Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Lakebase Autoscaling adalah versi terbaru Lakebase, dengan komputasi penskalaan otomatis, skala-ke-nol, percabangan, dan pemulihan instan. Untuk wilayah yang didukung, lihat Ketersediaan wilayah. Jika Anda adalah pengguna Lakebase Provisioned, lihat Lakebase Provisioned.
Ketersediaan tinggi memasangkan instans komputasi baca/tulis utama dengan satu atau beberapa instans komputasi sekunder yang didistribusikan secara geografis di seluruh zona ketersediaan. Ketika primer menjadi tidak tersedia, instans komputasi sekunder secara otomatis dipromosikan dan aplikasi Anda berlanjut dari transaksi terakhir yang dilakukan. String koneksi Anda tetap tidak berubah.
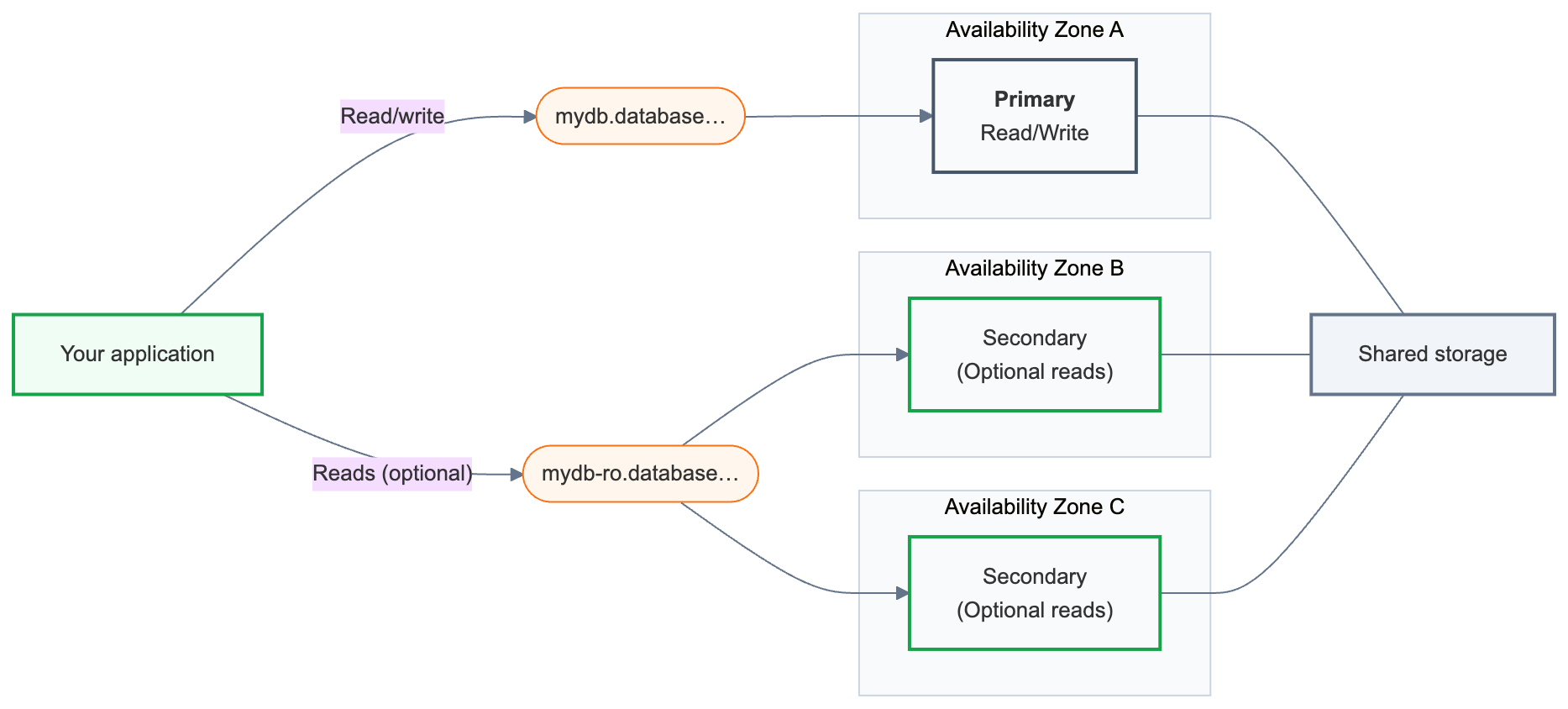
Cara kerja dari konsep ketersediaan tinggi
Titik akhir Lakebase adalah alamat database yang terhubung dengan aplikasi Anda. Titik akhir dengan ketersediaan tinggi menyediakan dua string koneksi.
-
Primer (
{endpoint-id}.database.{region}.databricks.com) — koneksi baca/tulis utama Anda. Gunakan ini di setiap aplikasi yang tersambung ke database Anda. Setelah failover, ia secara otomatis mengalihkan ke komputasi mana pun yang sekarang menjadi utama. -
Sekunder (
{endpoint-id}-ro.database.{region}.databricks.com) — hanya tersedia saat Izinkan akses ke instans komputasi baca-saja diaktifkan. Instans komputasi sekunder terutama ada sebagai cadangan untuk failover; mengaktifkan akses baca memungkinkan Anda juga merutekan kueri baca di antara instans-instans tersebut.
Kedua string koneksi tersedia dari dialog Sambungkan di titik akhir Anda.
Di balik string koneksi ini, titik akhir ketersediaan tinggi selalu memiliki tepat satu instans komputasi utama dan satu hingga tiga instans komputasi sekunder . Primer menangani semua lalu lintas baca/tulis. Instans komputasi sekunder berjalan di zona ketersediaan yang berbeda dan dipromosikan untuk menjadi yang utama jika terjadi kegagalan.
Setiap instans komputasi sekunder memiliki pengaturan Akses yang menentukan apakah instans tersebut juga melayani lalu lintas baca:
| Akses sekunder | Apa fungsinya |
|---|---|
| Baca-saja | Instans komputasi sekunder melayani pembacaan melalui -ro string koneksi dan dapat dipromosikan sebagai primer sesuai kebutuhan |
| Nonaktif | Instans komputasi sekunder aktif dan siap untuk failover, tetapi tidak melayani lalu lintas pembacaan data. |
Anda mengendalikan ini dengan pengaturan Izinkan akses ke instans komputasi baca-saja di titik akhir, yang dapat Anda akses di tab Edit komputasi. Saat diaktifkan, semua instans komputasi sekunder melayani permintaan baca; saat dinonaktifkan, mereka berfungsi sebagai cadangan untuk pengalihan otomatis. Dalam kedua kasus, perangkat keras komputasi sudah dialokasikan dan berjalan: promosi tidak memerlukan provisi baru, sehingga kapasitas failover Anda dicadangkan terlepas dari permintaan di zona ketersediaan.
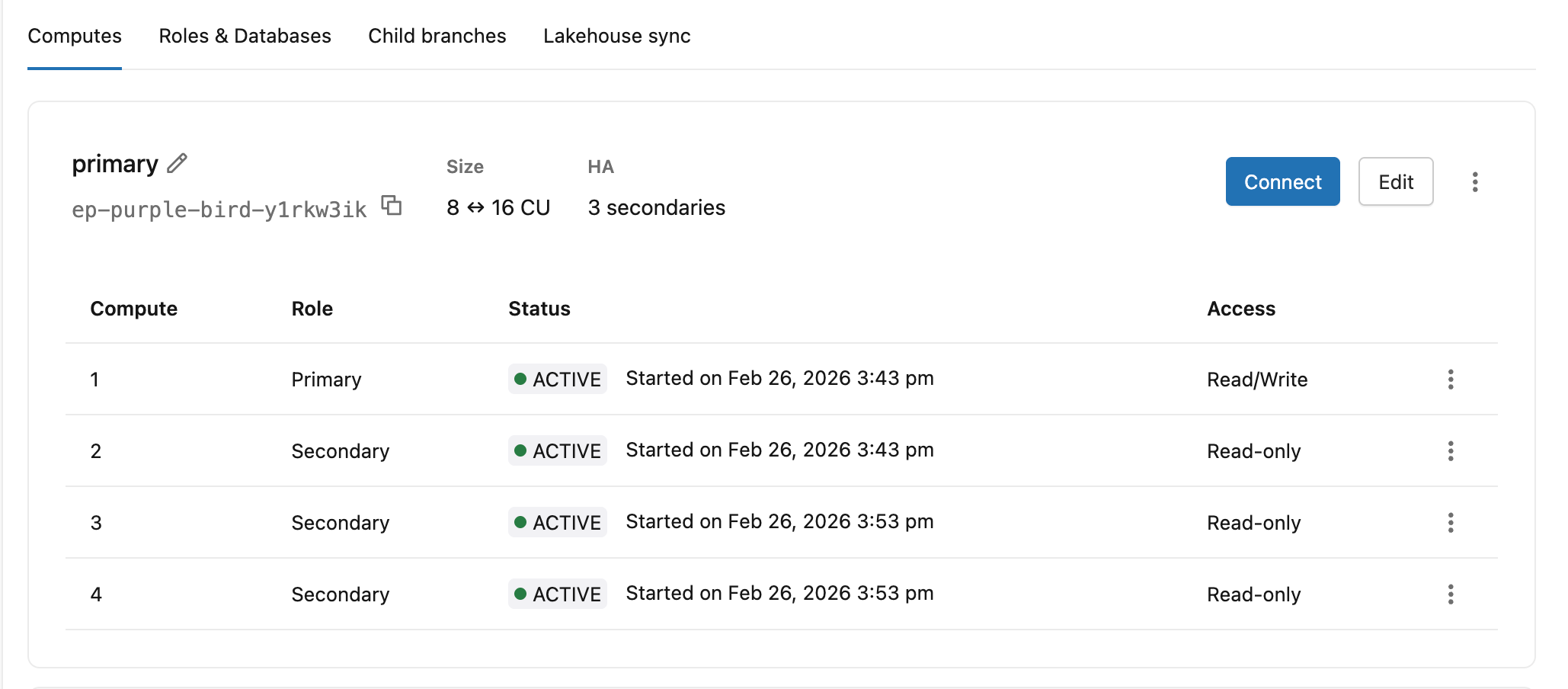
Tab Komputasi memperlihatkan peran setiap instans komputasi ( Primer atau Sekunder), Status, dan Tingkat akses secara sekilas.
Distribusi AZ
Lakebase mendistribusikan instans komputasi primer dan sekunder di seluruh zona ketersediaan, mengurangi risiko bahwa satu kegagalan AZ memengaruhi instans komputasi utama dan semua sekunder.
Autoscaling pada ketersediaan tinggi
Semua instans komputasi dalam konfigurasi ketersediaan tinggi memiliki rentang penskalaan otomatis yang sama. Rentang maksimum antara CU minimum dan maksimum Anda adalah 16 CU, batas yang sama dengan instans komputasi standalone.
Instans komputasi sekunder selalu diskalakan ke setidaknya ukuran CU yang sama dengan yang utama, memastikan kapasitas database Anda tetap konsisten setelah failover.
Skala ke nol tidak tersedia untuk instans komputasi dalam konfigurasi ketersediaan tinggi. Anda dapat menjeda semua instans komputasi secara manual, tetapi titik akhir Anda tidak akan tersedia saat dijeda.
Instans komputasi sekunder vs. replika baca mandiri
Instans komputasi sekunder dan replika baca mandiri adalah fitur berbeda yang dapat hidup berdampingan di cabang yang sama:
| Instance komputasi sekunder | Replika baca mandiri | |
|---|---|---|
| Kegunaan | Failover + pemindahan beban baca opsional | Baca offload saja |
| Ditambahkan melalui | Konfigurasi ketersediaan tinggi | Tambahkan Baca Replika |
| Berpartisipasi dalam proses failover | Yes | No |
| Rangkaian koneksi |
-ro pada titik akhir utama |
Memiliki titik akhir terpisah |
| Ukuran | Dibagikan dengan primer (tingkat titik akhir) | Berukuran mandiri |
Ketika Anda membutuhkan ketersediaan tinggi dan kapasitas baca tambahan di luar apa yang disediakan instans komputasi sekunder Anda, Anda dapat menggabungkan kedua fitur di cabang yang sama. Lihat Membaca replika.
Perilaku failover
Failover otomatis
Lakebase memantau kesehatan komputasi utama terus menerus. Jika server utama menjadi tidak tersedia, failover akan diaktifkan secara otomatis.
Failover mempertahankan semua transaksi yang dilakukan.
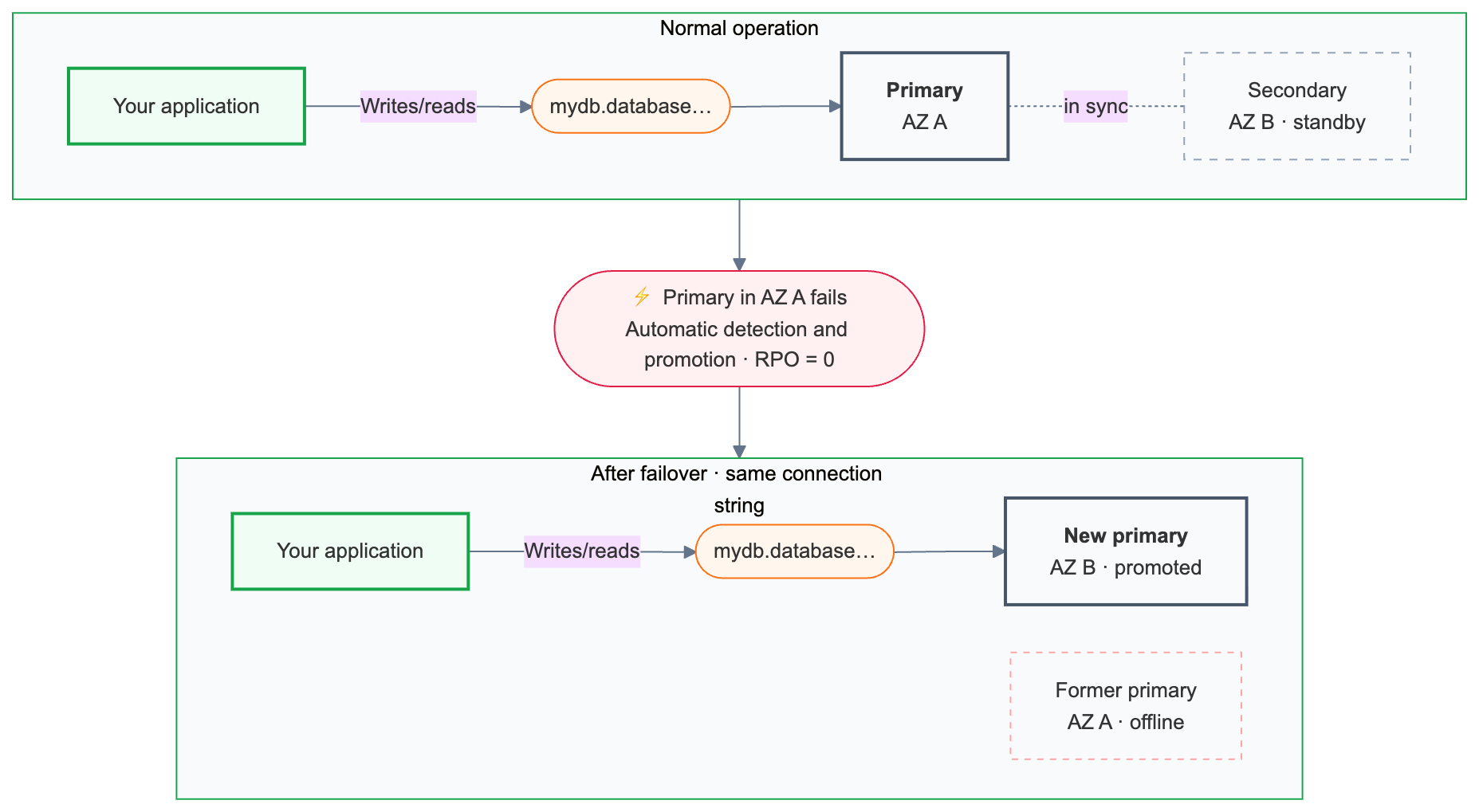
Setelah failover, string koneksi utama ({endpoint-id}.database.{region}.databricks.com) secara otomatis mengarahkan ke instans komputasi yang baru dinaikkan posisinya. Aplikasi tidak perlu mengubah konfigurasi koneksinya, tetapi koneksi yang ada dihentikan selama failover dan harus terhubung kembali. Aplikasi dengan logika coba lagi menangani ini secara otomatis.
Failover dengan akses hanya baca diaktifkan
Saat Izinkan akses ke instans komputasi baca-saja diaktifkan dan failover terjadi, sekunder yang dinaikkan menjadi primer baru dan menghentikan layanan pembacaan. Jika Anda memiliki dua atau lebih sekunder yang dapat dibaca, lalu lintas pembacaan di -ro string koneksi berlanjut pada kapasitas yang berkurang hingga penggantian disediakan. Jika Anda hanya memiliki satu, pembacaan data sepenuhnya terganggu sampai penggantian siap.
String sambungan
Dialog Sambungkan memperlihatkan kedua string koneksi dengan status komputasinya saat ini:
| Opsi Komputasi dalam dialog 'Sambungkan' | Rangkaian koneksi | Gunakan untuk |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
Semua penulisan; pembacaan yang harus mencapai primer utama saat ini. |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
Offload baca ke instans komputasi sekunder (hanya tersedia ketika opsi Izinkan akses ke instans komputasi hanya-baca diaktifkan) |
String koneksi utama selalu dialihkan ke primary yang aktif, termasuk setelah failover.
Setiap instans komputasi juga memiliki string koneksi langsungnya sendiri, dapat diakses dari tab Komputasi melalui menu tindakan (⋮) pada setiap baris. Koneksi langsung ditujukan untuk memecahkan masalah instans komputasi individual, bukan untuk penggunaan aplikasi. String koneksi langsung berlaku untuk setiap komputasi dan dapat berubah ketika komponen sekunder ditambahkan, dihapus, atau dipromosikan.
Batas ketersediaan tinggi
| Limit | Nilai |
|---|---|
| Instans komputasi | 2, 3, atau 4 (1 instans komputasi primer + 1–3 sekunder) |
| Rentang skala otomatis (maks − min) | ≤ 16 CU antara minimum dan maksimum |
| Skalakan ke nol | Tidak tersedia untuk instans komputasi dalam konfigurasi ketersediaan tinggi |
Praktik terbaik
Mengikuti praktik ini membantu aplikasi Anda tetap tangguh dan tersedia selama peristiwa failover.
| Latihan | Rincian |
|---|---|
| Menerapkan logika coba lagi koneksi | Koneksi aktif dihentikan selama failover. Koneksi ke primer yang gagal mungkin macet hingga waktu habis — konfigurasikan keepalives TCP atau batas waktu koneksi di driver Anda untuk segera mendeteksi kegagalan. Koneksi ke unit sekunder yang sedang dipromosikan secara aktif diputuskan, dan segera memberikan pesan kesalahan. Aplikasi dengan logika coba lagi terhubung kembali secara otomatis dalam hitungan detik. |
| Mengonfigurasi jumlah sekunder untuk kasus penggunaan Anda | Setiap instance komputasi sekunder mewakili perangkat keras yang sudah dialokasikan dan dicadangkan untuk keperluan failover. Mengurangi jumlah sekunder Anda berarti lebih sedikit kapasitas failover dan lebih sedikit zona ketersediaan yang tercakup. Satu instans komputasi sekunder menyediakan cakupan failover. Jika Anda mengaktifkan sekunder yang dapat dibaca, konfigurasikan dua atau lebih. Dengan hanya satu node, pembacaan sepenuhnya terganggu selama failover hingga penggantian disediakan. |
| Hindari kelebihan beban instans komputasi sekunder | Layanan ini dapat memulai ulang instans komputasi sekunder yang kelebihan beban atau tertinggal. Pantau beban kueri dan jumlah koneksi, dan tingkatkan ukuran CU jika Anda mengamati pemanfaatan tinggi berkelanjutan. |
Langkah berikutnya
- Mengelola ketersediaan tinggi untuk mengaktifkan dan mengonfigurasi ketersediaan tinggi
- Penskalaan otomatis untuk detail tentang ukuran CU dan rentang penskalaan otomatis
- String koneksi untuk referensi string koneksi yang lengkap