Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan cara menggunakan eksekusi MLflow untuk melihat dan menganalisis hasil eksperimen pelatihan model, dan cara mengelola dan mengatur eksekusi. Untuk informasi selengkapnya tentang eksperimen MLflow, lihat Mengatur eksekusi pelatihan dengan eksperimen MLflow.
Run MLflow berkaitan dengan satu eksekusi kode model. Pada setiap run, mencatat informasi seperti notebook yang meluncurkan run, model yang dibuat oleh run, parameter model dan metrik yang disimpan sebagai pasangan kunci-nilai, tag untuk metadata run, dan artefak atau file output yang dibuat oleh run.
Semua eksekusi MLflow dicatat ke eksperimen aktif. Jika Anda belum secara eksplisit menetapkan eksperimen sebagai eksperimen aktif, eksekusi akan dicatat ke eksperimen notebook.
Lihat detail jalankan
Anda dapat mengakses eksekusi baik dari halaman detail eksperimennya atau langsung dari buku catatan yang membuat eksekusi.
Dari halaman detail eksperimen , klik nama percobaan dalam tabel percobaan.
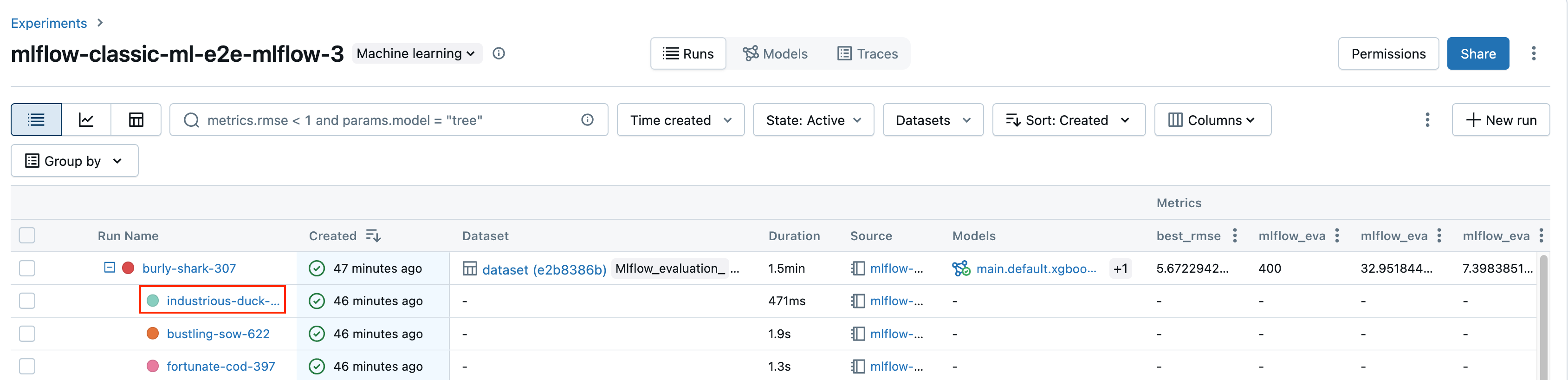
Dari buku catatan, klik nama eksekusi di bilah samping Eksekusi Eksperimen.
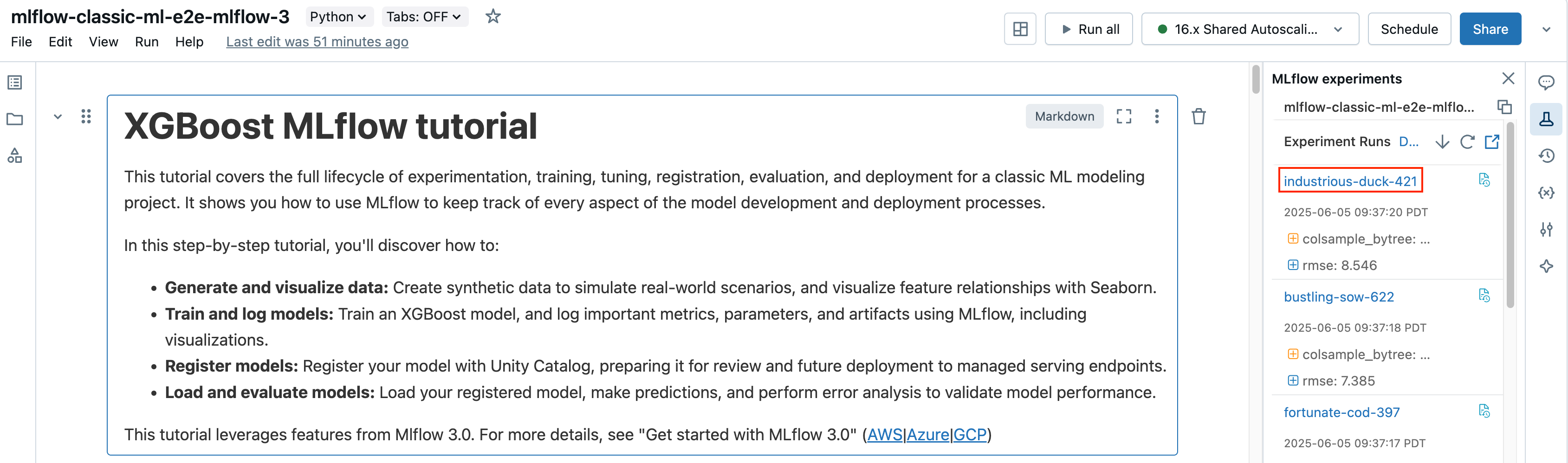
Layar eksekusi memperlihatkan ID eksekusi, parameter yang digunakan untuk eksekusi, metrik yang dihasilkan dari eksekusi, dan detail tentang eksekusi termasuk tautan ke buku catatan sumber. Artefak yang disimpan dari proses eksekusi tersedia di tab Artefak.
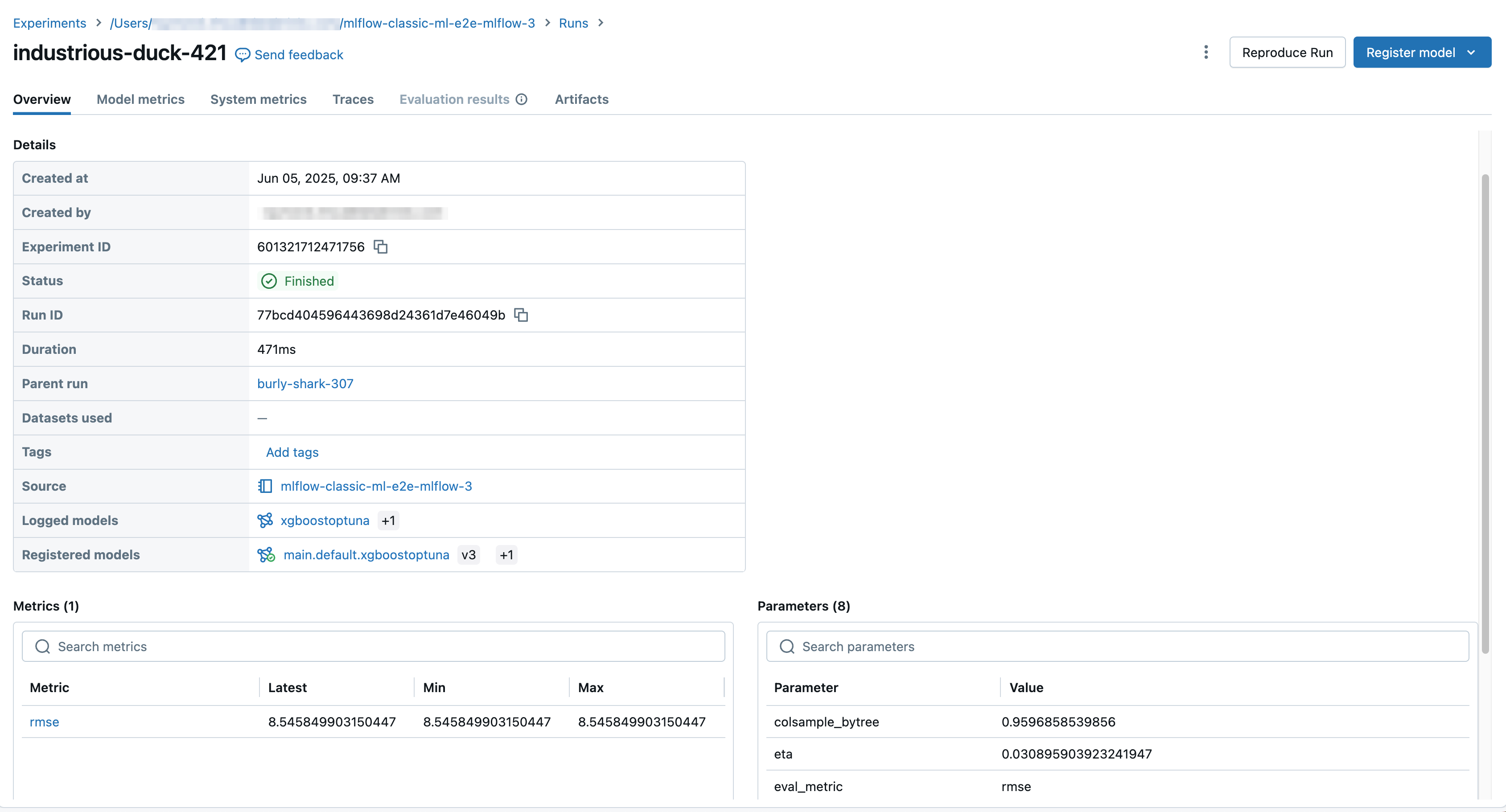
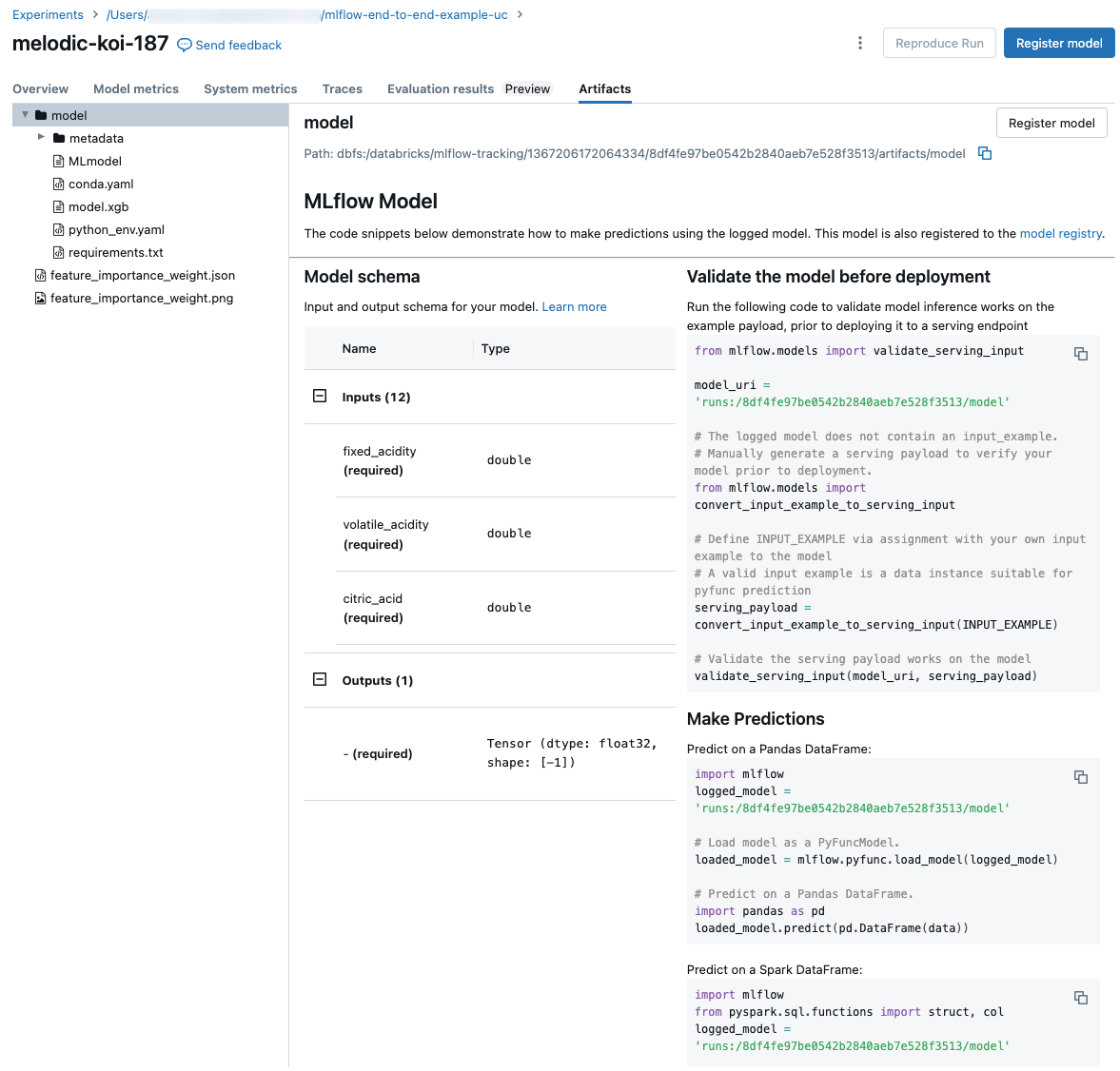
Cuplikan kode untuk prediksi
Jika Anda melog model dari suatu proses, model tersebut muncul di tab Artefak, bersama dengan cuplikan kode yang menunjukkan cara memuat dan menggunakan model untuk membuat prediksi pada Spark dan Pandas DataFrames. Di MLflow 3, model sekarang adalah objek kelas pertama yang terpisah, bukan lagi dicatat sebagai artefak eksekusi. Untuk informasi selengkapnya, lihat Mulai menggunakan MLflow 3 untuk model.
Menampilkan buku catatan yang digunakan untuk menjalankan
Untuk melihat versi notebook yang membuat eksekusi:
- Pada halaman detail eksperimen, klik tautan di kolom Sumber
. - Pada halaman eksekusi, klik link di samping Sumber.
- Dari buku catatan, di bilah samping Eksperimen Berjalan, klik ikon Versi Notebook ikon Buku Catatan di kotak untuk Eksperimen Berjalan.
Versi notebook yang terkait dengan eksekusi muncul di jendela utama dengan bilah sorotan yang menunjukkan tanggal dan waktu eksekusi.
Menambahkan tag ke sebuah proses
Tags adalah pasangan nilai-kunci yang dapat Anda buat dan gunakan nanti untuk mencari proses.
Di tabel Detail pada halaman jalankan, klik Tambahkan tag di samping Tag.

Dialog Tambahkan/Edit tag terbuka. Di bidang Kunci
, masukkan nama untuk kunci, dan klik Tambahkan tag .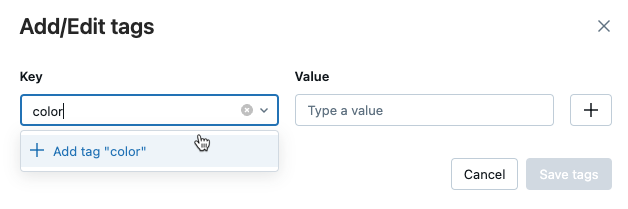
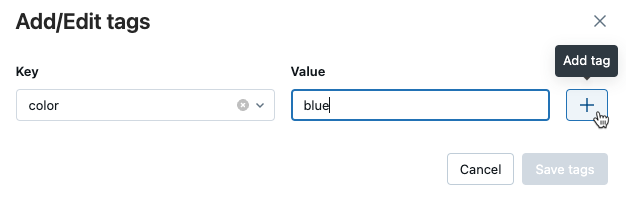
Di bidang Nilai
, masukkan nilai untuk tag. Klik tanda plus untuk menyimpan pasangan kunci-nilai yang baru saja Anda masukkan.
Untuk menambahkan tag tambahan, ulangi langkah 2 hingga 4.
Setelah selesai, klik Simpan tag.
Mengedit atau menghapus tag untuk menjalankan tugas
Di tabel Detail pada halaman jalankan, klik
 di samping tag yang ada.
di samping tag yang ada.
Dialog Tambahkan/Edit tag terbuka.
Untuk menghapus tag, klik X pada tag tersebut.
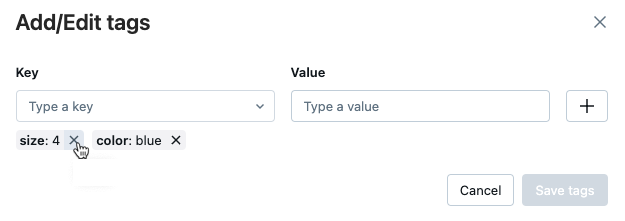
Untuk mengedit tag, pilih kunci dari menu drop-down, dan edit nilai di bidang Nilai. Klik tanda plus untuk menyimpan perubahan Anda.
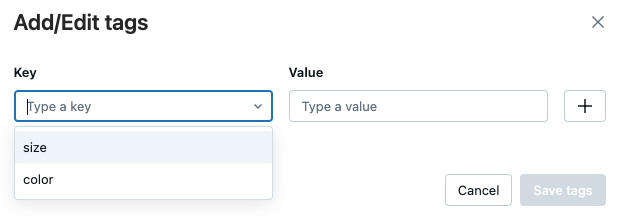
Setelah selesai, klik Simpan tag.
Mereproduksi lingkungan perangkat lunak eksekusi
Anda dapat mereproduksi lingkungan perangkat lunak yang tepat untuk eksekusi dengan mengklik Reproduksi Jalankan di kanan atas halaman eksekusi. Dialog berikut muncul:
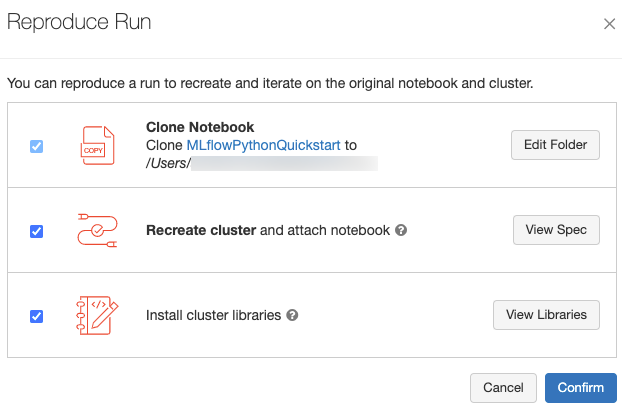
Dengan pengaturan default, saat Anda mengklik Konfirmasi:
- Notebook dikloning ke lokasi yang ditampilkan dalam dialog.
- Jika kluster asli masih ada, notebook kloning dilampirkan ke kluster asli dan kluster dimulai.
- Jika kluster asli tidak ada lagi, kluster baru dengan konfigurasi yang sama, termasuk setiap pustaka yang diinstal, akan dibuat dan dimulai. Notebook dilampirkan ke kluster baru.
Anda dapat memilih lokasi lain untuk notebook kloning dan memeriksa konfigurasi kluster dan pustaka yang diinstal:
- Untuk memilih folder lain untuk menyimpan notebook kloning, klik Edit Folder.
- Untuk melihat spesifikasi kluster, klik Tampilkan Spesifikasi. Untuk mengkloning notebook saja dan bukan kluster, hapus centang opsi ini.
- Jika kluster asli tidak ada lagi, Anda dapat melihat pustaka yang diinstal pada kluster asli dengan mengklik Lihat Pustaka. Jika kluster asli masih ada, bagian ini berwarna abu-abu.
Mengganti nama eksekusi
Untuk mengganti nama sesi, klik ![]() di sudut kanan atas halaman sesi (di samping tombol Izin) dan pilih Ganti Nama.
di sudut kanan atas halaman sesi (di samping tombol Izin) dan pilih Ganti Nama.
Pilih kolom untuk ditampilkan
Untuk mengontrol kolom yang ditampilkan dalam tabel eksekusi pada halaman detail eksperimen, klik Kolom dan pilih dari menu drop-down.
Filter eksekusi
Anda dapat mencari eksekusi dalam tabel di halaman detail eksperimen berdasarkan nilai parameter atau metrik. Anda juga dapat mencari proses berdasarkan tag.
Untuk mencari eksekusi yang cocok dengan ekspresi yang berisi nilai parameter dan metrik, masukkan kueri di bidang pencarian dan tekan Enter. Beberapa contoh sintaks kueri adalah:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Secara default, nilai metrik difilter berdasarkan nilai terakhir yang dicatat. Menggunakan
MINatauMAXmemungkinkan Anda mencari eksekusi berdasarkan nilai metrik minimum atau maksimum. Hanya berjalan yang dicatat setelah Agustus 2024 yang memiliki nilai metrik minimum dan maksimum.Untuk mencari eksekusi berdasarkan tag, masukkan tag dalam format:
tags.<key>="<value>". Nilai string harus diapit dalam tanda kutip seperti yang ditunjukkan.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Kedua kunci dan nilai boleh berisi spasi. Jika kunci menyertakan spasi, Anda harus melampirkannya dengan tanda petik terbalik seperti yang ditunjukkan.
tags.`my custom tag` = "my value"
Anda juga dapat memfilter eksekusi berdasarkan statusnya (Aktif atau Dihapus), saat eksekusi dibuat, dan himpunan data apa yang digunakan. Untuk melakukan ini, buat pilihan Anda dari menu tarik turun Waktu yang dibuat, Status, atau Himpunan Data.
Mengunduh eksekusi
Anda dapat mengunduh eksekusi dari halaman Detail eksperimen sebagai berikut:
Klik
 untuk membuka menu kebab.
untuk membuka menu kebab.
Untuk mengunduh file dalam format CSV yang berisi semua eksekusi yang ditampilkan (hingga maksimum 100), pilih Unduh
<n>eksekusi. MLflow membuat dan mengunduh file dengan satu eksekusi per baris, yang berisi bidang berikut untuk setiap eksekusi:Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...Jika Anda ingin mengunduh lebih dari 100 eksekusi atau ingin mengunduh eksekusi secara terprogram, pilih Unduh semua eksekusi. Dialog terbuka memperlihatkan cuplikan kode yang bisa Anda salin atau buka di buku catatan. Setelah Anda menjalankan kode ini dalam sel buku catatan, pilih Unduh semua baris dari output sel.
Menghapus proses
Anda dapat menghapus eksekusi dari halaman detail eksperimen dengan mengikuti langkah-langkah berikut:
- Dalam percobaan, pilih satu atau beberapa pengujian dengan mengklik kotak di sebelah kiri pengujian.
- Klik Hapus.
- Jika eksekusi merupakan eksekusi induk, putuskan apakah Anda juga ingin menghapus eksekusi turunan. Opsi ini dipilih untuk Anda secara default.
- Klik Hapus untuk mengonfirmasi. Eksekusi yang dihapus disimpan selama 30 hari. Untuk menampilkan eksekusi yang dihapus, pilih Dihapus di bidang Status.
Penghapusan massal berjalan berdasarkan waktu pembuatan
Anda dapat menggunakan Python untuk menghapus eksekusi eksperimen massal yang dibuat sebelum atau pada tanda waktu UNIX.
Dengan menggunakan Databricks Runtime 14.1 atau yang lebih baru, Anda dapat memanggil mlflow.delete_runs API untuk menghapus eksekusi dan mengembalikan jumlah eksekusi yang dihapus.
Berikut ini adalah parameternya mlflow.delete_runs :
-
experiment_id: ID eksperimen yang berisi pengujian yang akan dihapus. -
max_timestamp_millis: Tanda waktu pembuatan maksimum dalam milidetik sejak zaman UNIX untuk menghapus eksekusi. Hanya jalinan yang dibuat sebelum atau pada cap waktu ini yang dihapus. -
max_runs: Opsional. Bilangan bulat positif yang menunjukkan jumlah maksimum pengulangan yang akan dihapus. Nilai maksimum yang diizinkan untuk max_runs adalah 10000. Jika tidak ditentukan,max_runsbernilai bawaan 10000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Menggunakan Databricks Runtime 13.3 LTS atau yang lebih lama, Anda dapat menjalankan kode klien berikut di Notebook Azure Databricks.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Lihat dokumentasi API Eksperimen Azure Databricks untuk parameter dan spesifikasi nilai pengembalian untuk menghapus eksekusi berdasarkan waktu pembuatan.
Pemulihan proses
Anda dapat memulihkan eksekusi yang dihapus sebelumnya dari UI sebagai berikut:
- Pada halaman Eksperimen, di kolom Status, pilih Dihapus untuk menampilkan proses yang dihapus.
- Pilih satu atau beberapa eksekusi dengan mengklik di kotak centang di sebelah kiri eksekusi.
- Klik Pulihkan.
- Klik Pulihkan untuk mengonfirmasi. Eksekusi yang dipulihkan sekarang muncul saat Anda memilih Active di bidang Status.
Pemulihan data secara massal dilakukan berdasarkan waktu penghapusan
Anda juga dapat menggunakan Python untuk memulihkan eksekusi eksperimen massal yang dihapus pada atau setelah tanda waktu UNIX.
Dengan menggunakan Databricks Runtime 14.1 atau yang lebih baru, Anda dapat memanggil mlflow.restore_runs API untuk memulihkan eksekusi dan mengembalikan jumlah eksekusi yang dipulihkan.
Berikut ini adalah parameternya mlflow.restore_runs :
-
experiment_id: ID eksperimen yang berisi eksekusi untuk dipulihkan. -
min_timestamp_millis: Batas waktu minimum penghapusan dalam milidetik sejak zaman UNIX untuk memulihkan proses. Hanya jalinan yang dihapus pada atau setelah tanda waktu ini dipulihkan. -
max_runs: Opsional. Bilangan bulat positif yang menunjukkan jumlah maksimum eksekusi untuk dipulihkan. Nilai maksimum yang diizinkan untuk max_runs adalah 10000. Jika tidak ditentukan, max_runs default ke 10000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Menggunakan Databricks Runtime 13.3 LTS atau yang lebih lama, Anda dapat menjalankan kode klien berikut di Notebook Azure Databricks.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Lihat dokumentasi API Eksperimen Azure Databricks untuk parameter dan spesifikasi nilai pengembalian untuk memulihkan jalannya proses berdasarkan waktu penghapusan.
Membandingkan eksekusi
Anda dapat membandingkan proses dari satu eksperimen atau dari beberapa eksperimen. Halaman Membandingkan Eksekusi menyajikan informasi tentang eksekusi yang dipilih dalam format tabular. Anda juga dapat membuat visualisasi hasil eksekusi dan tabel informasi eksekusi, parameter eksekusi, dan metrik. Lihat Membandingkan eksekusi dan model MLflow menggunakan grafik dan bagan.
Tabel Parameter dan Metrik menampilkan parameter proses dan metrik dari semua proses yang dipilih. Kolom dalam tabel ini diidentifikasi oleh tabel Detail run tepat di atasnya. Untuk kesederhanaan, Anda dapat menyembunyikan parameter dan metrik yang identik dalam semua pengoperasian yang dipilih dengan mengaktifkan  .
.
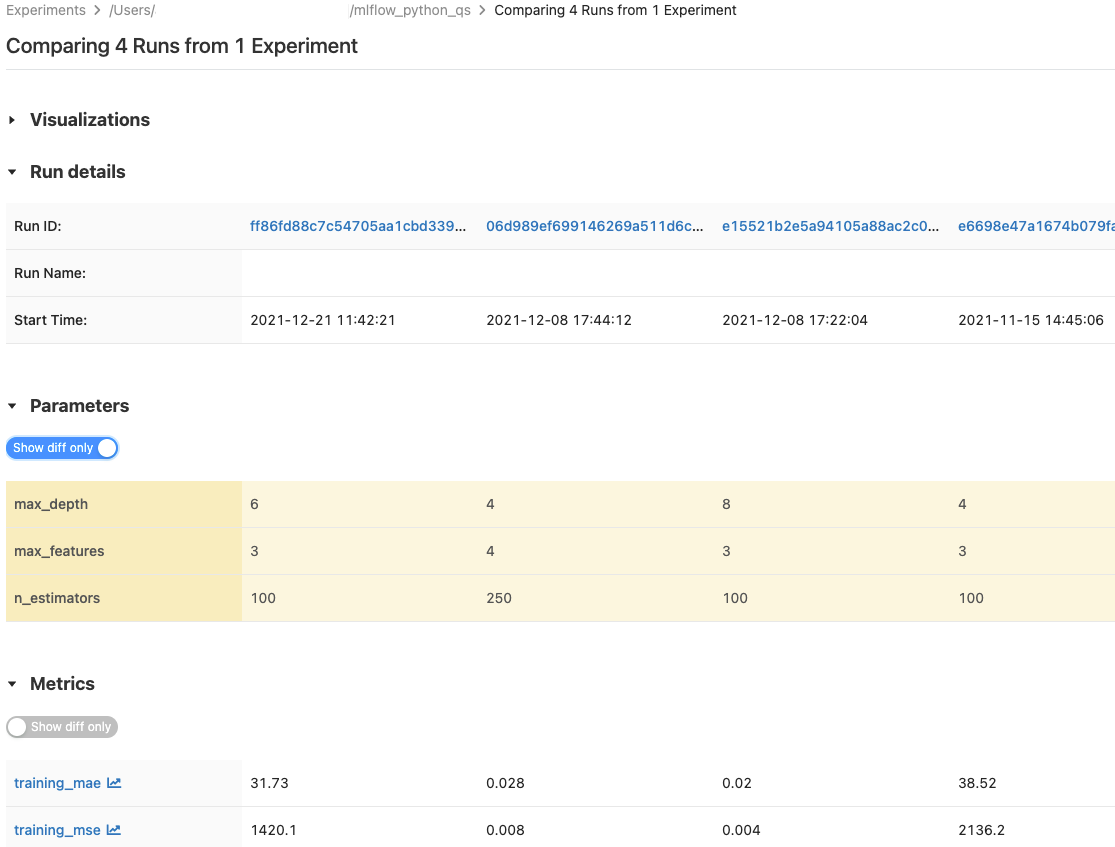
Membandingkan perulangan dari satu eksperimen
- Pada halaman detail eksperimen , pilih dua atau beberapa eksekusi dengan mengklik di kotak centang di sebelah kiri eksekusi, atau pilih semua eksekusi dengan mencentang kotak di bagian atas kolom.
- Klik Bandingkan. Layar Membandingkan
<N>Pelaksanaan muncul.
Membandingkan pelaksanaan dari beberapa eksperimen
- Pada halaman eksperimen, pilih eksperimen yang ingin Anda bandingkan dengan mengeklik kotak di sebelah kiri nama eksperimen.
- Klik Bandingkan (n) (n adalah jumlah eksperimen yang Anda pilih). Sebuah layar muncul yang menunjukkan semua proses dari eksperimen yang Anda pilih.
- Pilih dua atau lebih proses dengan mencentang kotak di sebelah kiri proses, atau pilih semua proses dengan mencentang kotak di bagian atas kolom.
- Klik Bandingkan. Layar Membandingkan Jalankan
<N>muncul.
Membandingkan eksekusi menggunakan tabel sistem
Metadata MLflow untuk eksperimen dan eksekusi juga tersedia dalam tabel sistem, di mana Anda dapat memanfaatkan Databricks SQL dan semua alat lakehouse yang ditawarkan Databricks untuk menganalisis data eksperimen Anda. Untuk detail selengkapnya, lihat Referensi tabel sistem MLflow.
Proses penyalinan dijalankan di antara ruang kerja
Untuk mengimpor atau mengekspor eksekusi MLflow ke atau dari ruang kerja Databricks, Anda bisa menggunakan proyek berbasis komunitas sumber terbuka Ekspor-Impor MLflow.