan profil data secara otomatis menghasilkan dasbor kualitas data dan model yang dapat Anda bagikan dengan pemangku kepentingan. Selain itu, Anda dapat mengaktifkan pemberitahuan untuk mengetahui kapan Anda perlu melatih kembali model Anda berdasarkan pergeseran dalam data masuk atau pengurangan performa model.
- Menyelesaikan masalah produksi. Tabel Inferensi mencatat data seperti kode status HTTP, waktu eksekusi model, dan kode JSON untuk permintaan dan respons. Anda dapat menggunakan data performa ini untuk tujuan mengurai kesalahan. Anda juga dapat menggunakan data historis dalam Tabel Inferensi untuk membandingkan performa model pada permintaan historis.
- Buat korpus pelatihan. Dengan menggabungkan Tabel Inferensi dengan label kebenaran dasar, Anda dapat membuat korpus pelatihan yang dapat Anda gunakan untuk melatih kembali atau menyempurnakan dan meningkatkan model Anda. Dengan Menggunakan Pekerjaan Lakeflow, Anda dapat menyiapkan perulangan umpan balik berkelanjutan dan mengotomatiskan pelatihan ulang.
Persyaratan
- Ruang kerja Anda harus mengaktifkan Katalog Unity.
- Pembuat titik akhir dan pengubah harus memiliki izin Dapat Mengelola pada titik akhir. Lihat Daftar kontrol akses.
- Pembuat titik akhir dan pengubah harus memiliki izin berikut di Katalog Unity:
-
USE CATALOGhak akses pada katalog yang ditentukan. -
USE SCHEMAhak akses pada skema yang ditentukan. -
CREATE TABLEhak akses dalam skema.
-
Mengaktifkan dan menonaktifkan tabel inferensi
Bagian ini memperlihatkan kepada Anda cara mengaktifkan atau menonaktifkan tabel inferensi menggunakan UI Databricks. Anda juga dapat menggunakan API; lihat Mengaktifkan tabel inferensi pada titik akhir penyajian model menggunakan API untuk instruksi.
Pemilik tabel inferensi adalah pengguna yang membuat titik akhir. Semua daftar kontrol akses (ACL) pada tabel mengikuti izin Katalog Unity standar dan dapat dimodifikasi oleh pemilik tabel.
Peringatan
Tabel inferensi bisa menjadi rusak jika Anda melakukan salah satu hal berikut:
- Ubah skema tabel.
- Ubah nama tabel.
- Hapus tabel.
- Kehilangan izin pada katalog atau skema Unity Catalog.
Dalam kasus ini, status auto_capture_config dari titik akhir menunjukkan keadaan FAILED untuk tabel payload. Jika ini terjadi, Anda harus membuat titik akhir baru untuk terus menggunakan tabel inferensi.
Untuk mengaktifkan tabel inferensi selama pembuatan titik akhir, gunakan langkah-langkah berikut:
Klik Melayani di antarmuka pengguna Databricks Mosaic AI.
Klik Buat titik akhir penayangan.
Pilih Aktifkan tabel inferensi.
Di menu drop-down, pilih katalog dan skema yang diinginkan tempat Anda ingin tabel berada.
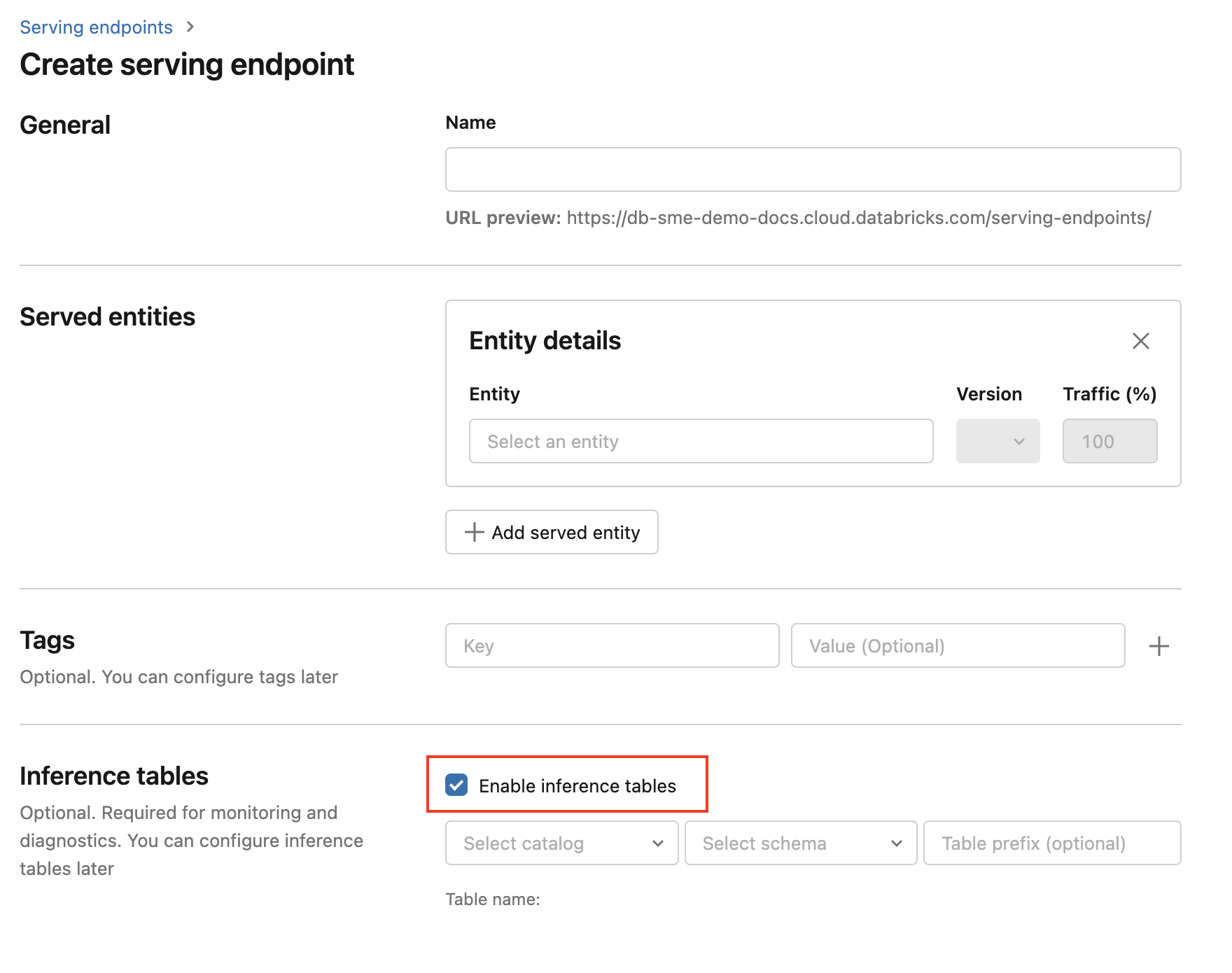
Nama tabel default adalah
<catalog>.<schema>.<endpoint-name>_payload. Jika diinginkan, Anda dapat memasukkan awalan tabel kustom.Klik Buat titik akhir penayangan.
Anda juga dapat mengaktifkan tabel inferensi pada titik akhir yang ada. Untuk mengedit konfigurasi titik akhir yang sudah ada, lakukan hal berikut:
- Navigasi ke halaman titik akhir Anda.
- Klik Sunting konfigurasi.
- Ikuti instruksi sebelumnya, dimulai dengan langkah 3.
- Setelah selesai, klik Perbarui endpoint layanan.
Ikuti instruksi berikut untuk menonaktifkan tabel inferensi:
- Navigasi ke halaman titik akhir Anda.
- Klik Sunting konfigurasi.
- Klik Aktifkan tabel inferensi untuk menghapus tanda centang.
- Setelah Anda puas dengan spesifikasi titik akhir, klik Perbarui.
Migrasi ke tabel inferensi Gateway AI
Penting
Setelah titik akhir bermigrasi untuk menggunakan tabel inferensi Gateway AI, titik akhir tidak dapat beralih kembali ke tabel warisan.
Catatan
Tabel inferensi AI Gateway memiliki skema yang berbeda dibandingkan dengan tabel inferensi warisan.
Untuk informasi harga, lihat halaman harga Mosaic AI Gateway.
Bagian ini menjelaskan cara bermigrasi dari tabel inferensi warisan ke tabel inferensi Gateway AI.
Ada dua langkah utama untuk memperbarui konfigurasi:
- Perbarui titik akhir penyajian untuk menonaktifkan tabel inferensi warisan.
- Perbarui titik akhir penyajian untuk mengaktifkan tabel inferensi Gateway AI.
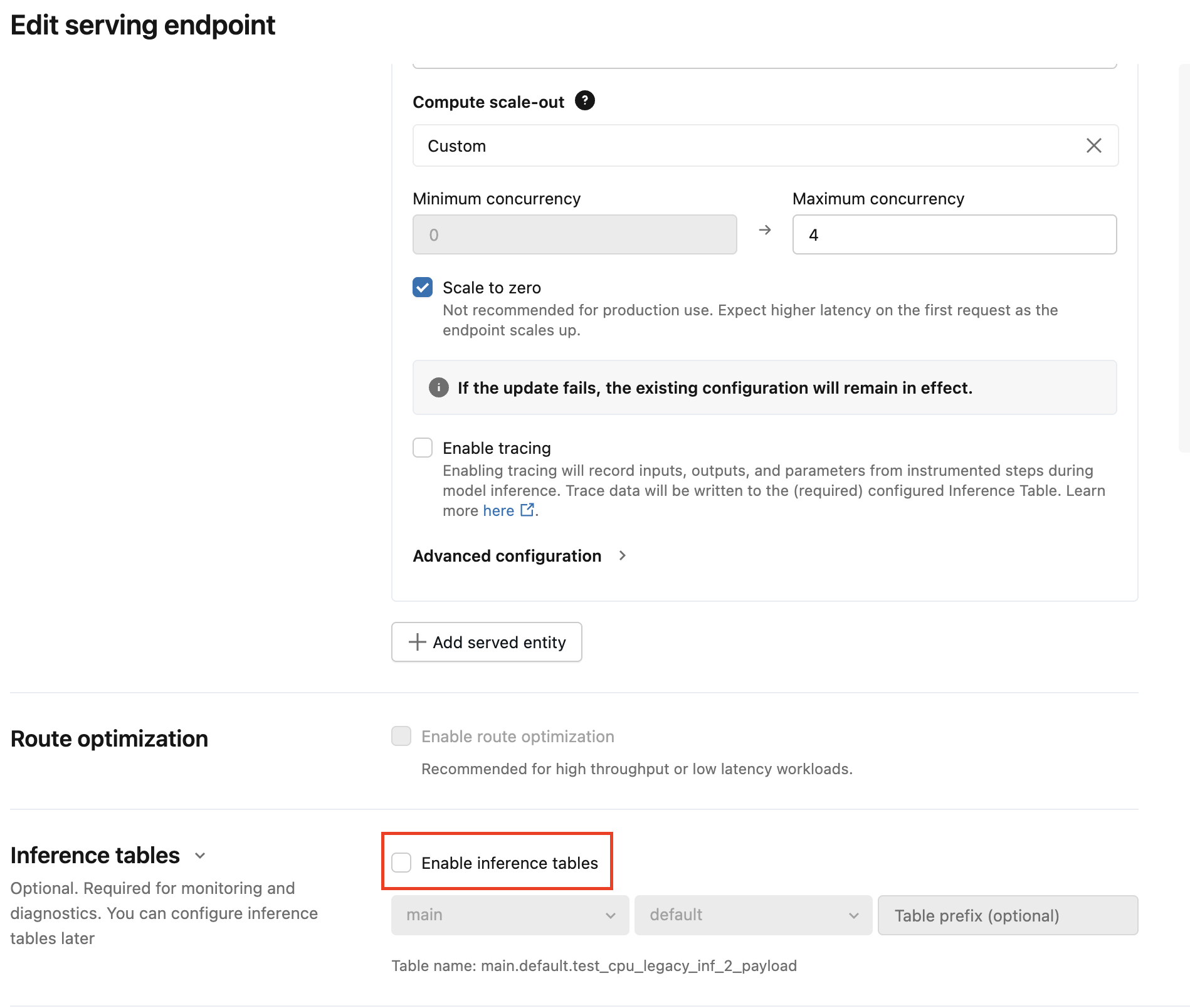
Menggunakan UI untuk memigrasikan konfigurasi tabel inferensi
Untuk sejumlah kecil titik akhir penyajian, edit konfigurasi titik akhir di UI:
Klik Melayani di antarmuka pengguna Databricks Mosaic AI dan navigasikan ke halaman titik akhir Anda.
Klik Sunting konfigurasi.
Klik Aktifkan tabel inferensi untuk menghapus tanda centang.
klik Perbarui dan tunggu status titik akhir menjadi Siap.
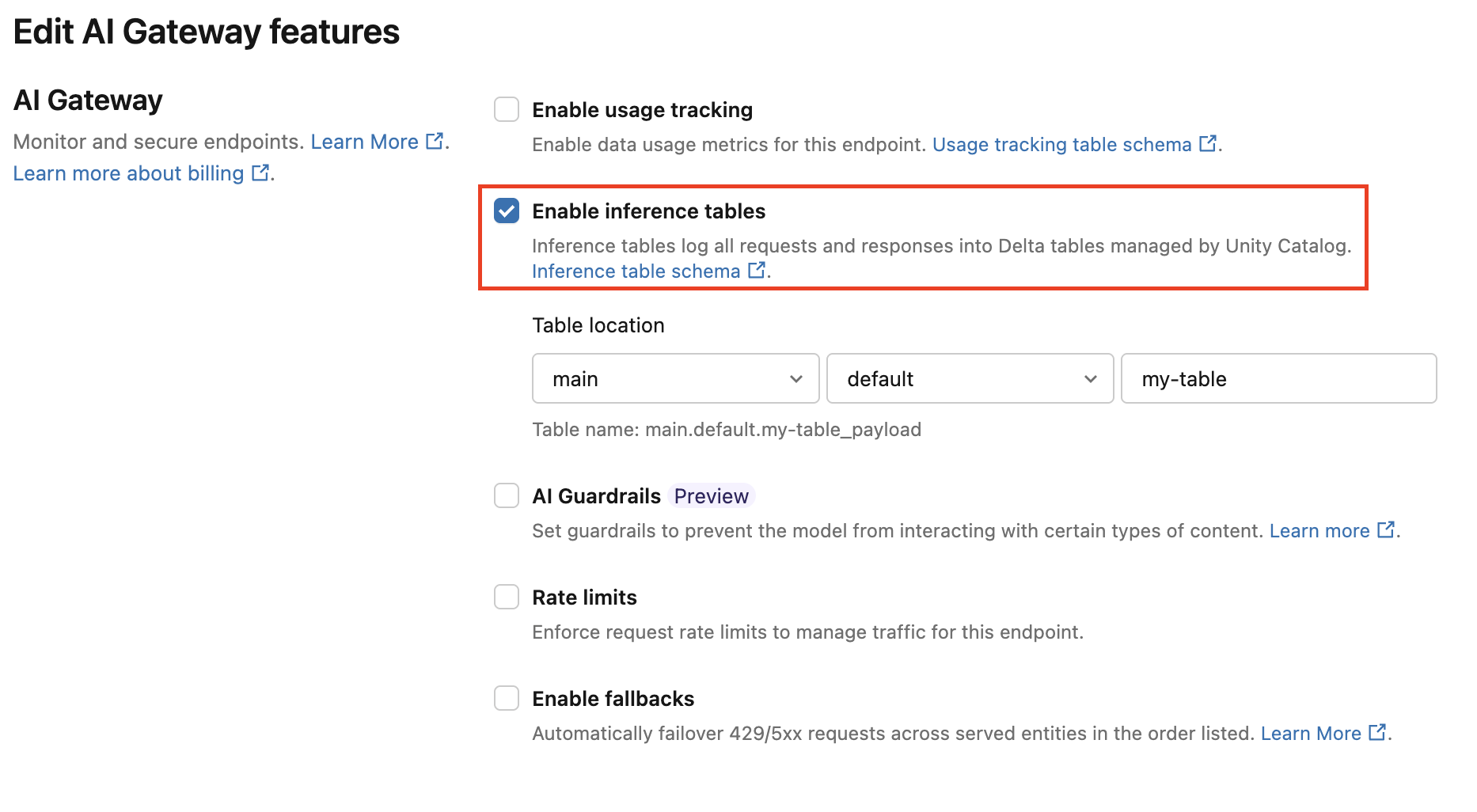
Ikuti instruksi berikut untuk mengaktifkan tabel inferensi Gateway AI:
Klik Melayani di antarmuka pengguna Databricks Mosaic AI dan navigasikan ke halaman titik akhir Anda.
Klik AI Gateway Edit.
Klik Aktifkan tabel inferensi.
Di menu drop-down, pilih katalog dan skema yang diinginkan tempat Anda ingin tabel berada.
Nama tabel default adalah
<catalog>.<schema>.<endpoint-name>_payload. Secara opsional, masukkan awalan tabel kustom.Klik Perbarui.
Menggunakan buku catatan untuk memigrasikan konfigurasi tabel inferensi
Untuk banyak titik akhir, Anda dapat menggunakan API untuk mengotomatiskan proses migrasi. Databricks menyediakan buku catatan contoh yang memigrasikan batch titik akhir layanan dan contoh cara memigrasikan data yang ada dari tabel inferensi lama ke tabel inferensi Gerbang AI.
Memigrasikan ke buku catatan tabel inferensi Gateway AI
alur kerja : Memantau performa model menggunakan tabel inferensi
Untuk memantau performa model menggunakan tabel inferensi, ikuti langkah-langkah berikut:
- Aktifkan tabel inferensi di titik akhir Anda, baik selama pembuatan titik akhir atau dengan memperbaruinya setelahnya.
- Jadwalkan alur kerja untuk memproses payload JSON dalam tabel inferensi dengan membongkarnya sesuai dengan skema titik akhir.
- (Opsional) Gabungkan permintaan dan respons yang tidak dikemas dengan label kebenaran dasar untuk memungkinkan metrik kualitas model dihitung.
- Buat monitor di atas tabel Delta yang dihasilkan dan refresh metrik.
Buku catatan pemula mengimplementasikan alur kerja ini.
Buku catatan pemula untuk memantau tabel inferensi
Notebook berikut menerapkan langkah-langkah yang diuraikan di atas untuk membongkar permintaan dari tabel inferensi pembuatan profil data. Notebook dapat dijalankan sesuai permintaan, atau pada jadwal berulang menggunakan Lakeflow Jobs.
Buku catatan permulaan pembuatan profil data tabel inferensi
Buku catatan awal untuk memantau kualitas teks dari antarmuka yang menangani LLM
Buku catatan berikut membongkar permintaan dari tabel inferensi, menghitung serangkaian metrik evaluasi teks (seperti keterbacaan dan toksisitas), dan memungkinkan pemantauan atas metrik ini. Notebook dapat dijalankan sesuai permintaan, atau pada jadwal berulang menggunakan Lakeflow Jobs.
Notebook awal untuk pemprofilan data tabel inferensi LLM
Mengkueri dan menganalisis hasil dalam tabel inferensi
Setelah model yang dilayani siap, semua permintaan yang dibuat untuk model Anda dicatat secara otomatis ke tabel inferensi, bersama dengan respons. Anda bisa menampilkan tabel di UI, mengkueri tabel dari DBSQL atau buku catatan, atau mengkueri tabel menggunakan REST API.
Untuk menampilkan tabel di UI: Pada halaman titik akhir, klik nama tabel inferensi untuk membuka tabel di Catalog Explorer.

Untuk mengkueri tabel dari DBSQL atau buku catatan Databricks: Anda bisa menjalankan kode yang mirip dengan yang berikut ini untuk mengkueri tabel inferensi.
SELECT * FROM <catalog>.<schema>.<payload_table>
Jika Anda mengaktifkan tabel inferensi menggunakan UI, payload_table adalah nama tabel yang Anda tetapkan saat membuat titik akhir. Jika Anda mengaktifkan tabel inferensi menggunakan API, payload_table dilaporkan di bagian state respons auto_capture_config. Misalnya, lihat Mengaktifkan tabel inferensi pada model yang melayani titik akhir menggunakan API.
Catatan performa
Setelah memanggil titik akhir, Anda dapat melihat pemanggilan yang dicatat ke tabel inferensi Anda dalam waktu satu jam setelah mengirim permintaan penilaian. Selain itu, Azure Databricks menjamin pengiriman log terjadi setidaknya sekali, sehingga mungkin, meskipun tidak mungkin, log duplikat tersebut dikirim.
skema tabel penarikan kesimpulan Katalog Unity
Setiap permintaan dan respons yang dicatat ke tabel inferensi ditulis ke tabel Delta dengan skema berikut:
Catatan
Jika Anda memanggil endpoint dengan sekumpulan input, seluruh batch dicatat sebagai satu baris.
| Nama kolom | Deskripsi | Jenis |
|---|---|---|
databricks_request_id |
Pengidentifikasi permintaan yang dihasilkan Azure Databricks yang dilampirkan pada semua permintaan penyajian model. | TALI |
client_request_id |
Pengidentifikasi permintaan opsional yang dihasilkan klien yang dapat ditentukan dalam isi permintaan pemrosesan model. Lihat Tentukan client_request_id untuk informasi selengkapnya. |
TALI |
date |
Tanggal UTC ketika permintaan untuk melayani model diterima. | TANGGAL |
timestamp_ms |
Stempel waktu dalam milidetik epoch ketika permintaan penyajian model diterima. | panjang |
status_code |
Kode status HTTP yang dikembalikan dari model. | INT |
sampling_fraction |
Fraksi penyampelan yang digunakan dalam kasus ketika permintaan telah dikurangi samplingnya. Nilai ini berada antara 0 dan 1, di mana 1 menunjukkan bahwa 100% permintaan masuk telah disertakan. | Ganda |
execution_time_ms |
Waktu eksekusi dalam milidetik yang modelnya melakukan inferensi. Ini tidak termasuk latensi jaringan overhead dan hanya mewakili waktu yang diperlukan model untuk menghasilkan prediksi. | panjang |
request |
Isi JSON permintaan mentah yang dikirim ke endpoint yang melayani model. | TALI |
response |
Isi JSON respons mentah yang dikembalikan oleh model yang melayani titik akhir. | TALI |
request_metadata |
Peta metadata yang terkait dengan model yang melayani titik akhir yang terkait dengan permintaan. Peta ini berisi nama titik akhir, nama model, dan versi model yang digunakan untuk titik akhir Anda. | PETA<STRING, STRING> |
Menentukan client_request_id
Bidang client_request_id adalah nilai opsional yang dapat diberikan pengguna dalam model yang melayani isi permintaan. Hal ini memungkinkan pengguna untuk memberikan pengidentifikasi mereka sendiri untuk permintaan yang muncul di tabel inferensi akhir di bawah client_request_id dan dapat digunakan untuk menggabungkan permintaan mereka dengan tabel lain yang menggunakan client_request_id, seperti menggabungkan dengan label kebenaran dasar. Untuk menentukan client_request_id, sertakan sebagai kunci tingkat atas payload permintaan. Jika tidak client_request_id ditentukan, nilai muncul sebagai null di baris yang sesuai dengan permintaan.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
client_request_id nantinya dapat digunakan untuk gabungan label kebenaran dasar jika ada tabel lain yang memiliki label yang terkait dengan client_request_id.
Batasan
- Kunci yang dikelola pelanggan tidak didukung.
- Untuk endpoint yang menghosting model fondasi , tabel inferensi hanya didukung pada throughput yang telah disediakan beban kerja.
- Azure Firewall dapat mengakibatkan kegagalan untuk membuat tabel Delta Katalog Unity, jadi tidak didukung secara default. Hubungi tim akun Databricks Anda untuk mengaktifkannya.
- Saat tabel inferensi diaktifkan, batas untuk total konkurensi maksimum di semua model yang digunakan dalam satu titik akhir adalah 128. Hubungi tim akun Azure Databricks Anda untuk meminta peningkatan batas ini.
- Jika tabel inferensi berisi lebih dari 500K file, tidak ada data tambahan yang dicatat. Untuk menghindari melebihi batas ini, jalankan OPTIMIZE atau siapkan retensi pada tabel Anda dengan menghapus data yang lebih lama. Untuk memeriksa jumlah file dalam tabel Anda, jalankan
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>. - Pengiriman log tabel inferensi saat ini adalah upaya terbaik, tetapi Anda dapat mengharapkan log tersedia dalam waktu 1 jam dari permintaan. Hubungi tim akun Databricks Anda untuk informasi selengkapnya.
Untuk batasan umum pada titik akhir penyajian model, lihat Batas dan wilayah Penyajian Model.