Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Halaman ini mencakup opsi untuk sumber daya komputasi buku catatan. Anda dapat menjalankan buku catatan pada sumber daya komputasi tujuan umum, komputasi nirkabel, atau, untuk perintah SQL, Anda dapat menggunakan gudang data SQL, jenis komputasi yang dioptimalkan khusus untuk analitik SQL. Untuk informasi selengkapnya tentang jenis komputasi, lihat Komputasi.
Komputasi default
Di ruang kerja yang diaktifkan untuk Katalog Unity, buku catatan baru secara default menggunakan komputasi tanpa server. Jika Anda tidak memilih sumber daya komputasi secara manual dan menjalankan sebuah sel, notebook secara otomatis tersambung ke komputasi tanpa server.
Menyematkan sumber daya komputasi secara otomatis
Di pengaturan pengembang, Anda dapat mengonfigurasi notebook untuk melampirkan secara otomatis ke sumber daya komputasi dan memulai sesi saat Anda berinteraksi dengan editor:
Klik ikon pengguna Anda di kiri atas.
Klik Pengaturan.
Klik Pengembang untuk menavigasi ke pengaturan pengembang Anda.
Aktifkan Buat sesi secara otomatis pada interaksi editor untuk memulai sesi komputasi secara otomatis pada interaksi editor. Databricks secara otomatis menggunakan sumber daya komputasi berdasarkan preferensi Anda (serverless atau gudang SQL) dan sumber daya komputasi terakhir yang digunakan.
OR
Nonaktifkan pengaturan ini jika Anda tidak ingin buku catatan tersambung secara otomatis dan memulai sumber daya komputasi.
Fitur bantuan kode, termasuk pelengkapan otomatis, pemformatan kode, dan debugger, mengharuskan buku catatan dilampirkan ke sesi komputasi aktif. Jika notebook belum memulai sesi komputasi, fitur bantuan kode tidak aktif.
Komputasi tanpa server untuk buku catatan
Komputasi tanpa server memungkinkan Anda menyambungkan notebook Anda dengan cepat ke sumber daya komputasi sesuai permintaan.
Untuk melampirkan ke komputasi tanpa server, klik menu drop-down komputasi di buku catatan dan pilih Tanpa Server.
Lihat Komputasi tanpa server untuk buku catatan untuk informasi selengkapnya.
Pemulihan sesi otomatis untuk notebook tanpa server
Penghentian komputasi tanpa server saat idle dapat menyebabkan Anda kehilangan proses yang sedang berlangsung, seperti nilai variabel Python, di buku catatan Anda. Untuk menghindari hal ini, aktifkan Pemulihan sesi otomatis untuk notebook tanpa server.
- Klik nama pengguna Anda di kanan atas ruang kerja Anda, lalu klik Pengaturan di daftar drop-down.
- Di bilah samping Pengaturan
, pilihPengembang . - Di bawah Fitur eksperimental, aktifkan Pemulihan otomatis sesi untuk notebook tanpa server .
Mengaktifkan pengaturan ini memungkinkan Databricks untuk mengambil rekam jepret status memori notebook tanpa server sebelum penghentian diam. Saat Anda kembali ke buku catatan setelah pemutusan sambungan karena tidak aktif, banner muncul di bagian atas halaman. Klik Sambungkan kembali untuk memulihkan status kerja Anda.
Saat Anda terhubung kembali, Databricks menginstal ulang seluruh lingkungan kerja Anda, termasuk:
- Python variabel, fungsi, dan definisi kelas: status Python diserialisasikan dalam proses menggunakan pickle/cloudpickle dan dipulihkan ke REPL baru, sehingga Anda tidak perlu mengimpor ulang atau mendeklarasi ulang.
- Spark DataFrames, cache, dan tampilan sementara: Data yang telah Anda muat, ubah, atau di-cache (termasuk tampilan sementara) dipertahankan, sehingga Anda menghindari pemuatan ulang atau komputasi ulang yang mahal.
- Status sesi Spark: Pengaturan konfigurasi tingkat Spark, tampilan sementara, modifikasi katalog, dan fungsi yang ditentukan pengguna (UDF) dipulihkan melalui migrasi sesi Spark Connect, sehingga Anda tidak perlu mengatur ulang.
Jika lingkungan telah berubah dengan cara yang akan membuat deserialisasi tidak aman, misalnya, versi Python atau paket yang tidak kompatibel, snapshot dibatalkan dan notebook beralih kembali ke sesi baru.
Penyimpanan data rekam jepret
Data rekam jepret disimpan di penyimpanan default ruang kerja Anda. Notebook itu sendiri hanya menyimpan metadata, termasuk pointer dengan ID notebook, tanda waktu, dan informasi sesi. Data beban tidak disimpan di notebook. Jalur blob dienkripsi sebelum disimpan dalam atribut notebook, dan jalur snapshot dikecualikan dari ekspor dan impor notebook untuk mencegah mengembalikan status ke ruang kerja yang berbeda.
Rekam jepret mengikuti default TTL penyimpanan cloud Anda (sekitar satu bulan) dan kedaluwarsa secara otomatis. Menghapus buku catatan juga menghapus rekam jepretnya. Akun cloud Anda dikenakan biaya penyimpanan sebagai bagian dari penggunaan penyimpanan ruang kerja standar. Fitur ini menggunakan serialisasi proses Python alih-alih titik pemeriksaan tingkat kontainer, yang menjaga rekam jepret lebih kecil dan lebih cepat untuk dibuat.
Keamanan dan kontrol akses
Pemulihan rekam jepret menghormati izin notebook. Memulihkan status memerlukan izin RUN pada buku catatan. Metadata terenkripsi mencegah penonton mengambil blob rekam jepret secara langsung, dan pemeriksaan izin diberlakukan saat pemulihan.
Keterbatasan
Fitur ini memiliki batasan dan tidak mendukung pemulihan hal berikut:
- Status Spark lebih lama dari 4 hari
- Status Spark lebih besar dari 50 MB
- Data yang terkait dengan SQL Scripting
- Penanganan berkas
- Kunci dan primitif konkurensi lainnya
- Koneksi jaringan
Melampirkan buku catatan ke sumber daya komputasi serbaguna
Untuk melampirkan buku catatan ke sumber daya komputasi serba guna, Anda memerlukan izin dapat melampirkan ke pada sumber daya komputasi.
Penting
Selama buku catatan terhubung ke sumber daya komputasi, setiap pengguna dengan izin untuk MENJALANKAN buku catatan secara implisit memiliki izin untuk mengakses sumber daya komputasi.
Untuk melampirkan buku catatan ke sumber daya komputasi, klik pemilih komputasi di toolbar buku catatan dan pilih sumber daya dari menu drop-down.
** Menu menunjukkan pilihan komputasi serba guna dan gudang SQL yang telah Anda gunakan baru-baru ini atau yang sedang dijalankan.
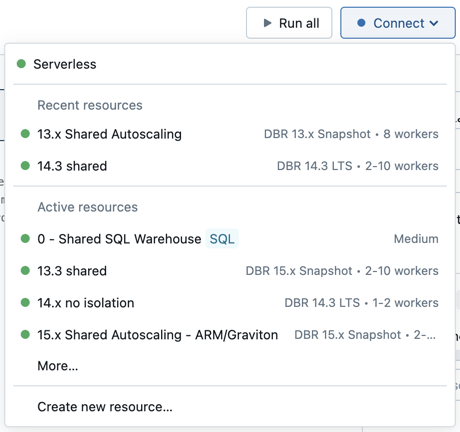
Untuk memilih dari semua sumber daya komputasi yang tersedia, klik Lainnya.... Pilih dari komputasi umum atau gudang SQL yang tersedia.
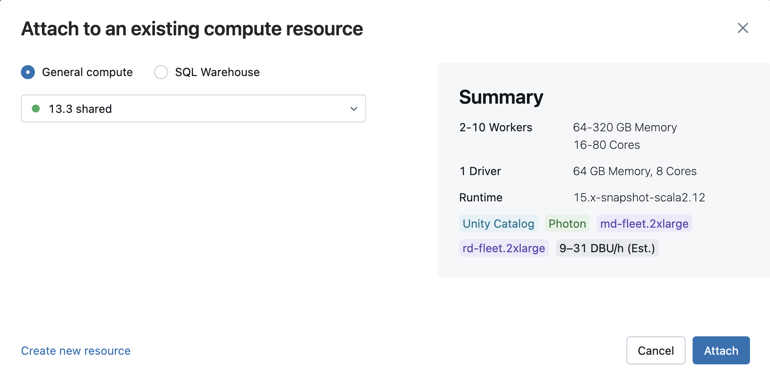
Anda juga dapat membuat sumber daya komputasi serba guna baru dengan memilih Buat sumber daya baru... dari menu drop-down.
Penting
Notebook terlampir memiliki variabel Apache Spark berikut yang ditentukan.
| Kelas | Nama Variabel |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Jangan membuat SparkSession, , SparkContextatau SQLContext. Melakukannya menyebabkan perilaku yang tidak konsisten.
Menggunakan notebook dengan gudang SQL
Saat buku catatan dilampirkan ke gudang SQL, Anda bisa menjalankan sel SQL dan Markdown. Menjalankan sel dalam bahasa lain (seperti Python atau R) menimbulkan kesalahan. Sel SQL yang dijalankan pada gudang SQL muncul dalam riwayat kueri gudang SQL. Pengguna yang menjalankan kueri dapat menampilkan profil kueri dari buku catatan dengan mengklik waktu yang berlalu di bagian bawah output.
Notebook yang dilampirkan ke gudang SQL mendukung sesi gudang SQL, di mana Anda dapat menentukan variabel, membuat tampilan sementara, dan mempertahankan status di beberapa eksekusi kueri. Anda dapat membangun logika SQL secara berulang tanpa perlu menjalankan semua pernyataan sekaligus. Lihat Apa itu sesi gudang SQL?.
Menjalankan notebook memerlukan gudang SQL pro atau tanpa server. Anda harus memiliki akses ke ruang kerja dan gudang SQL.
Untuk melampirkan buku catatan ke gudang SQL, lakukan hal berikut:
Klik pemilih komputasi di toolbar buku catatan. Menu drop-down menunjukkan sumber daya komputasi yang sedang berjalan atau yang baru-baru ini Anda gunakan. Gudang SQL ditandai dengan
 .
.Dari menu, pilih gudang SQL.
Untuk melihat semua gudang SQL yang tersedia, pilih Lainnya... dari menu drop-down. Dialog muncul memperlihatkan sumber daya komputasi yang tersedia untuk buku catatan. Pilih Gudang SQL, pilih gudang yang ingin Anda gunakan, dan klik Lampirkan.
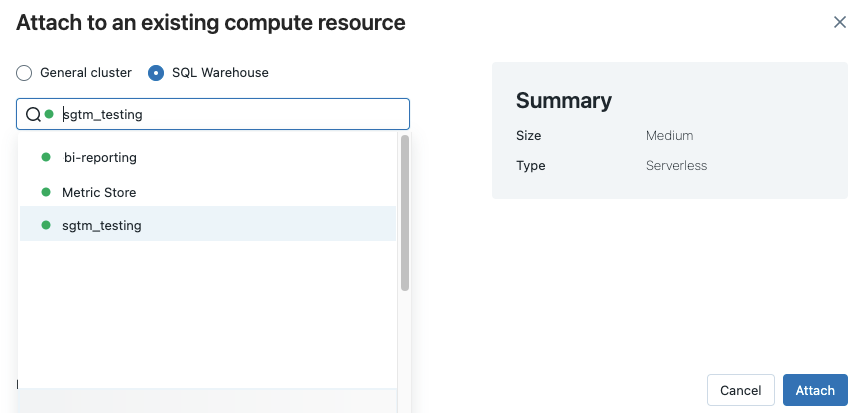
Anda juga dapat memilih gudang SQL sebagai sumber daya komputasi untuk notebook SQL saat Anda membuat alur kerja atau pekerjaan terjadwal.
Batasan gudang SQL
Lihat Batasan buku catatan Databricks yang diketahui untuk informasi selengkapnya.